Diffusion模型
Diffusion ,也就是扩散的意思。Diffusion 模型是一种受到非平衡热力学启发,定义马尔科夫链的扩散步骤,向数据添加噪声,学习逆扩散过程,从噪声中构建样本。最初设计用于去噪,训练时间越长,降噪越逼真。
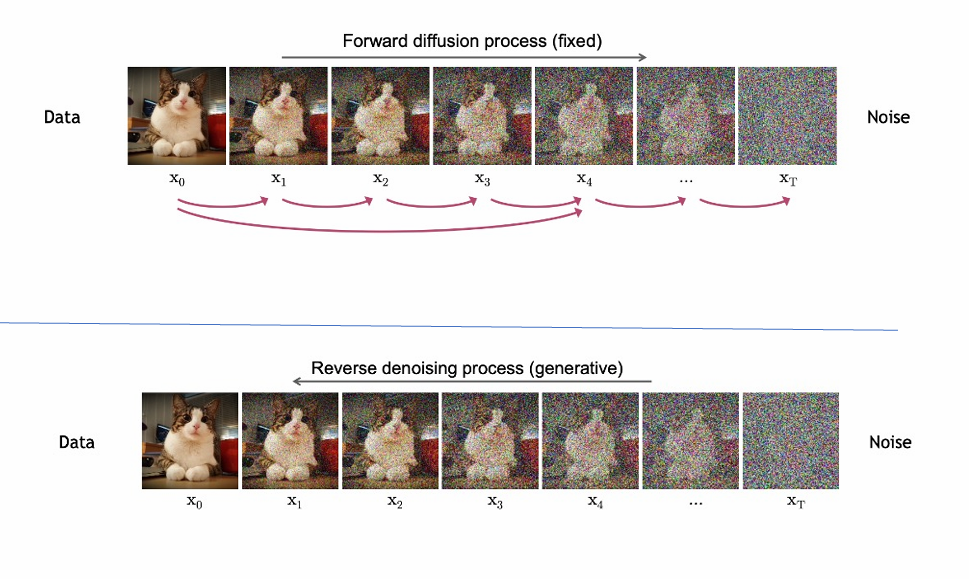
简而言之,该模型的训练分为两个步骤。首先,是正向过程,从到
的每一步,都在像原始图片中添加噪声 ,一步步将图片转为一个纯噪声数据样本 ;其次,是逆向过程,一步步从纯噪声数据样本去除噪声 ,得到一个无噪声数据样本,也就是上文所提及的去噪的功能。

当然,如果只是去噪Diffusion 模型不会成为图像生成的基石。在正向过程中,我们如何添加噪声?在逆向过程中,我们如何去除噪声?这些步骤的具体实现过程都会影响最终图片的具体生成结果。如果正反过程的过程正好互为正逆,那么就是实现去噪功能;而我在正向过程中比如额外添加了一个噪声,这个额外的噪声在经过一步步的去噪过程就会变成一个新的图形;又比如我使用噪声扩大图片的尺寸,就能实现图片的扩图功能等等。而Stable Diffusion 就使用了Difussion模型的逆向传播过程。
Stable Diffusion架构
1.文本编码器Clip
Clip 是由一个CNN 以及一个Transformer 构成的。它的作用是把用户输入的提示词与图像关联起来。
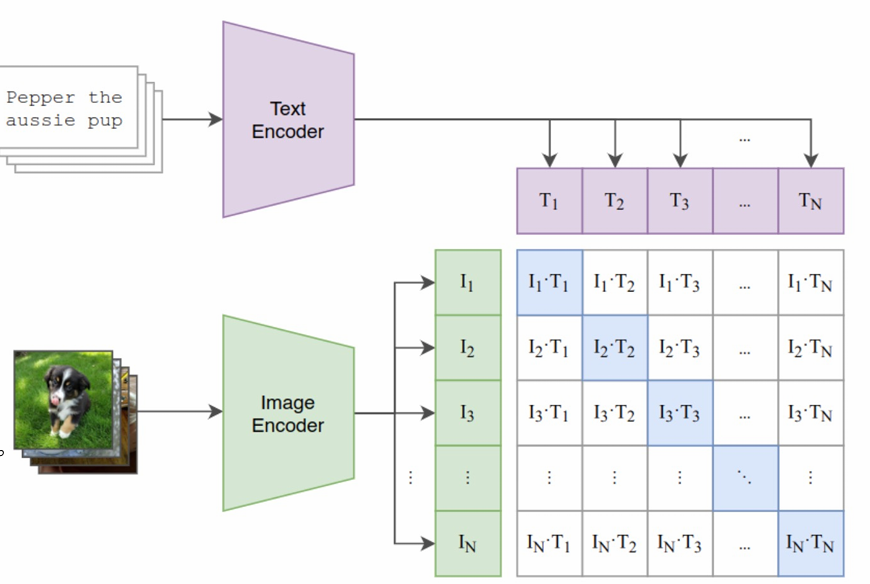
Text Encoder 就是Transformer,Image Encoder 就是CNN。如图,代表的是一个个词向量,
则是取出来的一个个图片对应的向量。通过最大化对角线上的余弦相似度使图片与对应的提示词对应,给图片打上标签,这就是训练Clip的阶段,也叫作对比学习阶段。
而在Stable Diffusion 中,仅仅是使用Transformer 模型把输入的提示词作为词向量矩阵输出,然后传入Unet中作为指导去噪。
2.Unet
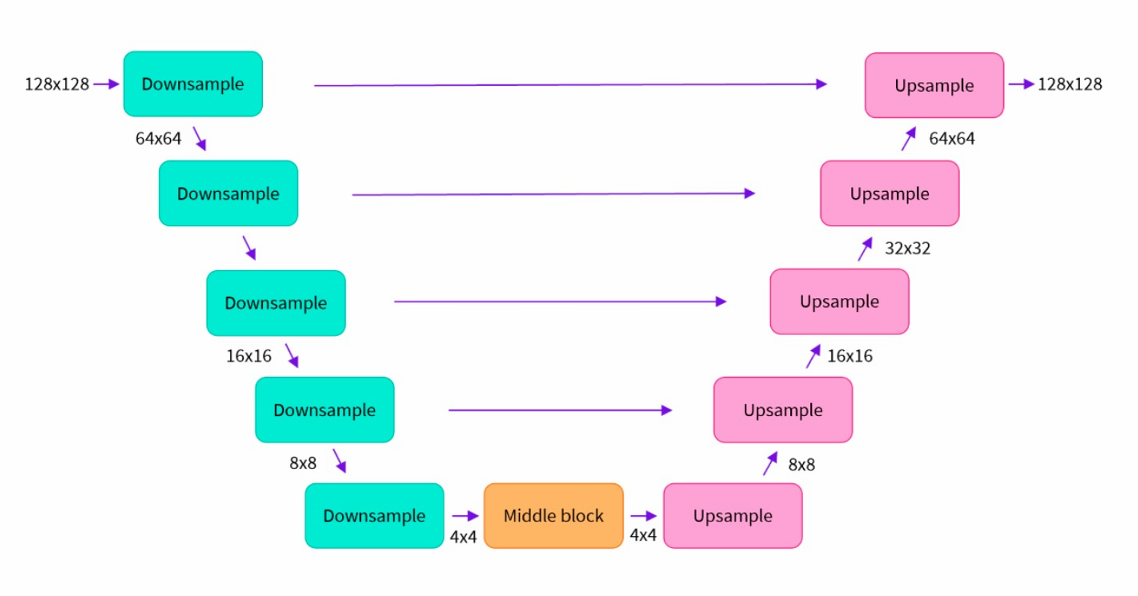
Unet 也是卷积神经网络的一种。主要分为三个部分:下采样(绿色部分)、上采样(粉色部分)和跳跃连接(横向连接)。这个就不过多介绍了,是卷积神经网络的基本内容。对比Stable Diffusion 与Diffusion ,前者使用Unet 替代后者每个时间步的直接去噪过程,横向连接保证了图片去噪前后的关联性 ,而在两个采样过程之间进行去噪过程(Middle block)有助于减少计算量,大幅提高了性能。
其中,去噪的算法成为Scheduler 也就是调度器。它可以定义降噪的步骤、是否具备随机性、查找去噪后样本的算法等,因此它又被称为采样算法。我们可以根据图像类型和使用的模型来选择不同的采样器,从而达到更佳的出图效果。
3.VAE模型
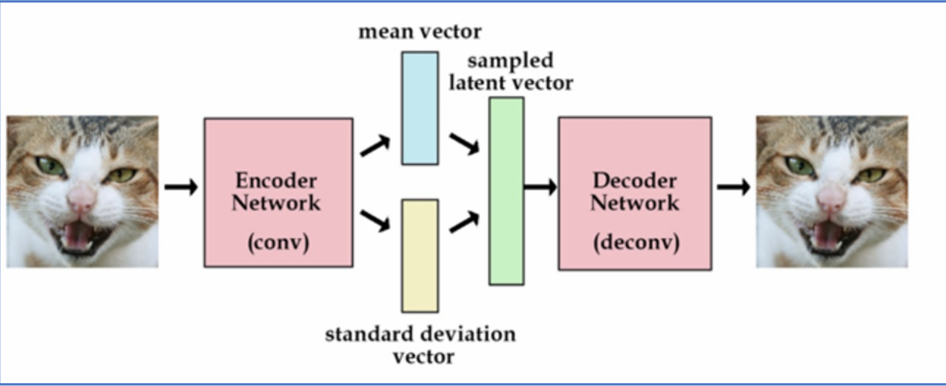
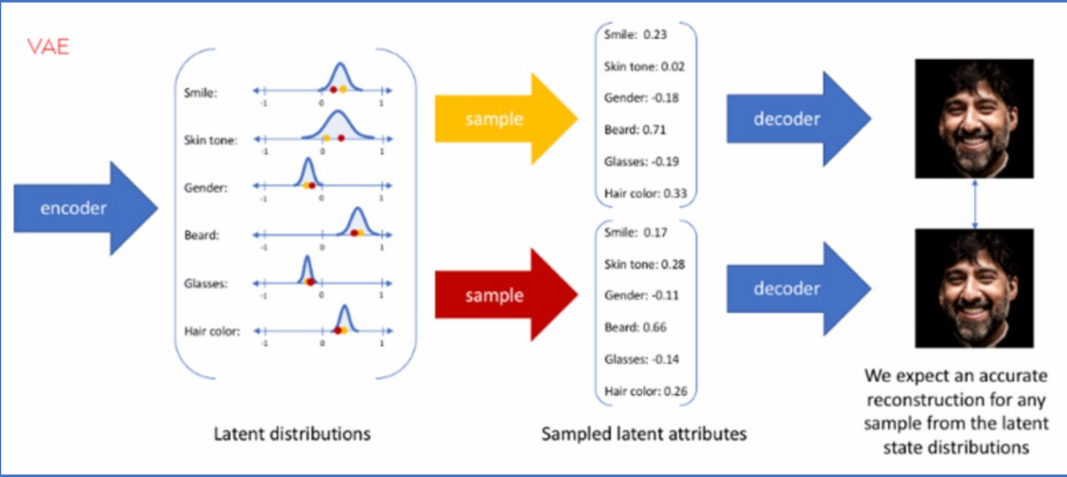
VAE ,变分自编码器。简单来说,它的作用就是将高维数据映射到低维空间(潜空间),从而实现数据的压缩和降维。它由编码器和解码器两部分组成,编码器将高维数据转换为潜在空间 概率分布,解码器从采样数据重建生成新数据,图像经解码器得多种特征,包括微笑、肤色、性别等。自编码器生成具体数值潜在特征,目的是生成更近似输入的图像特征。概率分布采样特征值范 围,生成图像的潜在特征表示解码器生成图像。
说白了,作用与上文中的Unet 类似,提取图像的特征降维,从而减少计算量。而在潜在扩散模型的推理生成过程中我们只需用到VAE的解码器部分。
4.总述
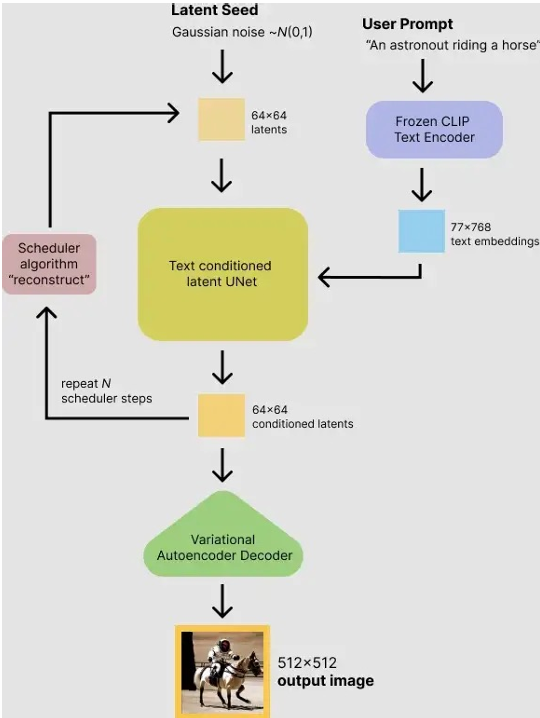
让我们从头到尾串起来。
首先,用户输入提示词。比如,提示词是:骑着马的宇航员。我设定Transformer的最大长度为77,词向量维度是768,那么Clip层的输出就是:
骑 着 马 的 宇 航 员 -> 1, 77, 768 维度的数据
其次,生成一个随机噪声图像数据,假定为64×64的尺寸。这里使用高斯噪声,我们可以任意定义一个种子seed ,用来生成不同的噪声数据。生成完噪声图像数据之后,把改噪声与词向量数据一起输入到Unet 中,其中词向量数据通过交叉注意力机制充分作用到Unet 的多层多位置,通过调度器Scheduler的算法进行去噪,并且把这句话的操作重复进行个时间步。
最终,使用VAE的解码器部分把去噪完的特征图片数据放大,变为正常尺寸512×512。
Stable Diffusion下载及使用
import os
import random
import torch
import asyncio
from diffusers import StableDiffusionXLPipeline
from googletrans import Translator
# ===== 翻译函数 =====
def translate_to_en(text: str) -> str:
try:
return Translator().translate(text, dest="en").text
except:
return text
# ===== 主程序 =====
async def main():
MODEL_ID = "stabilityai/stable-diffusion-xl-base-1.0"
CACHE_DIR = "D:/PythonProject/Pytorch/models/SDXL"
OUTPUT_DIR = r"D:\PythonProject\Pytorch\StableDiffusion\output_images"
OUTPUT_FILE = "girl.png"
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
chinese_prompt = "赛博朋克主题,一个女孩坐在楼顶望着远方的城市,动漫风"
negative_prompt = """
low quality, worst quality, lowres, blurry, out of focus,
bad anatomy, bad proportions, deformed,
extra fingers, missing fingers, fused fingers,
extra limbs, missing limbs,
asymmetrical face, distorted face, bad hands,
wrong perspective, incorrect viewpoint,
overexposed, underexposed,
text, watermark, logo,
anime, cartoon, 3d render, plastic skin, uncanny
"""
# ✅ 翻译
prompt = translate_to_en(chinese_prompt)
print("Translated prompt:", prompt)
pipe = StableDiffusionXLPipeline.from_pretrained(
MODEL_ID,
cache_dir=CACHE_DIR,
torch_dtype=dtype,
use_safetensors=True,
variant="fp16" if dtype == torch.float16 else None,
)
pipe.to(device)
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()
with torch.no_grad():
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
height=1024,
width=1024,
num_inference_steps=30,
guidance_scale=6.0,
generator=torch.Generator(device).manual_seed(random.randint(0, 2 ** 32 - 1)),
).images[0]
os.makedirs(OUTPUT_DIR, exist_ok=True)
image.save(os.path.join(OUTPUT_DIR, OUTPUT_FILE))
print("✅ Saved", OUTPUT_FILE)
# ===== 入口 =====
if __name__ == "__main__":
asyncio.run(main())使用以上代码,第一次可以从网上(国外)下载对应的模型文件,下载完之后运行就是直接使用模型进行图像生成了。支持使用中文输入,使用谷歌翻译为英文提示词进行推理。
参数说明:
MODEL_ID 下载后的模型文件名称,下载完后不要再改避免后面使用时又下
CACHE_DIR 下载后的缓存文件夹,同上不要改
OUTPUT_DIR 生成图片的文件夹
OUTPUT_FILE 生成图片的文件名
chinese_prompt 中文提示词
negative_prompt 负面提示词,告诉模型生成的图片不该怎么样以上代码下载的是SD XL版本,便于生成大尺寸图像,不过8GB显存跑就已经很吃力了,更不用说LoRA的训练什么的。也可以下载最基础的:
MODEL_ID = "model/stable-diffusion-v1-5"LoRA 是一种风格强化,训练的数据集要求规模小,训练时间短,模型文件小只作用于Unet 。由于我的电脑就是8GB,就只能训练基础版本的LoRA ,所以就没有SD XL 版本的训练代码了,不过应该也是差不多的。以下是基础版的LoRA训练代码:
import os
import numpy as np
import torch
from pathlib import Path
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from diffusers import (
StableDiffusionPipeline,
UNet2DConditionModel,
AutoencoderKL,
DDPMScheduler,
)
from transformers import CLIPTextModel, CLIPTokenizer
from peft import LoraConfig, get_peft_model
from diffusers.optimization import get_scheduler
from tqdm.auto import tqdm
# ========================
# 配置区(科比 LoRA)
# ========================
BASE_MODEL_PATH = "models/stable-diffusion-v1-5"
DATASET_PATH = "../data/common/kobe" # ⚠️ 建议英文路径
OUTPUT_DIR = "trained_models/lora_kobe"
# 训练用唯一标识符(非常重要)
PROMPT = "photo of KOBE BRYANT, male basketball player, athletic build, realistic face"
# 训练参数(41 张人物图)
RESOLUTION = 512
BATCH_SIZE = 1
GRADIENT_ACCUMULATION_STEPS = 1
LEARNING_RATE = 1e-5
MAX_TRAIN_STEPS = 700
SAVE_EVERY = 200
TEST_EVERY = 100
SEED = 42
# 测试 prompt
TEST_PROMPT = (
"photo of KOBE BRYANT wearing purple and gold jersey, "
"dunking a basketball, intense expression, NBA arena, "
"photorealistic, 8k"
)
NEGATIVE_PROMPT = (
"text, words, signature, blurry, deformed, bad anatomy, "
"cartoon, extra fingers, fused hands, low quality, jpeg artifacts, another person"
)
# 设备
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(SEED)
if device == "cuda":
torch.backends.cudnn.benchmark = True
# ========================
# 数据集
# ========================
class ImageDataset(Dataset):
def __init__(self, root_dir, size=512):
self.root_dir = Path(root_dir)
self.size = size
self.image_paths = [
p for p in self.root_dir.rglob("*")
if p.suffix.lower() in [".jpg", ".jpeg", ".png"]
]
if not self.image_paths:
raise ValueError(f"No images found in {root_dir}")
self.prompt = PROMPT
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
try:
image = Image.open(img_path).convert("RGB")
except Exception as e:
print(f"Warning: corrupted image {img_path}: {e}")
image = Image.new("RGB", (self.size, self.size), (128, 128, 128))
image = image.resize((self.size, self.size), Image.BICUBIC)
image = torch.tensor(np.array(image)).permute(2, 0, 1).float() / 255.0
image = image * 2 - 1 # [-1, 1]
return {
"pixel_values": image,
"prompt": self.prompt
}
# ========================
# 加载模型
# ========================
print("Loading models...")
tokenizer = CLIPTokenizer.from_pretrained(
BASE_MODEL_PATH, subfolder="tokenizer"
)
text_encoder = CLIPTextModel.from_pretrained(
BASE_MODEL_PATH,
subfolder="text_encoder",
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
).to(device)
# ❗冻结 text encoder
text_encoder.requires_grad_(False)
text_encoder.eval()
vae = AutoencoderKL.from_pretrained(
BASE_MODEL_PATH,
subfolder="vae",
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
).to(device)
vae.requires_grad_(False)
unet = UNet2DConditionModel.from_pretrained(
BASE_MODEL_PATH,
subfolder="unet",
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
).to(device)
# ========================
# LoRA 注入(人物建议 r=16)
# ========================
lora_config = LoraConfig(
r=16,
lora_alpha=16,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out.0"],
)
unet = get_peft_model(unet, lora_config)
unet.print_trainable_parameters()
optimizer = torch.optim.AdamW(unet.parameters(), lr=LEARNING_RATE)
# ========================
# 数据 & scheduler
# ========================
dataset = ImageDataset(DATASET_PATH, size=RESOLUTION)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
noise_scheduler = DDPMScheduler.from_pretrained(
BASE_MODEL_PATH, subfolder="scheduler"
)
lr_scheduler = get_scheduler(
"constant",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=MAX_TRAIN_STEPS,
)
# ========================
# 测试 pipeline(共享 UNet,但 eval 时用)
# ========================
print("Creating test pipeline...")
test_pipe = StableDiffusionPipeline.from_pretrained(
BASE_MODEL_PATH,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
safety_checker=None,
feature_extractor=None,
requires_safety_checker=False,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
).to(device)
# ========================
# 训练循环
# ========================
print(f"Start training on {device}...")
os.makedirs(os.path.join(OUTPUT_DIR, "test_images"), exist_ok=True)
unet.train()
global_step = 0
for epoch in range(9999):
for batch in tqdm(dataloader, desc=f"Epoch {epoch}"):
if global_step >= MAX_TRAIN_STEPS:
break
pixel_values = batch["pixel_values"].to(
device, dtype=torch.float16 if device == "cuda" else torch.float32
)
# ---- VAE encode ----
latents = vae.encode(pixel_values).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# ---- 正确加噪 ----
noise = torch.randn_like(latents)
timesteps = torch.randint(
0,
noise_scheduler.config.num_train_timesteps,
(latents.shape[0],),
device=device,
).long()
noisy_latents = noise_scheduler.add_noise(
latents, noise, timesteps
)
# ---- Text encode ----
text_input = tokenizer(
batch["prompt"],
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
).input_ids.to(device)
with torch.no_grad():
encoder_hidden_states = text_encoder(text_input)[0]
# ---- UNet ----
model_pred = unet(
noisy_latents,
timesteps,
encoder_hidden_states
).sample
loss = torch.nn.functional.mse_loss(
model_pred.float(),
noise.float(),
reduction="mean"
)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
global_step += 1
if global_step % 10 == 0:
print(f"Step {global_step}, Loss: {loss.item():.6f}")
# ---- 保存 LoRA ----
if global_step % SAVE_EVERY == 0:
save_path = os.path.join(OUTPUT_DIR, f"lora_step_{global_step}")
os.makedirs(save_path, exist_ok=True)
unet.save_pretrained(save_path)
print(f"Saved LoRA to {save_path}")
# ---- 测试生成 ----
if global_step % TEST_EVERY == 0:
unet.eval()
with torch.no_grad():
image = test_pipe(
prompt=TEST_PROMPT,
negative_prompt=NEGATIVE_PROMPT,
num_inference_steps=30,
guidance_scale=7.5,
generator=torch.Generator(device).manual_seed(42),
).images[0]
img_path = os.path.join(
OUTPUT_DIR, "test_images", f"test_step_{global_step}.png"
)
image.save(img_path)
print(f"Saved test image to {img_path}")
unet.train()
if global_step >= MAX_TRAIN_STEPS:
break
# ========================
# 最终保存
# ========================
final_path = os.path.join(OUTPUT_DIR, "lora_final")
os.makedirs(final_path, exist_ok=True)
unet.save_pretrained(final_path)
print("\n✅ Training finished!")
print(f"📦 Final LoRA saved to: {final_path}")
print(f"🖼️ Test images in: {os.path.join(OUTPUT_DIR, 'test_images')}")参数说明:
DATASET_PATH 数据集路径,建议英文路径
OUTPUT_DIR 输出LoRA模型文件夹
RESOLUTION 尺寸
BATCH_SIZE 批量,不建议大批量
GRADIENT_ACCUMULATION_STEPS 梯度累积
LEARNING_RATE 学习率
MAX_TRAIN_STEPS 训练步数
SAVE_EVERY 保存LoRA的间隔步数
TEST_EVERY 生成测试的间隔步数
SEED 随机种子【附】训练集批量获取
登录https://pixabay.com/api/docs/获取API_KEY:
import os
import requests
import random
from tqdm import tqdm
from PIL import Image
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
# =========================
# 配置区(只改这里)
# =========================
PIXABAY_API_KEY = "************" # ← 换成你的
SAVE_ROOT = "dataset/cyberpunk_lora"
NUM_IMAGES = 300 # 推荐 200~600
IMAGE_SIZE = 768
SEARCH_QUERY = (
"cyberpunk neon city futuristic night rain street "
"sci fi metropolis"
)
STYLE_TOKEN = "cyberpunk style" # LoRA 关键 token(训练时用)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# =========================
# 创建目录
# =========================
IMG_DIR = os.path.join(SAVE_ROOT, "images")
CAP_DIR = os.path.join(SAVE_ROOT, "captions")
os.makedirs(IMG_DIR, exist_ok=True)
os.makedirs(CAP_DIR, exist_ok=True)
# =========================
# 加载 BLIP(自动 caption)
# =========================
print("🔄 Loading BLIP caption model...")
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained(
"Salesforce/blip-image-captioning-base"
).to(DEVICE)
model.eval()
# =========================
# Pixabay 拉图
# =========================
def fetch_pixabay_images(num_images):
print("🌆 Fetching images from Pixabay...")
images = []
page = 1
while len(images) < num_images:
url = "https://pixabay.com/api/"
params = {
"key": PIXABAY_API_KEY,
"q": SEARCH_QUERY,
"image_type": "photo",
"orientation": "horizontal",
"per_page": 200,
"page": page,
"safesearch": "true",
}
r = requests.get(url, params=params, timeout=30)
r.raise_for_status()
hits = r.json().get("hits", [])
if not hits:
break
for h in hits:
images.append(h["largeImageURL"])
if len(images) >= num_images:
break
page += 1
return images[:num_images]
# =========================
# 生成 caption
# =========================
@torch.no_grad()
def generate_caption(image: Image.Image):
inputs = processor(image, return_tensors="pt").to(DEVICE)
out = model.generate(**inputs, max_length=50)
caption = processor.decode(out[0], skip_special_tokens=True)
# 强制加入风格 token
caption = f"{STYLE_TOKEN}, {caption}"
return caption
# =========================
# 主流程
# =========================
def main():
urls = fetch_pixabay_images(NUM_IMAGES)
print(f"📥 Downloading {len(urls)} images...")
for idx, url in enumerate(tqdm(urls)):
try:
img_id = f"{idx:05d}"
img_path = os.path.join(IMG_DIR, f"{img_id}.jpg")
cap_path = os.path.join(CAP_DIR, f"{img_id}.txt")
r = requests.get(url, timeout=30)
image = Image.open(
requests.get(url, stream=True).raw
).convert("RGB")
image = image.resize((IMAGE_SIZE, IMAGE_SIZE), Image.BICUBIC)
image.save(img_path, quality=95)
caption = generate_caption(image)
with open(cap_path, "w", encoding="utf-8") as f:
f.write(caption)
except Exception as e:
print(f"⚠️ Skipped image {idx}: {e}")
print("\n✅ Dataset ready!")
print(f"📁 Images: {IMG_DIR}")
print(f"📝 Captions: {CAP_DIR}")
print("\n🔥 Example caption:")
print(open(os.path.join(CAP_DIR, "00000.txt"), encoding="utf-8").read())
if __name__ == "__main__":
main()