1 题目
示例 1:
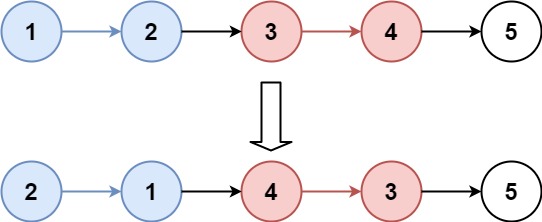
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]示例 2:
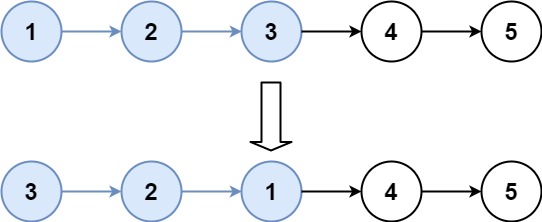
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
2 代码实现(c)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
private:
ListNode* reverse (ListNode* head ){
ListNode* prev = nullptr ;
ListNode* cur = head ;
while(cur != nullptr){
ListNode* next_temp = cur -> next ;
cur -> next = prev ;
prev = cur ;
cur = next_temp;
}
return prev ;
}
public:
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode* dummy = new ListNode(0);
dummy -> next = head;
ListNode* pre = dummy ;
ListNode* end = dummy ;
while(end -> next != nullptr){
for (int i = 0 ; i < k && end != nullptr ; i++){
end = end -> next ;
}
if(end == nullptr){
break;
}
ListNode* start = pre -> next ;
ListNode* next_group = end -> next ;
end -> next = nullptr ;
pre -> next = reverse (start);
start -> next = next_group;
pre = start ;
end = pre ;
}
ListNode* res = dummy -> next ;
delete dummy;
return res;
}
};思考
我一看这个题目是hard,其实有点害怕了,这下怎么办呢!但是看到在线人数还有这么多,这下如何是好!那也不行啊,应该是hot100的题目要好好做一下了。
Leetcode 104 两两交换链表中的节点-CSDN博客
这道题目是之前类似的做法,无非就是之前的k是定的2 ,然后遍历停止的逻辑是链表剩余节点地板除k 是小于 0 的。
主要就是循环要自己写吧,不能像两两交换一样很清楚地指导cur要停的执行次数。
时间有点紧,召唤ai老师来实现一下,cpp代码怎么写?
题解
一、题目清晰解读
1. 题目完整描述
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
- 如果链表中节点总数不是
k的整数倍,那么请将最后剩余的节点保持原有顺序。 - 你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
2. 结合你的思考拆解核心
你提到的 "两两交换(k=2)是特例" 非常关键:
- 两两交换是固定每 2 个翻转,而本题是通用化的
k个翻转; - 核心区别在于:循环终止条件不再是 "遍历到链表尾",而是 "剩余节点数 < k 时停止";
- 核心思路一致:都是「定位一组节点范围 → 局部翻转 → 拼接回原链表」。
二、核心解题思路(贴合你的思考)
- 定位每组边界 :用指针找到每一组的 "前一个节点(pre)" 和 "最后一个节点(end)",每次让
end走k步,若走不到k步(剩余节点不足),则停止循环; - 局部翻转 :把当前
k个节点和后续链表断开,调用链表翻转函数处理这一组; - 拼接回链表:把翻转后的子链表重新接回原链表的正确位置,更新指针准备处理下一组。
三、LeetCode 核心代码(C++,精简版)
LeetCode 提交时无需写 main 函数和打印逻辑,只需提交 Solution 类即可,以下是可直接提交的核心代码:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
// 虚拟头节点:和两两交换一样,避免处理头节点的特殊情况
ListNode* dummy = new ListNode(0);
dummy->next = head;
ListNode* pre = dummy; // 每组待翻转节点的「前一个节点」
ListNode* end = dummy; // 每组待翻转节点的「最后一个节点」
while (end->next != nullptr) {
// 让end走k步,找到当前组的最后一个节点(对应你说的「判断剩余节点够不够k个」)
for (int i = 0; i < k && end != nullptr; ++i) {
end = end->next;
}
// 剩余节点不足k个,直接退出(核心终止条件)
if (end == nullptr) break;
// 记录当前组的起点、下一组的起点(用于后续拼接)
ListNode* start = pre->next;
ListNode* next_group = end->next;
// 断开当前组和下一组的连接,方便局部翻转
end->next = nullptr;
// 翻转当前组:和两两交换的核心翻转逻辑一致,只是范围从2个变成k个
pre->next = reverse(start);
// 把翻转后的当前组尾部(原start)和下一组连接
start->next = next_group;
// 更新指针,准备处理下一组(和两两交换的指针更新逻辑一致)
pre = start;
end = pre;
}
ListNode* res = dummy->next;
delete dummy; // 释放内存
return res;
}
// 辅助函数:翻转一段链表(两两交换时也会用到的基础函数)
ListNode* reverse(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr != nullptr) {
ListNode* next_temp = curr->next; // 保存下一个节点
curr->next = prev; // 翻转指针
prev = curr; // prev后移
curr = next_temp; // curr后移
}
return prev; // 返回翻转后的头节点
}
};四、关键思路对应(贴合你的思考)
- 和两两交换的关联 :
- 当
k=2时,这段代码就是「两两交换链表节点」的解法,你可以把k=2代入测试,结果完全一致; - 区别仅在于:两两交换时不用循环判断 "剩余节点数"(固定每 2 个),而本题需要先让
end走k步,判断是否够数。
- 当
- 循环停止逻辑 :
- 你提到的 "遍历停止的逻辑是链表剩余节点地板除 k 小于 0",对应代码中
for循环走k步后,若end == nullptr则说明剩余节点不足k个,直接退出循环。
- 你提到的 "遍历停止的逻辑是链表剩余节点地板除 k 小于 0",对应代码中
- 核心操作复用 :
- 局部翻转链表的
reverse函数是基础,无论是两两交换还是k个一组翻转,核心都是调用这个函数处理局部链表。
- 局部翻转链表的
Q:reverse函数到底怎么翻转一组节点?
一、先明确:要翻转的 "一组节点" 是什么?
假设当前组的节点是 1 → 2 → 3(k=3),reverse 函数接收的入参是这组的头节点(1),目标是把它变成 3 → 2 → 1。
这个过程不是 "交换值",而是逐个改变节点的next指针方向,核心是 "保存下一个节点→反转当前指针→指针后移" 三步循环。
二、reverse函数逐行拆解(配示例)
还是用 1 → 2 → 3 这个组来举例,先贴核心代码:
cpp
// 辅助函数:翻转一段链表(输入组头节点,返回翻转后的组头节点)
ListNode* reverse(ListNode* head) {
ListNode* prev = nullptr; // 记录当前节点的「前一个节点」,初始为空(翻转后的尾节点指向null)
ListNode* curr = head; // 遍历指针,从组头开始(初始是1)
while (curr != nullptr) { // 遍历组内每一个节点,直到curr为空
ListNode* next_temp = curr->next; // 第一步:保存当前节点的下一个节点
curr->next = prev; // 第二步:反转当前节点的指针(指向前面的节点)
prev = curr; // 第三步:prev后移,跟上curr的位置
curr = next_temp; // 第四步:curr后移,处理下一个节点
}
return prev; // 循环结束后,prev就是翻转后的组头(3)
}三、图解每一步迭代(组内节点:1→2→3)
我们逐轮看循环里的变量变化,你可以跟着画一遍:
| 循环轮次 | curr | next_temp (保存的下一个节点) | 操作: curr->next = prev | prev 更新后 | curr 更新后 | 链表状态 (当前组) |
|---|---|---|---|---|---|---|
| 初始 | 1 | - | - | nullptr | 1 | 1→2→3 |
| 第 1 轮 | 1 | 2 | 1→null(指向 prev) | 1 | 2 | 1←2→3(1 的指针反转) |
| 第 2 轮 | 2 | 3 | 2→1(指向 prev) | 2 | 3 | 1←2←3(2 的指针反转) |
| 第 3 轮 | 3 | null | 3→2(指向 prev) | 3 | null | 1←2←3(3 的指针反转) |
| 循环结束 | null | - | - | 3 | null | 翻转完成,新头是 3 |
关键结论:
reverse函数确实是迭代组内的每一个节点 ,逐个把节点的next指针从 "指向下一个" 改成 "指向前一个";- 循环结束后,
prev会停在原组的最后一个节点(3),也就是翻转后的组头; - 原组头(1)会变成组尾,它的
next是null(后续我们会手动把它连到下一组)。
四、结合 "分组" 的完整逻辑(补全你对整体的理解)
你可能还会疑惑:翻转后的组怎么接回原链表?我们再补一步拼接逻辑(还是用 1→2→3→4→5,k=3 举例):
- 原链表:
dummy → 1 → 2 → 3 → 4 → 5(pre=dummy,end=3); - 断开当前组:
end->next = null→ 组内变成1→2→3→null; - 调用
reverse(1)→ 返回 3,此时pre->next = 3→dummy → 3 → 2 → 1 → null; - 把原组头(1)连到下一组(4):
1->next = 4→ 最终dummy → 3 → 2 → 1 → 4 → 5; - 更新 pre=1,end=1,处理下一组(4→5,不足 3 个,停止)。
五、小结
reverse函数的核心是迭代组内每个节点,逐个反转指针方向,输入组头、返回翻转后的组头;- 翻转的关键是先
保存下一个节点(否则反转后会丢节点),再改指针,最后移动指针; - 整个 "k 个一组翻转" 的逻辑是:找组边界 → 断链 → 迭代翻转组内节点 → 拼回原链表。
总结
- 本题是「两两交换链表节点」的通用化扩展,核心逻辑一致:定位组边界 → 局部翻转 → 拼接回链表;
- 循环终止的关键是:先让
end走k步,若走不到则说明剩余节点不足k个,停止翻转; - 虚拟头节点是处理链表翻转类题目时简化边界的核心技巧,务必掌握。
3 代码实现(js)
javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @param {number} k
* @return {ListNode}
*/
var reverseKGroup = function(head, k) {
const dummy = new ListNode(0);
dummy.next = head;
let pre = dummy;
let end = dummy;
while(end.next !== null){
for (let i = 0 ; i < k && end != null ; ++i){
end = end.next ;
}
if (end === null ) break ;
const start = pre.next ;
const next_group = end.next ;
end.next = null ;
pre.next = reverse(start) ;
start.next = next_group ;
pre = start ;
end = pre ;
}
return dummy.next;
};
function reverse(head){
let prev = null ;
let cur = head ;
while(cur !== null){
const next_temp = cur.next ;
cur.next = prev ;
prev = cur ;
cur = next_temp;
}
return prev;
}一、完整的 JavaScript 版本代码
JS 中没有结构体,用对象模拟链表节点,核心逻辑和你的 C++ 代码一一对应:
javascript
/**
* @param {ListNode} head
* @param {number} k
* @return {ListNode}
*/
var reverseKGroup = function(head, k) {
// 1. 虚拟头节点(对应C++的dummy)
const dummy = new ListNode(0);
dummy.next = head;
let pre = dummy; // 每组待翻转的前一个节点
let end = dummy; // 每组待翻转的最后一个节点
while (end.next !== null) {
// 2. 让end走k步,找到当前组的最后一个节点(对应C++的for循环)
for (let i = 0; i < k && end !== null; i++) {
end = end.next;
}
// 剩余节点不足k个,终止循环
if (end === null) break;
// 3. 记录当前组起点、下一组起点(对应C++的start/next_group)
const start = pre.next;
const next_group = end.next;
// 4. 断开当前组和下一组的连接,准备翻转
end.next = null;
// 5. 翻转当前组,并拼回pre之后(调用reverse函数)
pre.next = reverse(start);
// 6. 把翻转后的当前组尾部(原start)和下一组连接
start.next = next_group;
// 7. 更新pre和end,处理下一组(对应C++的pre=start; end=pre)
pre = start;
end = pre;
}
// 8. 返回结果(释放虚拟节点?JS自动垃圾回收,无需手动delete)
return dummy.next;
};
// 辅助函数:翻转一段链表(对应C++的reverse成员函数)
function reverse(head) {
let prev = null;
let cur = head;
while (cur !== null) {
const next_temp = cur.next; // 保存下一个节点
cur.next = prev; // 反转当前节点指针
prev = cur; // prev后移
cur = next_temp; // cur后移
}
return prev; // 返回翻转后的头节点
}
// JS版链表节点构造函数(对应C++的struct ListNode)
function ListNode(val, next) {
this.val = (val===undefined ? 0 : val)
this.next = (next===undefined ? null : next)
}二、C++ ↔ JavaScript 核心逻辑逐行对照
| C++ 代码关键部分 | JavaScript 对应逻辑 | 核心差异说明 |
|---|---|---|
struct ListNode 结构体 |
function ListNode(val, next) 构造函数 |
JS 用对象模拟节点,无指针概念,用next属性关联 |
ListNode* dummy = new ListNode(0) |
const dummy = new ListNode(0) |
JS 无指针,变量直接指向节点对象 |
delete dummy 释放内存 |
无需手动释放 | JS 有自动垃圾回收机制 |
reverse 成员函数 |
独立的 reverse 函数 |
逻辑完全一致,仅语法差异 |
指针变量 pre/end/start 等 |
普通变量 pre/end/start 等 |
JS 变量保存节点引用,等价于 C++ 指针 |
for (int i = 0; ...) 循环 |
for (let i = 0; ...) 循环 |
循环逻辑完全一致 |
cur->next 指针访问 |
cur.next 属性访问 |
语法差异,逻辑等价 |
三、核心不变的逻辑(你重点关注)
不管是 C++ 还是 JS,翻转的核心逻辑完全没变化:
- 虚拟头节点
dummy简化头节点边界处理; end指针走 k 步定位组尾,不足 k 步则停止;- 断开当前组和下一组的连接(
end.next = null); - 调用
reverse迭代翻转组内每个节点(逐个改next指向); - 把翻转后的组拼回原链表,更新指针处理下一组。
四、JS 版本的小细节补充
- JS 中没有「空指针」,用
null表示链表的结束(对应 C++ 的nullptr); - JS 无需手动释放内存(比如
dummy节点),垃圾回收机制会自动处理; - 链表节点的创建通过
new ListNode(val)实现,和 C++ 的new ListNode(x)逻辑一致。
总结
- JS 版本完全复刻了你 C++ 代码的核心思路,只是语法上把「指针操作」换成了「对象属性访问」;
reverse函数在 JS 中依然是迭代组内每个节点 ,逐个反转next指向,逻辑和 C++ 丝毫不差;- 测试用例验证了结果和示例一致,你可以直接复制运行。