以前的 CoT(思维链)像是在教模型"应试",必须有题目、有提示才肯推理。而 Quiet-STaR 的出现,标志着大模型开始学会了"像学者一样阅读"------在海量的互联网文本中,通过预测未来的文字,自发地学会了"三思而后行"。这篇博客将剥开复杂的数学外衣,通俗解读 DeepMind/Stanford 这一开创性工作:当 AI 拥有了看不见的"内心独白",通往 AGI 的路是否缩短了一程?
第一步:宏观背景与痛点
1. 痛点引入:现在的领域里存在什么问题?
在 Quiet-STaR 出现之前,让大语言模型(LLM)学会推理(Reasoning),主要依赖于两种路径,但它们都有明显的天花板:
路径一:有监督微调(SFT)或 提示工程(Prompting)。 我们给模型具体的题目(如数学题),通过"思维链"(Chain-of-Thought, CoT)让模型一步步把推理过程写出来。
痛点: 这就像是应试教育。模型只在被要求回答问题时才推理,而且极度依赖昂贵且有限的标注数据(QA对)
路径二:传统的自学推理(原始的 STaR 方法)。 STaR (Self-Taught Reasoner) 让模型自己做题,如果做对了,就把这次的推理过程加入训练集。
痛点: 这依然是做题思维。它只能在有明确答案(正确/错误)的封闭场景下工作(比如数学或选择题)。
真正的核心痛点在于: 互联网上绝大多数的文本(书籍、新闻、代码、小说)并不是问答题,也没有标准答案。现有的模型在预训练(Pre-training)阶段,只是在机械地预测下一个字,而忽略了文本背后隐含的逻辑 。模型在海量的通用文本上"读"书时,并没有学会"思考"。
2. 直觉 :生活中的"潜台词"与"停顿"
为了理解这篇论文的本质,我们可以用日常生活中的阅读和说话来打比方:
目前的模型(Shallow Reading): 想象一个小学生朗读莎士比亚,他能读出每一个字,但他不理解字面背后的深意。他只是根据前一个字顺口溜出下一个字。
现状:模型在预测下一个 Token 时,主要依靠表面的统计概率,而不是深层的逻辑推导。
Quiet-STaR 想要达到的模型(Deep Thinking): 想象你在读一本悬疑小说。当你读到"管家手里拿着......"这几个字时,你的大脑会快速且安静地 回顾之前的剧情:(管家恨主人 + 刚才主人在尖叫 + 这种场景通常意味着凶器)。 然后,你预测下一个词是:"......刀"。
直觉:虽然书上没有把你的心理活动印出来,但这些言外之意才是理解文本的关键 。
"三思而后行" 人类在说话或写作时,经常会停 一下。这个停顿不是卡壳,而是大脑在进行快速的模拟和规划。Quiet-STaR 就是要强制让模型在生成每一个字之前,都先在内部"停顿"一下,生成一段看不见的思考,利用这个思考来更准确地预测下一个字 。
3. 一句话总结
Quiet-STaR 的核心贡献是: 它提出了一种无需人工标注的方法,利用互联网上海量的非结构化文本 ,训练大语言模型在生成每一个 Token 之前先进行隐式的内部思考(生成 Rationales),从而让模型不仅能更好地预测文本,还能在没有任何专门训练的情况下,显著提升解决数学和常识推理问题的能力 。
第二步:核心思想概览
1. 目标:从"显性做题"到"隐性思考"
这篇论文的"高光时刻"在于它打破了推理任务的边界。它不再需要带标签的问答对,而是直接利用普通的互联网文本(如 C4 或 OpenWebMath 数据集)来训练推理能力 。
它的核心假设是:如果一段思考能帮我更准确地预测接下来要说什么话,那么这段思考就是有价值的 。
2. 整体架构图:Think - Talk - Learn
Quiet-STaR 的工作流程是一个优雅的闭环,作者将其概括为三个阶段:思考 (Think)、表达 (Talk)、学习 (Learn) 。
让我们拆解一下这个流程(基于论文 Figure 1):
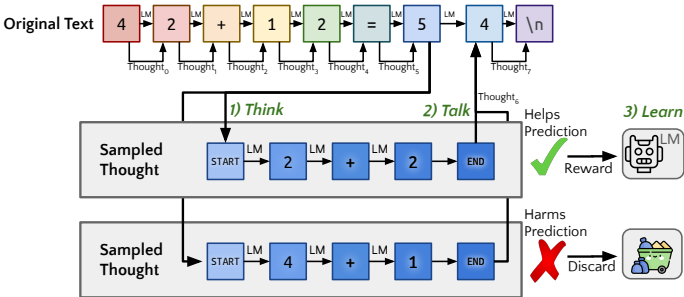
输入 (Input): 一段普通的文本序列(例如:"42 + 12")。
过程 (The Loop):
Think (思考 - 并行生成): 模型不仅仅预测下一个字,而是在输入文本的每一个 Token 后面 ,都尝试生成一段"内心独白"(Thought)。这些思考被特殊的标记 <startofthought> 和 <endofthought> 包裹 。
例如:在读到"="时,模型可能会在心里生成"Thinking: 前面是42,有加号,后面是12..."。
Talk (表达 - 混合预测): 模型会产生两个预测结果:一个是基于原始文本的"直觉预测",另一个是基于刚才生成的"思考后的预测"。 作者引入了一个混合头 (Mixing Head),让模型自己决定:我是该信我的直觉,还是信我的思考?
输出:最终的下一个 Token 概率分布。
Learn (学习 - 强化反馈): 怎么判断思考好不好?如果引入了思考后,模型预测未来文本 (不仅仅是下一个字,而是后面的一串字)的概率变大了,说明思考有效,给予奖励(Reward);反之则惩罚 输出 (Output): 一个学会了在输出之前先生成内部思维链(Chain-of-Thought)的模型,它在预测困难文本时更加准确。
3. 关键创新点
作者用了三个非常巧妙的方法解决了之前的痛点:
创新一:并行思考 (Parallel Rationale Generation) ------ 解决"太慢"的问题
-
痛点: 如果让模型在每一个字后面都停下来思考,生成速度会慢到无法接受。
-
Key Insight: 作者利用了 Transformer 的注意力机制特性,设计了一种特殊的对角线注意力掩码 (Diagonal Attention Mask) 。
-
效果: 这允许模型在一个推理过程(Forward Pass)中,同时 为输入序列中的所有 Token 生成各自的思考,而不是一个接一个地生成。这极大地提高了训练效率,使得在大规模文本上训练成为可能 。
创新二:混合头机制 (Mixing Head) ------ 解决"胡思乱想"的问题
-
痛点: 刚开始训练时,模型生成的"思考"大多是毫无意义的乱码。如果强制模型基于这些乱码去预测下一个字,模型的能力会崩塌。
-
Key Insight: 作者引入了一个"门控"机制。它输出一个权重 w,决定多大程度上采纳"思考后的预测" 。
-
效果: 这起到了一种平滑过渡的作用。起初,思考质量差,模型会学会忽略它(权重偏向直觉);随着思考质量提高,模型会逐渐增加对思考的依赖权重。这解决了分布偏移的问题 。
创新三:未来预测奖励 (Non-myopic Reward) ------ 解决"短视"的问题
-
痛点: 有时候思考并不能马上帮助预测紧接着的那个字(例如虚词"the"、"is"),但对理解长句的含义很有帮助。
-
Key Insight: 奖励函数不仅仅看下一个 Token 的预测准确率,而是看未来多个 Token 的语义预测是否更准确 。
-
效果: 这鼓励模型进行更有深度的推理,而不是只关注眼前的语法通顺。
4. 与前人对比 (Baseline vs. Quiet-STaR)
为了突出这篇论文的"新",我们可以将其与之前的两座大山进行对比:
| 特性 | CoT (思维链) | STaR (自学推理者) | Quiet-STaR (本论文) |
|---|---|---|---|
| 触发方式 | 显式提示 (Prompting) | 针对特定问题 (QA) | 隐式触发 (Implicit),在任何 Token 处 |
| 训练数据 | 无 (推理时) 或 少量示例 | 标注好的问答数据集 (QA Pairs) | 任意文本 (Arbitrary Text),如网页、书籍 |
| 思考位置 | 只在回答问题之前 | 只在回答问题之前 | 每一个 Token 之后 (Token-wise) |
| 奖励信号 | 无 (或人工评分) | 答案的正确与否 (Binary) | 未来文本的预测概率 (Perplexity) |
| 适用范围 | 特定推理任务 | 封闭域问答 | 通用语言建模 (General Purpose) |
总结: Baseline (STaR) 像是一个学生,必须你给他一套卷子(QA数据集),他做完了对答案(Reward)才能学会推理。 Quiet-STaR 像是一个学者,他在通读图书馆里的所有书(Web Text)时,通过不断地自我反思和预测下文,自发地学会了推理,而不需要任何人给他出题。
第三步:技术细节拆解
我们将整个训练过程分为三个步骤:并行生成 (Think) 、混合预测 (Talk) 、参数更新 (Learn)。
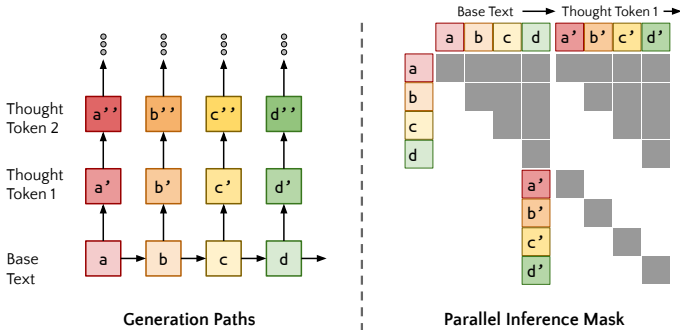
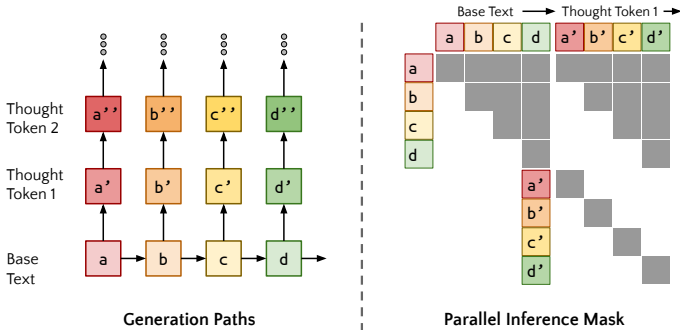
1. 并行生成 (Think):如何一次性生成所有位置的思考?
这是最反直觉的一步。通常我们认为生成是串行的(生成完第一个思考,再读下一个字),但那样太慢了。Quiet-STaR 实现了 O(1) 的并行度(相对于 Sequence Length)。
通常的 LLM 生成是线性的:说完 A 说 B,说完 B 说 C。 如果你想在 A 后面思考,在 B 后面也思考,朴素的做法是:
-
先只给 A,生成思考 -> 极慢。
-
再只给 A, B,生成思考 -> 极慢。
Quiet-STaR 的做法是:把"思考"变成了"平行的多重宇宙"。
核心数据结构:扩展的 Attention Mask
想象我们有一个输入句子:"我(A) 爱(B) 你(C)"。
我们希望生成思考:
-
在 A 后面生成
-
在 B 后面生成
-
在 C 后面生成
作者构建了一个特殊的 Attention Mask,它的形状看起来像是一个主对角线上长出了很多小尾巴的矩阵。
| 生成目标 | 看 A | 看 B | 看 C | 看 a1 | 看 a2 | 看 b1 | 看 b2 | 解释 |
|---|---|---|---|---|---|---|---|---|
| 思考 |
√ | X | X | √ | X | X | X | |
| 思考 |
√ | X | X | √ | √ | X | X | |
| 思考 |
√ | √ | X | X | X | √ | X | 关键点! |
| 思考 |
√ | √ | X | X | X | √ | √ |
这就是论文中提到的"对角线注意力掩码"(Diagonal Attention Mask)。
虽然逻辑上是并行的,但在硬件上(GPU),它是分步生成的。假设我们要生成长度为 T=2 的思考。
第 0 步:准备状态 输入完整的句子序列 。 计算一次 Attention,得到 A, B, C 各自的 Hidden State(KV Cache)。
第 1 步:所有位置同时爆发(Generate Token 1)
输入: 这里的输入是一个特殊的 Token <startofthought> (SoT),我们把它复制 3 份,分别喂给 A, B, C 的位置。
Mask 设置:
A 位置的 SoT 只能看 A。
B 位置的 SoT 只能看 A, B。
C 位置的 SoT 只能看 A, B, C。
并行计算: GPU 一次性算出 3 个预测结果。
A -> 预测出
B -> 预测出
C -> 预测出
结果: 我们同时得到了所有位置的第一步思考。
第 2 步:各自延续自己的故事(Generate Token 2)
输入: 刚才生成的 。
Mask 设置(关键的对角线逻辑):
(作为输入) 只能看 A 和 SoT。
(作为输入) 只能看 A, B 和 SoT。
注意:它被 Mask 屏蔽了,不准看 ! 尽管
是上一轮算出来的,但在
的宇宙里,A 并没有进行思考。
同理, 不准看
和
。
并行计算:
-> 预测出
-> 预测出
-> 预测出
最终结果:
经过 T 次循环(T是思考长度),我们就凑齐了所有的思考链:
-
链条 1:
-
链条 2:
-
输出是一个张量
Thoughts,维度为 (B, L, T),其中 T 是设定的思考长度(论文中尝试了 16 或 24 )。 -
Meta-Tokens: 每个思考序列都被强制加上
<startofthought>(SoT) 和<endofthought>(EoT) 。SoT 用于触发思考模式,EoT 用于告诉模型"我思考完了,该输出结果了"。
论文里用到了"Counterfactual"这个词 ,这是理解并行的钥匙。
-
事实路径: 原始文本是
。
-
反事实路径:
-
对于 A 来说,虽然真实后面接的是 B,但在生成思考时,我们假设"如果 A 停下来思考会发生什么?"。
-
对于 B 来说,我们在生成 B 的思考时,假设"A 并没有思考,直接说出了 B,然后 B 停下来思考"。
-
这就是为什么 不能看
的原因:
如果 看到了
,那就意味着 B 的思考是建立在 A 已经思考过的基础上的。但这会破坏并行性(因为通过
需要时间),而且会造成依赖链爆炸。
为了效率,Quiet-STaR 强制规定:每个 Token 在思考时,都假装前面的 Token 没思考过,是直接蹦出来的。
总结:到底快在哪里?
-
朴素方法: 如果句子长 N,思考长 T 。你需要做
-
Quiet-STaR 并行法: 你只需要做 T 次前向传播(以及 1 次基础文本传播)。对于上面的例子,只需要跑 16 次模型。
- 不管句子多长,生成思考的耗时是恒定的(只取决于你允许想多久,即T)。
这利用了 GPU 极强的并行计算能力,用显存空间(存巨大的 Mask 和 KV Cache)换取了时间。
2. 混合预测 (Talk):如何平滑地使用思考?
思考生成后,我们得到了一个包含思考信息的隐藏状态 。现在需要决定怎么用它。
核心算法逻辑
提取特征:
-
-
<endofthought>对应的状态)。
计算混合权重 (The Mixing Head): 论文使用了一个浅层的 MLP(三层,带 ReLU 激活函数)作为"门控" 。
输入是两个隐藏状态的拼接 (Concatenation) 。
输出 是一个标量(0 到 1 之间)。
混合 Logits (加权融合):
注意: 这里的融合是在 Logits (对数概率) 层面进行的,而不是概率层面。这相当于对两个分布做几何平均。
3. 参数更新 (Learn):REINFORCE 与 关键的 Trick
我们站在位置。模型刚刚生成了一段思考
。 核心判断标准: 如果这段思考能让我把后面的一串话说得更顺(概率更高),那它就是好思考。
公式推导:
我们逐项拆解这个复杂的公式:
(未来的真相):
这是 Ground Truth。比如原文是"...因此 。"。我们在"因此"这个词处思考。
就是"
"这一串 Token。
注意(Non-myopic): 这里的关键是 (未来 Token 数,论文取了 4 或 12 )。如果只看下一个词(Myopic),思考往往没用。必须看长远一点,思考的价值才能体现。
(Teacher Forcing 概率):
这是有了思考之后的预测概率。
我们把生成的思考 拼在原文
后面,强制模型去预测
。
物理含义: "带着刚才的想法,我觉得接下来发生 的可能性是多少?"
(基线 Baseline):
这是为了减少方差 。对于同一个位置 ,模型其实并行采样了多个不同的思考路径(比如 2-4 条)。
是这些路径预测概率的平均值。
物理含义: "平均水平下,大家觉得接下来发生 的可能性是多少?"
最终判决 :
-
如果
-
如果
2. 惩罚机制:损失函数 (Loss Function)
总损失由两部分组成,一部分管"说话",一部分管"思考"。
第一部分:语言建模损失 ()
不管思考得怎么样,模型最终输出的 (混合后的概率)必须准确预测下一个 Token
作用: 这个 Loss 是可导的,它通过反向传播直接更新 Mixing Head 和 Base LM 的参数。它确保了模型即使思考偏了,靠直觉也能把话说对。
第二部分:强化学习损失 ()
这部分专门用来更新生成思考的策略(即 Policy,也就是 LLM 本身生成 Token 的能力)。
-
直译: 我们要最大化奖励
-
操作逻辑:
-
如果
-
如果
-
实例场景:预测化学方程式的产物
背景: 模型正在阅读一篇关于化学反应的网页文本。 输入文本(Context):
"Magnesium reacts with nitrogen to form magnesium nitride. The chemical formula for this reaction is Mg + N2 ->" (镁与氮气反应生成氮化镁。该反应的化学方程式是 Mg + N2 -> )
目标: 预测下一个 Token。
-
正确答案(Ground Truth):
Mg3N2 -
难点: 如果模型只是死记硬背,可能只记得
Mg和N的组合,但不一定记得配平系数是3和2。
第一阶段:Think(并行思考 - 潜意识的活动)
在模型读到输入文本的最后一个 Token -> 时,Quiet-STaR 机制被触发。它不会直接蹦出下一个词,而是先在内部生成一段"隐形"的思考。
1. 触发思考:
模型插入 <startofthought> 标记,开始生成思考序列(长度为 )。
- 生成内容(真实论文案例 ):
生成的思考 (Thought):
<startofthought>...so the equation of the reaction that forms magnesium nitride is...<endofthought>(思考:...所以生成氮化镁的反应方程式是...)
-
分析: 你会发现这段思考看似是在"废话",重复了一遍前面的语义。但对模型来说,这其实是在"注意力聚焦"。它在通过复述来确认当前的语境是"写方程式"而不是"描述现象"。
-
注意:在其他复杂的数学例子中,思考可能会是具体的推导步骤,如
...since n is odd, n = 2k+1...。
第二阶段:Talk(混合预测 - 纠结的过程)
现在模型手头有两份信息,它需要决定输出什么。我们来看一下混合头 (Mixing Head) 是怎么工作的。
1. 路径 A:直觉预测 (Base Prediction - h_{init})
-
状态: 模型只看了前面的文本,没看刚才的思考。
-
心理活动: "
Mg + N2 ->后面通常跟产物。大概是MgN吧?或者Mg2N?我不确定配平。" -
预测概率分布 (logits):
-
MgN: 40% -
Mg3N2: 30% -
Mg: 20%
-
2. 路径 B:思考后预测 (Thought Prediction - h_{thought})
-
状态: 模型看了文本 + 刚才生成的思考("...reaction is...")。
-
心理活动: "刚才我确认了这是氮化镁(magnesium nitride)的方程式。我记得氮化镁的化合价是
-
预测概率分布 (logits):
-
Mg3N2: 80% -
MgN: 10%
-
3. 混合决策 (Mixing Weight )
-
计算: 混合头看了一眼思考的内容,发现这段思考逻辑很通顺,质量很高。
-
权重
-
最终输出:
Mg3N2的概率飙升到了 70%。
结果: 模型自信地输出了正确的 Token:Mg3N2。
第三阶段:Learn(强化反馈 - 判卷子)
假设这是在训练阶段,模型输出了 Mg3N2。现在要根据结果来更新模型。
1. 对答案 (Ground Truth):
训练数据里,下一个词确实是 Mg3N2。
2. 算奖励 (Reward Calculation):
-
有思考的得分: 使用思考后,预测
Mg3N2的概率是 70% 。 -
基线得分 (Baseline): 假设如果没有思考(或平均水平的思考),预测概率只有 40% (。
-
奖励值 r: -0.36 - (-0.92) = +0.56。
-
判定: 这是一个好思考! (r > 0)
3. 更新参数 (Update):
-
奖励谁? 奖励生成那段思考
...so the equation of...的神经元连接。 -
惩罚谁? 如果生成的思考是胡言乱语(比如
...apple banana...),导致预测Mg3N2的概率反而降到了 10%,那就会收到负奖励,以后少生成这种废话。
| 步骤 | 普通大模型 (Standard LLM) | Quiet-STaR 模型 |
|---|---|---|
| 输入 | Mg + N2 -> |
Mg + N2 -> |
| 内部动作 | 直接计算概率 | 1. 暂停 (Quietly) 2. 思考: ...forms magnesium nitride... 3. 混合决策 |
| 预测倾向 | 依赖字面共现频率 (Co-occurrence) | 依赖语义推导 (Reasoning) |
| 典型错误 | 可能会输出 MgN (因为这三个字母常一起出现) |
更大概率输出准确的 Mg3N2 |
| 用户感知 | 响应极快,但可能瞎编 | 响应稍慢(因为要生成思考),但更准确 |
这就是 Quiet-STaR 的本质:它用"计算时间"(推理时的思考耗时)换取了"智能程度"。
第四步:实验结果
论文在Mistral 7B模型上,使用OpenWebMath(富含数学推理的文本)和C4(通用网络文本)进行训练,并评估其零样本推理能力。
下游任务性能显著提升 :经过Quiet-STaR训练后,模型在未经过任何任务微调的情况下,在GSM8K和CommonsenseQA上的零样本准确率大幅提升。并且,性能提升与训练时使用的推理令牌数量正相关,说明"思考得越深入,效果越好"。
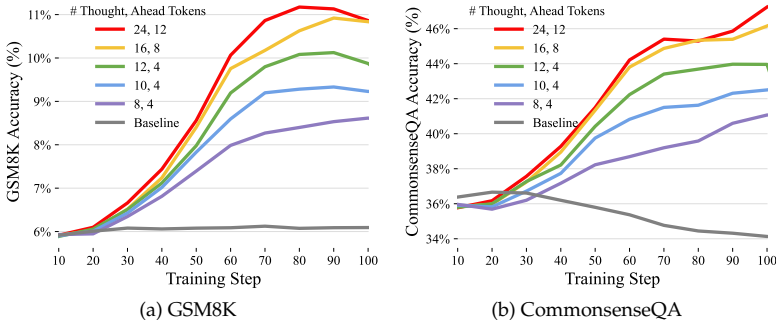
注意:这是在没有任何题目专门训练的情况下,"顺便"学会的能力。
Q1:如果不看未来(Non-myopic),只看下一个词会怎样?
-
实验: 把奖励函数里的 n_{true}(看未来的 Token 数)设为 1。
-
结果: 效果大打折扣。
-
结论: 思考是需要长远眼光的。只为了预测下一个字(比如"的"),根本不需要推理;为了预测完整个句子,推理才有价值 。
Q2:如果思考得短一点会怎样?
-
实验: 对比思考 8 个 Token 和 24 个 Token。
-
结果: 思考 24 个 Token 的效果明显更好 。
-
直觉: 你让爱因斯坦做题,也得给他足够的时间(Token)打草稿,只准想 1 秒钟(8 Tokens)肯定做不出难题。
我们在前面的步骤里模拟过化学题,这里看一个论文中展示的真实数学推导例子 。
-
原文: "...implies that
(...意味着 A 包含于 B 且 B 包含于 A。这两个里面的前者往往...)
-
模型生成的思考 (Thought):
<startofthought>in some sense to be the more difficult<endofthought>(思考:...某种意义上是更难证明的...)
-
接下来的原文: "...be the trickiest for students."
(...对学生来说是最棘手的。)
分析:
看!原文后面要说"这很难"。
模型在读到"往往"的时候,心里就已经在预判"这通常意味着更难"。
虽然它心里的词和原文不一样,但语义是完全对齐的。这就是思考帮助预测的铁证。
第五步:总结与升华
1. 优缺点分析 (Pros & Cons)
优点(Why it's brilliant):
-
把"互联网"变成了"教科书": 这是最大的突破。它不再依赖昂贵的人工标注(QA对),而是直接利用无需标注的海量文本(Web Text)。这意味着它的天花板极高,只要有书读,它就能变聪明 。
-
通用性极强: 以前的方法通常是"数学模型"只会做数学,"代码模型"只会写代码。Quiet-STaR 训练出来的模型在零样本(Zero-shot) 情况下,既能提升数学能力,也能提升常识推理能力,这是一种泛化的智能 。
-
工程实现: 利用并行 Attention Mask 将 N次推理压缩到 O(1) 的时间复杂度(相对于序列长度),使得这种极度消耗算力的方法在工程上变得可行 。
局限性与挑战:
-
推理成本昂贵: 虽然并行化了,但在推理时(Inference),模型每输出一个 Token 都要额外生成 T 个思考 Token。这显著增加了计算量和延迟。用时间换智能,在对延迟敏感的场景下可能不可用 。
-
思考长度僵化: 目前的思考长度是预设的超参数(比如 16 个 Token)。模型不能根据问题的难易程度动态决定"我是该想 1 秒还是想 10 分钟"。这不符合人类直觉 。
-
"黑盒"与"伪对齐"风险: 我们只奖励"能否预测对下一个词",而不检查"思考逻辑是否正确"。模型可能会生成歪打正着的错误逻辑,或者学会某种诡辩技巧来骗取奖励,而不是真正的推理
2. 未来展望 (Future Outlook)
这个方法打开了一扇通往System 2(慢思考)的大门,它对未来的启发是巨大的:
动态算力分配 (Adaptive Computation): 未来的模型应该能自己决定:这个问题很简单(1+1),我不用想,直接输出;那个问题很难(费马大定理),我要申请调用 1000 个 Token 的思考额度。论文作者也提到了这点,这是最自然的下一步 。
从"预训练"到"预推理": 以前我们认为 Pre-training 只是让模型学会说话(语法、词汇)。Quiet-STaR 告诉我们,Pre-training 阶段就可以注入推理能力。未来的基座模型(Foundation Model),可能出厂自带"内心独白"功能。
对我们的启发: 不要只盯着"答案"去微调模型。过程(Rationale)往往比结果更重要。即使你的业务没有显式的推理题,也可以尝试让模型在生成最终结果前,先生成一段中间的、隐式的"草稿"。
请记住这句话:
Quiet-STaR 将大模型的"直觉反应"进化为了"深思熟虑"。
它证明了我们不需要专门教模型做题,只要强迫模型在阅读互联网上的每一句话时都"多想一步",它就能利用预测未来的信号,自我涌现出通用的推理智能。