我们使用Django框架来实现我们的后端
我们先初始化我们的一个Django项目
我们先创建一个虚拟环境
我们随便找个目录文件,cmd进入到该目录
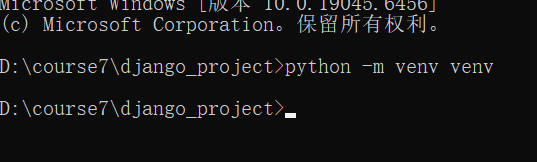
使用python命令创建一个虚拟环境python -m venv venv
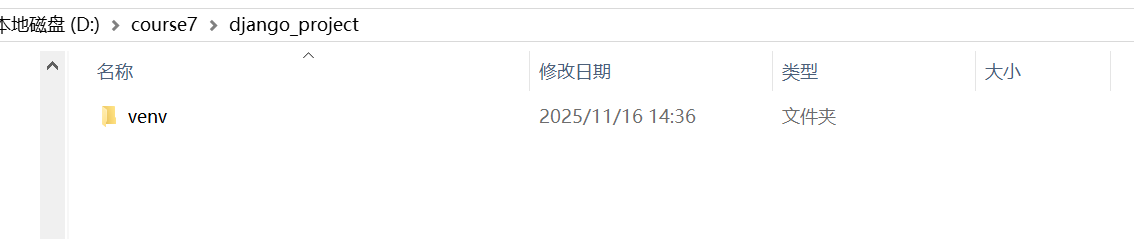
我们看下 本地目录实际上已经创建好了
然后我们进入到我们的script目录激活或者说进入虚拟环境
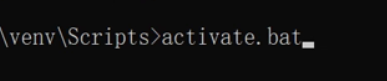
执行activate或者activate.bat都可以
回车后我们进入到虚拟环境里面
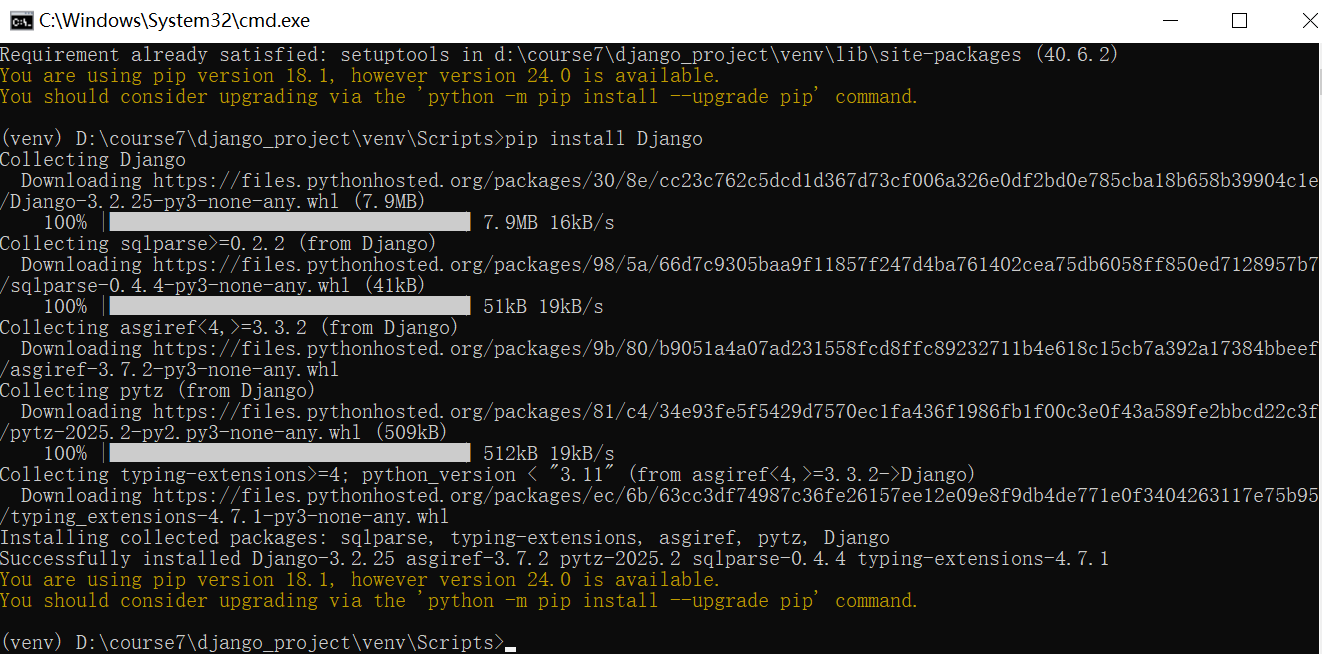
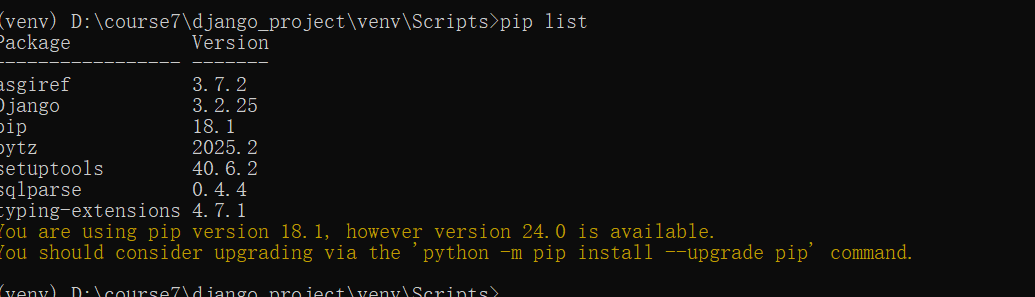
然后安装setuptools和django
然后,我们也可以使用pip list来查看我们安装了哪些库
接下来初始化一个Django的项目
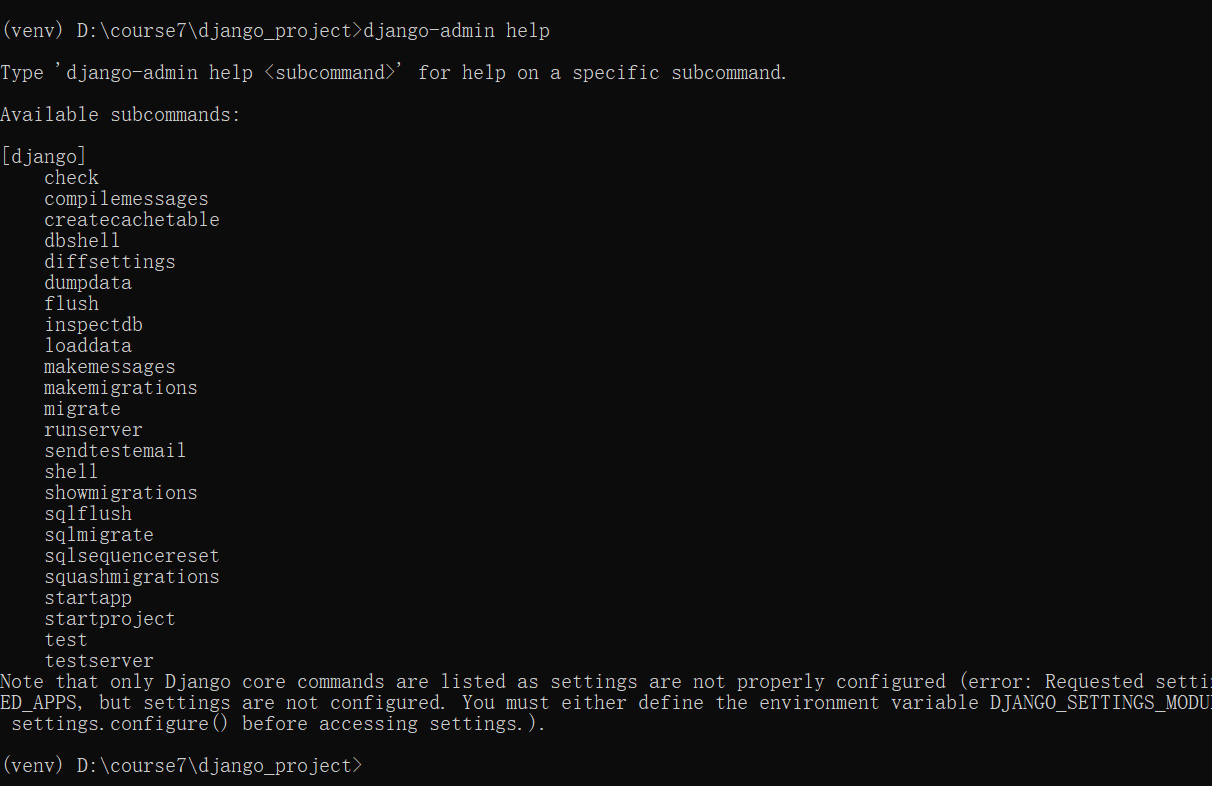
我们安装了Django就可以使用Django命令了,我们首先使用django-admin help命令看下有些命令
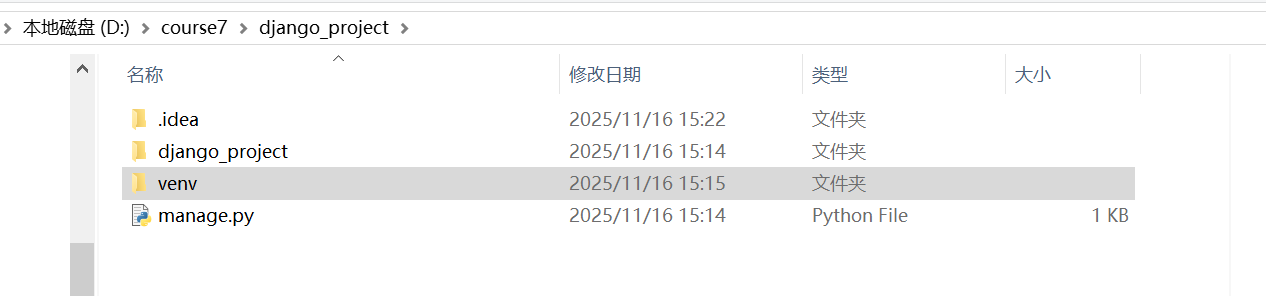
我们使用startproject来创建一个项目django-admin startproject django_project
最终的目录层级如下:
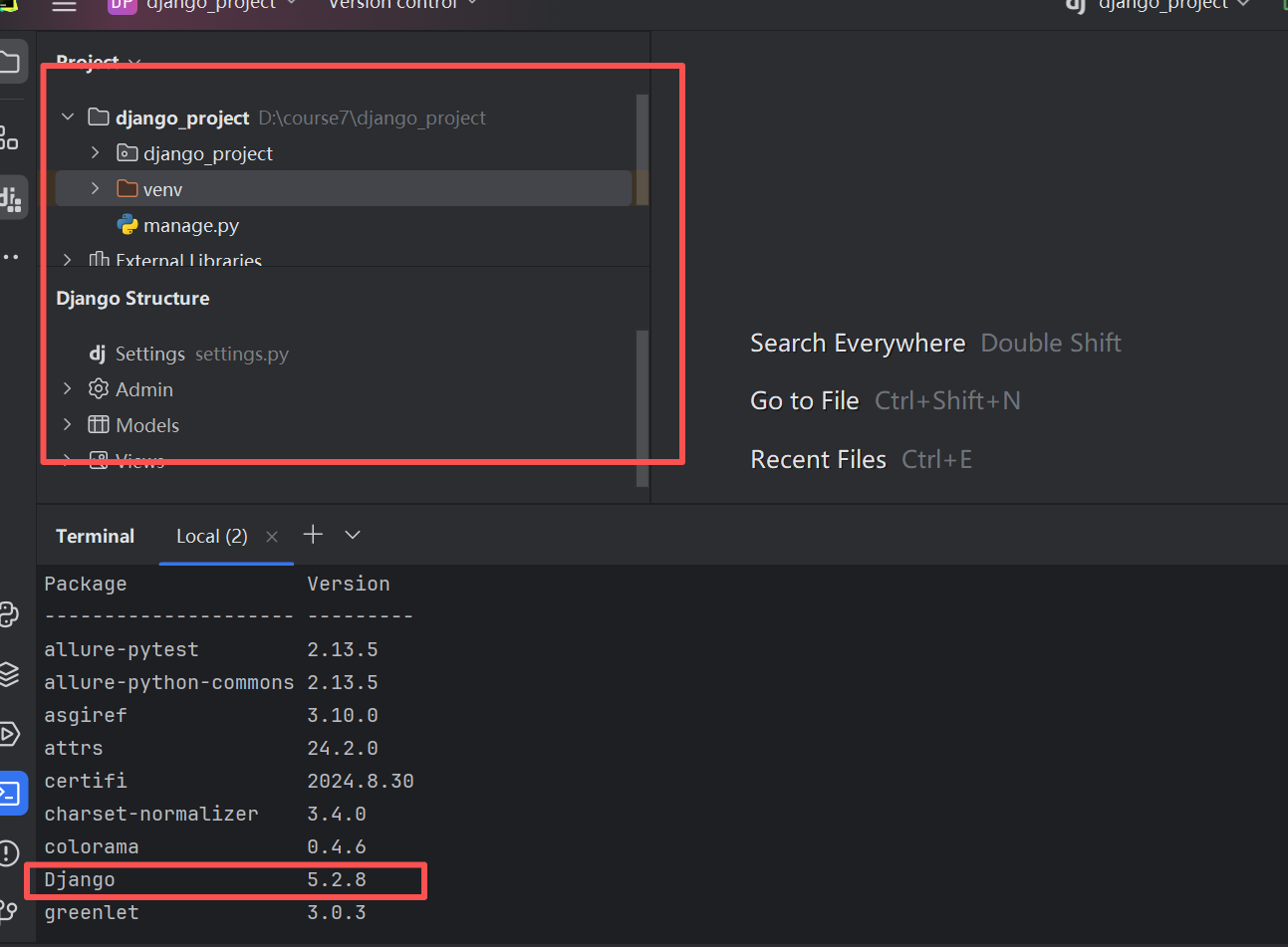
不过建议还是通过pycharm虚拟环境去进行安装
当然,我们也可以去启动这个项目
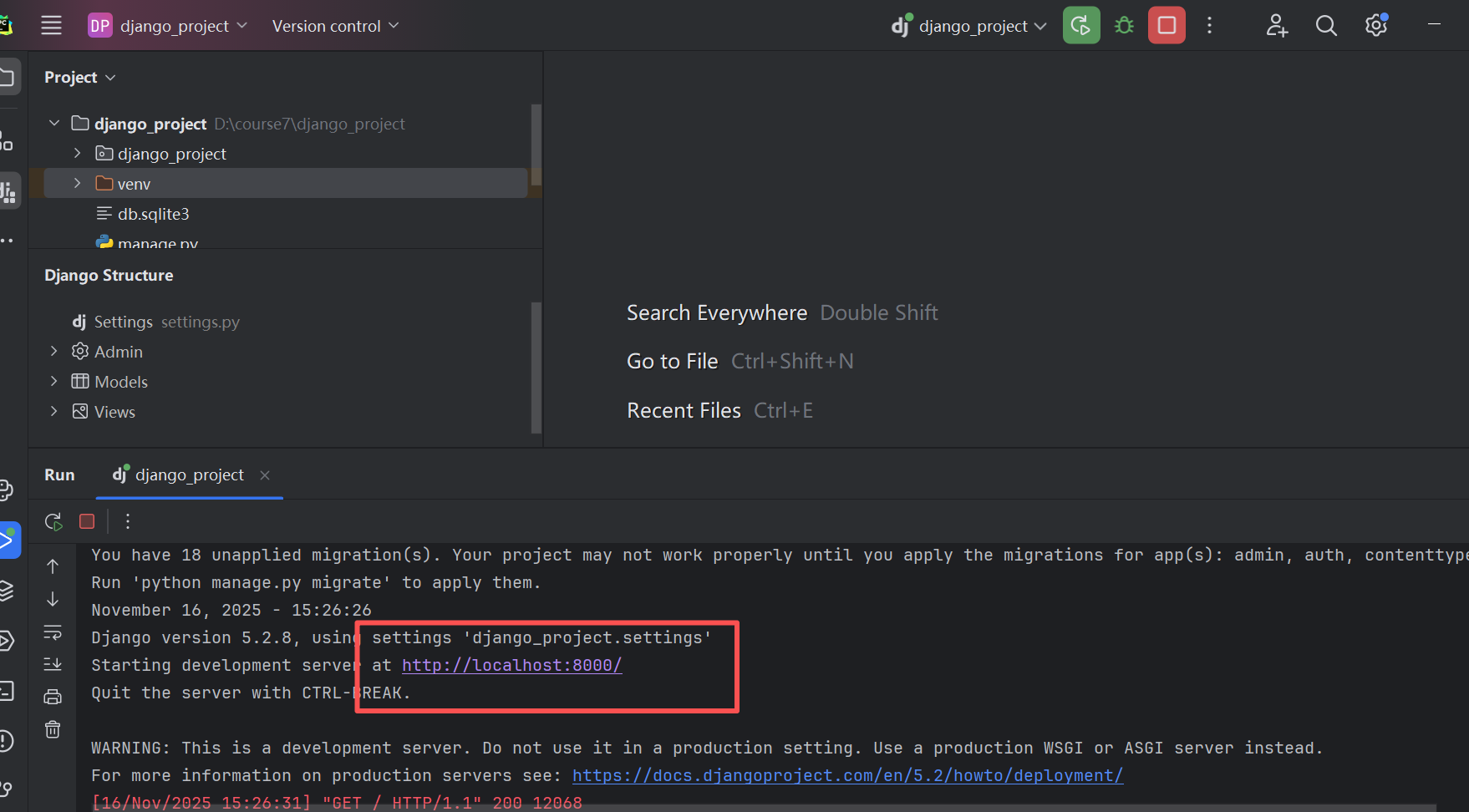
本地项目打开也不会报错
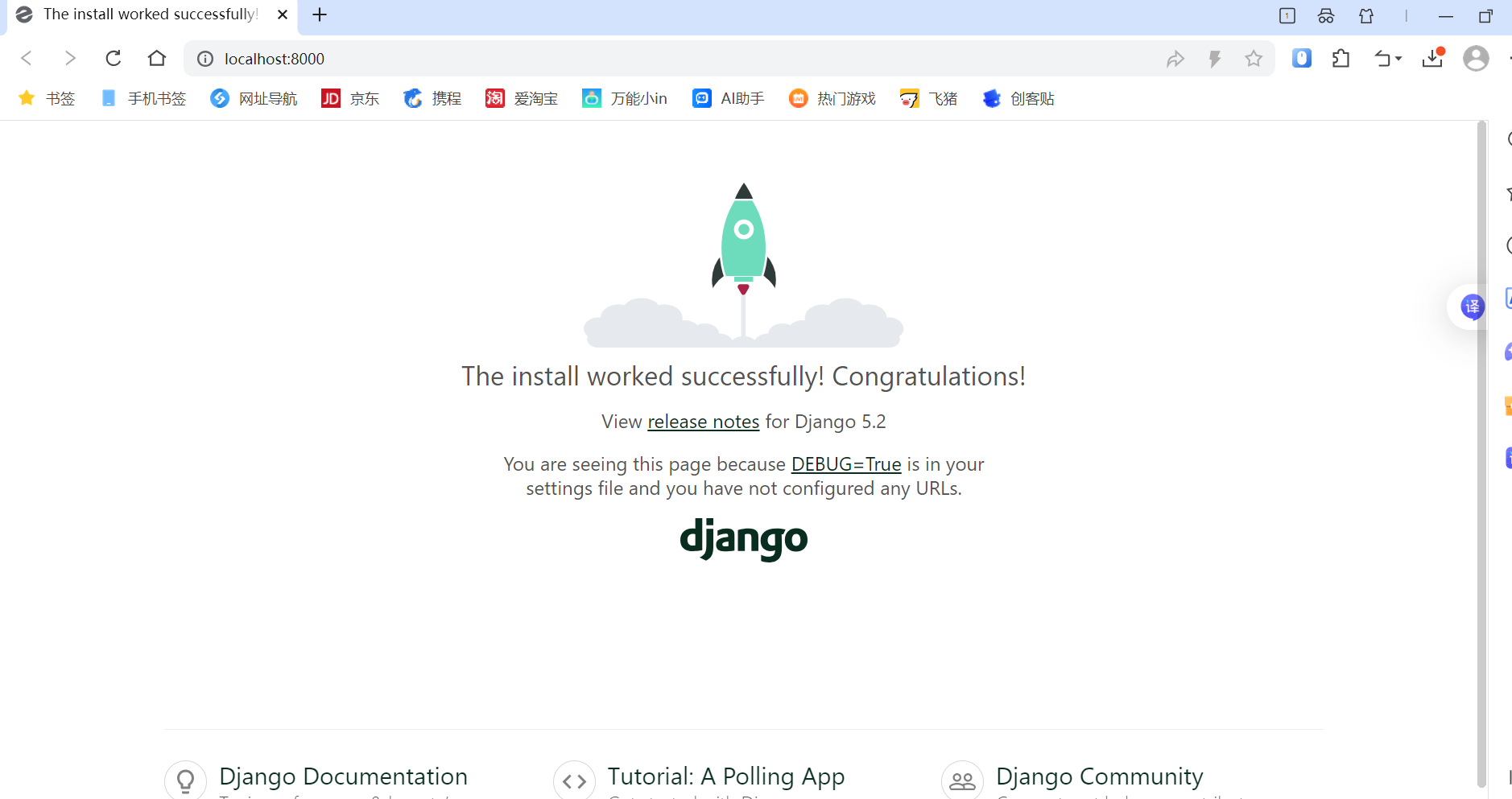
接下来我们应该就要闯创建应用了
对于大项目而言,会分成很多的模块。比如说系统管理模块、消息管理模块、定时任务模块、接口自动化测试模块、性能测试模块、功能测试模块等等
我们把一个模块做成一个应用,那么,一个项目就会包含很多应用,如果改天其他的项目需要用到其中的一个模块,那么你就把对应的应用拷贝给对方即可,
除了我们自己开发的应用之外,Django也自带了很多应用
我们在apps文件夹里面专门用来创建应用
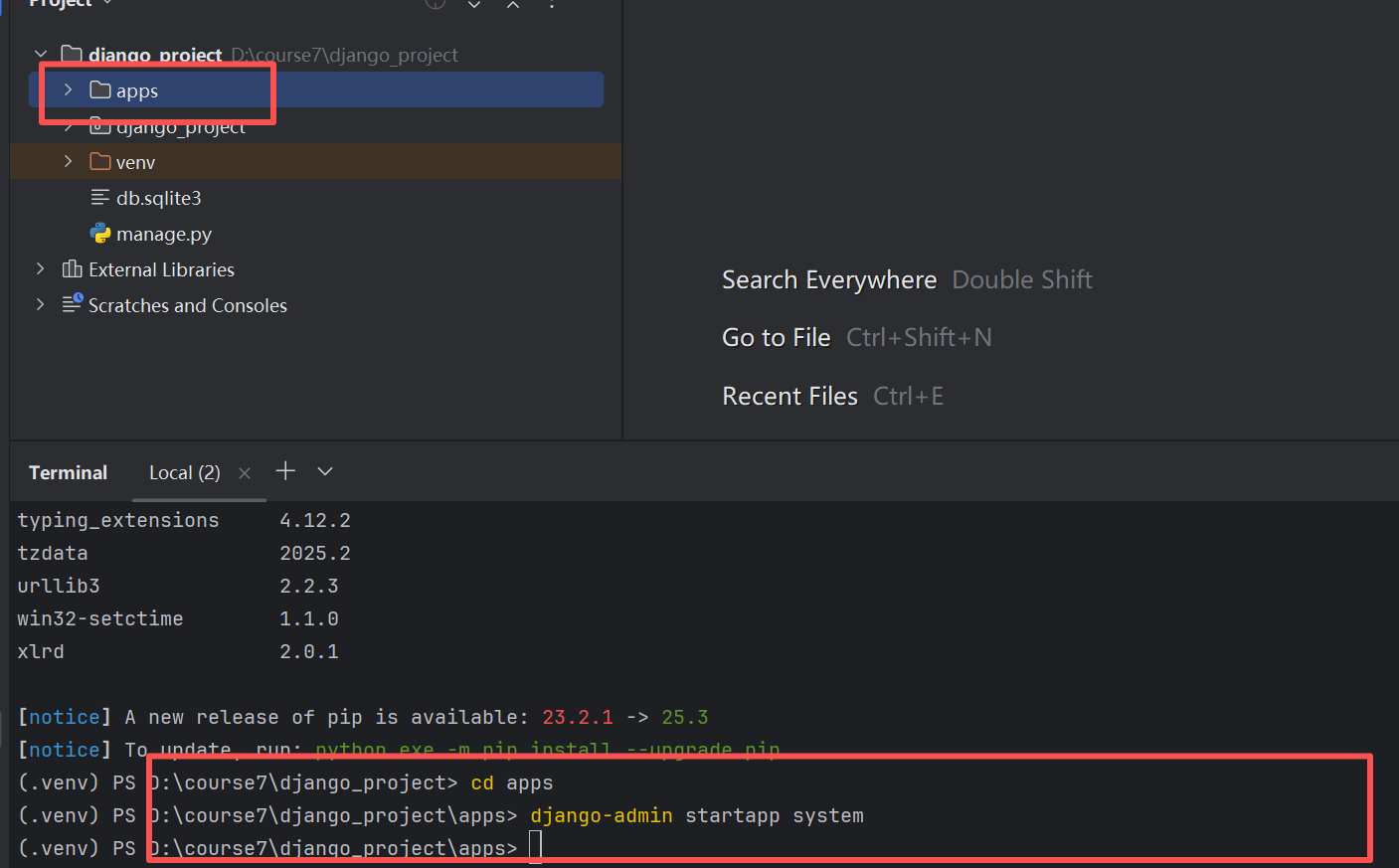

我们创建了两个应用system和api_test
接下来,我们需要
1、针对每个应用,需要修改一个文件
2、settings.py模块,需要指定应用
针对第一点,我们的每一个应用下的apps.py文件,里面的name,需要修改为apps.api_test
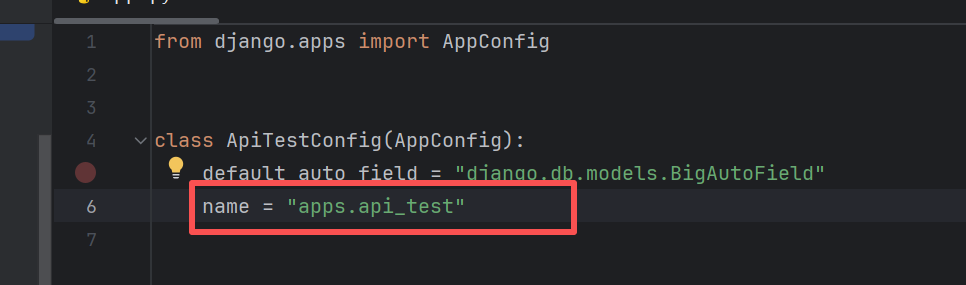
同理我们的system应用
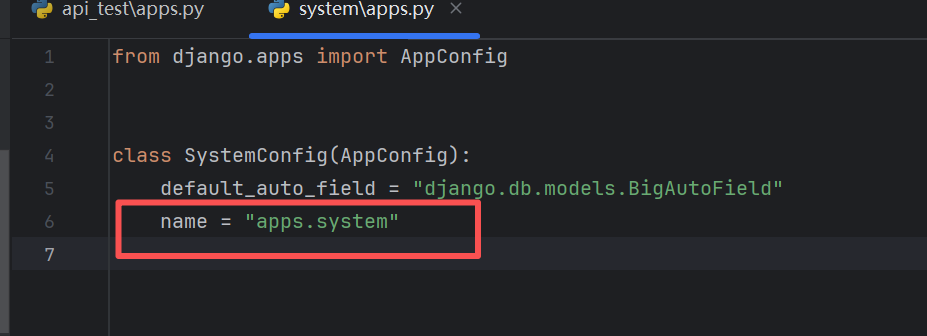
针对第二点,我们需要把我们apps放到环境变量里面
bash
# 把apps目录设置到环境变量中
sys.path.insert(0, os.path.join(BASE_DIR, 'apps'))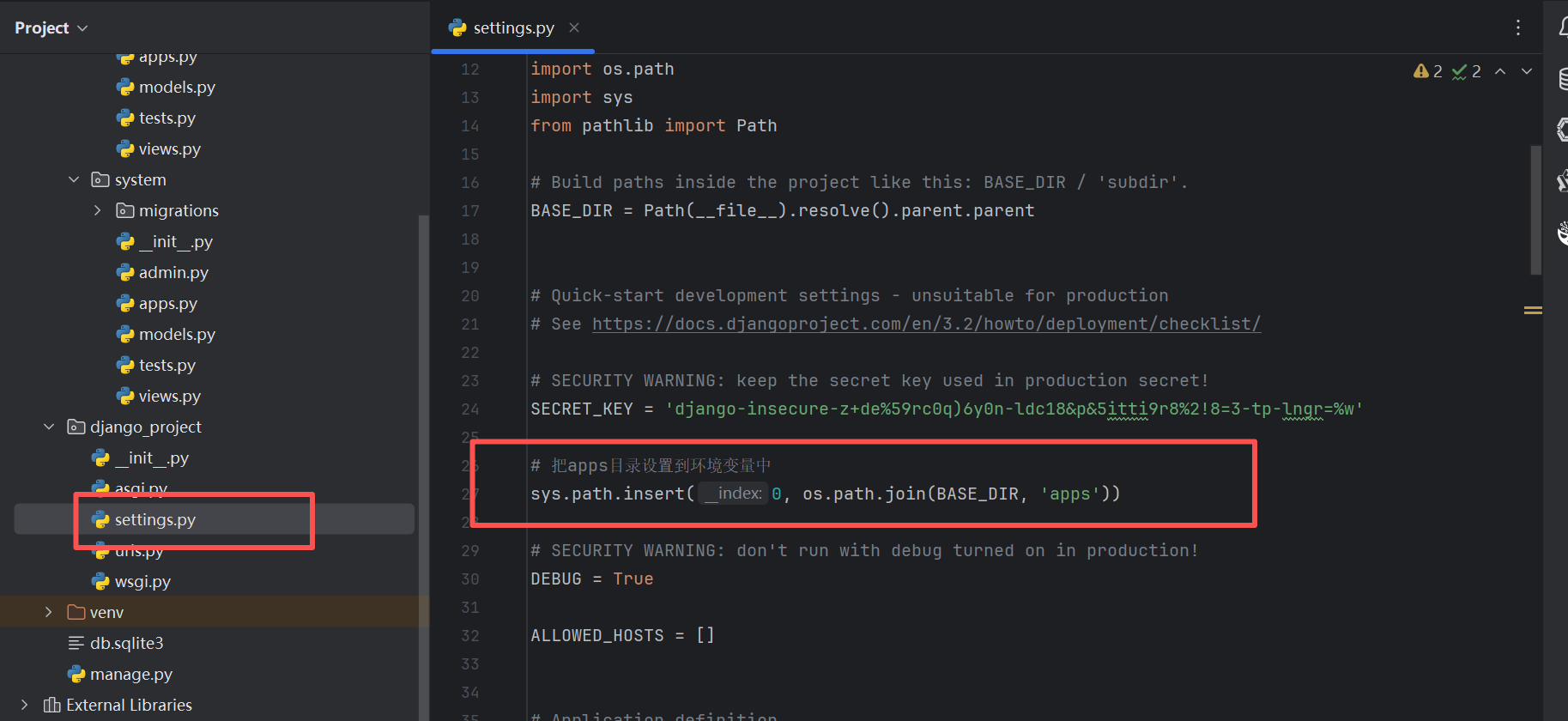
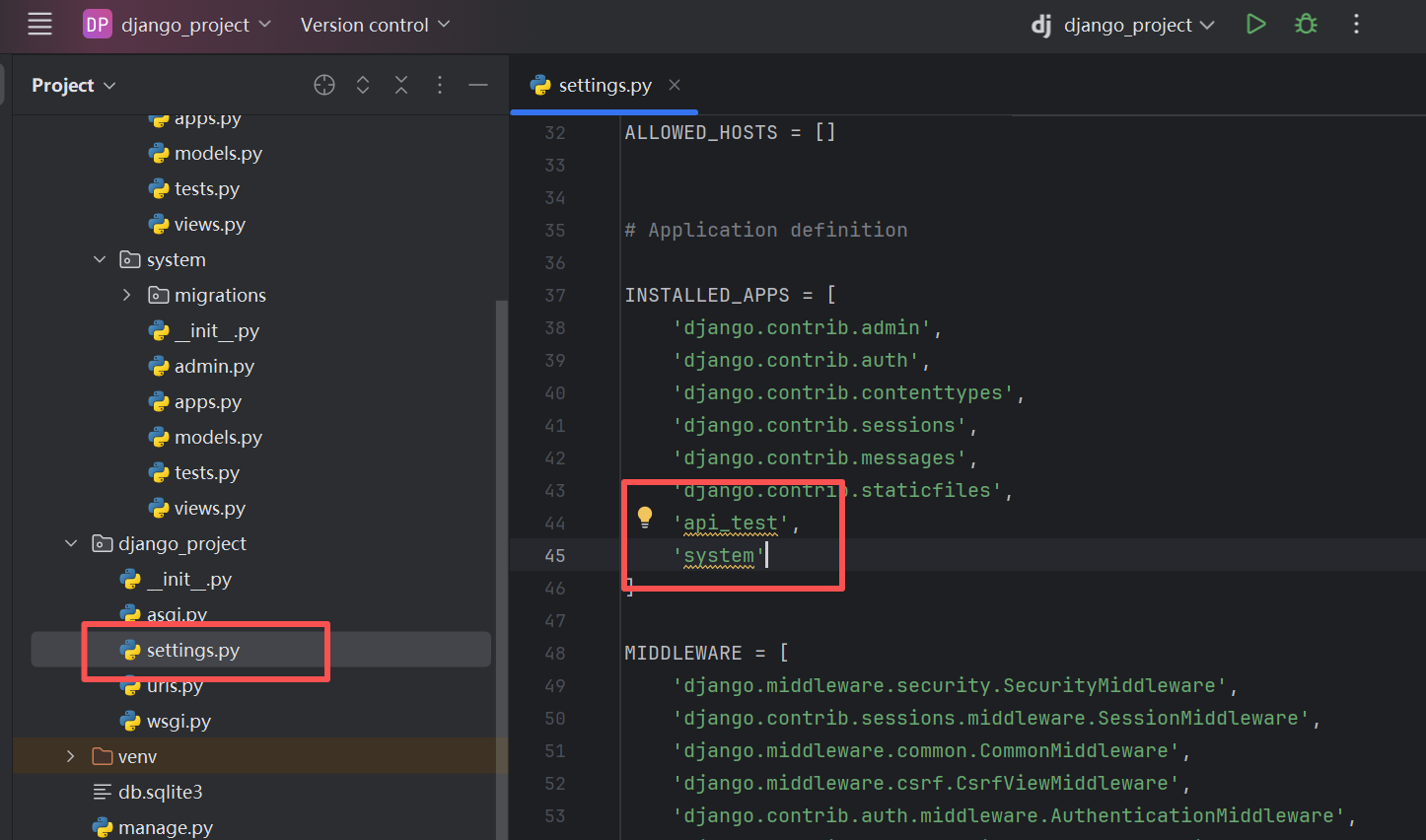
然后再添加我们的应用
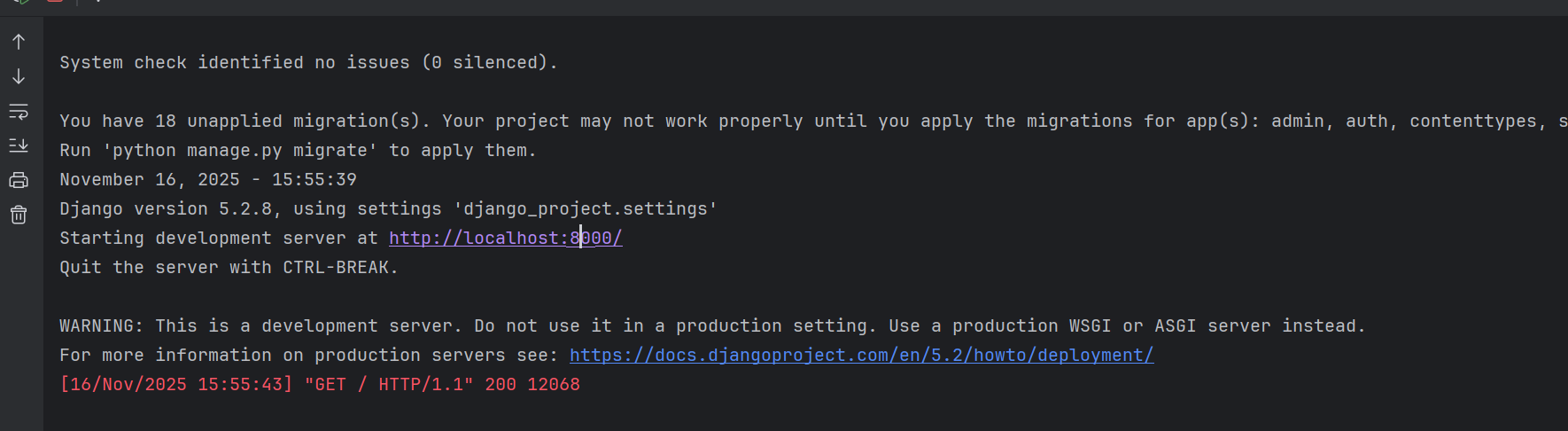
我们再次访问我们这个项目,我们发现也是可以的

数据库模型设计
在jango中,一个普通的模型对应数据库中的一个表。
我们可以定义一个模型,然后用jango命令就可以创建数据库的表,意思就是说,我们仅仅只需要定义模型即可,然后用两个命令就能够把数据库中创建表
比如说,api_test这个应用,我们就需要在models.py这个文件里面去定义我们的模型即可
不过在此之前,我们需要搞清楚几个概念
字段类型:数字类型(整型、浮点型)、布尔类型、Json类型、时间(日期-时间)
选项种类:
对于字符串,一定要有一个选项:长度
缺省值
是否为空
我们打开我们之前创建的项目
我们在models这个文件里面来创建我们的模型
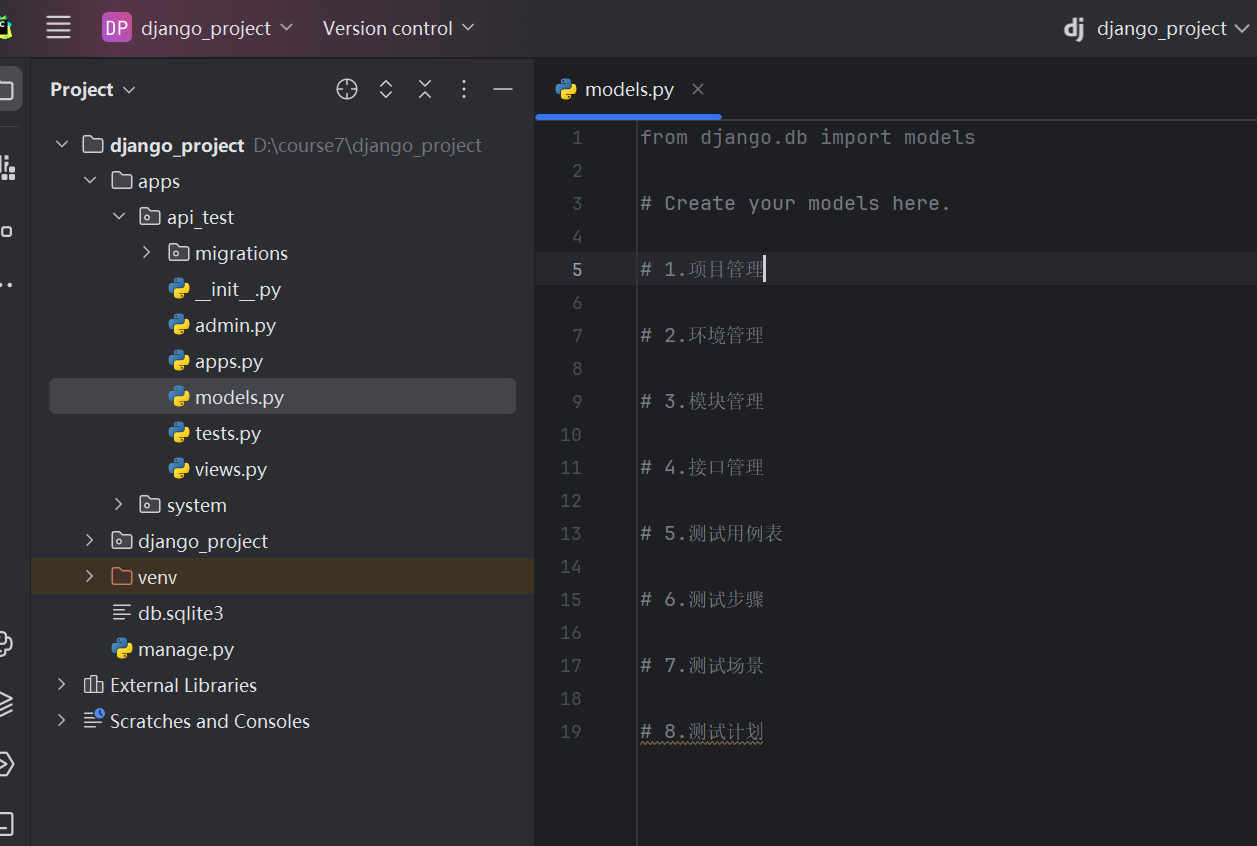
首先我们来定义我们每个模型的普通字段
以项目表为例
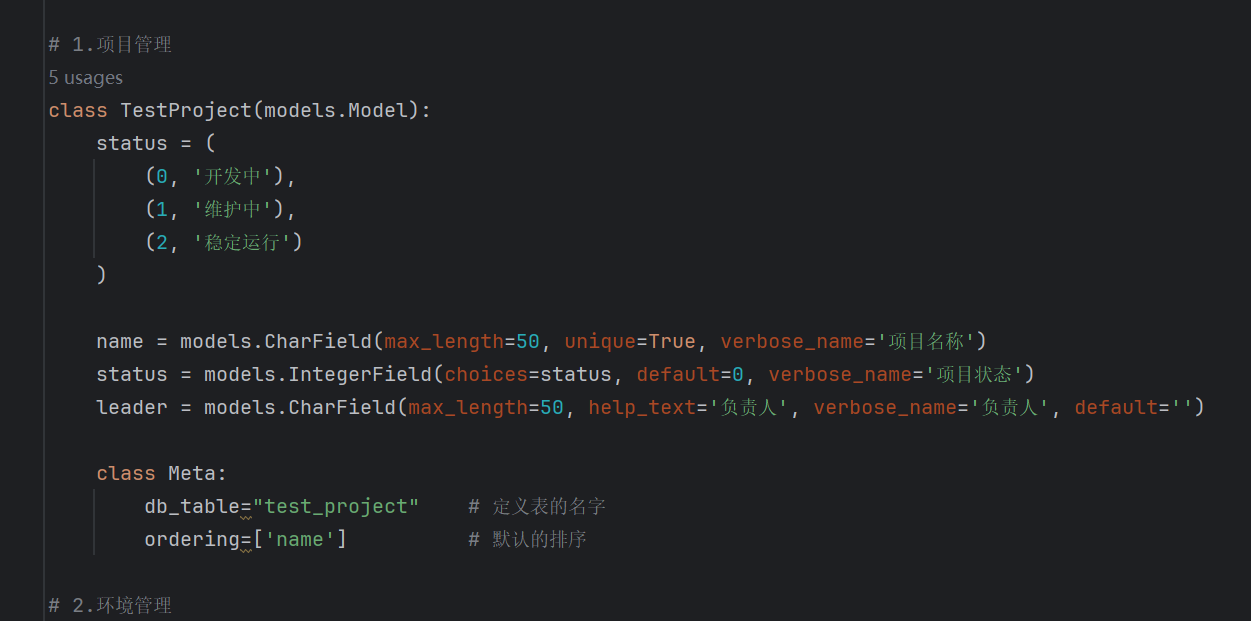
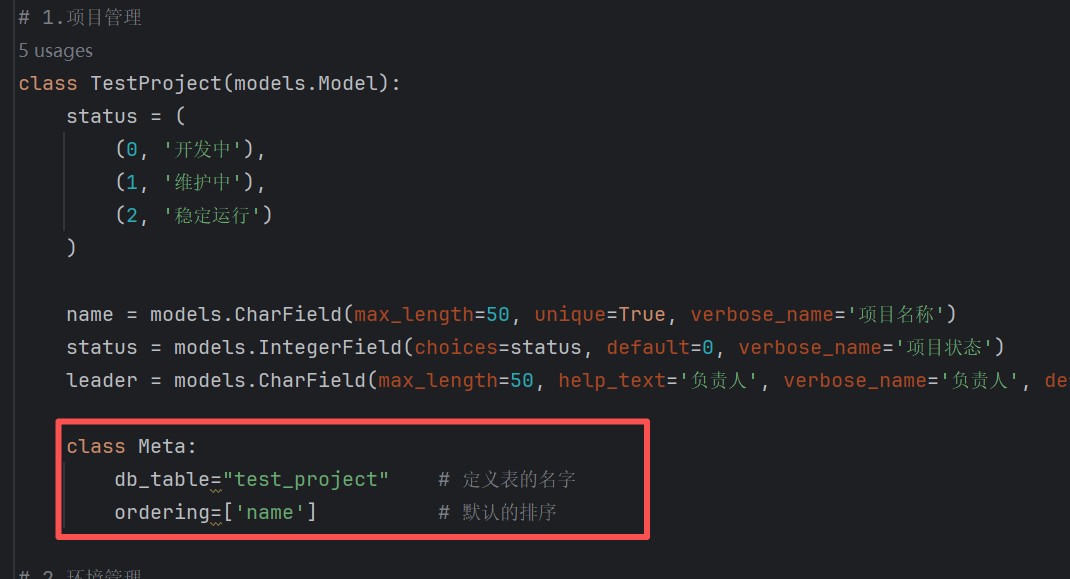
然后我们增加表的名称和排序相关的代码,在内部类中增加
最后就是我们最难的也就是关联关系
这里面
80%都是一对多的关系
10%是一对一的关系
10%是多对多的关系
如果是一对多的关系,关联字段一定要定义在多的一方
如果是一对一的关系,两边都行,一般是定义在次要的一方
以项目和环境为例,因为一个项目对应多个运行环境,所以,我们需要把关联关系定义在环境里面
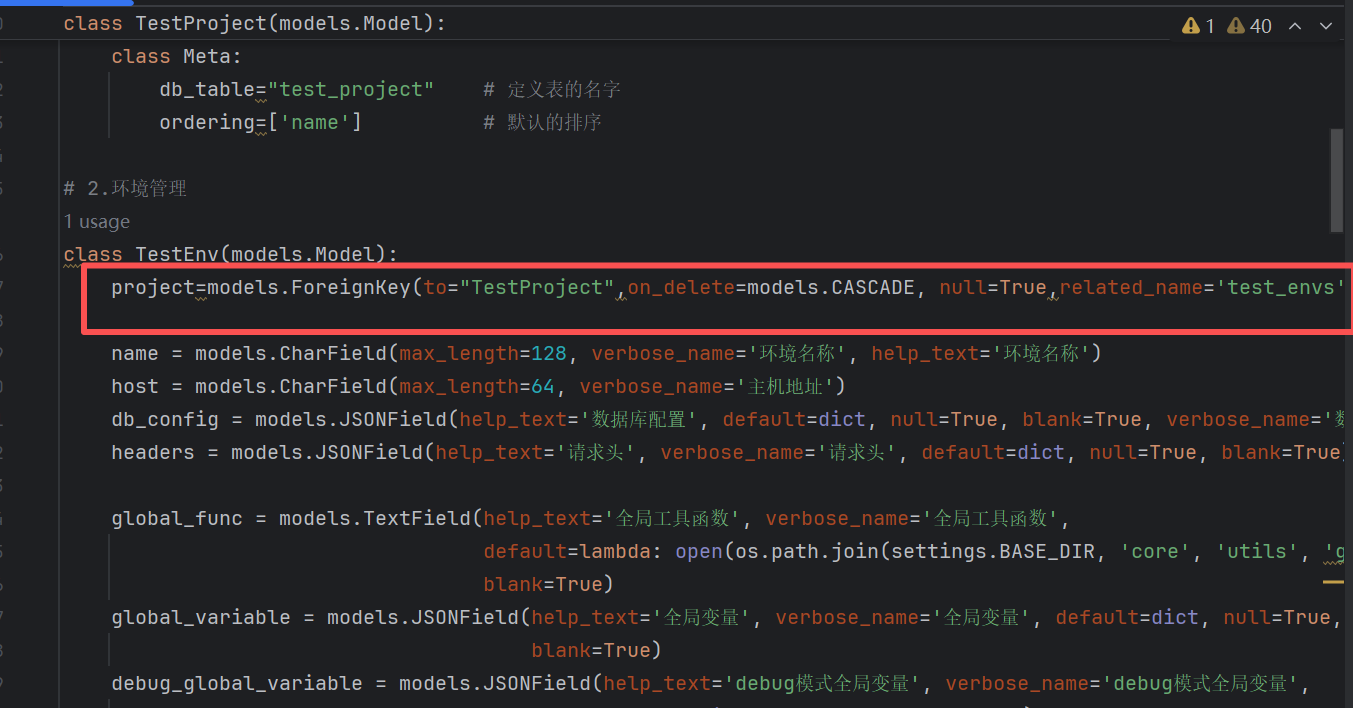
同样的道理,我们依次去处理每一个关联关系,当然,我们也可以去参照相关的模型字段去做处理
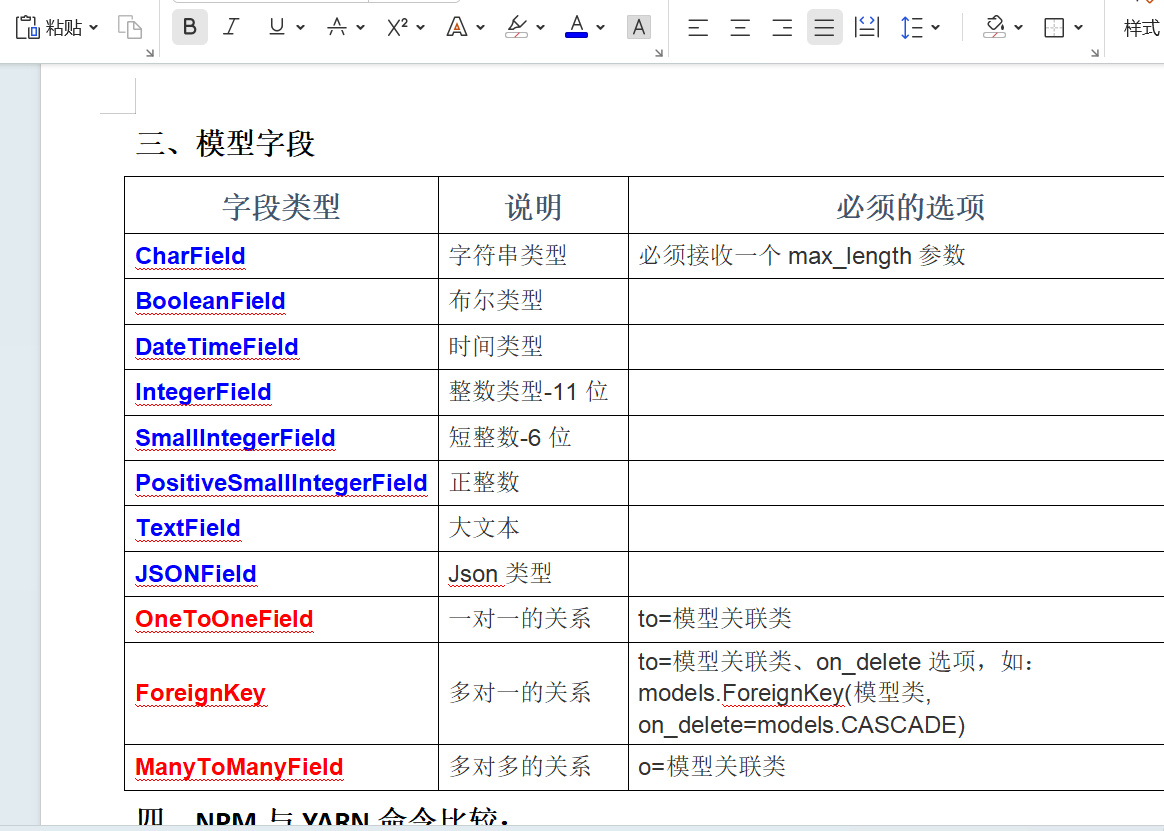
数据库设置
本地navicat链接数据库,然后去新建数据库
数据库名称我们可以使用项目名称
字符集:utf8mb4
排序规则:utf8mb4_general_ci
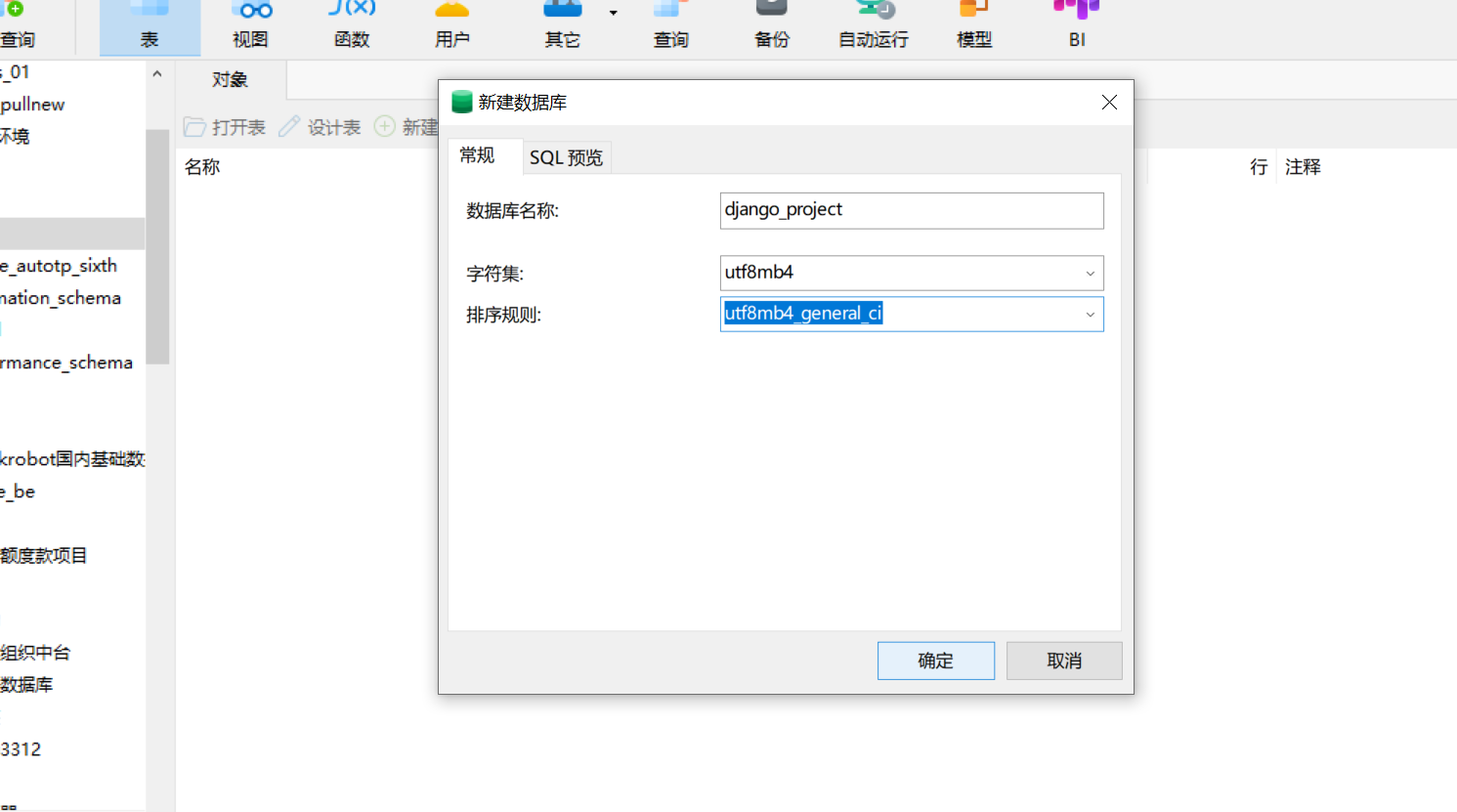
如果数据库链接有端口冲突,直接在如果服务列表中,有
Mysql 服务停止,把自动改为手动。
这个时候,我们创建的数据库中是没有任何表的
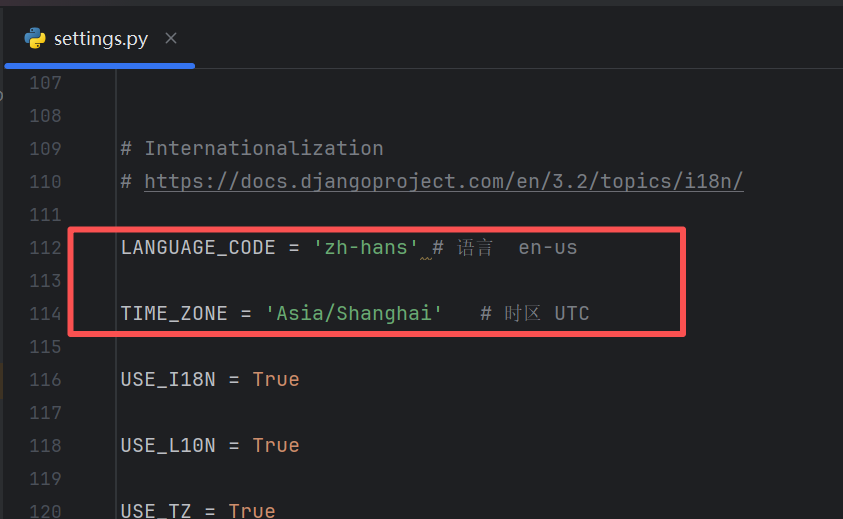
接下来我们去代码里面找到setting文件
我们修改下语言和时区
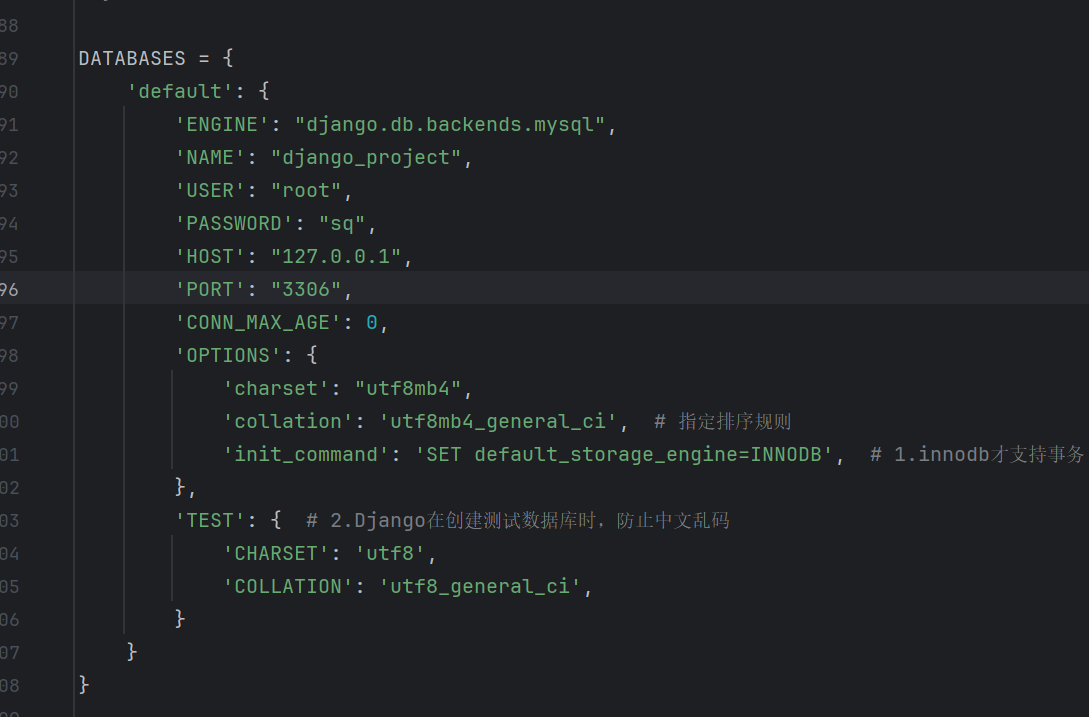
然后我们改下数据库配置
接着我们先安装mysqlclient
pip install mysqlclient
然后我们执行几个命令,去将我们之前模型的配置的数据库表同步到mysql
python manage.py makemigrations:生成数据库迁移文件
python manage.py migrate:将生成的迁移文件,落到数据库表中
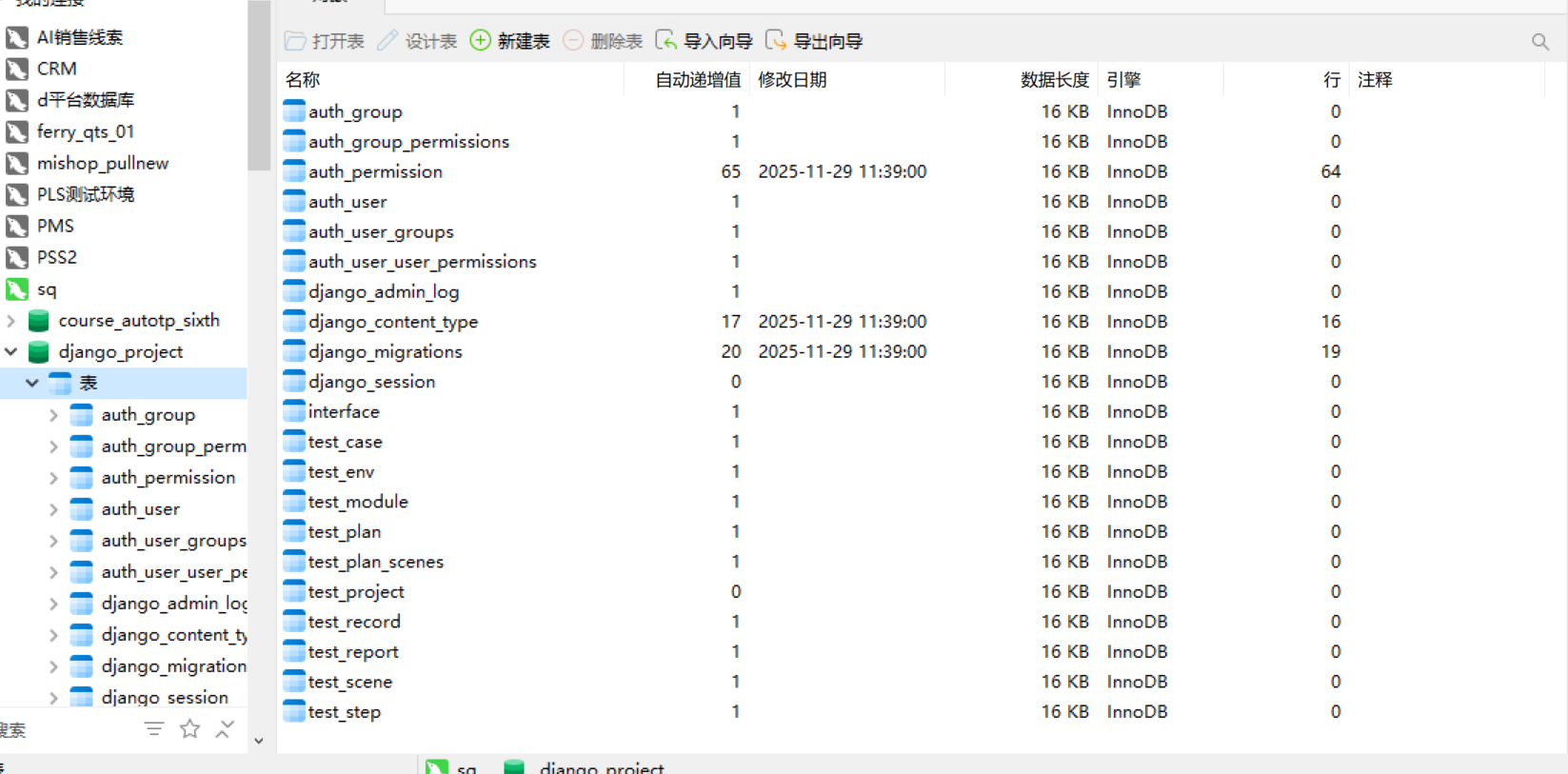
这个时候,我们再看下我们的数据库,就有表了
Django模型继承
在实际项目中,数据模型除了业务字段以外,还需要有一些通用字段,如创建时间,更新时间,创建者,更新者等,这些字段如果在每个模型都定义的话,冗余度很高,而且维护起来不方便。那么,如何解决呢?
此时,我们想到了Django的模型继承,它和Python继承工作方式几乎一样,只是被继承的类应该继承自django.db.models.Model。
Django的模型继承有三种方式:
- 抽象基类:抽象基类本身不会创建表,子类继承抽象基类的字段、Meta类等
- 多表继承:被继承的模型本身会创建表,其他没什么特别。
- 代理模型:被继承模型是一个正常模型(会创建表),子类是一个代理模型(不会创建表),只会有父类的管理器和自定义方法等
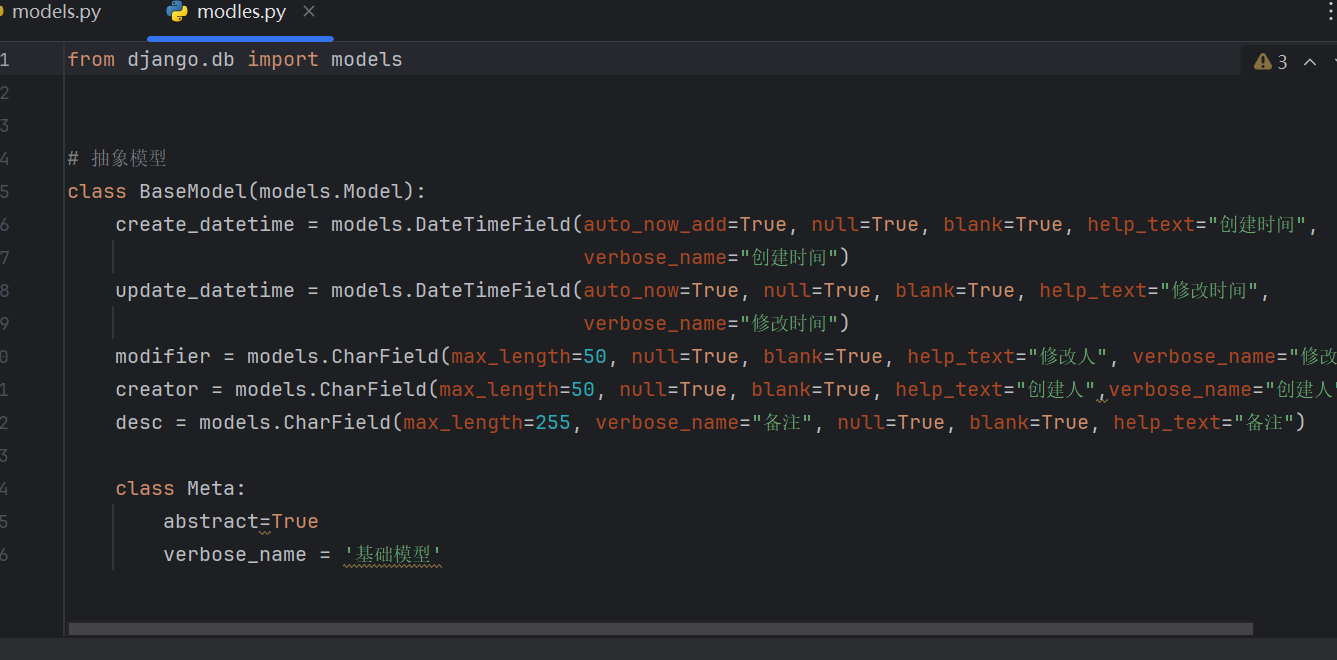
抽象基类
作用:将子表中通用的字段聚合在一起,并将这些字段统一定义在抽象基类中,避免于重复定义这些字段
定义:通过在模型的 Meta 中定义属性abstract=True来实现
特点:该抽象基类模型本身不会创建表。当子类继承基类时,它的字段、Meta类、方法等会自动添加至子类
配置如下代码:
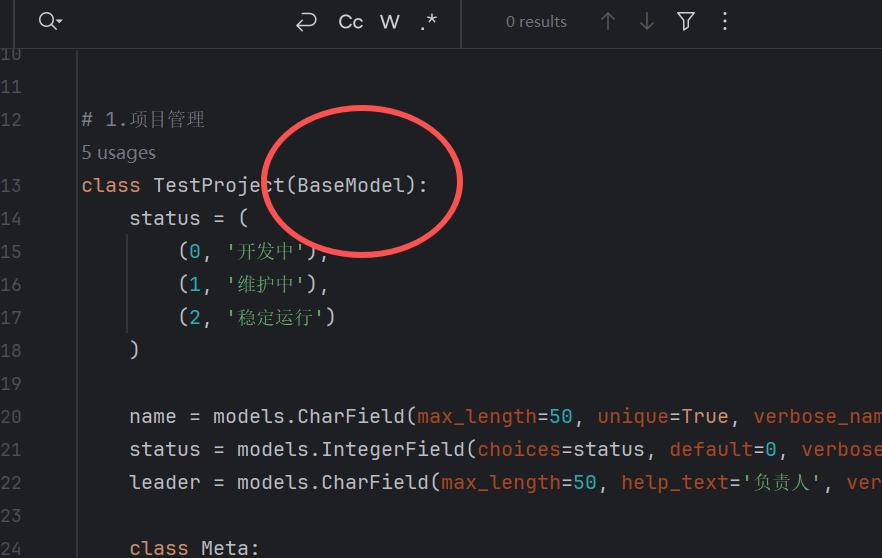
然后让我们的每个模型去继承这个类
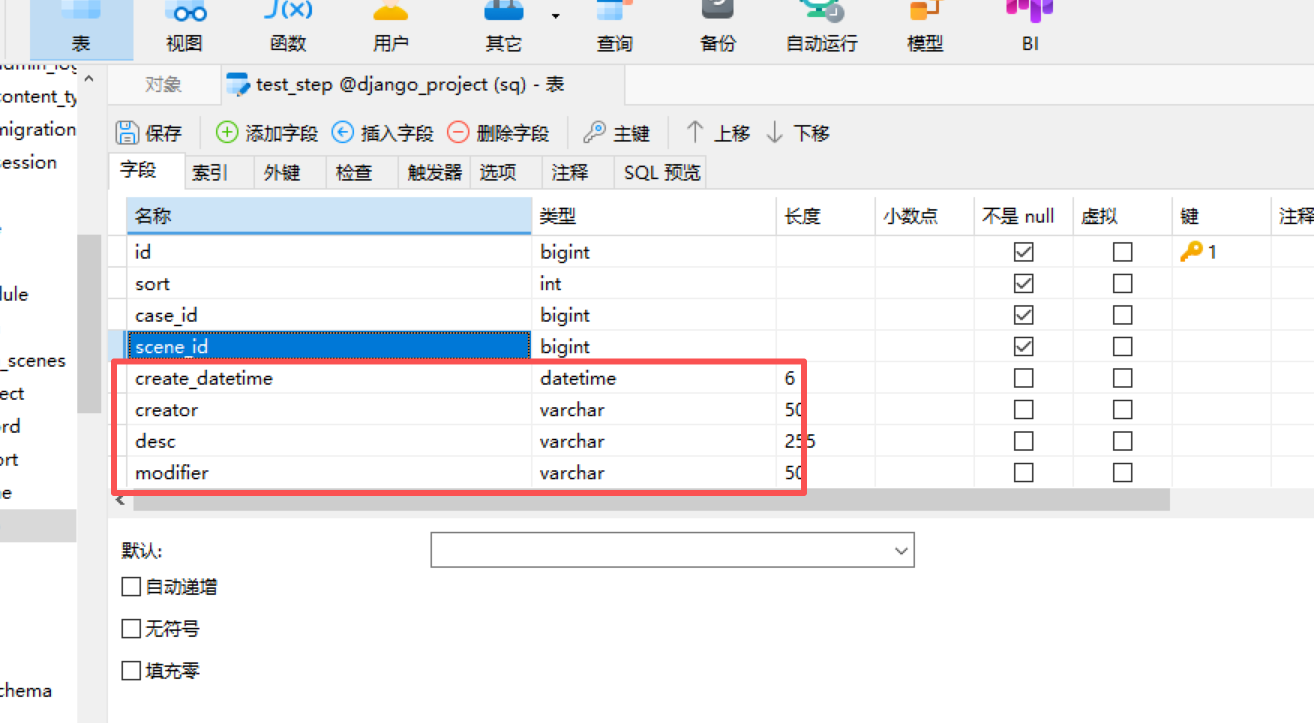
然后再去重新运行我们上面的命令
我们可以看到,我们表里面多了我们的新字段
其他表同理
DRF
Django Rest Framework(以下简称DRF或REST框架)是一个开源的Django扩展,提供了便捷的REST API开发框架,拥有以下特性:
- 直观的API web界面
- 多种身份认证和权限认证方式的支持
- 内置了OAuth1和OAuth2的支持
- 内置了限流系统
- 根据Django ORM或者其它库自动序列化和反序列化
- 丰富的定制层级:函数视图、类视图、视图集合等方式自动生成 API,满足各种需要
- 可扩展性,插件丰富广泛使用,文档丰富
安装:
pip install djangorestframework

配置:
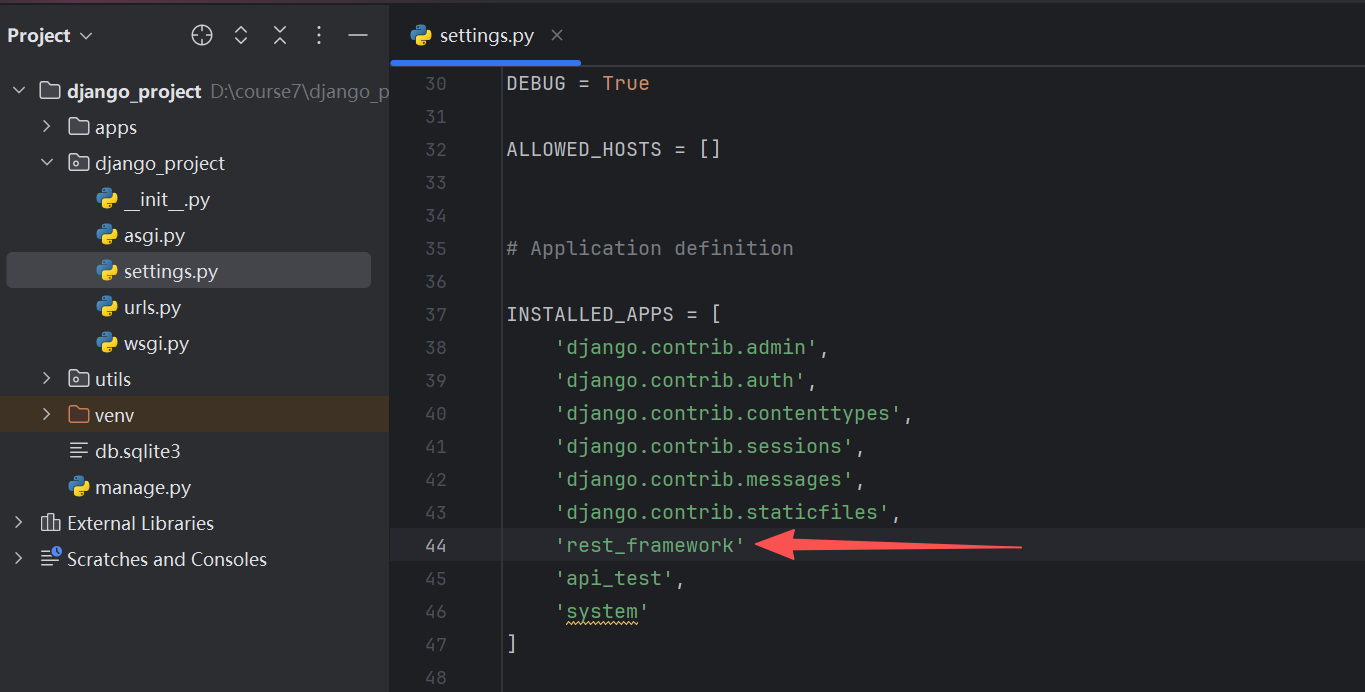
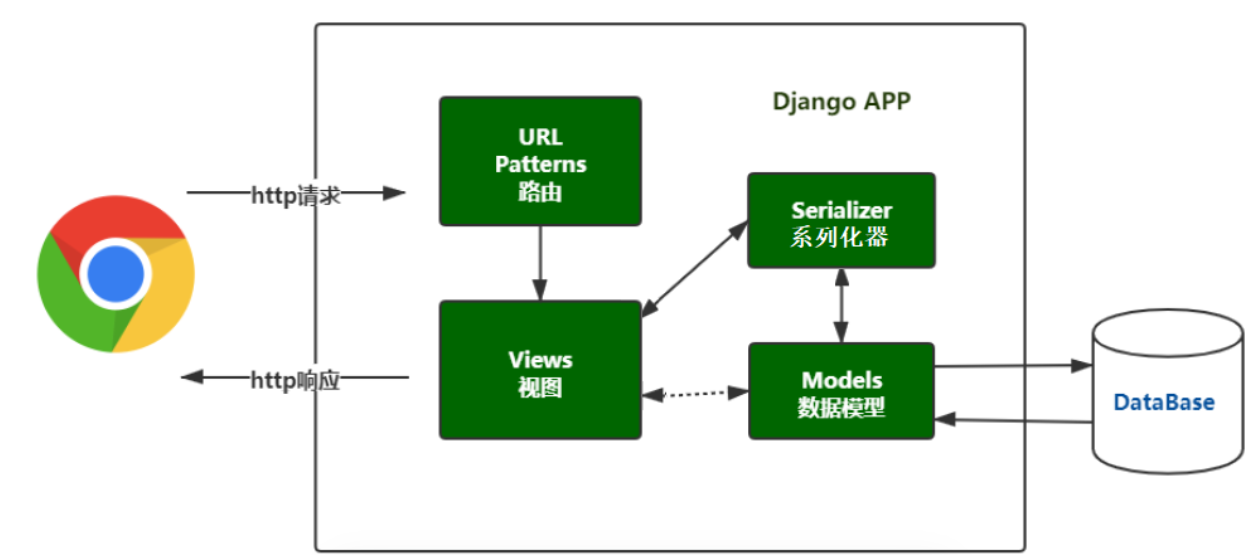
相比于原生django开发的web应用,多了一层序列化器(Serializer),类似于Django表单(Form),序列化器和表单都是基于Field进行字段验证的,而Field都来自于rest_framework.fields模块,相当于把Django的封装了一层
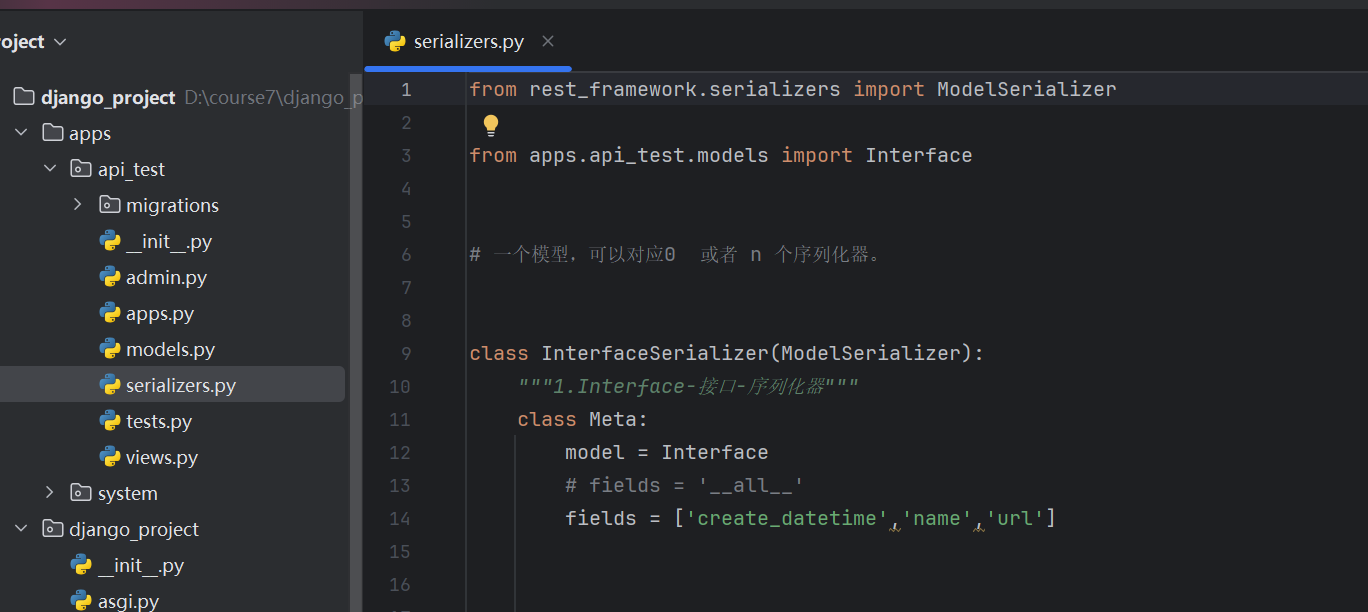
编写序列化器
一个模型,可以对应0 或者 n 个序列化器。
序列化(Serializer)是DRF的核心概念,提供了数据的验证和渲染功能,
其工作方式类似于Django Form。
它的作用是实现序列化和反序列化。
序列化:将一个数据结构类型(模型类对象)转换为其他格式(字典、列表、JSON、XML),我们把这个过程叫序列化
反序列化:将其他格式(字典、列表、JSON、XML等)转换为模型类对象,我们把这个过程称之为反序列化
也可以这样理解:
数据从数据库到网页页面,需要经过序列化处理
数据从网页页面到数据库,需要经过反序列化处理
和models、views模块类似,序列化通常定义在应用程序下,单独的serializer.py模块中
编写视图集
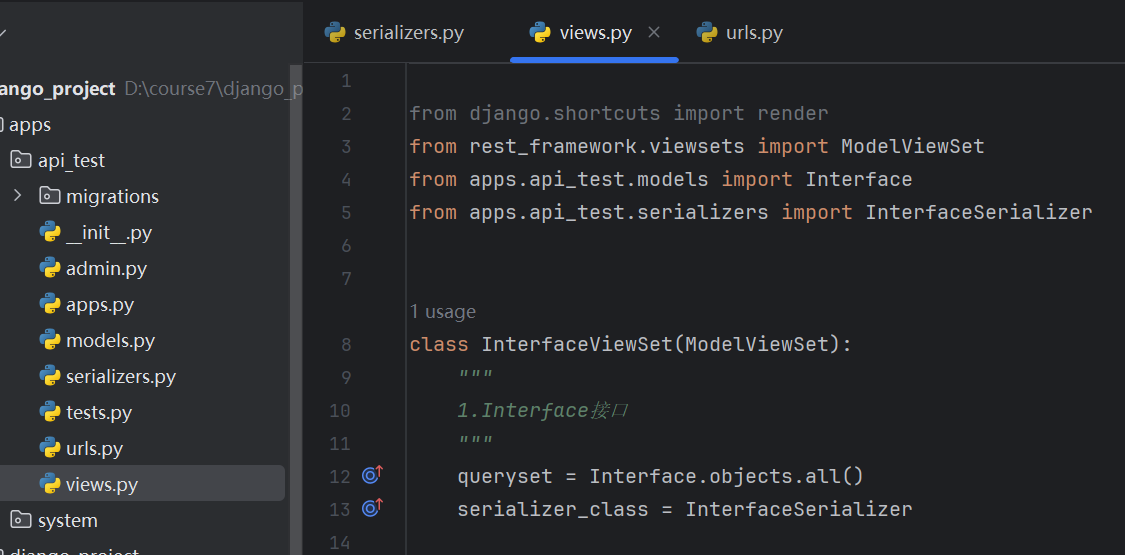
编写路由
二级路由。在apps/api_test/下创建urls.py模块,内容如下:
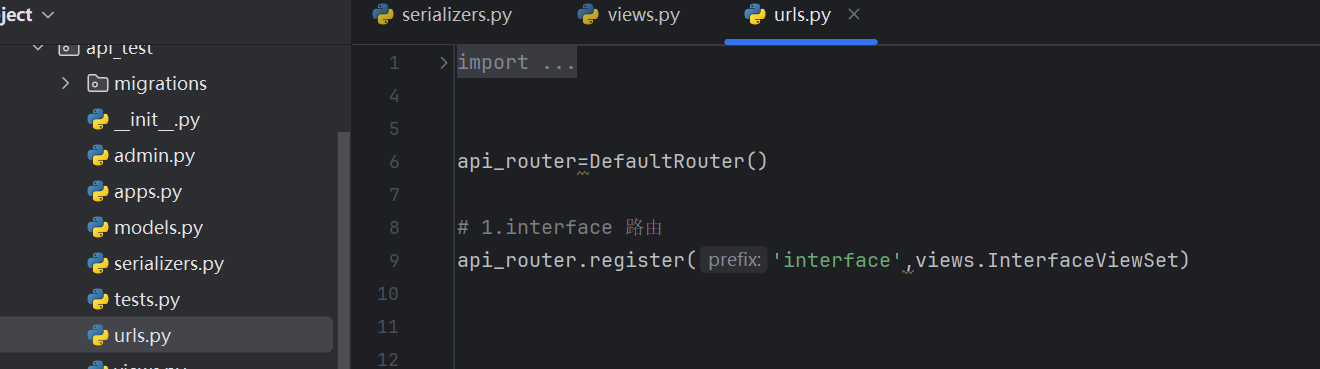
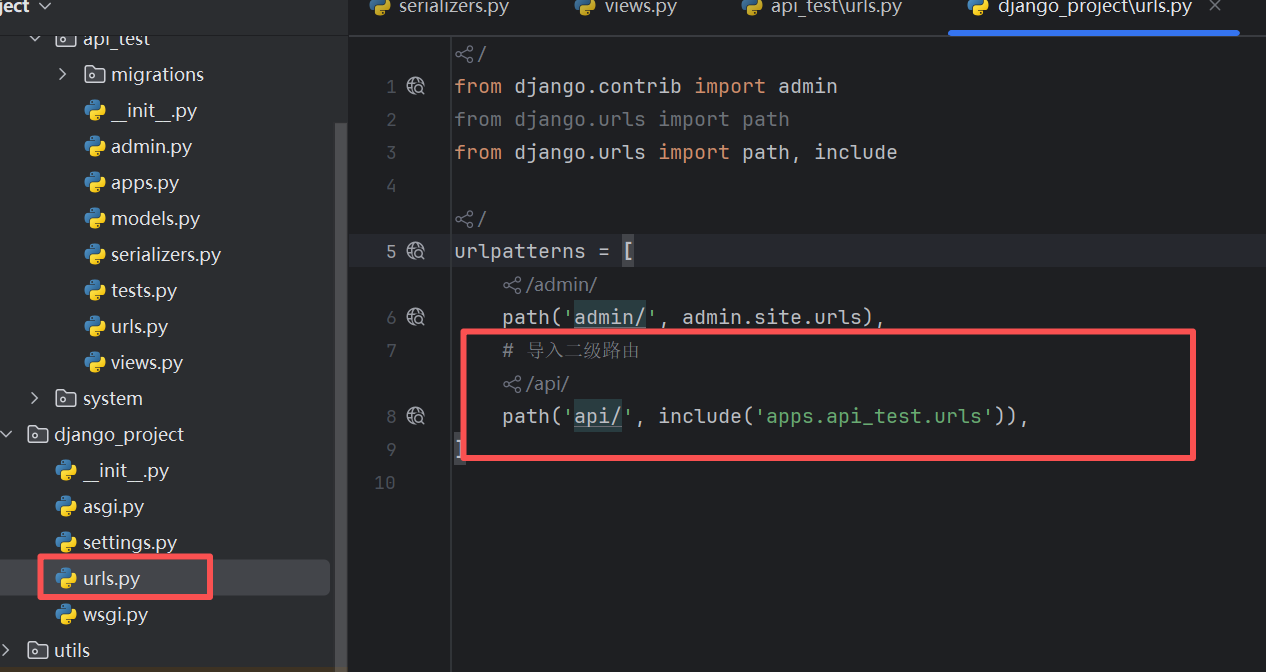
然后我们在总路由里面添加我们的二级路由
然后我们启动这个项目
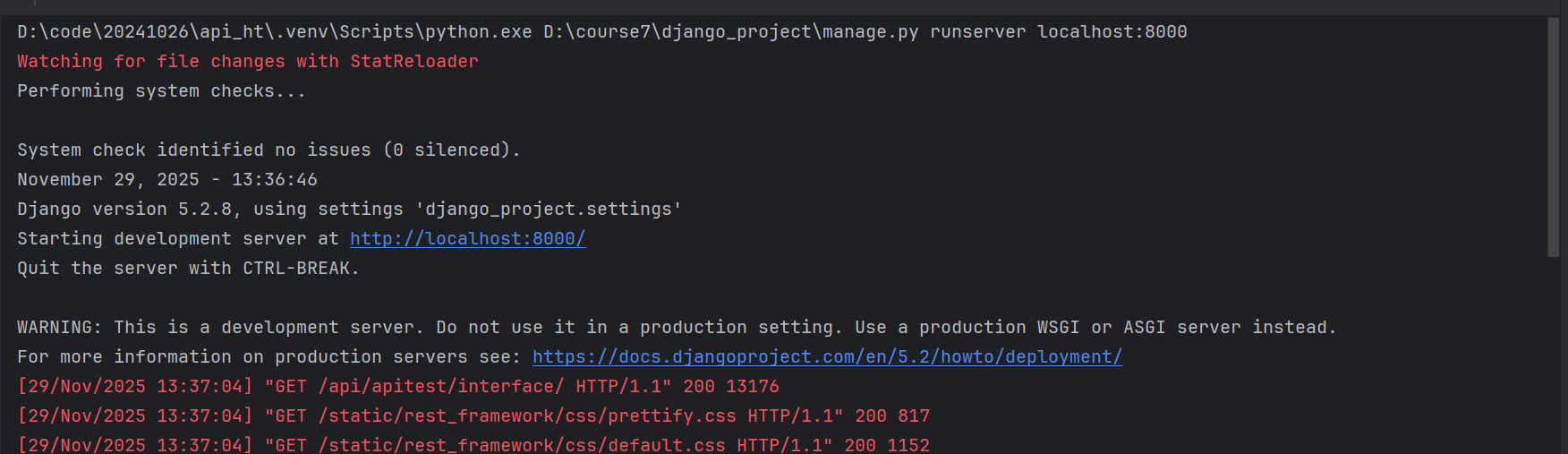
启动成功了
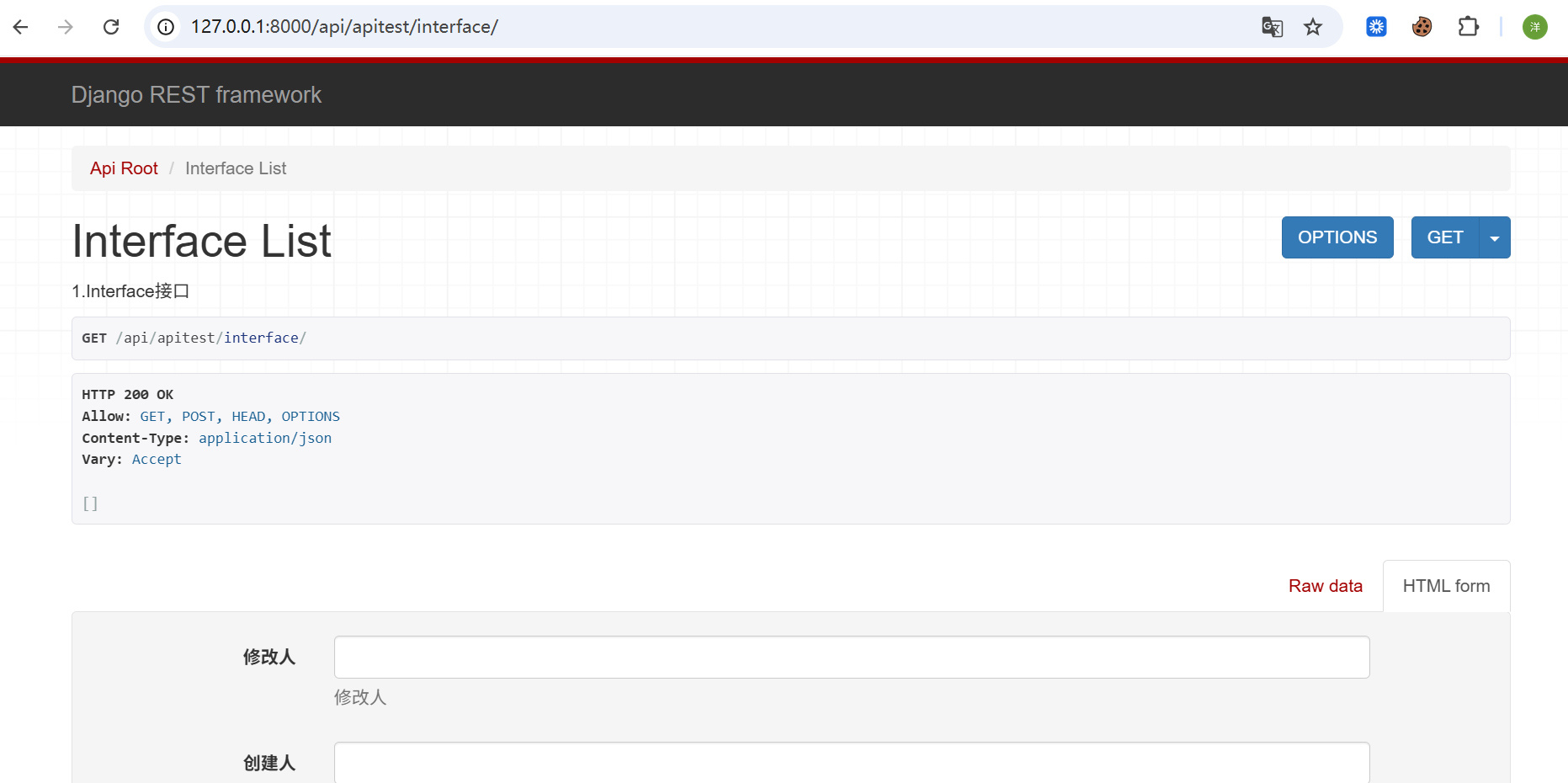
我们可以增加几条数据
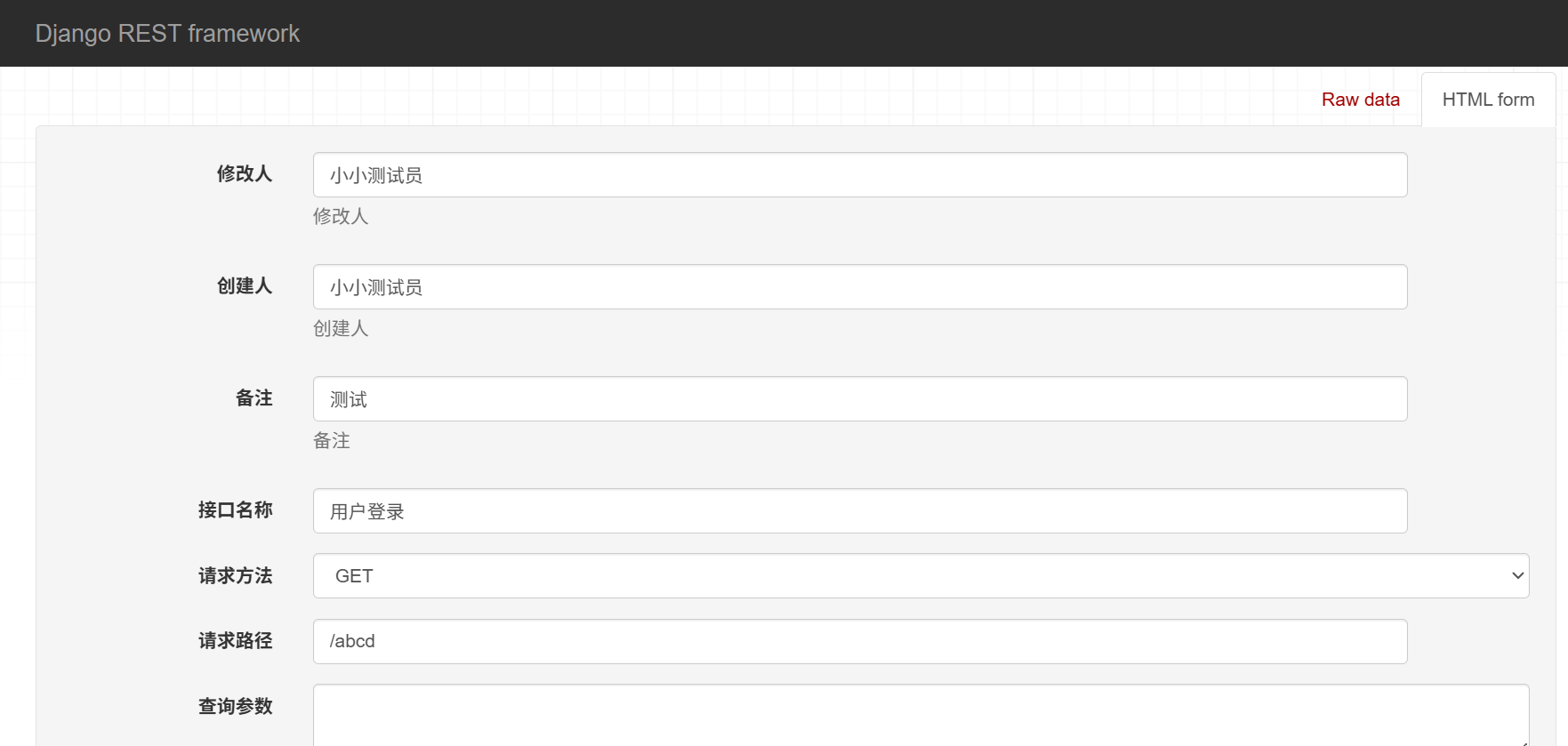
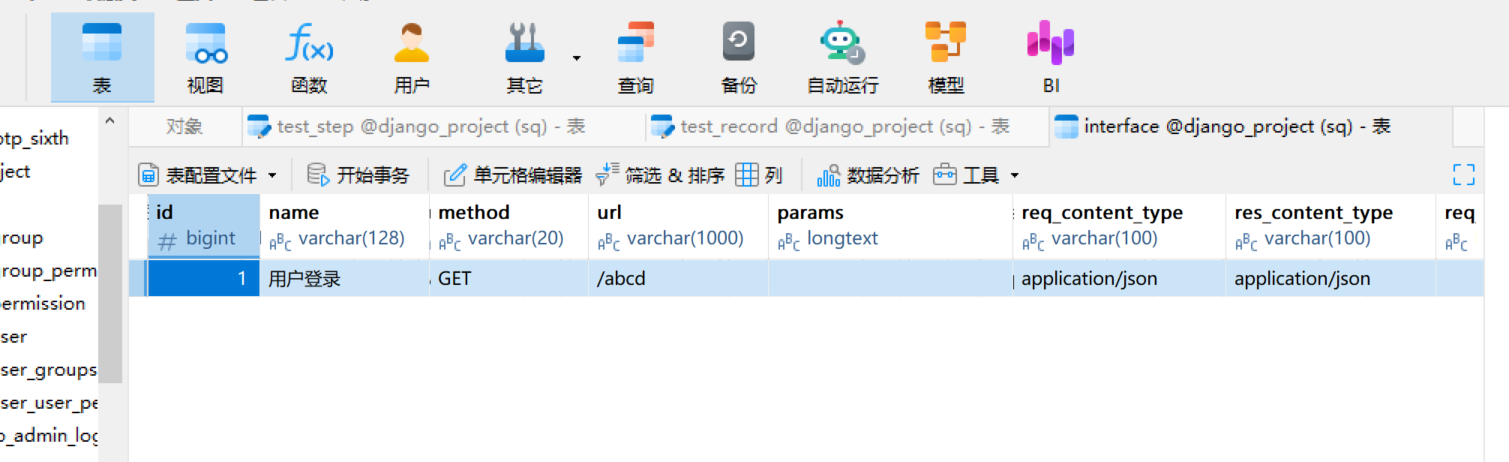
可以看到 数据库增加成功了
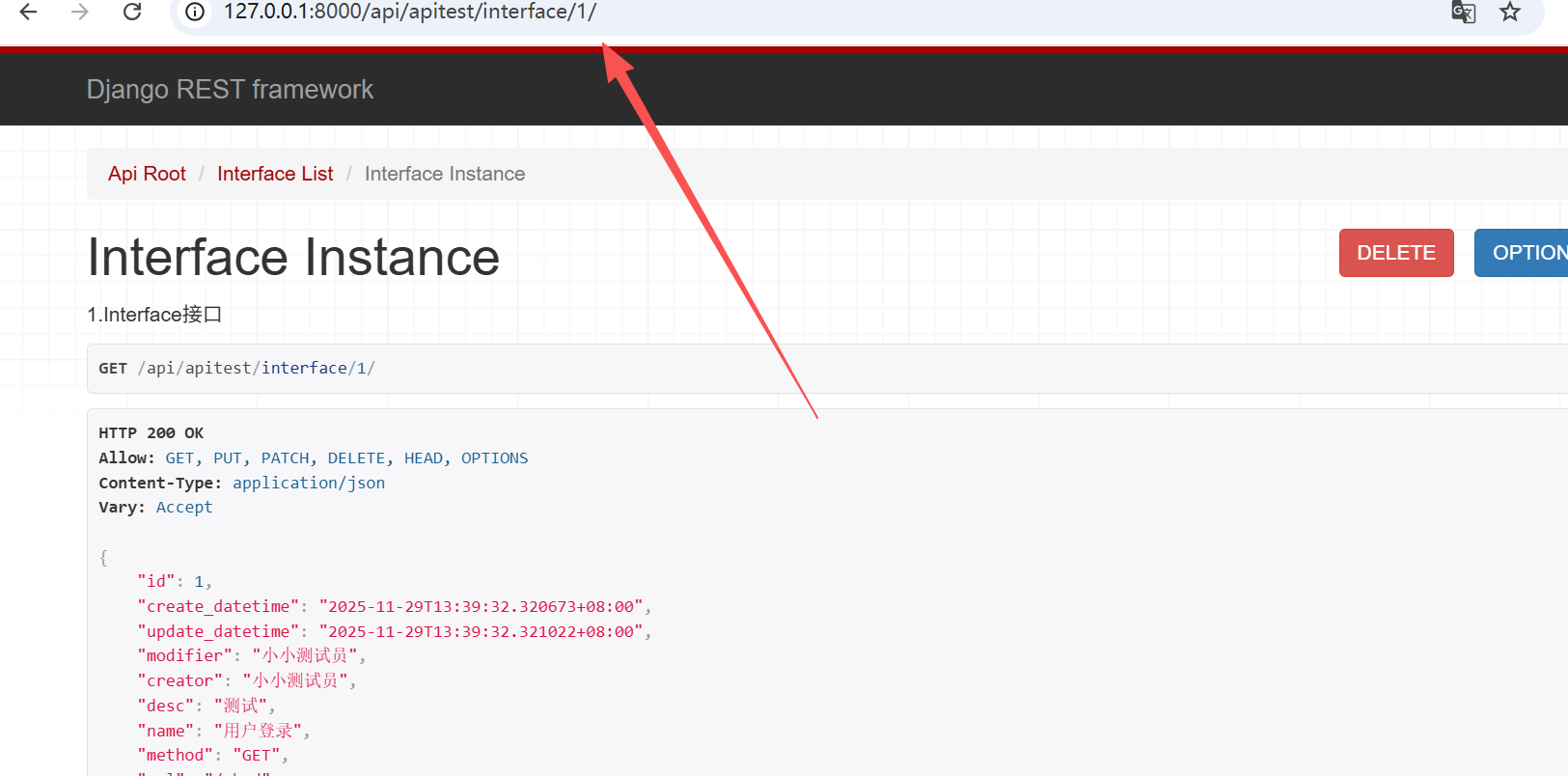
然后我们也可以查询数据
序列化器
接下来 我们专门来聊下序列化器,在序列化器文件中,我们创建了很多序列化器的类,来满足我们的业务需求
那么,我们以项目管理序列化器为例,进行简述
我们在pycharm,终端中,运行 python manage.py shell命令,进行入到shell运行环境

我们导入我们的序列化器以及项目
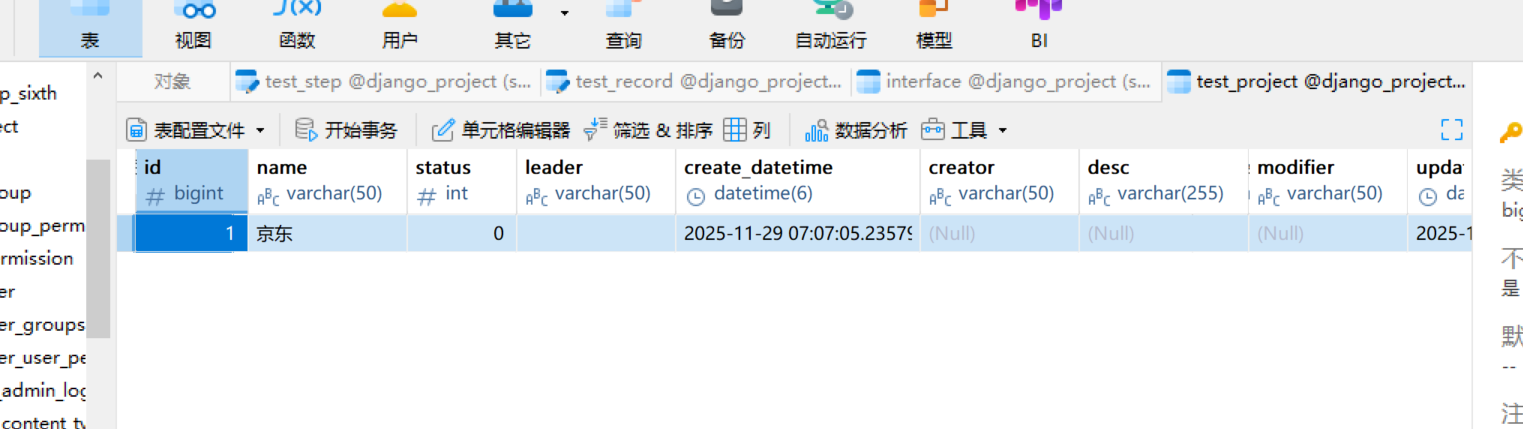
当然我们也可以插入一条数据

我们可以看下我们表里面插入了一条数据
我们再实例化一个序列化器

然后我们将其打印出来
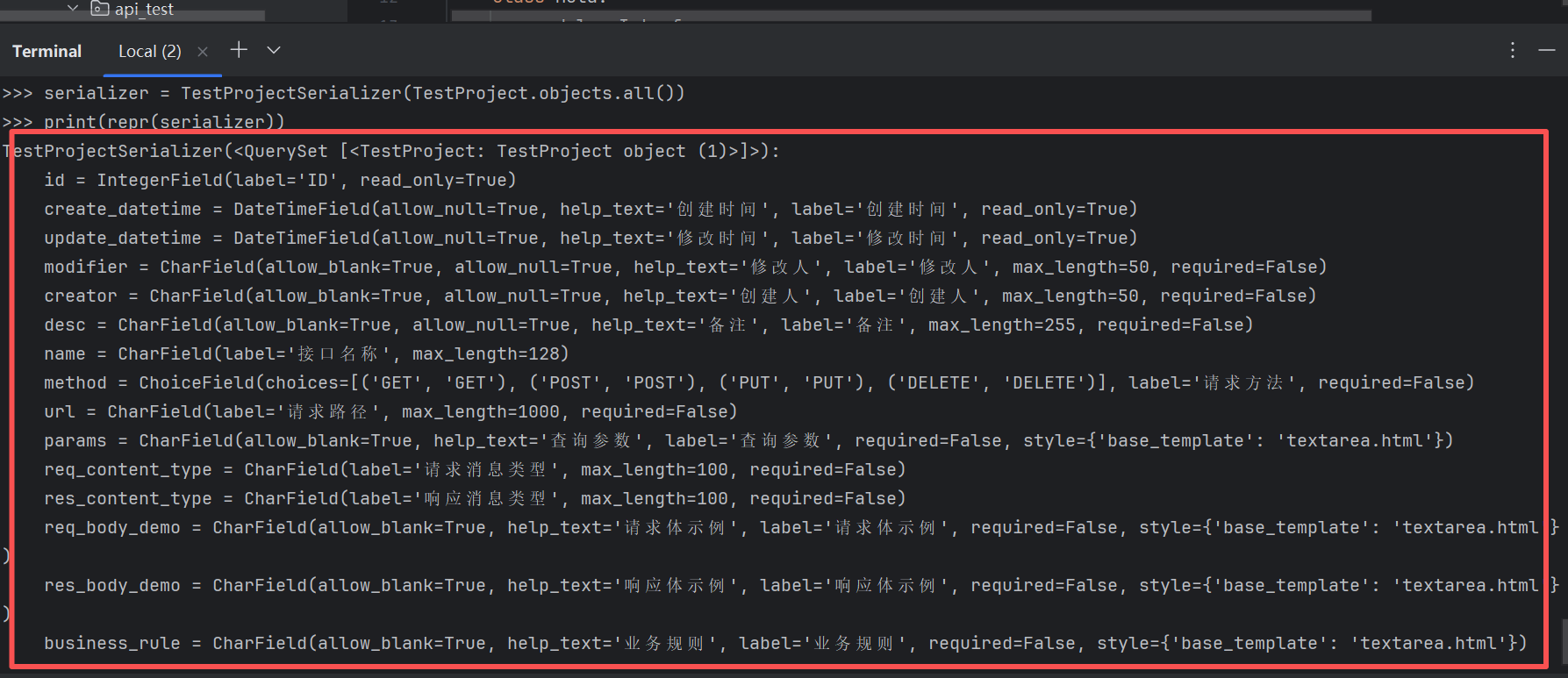
我们看到这些字段都有的,这也就是该序列化器的结构
如果模型中有null=True字段,序列化器中被添加了required=False属性(非必填)如果模型中有default字段,序列化器中被添加了required=False属性(非必填)
模型中的ID字段,序列化器中被添加了read_only(只读)属性其实,ModelSerializer类主要做了以下两件事:根据模型自动生成序列化器的字段,并设置了一些选项; 默认简单实现的create()和update()方法
这些字段全部返回的原因是因为我们在这里配置了all
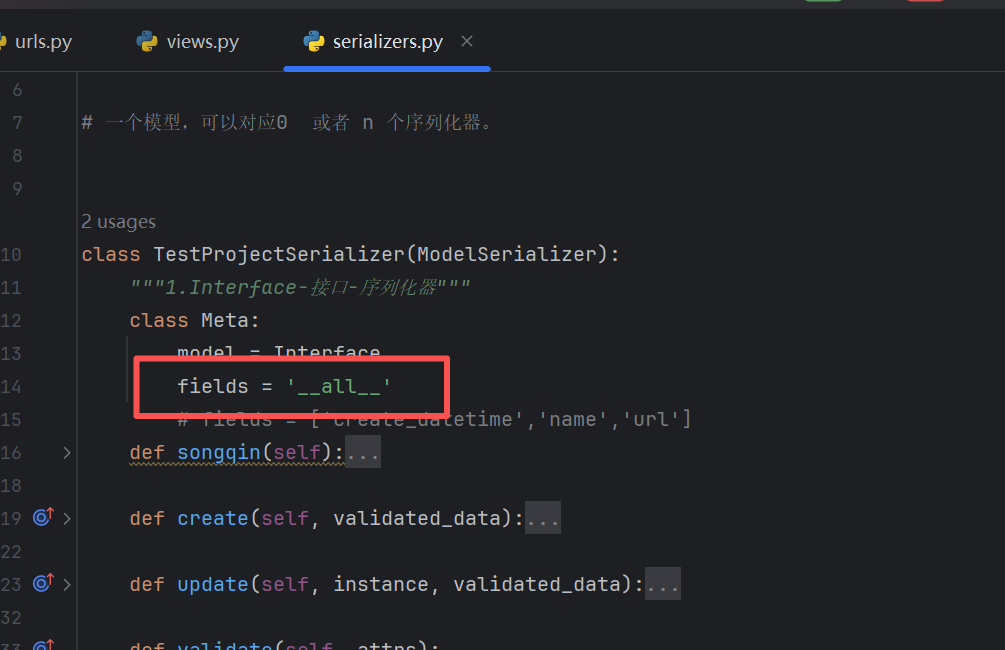
当然,我们也可以针对指定字段进行返回,这里就不过多赘述了
另外,我们在开发我们的Web API的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如JSON之类的表示形式的方式
我们在这个类里面进行重写几个方法
我们重新定义create()、update()和validate()方法
serializer.save()是将数据保存到数据库的方法,它会自动判断当前是新增数据还是修改数据,当为新增时,必须重写父类的create()方法;当为修改时,也必须重写父类的和update()方法。如果进行新增或者修改前,需要对参数进行额外的校验,则需要重写validate()方法
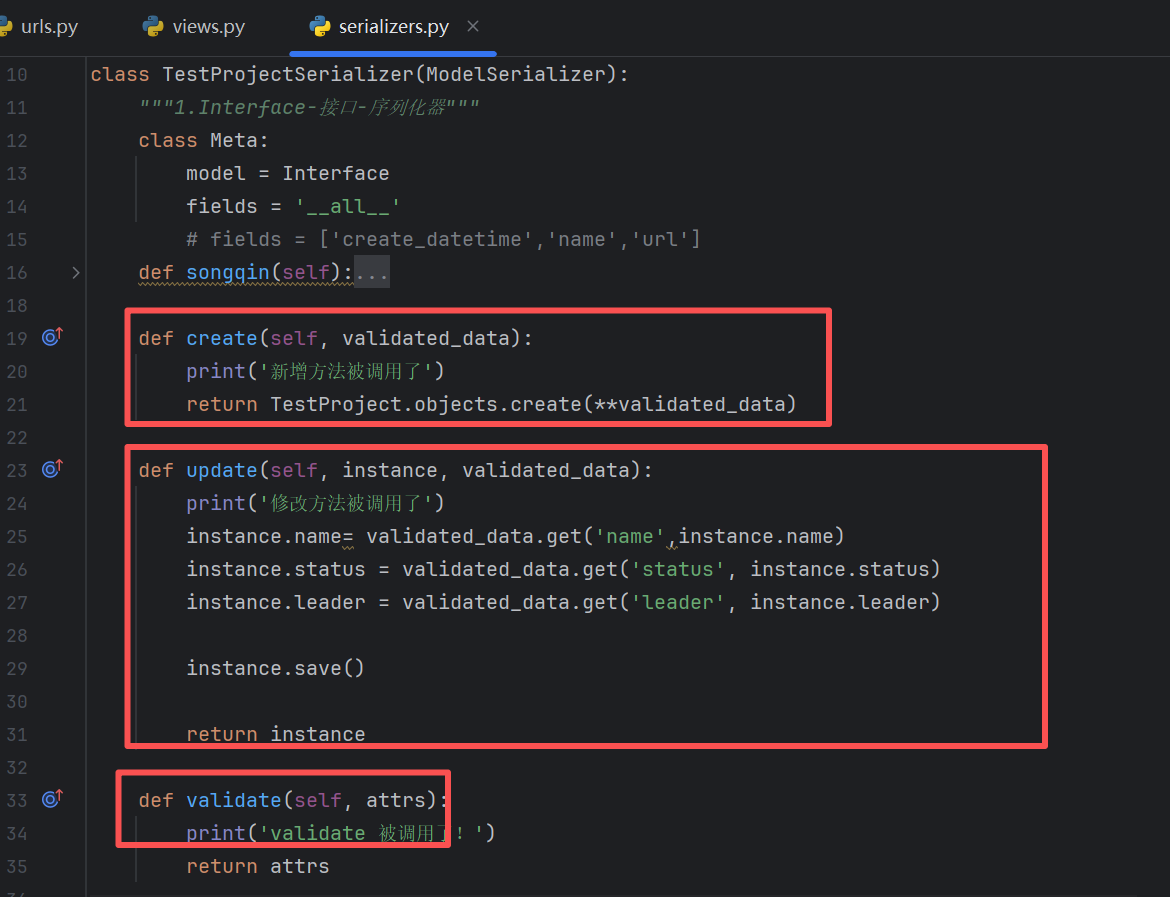
这里要注意的是:
create()方法要自己写TestProject.objects.create进行数据的新增
update()方法要自己写instance.save()进行数据的修改
validate()方法是在调用serializer.save()前,自动被调用的方法
序列化
1)将数据对象序列化
采用序列化器,将模型对象转化为字典
语法格式如下
bash
serializer=TestProjectSerializer(obj)
serializer.data# 序列化后的数据其中:obj是一个模型对象
例1:对TestProject数据对象进行序列化
bash
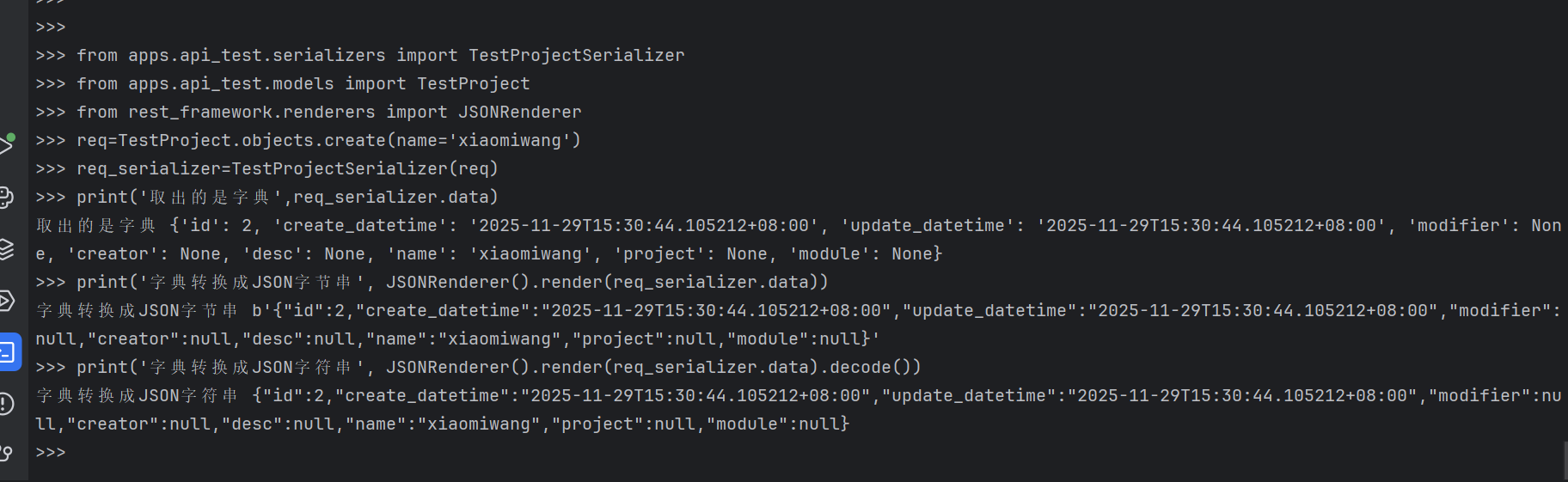
导入相关数据
>>> from apps.api_test.serializers import TestProjectSerializer
>>> from apps.api_test.models import TestProject
>>> from rest_framework.renderers import JSONRenderer
插入数据,得到数据对象
>>> req=TestProject.objects.create(name='xiaomiwang')
序列化1:将数据对象转换成python原生数据类型(字典)
>>> req_serializer=TestProjectSerializer(req)
>>> print('取出的是字典',req_serializer.data)
取出的是字典 {'id': 2, 'create_datetime': '2025-11-29T15:30:44.105212+08:00', 'update_datetime': '2025-11-29T15:30:44.105212+08:00', 'modifier': None, 'creator': None, 'desc': None, 'name': 'xiaomiwang', 'project': None, 'module': None}
>>> print('字典转换成JSON字节串', JSONRenderer().render(req_serializer.data))
字典转换成JSON字节串 b'{"id":2,"create_datetime":"2025-11-29T15:30:44.105212+08:00","update_datetime":"2025-11-29T15:30:44.105212+08:00","modifier":null,"creator":null,"desc":null,"name":"xiaomiwang","project":null,"module":null}'
>>> print('字典转换成JSON字符串', JSONRenderer().render(req_serializer.data).decode())
字典转换成JSON字符串 {"id":2,"create_datetime":"2025-11-29T15:30:44.105212+08:00","update_datetime":"2025-11-29T15:30:44.105212+08:00","modifier":null,"creator":null,"desc":null,"name":"xiaomiwang","project":null,"module":null}
>>>
(2)将QuerySet列表序列化
采用序列化器,将模型对象列表转化为python列表。语法格式如下:
bash
serializer=TestProjectSerializer(QuerySet,many=True)
serializer.data# 序列化后的数据注意,需要添加many=True参数
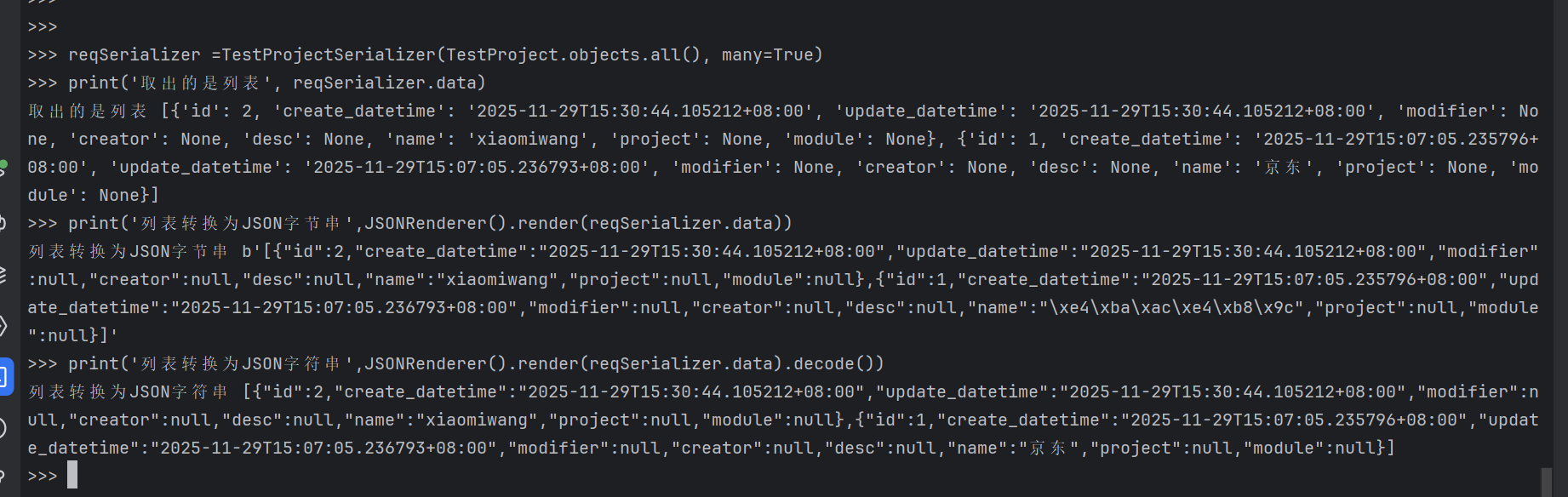
例2:对TestProject的QuerySet列表进行序列化
bash
>>> reqSerializer =TestProjectSerializer(TestProject.objects.all(), many=True)
>>> print('取出的是列表', reqSerializer.data)
取出的是列表 [{'id': 2, 'create_datetime': '2025-11-29T15:30:44.105212+08:00', 'update_datetime': '2025-11-29T15:30:44.105212+08:00', 'modifier': No
ne, 'creator': None, 'desc': None, 'name': 'xiaomiwang', 'project': None, 'module': None}, {'id': 1, 'create_datetime': '2025-11-29T15:07:05.235796+
08:00', 'update_datetime': '2025-11-29T15:07:05.236793+08:00', 'modifier': None, 'creator': None, 'desc': None, 'name': '京东', 'project': None, 'module': None}]
>>> print('列表转换为JSON字节串',JSONRenderer().render(reqSerializer.data))
列表转换为JSON字节串 b'[{"id":2,"create_datetime":"2025-11-29T15:30:44.105212+08:00","update_datetime":"2025-11-29T15:30:44.105212+08:00","modifier"
:null,"creator":null,"desc":null,"name":"xiaomiwang","project":null,"module":null},{"id":1,"create_datetime":"2025-11-29T15:07:05.235796+08:00","upd
ate_datetime":"2025-11-29T15:07:05.236793+08:00","modifier":null,"creator":null,"desc":null,"name":"\xe4\xba\xac\xe4\xb8\x9c","project":null,"module":null}]'
>>> print('列表转换为JSON字符串',JSONRenderer().render(reqSerializer.data).decode())
列表转换为JSON字符串 [{"id":2,"create_datetime":"2025-11-29T15:30:44.105212+08:00","update_datetime":"2025-11-29T15:30:44.105212+08:00","modifier":n
ull,"creator":null,"desc":null,"name":"xiaomiwang","project":null,"module":null},{"id":1,"create_datetime":"2025-11-29T15:07:05.235796+08:00","update_datetime":"2025-11-29T15:07:05.236793+08:00","modifier":null,"creator":null,"desc":null,"name":"京东","project":null,"module":null}]
>>>
反序列化
反序列化过程比序列化过程稍微复杂,因为反序列化需要对数据进行校验、更新到数据库等操作
但总的来说,就是把页面上传来的JSON格式的数据,经过序列化、校验等步骤,最终更新到数据库中
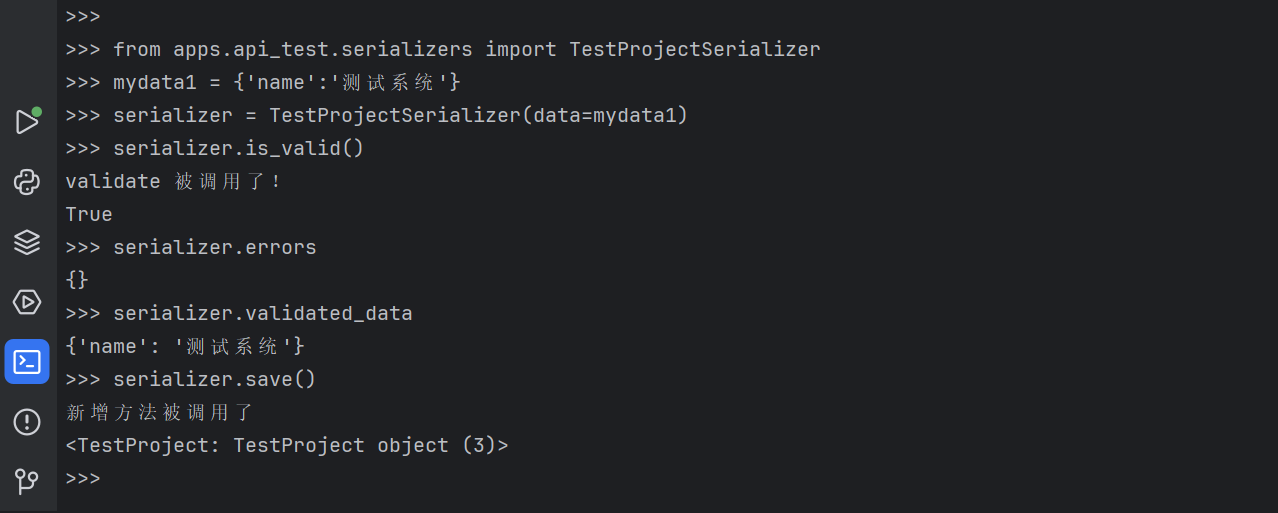
(1)反序列化-新增数据
以TestProject表的新增数据为例,模拟页面上传入一个my_data字典,经过反序列化后,保存到数据
传入一个标准的json
bash
>>> from apps.api_test.serializers import TestProjectSerializer
>>> mydata1 = {'name':'测试系统'}
>>> serializer = TestProjectSerializer(data=mydata1)
>>> serializer.is_valid()
validate 被调用了!
True
>>> serializer.errors
{}
>>> serializer.validated_data
{'name': '测试系统'}
>>> serializer.save()
新增方法被调用了
<TestProject: TestProject object (3)>
>>>
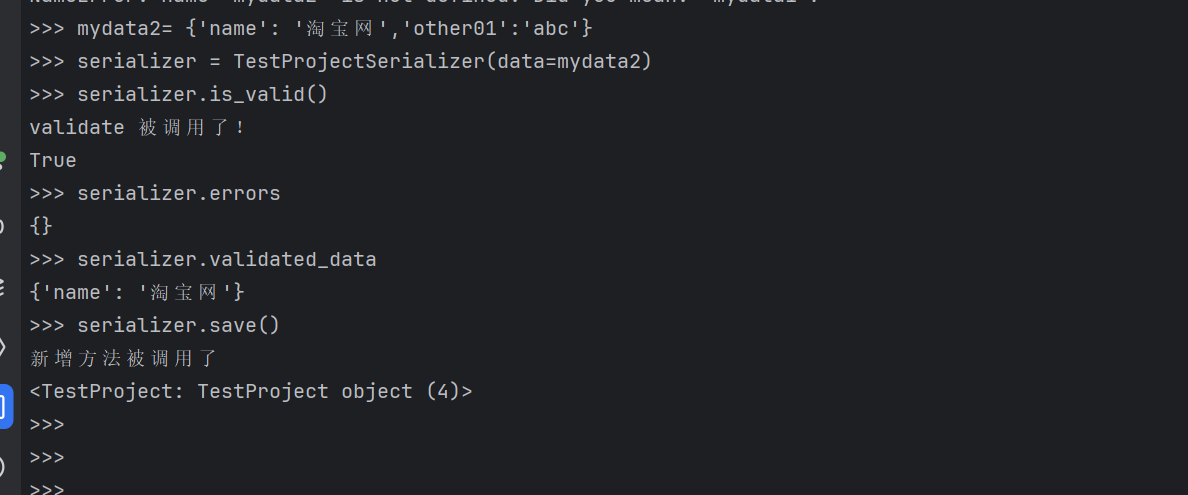
传入的JSON存在多余字段:other01,这个字段未被处理
bash
>>> mydata2= {'name': '淘宝网','other01':'abc'}
>>> serializer = TestProjectSerializer(data=mydata2)
>>> serializer.is_valid()
validate 被调用了!
True
>>> serializer.errors
{}
>>> serializer.validated_data
{'name': '淘宝网'}
>>> serializer.save()
新增方法被调用了
<TestProject: TestProject object (4)>
>>>
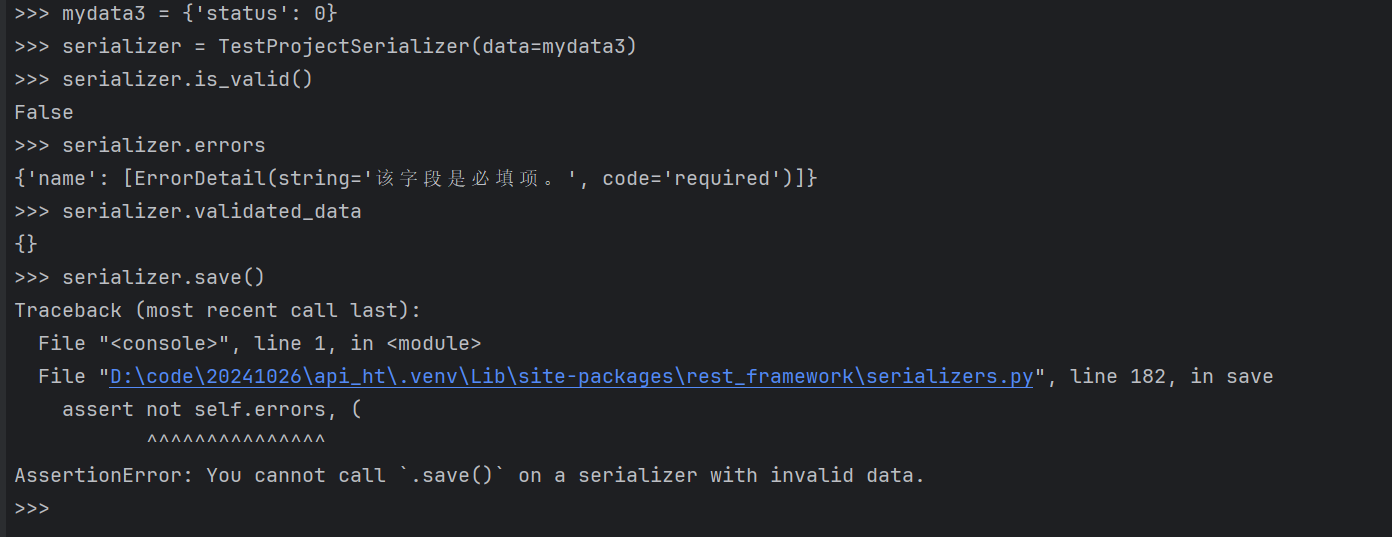
传入的JSON缺少:name字段
bash
>>> mydata3 = {'status': 0}
>>> serializer = TestProjectSerializer(data=mydata3)
>>> serializer.is_valid()
False
>>> serializer.errors
{'name': [ErrorDetail(string='该字段是必填项。', code='required')]}
>>> serializer.validated_data
{}
>>> serializer.save()
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "D:\code\20241026\api_ht\.venv\Lib\site-packages\rest_framework\serializers.py", line 182, in save
assert not self.errors, (
^^^^^^^^^^^^^^^
AssertionError: You cannot call `.save()` on a serializer with invalid data.
>>>
(2)反序列化-修改数据
以TestProject表的修改数据为例,模拟⻚面上传入一个my_data字典,经过反序列化后,修改到数据库
bash
>>> from apps.api_test.models import TestProject
>>> from apps.api_test.serializers import TestProjectSerializer
>>> req1=TestProject.objects.create(name='测试001')
>>> my_data= {'name': '测试008'}
>>> serializer=TestProjectSerializer(data=my_data)
>>> serializer.instance=req1
>>> serializer.is_valid()
validate 被调用了!
True
>>> serializer.save()
修改方法被调用了
<TestProject: TestProject object (5)>
>>> print(TestProject.objects.get(pk=req1.id).values('data'))
Traceback (most recent call last):
File "<console>", line 1, in <module>
AttributeError: 'TestProject' object has no attribute 'values'
>>> print(TestProject.objects.get(pk=req1.id).values('data'))
Traceback (most recent call last):
File "<console>", line 1, in <module>
AttributeError: 'TestProject' object has no attribute 'values'
>>> print(repr(serializer))
TestProjectSerializer(data={'name': '测试008'}):
id = IntegerField(label='ID', read_only=True)
create_datetime = DateTimeField(allow_null=True, help_text='创建时间', label='创建时间', read_only=True)
update_datetime = DateTimeField(allow_null=True, help_text='修改时间', label='修改时间', read_only=True)
modifier = CharField(allow_blank=True, allow_null=True, help_text='修改人', label='修改人', max_length=50, required=False)
creator = CharField(allow_blank=True, allow_null=True, help_text='创建人', label='创建人', max_length=50, required=False)
desc = CharField(allow_blank=True, allow_null=True, help_text='备注', label='备注', max_length=255, required=False)
name = CharField(label='接口名称', max_length=128)
method = ChoiceField(choices=[('GET', 'GET'), ('POST', 'POST'), ('PUT', 'PUT'), ('DELETE', 'DELETE')], label='请求方法', required=False)
url = CharField(label='请求路径', max_length=1000, required=False)
params = CharField(allow_blank=True, help_text='查询参数', label='查询参数', required=False, style={'base_template': 'textarea.html'})
req_content_type = CharField(label='请求消息类型', max_length=100, required=False)
res_content_type = CharField(label='响应消息类型', max_length=100, required=False)
req_body_demo = CharField(allow_blank=True, help_text='请求体示例', label='请求体示例', required=False, style={'base_template': 'textarea.html'})
res_body_demo = CharField(allow_blank=True, help_text='响应体示例', label='响应体示例', required=False, style={'base_template': 'textarea.html'})
business_rule = CharField(allow_blank=True, help_text='业务规则', label='业务规则', required=False, style={'base_template': 'textarea.html'})
project = PrimaryKeyRelatedField(allow_null=True, label='项目名称', queryset=TestProject.objects.all(), required=False)
module = PrimaryKeyRelatedField(allow_null=True, label='所属模块', queryset=TestModule.objects.all(), required=False)
>>>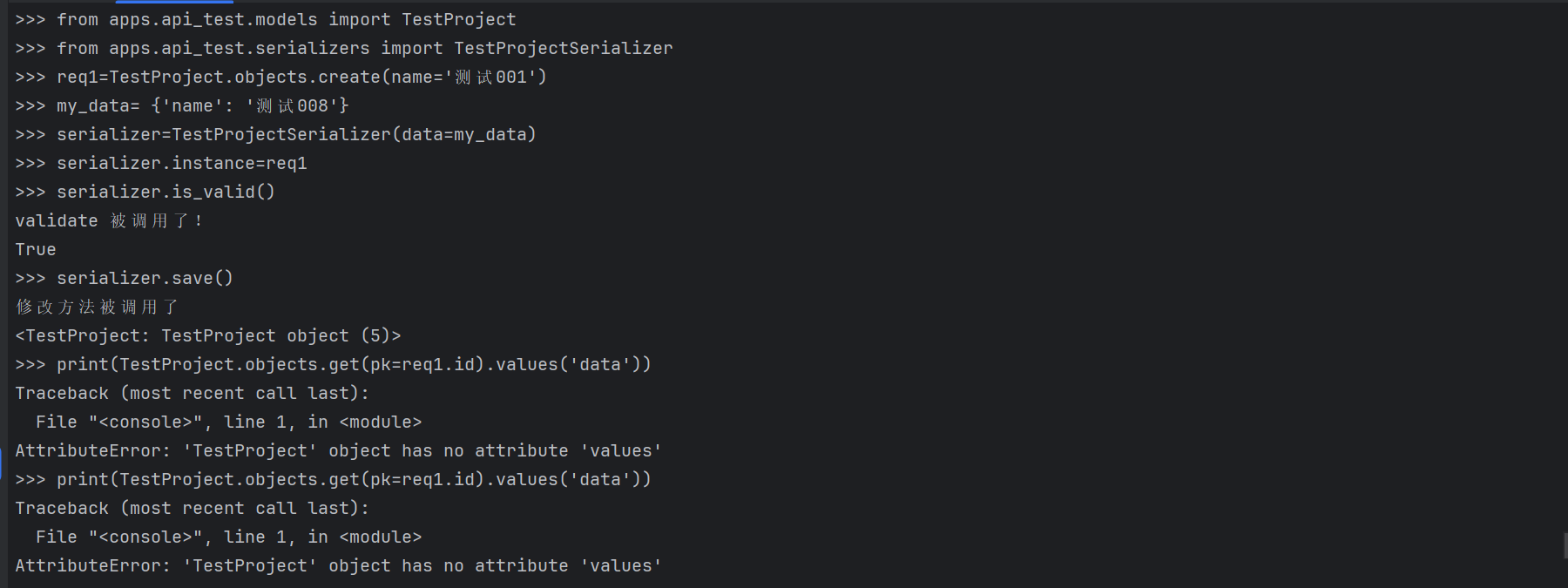
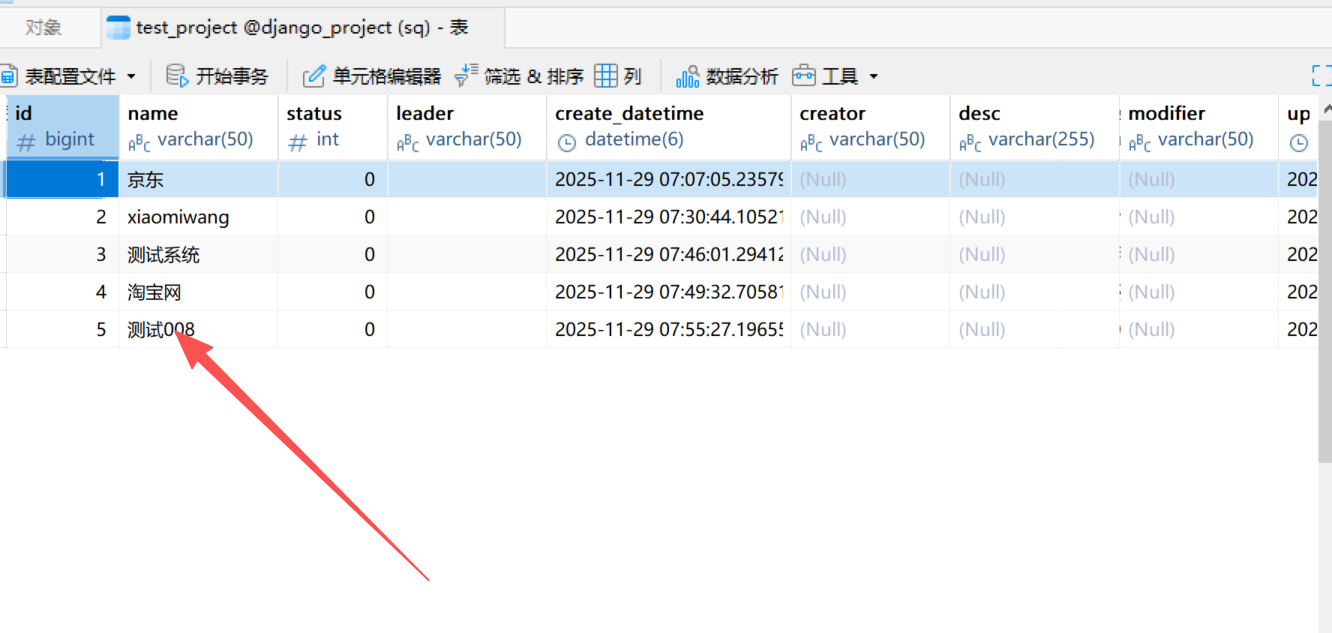
我们查看数据库表发现 该数据确实被修改了
视图函数
普通视图函数
编写一个视图,返回所有的请求数据
bash
def project_1(request):
if request.method == 'GET':
serializer=TestProjectSerializer(TestProject.objects.all(), many=True)
# safe=False的作用是为了支持字典{}以外的python对象转json
return JsonResponse(serializer.data, safe=False)api_test/urls.py,写入路由:
重新启动服务

函数视图-加装饰器使用
@api_view语法格式如下:
bash
@api_view([请求方法列表])
def xxxx(request):
pass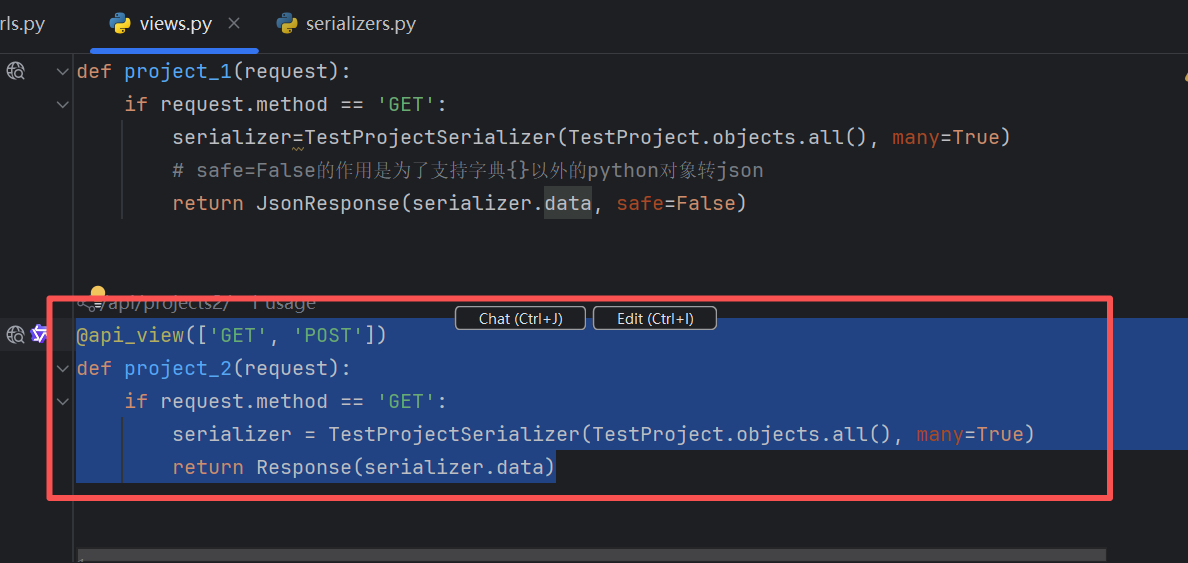
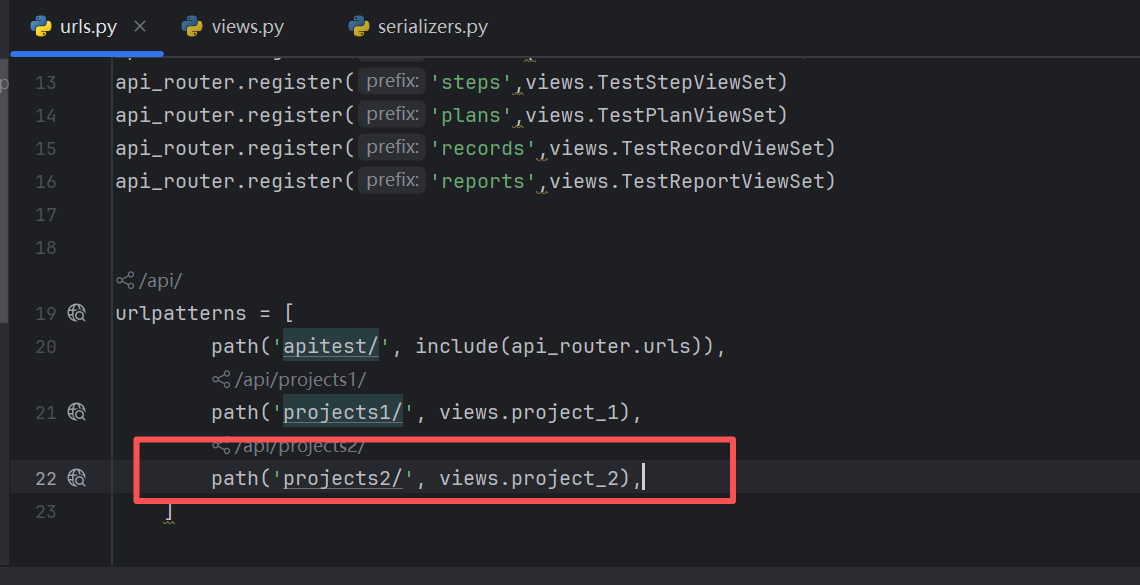
添加路由
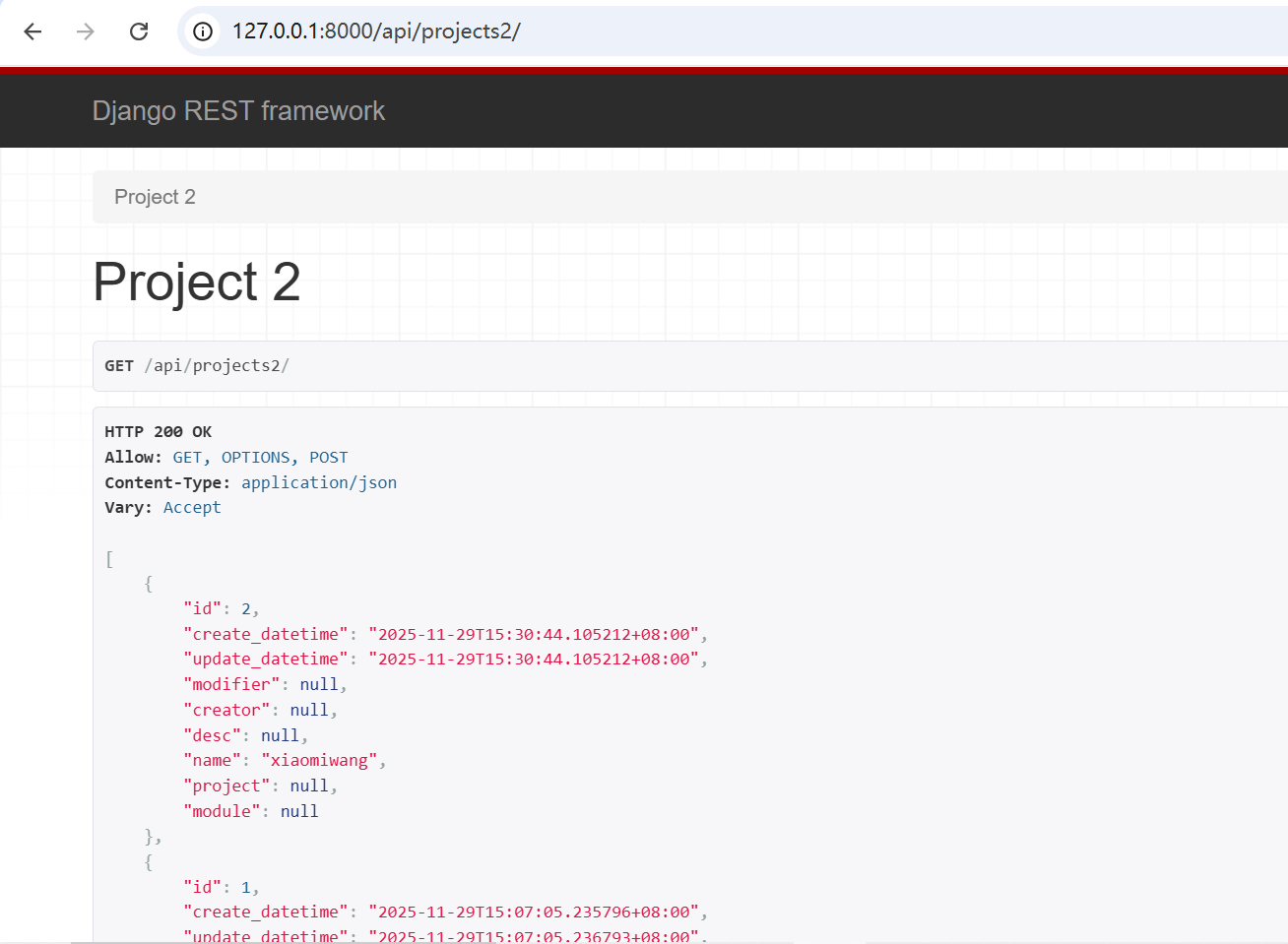
重启服务
使用装饰器四大变化
变化1:可以指定接收的请求方法列表
变化2:Response对象,添加了装饰器后,可以使用DRF的Response对象,代替Django的HTTPResponse、render、JsonResponse对象,进行响应数据的返回
变化3:Request 对象,添加了装饰器后,request对象多了一个data属性,可以接收任意形式的数据,且适用于POST、PUT、PATCH请求
变化4:url中的format参数,目前,我们采用了函数装饰器、包括后面采用类视图、通用类视图、视图集后,默认接口请求,返回的HTML页面,而不是json数据。我们可以给URL添加format查询字符串,来获取不同格式的数据
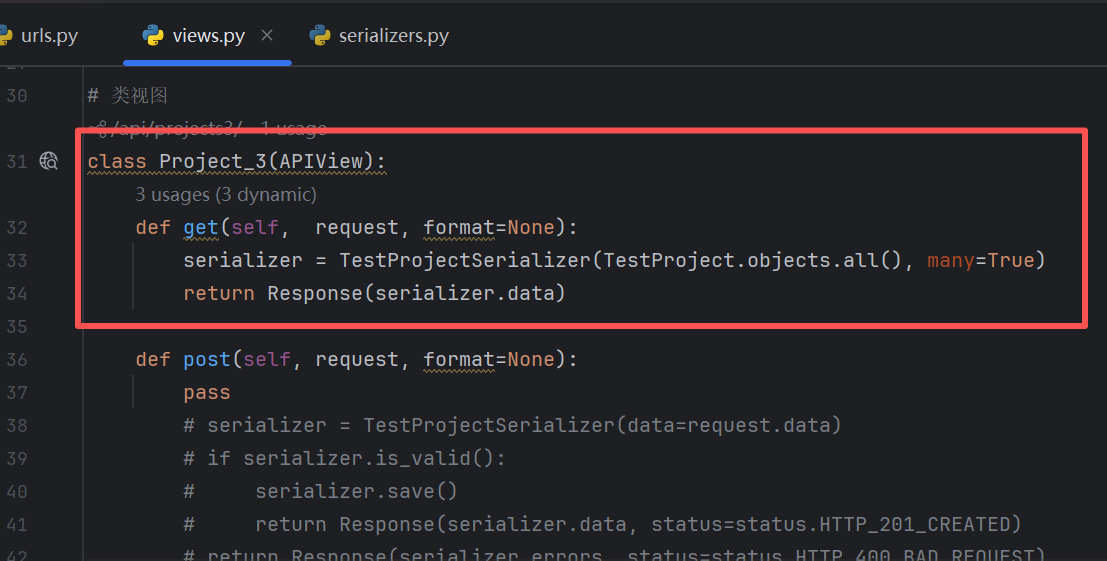
类视图
顾名思义,要写一个类
增加路由
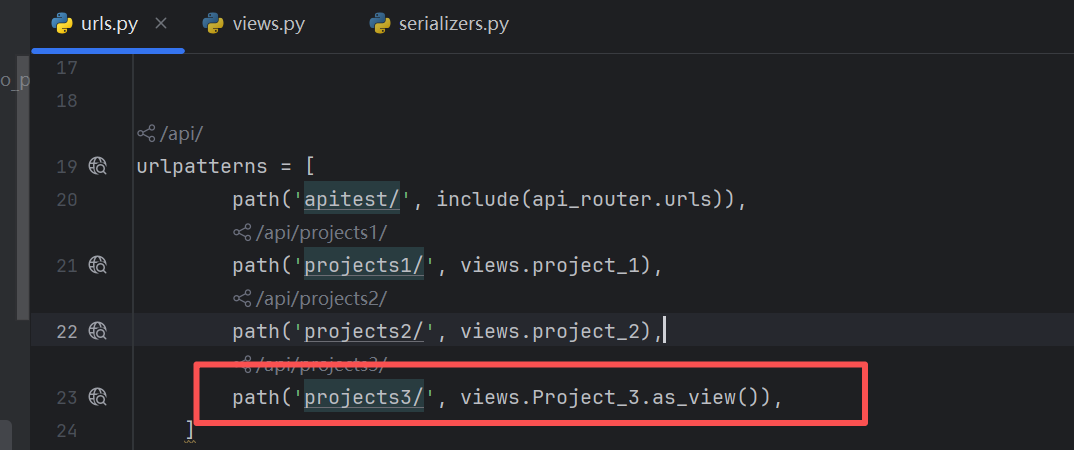
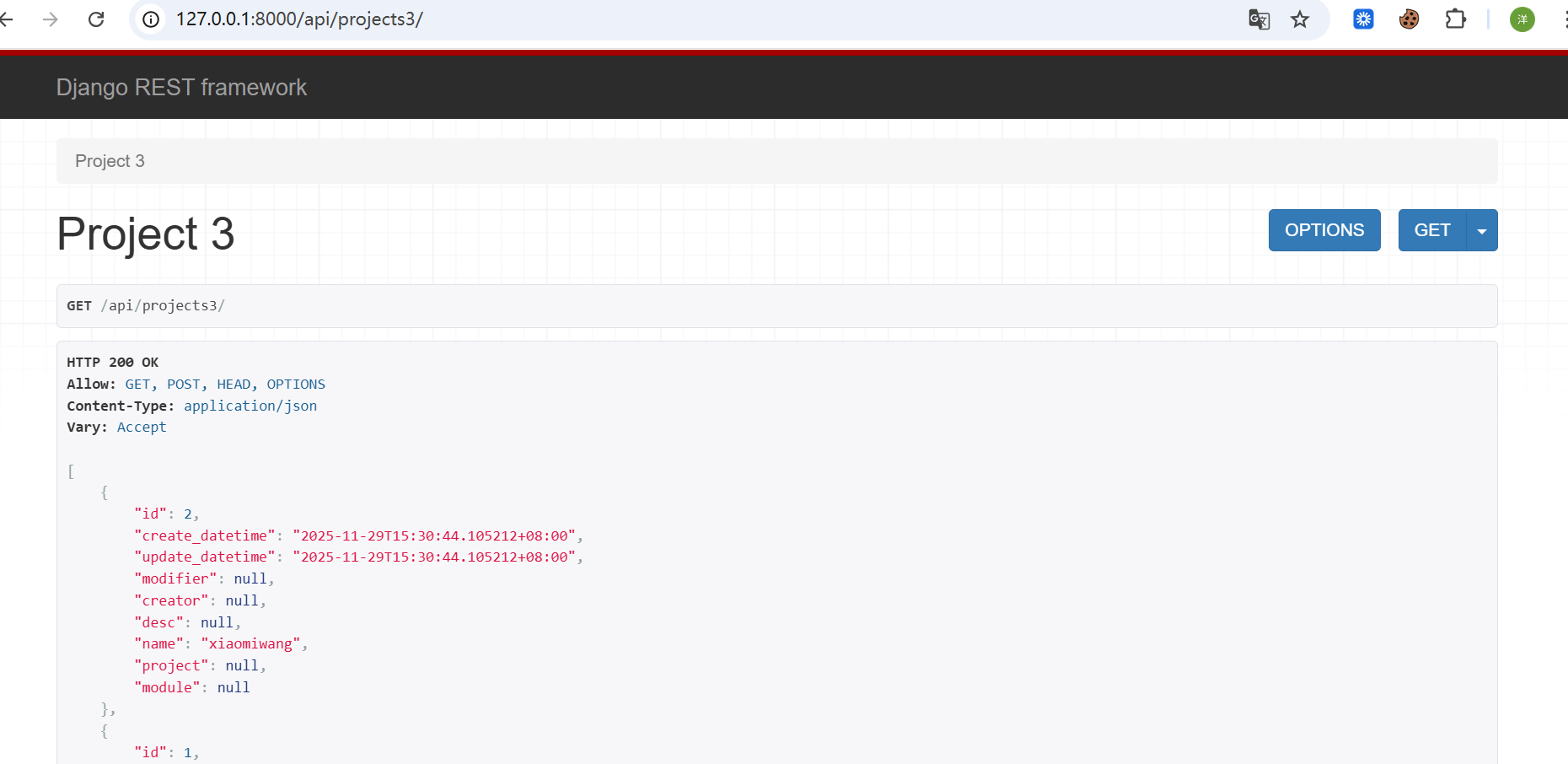
重启下服务,正常也能访问
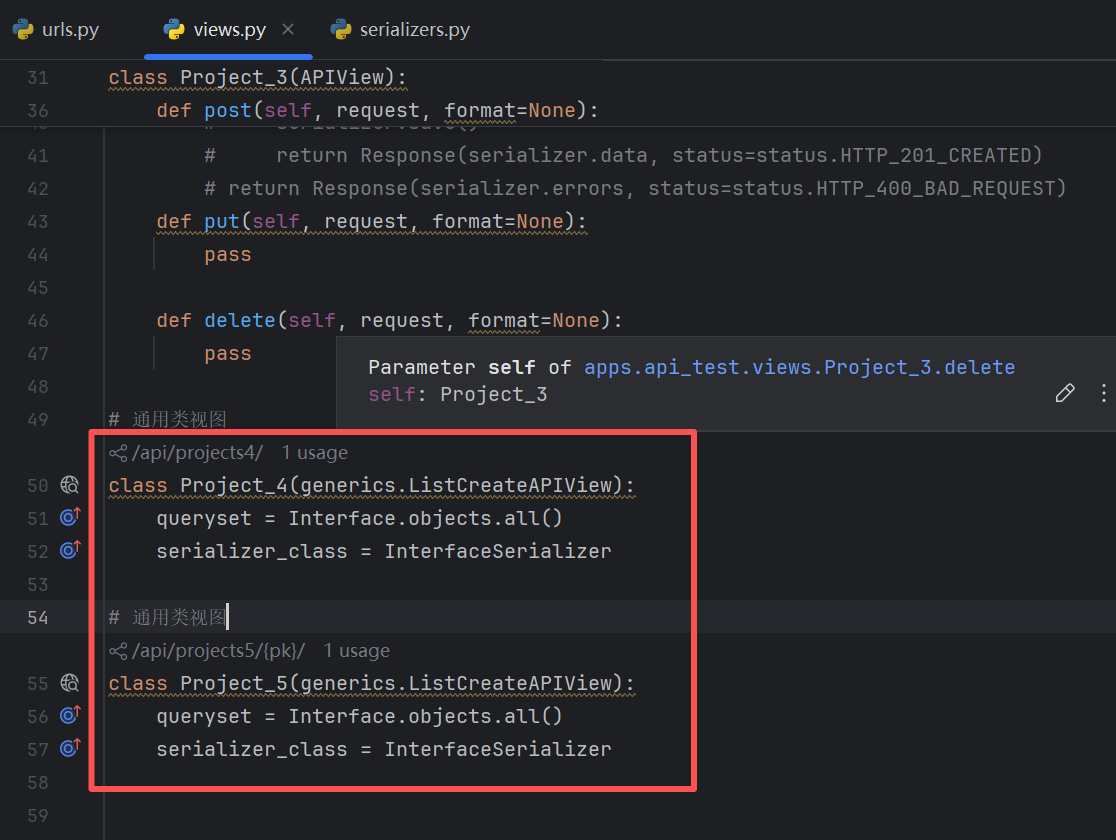
通用类视图
直接上代码
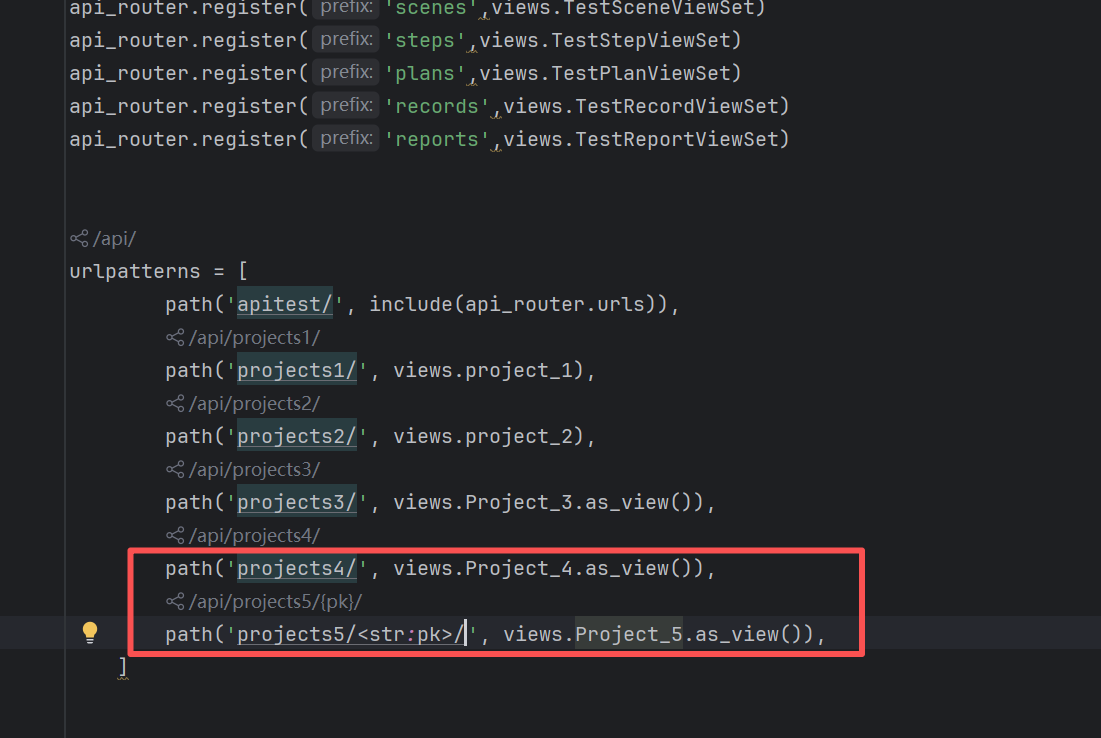
访问其实也是可以的
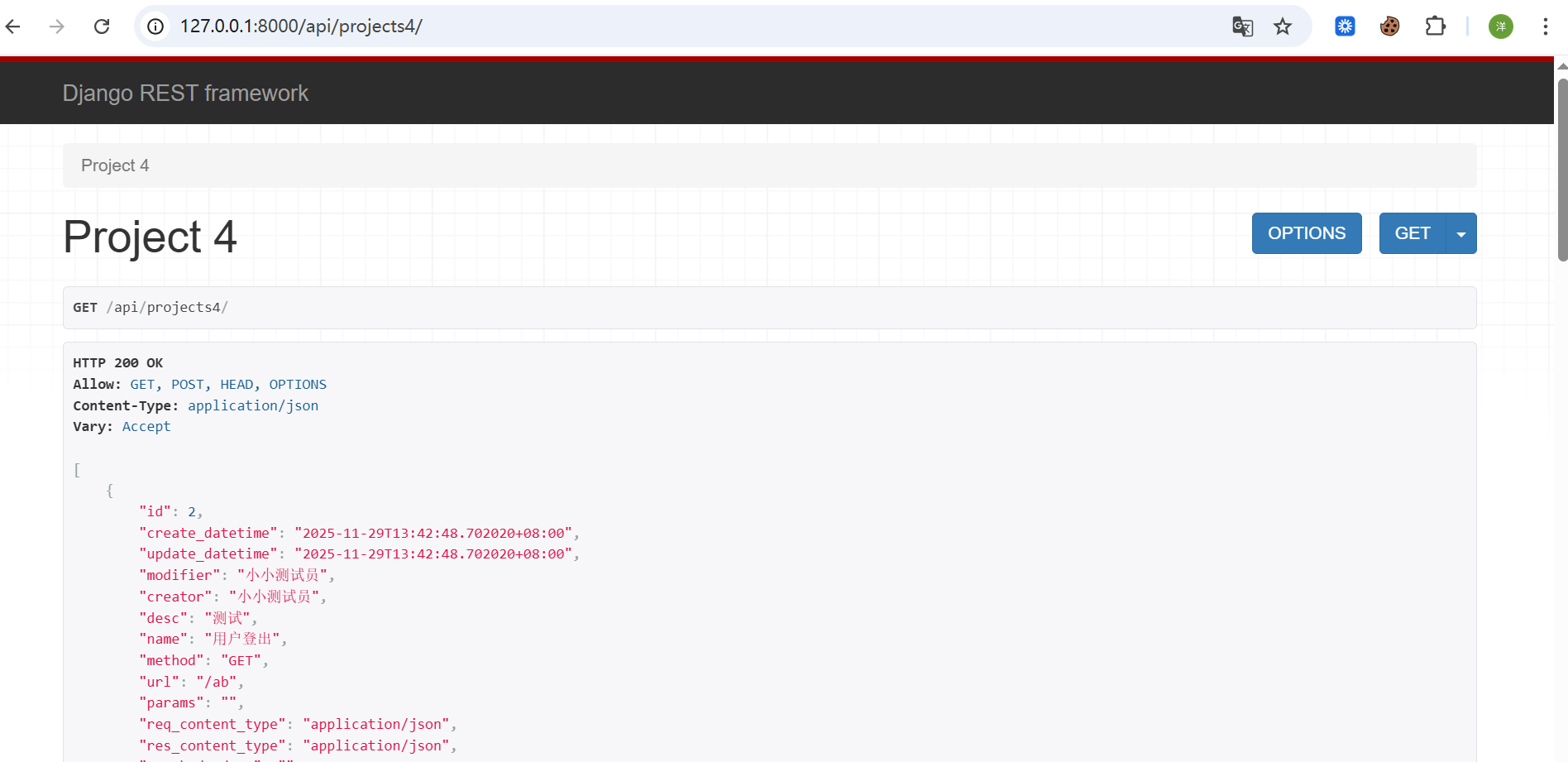
统一API接口返回规范
从上面可以看出,视图集返回的API数据,不完全符合我们的需求,也不利于前端的渲染,也不符合RESTFull规范。在项目开发之前,项目组必须制定API接口响应规范。响应规范包括对象数组、单个对象、返回异常、未登录情况。
说的直白一点就是,之前我们看到的数据都是数据表里面的数据返回,对于code,message等接口通用性信息,并没有返回,所以,我们要增加这一部分内容
规范1-对象数组
在调用列出全部API接口时,后端返回的数据为对象数组,此外还有总数据条数等信息。因此,返回数据格式规范如下:
bash
```json
{
"msg": "xxx",
"code": 200,
"result": {
"data": [],
"total": 20,
"page": 1,
"limit": 10
}
}
其中:
code属性:为响应编码。操作成功为200
msg属性:为提示信息
result属性:返回的数据对象
data属性:JSON对象数组
total属性:总数据条数
page属性:第几页
limit属性:每页显示数据条数
规范2-单个对象
在调用新增、修改、查看详细API时,后端返回的数据为单个对象。因此,返回数据格式规范如下:
bash
```json
{
"code": 200,
"msg": "",
"result": {}
}规范3-返回异常
在调用API时,难免不会出现异常。因此,当出现异常时,返回数据格式规范如下:
bash
```json
{
"code": 400,
"msg": "xxx",
"result": null
}
规范4-未登录
在调用API时,如果有些接口需要用戶登录后,才能够调用。当用戶没有登录时,访问接口会出现异常。为了前端能够方便的区别是未登录引起的异常,还是其他异常。我们把未登录单独从异常中剥离出来。也就是说,后端发现是未登录异常,那么返回code的值为401。规范如下:
bash
```json
{
"code": 401,
"msg": "未提供身份认证信息",
"result": null
}
封装响应类
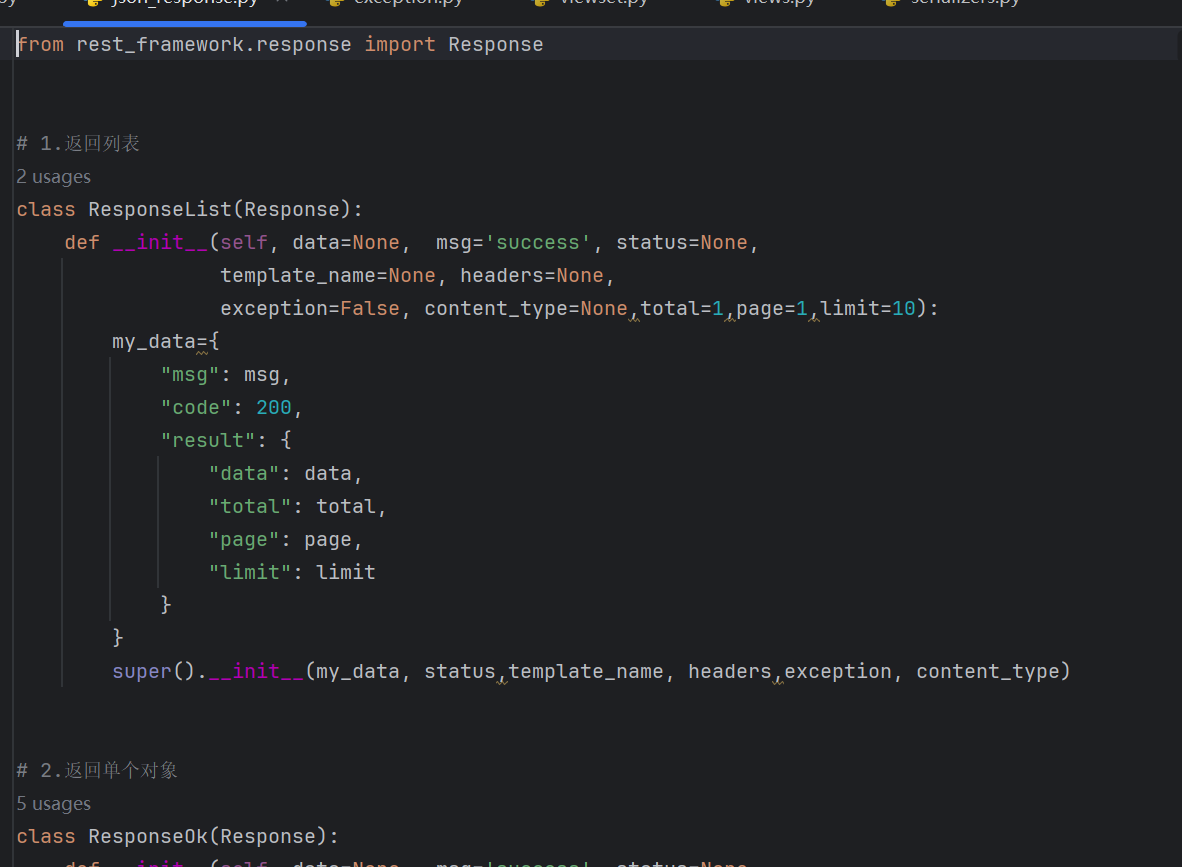
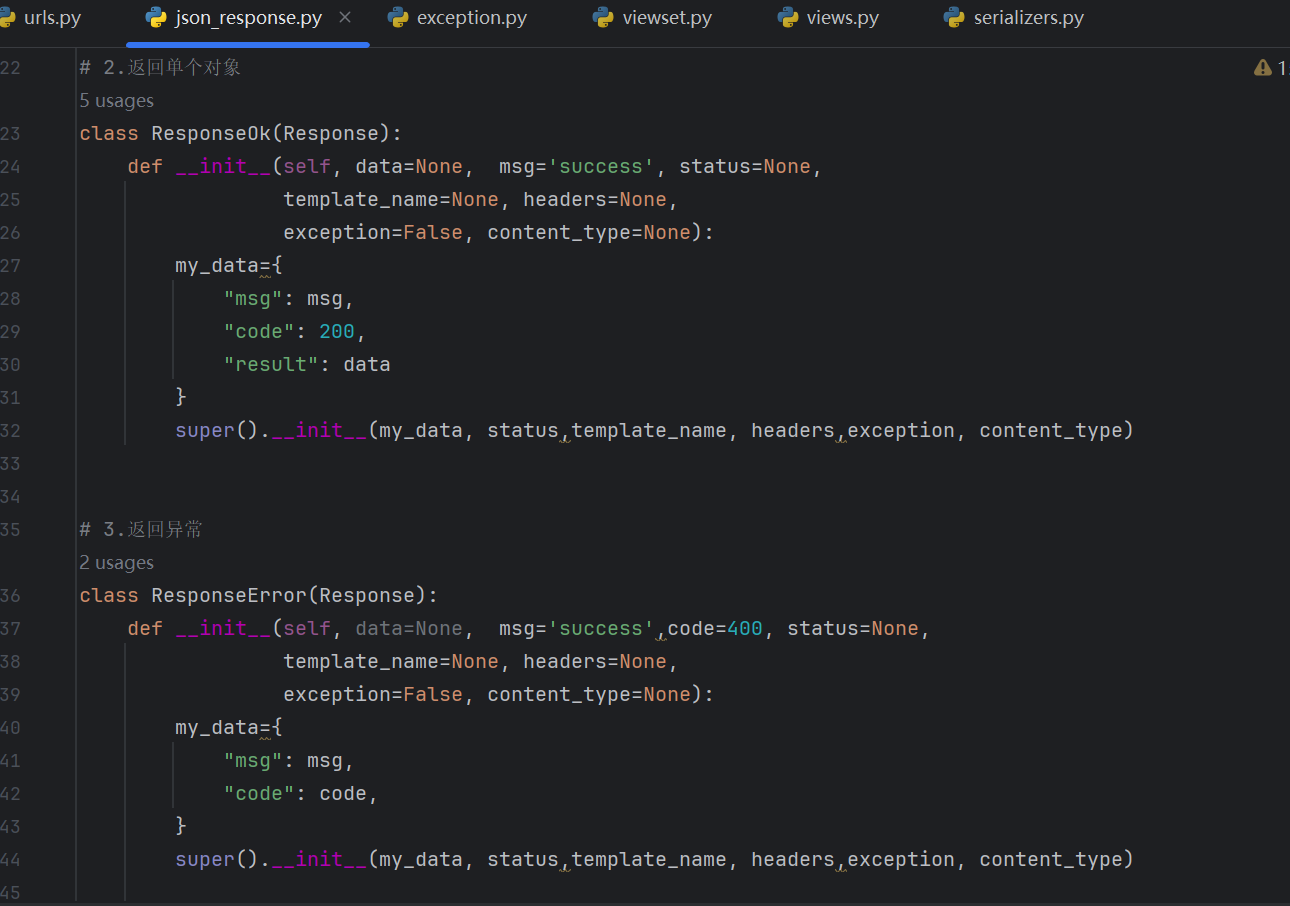
接下来,在项目的utils包下,新建json_response.py(名称随意)模块。
在该模块中,分别定义三个类:
ResponseOk类:继承DRF的Response类,用于返回单个对象
ResponseList类:继承DRF的Response类,用于返回对象列表
ResponseError类:继承DRF的Response类,用于返回所有异常信息(含未登录异常)
封装视图集
为了解决视图集的数据返回格式问题,我们可以对视图集的五个API函数进行重写(当然,这不是唯一的解决办法),每个函数中仅需要替换Response返回类为我们上面自己封装的三个ResponseXXX类。
我们在utils包下,新建一个viewset.py(名称随意)模块。在模块中创建一个视图集的基类(如:BaseModelViewSet),来完成重写API,其他视图集均可继承该基类即可。完整代码如下
bash
from rest_framework import status
from rest_framework.viewsets import ModelViewSet
from utils.json_response import ResponseOk, ResponseList
class BaseModelViewSet(ModelViewSet):
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return ResponseOk(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return ResponseList(serializer.data)
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return ResponseOk(serializer.data)
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return ResponseOk(serializer.data)
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
self.perform_destroy(instance)
return ResponseOk(status=status.HTTP_204_NO_CONTENT)我们看下效果:
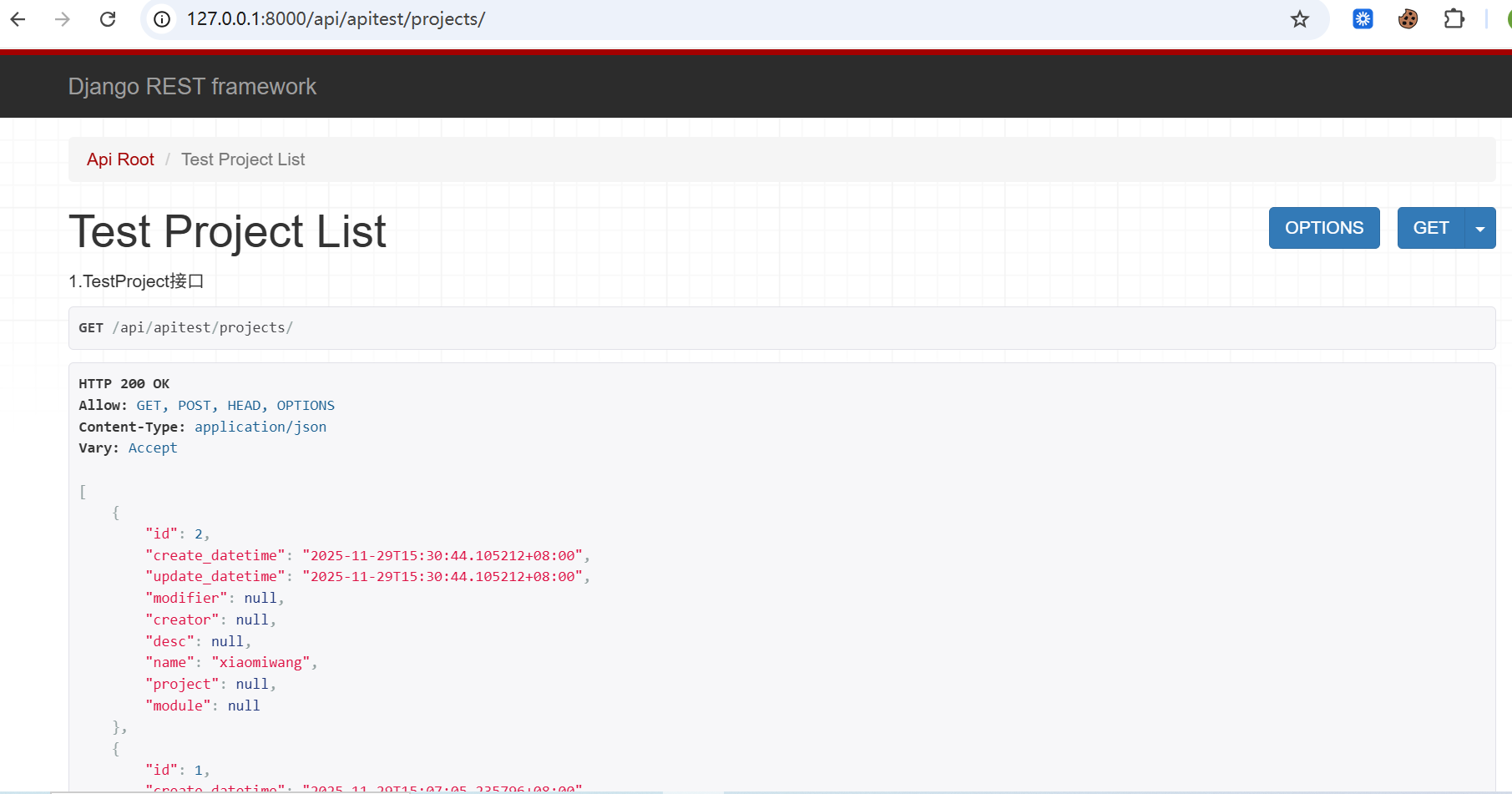
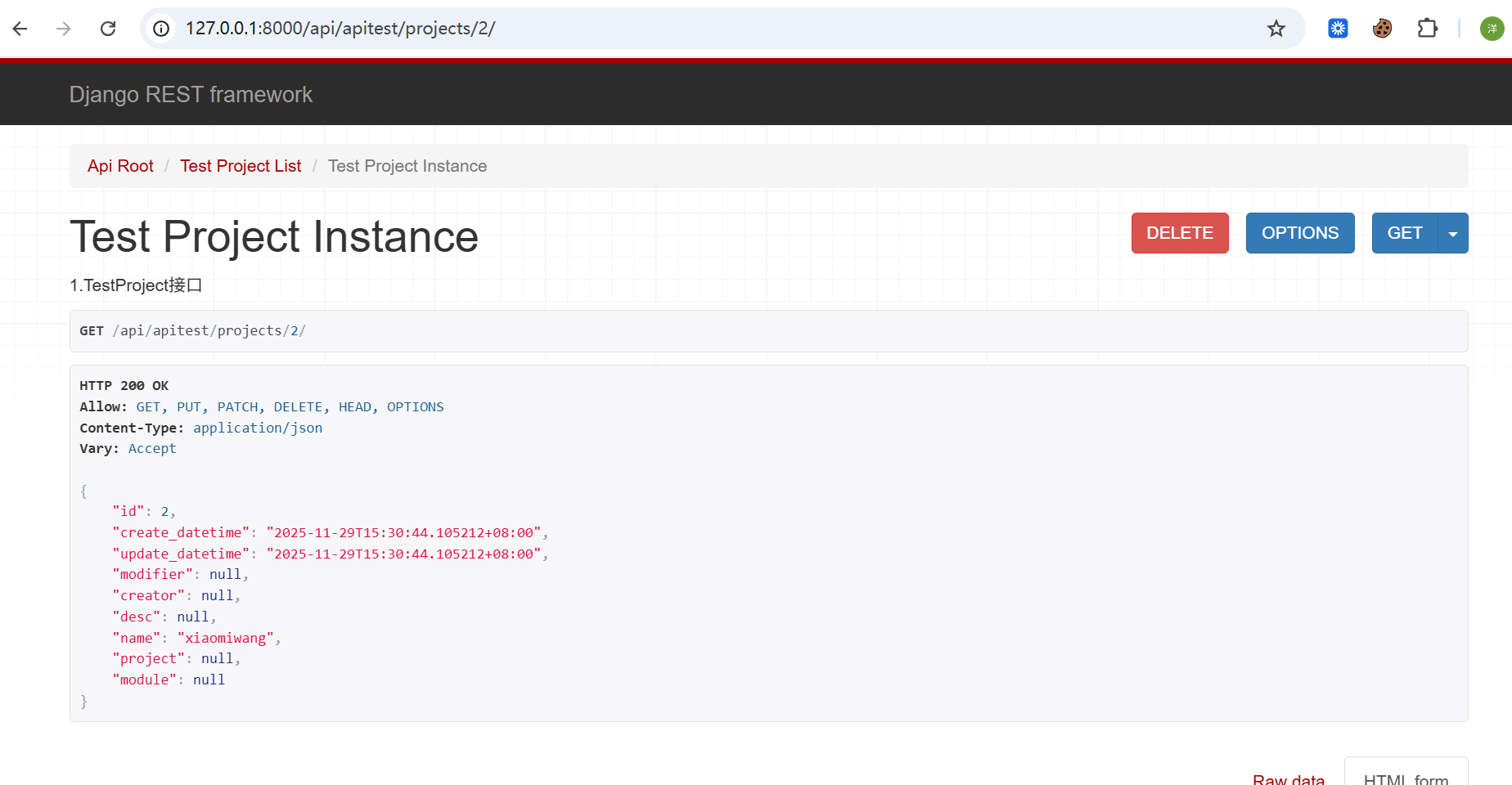
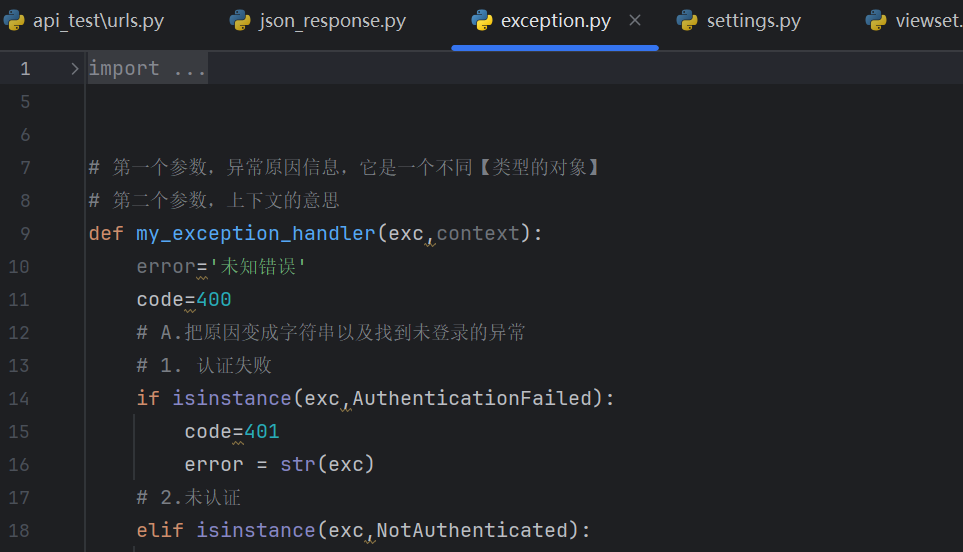
对于异常的返回,我们要先封装一个异常的函数,这里就不给大家展示了
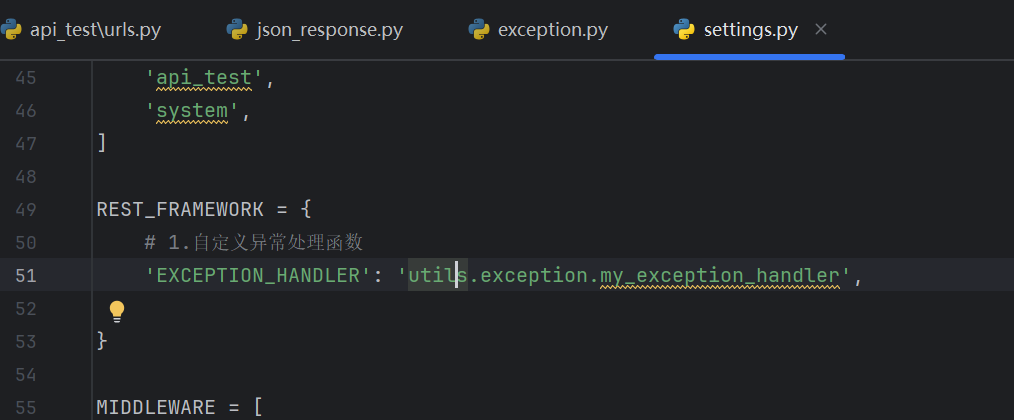
然后在配置文件里面再新增一个配置
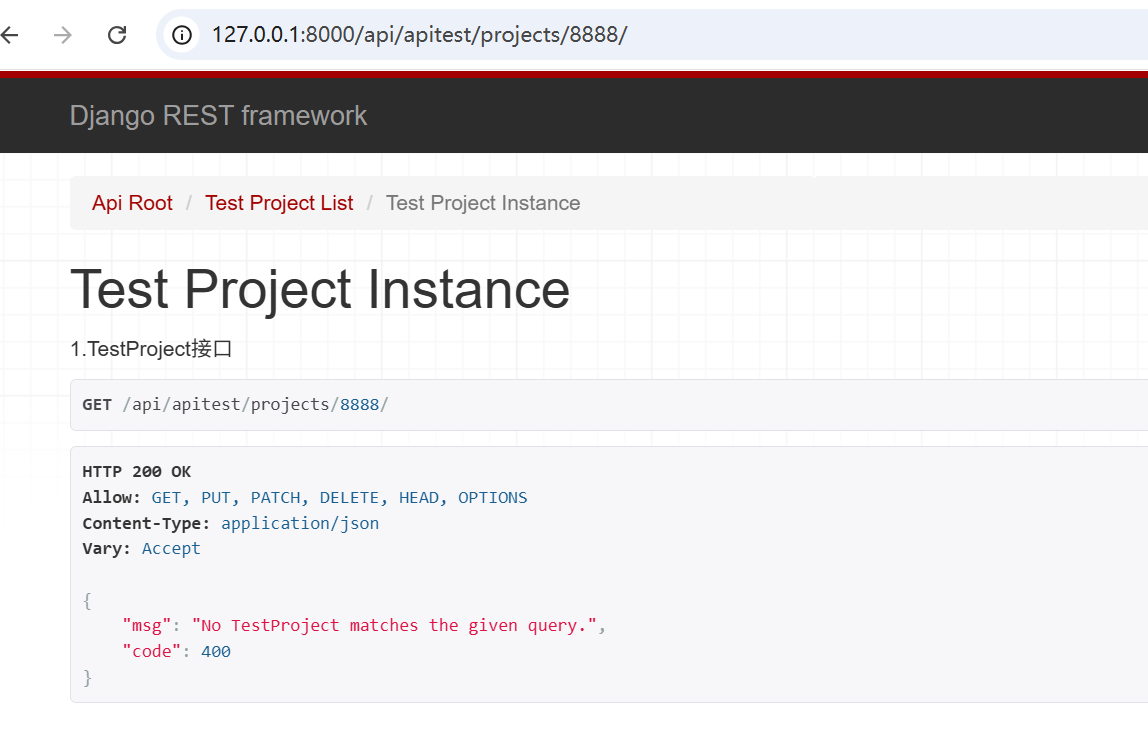
我们看下效果
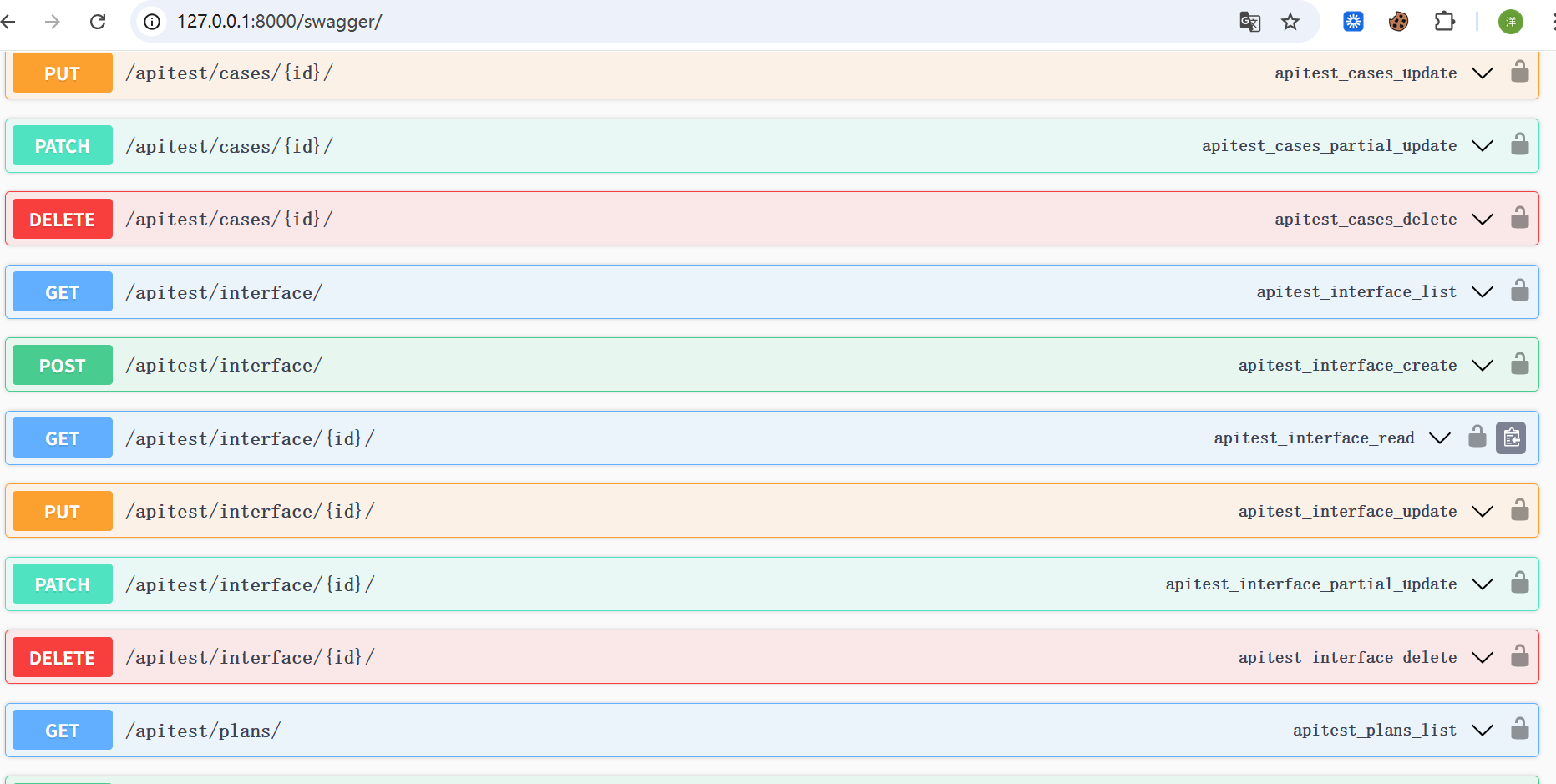
集成Swagger在线接口文档
目前为止,我们的接口开发到了一定的阶段,已经初具规模,在和前端对接之前,需要规范化我们的接口文档。如果纯手写的话工作量大且重复枯燥,因此,我们可以用工具帮助我们实现接口文档的自动生成。
Django REST Swagger项目已经不维护了,并且不支持最新的Django,所以我们选择drf-yasg 项目作为接口文档生成器。
yasg的功能非常强大,可以同时支持多种文档格式。
官网地址为:https://github.com/axnsan12/drf-yasg
bash
pipinstall-Udrf-yasg# 安装最新版的drf-yasg配置文件中配置:
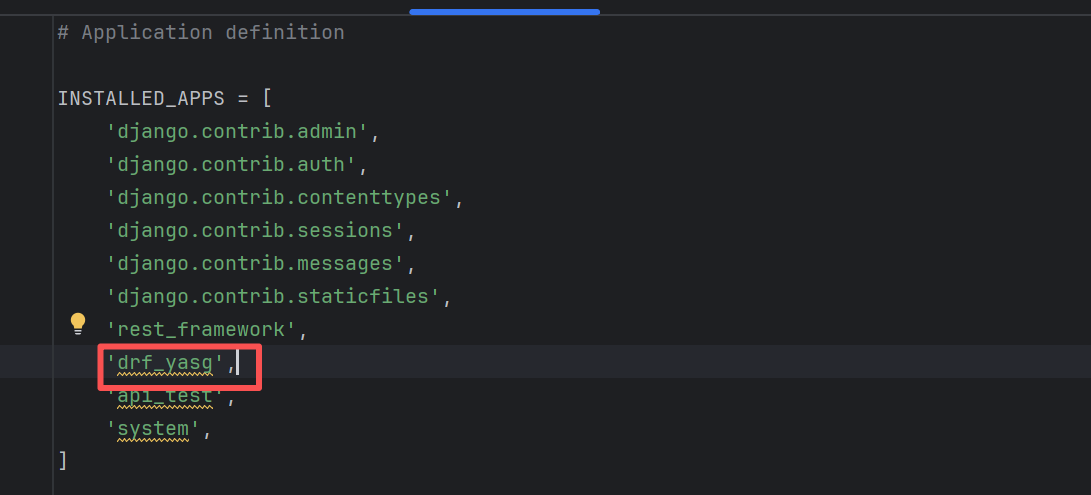
配置路由
swagger页面的访问需要配置路由。
因此,我们再总路由中,添加相关的配置。autotp_django/urls.py总路由配置中,添加:
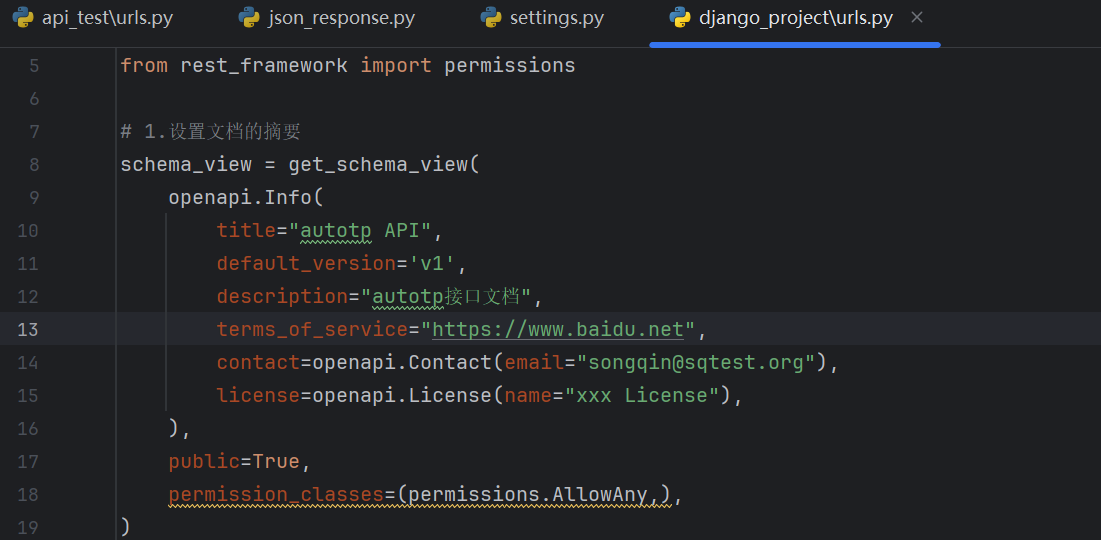
然后再添加一个路由
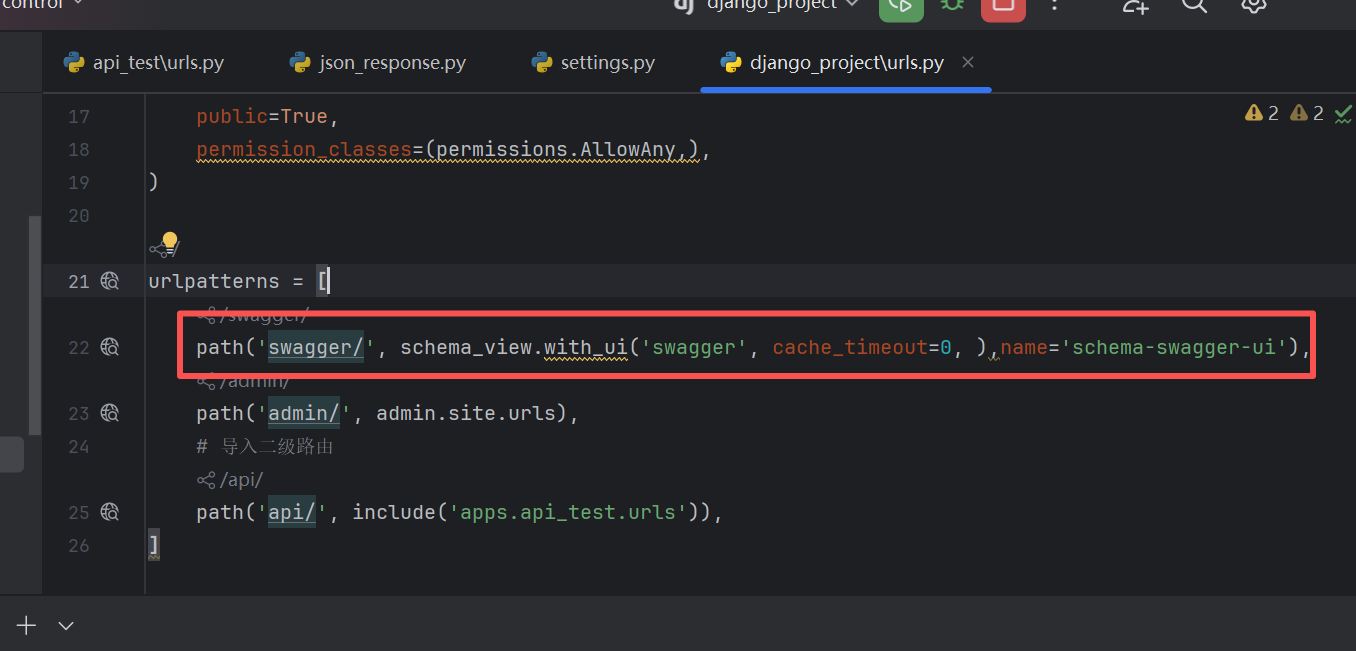
好,我们看下效果