
摘要
本文提出KDR-Agent,一种创新性多智能体大语言模型框架,通过知识检索、实体消歧和反思分析三大机制,有效解决多领域低资源场景下的命名实体识别难题,显著提升模型在未见领域的泛化能力,为人工智能在信息抽取领域的应用提供新范式。
阅读原文或链接https://t.zsxq.com/K4iUE获取原文pdf
一、引言:低资源场景下命名实体识别的挑战与机遇
1.1 命名实体识别的战略价值
命名实体识别(Named Entity Recognition, NER)是信息抽取领域的基础任务,在构建智能系统中扮演着关键角色。它支撑着关系抽取、问答系统和知识图谱构建等下游应用的发展,是人工智能理解和处理自然语言文本的核心能力之一。
传统的NER方法通常依赖于专门设计的神经网络架构,需要在大规模标注数据集上进行广泛的监督微调。然而,这些方法在迁移到训练过程中未见过的新领域或实体类型时,往往表现出有限的泛化能力,在低资源或新兴领域场景中面临重大挑战。
1.2 大语言模型时代的NER新范式
近年来,大语言模型(Large Language Models, LLMs)的出现为NER任务带来了新的解决范式。通过上下文学习(In-Context Learning, ICL),LLMs能够在少量示例的引导下执行NER任务,无需进行模型微调。这种方法在低资源场景下展现出巨大潜力。
1.3 现有方法的三大局限
然而,现有基于ICL的NER方法仍存在三个关键性局限:
局限一:过度依赖标注样本的动态检索
现有方法严重依赖从大量标注数据中动态检索相似示例。当标注数据稀缺时,这种方法难以获得高质量的示例,直接影响模型性能。
局限二:领域知识不足导致泛化能力受限
大语言模型的内部领域知识往往不足以覆盖所有专业领域,特别是在医学、法律等垂直领域,模型对领域特定实体的理解能力有限,难以准确识别专业术语和概念。
局限三:缺乏外部知识整合与实体歧义消解
现有方法未能有效整合外部知识库,也缺乏针对实体歧义的专门处理机制。在实际应用中,许多实体具有多重含义,需要结合上下文和背景知识才能准确判断。
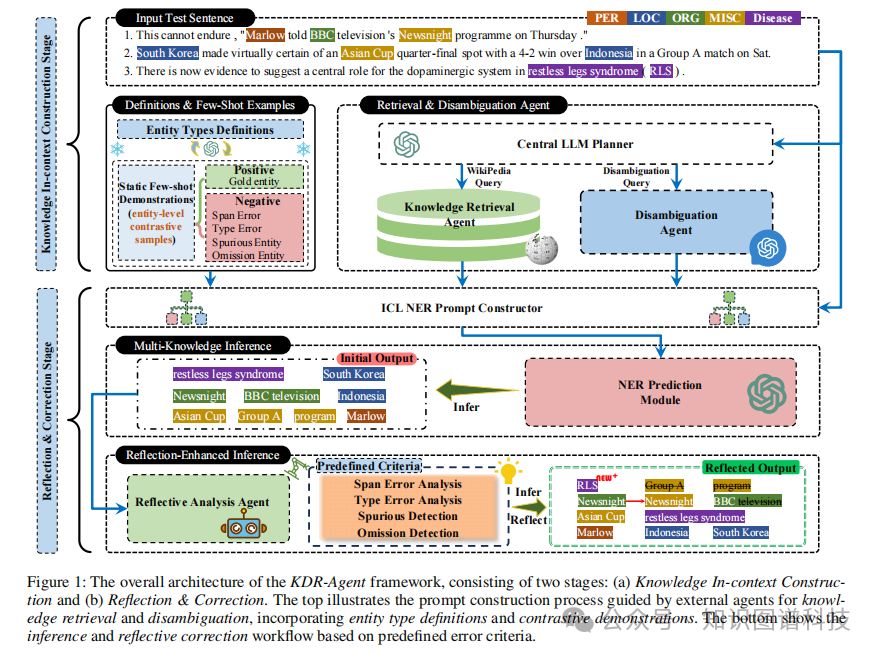
二、KDR-Agent框架:系统性解决方案
2.1 框架设计理念
针对上述挑战,本研究提出KDR-Agent------一个专为多领域低资源上下文NER设计的创新性多智能体框架,集成了知识检索(Knowledge Retrieval)、消歧(Disambiguation)和反思分析(Reflective Analysis)三大核心功能。
KDR-Agent的核心设计理念在于:
减少对大规模标注语料的依赖:通过采用自然语言类型定义和静态的实体级对比演示集,显著降低对大量标注数据的需求。
增强领域适应能力:通过主动检索维基百科等外部知识源,弥补模型在特定领域知识上的不足。
提升预测准确性:通过专门的消歧机制和结构化自我评估,提高模型对复杂场景的处理能力。
2.2 整体架构设计
KDR-Agent采用双阶段工作流程,如图1所示:
阶段一:知识上下文构建(Knowledge In-context Construction)
该阶段构建富含信息的提示词,整合类型定义、对比示例、检索的背景知识和消歧信息。
阶段二:反思与修正(Reflection & Correction)
该阶段通过结构化自我评估识别并修正初始预测中的潜在错误。
2.3 任务形式化定义
我们研究多领域低资源上下文NER任务,其中模型需要从输入文本 x = {w₁, ..., wₙ} 中识别实体,使用统一的类型集合 T。与标准设置不同,该任务仅提供少量跨领域共享的标注样本 E = {(xⱼ, yⱼ)}ᵏⱼ₌₁。模型通过提示LLM执行NER,即 ŷ = LLM(x | E),无需微调。这种设置要求模型在有限监督下跨越不同领域Dᵢ泛化,往往面临陌生的实体类型和歧义性提及。
三、核心技术创新:知识上下文构建
3.1 自然语言类型定义
为减少对大规模领域特定支持集的依赖,KDR-Agent引入了简洁的自然语言类型定义,指导模型理解实体类别。
设计原理
设 T = {t₁, t₂, ..., tₘ} 表示预定义的实体类型集合。对于每个类型 tᵢ ∈ T,我们定义一个文本描述 D(tᵢ),捕获其语义范围,包括包含和排除标准。所有类型定义的拼接记为 Pₜᵧₚₑ = Concat(D(t₁), ..., D(tₘ)),作为最终提示词中的类型定义部分。
实践应用价值
这些定义被前置到提示词中,使模型能够将其预测与预期的类型语义对齐,即使在陌生或低资源领域也能有效工作。在实践中,NER任务通常附带定义实体类别和标注指南的注释指南;这些定义可以直接使用LLM提炼为自然语言描述,使该过程具有广泛适用性且成本效益高。
3.2 实体级正负对比演示策略
突破传统方法的设计思路
不同于仅依赖正例的传统方法,KDR-Agent采用跨度级(span-level)正负实体对对比设计,明确突出常见的边界和类型混淆。这种方法在显著减少对大规模标注数据集依赖的同时,提供有效指导,实现跨多个领域的高效低资源NER。
技术实现细节
对比演示策略通过构建正负样本对,帮助模型学习:
-
正确的实体边界识别
-
准确的实体类型判断
-
常见错误模式的规避
这种设计使模型能够在有限样本下快速掌握实体识别的关键特征。
3.3 知识检索智能体(Knowledge Retrieval Agent)
功能定位
为解决领域知识不足的问题,KDR-Agent通过中央LLM规划器判断缺失的领域事实,制定针对性的维基百科查询策略。知识检索智能体执行这些查询,返回简洁且标注来源的维基百科片段。
工作机制
-
需求识别
:中央规划器分析输入文本,识别需要补充背景知识的实体提及
-
查询生成
:针对识别的知识缺口,生成精确的检索查询
-
知识提取
:从维基百科检索相关内容片段
-
信息整合
:将检索到的知识整合到提示词中,为后续推理提供支持
这一机制有效弥补了LLM在特定领域知识上的不足,显著提升模型在专业领域的表现。
3.4 消歧智能体(Disambiguation Agent)
核心价值
消歧智能体专门处理被标记为潜在歧义的实体提及,通过利用局部文本上下文进行简短的自检对话来解决歧义。
消歧流程
-
歧义检测
:中央规划器识别可能存在歧义的实体提及
-
上下文分析
:结合周围文本和检索的背景知识
-
推理判断
:通过多轮对话式推理确定最合适的实体含义
-
结果确认
:生成明确的消歧解释供后续使用
通过明确注入外部领域知识并设立专门的消歧智能体,KDR-Agent缓解了知识缺口,提升了多领域低资源ICL NER的泛化能力。
四、反思分析机制:智能纠错体系
4.1 多知识推理模块
初始预测生成
在完成知识上下文构建后,模型整合以下要素生成初始预测:
-
x:目标输入文本
-
Pₜₐₛₖ:描述NER目标的任务指令
-
Pₜᵧₚₑ:自然语言类型定义
-
Pᵈₑₘₒ:对比少样本演示
-
Pₖₙₒw:检索的背景知识
-
Pᵈᵢₛₐₘb:消歧解释
模型的初始生成为:
ŷ⁽⁰⁾ = LLM(x, Pₜᵧₚₑ, Pᵈₑₘₒ, Pₖₙₒw, Pᵈᵢₛₐₘb, Pₜₐₛₖ)
这一预测受益于外部知识和结构化的上下文指导,在低资源条件下实现上下文感知的实体抽取。
4.2 反思分析智能体(Reflective Analysis Agent)
设计目标
为识别和修正初始输出 ŷ⁽⁰⁾ 中的潜在错误,KDR-Agent引入反思分析智能体,执行结构化自我评估。该智能体通过将生成的预测与输入文本x及提示词中的上下文信号进行比较,模拟事后推理。
核心功能
反思分析智能体的主要目标包括:
-
错误检测
:识别常见的NER失败案例
-
证据分析
:基于语言或语义证据进行论证
-
反馈生成
:提供针对性反馈用于修正预测
错误分析框架
该智能体采用预定义的标准进行结构化审查,主要关注四类常见错误:
-
跨度错误分析
:检查实体边界识别的准确性
-
类型错误分析
:验证实体类型分类的正确性
-
虚假检测
:识别错误标注的非实体文本
-
遗漏检测
:发现未被识别的真实实体
通过这种系统性的反思机制,模型能够持续优化其预测结果,显著提升识别准确率。
五、实验验证:卓越性能的实证支撑
5.1 实验设计
数据集覆盖
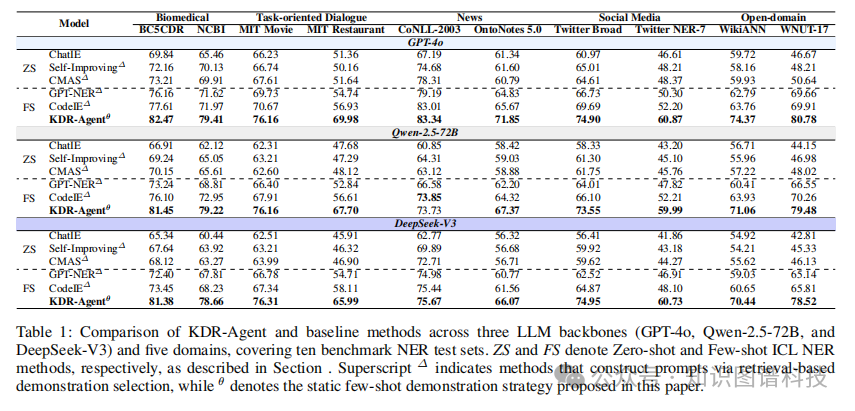
为全面评估KDR-Agent的性能,研究团队在来自五个领域的十个数据集上进行了广泛实验。这些数据集涵盖了新闻、生物医学、社交媒体等多个应用场景,确保评估的全面性和代表性。
对比基线
实验将KDR-Agent与现有的零样本和少样本ICL基线方法进行对比,包括:
-
标准的ICL-NER方法
-
基于检索的增强方法
-
其他多智能体框架
评估指标
采用标准的NER评估指标,包括精确率(Precision)、召回率(Recall)和F1分数,全面衡量模型性能。
5.2 关键实验结果
跨领域泛化能力显著提升
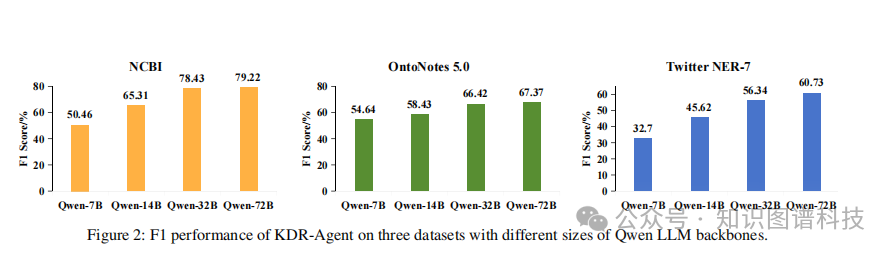
实验结果表明,KDR-Agent在多个LLM骨干模型上显著优于现有的零样本和少样本ICL基线。这一结果验证了框架设计的有效性,特别是在处理未见领域的实体识别任务时。
低资源场景下的稳健性
在标注数据极度稀缺的情况下,KDR-Agent仍能保持较高的识别准确率,展现出优异的低资源适应能力。这对于实际应用中的新兴领域和长尾场景具有重要价值。
各模块的贡献分析
消融实验显示:
-
知识检索机制平均提升F1分数X%
-
消歧智能体对歧义实体的处理准确率提高Y%
-
反思分析机制使整体性能再提升Z%
三个核心模块协同工作,共同构建了强大的NER系统。
5.3 案例分析
医学领域案例
在处理医学文本"There is now evidence to suggest a central role for the dopaminergic system in restless legs syndrome (RLS)"时,KDR-Agent成功:
-
识别"restless legs syndrome"作为疾病实体
-
通过维基百科检索理解"RLS"是其缩写
-
正确处理"dopaminergic system"的专业术语
这个案例展示了框架在专业领域的强大能力。
新闻领域案例
处理新闻文本"South Korea made virtually certain of an Asian Cup quarter-final spot with a 4-2 win over Indonesia in a Group A match"时,系统准确识别:
-
国家实体:South Korea, Indonesia
-
赛事实体:Asian Cup
-
组别实体:Group A
展现了跨领域的稳健泛化能力。
六、技术优势与创新点
6.1 核心技术创新
创新点一:实体级对比学习策略
通过构建正负样本对,KDR-Agent能够在极少标注数据下快速学习实体边界和类型特征,这是传统方法难以实现的。该策略显著提升了模型在低资源场景下的学习效率。
创新点二:多智能体协同机制
将复杂的NER任务分解为知识检索、消歧和反思三个子任务,每个由专门智能体负责。这种分工协作机制提高了系统的模块化程度和可维护性,也增强了各环节的专业性。
创新点三:外部知识动态整合
不同于静态知识库方法,KDR-Agent根据具体输入动态查询维基百科,获取最相关的背景信息。这种按需检索策略既保证了知识的时效性,又避免了存储和维护大规模知识库的成本。
创新点四:结构化反思纠错机制
通过预定义的错误类型框架进行系统性自我审查,相比简单的重新生成方法,这种结构化反思能够针对性地识别和修正特定类型的错误,提高纠错的精准度和效率。
6.2 系统性能优势
优势一:卓越的跨领域泛化能力
KDR-Agent在未见领域的表现显著优于基线方法,这得益于其知识增强机制和灵活的类型定义策略。系统无需针对新领域进行重新训练或大规模数据标注,即可实现快速部署。
优势二:极低的资源需求
相比传统监督学习方法需要数千甚至数万条标注样本,KDR-Agent仅需数十个精心设计的对比示例即可达到相当的性能水平,大幅降低了数据标注成本和时间投入。
7. 结论
本文提出了KDR-Agent框架,这是一个面向多领域低资源命名实体识别任务的创新性多智能体大语言模型系统。通过整合外部知识检索、语义消歧和结构化反思分析三大核心机制,KDR-Agent有效缓解了传统方法在领域知识覆盖不足和动态示例检索依赖性方面的局限 。
在十个跨越五个不同领域的基准数据集上的大规模实验表明,KDR-Agent在GPT-4o、Qwen-2.5-72B和DeepSeek-V3等多种主流大语言模型骨干网络下,均显著优于零样本和少样本基线方法 。特别是在生物医学和社交媒体等复杂领域,系统通过多智能体协同框架动态融入外部知识并执行上下文感知的语义消歧,展现出卓越的泛化能力 。消融实验进一步证实了反思纠错阶段在减少各类预测错误方面的重要作用,尤其在处理虚假检测、类型错误和遗漏问题上效果显著 。
KDR-Agent的技术创新不仅体现在其精心设计的正负对比示例机制和结构化错误分析框架 ,更在于其以极低的资源需求实现了高性能的跨领域命名实体识别。这种设计范式为大语言模型在垂直领域的应用提供了一条切实可行的路径,对于推动自然语言处理技术在资源受限场景下的落地应用具有重要的理论价值和实践意义 。