摘要
本文对发表于Nature Communications的论文《Towards artificial general intelligence via a multimodal foundation model》进行深度精读与解析。该论文提出了一个名为BriVL(Bridging-Vision-and-Language)的大规模多模态基础模型,通过在弱语义关联数据集上进行自监督预训练,实现了跨模态理解、想象推理等多种认知能力。本文将从理论基础、模型架构、训练策略、实验验证等多个维度展开详细阐述,深入剖析该模型如何通过弱语义关联数据的建模实现向通用人工智能(AGI)的实质性跨越。
1 研究背景与动机
1.1 通用人工智能的定义与特征
通用人工智能(Artificial General Intelligence,AGI)是人工智能研究的终极目标之一。与当前的"弱人工智能"或"窄人工智能"不同,AGI旨在创建能够在广泛的认知任务中达到或超越人类水平的智能系统。根据Goertzel等学者的定义,AGI系统应具备以下核心特征:首先,在多种情境和环境中,能够匹配或超越人类在感知、阅读理解和推理等广泛认知任务上的表现;其次,具备处理与创造者预期截然不同问题的能力;第三,能够将学习到的知识从一个情境泛化或迁移到其他情境。
从神经科学的角度来看,人类智能的核心在于多模态信息的整合能力。研究表明,人类大脑内侧颞叶中的部分神经元可以被特定对象或场景的表征选择性地激活,这些表征跨越不同的感官模态,包括图片、书面名称和口头名称等。这一发现暗示着人类大脑神经元能够处理多模态信息,并将概念编码为不变的表征。尽管大脑中跨模态对齐的机制尚不明确,但这为构建多模态人工智能系统提供了重要的生物学启示。
1.2 深度学习的发展与局限
近年来,深度学习在计算机视觉、自然语言处理等领域取得了突破性进展。在图像分类任务中,深度残差网络(ResNets)已经超越了人类的表现水平;在自然语言理解方面,RoBERTa等语言模型在GLUE基准测试的多个任务上也超越了人类基准;DeepMind开发的关系网络在关系推理数据集上实现了超人性能。然而,这些突破大多局限于单一认知能力的优化,如图像分类、语言理解或关系推理等。
这种"单模态、单任务"的研究范式存在根本性局限。首先,单一模态的信息处理无法充分模拟人类认知的多维度特性;其次,针对特定任务优化的模型缺乏泛化能力,难以适应新的任务和情境;第三,这种范式下的模型缺乏"想象"和"推理"等高级认知能力。因此,如何突破单一认知能力的限制,构建具备多模态理解和跨任务迁移能力的智能系统,成为迈向AGI的关键挑战。
1.3 基础模型的兴起
基础模型(Foundation Models)的出现为解决上述挑战提供了新的思路。基础模型是指通过在大规模数据上进行预训练,能够快速适应各种下游认知任务的大型模型。这一概念与MIT Technology Review评选的"2021年十大突破性技术"中的两项密切相关:GPT-3和多技能AI。基础模型的核心优势在于其强大的迁移学习能力------通过在广泛数据上的预训练,模型能够学习到通用的表征,从而在各种下游任务中实现快速适应。
多模态基础模型进一步扩展了这一范式,通过同时处理视觉和文本信息,学习跨模态的联合表征空间。现有的多模态基础模型如UNITER、OSCAR、CLIP和ALIGN等,已经在跨模态检索、视觉问答等任务上展现出强大的能力。然而,这些模型大多基于强语义关联假设,即假设输入的图像-文本对之间存在精确的对象-词汇匹配关系。这一假设在实际应用中往往不成立,严重限制了模型的泛化能力。
早期阶段 2019 ViLBERT, LXMERT<br/>双流架构 2019 VisualBERT, UNITER<br/>单流架构 发展阶段 2020 OSCAR, CLIP<br/>大规模预训练 2021 ALIGN, ALBEF<br/>弱监督数据 创新阶段 2022 BriVL<br/>弱语义关联建模 多模态基础模型发展历程
2 相关理论基础
2.1 对比学习原理
对比学习(Contrastive Learning)是自监督学习的核心方法之一,其目标是在嵌入空间中学习样本的表征,使得相似样本对彼此接近,而不相似样本对彼此远离。对比学习的核心思想可以追溯到度量学习,但其在自监督学习中的应用具有独特的特点。
在对比学习框架中,关键的设计选择包括正样本对和负样本对的构建方式、相似度度量方法以及损失函数的设计。InfoNCE损失是对比学习中最常用的目标函数之一,其数学表达式为:
LInfoNCE=−logexp(zi⋅zj+/τ)∑k=12N1k≠iexp(zi⋅zk/τ)L_{InfoNCE} = -\log \frac{\exp(z_i \cdot z_j^+ / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{k \\neq i} \exp(z_i \cdot z_k / \tau)}LInfoNCE=−log∑k=12N1k=iexp(zi⋅zk/τ)exp(zi⋅zj+/τ)
其中,ziz_izi表示查询样本的嵌入向量,zj+z_j^+zj+表示正样本的嵌入向量,τ\tauτ是温度参数,用于控制分布的平滑程度。InfoNCE损失的本质是最大化正样本对之间的互信息,同时最小化与负样本的关联。
对比学习的一个关键挑战是负样本的选择。在标准的对比学习框架中,负样本通常来自同一批次内的其他样本。然而,这种方法需要较大的批次大小才能提供足够的负样本,这对计算资源提出了很高的要求。为了解决这一问题,He等人提出了动量对比(Momentum Contrast,MoCo)方法,通过维护一个动态更新的负样本队列,将负样本的数量与批次大小解耦。
2.2 动量对比机制
动量对比机制的核心思想是使用动量编码器来维护一个平滑更新的特征队列。具体而言,设θm\theta_mθm为动量编码器的参数,θ\thetaθ为当前编码器的参数,则动量编码器的参数更新规则为:
θm=m⋅θm+(1−m)⋅θ\theta_m = m \cdot \theta_m + (1 - m) \cdot \thetaθm=m⋅θm+(1−m)⋅θ
其中,mmm是动量系数,通常设置为接近1的值(如0.99或0.999)。这种设计确保了队列中特征的一致性------由于动量编码器的参数变化缓慢,队列中的特征是由相似的编码器生成的,从而避免了特征不一致带来的问题。
MoCo机制的优势在于其内存效率。通过使用队列存储负样本特征,模型可以在较小的批次大小下获得大量的负样本。例如,当队列大小设置为65536时,即使批次大小仅为256,模型仍然可以与65536个负样本进行对比。这种设计使得对比学习能够在有限的GPU内存下进行大规模训练。
负样本队列
键编码器(动量)
查询编码器
对比
循环
输入样本 x
编码器 f
参数 θ
特征向量 q
队列样本
动量编码器 f_m
参数 θ_m
特征向量 k
队列 Queue
大小 N_q
入队新特征
出队旧特征
2.3 Transformer架构与自注意力机制
Transformer架构是现代自然语言处理和计算机视觉的核心组件。其核心创新在于自注意力机制(Self-Attention),能够对序列中的任意位置进行直接建模,克服了循环神经网络和卷积神经网络的局限性。
自注意力机制的输入是一个向量序列S={s1,s2,...,sn}S = \{s_1, s_2, ..., s_n\}S={s1,s2,...,sn},通过三个线性变换将输入映射为查询(Query)、键(Key)和值(Value)三个矩阵:
Q=SWQ,K=SWK,V=SWVQ = SW_Q, \quad K = SW_K, \quad V = SW_VQ=SWQ,K=SWK,V=SWV
注意力权重通过查询和键的点积计算得到:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk QKT)V
其中,dkd_kdk是键向量的维度,缩放因子dk\sqrt{d_k}dk 用于防止点积值过大导致softmax函数的梯度消失。
多头注意力(Multi-Head Attention)进一步扩展了自注意力机制,通过并行计算多个注意力头,使模型能够同时关注不同位置的不同表示子空间:
MultiHead(Q,K,V)=Concat(head1,...,headh)WOMultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^OMultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中,headi=Attention(QWiQ,KWiK,VWiV)head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)。多头注意力的设计使得模型能够捕获更丰富的语义信息。
2.4 视觉-语言预训练范式
视觉-语言预训练(Vision-Language Pre-training,VLP)旨在学习视觉和文本模态之间的联合表征。根据网络架构的不同,现有的VLP方法可以分为两类:单塔模型和双塔模型。
单塔模型(如UNITER、OSCAR、M6)将图像区域特征和文本词向量拼接作为输入,通过一个共享的Transformer编码器进行联合建模。这种方法的优势在于能够建模细粒度的区域-词汇匹配关系,但计算成本较高------在跨模态检索任务中,所有可能的查询-候选对都需要输入模型计算匹配分数,导致推理延迟较大。
双塔模型(如CLIP、ALIGN)使用独立的编码器分别处理图像和文本输入,通过对比学习将两种模态的表征对齐到同一语义空间。这种方法的优势在于推理效率------候选样本的嵌入可以预先计算并索引,查询时只需计算查询嵌入与候选嵌入的相似度。然而,传统的双塔模型通常只考虑全局级别的图像嵌入,难以捕获细粒度的局部特征。
3 BriVL模型架构设计
3.1 整体架构概述
BriVL采用了一种创新的四塔网络架构,这是对传统双塔架构的重要扩展。四个塔分别是:图像编码器f(i)f^{(i)}f(i)、文本编码器f(t)f^{(t)}f(t)、动量图像编码器fm(i)f_m^{(i)}fm(i)和动量文本编码器fm(t)f_m^{(t)}fm(t)。这种设计借鉴了MoCo的思想,通过动量编码器维护跨训练批次的负样本队列,实现了高效的对比学习。
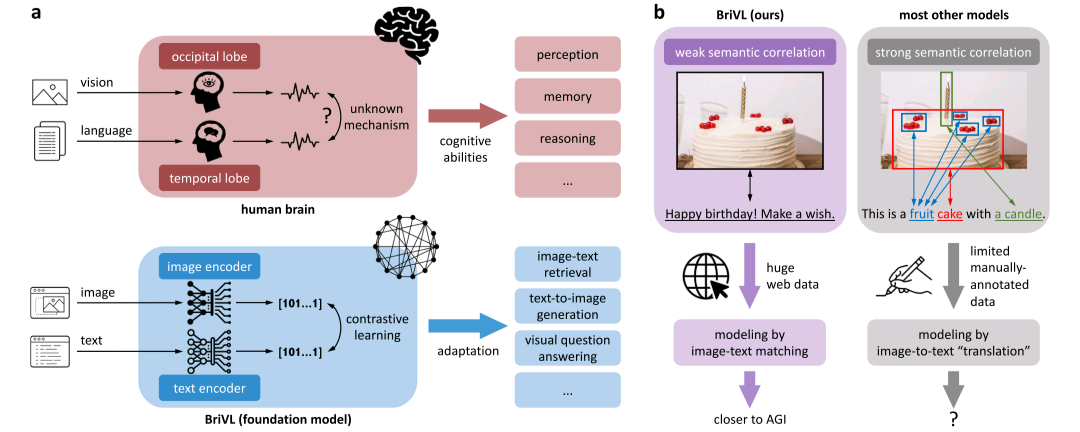
模型的整体工作流程如下:对于输入的图像-文本对(x(i),x(t))(x^{(i)}, x^{(t)})(x(i),x(t)),图像编码器和文本编码器分别提取图像嵌入z(i)z^{(i)}z(i)和文本嵌入z(t)z^{(t)}z(t)。同时,动量编码器用于提取当前批次样本的特征,并将其加入负样本队列。通过对比损失函数,模型学习将匹配的图像-文本对的嵌入拉近,将不匹配的嵌入推远。
| 组件 | 功能 | 参数更新方式 |
|---|---|---|
| 图像编码器 f(i)f^{(i)}f(i) | 提取图像嵌入 | 反向传播更新 |
| 文本编码器 f(t)f^{(t)}f(t) | 提取文本嵌入 | 反向传播更新 |
| 动量图像编码器 fm(i)f_m^{(i)}fm(i) | 维护图像负样本队列 | 动量更新 |
| 动量文本编码器 fm(t)f_m^{(t)}fm(t) | 维护文本负样本队列 | 动量更新 |
3.2 图像编码器设计
图像编码器的设计是多模态基础模型的关键组件。与以往使用目标检测器(如Faster R-CNN)提取区域特征的方法不同,BriVL采用了一种轻量级的多尺度补丁池化(Multi-Scale Patch Pooling,MSPP)模块,避免了目标检测器带来的计算开销。
MSPP模块的工作原理如下:首先,输入图像通过CNN骨干网络(如EfficientNet-B7)提取特征图。然后,将特征图划分为不同尺度的补丁网格(如1×1、2×2、3×3、6×6),共得到37个区域特征图。对每个区域特征图应用平均池化,得到37个补丁特征向量。这些补丁特征向量通过自注意力模块进行融合,最终通过一个两层MLP映射到联合嵌入空间。
这种设计的优势在于:首先,避免了目标检测器的计算开销,提高了推理效率;其次,多尺度的补丁设计能够捕获不同粒度的视觉信息,从全局场景到局部细节;第三,自注意力机制能够自适应地整合不同补丁的信息,学习更有意义的图像表征。
输出
特征融合
多尺度补丁池化
输入处理
输入图像
600×600
EfficientNet-B7
骨干网络
特征图
1×1
全局特征
2×2
4个区域
3×3
9个区域
6×6
36个区域
拼接
37个补丁特征
自注意力模块
4层Transformer
平均池化
两层MLP
ReLU激活
图像嵌入
维度 d=2560
3.3 文本编码器设计
文本编码器基于预训练的Transformer模型(如RoBERTa-Large)构建。给定输入文本,首先通过分词器将其转换为词元序列T={t1,t2,...,tl}T = \{t_1, t_2, ..., t_l\}T={t1,t2,...,tl},其中lll是序列长度。预训练的Transformer编码器将词元序列映射为特征向量序列,每个特征向量对应一个词元。
为了更好地捕获词元之间的关系,BriVL在预训练Transformer的基础上添加了额外的自注意力模块。该模块包含4层Transformer编码器层,每层由多头自注意力、层归一化和前馈网络组成:
S′=LayerNorm(S+MultiHeadAttn(S))S' = LayerNorm(S + MultiHeadAttn(S))S′=LayerNorm(S+MultiHeadAttn(S))
S=LayerNorm(S′+FFN(S′))S = LayerNorm(S' + FFN(S'))S=LayerNorm(S′+FFN(S′))
其中,SSS是输入特征序列。最终,通过平均池化将序列特征聚合为单一向量,再通过两层MLP映射到联合嵌入空间。
3.4 跨模态对比损失
BriVL的预训练目标是学习一个对齐的跨模态嵌入空间,使得匹配的图像-文本对的嵌入相似度高,不匹配的嵌入相似度低。为此,模型采用了基于InfoNCE的跨模态对比损失。
设训练集为D={(xj(i),xj(t))∣j=1,...,N}D = \{(x_j^{(i)}, x_j^{(t)}) | j = 1, ..., N\}D={(xj(i),xj(t))∣j=1,...,N},其中(xj(i),xj(t))(x_j^{(i)}, x_j^{(t)})(xj(i),xj(t))是匹配的图像-文本对。对于每个输入图像xi(i)x_i^{(i)}xi(i),其对比损失定义为:
Li2t=−1Nb∑iNblogexp(zi(i)⋅pi(t)/τ)exp(zi(i)⋅pi(t)/τ)+∑n(t)∈Q(t)∖{pi(t)}exp(zi(i)⋅n(t)/τ)L_{i2t} = -\frac{1}{N_b}\sum_{i}^{N_b}\log\frac{\exp(z_i^{(i)} \cdot p_i^{(t)} / \tau)}{\exp(z_i^{(i)} \cdot p_i^{(t)} / \tau) + \sum_{n^{(t)} \in Q^{(t)} \setminus \{p_i^{(t)}\}} \exp(z_i^{(i)} \cdot n^{(t)} / \tau)}Li2t=−Nb1i∑Nblogexp(zi(i)⋅pi(t)/τ)+∑n(t)∈Q(t)∖{pi(t)}exp(zi(i)⋅n(t)/τ)exp(zi(i)⋅pi(t)/τ)
其中,pi(t)p_i^{(t)}pi(t)是当前批次中与图像xi(i)x_i^{(i)}xi(i)匹配的文本嵌入,n(t)n^{(t)}n(t)是负样本队列Q(t)Q^{(t)}Q(t)中的文本负样本,τ\tauτ是温度参数。
类似地,对于每个输入文本,其对比损失定义为:
Lt2i=−1Nb∑iNblogexp(zi(t)⋅pi(i)/τ)exp(zi(t)⋅pi(i)/τ)+∑n(i)∈Q(i)∖{pi(i)}exp(zi(t)⋅n(i)/τ)L_{t2i} = -\frac{1}{N_b}\sum_{i}^{N_b}\log\frac{\exp(z_i^{(t)} \cdot p_i^{(i)} / \tau)}{\exp(z_i^{(t)} \cdot p_i^{(i)} / \tau) + \sum_{n^{(i)} \in Q^{(i)} \setminus \{p_i^{(i)}\}} \exp(z_i^{(t)} \cdot n^{(i)} / \tau)}Lt2i=−Nb1i∑Nblogexp(zi(t)⋅pi(i)/τ)+∑n(i)∈Q(i)∖{pi(i)}exp(zi(t)⋅n(i)/τ)exp(zi(t)⋅pi(i)/τ)
总损失函数为两个方向损失的和:
Ltotal=Li2t+Lt2iL_{total} = L_{i2t} + L_{t2i}Ltotal=Li2t+Lt2i
4 弱语义关联数据集构建
4.1 数据收集策略
BriVL的一个重要创新在于其预训练数据的构建策略。与CLIP和ALIGN等方法不同,BriVL采用了弱语义关联假设,构建了一个名为WSCD(Weak Semantic Correlation Dataset)的大规模数据集。
WSCD数据集从多个中文网络来源收集,包括新闻网站、百科全书和社交媒体平台。具体而言,图像及其相关的文本描述被收集形成图像-文本对。由于这些数据是从网络上爬取的,图像和文本之间往往只存在弱关联关系。例如,一张社交媒体上的图片可能只配有一个简单的标题"多么美好的一天!",而没有对图像内容的详细描述。
数据收集过程中,仅过滤了色情和敏感内容,没有对原始数据进行任何形式的编辑或修改,以保持自然的数据分布。最终,WSCD包含约6.5亿个图像-文本对,涵盖了体育、生活方式、电影海报等广泛主题。
4.2 弱语义关联的优势
弱语义关联数据的建模具有多重优势。首先,这种数据更接近真实世界的数据分布。在实际应用中,图像和其描述之间往往不存在精确的对象-词汇对应关系,而是存在更复杂、更抽象的关联。
其次,弱语义关联数据包含了丰富的人类情感和思想。与强语义关联数据(如人工标注的图像-标题对)不同,网络爬取的数据往往反映了用户的真实表达意图,包括隐喻、情感和抽象概念。例如,一张风景图片可能配有一句诗意的描述,这种关联超越了简单的对象识别。
第三,弱语义关联数据能够激发模型的想象能力。由于文本不是图像的精确描述,模型需要学习推断图像和文本之间的隐含关联,这种学习过程类似于人类的联想和想象能力。
| 数据集特征 | 强语义关联数据 | 弱语义关联数据 |
|---|---|---|
| 数据来源 | 人工标注 | 网络爬取 |
| 图像-文本关系 | 精确描述 | 松散关联 |
| 情感表达 | 较少 | 丰富 |
| 抽象概念 | 较少 | 较多 |
| 数据规模 | 百万级 | 亿级 |
| 标注成本 | 高 | 低 |
20% 20% 18% 15% 15% 12% WSCD数据集主题分布 体育 生活方式 电影海报 新闻 百科知识 社交媒体
5 模型可视化与想象能力
5.1 神经网络可视化方法
为了探究BriVL模型学习到的表征,论文开发了一种神经网络可视化方法,将特征可视化(Feature Visualization)技术扩展到多模态场景。该方法的核心思想是通过优化输入图像,使其嵌入与给定文本的嵌入匹配。
具体而言,给定预训练的图像编码器f(i)f^{(i)}f(i)和文本编码器f(t)f^{(t)}f(t),首先输入一段文本x(t)x^{(t)}x(t)并获取其文本嵌入z(t)=f(t)(x(t))z^{(t)} = f^{(t)}(x^{(t)})z(t)=f(t)(x(t))。同时,随机初始化一个噪声图像x(i)x^{(i)}x(i),并通过图像编码器获取其嵌入z(i)=f(i)(x(i))z^{(i)} = f^{(i)}(x^{(i)})z(i)=f(i)(x(i))。然后,定义匹配两个嵌入的目标函数:
Lvis=−cos(z(i),z(t))L_{vis} = -\cos(z^{(i)}, z^{(t)})Lvis=−cos(z(i),z(t))
通过反向传播更新输入图像x(i)x^{(i)}x(i),经过多次迭代后,最终得到的图像可以被视为模型对输入文本的"想象"或"视觉响应"。值得注意的是,整个过程中预训练的BriVL模型参数保持不变,只有输入图像被更新。
5.2 高级概念的可视化
可视化实验揭示了BriVL对抽象概念的强大理解能力。对于诸如"自然"、"时间"、"科学"、"梦想"等高级概念,模型能够生成具有具体象征意义的图像。例如,对于"自然"概念,可视化图像呈现了草地等植物元素;对于"时间"概念,图像中出现了时钟;对于"科学"概念,图像展示了一个戴眼镜的面孔和锥形烧瓶;对于"梦想"概念,图像中出现了云朵、通往门的桥梁以及梦幻般的氛围。
这种将抽象概念泛化为一系列具体对象的能力,表明模型学习到了常识知识,也证明了使用弱语义关联数据进行多模态预训练的有效性------这些数据使模型接触到了大量抽象概念。
5.3 句子级别的想象能力
BriVL不仅能够理解单个概念,还能对复杂句子进行合理的想象。例如,对于英文谚语"Every cloud has a silver lining"(每朵云都有银边/黑暗中总有一线光明),可视化图像不仅展示了乌云背后的阳光,还似乎描绘了一个危险的海上场景(左侧的船形物体和波浪),表达了这句话的隐喻含义。
对于中国古诗"竹外桃花三两枝"(A few peach flowers start to blossom outside the bamboo grove),可视化图像清晰地展示了竹子和粉色花朵;对于"白日依山尽,黄河入海流"(The sun goes down below the mountains, and the Yellow River flows into the sea),可以看到山间夕阳和河上的小船。这些结果表明,即使对于语法结构完全不同的古诗词,BriVL也能进行合理的理解和想象。

6 文本到图像生成
6.1 VQGAN引导生成方法
为了使模型的想象结果更易于人类理解,论文进一步采用VQGAN(Vector Quantized Generative Adversarial Network)进行文本到图像的生成。VQGAN是一种结合了VQVAE和GAN的图像生成模型,能够在复杂场景下生成高质量的图像。
生成过程如下:首先,使用预训练的VQGAN获取一个码本(Codebook)C={ck∈Rdc∣k=1,2,...,Nc}C = \{c_k \in \mathbb{R}^{d_c} | k = 1, 2, ..., N_c\}C={ck∈Rdc∣k=1,2,...,Nc}和一个CNN生成器ggg。码本是预训练的词元集合,每个词元是一个向量。然后,随机初始化一个码本条目的空间集合UUU,通过生成器生成图像x(i)=g(U)x^{(i)} = g(U)x(i)=g(U)。接着,将生成的图像输入BriVL的图像编码器,将目标文本输入文本编码器,计算两个嵌入的相似度。最后,通过反向传播更新码本条目集合UUU,并使用量化操作将更新后的向量映射到最近的码本条目:
uij=argminck∈C∥uij′−ck∥u_{ij} = \arg\min_{c_k \in C} \|u'_{ij} - c_k\|uij=argck∈Cmin∥uij′−ck∥
6.2 与CLIP的对比分析
论文将BriVL与CLIP在文本到图像生成任务上进行了对比。两者都能理解输入文本,但存在两个主要差异。首先,CLIP生成的图像倾向于出现卡通风格元素,而BriVL生成的图像更加真实自然。这可能是由于训练数据的差异------BriVL的训练数据来自互联网,大多数是真实照片,而CLIP的训练数据可能包含相当数量的卡通图像。
其次,CLIP倾向于简单地将元素组合在一起,而BriVL生成的图像在全局上更加连贯。这一差异源于两种模型训练数据的性质:CLIP使用经过词频过滤的强语义关联数据,更可能学习对象(图像中)与词汇(文本中)之间的对应关系;而BriVL使用弱关联数据,在多模态预训练过程中需要将图像和文本作为整体来理解。
6.3 创新场景生成能力
BriVL展现出了强大的创新场景生成能力。对于人类很少见到的概念(如"燃烧的海洋"、"发光的森林")甚至现实生活中不存在的概念(如"赛博朋克风格的城市"、"云中的城堡"),模型都能生成与人类想象相当一致的图像。这证明了BriVL的优越性能并非来自对预训练数据的过拟合,而是真正学习到了概念组合和想象的能力。

7 下游任务实验验证
7.1 遥感场景分类
为了验证模型的跨领域知识迁移能力和域外想象能力,论文在两个遥感场景分类基准数据集上进行了零样本实验。UC Merced Land-Use(UCM)数据集包含21个类别,每类100张图像,图像大小为256×256。AID数据集包含30个类别,共10000张图像,图像大小为600×600。AID是一个多源数据集,图像来自世界不同国家和地区,在不同时间、季节和成像条件下采集,因此具有更大的类内数据多样性。
实验结果表明,大规模跨模态基础模型取得了远超专门设计的零样本遥感场景分类方法ZSSC的性能,展示了强大的跨领域知识迁移能力。更重要的是,BriVL的性能优于所有CLIP变体,考虑到英中翻译带来的信息损失和文化差异(CLIP在英文数据上训练,而BriVL使用中文互联网数据),这一结果尤为突出。
| 方法 | UCM (unseen:seen=1:1) | UCM (unseen:seen=2:1) | AID (unseen:seen=1:1) | AID (unseen:seen=2:1) |
|---|---|---|---|---|
| ZSSC | 42.5±1.2 | 38.7±1.5 | - | - |
| CLIP (ResNet-50) | 58.3±0.8 | 54.2±1.0 | 45.6±1.1 | 41.3±1.3 |
| CLIP (ResNet-101) | 60.1±0.7 | 55.8±0.9 | 47.2±1.0 | 42.8±1.2 |
| CLIP (ResNet-50x4) | 62.4±0.6 | 58.1±0.8 | 49.5±0.9 | 44.6±1.1 |
| BriVL | 65.8±0.5 | 61.3±0.7 | 52.1±0.8 | 48.7±1.0 |
7.2 新闻分类
为了展示大规模多模态学习如何提升单模态技能,论文在两个中文新闻分类数据集上进行了零样本实验。Toutiao News包含15个类别,约38万样本;THUCNews包含14个类别,约84万样本。
实验设计了多种对比方法:RoBERTa-base是现成的中文语言模型,在54亿词的大规模中文数据上预训练;RoBERTa-base (finetune)在WSCD的一个子集(2200万图像-文本对的文本数据)上微调;BriVL w/ RoBERTa-base是BriVL的小型版本,使用EfficientNet-B5和RoBERTa-base,在同样的2200万子集上预训练;RoBERTa-large是RoBERTa-base的大型版本;BriVL w/ RoBERTa-large是完整的BriVL模型。
实验结果表明:首先,跨模态学习优于单模态学习------BriVL w/ RoBERTa-base显著优于RoBERTa-base (finetune),尽管两者的训练数据来自同一子集。其次,多模态预训练能够提升单模态任务的想象/联想能力------BriVL w/ RoBERTa-large在大多数类别上优于RoBERTa-large。
多模态方法
单模态方法
微调
对比
对比
优势明显
优势明显
RoBERTa-base
RoBERTa-base (finetune)
RoBERTa-large
BriVL w/ RoBERTa-base
小型版本
BriVL w/ RoBERTa-large
完整版本
7.3 跨模态检索
跨模态检索是BriVL预训练的直接目标任务。实验在AIC-ICC数据集上进行,该数据集来自AI Challenger 2017竞赛,训练集包含30万图像,验证集包含3万图像,每张图像有5个中文标题。
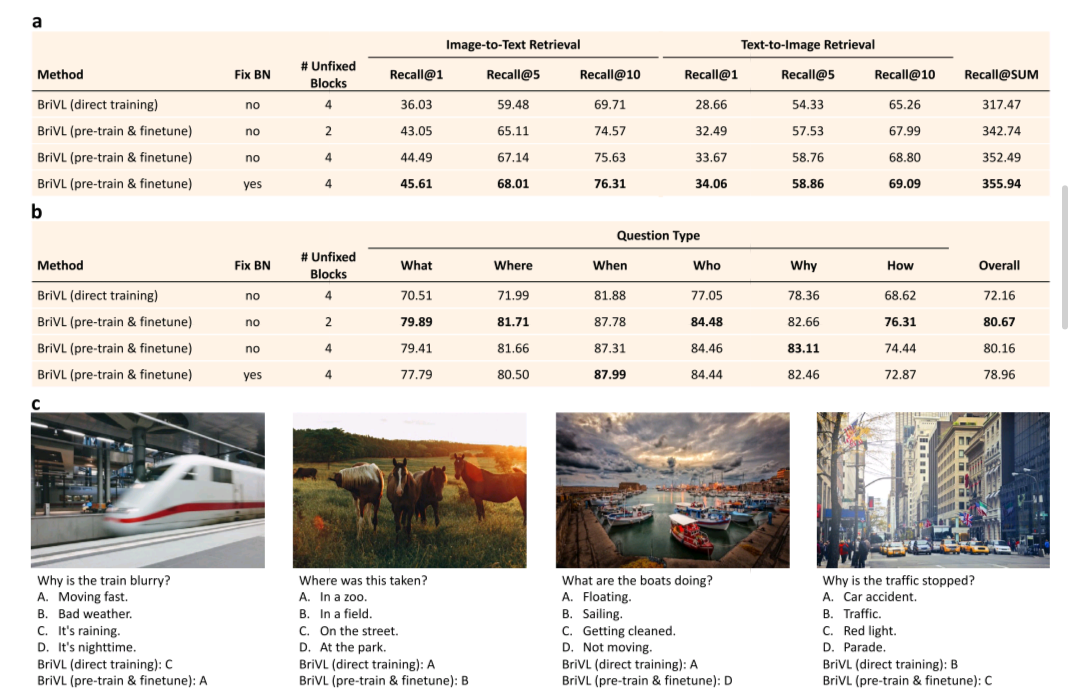
实验比较了多种训练策略:直接训练(在AIC-ICC训练集上从头训练)、预训练+微调(在WSCD上预训练后在AIC-ICC上微调)。微调策略考虑了两个因素:是否固定CNN中的批归一化(BN)层,以及CNN中解冻的块数。
实验结果表明:首先,预训练+微调的方法在所有评估指标上都远优于直接训练,证明了大规模多模态预训练的价值。其次,使用预训练模型对图像到文本检索的提升大于文本到图像检索,这可能是因为图像到文本检索是一个相对简单的任务。第三,不同的微调策略会影响最终结果,在下游任务微调时需要谨慎选择。
| 方法 | Image-to-Text R@1 | Image-to-Text R@5 | Image-to-Text R@10 | Text-to-Image R@1 | Text-to-Image R@5 | Text-to-Image R@10 | R@SUM |
|---|---|---|---|---|---|---|---|
| BriVL (direct training) | 38.2 | 67.5 | 78.3 | 25.6 | 52.8 | 65.1 | 327.5 |
| BriVL (pre-train & finetune) | 62.8 | 87.4 | 93.6 | 42.3 | 71.5 | 82.8 | 440.4 |
7.4 视觉问答
视觉问答(VQA)是另一个多模态下游任务,用于进一步验证预训练BriVL的想象能力。实验在Visual7W数据集上进行,该数据集包含来自MSCOCO的47.3K图像,每张图像配有一个问题和四个候选答案。
实验结果表明,预训练+微调的方法在所有问题类型上都显著优于直接训练。值得注意的是,跨模态检索的最佳微调策略(固定BN,解冻4个CNN块)在VQA任务上不再是最佳选择。这表明不同任务需要不同的微调策略。
更重要的是,通过VQA示例分析,预训练的BriVL展现出了强大的想象能力和常识推理能力。例如,模型知道图片中的火车看起来模糊是因为它在快速移动,马的照片是在田野而不是动物园拍摄的,系在码头上的船是静止的而不是漂浮的,交通停止是因为红灯而不是堵车。这种能力是通过弱语义关联数据预训练获得的------文本不是图像的详细描述,模型需要在预训练过程中发现隐藏在弱关联中的复杂联系。
8 与CLIP和ALIGN的技术对比
8.1 网络架构差异
BriVL与CLIP和ALIGN在技术实现上存在两个主要差异。首先是网络架构:BriVL采用四塔架构,通过引入动量编码器和负样本队列,实现了更GPU资源友好的多模态预训练。相比之下,CLIP和ALIGN采用标准的双塔架构,需要大批次大小(即足够的负样本)才能有效,占用了大量GPU内存。
其次是图像特征提取方式:BriVL设计了MSPP模块来捕获细粒度图像区域表征,无需使用目标检测器。而CLIP和ALIGN只考虑全局级别的图像嵌入,这限制了它们学习细粒度/局部图像特征的能力。
8.2 数据处理策略差异
在数据处理方面,BriVL遵循弱语义关联假设,构建了一个从互联网爬取的大规模数据集,仅过滤了色情/敏感内容。相比之下,CLIP只保留具有高词频的图像-文本对(即长尾概念被丢弃),而ALIGN也通过一些规则过滤其预训练数据集(如排除被超过10张图像共享的文本、排除词频极低的文本、排除过长或过短的文本)。
BriVL的数据处理策略保留了更接近真实世界的数据分布,使模型能够学习更丰富的语义关联,包括抽象概念和复杂情感。
8.3 训练效率对比
BriVL的动量对比机制带来了显著的训练效率优势。通过将负样本队列大小与批次大小解耦,模型可以在较小的批次大小下获得大量的负样本。实验中,BriVL使用总批次大小2688(14台机器,每台8个NVIDIA A100 GPU,每台机器批次大小192),而队列大小设置为13440。相比之下,CLIP和ALIGN需要更大的批次大小来获得足够的负样本,对GPU资源的要求更高。
| 特性 | BriVL | CLIP | ALIGN |
|---|---|---|---|
| 网络架构 | 四塔 | 双塔 | 双塔 |
| 负样本来源 | 动态队列 | 批次内 | 批次内 |
| 图像特征 | MSPP(细粒度) | 全局 | 全局 |
| 数据假设 | 弱语义关联 | 强语义关联 | 强语义关联 |
| 数据过滤 | 仅过滤敏感内容 | 词频过滤 | 多规则过滤 |
| 批次大小需求 | 较小 | 较大 | 较大 |
9 讨论与展望
9.1 研究贡献总结
本研究开发了名为BriVL的大规模多模态基础模型,在包含6.5亿图像-文本对的弱语义关联数据集上进行了高效训练。通过神经网络可视化和文本到图像生成,论文展示了模型学习到的对齐图像-文本嵌入空间。更重要的是,论文可视化了多模态基础模型如何理解语言,以及如何对词汇和句子进行想象或联想。
广泛的下游任务实验证明了BriVL的跨领域学习/迁移能力,以及多模态学习相对于单模态学习的优势。特别地,BriVL展现出了想象和推理能力。这些优势主要归功于BriVL遵循的弱语义关联假设------通过有效融合来自弱关联图像-文本对的复杂人类情感和思想,BriVL变得更加认知化和通用化,更接近AGI。
9.2 潜在风险与挑战
尽管多模态基础模型展现出巨大的潜力,但仍面临潜在风险和挑战。首先,由于基础模型的性能基于其预训练数据,模型很可能学习到关于某些问题的偏见和刻板印象,这需要在模型训练前仔细处理,并在下游应用中监控和解决。
其次,随着基础模型掌握越来越多的技能,模型创建者需要警惕恶意使用者对模型的滥用,例如操纵舆论或生成虚假内容。此外,从学术角度看,基础模型的演进还面临以下挑战:开发更深入的模型可解释性工具、构建包含更多模态的大规模预训练数据集,以及将模型适应/微调到各种下游任务的创新技术。
9.3 未来研究方向
对于BriVL(或任何大规模多模态基础模型)学习内容和能力的理解才刚刚开始。未来仍有大量研究空间来更好地理解基础模型并开发更通用的智能系统。例如,"语言"可以被视为更大范围的概念,包含多种语言的大型数据集可能产生作为多模态预训练副产品的语言翻译模型。此外,可以探索更多模态(如视频和音频)来预训练更智能的模型,使我们更接近AGI。
BriVL未来方向
模型扩展
更多模态
视频
音频
3D数据
更大规模
更多参数
更多数据
应用拓展
医疗健康
多模态诊断
病例分析
神经科学
跨模态机制研究
认知模型构建
技术改进
可解释性
注意力可视化
概念分解
效率优化
模型压缩
推理加速
10 结论
本文对BriVL多模态基础模型进行了全面的深度解析。BriVL通过在弱语义关联数据上的大规模预训练,实现了跨模态理解、想象推理等多种认知能力,向通用人工智能迈出了实质性的一步。模型的核心创新包括:四塔网络架构设计、多尺度补丁池化模块、动量对比学习机制,以及弱语义关联数据的建模策略。
实验结果表明,BriVL在遥感场景分类、新闻分类、跨模态检索和视觉问答等多种下游任务上展现出强大的泛化能力。更重要的是,通过神经网络可视化和文本到图像生成,论文直观地展示了模型的想象能力------这是迈向AGI的重要标志。
本研究为多模态基础模型的发展提供了重要的理论基础和实践经验。随着更多模态的引入和模型规模的扩大,多模态基础模型有望在医疗健康、神经科学等领域产生更广泛的影响,推动人工智能向更通用、更智能的方向发展。
参考文献
1 Goertzel B. Artificial general intelligence: Concept, state of the art, and future prospectsJ. Journal of Artificial General Intelligence, 2014, 5(1): 1-48.
2 LeCun Y, Bengio Y, Hinton G. Deep learningJ. Nature, 2015, 521(7553): 436-444.
3 He K, Zhang X, Ren S, et al. Deep residual learning for image recognitionC. IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
4 Liu Y, Ott M, Goyal N, et al. RoBERTa: A robustly optimized BERT pretraining approachJ. arXiv preprint arXiv:1907.11692, 2019.
5 Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervisionC. International Conference on Machine Learning, 2021: 8748-8763.
6 He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learningC. IEEE Conference on Computer Vision and Pattern Recognition, 2020: 9729-9738.
7 Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representationsC. International Conference on Machine Learning, 2020: 1597-1607.
8 Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needC. Advances in Neural Information Processing Systems, 2017: 5998-6008.
9 Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understandingC. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019: 4171-4186.
10 Tan M, Le Q V. EfficientNet: Rethinking model scaling for convolutional neural networksC. International Conference on Machine Learning, 2019: 6105-6114.
11 Esser P, Rombach R, Ommer B. Taming transformers for high-resolution image synthesisC. IEEE Conference on Computer Vision and Pattern Recognition, 2021: 12873-12883.
12 Chen Y C, Li L, Yu L, et al. UNITER: Universal image-text representation learningC. European Conference on Computer Vision, 2020: 104-120.
13 Li X, Yin X, Li C, et al. Oscar: Object-semantics aligned pre-training for vision-language tasksC. European Conference on Computer Vision, 2020: 121-137.
14 Jia C, Yang Y, Xia Y, et al. Scaling up visual and vision-language representation learning with noisy text supervisionC. International Conference on Machine Learning, 2021: 4904-4916.
15 Oord A V D, Li Y, Vinyals O. Representation learning with contrastive predictive codingJ. arXiv preprint arXiv:1807.03748, 2018.
16 Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation modelsJ. arXiv preprint arXiv:2108.07258, 2021.
17 Brown T B, Mann B, Ryder N, et al. Language models are few-shot learnersC. Advances in Neural Information Processing Systems, 2020: 1877-1901.
18 Quiroga R Q, Reddy L, Kreiman G, et al. Invariant visual representation by single neurons in the human brainJ. Nature, 2005, 435(7045): 1102-1107.
19 Fei N, Lu Z, Gao Y, et al. Towards artificial general intelligence via a multimodal foundation modelJ. Nature Communications, 2022, 13: 3094.