微软近期正式推出新一代 AI 加速器 Microsoft Azure Maia 200。作为 Maia GPU 系列的第二代产品,这款芯片从一开始就被明确定位为面向 AI 模型推理的专用加速器,而非通用训练 GPU。在官方披露的信息中,微软将 Maia 200 称为"史上部署的最高效推理系统",并多次强调其在性能、能效以及可持续性方面的综合优势。

Maia 200技术规格
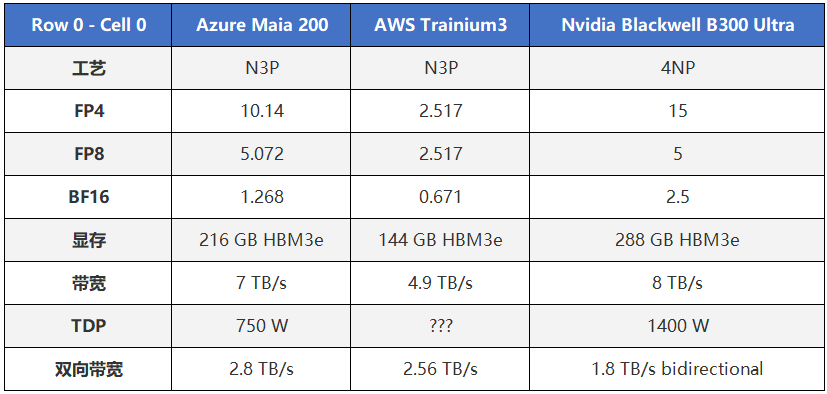
从已公开参数看,Maia 200 采用 TSMC 3nm 制程,配备 216GB HBM3e 高带宽显存,并在多项推理相关指标上,表现优于亚马逊、谷歌等超大规模云厂商的定制化 AI 芯片方案。微软给出的一个核心结论是:在功耗明显提升的情况下,Maia 200 的每美元性能较上一代 Maia 100 提升了约 30%。
这个数字之所以值得关注,是因为 Maia 200 的标称热设计功耗(TDP)相比 Maia 100 提高了约 50%。换句话说,这并不是通过"压功耗"换来的账面效率,而是一次在更高功耗区间内实现的真实性能跃迁。
如果只停留在官方结论层面,很容易把 Maia 200 看成一次"常规升级"。但当我们把它放回推理系统的工程语境中,会发现微软在这颗芯片上的取舍相当明确。
能效优先,而非峰值算力优先
在与英伟达 Blackwell B300 Ultra 的讨论中,很多声音试图直接对比二者性能,但这种比较本身并不完全成立。Maia 200 并不对外销售,其服务对象是 Azure 内部的 AI 负载;而 B300 Ultra 面向的是更高强度、更通用的算力需求场景,且背后有成熟的软件与生态体系支撑。
但即便如此,Maia 200 在能效层面的优势仍然值得单独拎出来讨论。
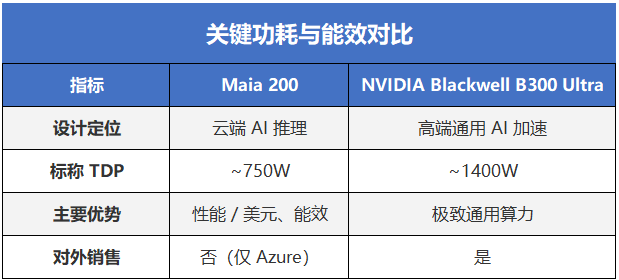
在当前 AI 能耗与碳排放问题被频繁讨论的背景下,运行功耗几乎减半本身就是一项极具现实意义的优势。更重要的是,结合 Maia 100 的历史表现,这个 750W 并不一定等同于实际运行功耗。
上一代 Maia 100 的设计功耗为 700W,但微软公开表示其在真实部署中通常被限制在 约 500W 左右运行,这意味着 Maia 200 在实际环境中的能效表现,仍存在进一步释放空间。
对推理计算精度的高度针对性设计
Maia 200 并未追求 FP16 / FP32 的全面覆盖,而是重点优化 FP4 与 FP8 精度下的性能。这一选择背后,并非技术激进,而是工程现实:
在经过量化与校准之后,大多数大模型在推理阶段对低精度具备较高容忍度,而 FP4/FP8 带来的吞吐提升与能耗下降,往往远超精度损失所带来的影响。这也决定了 Maia 200 的应用边界:
它非常适合高并发、低延迟、成本敏感的推理场景,但并不适合复杂训练任务或研究型负载。
内存层级结构优化
真正体现 Maia 200 "推理取向"的,是它在内存层级结构上的投入。
除了 216GB HBM3e,微软在芯片内部集成了 272MB 高效 SRAM,并将其拆分为两层结构:
●CSRAM(集群级 SRAM)
●TSRAM(瓦片级 SRAM)
这种设计的核心目标,并不是单纯提高带宽,而是实现 HBM 与 SRAM 之间的负载均衡与智能调度。在大规模推理场景中,数据访问模式高度碎片化,如果缺乏足够的片上缓存与合理的调度机制,算力单元往往会被内存延迟"拖住"。
Maia 200 在 SRAM 上的投入,本质上是在为推理系统减少"无效等待"。
需要说明的是,目前很难对 Maia 200 与 Maia 100 的性能提升做更精细的量化比较。微软公布的两代
芯片官方参数表,几乎没有直接可对齐的指标。现阶段能够确认的只有两点:
1.Maia 200 的运行功耗与工作温度将高于 Maia 100
2.其每美元性能提升约 30%
这在一定程度上也反映了一个事实:微软更关注的是系统级推理效率,而非单点参数对比。

从行业视角看,Maia 200 并不是一颗"挑战 NVIDIA 地位"的芯片,而是一次对 AI 推理成本结构的重新拆解。训练与推理正在走向不同的硬件路径,通用 GPU 与专用加速器开始各司其职,而云端与本地算力的选择逻辑也随之分化。
在实际项目中,我们也越来越多地看到客户同时评估云端专用推理算力与本地 AI 服务器方案的组合方式------在不同阶段、不同负载下选择最合适的算力形态,而不是依赖单一架构。