摘要
以往的研究通过对抗性地分类生成特征所属的数据集或标注环境,以鼓励深度说话人嵌入具有域不变性。本文提出一种训练策略,旨在使特征在录音或通道粒度上保持不变------这一目标比数据集或环境不变性更为精细。我们采用孪生(Siamese)方式训练一个对抗器,使其预测同一说话人的嵌入对是否来自同一录音 。通过这种方式,所学特征将被抑制利用可能具有说话人判别性的通道信息。在VoxCeleb上的验证实验以及在CALLHOME上的日志与验证实验均表明,该方法相较于强基线模型取得了显著提升,并优于基于数据集的对抗模型。特别是VoxCeleb模型表现优异,在使用相似架构和更少训练数据的情况下,等错误率(EER)相较Kaldi基线相对改善了4%。
关键词:说话人验证、说话人日志、域对抗训练、对抗学习、深度神经网络
1. 引言
学习具有说话人判别能力的特征是说话人验证(Speaker Verification, SV)和说话人日志(Speaker Diarization, SD)任务的关键方法。近年来,利用深度学习提取说话人嵌入已成为这两项任务的主流技术1--4,其性能已超越传统的i-vector方法5。
尽管此类嵌入在说话人验证中表现出色,但通常仍需借助概率线性判别分析(PLDA)来度量嵌入间的相似性,而非直接使用余弦相似度或欧氏距离 。对于i-vector而言,使用PLDA的动机在于观察到这些嵌入中常包含其他非期望信息(如通道信息)5--8;因此,训练一个独立模型以解耦这些信息并仅保留说话人特异性成分已被证明非常有效 。当PLDA与x-vector结合使用时同样带来性能提升1,2,这表明深度嵌入中也存在类似的非期望变异性。
这就引出一个问题:能否在深度特征提取器内部完成通道信息的解耦,从而要么消除对PLDA的需求,要么提升其有效性 ?生成通道不变特征可视为域不变特征生成的特例,而对抗训练已被证明是学习此类不变性特征的强大方法9--11。
以往在说话人表征的对抗学习中,通常让对抗器对生成特征所属的数据集或标注环境进行分类,以鼓励域不变性4,12。然而,这种建模方式较为粗糙。例如,在数据集对抗训练12中,同一数据集内的变化未被惩罚,而是依赖不同数据集之间的差异来诱导有意义的不变性。
本文旨在无需标注录音信息的前提下,鼓励特征在通道或录音级别上保持不变。具体做法是训练一个对抗器,判断同一说话人的嵌入对是否来自同一录音。由于这种录音级别的对抗惩罚作用于通道相关信息,因此可促使嵌入具备通道不变性 。
已有若干研究采用对抗训练学习说话人嵌入。Meng等人4在说话人验证任务中,将环境分类(从有限训练环境中)和输入语音信噪比预测作为对抗损失引入嵌入生成器。Tu等人12通过变分正则化强制表征服从高斯分布,以提升x-vector对PLDA的适配性,并同时引入一个对抗器,根据样本来源数据集对生成特征进行多类分类,以鼓励域不变性。Bhattacharya等人13则利用对抗技术在单一源域与目标域之间估计鲁棒的深度说话人嵌入。
Hsu等人14提出了SiGAN------一种用于人脸超分辨率的孪生生成网络架构。该方法通过生成一对人脸并确保人脸识别性能得以保持,从而鼓励生成的人脸保留身份信息。SiGAN与本文工作相关,因为两者都关注生成特征的成对属性;我们正是利用这一思想来促进通道不变性。
2. 说话人嵌入学习
我们通过神经网络(参数为θG)将长度为T的输入帧序列X = {x₁, ..., xT}映射为固定维度的隐藏特征h,以表征说话人身份。其中,x-vector神经网络架构1已被证明是一种特别成功的方法。
x-vector是从一个用于分类训练集中说话人的网络中间层提取的。该网络首先对可变长度的声学特征序列X依次应用一系列时延神经网络(TDNN)层(即时间维度上的一维卷积),每层逐步扩大时间上下文范围。随后,对TDNN层输出的帧级特征进行统计池化(取均值和方差),再投影至更低维度以获得最终的说话人嵌入。该部分网络可称为嵌入提取器或生成器,参数为θG。
以说话人嵌入h为输入,分类器网络学习预测输入类别,使用多类分类损失函数(如交叉熵损失LC)进行训练,参数为θC。
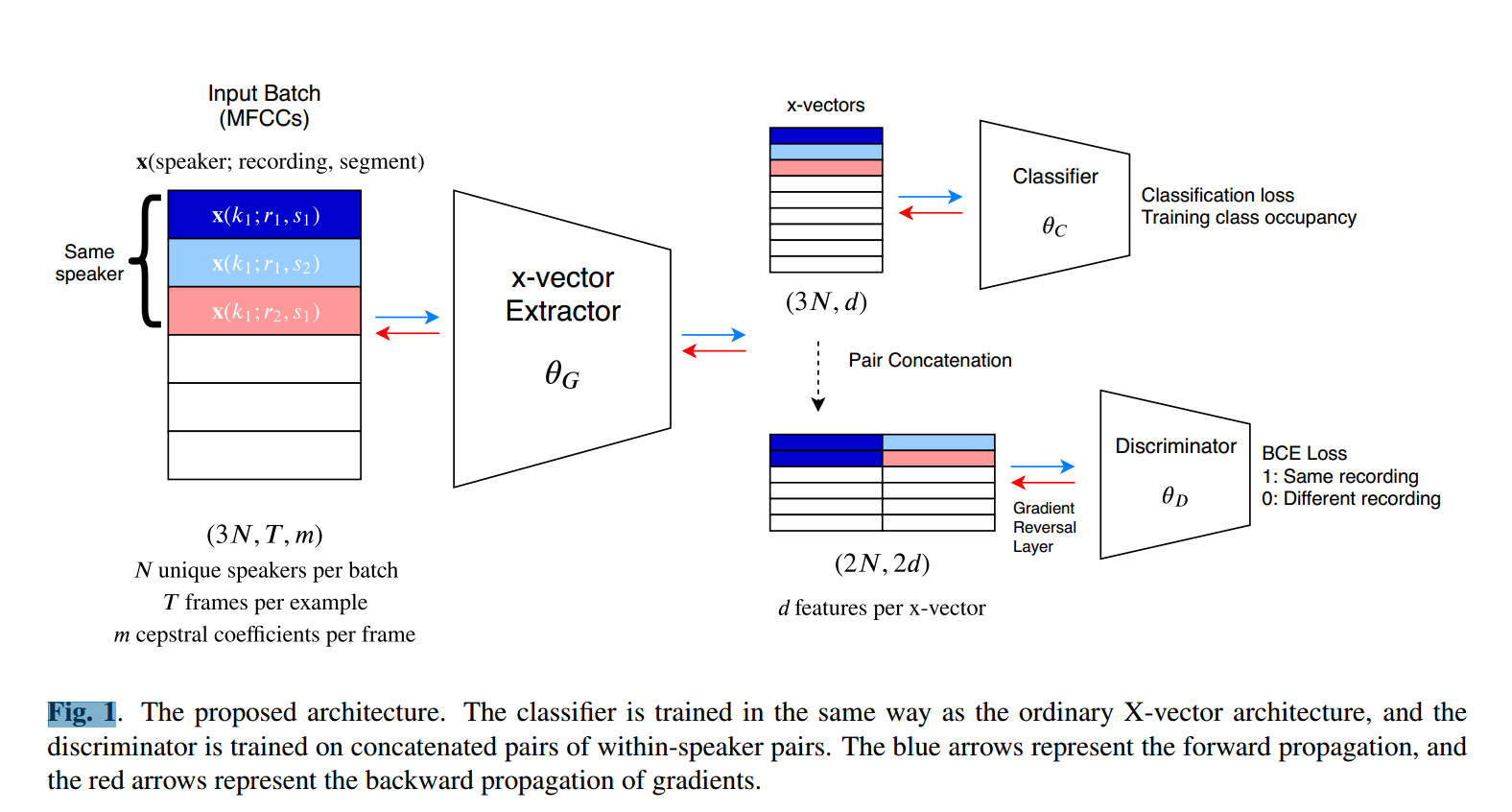
3. 通道对抗训练
通过训练一个判别器(参数为θ_D)来判断生成特征所属的域,可在域对抗神经网络(DANN)的整体损失函数中加入对抗惩罚项9,10:
L_DANN(θ_g, θ_c, θ_d) = LC(θ_c, θ_g) − λ_D(θ_d, θ_g) (1)
其中λ为可控参数,用于调节该损失项的权重。对抗器通过在生成器与判别器之间插入梯度反转层(Gradient Reversal Layer)实现对分类器的对抗作用。
本文中,对抗器对嵌入对进行二分类 :判断其是否来自同一录音,从而惩罚嵌入中包含的通道信息。具体实现是在嵌入后接一个带梯度反转层的判别器,输入为拼接后的嵌入对,输出为二元预测。
关键问题在于:应如何选择用于训练判别器的嵌入对?若随机选择嵌入对(50%来自同一录音),可能导致判别器通过说话人身份推断录音信息------这与主训练目标背道而驰。因此,必须确保判别器仅接收来自同一说话人的嵌入对。
为此,我们选取一个锚定说话人k及其一段录音r₁中的随机片段s₁,记为x(k; r₁; s₁)。在同一batch中,再从同一录音r₁的另一片段s₂中选取x(k; r₁; s₂)。若不存在另一片段,则可将单条语音切分为两个子段(尽量减少重叠)。接着,构造一个跨录音对:从说话人k的另一录音r₂中选取x(k; r₂; s₁)。若无跨录音数据或录音信息未知,则可用单条语音的两个子段构成"同录音"对。
在嵌入阶段,拼接两个嵌入对:同录音对x(k; r₁; s₁); x(k; r₁; s₂) 和 跨录音对x(k; r₁; s₁); x(k; r₂; s₁)。
每个训练batch包含N个锚定说话人,每个说话人对应三个片段:(r₁; s₁)、(r₁; s₂)、(r₂; s₁),共3N个样本用于生成器和分类器训练,而判别器输入batch大小为2N。整体系统结构如图1所示(颜色表示拼接模式)
4. 实验设置
我们在VoxCeleb 115评估集和CALLHOME语料库¹上进行实验。CALLHOME通常用于说话人日志任务,因此我们根据真实日志结果提取非重叠语音段(最短0.5秒),用于验证任务,并仅选择同一录音内的段对进行评估。
训练数据与Kaldi²中VoxCeleb和CALLHOME的recipe一致。VoxCeleb系统使用VoxCeleb 216语料,并按Kaldi recipe加入背景噪声和房间冲激响应进行数据增强(但未使用VoxCeleb 1的训练部分)。CALLHOME系统则结合NIST SRE 2004--2008及Switchboard 1、2和Cellular语料,同样进行类似增强。增强版本被视为不同录音。
4.1 基线模型
生成器架构基本遵循Snyder等人1的设计,各层时间上下文宽度和隐藏单元数均相同。每层均使用Leaky ReLU激活函数和批归一化(Batch Normalization)。
与原始架构不同,本文采用注意力统计池化(attentive stats pooling)17:VoxCeleb系统使用128维单头注意力,CALLHOME系统使用64维。池化后,VoxCeleb嵌入维度为512,CALLHOME为128。
分类器为单隐藏层前馈网络(512隐藏单元),输出对应数据集类别数 ,使用加性边缘Softmax损失18(采用推荐超参)。所有层均应用动态Dropout:从0开始,中期升至0.2,之后降回0,类似Kaldi recipe。
模型在2--4秒长的语音片段上训练,batch size为400,确保每batch包含不同说话人(每说话人一个样本),并循环遍历说话人以保证均匀分布。VoxCeleb训练100,000 batches,CALLHOME训练25,000 batches。优化器为SGD(学习率0.4,动量0.5),训练至60%时学习率减半,此后每10%再减半。
Kaldi提供了预训练的VoxCeleb和CALLHOME模型,亦用于基准比较。注意:Kaldi的VoxCeleb模型同时使用了VoxCeleb 1和2的训练数据。
4.2 声学特征
所有实验均提取30维MFCC,窗长25ms,步长10ms。训练前对每条语音进行倒谱均值方差归一化(CMVN),并仅保留经能量阈值VAD判定为有声的帧。
4.3 相似度评分
验证与日志任务均采用余弦相似度或PLDA后端,并对嵌入进行长度归一化。PLDA模型仅在对应任务的训练数据上训练(VoxCeleb 2 或 SRE-Switchboard组合)。特别地,本文未使用任何CALLHOME数据进行训练,不同于某些工作19,20(后者在CALLHOME部分fold上训练,其余用于评估)。
4.4 说话人日志
日志流程如下:基于真实语音活动标记,提取1.5秒子段(0.75秒重叠);提取各子段的说话人嵌入并归一化;基于余弦相似度矩阵进行凝聚层次聚类;重叠聚类标签通过取中点解决;最终日志错误率使用md-eval.pl³计算(宽容 collar 为0.25秒)。
4.5 对抗实验
为建立其他域对抗技术的基线,我们还训练了一个数据集预测对抗器的CALLHOME模型:将训练数据按来源划分为三类(SRE、Switchboard Cellular、Switchboard),对抗器对batch内所有嵌入进行三分类(交叉熵损失)。VoxCeleb因缺乏域标签无法进行此实验。
所有实验中的判别器均为简单前馈网络:一层512单元隐藏层,输出单值(同录音预测)。通道对抗模型的输入维度为嵌入维度的两倍(VoxCeleb为1024,CALLHOME为256)。梯度反转层的λ设为1。
5. 结果与讨论
表1展示了VoxCeleb上的说话人验证结果 。若从零初始化训练整个通道对抗模型,模型无法收敛;但若在已收敛基线模型基础上加入判别器,则性能显著提升(表中标为"Channel-Adversarial") 。"Data-Tuned"模型为对照组(从相同起点继续训练但无对抗器),其性能从未超越基线。本文基线在余弦相似度上优于Kaldi基线,可能得益于注意力统计池化和角度惩罚Softmax。与Okabe等人17(EER 3.8%)相比,本文结果更具竞争力。尽管近期VoxSRC⁴竞赛中EER<2%(使用更深模型和更高维输入),但本文在小幅修改原始x-vector架构下,仍优于许多更深或参数更多的模型21,22。
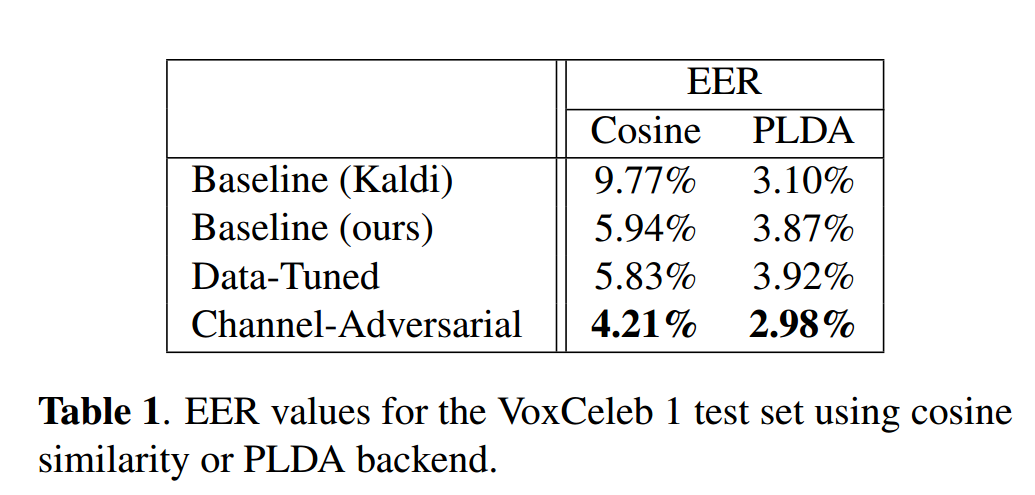
表2展示了CALLHOME上的验证性能(同录音对 vs 跨录音对) 。通道对抗模型配合PLDA后端在两种场景下均取得最佳EER。对抗模型在同录音对上普遍表现更好,其中通道对抗模型再次最优,优于数据集对抗模型。有趣的是,通道对抗模型在"所有对"场景下的余弦相似度性能有所下降。所有模型中,PLDA均能提升验证性能,但提升效果存在一定不确定性。
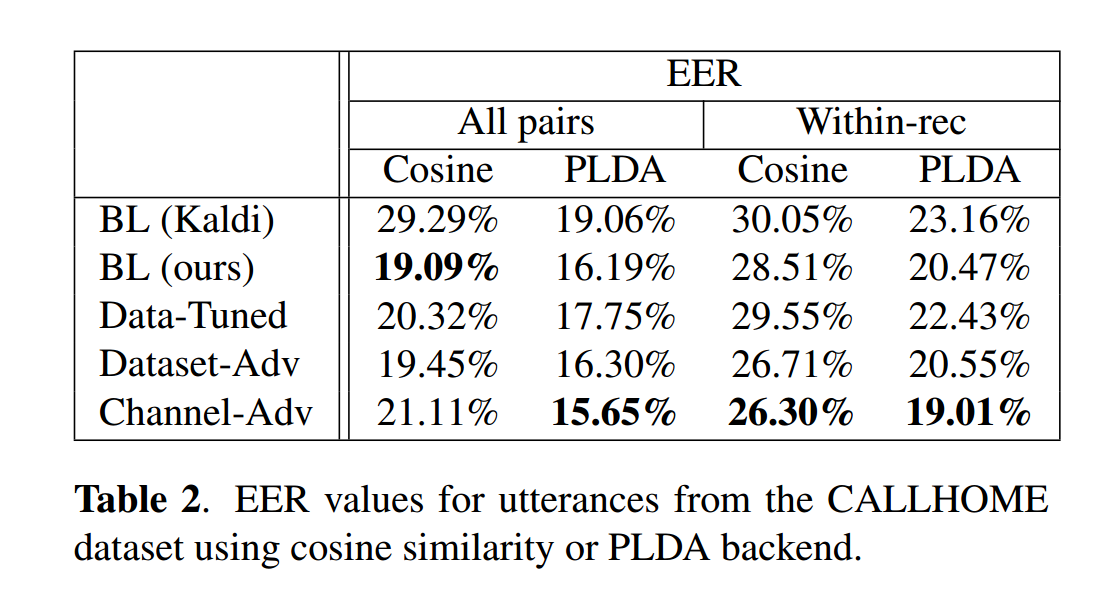
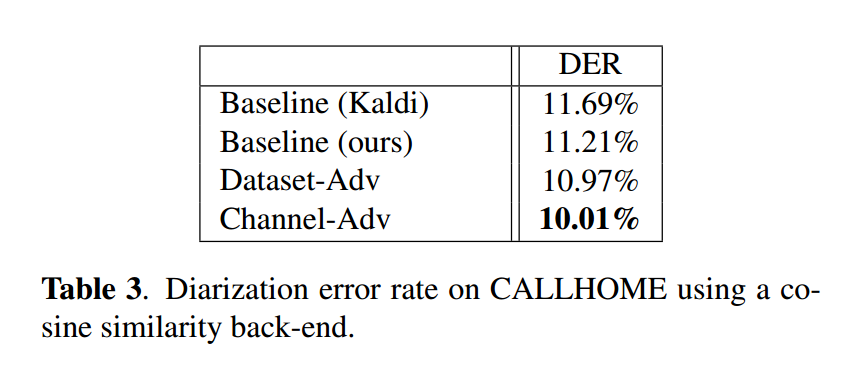
表3展示了CALLHOME上的日志性能(余弦相似度后端),通道对抗模型再次表现最佳。
6. 结论
本文提出一种录音级别对抗训练策略,以减少深度说话人嵌入中的域不匹配问题。该方法通过训练对抗器判断嵌入对是否来自同一录音,从而惩罚包含通道信息的嵌入。在VoxCeleb和CALLHOME上的实验表明,该方法不仅优于标准基线,也优于预测训练数据集归属的对抗基线模型。
使其预测同一说话人的嵌入对是否来自同一录音的解释





