对于越大越好的:
x ′ = x − x min x max − x min x' = \frac{x - x_{\min}}{x_{\max} - x_{\min}} x′=xmax−xminx−xmin
对于越小越好的:
x ′ = x max − x x max − x min x' = \frac{x_{\max} - x}{x_{\max} - x_{\min}} x′=xmax−xminxmax−x
优点: 简单直观
缺点: 异常值敏感
2. mean normalization
缩放到-1-1区间, 均值为0
x ′ = x − μ x max − x min x' = \frac{x - \mu}{x_{\max} - x_{\min}} x′=xmax−xminx−μ
优点: 简单直观, 保留数据中心化
缺点: 异常值敏感
3. z-score normalization
均值为0, 方差为1的标准正态分布 (适用于消除异常值影响)
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ
优点: 适用于正态分布的数据
缺点: 不适用于正态分布的数据; 异常值敏感
4. vector normalization
适用于欧几里得空间中的多维数据 (x除以其模长)
x ′ = x ∑ i = 1 n x i 2 x' = \frac{x}{\sqrt{\sum_{i=1}^n x_i^2}} x′=∑i=1nxi2 x
优点: 适用于计算欧几里得距离(文本分类, 图像处理)
缺点: 不适用于需要保留数据间原有比例关系的场景
5. score normalization
缩放, 用于评分系统
x ′ = x ∑ i = 1 n x i x' = \frac{x}{\sum_{i=1}^n x_i} x′=∑i=1nxix
优点: 直观, 用于评分
缺点: 不适用于需要保留数据绝对值的场景; 极端值敏感
6. log
适用于数据分布高度偏斜 (+1避免对数零的情况)
x ′ = log ( x + 1 ) x' = \log(x+1) x′=log(x+1)
优点: 适用于高度偏斜的数据
缺点: 对非正值无效
确定权重
1.主观赋权
专家经验
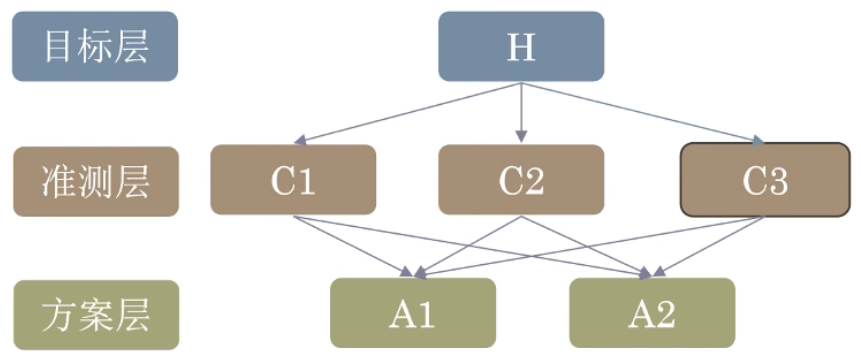
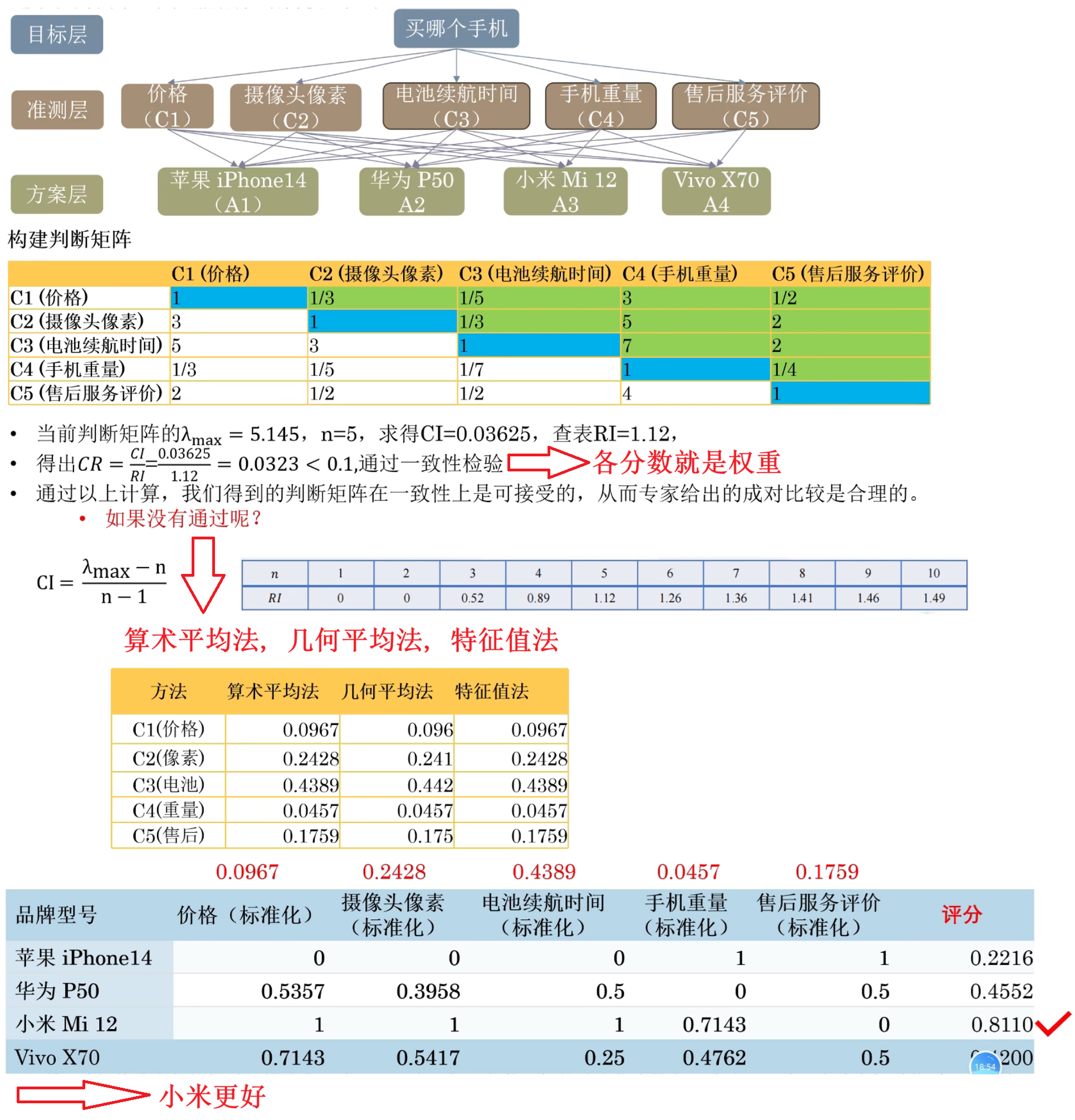
层次分析AHP
模拟层次分析
德尔菲法
2.客观赋权
数据本身
熵权法EWM
因子分析
变异系数法
3.组合赋权
加权平均法
乘法融合法
优化模型
层次分析AHP
建立递阶层次结构模型
构造出各层次中的所有判断矩阵
( a i j a_{ij} aij: 第i个指标相对第j个指标的重要程度)
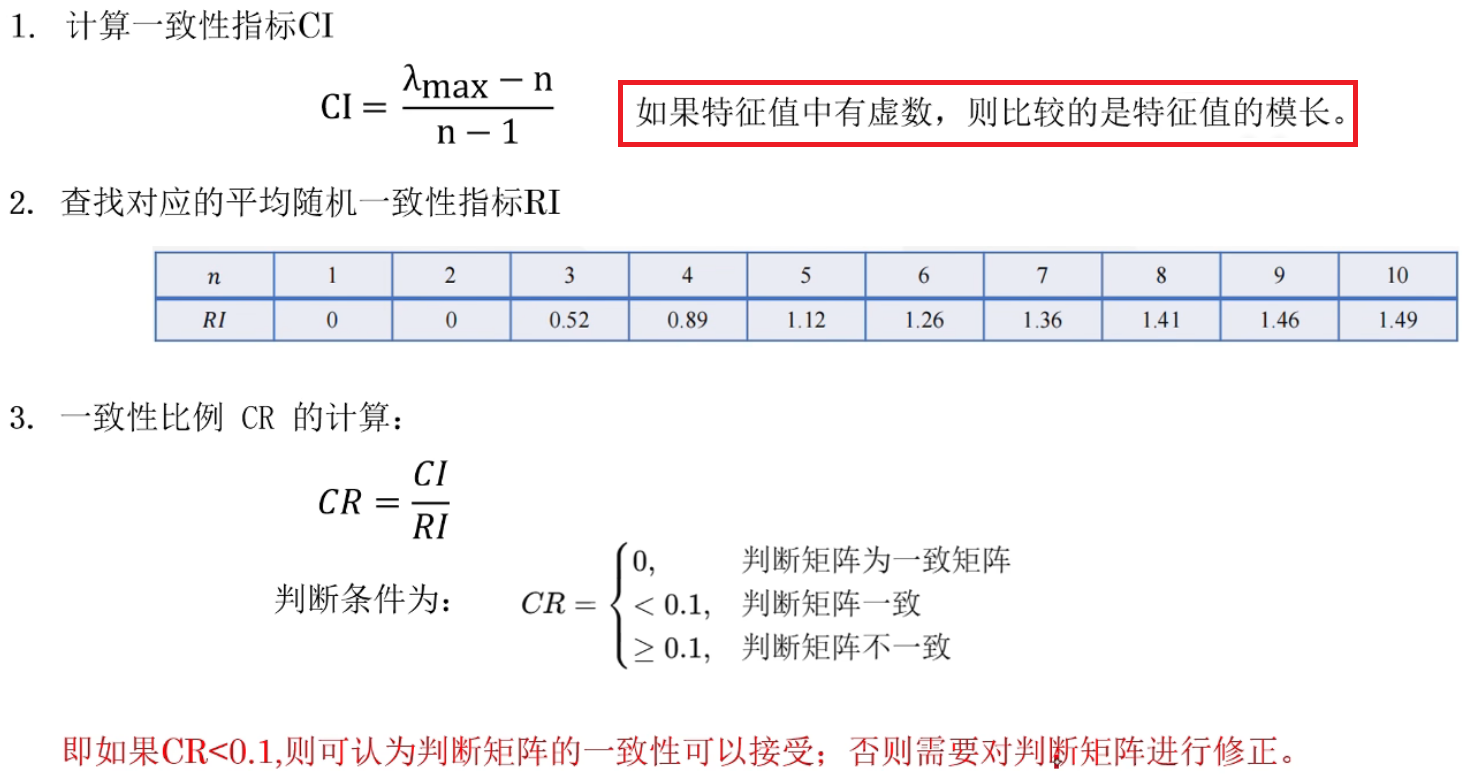
一致性检验
求权重后进行评价
(各指标乘以其对应的权重, 加和得到总分)
例子:
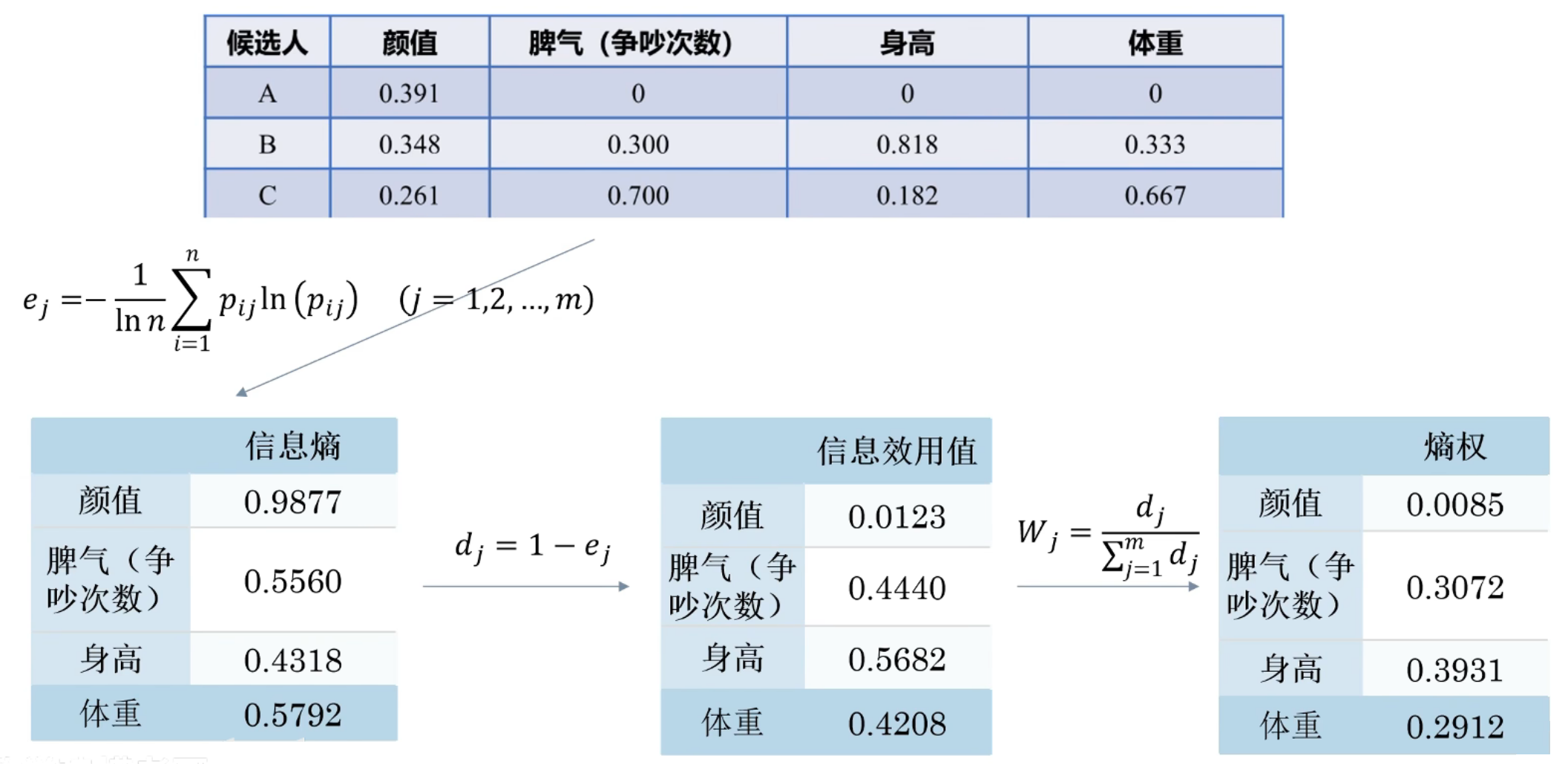
熵权法EWM
对于某个指标, 可以用熵值来判断某个指标的离散程度
信息熵值越小, 指标的离散程度就越大, 该指标的影响/权重就越大
(如果某项指标的值都相等, 则该指标不起作用)
(依据的原理: 指标的变异程度越小, 其反映的信息量越少, 对应的权重越低)
数据标准化
z i j = x i j ∑ i = 1 n x i j 2 z_{ij}=\frac{x_{ij}}{\sqrt{\sum_{i=1}^n}x_{ij}^2} zij=∑i=1n xij2xij
计算第j个指标下, 第i个样本所占的比重
p i j = z i j ~ ∑ i = 1 n z i j ~ p_{ij}=\frac{\widetilde{z_{ij}}}{\sqrt{\sum_{i=1}^n}\widetilde{z_{ij}}} pij=∑i=1n zij zij
计算熵权
e j = − 1 ln n ∑ i = 1 n p i j ln ( p i j ) ( j = 1 , 2 , . . . , m ) d j = 1 − e j W j = d j ∑ j = 1 m d j e_j = -\frac{1}{\ln n}\sum_{i=1}^n p_{ij} \ln(p_{ij}) \quad (j = 1,2,...,m) \\ d_j = 1 - e_j \\ W_j = \frac{d_j}{\sum_{j=1}^m d_j} ej=−lnn1i=1∑npijln(pij)(j=1,2,...,m)dj=1−ejWj=∑j=1mdjdj
除以 ln n \ln n lnn是为了使信息熵始终在0,1区间
由于信息熵 e j e_j ej越大, 其信息效用越小, 所以需要用1来减
-> 信息效用 d j d_j dj越大, 其权重 W j W_j Wj越大
例子:
组合赋权法
线性加权平均法:
设定参数 α , β α,β α,β 且 α + β = 1 α + β=1 α+β=1,则
W ∗ = α W A H P + β W E W M W^* = αW_{AHP} + βW_{EWM} W∗=αWAHP+βWEWM
可根据决策者对主客观判断的信任度调节 α , β α,β α,β
乘法组合法:
将对应指标的AHP和EWM权重相乘后归一化
w i ∗ = w i A H P ⋅ w i E W M ∑ j w j A H P ⋅ w j E W M w_i^* = \frac{w_i^{AHP} \cdot w_i^{EWM}}{\sum_j w_j^{AHP} \cdot w_j^{EWM}} wi∗=∑jwjAHP⋅wjEWMwiAHP⋅wiEWM
若两种方法对同一指标权重均高,则综合后该指标权重更突出
准备数据:已有指标数据并通过 AHP 求得 W A H P W_{AHP} WAHP,通过 EWM 求得 W E W M W_{EWM} WEWM
选择组合策略:根据需求选择加权平均法或乘法组合法
计算综合权重
归一化处理:若计算后 Σ w ≠ 1 \Sigma w≠1 Σw=1,则归一化使 Σ w ∗ = 1 \Sigma w^*=1 Σw∗=1
验证与分析:比较 w ∗ w^* w∗ 与 W A H P , W E W M W_{AHP},W_{EWM} WAHP,WEWM,分析组合后权重的变化特性
逼近理想解排序法TOPSIS
通过计算各方案与理想解和负理想解的距离, 对多个方案进行排序
核心思想: 最优方案应该同时最接近理想解和最原理负理想解
TOPSIS基于欧几里得距离
e.g. 供应商的选择, 投资策略, 资源分配
数据标准化(x->z)
加权处理(z->v)
确定理想解和负理想解
(分别计算各指标的最优值和最劣值)
理想解: A + = ( max ( v i 1 ) , max ( v i 2 ) , ... , max ( v i n ) ) 负理想解: A − = ( min ( v i 1 ) , min ( v i 2 ) , ... , min ( v i n ) ) \text{理想解:}\quad A^+ = \left(\max(v_{i1}), \max(v_{i2}), \dots, \max(v_{in})\right) \\ \text{负理想解:}\quad A^- = \left(\min(v_{i1}), \min(v_{i2}), \dots, \min(v_{in})\right) 理想解:A+=(max(vi1),max(vi2),...,max(vin))负理想解:A−=(min(vi1),min(vi2),...,min(vin))
计算距离
D i + : 第i个方案与理想解的欧几里得距离 D i − : 第i个方案与负理想解的欧几里得距离 D_i^+: \text{第i个方案与理想解的欧几里得距离} \\ D_i^-: \text{第i个方案与负理想解的欧几里得距离} Di+:第i个方案与理想解的欧几里得距离Di−:第i个方案与负理想解的欧几里得距离
计算贴近度
(贴近度越大, 方案越优)
C i = D i − D i + + D i − C_i = \frac{D_i^-}{D_i^+ + D_i^-} Ci=Di++Di−Di−
对于正互反矩阵A: A ∈ R n × n A\in\mathbb{R}^{n\times n} A∈Rn×n
A = a 11 a 12 ... a 1 n a 21 a 22 ... a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ... a n n A = \begin{bmatrix} a_{11} & a_{12} & \dots & a_{1n} \\ a_{21} & a_{22} & \dots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \dots & a_{nn} \end{bmatrix} A= a11a21⋮an1a12a22⋮an2......⋱...a1na2n⋮ann
a i j > 0 , a i i = 1 , a i j = 1 a j i a_{ij}>0,\quad a_{ii}=1,\quad a_{ij}=\frac{1}{a_{ji}} aij>0,aii=1,aij=aji1
其为一致矩阵的充要条件是:
{ a i j > 0 所有元素均大于 0 a 11 = a 22 = ⋯ = a n n = 1 对角线元素均为 1 a i 1 , a i 2 , ... , a i n = k i a 11 , a 12 , ... , a 1 n 矩阵每行成比例(r(A)=1) \begin{cases} a_{ij} > 0 & \text{所有元素均大于 0} \\ a_{11} = a_{22} = \dots = a_{nn} = 1 & \text{对角线元素均为 1} \\ \left a_{i1}, a_{i2}, \\dots, a_{in} \\right = k_i \left a_{11}, a_{12}, \\dots, a_{1n} \\right & \text{矩阵每行成比例(r(A)=1)} \end{cases} ⎩ ⎨ ⎧aij>0a11=a22=⋯=ann=1ai1,ai2,...,ain=kia11,a12,...,a1n所有元素均大于 0对角线元素均为 1矩阵每行成比例(r(A)=1)
故而, 一致矩阵只有一个特征值 n n n, 其余为0
特征值为n时, 其特征向量对应为:
k 1 a 11 1 a 12 ⋮ 1 a 1 n , k ≠ 0 k \begin{bmatrix} \frac{1}{a_{11}} \\ \frac{1}{a_{12}} \\ \vdots \\ \frac{1}{a_{1n}} \end{bmatrix}, \quad k \ne 0 k a111a121⋮a1n1 ,k=0
推论: n阶正互反矩阵A为一致矩阵 当且仅当 最大特征值 λ m a x = n \lambda_{max}=n λmax=n
若正互反矩阵A的最大特征值 λ m a x > n \lambda_{max}>n λmax>n, 则需要一致性检验(判断该矩阵的一致性是否在接受范围内)
补充-层次分析法若未通过一致性检验
1.算术平均法求权重
第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)
第二步:将归一化的各列相加(按行求和)
第三步:将相加后得到的向量中每个元素除以n即可得到权重向量
假设判断矩阵:
A = a 11 ... a 1 n ⋮ ⋱ ⋮ a n 1 ... a n n A= \begin{bmatrix} a_{11} & \dots & a_{1n} \\ \vdots & \ddots & \vdots \\ a_{n1} & \dots & a_{nn} \end{bmatrix} A= a11⋮an1...⋱...a1n⋮ann
那么算术平均法求得的权重向量:
w i = 1 n ∑ j = 1 n a i j ∑ k = 1 n a k j ( i = 1 , 2 , 3 , . . . , n ) w_i = \frac{1}{n}\sum_{j=1}^n \frac{a_{ij}}{\sum_{k=1}^n a_{kj}} \quad (i = 1,2,3,...,n) wi=n1j=1∑n∑k=1nakjaij(i=1,2,3,...,n)
2.几何平均法求权重
第一步:将判断矩阵的各行元素相乘得到的值组成一个列向量
第二步:将得到的列向量的每个分量开n次方
第三步:对该列向量进行归一化即可得到权重向量
假设判断矩阵:
A = a 11 ... a 1 n ⋮ ⋱ ⋮ a n 1 ... a n n A= \begin{bmatrix} a_{11} & \dots & a_{1n} \\ \vdots & \ddots & \vdots \\ a_{n1} & \dots & a_{nn} \end{bmatrix} A= a11⋮an1...⋱...a1n⋮ann
那么几何平均法求得的权重向量:
w i = ( ∏ j = 1 n a i j ) 1 n ∑ k = 1 n ( ∏ j = 1 n a k j ) 1 n ( i = 1 , 2 , . . . , n ) w_i = \frac{\left(\prod_{j=1}^n a_{ij}\right)^{\frac{1}{n}}}{\sum_{k=1}^n \left(\prod_{j=1}^n a_{kj}\right)^{\frac{1}{n}}} \quad (i = 1,2,...,n) wi=∑k=1n(∏j=1nakj)n1(∏j=1naij)n1(i=1,2,...,n)
3.特征值法求权重
一致矩阵有一个特征值 n n n,其余特征值均为 0 0 0
另外,我们很容易得到,特征值为 n n n时,对应的特征向量刚好为权重向量
假如我们的判断矩阵一致性可以接受,那么我们可以仿照一致矩阵权重的求法
第一步:求出矩阵 A A A的最大特征值 λ m a x \lambda_{max} λmax以及其对应的特征向量 x x x
第二步:对求出的特征向量进行归一化即可得到我们的权重
( A − λ m a x E ) x = 0 (A-\lambda_{max}E)x=0 (A−λmaxE)x=0