在容器与 Kubernetes 场景里,"僵尸进程"看起来是个小问题,但一旦放任不管,会逐步侵蚀节点可用的 PID 资源,最终演变为无法创建新进程、业务异常甚至节点不稳定。更棘手的是:容器里最常见的 PID 1 往往并不是传统意义上的 init 进程,它可能不会回收子进程,导致僵尸进程在容器生命周期内长期存在。
本文从 Linux 进程回收机制出发,解释为什么容器更容易遇到僵尸进程,并给出 Kubernetes 中可落地的三类方案,重点讲清楚生产最通用的选择:使用轻量 init(tini / dumb-init)让容器优雅、可控地回收僵尸进程与转发信号。
一、什么是僵尸进程?为什么它会成为隐患?
理解僵尸进程,先看一个"正常退出"应该发生什么:
- 子进程结束时向父进程发送
SIGCHLD - 父进程收到信号后调用
wait/waitpid回收子进程的退出状态与内核资源
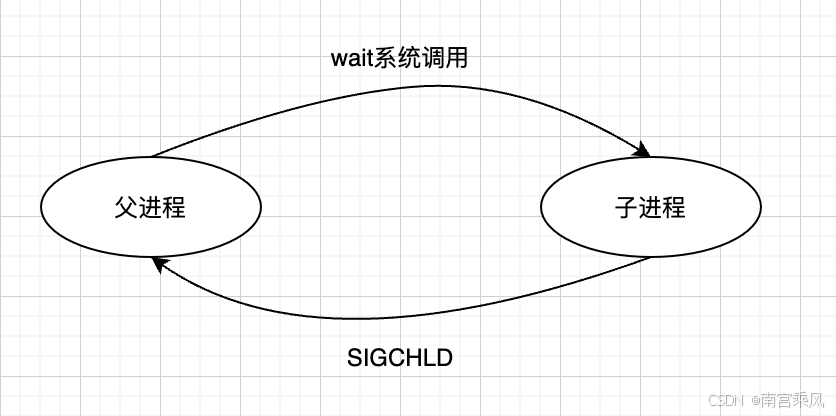
僵尸进程(Zombie Process)是指:子进程已经退出,但父进程没有执行 wait 回收。它不会占用 CPU/内存,但会在进程表中保留记录,并持续占用 PID。
为什么这很危险:
- 僵尸进程无法通过
kill清除(它已经退出,只是"尸体"没被回收) - PID 是有限资源,持续积累会导致 PID 耗尽,新进程无法创建,严重时系统行为异常

二、为什么容器/Pod 环境更容易出现僵尸进程?
在宿主机上,孤儿进程会被 init(PID 1)接管并回收,很多"父进程没做好回收"的问题会被系统兜底。
但在容器里,情况变了:
- 容器通常有独立 PID 命名空间
- 容器内的 PID 1 往往是镜像的 ENTRYPOINT/CMD(例如你的应用、shell 脚本、语言运行时)
- 如果这个 PID 1 不具备 init 的职责(不 wait、不转发信号),孤儿进程更容易变成僵尸进程,并且一直存在到容器重启
这就是容器世界里"PID 1 问题"的核心:你的业务进程被迫承担 init 的责任,但大多数业务并没为此设计。
三、Kubernetes 中三类主流方案:怎么选?
解决僵尸进程,本质上是在补齐两件事:
- 回收子进程(wait/waitpid)
- 正确处理信号(SIGTERM 等),保证优雅退出
在 Kubernetes 里常见有三类做法。
方案 1:共享 Pod 进程命名空间(shareProcessNamespace)
k8s 中 pause 容器 是所有容器的 父容器(parent container),它有2个作用
- 它是pod中 Linux命名空间 共享的基础
- 启用 PID 命名空间 共享,pod 中 PID 1 的 init 进程有它维护,并接收收割僵尸进程
启用 shareProcessNamespace: true 后,Pod 内多个容器共享 PID 命名空间,Pause 容器会更像一个"兜底的 init",孤儿进程有机会被接管回收。
示例:
yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
shareProcessNamespace: true
containers:
- name: app
image: my-app:latest
command: ["/app"]优点:
- 平台原生能力,不一定需要改镜像
- 对某些调试/观测场景很方便(容器间可看到彼此进程)
注意事项:
- 进程可见性提升会带来隔离性下降,需要评估安全影响
- 这不是万能解:如果主进程本身产生僵尸进程(父进程是主进程),Pause 并不能替它回收
方案 2:使用轻量 init(tini / dumb-init)作为容器 PID 1(推荐)
这是最通用、最推荐的生产做法:在容器里引入一个轻量 init 作为 PID 1,它负责:
- 作为 PID 1 运行并回收子进程(避免僵尸堆积)
- 将信号转发给业务进程(例如
SIGTERM),保证优雅退出
在绝大多数"业务会 fork/exec 子进程或调用外部命令"的容器里,这个方案能显著降低僵尸风险,并改善退出行为。
2.1 使用 tini:Dockerfile 落地示例
以 Debian/Ubuntu 基础镜像为例:
dockerfile
FROM ubuntu:22.04
RUN apt-get update && apt-get install -y tini
ENTRYPOINT ["/usr/bin/tini", "--"]
CMD ["/app/my-app"]部署到 Kubernetes 时无需额外配置,镜像入口已经交给 tini:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: app
image: my-app-with-tini:latest2.2 使用 dumb-init:适合需要处理后台/进程组的场景
示例(alpine 体系):
dockerfile
FROM nginx:alpine
RUN wget -O /usr/bin/dumb-init https://github.com/Yelp/dumb-init/releases/download/v1.2.2/dumb-init_1.2.2_amd64 \
&& chmod +x /usr/bin/dumb-init
ENTRYPOINT ["/usr/bin/dumb-init", "--"]
CMD ["nginx", "-g", "daemon off;"]选择建议(经验法则):
- 绝大多数场景优先 tini:简单、稳定、通用
- 如果你的容器里经常有后台进程、需要更"进程组级别"的信号处理,再考虑 dumb-init
方案 3:运行时层启用 init(例如 Docker 的 --init 思路)
某些运行时支持在启动容器时自动加一个 init 进程;如果你无法改镜像,可以评估用运行时能力来补齐 init 职责。
该方案的限制也很明显:会依赖运行时实现,平台一致性与可移植性相对弱。能改镜像时,通常优先方案 2。
四、实战:如何验证容器内是否有僵尸进程?
在 Pod 内检查僵尸进程,最直观的方式是查看进程状态(Z/defunct)。
进入容器后:
bash
ps -ef如果看到类似:
[xxx] <defunct>- 或进程状态为
Z
通常意味着存在僵尸进程,需要确认父进程是否在回收。
你也可以把这个检查做成周期性巡检任务(结合业务特点设置频率),在僵尸开始堆积前就发现问题。
五、落地建议:生产环境怎么做更稳?
- 优先把 tini 作为容器 ENTRYPOINT:成本低、收益大,是最稳妥的"通用补丁"
- 谨慎开启
shareProcessNamespace:它改变了容器隔离边界,适合明确需要的 Pod(例如监控、调试、sidecar 协作) - 不要依赖"重启容器"解决僵尸:重启只是清空现场,根因仍在
- 如果应用本身频繁派生子进程且父进程不 wait,最终仍需要从应用层修复(正确处理 SIGCHLD / wait)
六、总结
僵尸进程的本质是"子进程退出后没有被父进程回收",容器环境让这个问题更容易暴露,因为容器内 PID 1 往往不是一个真正的 init。Kubernetes 里可以用共享进程命名空间兜底,但生产更通用、影响面更可控的做法,是在镜像中引入 tini/dumb-init 作为轻量 init:既能回收僵尸进程,也能正确转发信号,显著提升容器的稳定性与可运维性。