1、引言
在现代 ARM 处理器中,由于乱序执行、多级缓存以及多核并发 的存在,程序中"看起来按顺序执行"的内存访问,并不一定以相同顺序被系统中其他观察者看到 。
内存屏障(Memory Barrier)正是用于显式约束这种重排行为,以保证程序的正确性和可预测性。
2、ARM32
内存屏障的基本目标
ARM 内存屏障主要解决三类问题:
- 排序(Ordering)
- 限制屏障前后的 Load / Store 重排序,使内存访问顺序可被预测。
- 完成性(Completion)
- 确保屏障之前的内存访问已经真正完成(而不仅仅是"被发出")。
- 上下文同步(Context Synchronization)
- 保证系统状态(如 MMU、TLB、异常向量)的修改对后续指令生效。
基于这三种需求,ARMv6 / ARMv7 定义了三条核心屏障指令:
| 指令 | 关注点 | 典型用途 |
|---|---|---|
| DMB | 排序 | 普通内存、DMA 同步 |
| DSB | 完成性 | MMIO、设备时序 |
| ISB | 上下文 | MMU / TLB / 异常 |
2.1 DMB
Data Memory Barrier(DMB) 用于保证:
在程序顺序上位于 DMB 之前的显式内存访问,在可见性上先于 DMB 之后的内存访问被观察到。
数据访问包括普通的加载操作(load)和存储操作(store),也包括数据高速缓存(data cache)维护指令(因为它也算数据访问指令)
⚠️ 关键点:
- DMB 只约束可见顺序(observed order)
- 不保证写操作已经真正到达目标(即不保证完成)
作用域(option)
DMB 可指定作用域与访问类型,例如:
- SY:全系统(默认)
- OSH / ISH / NSH:不同共享域
- ST:仅约束 store
- ...
典型场景:DMA 描述符
c
dma_wmb(); /* 确保描述符先对 DMA 可见 */
writel(start, host->regs + SD_EMMC_START);这里的 dma_wmb()(dmb oshst)确保:
CPU 对描述符的写入
在 DMA 控制器(通常属于 outer shareable domain)
可见于启动 DMA 之前
👉 不要求写入已经完成,只要求"DMA 能看到正确内容"
c
/* arch/arm/include/asm/barrier.h */
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
#define dma_wmb() dmb(oshst)
/* Linux/drivers/mmc/host/meson-gx-mmc.c */
static void meson_mmc_desc_chain_transfer(struct mmc_host *mmc, u32 cmd_cfg)
{
......
for_each_sg(data->sg, sg, data->sg_count, i) {
unsigned int len = sg_dma_len(sg);
if (data->blocks > 1)
len /= data->blksz;
desc[i].cmd_cfg = cmd_cfg;
desc[i].cmd_cfg |= FIELD_PREP(CMD_CFG_LENGTH_MASK, len);
if (i > 0)
desc[i].cmd_cfg |= CMD_CFG_NO_CMD;
desc[i].cmd_arg = host->cmd->arg;
desc[i].cmd_resp = 0;
desc[i].cmd_data = sg_dma_address(sg);
}
desc[data->sg_count - 1].cmd_cfg |= CMD_CFG_END_OF_CHAIN;
dma_wmb(); /* ensure descriptor is written before kicked */
start = host->descs_dma_addr | START_DESC_BUSY;
writel(start, host->regs + SD_EMMC_START);
} 从上面的代码来看,对于 DMA 描述符 desc 来说,dma_wmb 确保了该指令之前的显示内存访问操作,能够被 outer shareable domain 内的观察者观测到(通常情况下,DMA 控制器属于 "outer shareable domain")。
这里注意,网上很多说法:"DMB 不能确保该屏障之前的数据访问已经执行结束"
我们这里不要去纠结,不管数据访问是否执行结束,只要是 DMB 指定的作用域内,都能看到 DMB 屏障之前的访存操作的结果,记住这一点就可以
2.2 DSB
Data Synchronization Barrier(DSB) 是比 DMB 更强的屏障:
DSB 之后的任何指令,在 DSB 完成之前都不会执行
DSB 完成的条件是:
- 屏障之前的所有显式内存访问 已完成
- 所有缓存 / TLB / 分支预测器维护操作 已完成
下面考虑一个典型场景:连续访问两个 MMIO 寄存器。
ARM 架构中,访问 MMIO 寄存器,从架构层次看,属于内存访问。因为使用 Load / Store 体系访问、受内存类型和内存属性约束
c
writel(ENABLE, REG);
dsb;
writel(START, REG2);这个场景中,只能使用 DSB,而不能使用 DMB。
原因在于:START 信号在硬件语义上依赖 ENABLE 已经真正生效。如果使用 DMB,只能保证当设备观察到 START 这次写操作时,ENABLE 这次写在程序顺序上已经发生;但这并不意味着 ENABLE 已经实际写入到了硬件寄存器。
对 MMIO 而言,"写操作已经被发出"与"写操作已经到达并生效"是两回事。如果 ENABLE 仍滞留在写缓冲或总线中,设备的内部状态仍是不可预测的,此时触发 START,行为就可能出错。
只有在 ENABLE 确实已经写入寄存器、设备状态已经更新之后,START 才具有确定语义。因此,这里必须使用 DSB。
相比之下,普通内存访问并不要求"立即生效"。即使数据尚未真正写入物理内存,只要系统能保证最终可见性,其状态仍然是可预测的,因此通常不需要 DSB 这样的强约束。
Linux 中,ARM 架构下,writel 函数实现如下:
c
#define writel(v,c) ({ __iowmb(); writel_relaxed(v,c); })
#define __iowmb() wmb()
#define wmb() __arm_heavy_mb(st)
#define __arm_heavy_mb(x...) dsb(x) 可以看到,writel 函数中,自带一个 dsb 内存屏障。
2.3 ISB
Instruction Synchronization Barrier(ISB) 用于同步指令执行上下文:
- 清空指令流水线
- 丢弃已预取的指令
- 强制在新上下文下重新取指、译码、执行
ISB 保证什么?
ISB 之前完成的所有"上下文类变更",
对 ISB 之后执行的指令可见
包括但不限于:
- MMU / Cache 开关
- TLB、ASID、分支预测器维护
- SCTLR、VBAR 等系统寄存器修改
此外,ISB 还保证:程序顺序上位于 ISB 之后的所有分支指令,都会基于 ISB 执行后的最新上下文状态,重新参与分支预测 。换句话说,ISB 强制 CPU "忘掉过去已经取过的指令",从一个全新的执行环境重新开始取指和执行,从而确保指令流语义的正确性。
典型示例:开启 MMU
c
MSR SCTLR_EL1 , X0 // 修改 SCTLR,开启 MMU
isb();为什么 必须 用 ISB?
- 修改 SCTLR(如开启 MMU、改变缓存策略):
- 不涉及内存访问
- 改变的是指令执行的解释方式
ISB:确保后续指令按新执行环境解释
👉 没有 ISB,CPU 可能"活在过去"
3、ARM64
ARMv8 在保留 DMB / DSB / ISB 的同时,引入了更细粒度的同步原语:
- Load-Acquire(LDAR)
- Store-Release(STLR)
它们是附着在具体访存指令上的轻量级屏障,用于实现 RCsc(Release Consistency, sequentially consistent)模型。
3.1 Load-Acquire
LDAR 保证:
该加载操作
先于程序顺序上位于其后的所有 Load / Store 被观察到
但对其之前的访问不施加额外约束。
👉 约束方向:向后
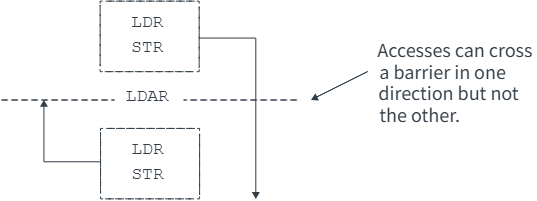
Figure 1. LDAR ordering requirements
3.2 Store-Release
STLR 保证:
程序顺序上位于 STLR 之前的所有 Load / Store 先于该 Store 被观察到
但对其之后的访问不施加约束。
👉 约束方向:向前
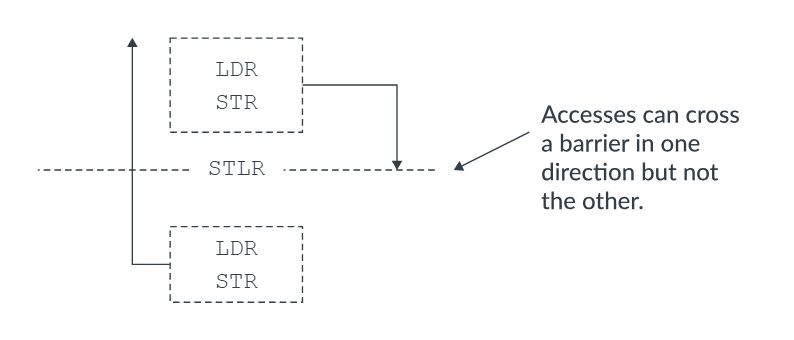
Figure 2. STLR ordering requirements
3.3 对于 Device 类型的内存
此外,对于映射到外设的内存区域(memory-mapped peripheral),当访问的是系统定义的任意大小、且被定义为 Device 类型内存 的区域时,这些指令还具有以下要求:
- 对外设内存区域中某地址执行 Load-Acquire,可确保所有在体系结构上要求在该 Load-Acquire 之后被观测到的、使用 Device 内存类型的对外设的内存访问,将在该 Load-Acquire 的内存访问之后到达该外设。
- 对外设内存区域中某地址执行 Store-Release,可确保所有在体系结构上要求在该 Store-Release 之前被观测到的、使用 Device 内存类型的对外设的内存访问,将在该 Store-Release 的内存访问之前到达该外设。
- 如果某个对外设内存地址的 Load-Acquire 已观测到由 Store-Release 写入该地址的值,那么:
- 所有在体系结构上要求在该 Store-Release 之前发生的对外设的内存访问,
- 将先于所有在体系结构上要求在该 Load-Acquire 之后发生的对外设的内存访问,
- 到达该外设。
当访问 Device 类型内存 时:LDAR / STLR 会保证对外设的访问按体系结构顺序到达。其效果在语义上接近 DSB。
而对普通内存,更接近 DMB
3.4 Release + Acquire:真正的同步
单独的 STLR 或 LDAR 并不会同步线程。
只有当:
- 一个线程用 STLR 写入
- 另一个线程用 LDAR 读到该值
才建立 happens-before 关系。
经典 publish--subscribe 示例
c
T1: T2:
a = 123;
stlr(b, true); if (ldar(b)) {
print(a);
}保证:
- T2 一旦看到 b == true
- 就 必然 看到 a == 123
这正是:
- ARM 架构中的 multi-copy atomic
- RCsc 模型
- 无锁通信的基础
在多处理器系统中,对某一内存位置的写操作具有 multi-copy atomic ,当且仅当同时满足以下两个条件:
- 所有对该同一内存位置的写操作是串行化的(serialized),即:所有观察者(observers)所观测到的这些写操作的顺序是一致的(相同的全局顺序),尽管某些观察者可能并未观测到其中全部的写操作。
- 对某一内存位置的读操作,不会返回某个写操作所写入的值,除非该写操作已被所有观察者观测到。
换言之,一个写入的值只有在其对系统中所有相关观察者都"全局可见"之后,才可能被任何读操作返回。