摘要
人工智能领域长期面临一个核心困境:通用人工智能(Artificial General Intelligence, AGI)这一概念始终缺乏清晰、可量化的定义标准。随着大语言模型在各类任务上展现出令人瞩目的能力,关于"我们距离AGI还有多远"的讨论愈发激烈,却因缺乏统一的衡量尺度而难以形成共识。本文献精读聚焦于Dan Hendrycks、Dawn Song、Yoshua Bengio等数十位顶尖学者联合发表的开创性论文《A Definition of AGI》,该论文创新性地将心理学领域最具实证基础的Cattell-Horn-Carroll(CHC)认知能力理论引入AI评估体系,构建了一个涵盖十大核心认知领域的量化框架。通过对GPT-4(27%)和GPT-5(57%)的实证评估,该框架不仅揭示了当代AI系统"锯齿状"的能力分布特征,更精准定位了通往AGI道路上的关键瓶颈------尤其是长期记忆存储能力的严重缺失。本文将从理论基础、框架构建、实证分析等多个维度,深入剖析这一里程碑式研究的学术价值与实践意义。
1 引言与研究背景
1.1 AGI定义的困境与挑战
通用人工智能的概念自诞生以来便处于一种尴尬的境地:它既是人工智能研究的终极目标,又是学术界最具争议的话题之一。这种争议的核心在于,AGI的定义始终如同移动的球门------每当AI系统在某个领域取得突破,AGI的标准便随之调整。从国际象棋到围棋,从图像识别到自然语言处理,AI系统一次次征服曾被认为需要人类智慧的任务,而AGI的定义却始终模糊不清。
这种定义的模糊性带来了严重的后果。首先,它阻碍了学术界对AI发展水平的客观评估。当研究者声称某个模型"接近AGI"时,缺乏统一标准使得这一断言难以验证或反驳。其次,模糊的定义助长了不切实际的预期,无论是过度乐观的"AGI即将到来"论调,还是过度悲观的"AGI遥不可及"观点,都缺乏坚实的事实基础。更为重要的是,缺乏清晰的AGI定义使得政策制定者、企业决策者和公众难以准确理解AI技术的真实能力边界,从而可能做出错误的战略决策。
论文开篇便直指这一核心问题:AGI可能成为人类历史上最重要的技术发展,但这个术语本身却令人沮丧地模糊,不断充当着移动的球门角色。随着专门的AI系统掌握了曾被认为需要人类智慧的任务------从数学到艺术------AGI的标准持续变化。这种模糊性助长了无益的争论,阻碍了关于AGI还有多远的讨论,最终模糊了当今AI与AGI之间的差距。
1.2 从模糊到精确:量化框架的必要性
面对AGI定义的困境,论文作者们提出了一个核心观点:我们需要一个全面、可量化的框架来穿透这种模糊性。这个框架的目标是将一个非正式的定义具体化:
AGI是一种能够匹配或超越受过良好教育成年人的认知多样性和熟练度的人工智能。
这一定义强调,通用智能不仅需要在狭窄领域中的专门表现,更需要人类认知所特有的广度(多样性)和深度(熟练度)。然而,如何将这一看似抽象的定义转化为可操作的评估标准?论文给出的答案是:向人类学习。
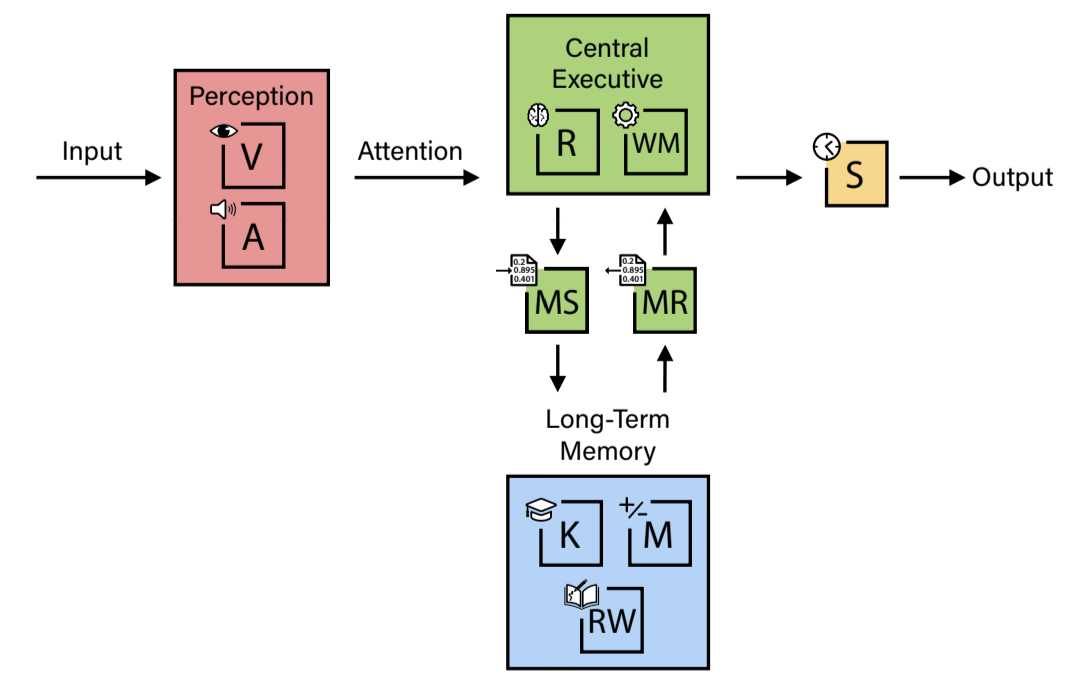
人类认知不是一种单一的能力,而是由进化塑造的复杂架构,包含许多独特的能力。这些能力使人类具有非凡的适应性和对世界的理解。为了系统地研究AI系统是否具备这种能力谱系,论文将方法建立在CHC认知能力理论之上------这是人类智力最经实证验证的模型。
1.3 研究意义与学术贡献
本研究的学术贡献体现在多个层面。在理论层面,它首次系统地将心理学领域成熟的认知能力理论应用于AI评估,建立了跨学科的理论桥梁。在方法论层面,它提供了一个标准化的AGI评分体系(0%至100%),使得不同AI系统的能力比较成为可能。在实践层面,通过对GPT-4和GPT-5的评估,它揭示了当代AI系统的真实能力边界和关键短板。
AGI定义框架
理论基础
CHC认知理论
流体智力与晶体智力
三层认知架构
核心贡献
量化评估体系
十大认知领域
标准化AGI评分
实践价值
揭示能力短板
指导研究方向
政策决策参考
2 CHC认知理论基础
2.1 理论发展历程
Cattell-Horn-Carroll理论是当代心理学领域最具影响力的认知能力理论,其发展历程跨越了近一个世纪的研究积累。理解这一理论的发展脉络,对于把握AGI评估框架的理论根基至关重要。
CHC理论的形成可以追溯到20世纪中叶两位心理学大师的开创性工作。Raymond Cattell于1963年首次提出了流体智力(Fluid Intelligence, Gf)与晶体智力(Crystallized Intelligence, Gc)的区分,这一二元划分奠定了现代智力理论的基础。流体智力指的是解决新颖问题、识别模式、运用逻辑推理的能力,它与先天的神经功能密切相关,倾向于随着年龄增长而下降。晶体智力则代表通过教育和经验积累获得的知识和技能,包括词汇、一般信息和专业领域知识,通常随着年龄增长而保持稳定甚至提升。
John Horn在Cattell工作的基础上进行了扩展,提出了包含更多认知维度的Gf-Gc理论。Horn的研究识别出多达九种不同的认知能力,包括视觉处理、听觉处理、处理速度等,大大丰富了智力理论的结构维度。
John Carroll于1993年发表的里程碑式著作《Human Cognitive Abilities: A Survey of Factor-Analytic Studies》为CHC理论提供了最坚实的实证基础。Carroll对过去半个世纪中超过460组数据进行了再分析,提出了著名的三层认知能力模型(Three-Stratum Model)。在这个模型中,第一层包含数十种狭窄能力(Narrow Abilities),第二层包含约十六种广泛能力(Broad Abilities),第三层则是一般智力因素g。
2.2 三层认知架构详解
CHC理论的三层架构提供了一个从具体到抽象的认知能力分类体系,这一架构对于理解AGI评估框架的设计逻辑具有重要意义。
第三层:一般智力(g因素)
位于金字塔顶端的一般智力因素g代表了个体在所有认知任务上表现的正相关倾向。这一概念最早由Spearman于1904年提出,其核心观察是:在某一认知任务上表现优异的人,往往在其他认知任务上也表现较好。g因素反映了认知能力的总体效率,可以类比为计算机的"处理器性能"。
第二层:广泛能力
CHC理论识别出十六种广泛认知能力,每种能力代表一个相对独立的认知领域。这些能力包括但不限于:
- 流体推理(Gf):解决新颖问题的能力
- 晶体知识(Gc):通过学习获得的知识储备
- 短期记忆(Gwm):在活跃状态下维持和处理信息的能力
- 视觉处理(Gv):感知和分析视觉信息的能力
- 听觉处理(Ga):处理听觉信息的能力
- 处理速度(Gs):快速完成认知任务的能力
- 长期存储与提取(Glr):存储和检索信息的能力
第一层:狭窄能力
每种广泛能力下又包含多种狭窄能力。例如,流体推理(Gf)下包含演绎推理、归纳推理、数量推理等;视觉处理(Gv)下包含空间关系、视觉记忆、闭合速度等。这些狭窄能力代表了认知能力的最精细划分,也是实际测试中最直接的测量对象。
第一层
第二层
第三层
一般智力 (g)
流体推理 (Gf)
晶体知识 (Gc)
工作记忆 (Gwm)
视觉处理 (Gv)
听觉处理 (Ga)
处理速度 (Gs)
长期存储与提取 (Glr)
归纳推理
演绎推理
一般信息
阅读解码
记忆广度
可视化
语音辨别
知觉速度
联想记忆
2.3 CHC理论的实证基础与局限性
CHC理论之所以被选为AGI评估框架的理论基础,关键在于其深厚的实证根基。论文指出,CHC理论主要源于对一个多世纪以来多样化认知能力测试的迭代因素分析的综合。在1990年代至2000年代,几乎所有主要的临床个体智力测试都进行了修订,这些修订或明确或隐含地基于CHC模型的设计蓝图。
这种广泛的实证验证使CHC理论成为心理学领域最可靠的认知能力分类体系。然而,论文也坦诚地指出了该理论的局限性。首先,CHC理论并非穷尽的智力概念化,它有意识地排除了某些能力,如加德纳多元智能理论中提出的动觉能力。其次,该理论主要基于西方教育背景下的测试数据发展而来,其跨文化适用性仍有待进一步验证。
对于AI评估而言,CHC理论提供了一个经过验证的认知能力分类框架,但研究者需要认识到,人类认知与机器智能之间存在本质差异。论文采用CHC框架并非假设AI必须完全复制人类认知结构,而是将其作为一个有用的启发式工具,帮助系统化地评估AI系统的能力谱系。
3 AGI评估框架构建
3.1 从人类认知到AI评估的映射
将CHC理论应用于AI评估需要解决一个核心问题:如何将人类认知测试转化为适用于AI系统的评估任务?论文通过精心的设计,建立了一套完整的映射机制。
首先,论文从CHC理论的十六种广泛能力中选取了十种最核心的认知领域,这些领域被认为代表了受过良好教育成年人应具备的关键认知能力。这十种能力分别是:一般知识(K)、阅读与写作能力(RW)、数学能力(M)、即时推理(R)、工作记忆(WM)、长期记忆存储(MS)、长期记忆提取(MR)、视觉处理(V)、听觉处理(A)和处理速度(S)。
每种广泛能力被赋予10%的权重,总计100%。这种等权重设计反映了对各认知领域相对重要性的不可知论态度------在缺乏充分证据表明某些能力对AGI更为关键的情况下,平等对待各领域是最审慎的选择。
其次,每种广泛能力下又细分为若干狭窄能力,每个狭窄能力对应具体的测试任务。例如,即时推理(R)下包含演绎推理、归纳推理、心理理论、规划和适应五种狭窄能力。这种分层设计使得评估既具有整体性(AGI总分),又具有诊断性(各领域能力剖析)。
3.2 评估方法论设计
论文的评估方法论体现了几个关键原则,这些原则确保了评估的科学性和实用性。
任务导向而非数据集导向
论文明确指出,其定义不是自动评估也不是数据集,而是一系列定义明确的任务集合,用于测试特定的认知能力。AI是否能解决这些任务可以由任何人手动评估,人们可以使用当时最好的评估方法来补充测试。这使得该定义比固定的自动AI能力数据集更广泛、更稳健。
这一设计选择具有重要意义。传统的AI基准测试往往依赖于固定的数据集,这可能导致"数据集污染"问题------模型在训练过程中已经接触过测试数据。而任务导向的方法关注的是能力本身,而非特定数据集上的表现,从而提高了评估的可靠性。
人类水平而非超人聚合
论文强调,其定义关注的是受过良好教育个体经常具备的能力,而非所有受过良好教育个体知识和技能的超人聚合。因此,AGI定义是关于人类水平的AI,而非经济水平的AI;研究测量的是认知能力而非专门的、具有经济价值的专门知识,也不是自动化或经济扩散的直接预测指标。
这一区分至关重要。将AGI定义为"人类水平"而非"超人聚合",使得AGI成为一个可达到的目标,而非一个永远无法企及的理想。同时,这也意味着AGI评估关注的是认知能力本身,而非其在经济活动中的应用价值。
认知能力而非物理能力
论文有意识地聚焦于核心认知能力,而非运动技能或触觉感知等物理能力。这是因为研究旨在测量心智的能力,而非其执行器或传感器的质量。这一选择使得评估框架专注于AI系统的"大脑"功能,而非其"身体"能力。
3.3 评分体系与权重分配
AGI评分体系采用百分制,100%代表达到AGI水平。每种广泛能力贡献10分,各狭窄能力根据其重要性分配不同的分值。
以一般知识(K)为例,该领域总分10分,细分为五个子领域:常识(2%)、科学(2%)、社会科学(2%)、历史(2%)和文化(2%)。每个子领域的评分基于模型在相应测试上的表现。例如,科学领域又细分为物理、化学和生物三个学科,如果模型在一个学科上表现熟练得1%,在两个或以上学科上表现熟练得2%。
这种评分设计既保证了评估的全面性,又提供了足够的灵活性。对于某些能力,如归纳推理,评分还考虑了表现水平------达到第50百分位得1%,达到第90百分位得2%。这种分层评分机制使得评估能够区分"具备基本能力"和"达到熟练水平"。
10% 10% 10% 10% 10% 10% 10% 10% 10% 10% AGI评分权重分布 一般知识 (K) 阅读与写作 (RW) 数学能力 (M) 即时推理 (R) 工作记忆 (WM) 长期记忆存储 (MS) 长期记忆提取 (MR) 视觉处理 (V) 听觉处理 (A) 处理速度 (S)
4 十大认知领域详解
4.1 一般知识(K)
一般知识领域评估的是那些对大多数受过良好教育者而言熟悉或足够重要以至于他们曾接触过的知识。这一领域反映了AI系统的"晶体智力"------通过学习和经验积累获得的知识储备。
常识(2%)
常识是指关于世界如何运作的大量共享的、显而易见的背景知识。这包括直观物理(如"如果将玻璃瓶掉在混凝土地板上,最可能的结果是什么?")、程序性知识(如描述在机场准备登机的典型行动序列)、时间常识(如"制作三明治通常比烤面包需要更长时间吗?")以及常识道德/认知共情(如"如果人们发现一个人为了好玩烧孩子,他们通常会生气吗?")。
测试要求系统在PIQA数据集上的准确率超过85%,在ETHICS常识道德测试上的准确率超过80%。这些测试采用文本输入、文本输出形式,不给予部分分数,且禁用外部工具(如搜索)。
科学知识(2%)
科学知识领域测试对自然科学和物理科学的了解,但不假设具备微积分知识。该领域提供三次展示熟练度的机会:物理、化学和生物。如果模型在一个学科上表现熟练得1%,在两个或以上学科上表现熟练得2%。
物理测试要求在AP物理1和物理2考试中均获得5分;化学测试要求在AP化学考试中获得5分;生物测试要求在AP生物考试中获得5分。AP考试的5分通常对应考生中的第80百分位或更高。
社会科学(2%)
社会科学领域测试对人类行为、社会和制度的理解。该领域提供五次展示熟练度的机会:心理学、微观经济学、宏观经济学、地理和比较政府。评分规则与科学领域相同:一个学科熟练得1%,两个或以上学科熟练得2%。
历史(2%)
历史领域测试对过去事件和物品的知识。该领域涵盖欧洲历史、美国历史、世界历史和艺术历史四个子领域。与科学和社会科学类似,一个领域熟练得1%,两个或以上领域熟练得2%。
文化(2%)
文化领域评估文化素养和意识,分为时事(1%)和流行文化(1%)两部分。时事测试要求了解最近的重要事件和当代议题,允许使用搜索工具。流行文化测试广泛认可的艺术、音乐、文学、媒体和公众人物的知识,涉及文本、音频和视觉多种模态。
4.2 阅读与写作能力(RW)
阅读与写作能力捕捉一个人用于消费和产生书面语言的所有陈述性知识和程序性技能。这一领域与CHC理论中的"阅读与写作(Grw)"广泛能力高度相关。
字母-单词能力(1%)
这是识别字母和解码单词的能力。测试示例包括:哪两个字母完全匹配?door中缺少什么字母?哪个字母朝向正确?raspberry中有几个r?refrigerator有几个音节?tennessee中有几个t?
这些看似简单的任务对于AI系统却可能具有挑战性,因为大语言模型通常在token级别而非字符级别处理文本,这可能导致对单词内部结构的理解困难。
阅读理解(3%)
阅读理解分为三个层次:句子层次(1%)、段落层次(1%)和文档层次(1%)。系统还必须能够判断问题是否由上下文决定不足。
句子层次测试要求可靠地解决Winograd模式,例如在WinoGrande数据集上达到85%以上的准确率。段落层次测试要求在COQA数据集上准确率超过85%,在ReCoRD数据集上准确率超过90%,在LAMBADA数据集上零样本准确率超过80%。文档层次测试要求在LongBench v2上准确率超过55%,同时在Vectara HHEM上的幻觉率低于1%。
写作能力(3%)
写作能力同样分为三个层次:句子层次(1%)、段落层次(1%)和文章层次(1%)。如果模型在GRE分析性写作提示上获得4分或以上(满分6分),则被认为具备写作能力。
英语用法知识(3%)
英语用法知识测试关于英语写作中大小写、标点、用法和拼写方面的知识。分为句子层次(1%)、段落层次(1%)和文档层次(1%)。句子层次要求在语言可接受性语料库上达到60%以上的相关性。
4.3 数学能力(M)
数学能力测试数学知识和技能的深度和广度。这一领域与CHC理论中的"定量知识(Gq)"广泛能力以及数学知识、数学成就和一般序列推理等狭窄能力高度相关。
算术(2%)
算术测试使用四种基本运算对数字进行操作和解决应用题的能力。基础算术占1%,涵盖最多五位数的算术表达式求值;熟练算术占1%,涵盖基本算术应用题的解决。
测试要求在GSM8K数据集上达到95%以上的准确率。GSM8K是一个广泛使用的小学数学应用题数据集,其问题需要多步推理才能解决。
代数(2%)
代数研究符号及其组合规则,用于表达一般关系和求解方程。基础代数占1%,涵盖SAT级别的代数问题;熟练代数占1%,涵盖竞赛级别(MathCounts州/国家级)的代数问题。
测试要求在MATH数据集的代数部分达到90%以上的准确率。MATH数据集包含来自高中数学竞赛的问题,难度显著高于标准课程。
几何(2%)
几何研究形状、空间、大小、位置和距离。基础几何占1%,涵盖SAT级别的几何问题;熟练几何占1%,涵盖竞赛级别的几何问题。
测试要求在MATH数据集的几何部分达到95%以上的准确率。几何问题特别考验空间推理能力,这对于主要基于文本训练的语言模型构成独特挑战。
概率(2%)
概率通过将0到1的数字分配给事件来量化不确定性。基础概率占1%,涵盖SAT级别的概率问题;熟练概率占1%,涵盖大学水平的概率计算。
微积分(2%)
微积分是变化和累积的数学,使用导数求瞬时速率,使用积分计算量的累积。基础微积分占1%,涵盖AP微积分AB的计算问题;熟练微积分占1%,涵盖AP微积分BC和多变量微积分。
4.4 即时推理(R)
即时推理是指有意识但灵活地控制注意力,解决无法仅依靠先前学习的习惯、图式和脚本完成的"即时"新问题的能力。这一领域与CHC理论中的"流体推理(Gf)"广泛能力高度相关。
演绎推理(2%)
演绎推理是从一个或多个一般陈述或前提出发,得出逻辑上必然正确的结论的过程。测试应涵盖分类推理、充分条件推理、必要条件推理、选言推理和联言推理。
测试要求在LogiQA 2.0上达到86%(人类水平)的准确率。LogiQA是一个逻辑推理数据集,其问题需要多步逻辑推导才能解决。
归纳推理(4%)
归纳推理是观察现象并发现决定其行为的潜在原理或规则的能力。论文使用瑞文渐进矩阵(Raven's Progressive Matrices, RPMs)作为主要测试工具。
评分基于与人类群体相比的百分位:低于第50百分位得0%;第50至第90百分位得1%;第90百分位及以上得2%。由于不偏袒任何模态,测试在语言描述(2%)和视觉呈现(2%)两种形式上进行。这与著名的ARC-AGI挑战密切相关。
心理理论(2%)
心理理论是将不可观察的心理状态------如信念、意图和欲望------归因于他人,并理解这些状态可能与自己的不同的能力。
测试要求在FANToM数据集上达到87.5%以上(人类水平)的准确率,在ToMBench上达到85.4%以上(人类水平)的准确率。这些数据集专门设计用于测试AI系统理解他人心理状态的能力。
规划(1%)
规划是通过心理映射从初始状态到期望未来状态的步骤,设计一系列行动以实现特定目标的能力。
测试要求在NaturalPlan数据集上达到90%以上的准确率,在PlanBench BlocksWorld上达到90%以上的准确率。这些数据集测试AI系统在复杂约束条件下制定和执行计划的能力。
适应(1%)
适应是从表现反馈序列中推断未说明的分类规则,并在分类标准毫无预警地改变时灵活放弃该规则并搜索新规则的能力。
测试要求在威斯康星卡片分类测试中少于15个总错误。这个经典神经心理学测试评估认知灵活性和规则切换能力,与ARC-AGI v3挑战相关。
4.5 工作记忆(WM)
工作记忆(常被称为短期记忆)是在活跃注意中维持、操作和更新信息的能力。这一领域与CHC理论中的"工作记忆容量(Gwm)"广泛能力高度相关。
文本工作记忆(2%)
文本工作记忆测试在活跃注意中维持和转换文本信息的能力。分为回忆(1%)和转换序列(1%)两部分。
回忆测试要求记住短序列的元素(数字、字母、单词和无意义词)并回答关于它们的基本问题。转换序列测试要求按照一系列操作(如追加、插入、弹出、删除、切片、排序、反转、并集、交集、差集、逐元素加法、交换位置元素)记住和更新短的数字列表或数字列表。
听觉工作记忆(2%)
听觉工作记忆测试在活跃注意中维持和操作听觉信息的能力,包括语音、声音和音乐。同样分为回忆(1%)和转换序列(1%)两部分。
回忆测试要求记住一组声音、话语和音效,并回答关于它们的基本问题。转换序列测试要求用各种转换(改变发音、改变情感表达、疑问语调、笑、叹气、哼唱、改变音高、改变音色)记住和修改短话语。
视觉工作记忆(4%)
视觉工作记忆测试在活跃注意中维持和操作视觉信息的能力,包括图像、场景、空间布局和视频。分为回忆(1%)、转换序列(1%)、空间导航记忆(1%)和长视频问答(1%)四部分。
空间导航记忆测试要求在环境中表示位置感。测试要求在VSI-Bench上准确率超过80%,在MindCube Tiny上准确率超过90%。长视频问答测试要求观看长视频或电影(最多三小时)并回答关于它的基本问题。
跨模态工作记忆(2%)
跨模态工作记忆测试跨不同模态呈现的信息的维持和修改能力。分为跨模态绑定(1%)和双n-back(1%)两部分。
跨模态绑定测试要求记住跨模态(文本、听觉、视觉)的少量元素对应关系。双n-back测试要求同时监控和更新视觉和听觉的近期信息流,并识别和报告当前每个流中的项目是否与固定步数前呈现的项目匹配。测试要求在双n-back测试(n=2)上达到85%或以上。
4.6 长期记忆存储(MS)
长期记忆存储是从近期经历中稳定获取、巩固和存储新信息的能力。这一领域与CHC理论中的"长期存储(Gl)"广泛能力高度相关。为确保测试的是长期存储而非工作记忆,所有测试必须在与初始信息呈现分开的新会话中进行,且必须禁用外部工具。
联想记忆(4%)
联想记忆是将先前无关的信息片段联系起来的能力。分为跨模态联想(2%)、个性化遵守(1%)和程序联想(1%)三部分。
跨模态联想测试在音频、视觉或文本信息之间形成联想的能力。例如,向AI介绍几个虚构人物,每个都有几个独特的传记细节,在相当于48小时的经历后,询问关于这些人物的问题。
个性化遵守测试将特定规则、偏好或修正与独特的交互上下文(如特定用户、项目或角色)联系起来,并随时间一致地、主动地应用它们的能力。
程序联想测试获取和保留一系列相关步骤或规则(一个程序),并在被程序名称提示时执行它们的能力。
有意义记忆(3%)
有意义记忆是记住叙事和其他形式的语义相关信息的能力。分为故事回忆(1%)、电影回忆(1%)和情景上下文回忆(1%)三部分。
故事回忆测试记住故事要点的能力。电影回忆测试记住电影要点的能力。情景上下文回忆测试记住特定事件或经历的能力,包括其上下文("什么、哪里、何时和如何")。
逐字记忆(3%)
逐字记忆是完全按照呈现的方式回忆信息的能力,需要精确编码特定序列、集合或设计,通常独立于信息的意义。分为短序列回忆(1%)、集合回忆(1%)和设计回忆(1%)三部分。
短序列回忆测试在延迟后精确回忆短文本序列的能力。集合回忆测试回忆一个集合的能力(回忆顺序不重要)。设计回忆测试回忆视觉信息的空间排列和结构的能力。
4.7 长期记忆提取(MR)
长期记忆提取是个体访问长期记忆的流畅性和精确性。这一领域与CHC理论中的"提取流畅性(Gr)"广泛能力高度相关。
提取流畅性(6%)
提取流畅性是基于存储知识快速轻松地产生想法、联想和解决方案的速度和容易程度。分为六个部分:观念流畅性(1%)、表达流畅性(1%)、替代方案流畅性(1%)、词汇流畅性(1%)、命名便利性(1%)和图形流畅性(1%)。
观念流畅性是快速产生与特定条件、类别或对象相关的一系列想法、词汇或短语的能力。表达流畅性是快速想出表达想法的不同方式的能力。替代方案流畅性是快速想出实际问题的几种替代解决方案的能力。词汇流畅性是快速产生共享非语义特征的词汇的能力。命名便利性是快速用名称称呼常见对象的能力。图形流畅性是快速绘制或素描尽可能多的东西的能力。
提取精确性/幻觉(4%)
提取精确性是访问知识的准确性,包括避免虚构(幻觉)的关键能力。测试要求在各种主题(人物、地点、电视节目等)上不产生虚构或幻觉。
测试要求在SimpleQA数据集上(不使用工具)幻觉率低于5%。SimpleQA是一个专门设计用于检测AI系统幻觉的数据集,包含需要精确事实知识的问题。
4.8 视觉处理(V)
视觉处理是分析和生成自然和非自然图像及视频的能力。这一领域与CHC理论中的"视觉处理(Gv)"广泛能力高度相关。
感知(4%)
感知是从图像和视频中处理和解释视觉输入以识别对象和理解场景的能力。提供五次展示熟练度的机会:图像识别、图像描述、图像异常检测、片段描述和视频异常检测。一个任务熟练得2%,所有任务熟练得4%。
图像识别是对常见对象、地点或面部表情的图像进行分类的能力,包括扭曲(如遮挡、噪声、模糊等)图像。测试要求在ImageNet上超过85%,在ImageNet-R上超过90%。
图像异常检测包括检测图像中是否有异常,或对象缺少什么。这些问题不应是推理密集型的。
视频异常检测是检测短视频片段是否异常或不合理的能力。测试要求在IntPhysics2上超过85%,这是直观物理理解的测量。
视觉生成(3%)
视觉生成是合成图像和短视频的能力。测试三种视觉生成能力:生成简单自然图像、复杂图像和简单自然视频。一个任务熟练得1%,两个任务得2%,三个任务得3%。
视觉推理(2%)
视觉推理是使用空间逻辑和视觉抽象理解和做出图像信息逻辑推断的能力。测试多种技能:格式塔推理、心理旋转、心理折叠、具身推理、图表问答以及其他类似技能。所有任务熟练得2%。
测试要求在SPACE(各种视觉推理技能测试)上超过80%,在SpatialViz-Bench(心理旋转和折叠测试)上超过80%,在CharXiv(图表问答测试)上超过80%,在ERQA(具身推理测试)上超过80%,在ClockBench(读时钟指针测试)上超过80%。
空间扫描(1%)
空间扫描是准确调查(视觉探索)宽广或复杂的空间场或具有多个障碍物的模式,并识别目标配置或找到穿过场到达目标端点的路径的能力。测试多种技能:追踪迷宫路径、在图像中找到对象的所有实例、连接点、地图路线分析等。所有任务熟练得1%。
4.9 听觉处理(A)
听觉处理是辨别、记忆、推理和创造性地处理听觉刺激的能力,这些刺激可能由音调和语音单元组成。这一领域与CHC理论中的"听觉处理(Ga)"广泛能力高度相关。
语音编码(1%)
语音编码是清晰地听到音素、将声音混合成词、将词分割成部分、声音或音素的能力。测试采用音频输入、音频输出形式。
语音识别(4%)
语音识别是将口语音频信号转录为相应文本序列的能力。在清晰音频和嘈杂音频(如白噪声、酒吧噪声、多说话者、交通等)上测试。
如果模型能以人类水平或更高的词错误率(WER)转录清晰音频得2%;如果还能以人类水平或更高的WER转录嘈杂音频得4%。测试要求在LibriSpeech test-clean上WER低于5.83%(人类水平)得清晰音频的2%,在LibriSpeech test-other上WER低于12.69%(人类水平)得嘈杂音频的额外2%。
语音(3%)
语音评估AI合成语音的质量和响应性。分为自然语音(2%)和自然对话(1%)两部分。
自然语音测试说出听起来自然而非机器人的句子或段落的能力。自然对话测试在没有长延迟或过度中断的情况下保持对话流畅性的能力。
节奏能力(1%)
节奏能力是识别和保持音乐节拍的能力,包括复制节奏、检测节奏之间的差异以及通过演奏或哼唱同步。
音乐判断(1%)
音乐判断是辨别和判断音乐中简单模式的能力。测试不应需要音乐术语知识。
4.10 处理速度(S)
处理速度是快速完成简单认知任务的能力。这一领域与CHC理论中的"处理速度(Gs)"、"反应和决策速度(Gt)"广泛能力以及较小程度上的"心理运动速度(Gps)"高度相关。
知觉速度-搜索(1%)
知觉速度-搜索是搜索或扫描扩展的文本或视觉场以定位一个或多个简单模式的速度和流畅性。
知觉速度-比较(1%)
知觉速度-比较是在扩展的文本或视觉场中并排或更广泛分离地查找和比较文本或视觉刺激的速度和流畅性。
阅读速度(1%)
阅读速度是在完全理解的情况下阅读文本的速率。通过输入文本token处理速度来衡量阅读速度,可以测量10万token提示的"首个token时间"延迟。
写作速度(1%)
写作速度是生成或复制词汇或句子的速率。通过输出文本token处理速度来衡量写作速度。
数字便利性(1%)
数字便利性是准确执行基本算术或算法操作的速率。
简单反应时间(1%)
简单反应时间是对单一刺激(文本、视觉或听觉)出现的反应时间。
选择反应时间(1%)
选择反应时间是对几种可能刺激中的一种出现的反应时间。
检查时间(1%)
检查时间是感知视觉或听觉刺激之间细微差异的速度。
比较速度(1%)
比较时间是在特定属性上比较两个刺激做出判断的反应时间。
指针流畅性(1%)
指针流畅性是移动计算机鼠标执行简单请求的流畅性。AI可以使用虚拟鼠标完成此任务,就像它使用虚拟键来编写响应一样。
5 实证评估与发现
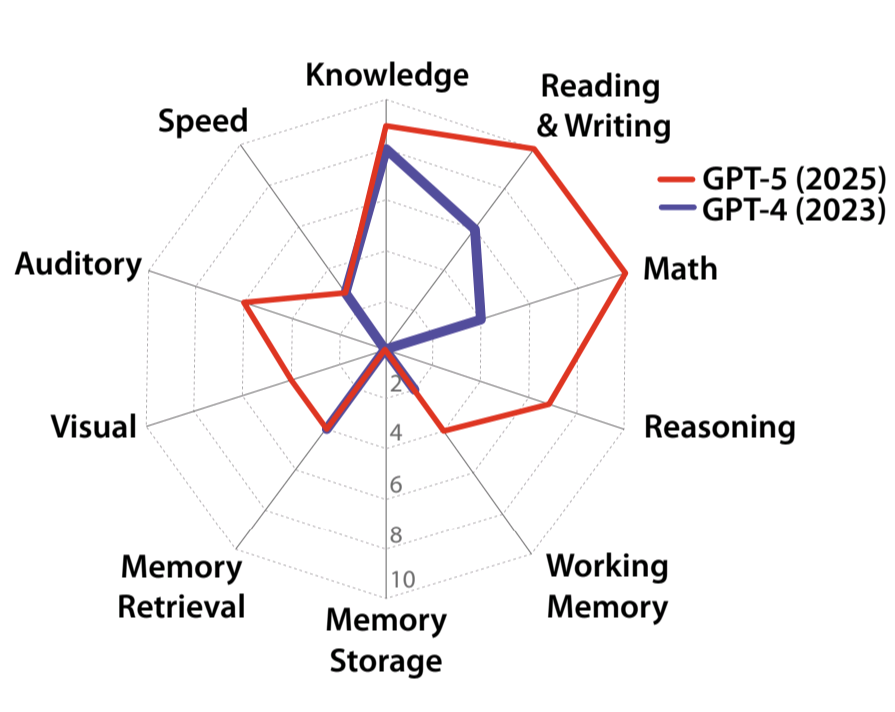
5.1 GPT-4与GPT-5的能力剖析
论文对GPT-4和GPT-5进行了全面评估,结果揭示了一个重要发现:当代AI系统呈现出高度"锯齿状"的认知能力分布。这意味着它们在某些领域表现出色,而在其他领域则存在严重缺陷。
表1:GPT-4与GPT-5 AGI评分对比
| 认知领域 | GPT-4 (2023) | GPT-5 (2025) | 提升幅度 |
|---|---|---|---|
| 一般知识 (K) | 8% | 9% | +1% |
| 阅读与写作 (RW) | 6% | 10% | +4% |
| 数学能力 (M) | 4% | 10% | +6% |
| 即时推理 ® | 0% | 7% | +7% |
| 工作记忆 (WM) | 2% | 4% | +2% |
| 长期记忆存储 (MS) | 0% | 0% | 0% |
| 长期记忆提取 (MR) | 4% | 4% | 0% |
| 视觉处理 (V) | 0% | 4% | +4% |
| 听觉处理 (A) | 0% | 6% | +6% |
| 处理速度 (S) | 3% | 3% | 0% |
| AGI总分 | 27% | 57% | +30% |
从表中可以清晰地看到,GPT-5相比GPT-4取得了显著进步,AGI总分从27%提升至57%,增幅达30个百分点。然而,这种进步并非均匀分布,而是呈现出明显的领域差异。
在数学能力、即时推理和听觉处理领域,GPT-5展现了最显著的进步。数学能力从4%跃升至10%(满分),即时推理从0%提升至7%,听觉处理从0%增长到6%。这些进步反映了GPT-5在推理能力和多模态处理方面的重大突破。
然而,两个关键领域几乎没有任何进展:长期记忆存储(MS)和处理速度(S)。GPT-4和GPT-5在长期记忆存储上均得0%,这揭示了当代AI系统最致命的短板------无法持续学习和存储新信息。
5.2 锯齿状能力分布的深层分析
论文将当代AI系统的能力分布特征描述为"锯齿状"(jagged),这一比喻生动地刻画了AI能力的极端不均衡性。
优势领域:知识密集型任务
GPT-4和GPT-5在知识密集型领域表现出色。一般知识、阅读与写作、数学能力等领域的高分反映了大语言模型的核心优势:通过大规模预训练,模型能够吸收和整合海量知识,并在需要调用这些知识的任务中表现出色。
这种优势源于大语言模型的基本架构。Transformer模型通过自注意力机制能够有效捕捉文本中的长距离依赖关系,而大规模预训练则使模型接触到极其丰富的知识谱系。当任务主要依赖于知识检索和模式匹配时,这些模型能够展现出接近甚至超越人类的表现。
劣势领域:基础认知机制
然而,当任务需要基础认知机制的支持时,AI系统的表现急剧下降。长期记忆存储能力的完全缺失是最突出的例子。人类能够持续学习新信息,将其整合到现有知识体系中,并在需要时检索这些信息。而当前的AI系统每次交互都从零开始,无法积累经验,无法形成持久的记忆。
这种"健忘症"严重限制了AI系统的实用性。在实际应用中,用户不得不每次重新提供上下文,或者依赖超长上下文窗口来临时存储信息。然而,正如论文指出的,这种用工作记忆补偿长期记忆存储缺失的策略是低效的、计算昂贵的,并且最终无法扩展到需要数天或数周累积上下文的任务。
GPT-5能力分布
K: 9%
RW: 10%
M: 10%
R: 7%
WM: 4%
MS: 0%
MR: 4%
V: 4%
A: 6%
S: 3%
GPT-4能力分布
K: 8%
RW: 6%
M: 4%
R: 0%
WM: 2%
MS: 0%
MR: 4%
V: 0%
A: 0%
S: 3%
5.3 能力扭曲与通用性的幻觉
论文提出了一个深刻的概念:"能力扭曲"(capability contortions)。这一概念描述了AI系统如何利用某些领域的优势来补偿其他领域的严重缺陷,从而制造出通用能力的假象。
工作记忆与长期存储的扭曲
最突出的扭曲是用超大上下文窗口(工作记忆)来补偿长期记忆存储的缺失。实践者使用这些长上下文来管理状态和吸收信息(例如整个代码库)。然而,这种方法是低效的、计算昂贵的,并且可能使系统的注意机制过载。它最终无法扩展到需要数天或数周累积上下文的任务。
论文建议,长期记忆系统可能采取模块的形式(例如LoRA适配器),持续调整模型权重以整合经验。这种架构将使AI系统能够真正"学习"而非仅仅"处理"信息。
外部搜索与内部检索的扭曲
长期记忆提取的不精确------表现为幻觉或虚构------通常通过集成外部搜索引擎来缓解。虽然这种方法在许多应用中有效,但它掩盖了模型内部知识检索的根本缺陷。当无法访问外部工具时,模型仍然可能产生自信但错误的回答。
扭曲的误导性
论文警告,将这些扭曲误认为真正的认知广度可能导致对AGI何时到来的不准确评估。这些扭曲也可能误导人们认为智能太过锯齿状而无法系统理解。实际上,锯齿状的能力分布恰恰反映了AI系统在认知架构上的根本缺陷,而非智能本质的不可理解性。
6 引擎类比与认知瓶颈
6.1 智力作为处理器
论文提出了一个富有洞察力的类比:将多面智力比作高性能引擎,整体智力就是"马力"。就像一个引擎最终受限于其最弱的组件,人工心智同样受限于其最薄弱的环节。
这个类比深刻地揭示了AGI评估的核心洞见:即使某些组件高度优化,其他关键部件的严重缺陷也会严重限制系统的整体"马力"。当前,AI"引擎"的几个关键部分高度缺陷,这严重限制了系统的整体性能,无论其他组件多么优化。
AI认知引擎
输入处理
知识模块
效率: 高
读写模块
效率: 高
数学模块
效率: 高
长期记忆存储
效率: 极低 ⚠️
推理模块
效率: 中等
工作记忆
效率: 中等
输出处理
6.2 关键瓶颈识别
通过AGI评估框架,论文精准定位了通往AGI道路上的几个关键瓶颈。
长期记忆存储:最致命的短板
长期记忆存储能力接近0%是当前模型最显著的瓶颈。没有持续学习的能力,AI系统遭受"健忘症"的困扰,这限制了它们的实用性,迫使AI在每次交互中重新学习上下文。
这一瓶颈的根源在于当前大语言模型的基本架构。Transformer模型本质上是无状态的前馈网络,每次推理都是独立的,无法在推理过程中更新模型参数或存储持久信息。虽然可以通过外部记忆机制(如检索增强生成)部分缓解这一问题,但真正的解决方案可能需要根本性的架构创新。
视觉推理:交互能力的限制
视觉推理能力的缺陷限制了AI代理与复杂数字环境交互的能力。虽然GPT-5在视觉处理方面取得了显著进步(从0%提升到4%),但视觉推理(0%)仍然是一个短板。
视觉推理涉及多种技能:格式塔推理、心理旋转、心理折叠、具身推理等。这些能力对于AI系统理解物理世界、与图形界面交互、处理空间信息至关重要。当前模型在这方面的不足反映了视觉-语言多模态学习的挑战。
处理速度:效率的制约
处理速度领域的停滞(GPT-4和GPT-5均为3%)反映了另一个重要瓶颈。虽然模型能够快速阅读和写作,但在多模态处理速度方面仍然缓慢。GPT-5在"思考"模式下通常需要很长时间才能回答,而且几个速度测试需要多模态能力,但GPT-5的多模态能力是缓慢的。
6.3 认知能力的相互依赖
论文强调,虽然框架将智力分解为十个不同的轴进行测量,但认识到这些能力是深度相互依赖的至关重要。复杂的认知任务很少单独使用一个领域。
跨领域能力整合示例
- 解决高级数学问题需要数学能力(M)和即时推理(R)
- 心理理论问题需要即时推理(R)和一般知识(K)
- 图像识别涉及视觉处理(V)和一般知识(K)
- 理解电影需要整合听觉处理(A)、视觉处理(V)和工作记忆(WM)
这种相互依赖性意味着,各种狭窄能力测试实际上是在组合中测试认知能力,反映了通用智力的整合性质。同时,这也意味着某一领域的缺陷可能影响多个相关领域的表现。
表2:认知能力相互依赖关系
| 复杂任务 | 主要能力 | 辅助能力 | 依赖类型 |
|---|---|---|---|
| 数学竞赛 | 数学(M) | 推理® | 串行依赖 |
| 心理理论 | 推理® | 知识(K) | 并行整合 |
| 电影理解 | 视觉(V) | 听觉(A)+记忆(WM) | 多模态融合 |
| 空间导航 | 视觉(V) | 记忆(WM) | 循环交互 |
| 科学推理 | 知识(K) | 推理® | 层次结构 |
7 与现有AGI定义的比较
7.1 图灵测试及其局限
图灵测试是最早的AGI评估方法之一,由Alan Turing于1950年提出。该测试的核心思想是:如果一台机器能够在对话中让人类无法分辨其是机器还是人类,那么这台机器就可以被认为具有智能。
然而,图灵测试存在根本性局限。首先,它只关注对话能力,而忽视了认知能力的其他维度。一个系统可能通过精心设计的对话策略通过图灵测试,却缺乏真正的推理、学习或问题解决能力。其次,图灵测试的标准是主观的------"无法分辨"依赖于人类判断者的能力和期望。最后,图灵测试容易被"欺骗"------通过模仿人类对话模式而非真正理解来通过测试。
论文指出,图灵测试可以指示一般能力,但需要超越图灵测试来捕捉智力的多维性质。CHC框架正是对这一需求的回应,它提供了一个多维度的、可量化的评估体系。
7.2 经济导向定义的问题
近年来,一些组织提出了经济导向的AGI定义。例如,据报道微软和OpenAI将AGI定义为能够产生1000亿美元利润的系统。这种定义将AGI与经济价值直接挂钩,但论文明确反对这种做法。
论文指出,不应将AGI与经济上有价值的AI混淆,因为狭窄技术(如iPhone)可以产生数十亿的经济价值,尽管它们并非通用智能。同时,"替代AI"是关于经济水平的AI,包括物理任务,与AGI不同。
经济导向定义的问题在于,它混淆了"能力"与"价值"。一个系统可能具有极高的经济价值(例如自动化特定行业),却不具备通用智能。反之,一个系统可能具备通用智能,却尚未找到产生巨大经济价值的应用场景。将AGI定义为经济指标,实际上是将科学问题转化为商业问题,这不利于对AI能力的客观评估。
7.3 层级化AGI框架
Morris等人(2023)提出了一个层级化的AGI框架,基于性能百分位定义AGI的不同级别。这一框架将AGI分为多个层次,从"新兴AGI"到"超级AGI",每个层次对应不同的能力水平。
这种层级化方法与CHC框架有相似之处------两者都试图将AGI从二元概念转化为连续谱系。然而,层级化框架仍然依赖于整体性能评估,而非分解为具体的认知能力。这意味着它难以提供诊断性信息,无法指出AI系统的具体短板。
CHC框架的优势在于其细粒度的能力分解。通过将AGI分解为十个认知领域,每个领域又细分为多个狭窄能力,CHC框架能够提供详细的能力剖析,指出具体需要改进的方向。
7.4 本框架的独特贡献
与现有AGI定义相比,CHC框架具有几个独特优势:
理论基础坚实
CHC框架建立在心理学领域最经实证验证的认知能力理论之上。这不仅为评估提供了科学基础,也使得评估结果具有跨学科的可解释性。
评估维度全面
十个认知领域覆盖了人类智力的主要维度,从知识储备到推理能力,从记忆功能到感知处理,提供了一个全面的评估框架。
诊断性强
细粒度的能力分解使得评估结果具有高度诊断性。研究者和工程师可以准确定位AI系统的短板,从而有针对性地改进。
可量化比较
标准化的AGI评分(0-100%)使得不同AI系统的能力比较成为可能,也为追踪AI发展进程提供了客观尺度。
理想区域 理论优先 需要改进 实践优先 CHC框架 层级框架 经济定义 图灵测试 低诊断性 高诊断性 弱理论基础 强理论基础 AGI定义方法比较
8 局限性与未来方向
8.1 框架的固有局限
论文坦诚地讨论了AGI评估框架的几个固有局限,这种学术诚实性值得赞赏。
智力概念的非穷尽性
首先,框架对智力的概念化并非穷尽的。它有意识地排除了某些能力,如加德纳多元智能理论中提出的动觉能力。这意味着即使一个系统在CHC框架上达到100%,它仍可能缺乏某些人类智能的重要维度。
文化偏倚问题
其次,框架的示例特定于英语语言,并非文化中立的。未来的研究可能需要将这些测试适应于不同的语言和文化背景。这一局限反映了当前AI评估的普遍问题------大多数基准测试都以英语为中心,可能无法准确评估AI系统在其他语言和文化背景下的能力。
测试选择的约束
再次,框架的操作化存在固有约束。一般知识测试必然是选择性的,不能评估所有可能的主题领域。100%的AGI评分代表的是在测试维度上达到"高度熟练"的受过良好教育个体,而非拥有大学学位意义上的受过良好教育。
权重分配的任意性
最后,虽然评分权重对于定量测量是必要的,但它们代表了许多可能配置中的一种。框架给予每个广泛能力相等权重(10%)以优先考虑广度,但更自由裁量的权重方案也可能是合理的。结果取决于这些方法论选择,未来的工作可以探索替代的任务集合和权重方案。
8.2 AGI总分的使用警示
论文提出了一个重要警示:虽然提供了AGI总分作为便利,但它可能具有误导性。简单的求和可能掩盖瓶颈能力的关键失败。
论文给出了一个极端例子:一个AGI评分为90%但在长期记忆存储上得0%的AI系统,将因"健忘症"形式而在功能上受损,尽管总分很高,但其能力严重受限。因此,论文建议报告AI系统的认知剖析,而不仅仅是其AGI总分。
这一警示具有重要的实践意义。在实际应用中,用户和开发者需要了解AI系统的具体能力边界,而非仅仅依赖一个总体评分。一个在某些关键领域存在严重缺陷的系统,即使总分很高,也可能在特定应用场景中表现不佳。
8.3 未来研究方向
论文为未来研究指明了几个有价值的方向。
跨文化适应
将测试适应于不同的语言和文化背景是一个重要的研究方向。这不仅涉及翻译,还需要考虑文化差异对认知任务表现的影响。例如,某些推理任务可能在不同文化背景下有不同的难度。
替代权重方案
探索替代的任务集合和权重方案可以提供更全面的评估视角。不同的应用场景可能需要不同的能力权重,例如,医疗AI可能需要更高的知识准确性权重,而创意AI可能需要更高的流畅性权重。
动态评估
当前的评估框架是静态的,未来可以发展动态评估方法,追踪AI系统能力的变化轨迹。这对于评估AI系统的学习能力和适应性具有重要意义。
与神经科学的整合
将CHC框架与神经科学发现整合,可以深化对AI认知能力的理解。例如,将AI系统的能力分布与人类大脑的功能组织进行比较,可能揭示AI认知架构的优势和劣势。
9 结论与启示
9.1 核心贡献总结
本论文的核心贡献在于为AGI这一长期模糊的概念提供了一个清晰、可量化的定义框架。通过将CHC认知能力理论引入AI评估,论文建立了一个跨学科的理论桥梁,使得AI评估能够借鉴心理学领域一个多世纪的研究积累。
框架的实证应用揭示了当代AI系统的真实能力边界。GPT-4的27%和GPT-5的57%评分具体量化了AI发展的快速进步,同时也清晰地表明了与AGI之间的巨大差距。更重要的是,框架精准定位了AI系统的关键短板------长期记忆存储能力的严重缺失,为未来的研究和工程努力指明了方向。
论文提出的"锯齿状"能力分布概念和"能力扭曲"现象,深刻揭示了当前AI评估中可能存在的误区。将某些领域的优势误认为通用能力,可能导致对AGI何时到来的错误预期。只有通过细粒度的、多维度的评估,才能准确把握AI系统的真实能力。
9.2 对AI研究的启示
架构创新的必要性
长期记忆存储能力的缺失指向了架构创新的必要性。当前的Transformer架构本质上是无状态的前馈网络,无法在推理过程中持续学习。真正的解决方案可能需要引入可塑性机制,使模型能够根据经验调整其参数或结构。
评估方法的革新
论文的评估方法论为AI评估提供了新的思路。任务导向而非数据集导向的评估,能够更好地测试真正的能力而非记忆效果。同时,多维度、细粒度的评估能够提供诊断性信息,指导有针对性的改进。
跨学科合作的价值
CHC框架的成功应用展示了跨学科合作的价值。心理学、神经科学等领域积累了丰富的认知研究,这些知识可以为AI评估和发展提供宝贵的指导。未来的AI研究应该更加开放地吸收其他学科的智慧。
9.3 对政策制定的启示
客观评估标准的建立
政策制定者需要客观、可量化的标准来评估AI系统的能力。CHC框架提供了这样一个标准,使得关于AI监管、安全评估的政策讨论能够建立在坚实的事实基础之上。
风险识别与应对
框架揭示的AI能力短板也指出了潜在的风险领域。例如,长期记忆存储能力的缺失意味着AI系统可能无法可靠地学习和遵守长期规则,这对于AI安全具有重要意义。
发展进程的追踪
标准化的AGI评分为追踪AI发展进程提供了客观尺度。政策制定者可以利用这一工具监测AI技术的进步速度,预测可能的社会影响,并相应地调整政策准备。
9.4 结语
AGI的定义问题不仅是一个学术问题,更是一个关乎人类未来的重要议题。一个清晰、可量化的AGI定义,能够帮助我们准确把握AI技术的真实水平,理性评估其发展前景,并做出明智的决策。
本论文通过引入CHC认知能力理论,为AGI定义提供了一个坚实的科学基础。虽然框架仍有其局限性,但它代表了向科学化、系统化AGI评估迈出的重要一步。随着AI技术的持续发展,这一框架也将不断演进和完善,为我们理解和塑造AI的未来提供持续指导。
在AGI可能成为人类历史上最重要技术发展的背景下,这项研究的意义远远超出了学术范畴。它为我们提供了一个思考AI能力、评估AI进展、规划AI未来的共同语言和框架。这正是科学研究的最高价值所在------不仅回答问题,更提出正确的问题,并为寻找答案指明方向。
参考文献
1 Hendrycks D, Song D, Szegedy C, et al. A Definition of AGIJ. arXiv preprint arXiv:2510.18212v3, 2025.
2 Carroll J B. Human Cognitive Abilities: A Survey of Factor-Analytic StudiesM. Cambridge University Press, 1993.
3 McGrew K S. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence researchJ. Intelligence, 2009, 37(1): 1-10.
4 McGrew K S, Schneider W J. CHC theory revised: A visual-graphic summary of Schneider and McGrew's 2018 CHC update chapterM. MindHub/IAP Psych working paper, 2018.
5 Schneider W J, McGrew K S. The Cattell-Horn-Carroll theory of cognitive abilitiesM//Contemporary intellectual assessment: Theories, tests, and issues. Guilford Press, 2018: 73-163.
6 Morris M R, Sohl-Dickstein J, Fiedel N, et al. Levels of AGI: Operationalizing progress on the path to AGIJ. arXiv preprint arXiv:2311.02462, 2023.
7 Legg S, Hutter M. Tests of machine intelligenceC//50 Years of Artificial Intelligence. Springer, 2007.
8 Turing A M. Computing machinery and intelligenceJ. Mind, 1950, 59: 433-460.
9 Gardner H E. Multiple Intelligences: The Theory in Practice, a ReaderM. Basic Books, 1993.
10 Jensen A R. The g factor: psychometrics and biologyJ. Novartis Foundation symposium, 2000, 233: 37-47.
11 Canivez G L, Youngstrom E A. Challenges to the Cattell-Horn-Carroll theory: Empirical, clinical, and policy implicationsJ. Applied Measurement in Education, 2019, 32(3): 232-248.
12 Wasserman J D. Deconstructing CHCJ. Applied Measurement in Education, 2019, 32(3): 249-268.
13 Ilić D, Gignac G E. Evidence of interrelated cognitive-like capabilities in large language models: Indication of artificial general intelligence or achievement?J. Intelligence, 2024, 106: 106.
14 Jin J, Syrgkanis V, Kakade S M, et al. Discovering hierarchical latent capabilities of language models via causal representation learningJ. arXiv preprint arXiv:2506.10378, 2025.
15 Hu E J, Shen Y, Wallis P, et al. LoRA: Low-rank adaptation of large language modelsJ. arXiv preprint arXiv:2106.09685, 2021.