摘要:本篇内容围绕 InnoDB 存储引擎核心知识展开,详解其体系架构(后台线程、内存池、磁盘文件及整体工作流程),同时系统介绍了 MySQL 各类日志文件的作用。


第二章 InnoDB存储引擎
2.3 InnoDB体系架构
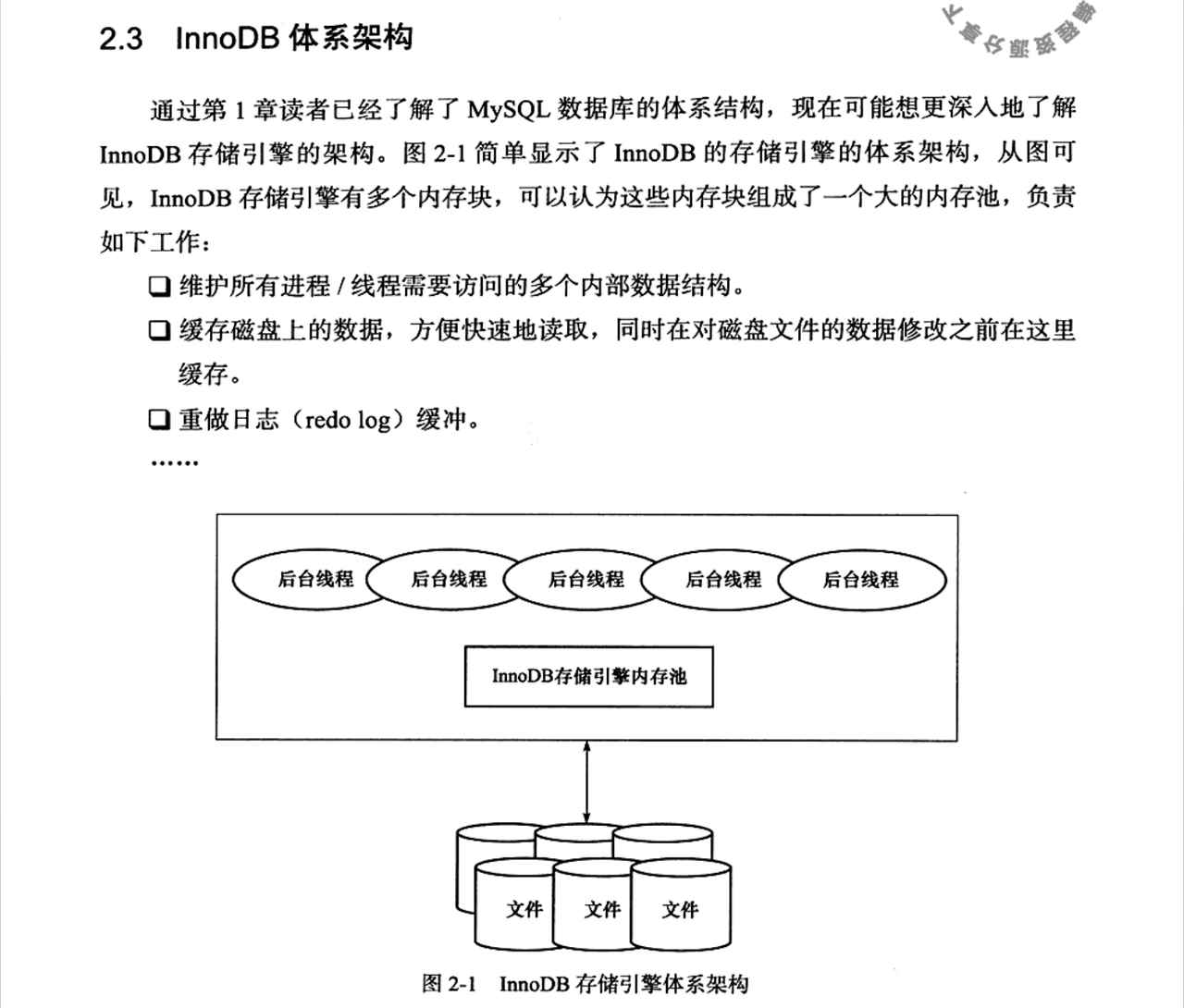
++最上层:后台线程(Background Threads)++
InnoDB 通过多线程模型来提升性能和稳定性,这些后台线程各司其职:
-
Master Thread:核心后台线程,负责将缓冲池中的数据异步刷新到磁盘,保证数据一致性,还包括脏页刷新、合并插入缓冲、Undo 页回收等关键操作。
-
IO Thread:负责处理读写 IO 请求,分为读、写、插入缓冲、日志等不同类型的 IO 线程,通过并发处理提升效率。
-
Purge Thread:用于回收事务提交后不再需要的 Undo 日志,避免 Undo 文件无限膨胀。
-
Page Cleaner Thread :它的核心作用是将原本由 Master Thread 承担的脏页刷新操作,剥离到单独线程 中执行。这一设计旨在减轻 Master Thread 的工作负担,减少对用户查询线程的阻塞,从而有效提升 InnoDB 存储引擎的并发性能。
++中间层:InnoDB 存储引擎++ ++内存池++ ++(Buffer Pool & More)++
这是 InnoDB 性能的核心,它不是单一结构,而是由多个内存块组成的内存池,主要包含:
- 缓冲池 (Buffer Pool):这是最核心的部分,用来缓存磁盘上的表数据和索引数据,让大部分读写操作都在内存中完成,大幅提升速度。

-
重做日志缓冲(Redo Log Buffer):缓存要写入重做日志(redo log)的数据,会定期或在事务提交时刷新到磁盘的重做日志文件,用于崩溃恢复。
-
额外的内存结构:包括锁信息、自适应哈希索引、事务信息等,支撑 InnoDB 的事务和并发控制能力。
它的核心作用:
-
维护所有进程 / 线程需要访问的内部数据结构,比如锁、事务信息。
-
缓存磁盘数据,避免频繁的磁盘 IO,加速数据读写。
-
缓冲重做日志,提升日志写入效率。
++最下层:磁盘文件(Disk Files)++
这是数据的最终持久化存储,主要包含:
-
表空间文件(Tablespace):分为系统表空间、独立表空间等,存储表数据和索引。
-
重做日志文件(Redo Log Files):记录了数据的修改操作,是 InnoDB 实现崩溃恢复的关键。
-
Undo 日志文件(Undo Logs):用于事务回滚和多版本并发控制(MVCC),保存数据修改前的镜像。
-
其他文件:如插入缓冲、双写缓冲(Double Write)等辅助文件,用于提升性能和可靠性。
++整体工作流程++
-
当你执行增删改查时,InnoDB 会先在内存池的缓冲池中操作数据。
-
修改的数据会被标记为 "脏页",并在后台线程的调度下异步刷新到磁盘。
-
所有修改操作都会先写入重做日志缓冲,再定期刷入磁盘的重做日志文件,保证崩溃后可以恢复。
-
后台线程持续进行脏页刷新、日志回收等工作,维持系统的性能和稳定性。

结合 LRU 算法的特性,自增主键确实能显著提升 InnoDB 缓冲池的内存读写效率,具体逻辑是这样的:
++自增主键的写入特性++
-
自增主键是按顺序递增的,新插入的行总是被追加到索引树的最右侧叶子节点。
-
这意味着新数据页的加载是顺序的、连续的,每次加载的新页都会被直接放到 LRU 列表的前端。
-
不会出现随机主键那种频繁 "跳跃式" 加载分散数据页的情况。
++与 LRU 算法的高效配合++
-
在 LRU 机制下,最近被访问的页会被保留在列表前端,而最少被访问的页会被淘汰。
-
自增主键的顺序写入,让新数据页在加载后会被频繁访问,自然留在 LRU 列表的活跃区域。
-
这避免了频繁淘汰活跃页和重新加载冷页的开销,大幅减少了缓冲池的 "颠簸"。

++核心优化:Midpoint Insertion Strategy++
InnoDB 没有采用朴素的 LRU 算法,而是引入了中点插入策略(midpoint insertion strategy),核心设计是:
-
在 LRU 列表中加入了
midpoint位置,默认在列表长度的 37% 处(可通过innodb_old_blocks_pct参数调整)。 -
新读取到的页,不会直接放入 LRU 列表首部,而是插入到
midpoint位置。 -
以此为界,列表被分为两部分:
-
new 列表(前半部分):存放最活跃的热点数据,会被频繁访问。
-
old 列表(后半部分):存放相对不活跃的冷数据,容易被淘汰。
-
++为什么要做这个优化?++
这是为了解决朴素 LRU 的一个关键缺陷:全表扫描或索引扫描这类一次性操作,会把大量冷页刷入 LRU 列表首部,从而挤走真正的热点数据。
-
比如执行一次
SELECT * FROM large_table,会加载大量只在本次查询中用到的页。 -
如果用朴素 LRU,这些冷页会直接进入 LRU 首部,把活跃的热点数据挤到尾部甚至被淘汰。
-
当下次再访问热点数据时,就需要重新从磁盘加载,导致性能下降。
通过中点插入策略,这些冷页会被先放到 old 列表中。只有当它们在后续被再次访问时,才会被移动到 new 列表的首部,这样就保护了真正的热点数据不被轻易淘汰。

这段内容清晰地解释了 InnoDB 中脏页、LRU 列表与 Flush 列表的关系,我帮你梳理成更直观的结构:
++脏页(Dirty Page)的定义++
当 LRU 列表中的页被修改后,缓冲池中的数据与磁盘上的数据就产生了不一致,这样的页就被称为脏页。
++两个列表的分工++
|----------|-------------------------|------------|
| 列表类型 | 核心作用 | 管理目标 |
| LRU 列表 | 管理缓冲池中页的可用性,决定哪些页会被优先淘汰 | 内存资源的高效利用 |
| Flush 列表 | 管理脏页的刷新顺序,决定哪些脏页会被刷回磁盘 | 数据持久化与崩溃恢复 |
- 一个脏页会同时存在于 LRU 列表和 Flush 列表中,但两个列表的管理逻辑完全独立、互不影响。
++CHECKPOINT 机制++
这是 InnoDB 保证数据一致性的核心机制,它会定期将 Flush 列表中的脏页刷新回磁盘,主要作用是:
-
确保脏页不会无限期留在内存中,避免数据库崩溃时需要恢复的 redo log 过大。
-
控制缓冲池的脏页比例,维持系统的读写性能。
2.4 Checkpoint 技术

++背景:缓冲池与性能矛盾++
-
缓冲池的设计是为了协调 CPU 与磁盘的速度差异,所有页的修改操作都会先在内存中完成。
-
如果每次页修改后都立即刷盘,会产生巨大的 IO 开销,严重影响性能。
-
为了保证事务的持久性(Durability),数据库采用 Write Ahead Log(WAL) 策略:事务提交时,先写入重做日志(redo log),再修改缓冲池中的页。
++理想场景的不现实性++
理论上,如果满足以下两个条件,脏页可以永远不刷回磁盘:
-
缓冲池足够大,能缓存所有数据库数据
-
重做日志可以无限增大
但在现实中,这两个条件都无法满足:
-
缓冲池容量有限,必须淘汰旧页以加载新页
-
重做日志文件大小固定,写满后必须循环覆盖旧日志
如果不及时刷脏页,当旧日志被覆盖后,一旦发生宕机,就无法通过重做日志恢复数据。
++Checkpoint 的三大核心目标++
|--------------|------------------------------------------------------------|
| 目标 | 场景与作用 |
| 缩短数据库恢复时间 | 宕机后,只需恢复 Checkpoint 之后的重做日志,无需回放全部历史日志,大幅提升恢复效率。 |
| 缓冲池不足时刷新脏页 | 当缓冲池空间不足时,通过 Checkpoint 将部分脏页刷回磁盘,释放内存空间以加载新数据。 |
| 重做日志不可用时刷新脏页 | 重做日志是循环写的,当旧日志即将被覆盖时,Checkpoint 会刷新对应脏页,确保这些修改已持久化,避免数据丢失。 |
2.6 InnoDB关键特性
2.6.1 插入缓冲

++设计目的与核心原理++
-
问题背景:非聚集索引(辅助索引)的叶子节点通常是离散的,直接插入会产生大量随机 IO,影响性能。
-
核心思路:对于非聚集索引的插入 / 更新,先判断目标索引页是否在缓冲池中:
-
如果在,直接插入;
-
如果不在,就先写入 Insert Buffer 这个临时结构(InnoDB 的 Insert Buffer 区域在磁盘上是连续的,缓存写入和批量刷盘时,磁头不用来回移动,直接连续读写),再在后台以一定频率批量合并到实际的索引页中。(合并随机IO)
-
-
性能收益:将多次离散的插入合并为一次批量操作,减少了随机 IO,显著提升非聚集索引的插入性能。
++使用条件++
Insert Buffer 必须同时满足以下两个条件才能生效:
-
索引是辅助索引(secondary index),而不是聚簇索引;
-
索引是非唯一(non-unique)的。
**为什么不能是唯一索引?**因为插入时需要检查唯一性,这会触发离散的索引页读取,与 Insert Buffer 减少随机 IO 的设计初衷相悖。

2.6.2 两次写(Double Write)

++Double Write(两次写)核心逻辑解析++
++为什么需要 Double Write?++
要理解 Double Write,必须先明白它要解决的 "部分写失效" 问题:
数据页与磁盘原子性不匹配
-
InnoDB 的数据页大小是 16KB ,而绝大多数磁盘的原子写入单位只有 4KB。
-
当一个 16KB 的页刷盘时,磁盘需要分 4 次完成写入。
-
如果在这 4 次写入过程中发生宕机(比如第 2 次写完后断电),导致部分写失效。
重做日志的局限性
-
重做日志(redo log)记录的是 "在页的某个偏移量写入什么内容" 这类物理操作。
-
如果页本身已损坏(如只有前 4KB 有效),直接应用重做日志是无效的,因为操作的基础已经不存在了。
-
所以,恢复的前提是先有一个完整的页副本,再在这个副本上应用重做日志。
++核心原理:先写副本,再刷磁盘++
Double Write 的本质是为数据页准备一个 "安全副本",确保在应用重做日志前,有一个完整的页可以用来恢复。它由两部分组成:
-
内存层(Double Write Buffer):大小为 2MB 的内存缓冲,临时存放待刷盘的脏页。
-
磁盘层(Double Write 物理区域):位于共享表空间中,是连续的 128 个页(2MB),用于存储脏页副本。
++完整工作流程(刷新++ ++脏页++ ++时)++
当缓冲池中的脏页需要刷新回磁盘时,Double Write 会按以下步骤执行:
-
内存复制:从缓冲池到 Double Write Buffer
-
第一次写:写入磁盘副本区域
-
第二次写:写入实际表空间
-
InnoDB 会先通过
memcpy函数,把要刷盘的脏页批量复制到内存中的 Double Write Buffer。这一步是纯内存操作,速度极快,没有任何磁盘 IO。 -
内存缓冲中的脏页会被分成两次(每次 1MB),顺序写入 到磁盘上的 Double Write 物理区域。写入完成后,会立即调用
fsync()函数,确保数据真正落盘,避免操作系统缓存带来的风险。这个过程是顺序 IO,因为 Double Write 区域是连续的,磁头不需要来回移动,性能开销很小。 -
确认副本区域写入成功后,InnoDB 才会把这些脏页写入到实际的 表空间 文件 (如
.ibd文件)中。这一步的写入位置是离散的(因为数据页在表空间中是随机分布的),属于随机 IO。
++宕机恢复流程++
如果在刷盘过程中发生宕机,InnoDB 启动时会通过 Double Write 进行恢复:
-
检测损坏页:扫描所有数据页,检查哪些页在刷盘时发生了部分写失效。
-
从副本还原:对于损坏的页,从 Double Write 物理区域中读取对应的完整页副本,覆盖损坏的页。
-
应用重做日志:在还原后的完整页上,应用重做日志,恢复到宕机前的最新状态。
第三章 文件
3.2 日志文件
3.2.1 错误日志

这段内容系统介绍了 MySQL 错误日志的定位、作用和使用场景:
核心作用
错误日志是 MySQL 最重要的诊断日志之一,它完整记录了:
-
数据库启动、运行、关闭的全流程信息
-
所有错误信息(如启动失败、连接异常、崩溃恢复)
-
警告信息(如配置不兼容、性能瓶颈预警)
-
部分正常运行状态信息
它是排查问题的 "第一入口",尤其是当数据库无法启动或运行异常时,错误日志是首要检查的文件。
定位与命名规则
-
查看路径 :通过
SHOW VARIABLES LIKE 'log_error'可以直接获取错误日志的存储路径和文件名,例如图中的结果为/mysql_data_2/stargazer.log。 -
默认命名 :默认情况下,错误日志的文件名以服务器主机名命名,格式为
[hostname].err。图中主机名为stargazer,因此默认文件名为stargazer.err。
3.2.2 慢查询日志

这段内容系统讲解了慢查询日志的作用、配置和使用场景:
核心作用:
慢查询日志是 SQL 语句性能优化的核心工具,主要用于:
-
捕获执行时间超过阈值的 SQL 语句
-
定位存在性能问题的查询,为优化提供依据
-
长期监控数据库的 SQL 执行效率,预防性能问题
它和错误日志的定位不同:错误日志聚焦数据库运行故障,慢查询日志聚焦 SQL 语句层面的性能瓶颈。
关键配置参数
-
long_query_time:慢查询的时间阈值,默认值为 10 秒。执行时间超过该值的 SQL 会被记录到其中。 -
log_slow_queries:慢查询日志的开关,默认状态为关闭(OFF)。需要手动设置为 ON 才能启用。


mysqldumpslow 的核心作用就是对慢查询日志进行聚合和统计分析,将重复的慢 SQL 归类,并展示执行次数、耗时等关键指标,让你能快速找到最影响性能的 SQL。
3.2.3 查询日志

查询日志会记录所有发送到 MySQL 服务器的请求信息,无论这些请求是否成功执行。
-
包含内容:所有 SQL 语句(查询、插入、更新、删除等)、连接与断开事件、错误请求等。
-
关键特点:它是 "全量" 日志,不像慢查询日志只记录耗时超标的 SQL。
3.2.4 二进制日志

二进制日志是 MySQL 最重要的日志之一,它记录了所有对数据库数据进行修改的操作 ,但不包含 SELECT、SHOW 这类只读操作。
-
包含操作 :
INSERT、UPDATE、DELETE、CREATE TABLE、ALTER TABLE等数据变更操作。 -
特殊情况 :即使操作最终没有改变数据(如
UPDATE t SET a=1 WHERE id=999但 id=999 不存在),这类操作也可能被记录,以保证日志的完整性。

为什么 READ COMMITTED 会引发主从不一致?
-
在
READ COMMITTED隔离级别下,事务每次读取都会获取最新的已提交数据,这会导致同一个事务内的两次查询结果可能不同(不可重复读)。 -
早期 MySQL 的二进制日志默认使用 STATEMENT 格式 (记录 SQL 语句而非物理变更)。当主库在
READ COMMITTED下执行依赖当前数据状态的 SQL(如UPDATE t SET a=a+1 WHERE id=1)时,从库回放该 SQL 可能因为数据状态不同,导致执行结果不一致,出现 "丢失更新"。

- STATEMENT 格式
-
记录内容 :记录的是执行的逻辑 SQL 语句,如
UPDATE t SET a=1 WHERE id=2。 -
优点:日志体积小,性能开销低,可读性好。
-
缺点 :当 SQL 包含不确定函数(如
UUID())、依赖当前数据状态时,从库回放可能得到不同结果,导致主从不一致。 -
适用场景:仅在数据量小、SQL 逻辑简单且无不确定函数的场景下使用。
- ROW 格式
-
记录内容 :不记录 SQL 语句,而是记录行的物理变更,如 "将
t表中id=2的行的a字段从0改为1"。 -
优点 :彻底解决 STATEMENT 格式的主从不一致问题,复制可靠性最高;支持
READ COMMITTED隔离级别,提升并发性能。 -
缺点:日志体积大,性能开销略高;可读性差,需要解析工具才能看懂。
-
适用场景:生产环境的默认推荐格式,尤其是对数据一致性要求高的场景。
- MIXED 格式
-
记录策略:默认使用 STATEMENT 格式记录,当遇到特定场景时自动切换为 ROW 格式,包括:
-
表的存储引擎为 NDB
-
使用
UUID()、USER()等不确定函数 -
使用
INSERT DELAY语句 -
使用用户定义函数(UDF)
-
使用临时表(temporary table)
-
-
优点:兼顾 STATEMENT 的性能和 ROW 的一致性,是一种折中方案。
-
适用场景:希望平衡性能与一致性的场景。
3.6 InnoDB 存储引擎文件
3.6.2 重做日志文件

这段内容系统讲解了 InnoDB 重做日志的基础定义、作用和架构设计,我帮你梳理成结构化要点,让你清晰理解它的核心价值:
++基础定义与默认文件++
-
文件位置 :默认存储在 InnoDB 数据目录下,文件名通常为
ib_logfile0和ib_logfile1。 -
本质:记录了 InnoDB 事务的物理变更操作,是保证数据持久性(ACID 中的 D)的核心组件。
++核心作用:故障恢复++
重做日志的核心价值是在实例或介质故障时恢复数据,比如:
-
当数据库因主机掉电、进程崩溃等原因异常关闭时,InnoDB 会在重启时回放重做日志。
-
通过重做日志,将数据恢复到宕机前的最新状态,保证数据的完整性。
它和二进制日志的区别是:
-
重做日志:面向 InnoDB 存储引擎,用于崩溃恢复,保证数据不丢失。
-
二进制日志:面向整个 MySQL 服务器,用于主从复制和时间点恢复。
恭喜你学习完本节内容!✿