一、什么是 scikit-learn?
scikit-learn (简称 sklearn)是 Python 中最流行的开源机器学习库之一。它建立在 NumPy、SciPy 和 Matplotlib 之上,提供了大量高效、易用的工具,用于:
- 数据预处理(标准化、编码等)
- 模型训练(分类、回归、聚类等)
- 模型评估(准确率、交叉验证等)
- 特征选择与降维
无论是初学者还是资深工程师,sklearn 都是快速实现机器学习原型的首选工具。
二、如何安装 scikit-learn?
方法 1:使用 pip(推荐)
pip install scikit-learn方法 2:使用 conda(如果你用 Anaconda)
conda install scikit-learn三、KNN 算法简介
KNN(K-Nearest Neighbors,K近邻) 是一种简单但强大的监督学习算法,常用于分类和回归任务。
1、KNN 分类
- 预测目标是离散类别标签
- 找出待预测样本最近的 K 个训练样本,通过"投票"决定其类别。
2、 算法步骤
- 计算待预测点 xx 与所有训练样本的距离;
- 选择距离最小的 K 个邻居;
- 统计这 K 个邻居中各类别出现的次数;
- 将出现次数最多的类别作为 xx 的预测结果。
示例
假设 K=5,5 个最近邻居的类别为:[A, A, B, A, C]
→ A 出现 3 次(最多) → 预测结果为 A
💡 若出现平票(如 K=4,结果为 A, A, B, B),sklearn 默认选择索引最小的类别 ,所以最好将K设置为奇数。
3、KNN 回归
- 预测目标是连续数值(如:房价、温度、股票价格等)。
- 找出待预测样本最近的 K 个训练样本,取它们目标值的平均值(或加权平均)作为预测结果。
4、算法步骤
- 计算待预测点 x 与所有训练样本的距离;
- 选择距离最小的 K 个邻居;
- 取这 K 个邻居对应的目标值 y1,y2,...,yk ;
- 计算它们的算术平均值(或加权平均):
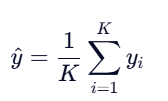
或加权形式(距离越近权重越大):
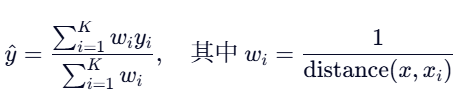
示例
K=3,3 个邻居的目标值为:[10.2, 9.8, 10.5]
→ 预测值 = (10.2+9.8+10.5)/3=10.17(10.2+9.8+10.5)/3=10.17
四、KNN 中的距离计算公式
KNN 依赖"距离"衡量相似性。常用距离有:
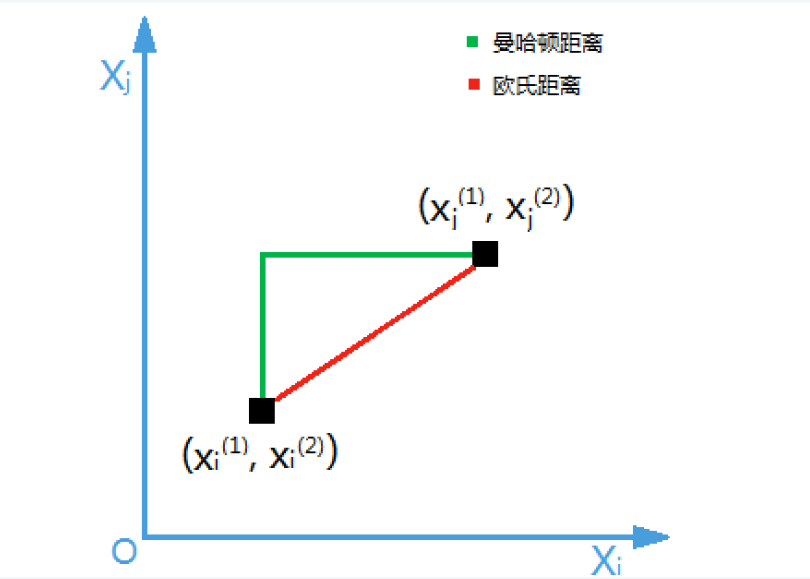
1. 欧式距离

scikit-learn 默认使用欧式距离。
2. 曼哈顿距离
也称"城市街区距离",适用于网格状路径,用于计算两个点之间轴平行线的距离只和。
n 维空间计算公式:
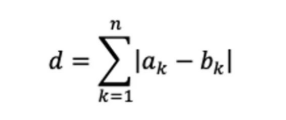
欧式距离与曼哈顿距离的区别:
五、实战:用 KNN 分类鸢尾花(Iris Dataset)
鸢尾花数据集是机器学习的"Hello World"!包含 150 个样本,3 种花(Setosa、Versicolor、Virginica),每种 50 个,4 个特征:
- 花萼长度(sepal length)
- 花萼宽度(sepal width)
- 花瓣长度(petal length)
- 花瓣宽度(petal width)
1、加载鸢尾花数据
python
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data # 特征矩阵 (150, 4)
y = iris.target # 标签 (150,),0/1/2 代表三种花sklearn是一个强大的 Python 机器学习库。它内置了许多经典数据集(如鸢尾花、手写数字、波士顿房价等),都放在datasets模块中。- 从
iris对象中取出特征数据 (即输入变量),并赋值给变量X - 从
iris对象中取出目标标签 (即输出变量/真实类别),并赋值给变量y
从datasets 模块中导出的鸢尾花数据如下所示:
2、划分训练集和测试集(7:3)
python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)-
train_test_split函数是 scikit-learn 提供的标准数据划分工具,用于将数据集拆分为训练和测试部分。 -
将数据集
X(特征)和y(标签) 随机划分为 训练集 和 测试集 ,比例为 7:3。 -
random_state=42控制随机打乱的顺序, 若不设置,每次运行结果都不同;也可用0、123等 -
stratify=y保证训练集和测试集中各类别比例相同。
3、特征标准化
对特征数据进行 Z-Score 标准化,使得每个特征的均值为 0、标准差为 1。
什么是Z-Score 标准化?
Z-Score 标准化(是一种常用的数据预处理方法,其核心目标是将原始数据转换为均值为 0、标准差为 1 的分布形式,从而消除不同特征之间的量纲(单位)和数值尺度差异。
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) - StandardScaler是 scikit-learn 提供的标准化工具,用于将数据转换为均值为 0、方差为 1 的分布。
标准化的正确流程
| 步骤 | 代码 | 作用 |
|---|---|---|
| 1. 创建标准化器 | scaler = StandardScaler() |
初始化 |
| 2. 学习训练集统计量并转换 | X_train_scaled = scaler.fit_transform(X_train) |
fit + transform |
| 3. 用训练集参数转换测试集 | X_test_scaled = scaler.transform(X_test) |
仅 transform |
4、创建并训练KNN模型
python
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5) # 创建KNN模型实例
knn.fit(X_train_scaled, y_train) # 训练模型(拟合)KNeighborsClassifier是 sklearn 提供的用于分类任务的 KNN 实现, 适用于监督学习中的多分类问题(如鸢尾花种类、手写数字识别等)。- K 值:预测时参考的最近邻居数量,通常取奇数(避免平票),默认值是 5。
- 将标准化后的训练特征
X_train_scaled和对应的真实标签y_train"喂给"模型,完成训练。 .fit()这一步非常快 (只是复制数据),但后续.predict()较慢(需计算距离)。
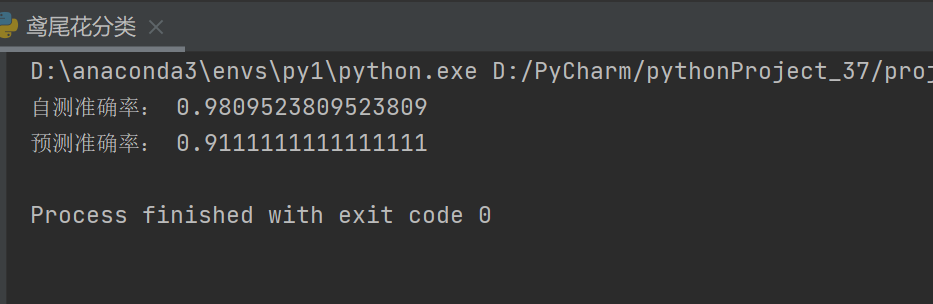
5、自测与预测
python
from sklearn.metrics import accuracy_score
score = knn.score(X_train_scaled, y_train)
print("自测准确率:", score)
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("预测准确率:", accuracy)方法一 ------ 使用模型内置 .score()
-
knn.score(X, y_true)是 scikit-learn 模型的标准评估接口; -
它内部自动执行:
pythony_pred = self.predict(X) return accuracy_score(y_true, y_pred)
X:特征数据(必须是模型训练时的输入格式,如标准化后的数据)y_true:真实标签(不是预测值!)
方法二 ------ 使用 accuracy_score() 手动计算
python
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("预测准确率:", accuracy)- 先预测 :
knn.predict(X_test_scaled)→ 得到测试集预测结果y_pred; - 再评估 :
accuracy_score(y_test, y_pred)→ 比较真实标签y_test和预测标签y_pred
完整代码
python
# 导入所需库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征矩阵 (150, 4)
y = iris.target # 标签 (150,),0/1/2 代表三种花
# 2. 划分训练集和测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 3. 特征标准化(KNN 对量纲敏感!)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 注意:只 transform 测试集!
# 4. 创建并训练 KNN 模型(k=5)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_scaled, y_train)
# 5. 自测与预测
y_self = knn.predict(X_train_scaled)
score = knn.score(X_train_scaled, y_self)
print("自测准确率:", score)
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("预测准确率:", accuracy)
print("测试集准确率:", accuracy)
# 输出示例:测试集准确率: 1.0 (几乎完美!)运行结果: