「解决VLM导航"走一步停一步"难题」
目录
[01 语音不仅控制座舱,并且参与驾驶决策](#01 语音不仅控制座舱,并且参与驾驶决策)
[02 技术亮点](#02 技术亮点)
主动语义查询(ADTR):减少"问模型"的次数,但提高每次的价值
[03 实验与表现](#03 实验与表现)
[04 总结](#04 总结)
在仿真里,无人机可以慢慢想。但在真实世界,它只能一边飞,一边决定。
很多看起来"很智能"的语义导航方法,一旦走出实验室,就会因为模型推理慢而导致飞行频繁中断。
为了解决这个"快飞慢想"的矛盾,南方科技大学周博宇团队提出了一种反直觉的解法------AirHunt。
他们没有继续堆模型能力,而是把注意力放在了一个更工程化的问题上:让 VLM 不再直接"指挥动作",而是以一种可持续、可复用的方式参与导航决策,从而在真实飞行节奏下依然保持语义引导能力。
01 语音不仅控制座舱,并且参与驾驶决策
传统做法里,VLM 往往被当成"决策大脑":
看到一帧图像 → 推理 → 给出下一个动作或方向。
但 AirHunt 反其道而行之,提出了一个关键转变:
VLM 不负责"下一步怎么飞",只负责回答"哪些地方值得去"。
于是,整套系统被拆成了两条并行的节奏:
一条是慢速的语义推理路径
无人机在飞行过程中,主动挑选关键视角,请 VLM 判断哪些区域更可能存在目标,并持续更新一个三维语义价值分布。
另一条是高速的连续规划路径
飞行控制和路径规划始终以高频运行,从三维语义地图中"读取"线索,而不是等待新的模型输出。
这样一来,语义推理不再是飞行的"刹车片",而是变成了一种可被反复读取、逐步累积的空间记忆。
从系统视角看,AirHunt 的核心不是某个模型,而是一个重新设计的协作关系:
语义负责"指路",规划负责"走路",两者互不拖慢。
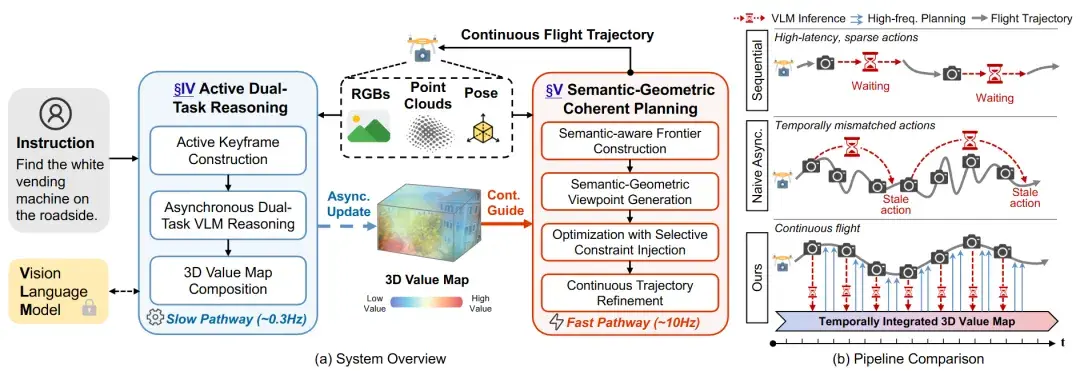
图1|系统整体框架与不同导航流程的对比。(a) AirHunt 的核心是一个双通路的异步系统架构。一条通路以较低频率运行,由视觉语言模型提取与指令相关的语义信息,并持续更新三维语义价值地图;另一条通路以高频运行,从这张语义地图中实时读取线索,生成连续、可执行的飞行轨迹。两条通路各自按最合适的频率工作,互不阻塞,但始终保持协同。(b) 不同导航流程的对比示意。顺序式方法需要无人机悬停等待模型推理,导致飞行断断续续、搜索效率极低;简单异步方法虽然允许飞行,但动作基于过时观测,容易出现决策错位;相比之下,AirHunt 将 VLM 定位为高层语义生成器,并把语义信息积累到三维空间中,使无人机能够在持续飞行中获得稳定、连贯的语义引导
02 技术亮点
主动语义查询(ADTR):减少"问模型"的次数,但提高每次的价值
在 AirHunt 中,VLM 并不是每一帧都被调用。系统会主动筛选那些最可能改变导航决策的视角,只在这些关键时刻才请求语义推理。
这样做的直接效果是显著降低了推理频率,避免了无人机因为等待模型而被迫停飞。更重要的是,减少无意义的查询还能降低语义判断在时间上的抖动,让系统的整体行为更加稳定。
从真实部署角度看,这一步并不是"为了省算力",而是为了让语义推理真正跟得上飞行节奏。
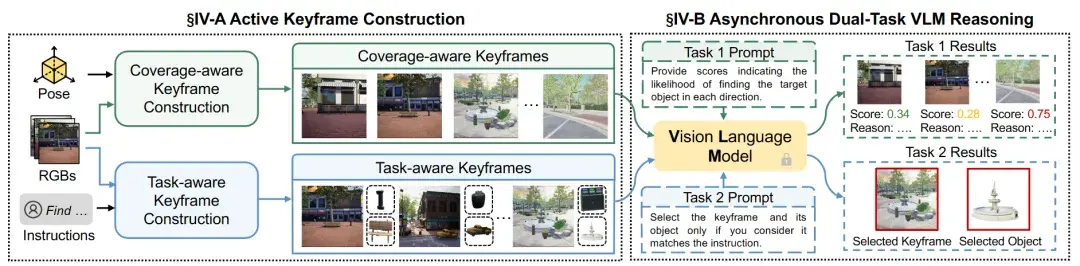
图2|系统会主动构建两类关键帧集合:一类关注环境覆盖情况,用于评估哪些区域更值得探索;另一类聚焦任务相关区域,用于核验目标是否存在。这两类关键帧分别送入视觉语言模型,完成语义价值评估和目标确认两项任务,在减少无效推理的同时,提高每一次语义判断的决策价值
三维语义价值地图:让语义线索跨时间"留存"下来
AirHunt 并不把 VLM 的输出当作一次性的决策结果,而是将其映射到三维空间中,形成持续更新的语义价值分布。
这意味着语义信息不会随着视角切换而立刻消失。
当无人机飞离某个区域,甚至暂时看不到目标时,规划器依然可以从这张三维语义地图中读取历史证据,判断哪些方向仍然值得探索。这种设计极大增强了系统对真实环境中遮挡、视角变化和长距离搜索的适应性,是从"看一眼就忘"走向"空间记忆"的关键一步。
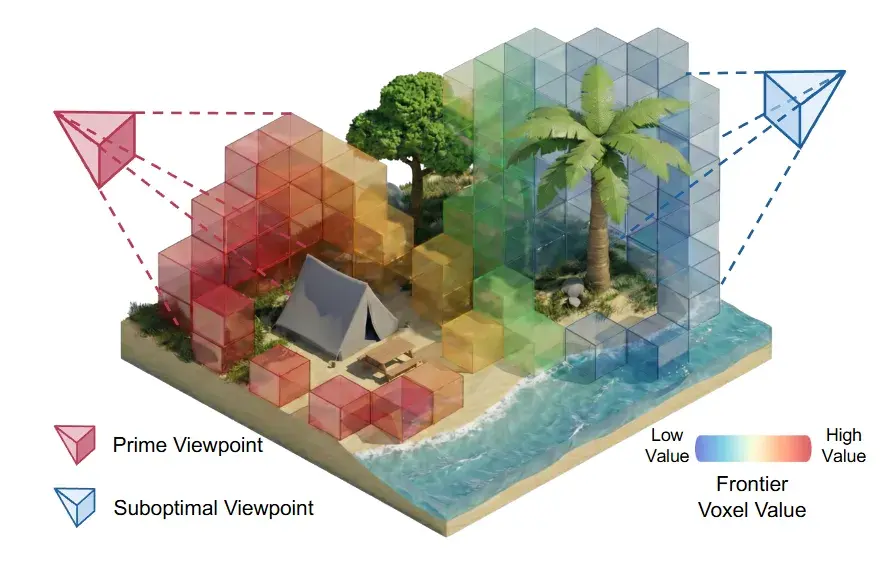
图3|语义-几何协同的视点选择示意。在"飞向海滩上的帐篷"这一指令下,靠近目标区域的前沿体素被赋予更高的语义价值(红色区域)。系统通过计算不同视点下可观测前沿区域的语义信息增益,自动选择最有价值的观察位置。这种设计使无人机能够主动朝着"最有希望看到目标"的方向飞行,而不是盲目遍历空间
语义-几何一致规划(SGCP):既听语义,也尊重飞行代价
在规划阶段,AirHunt 并没有简单地把语义分数和几何代价做线性加权。相反,它通过一致性约束,让语义引导在可行的情况下发挥作用,而在代价过高或风险过大时自动退让。
这使得无人机不会因为"盲目追语义"而绕远路,也不会在语义不确定时陷入犹豫。
路径选择始终保持连续、可执行,并且符合飞行平台的运动约束。从工程角度看,这一步解决的不是"规划最优",而是规划是否能长期稳定运行。
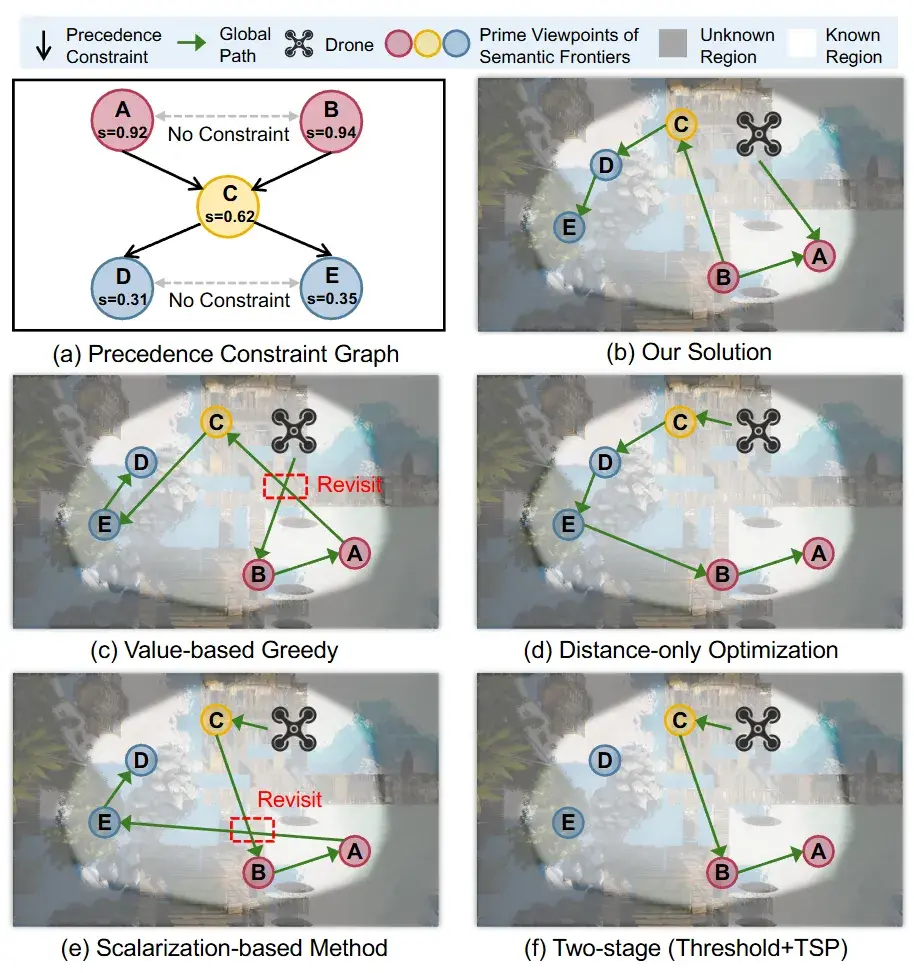
图4|不同全局规划策略的路径对比。(a) 约束图示意:只有当语义价值差异显著时,系统才强制优先访问高价值区域;当多个区域语义相近时,则交由几何规划自由优化。(b) AirHunt 生成的全局路径能够优先覆盖高语义价值区域,并避免重复访问。(c)--(f) 对比方法往往会反复进入已经搜索过的区域(红色虚线框),或延迟访问关键语义区域,导致整体搜索效率下降
03 实验与表现
在大尺度仿真环境中,AirHunt 在多项关键指标上都表现出明显优势。
在成功率(SR)方面,AirHunt 达到了 73.1% ,显著高于所有自动化基线方法,并且已经接近人类飞手的 80.5% 水平。
这表明在目标搜索任务中,系统能够更稳定地完成从起点到目标的完整闭环。
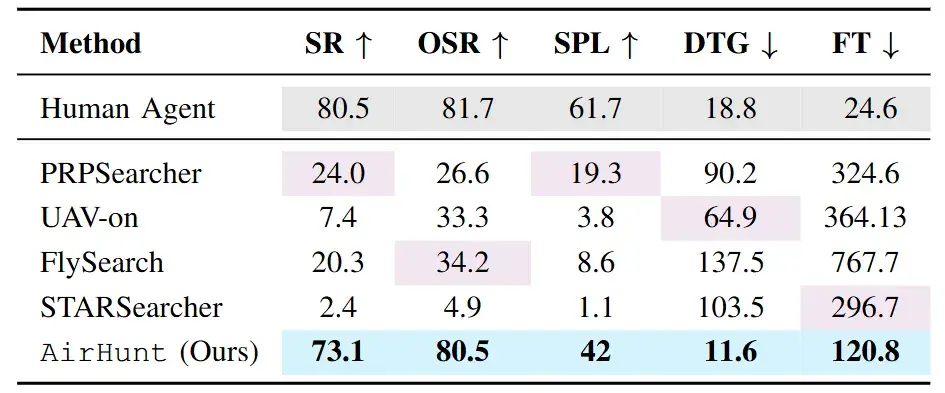
图5|不同方法在成功率、飞行时间等核心指标上的整体表现对比。表中高亮显示了最优结果和次优结果,并给出了人类飞手作为参考上限,便于直观理解系统与人工操作之间的差距
在飞行效率上,AirHunt 的平均飞行时间(FT)为 120.8 秒,相比最强基线方法缩短了约 59%。这一差距并非来自更激进的飞行策略,而是源于减少了反复探索和无效绕行。
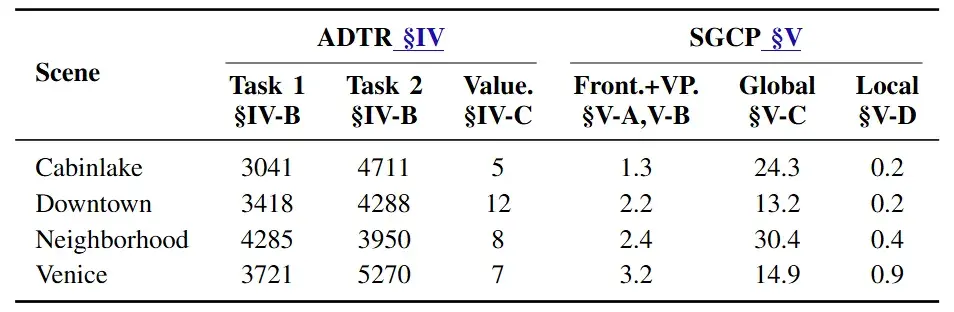
图6|关键组件的平均计算开销。列出了系统中各个核心模块的平均计算时间(毫秒),展示 AirHunt 在保证实时性的同时,仍能稳定运行在无人机平台上
作者在分析中指出,这种效率提升主要来自三个方面:
● 一是异步架构避免了因等待语义推理而造成的停飞;
● 二是主动语义查询减少了低价值的决策干扰;
● 三是语义-几何一致规划显著降低了重复访问区域的情况。

图7|左侧为场景的俯视图,右上为无人机第一视角画面,右下为对应的三维语义价值地图。可以看到,语义信息被稳定地积累在空间中,并持续引导无人机向高价值区域移动
在真实室外场景的飞行实验中,系统同样展现出稳定行为。
无人机在长距离搜索过程中几乎不再出现"停下来思考"的现象,飞行轨迹更加连贯,语义引导也更具方向性。

图8|真实飞行实验在三个具有挑战性的室外环境中进行,包括公园区域(E-1)、景观区域(E-2)和居民区(E-3)。每个任务中,第一张图展示整体场景的俯视关系,其余图片记录无人机在执行任务过程中的不同状态。黄色圆圈标记无人机位置,红色矩形标记目标物体
这些结果共同说明,AirHunt 的优势并不只体现在指标上,而是在整体飞行行为层面更接近真实可部署系统的需求。
04 总结
AirHunt 展示的,并不是一个更大的模型,而是一种更清醒的系统设计观。当视觉语言模型进入具身系统,真正的挑战往往不在"能不能看懂",而在看懂之后,这些信息要以什么形式、在什么节奏下,参与真实世界的运动决策。
REF
论文标题:AirHunt: Bridging VLM Semantics and Continuous Planning for Efficient Aerial Object Navigation
论文链接:https://arxiv.org/pdf/2601.12742
论文作者:Xuecheng Chen, Zongzhuo Liu, Jianfa Ma, Bang Du, Tiantian Zhang, Xueqian Wang, and Boyu Zhou