目录
一.先看一个问题
1.痛点:大模型无法回答私有知识相关的问题
当我们问大模型一些公司私有的东西,它并不能做出回答,尽管可以开放大模型的联网功能,查询网络上的相关信息,但是我所问的是公司内部的私有知识,网上也没有相关信息,所以大模型根本不可能回答出来这个问题。
2.解决方案:搭建一个RAG知识库
我们可以搜集这些私有的知识(比如公司手册、管理手册、内部文件等等内部资源),然后把这些知识存到一个地方(RAG知识库),从而供大模型后续参考,这样大模型就能回答公司的内部知识了。
二.什么是RAG知识库?
1.定义
RAG知识库(Retrieval-Augmented Generation Knowledge Base) 是一种结合了信息检索 和大语言模型生成能力 的智能系统。它的核心目标是让AI在回答问题时,能够从指定的、可靠的资料库中获取信息,而不是仅仅依赖训练时学到的通用知识,从而生成更准确、可靠且可追溯的答案。
2.RAG知识库的工作原理
①没挂RAG知识库的场景
没挂RAG知识库时,我们只能问大模型一些通用的问题,而无法获取未公开的知识(比如公司内部架构、管理制度、内部系统使用方法等等)。因为你们公司内部的知识,大模型不可能知道,所以根本回答不了。
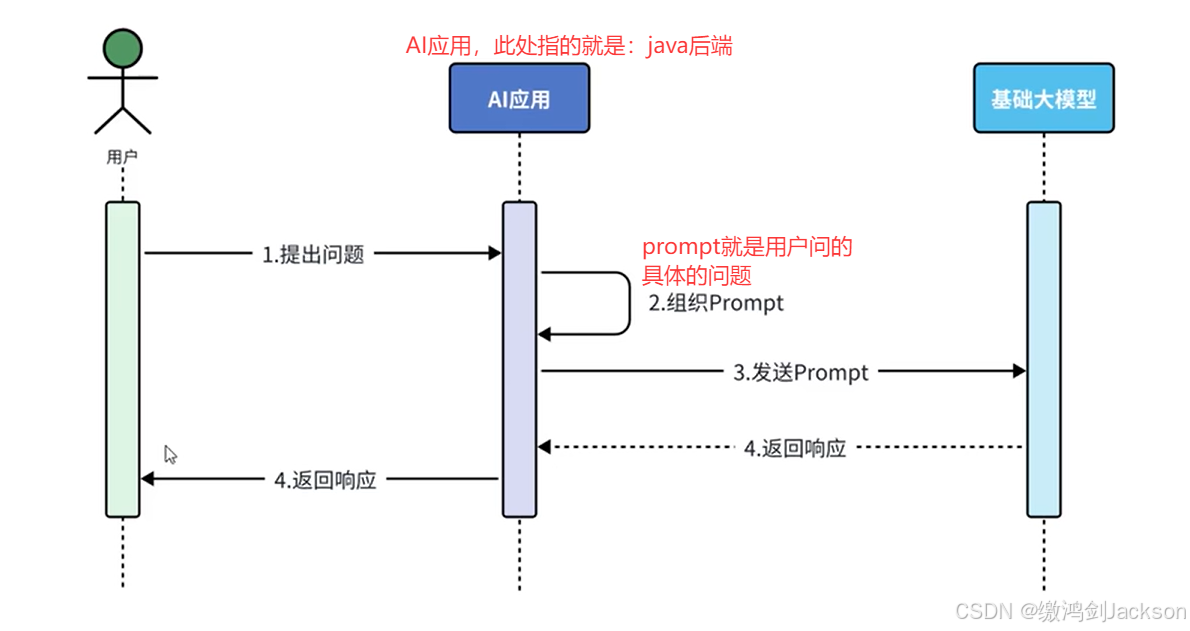
②外挂RAG知识库的场景
如下图,当用户问一些未公开的内部问题时,Java后端会先根据问题,去RAG知识库找响应的知识片段,然后java后端带着这些知识片段,再调用大模型,这样一来,大模型就知道未公开的知识了,也就可以回答你问的未公开的内部问题了。
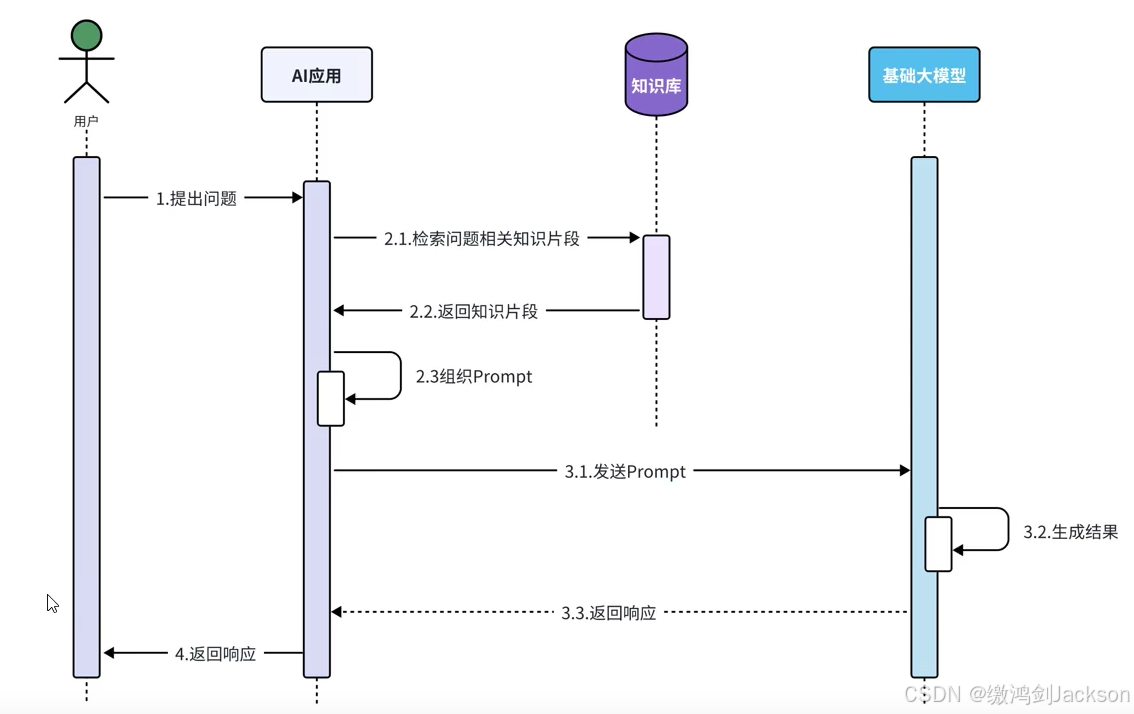
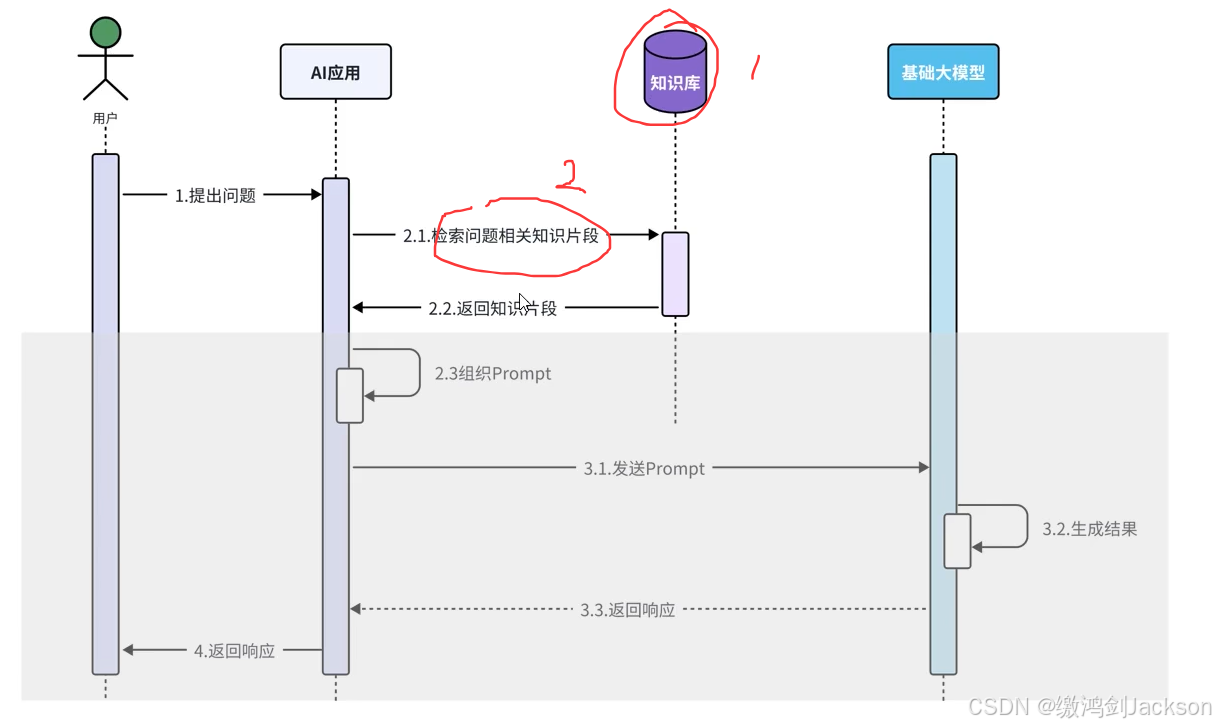
3.我们应该关注哪些点?
如下图,灰色部分,langchain4j会替我们解决,我们无需关心。
我们要关注的就红圈的两点:
①RAG知识库如何搭建?
②如何根据用户的提问,从RAG知识库检索出相关的知识片段?
这两点后续文章会详细讲解。
三.向量数据库
1.为什么学习向量数据库?
我们可以使用向量数据库,来实现RAG知识库这个需求。
2.向量数据库有哪些?

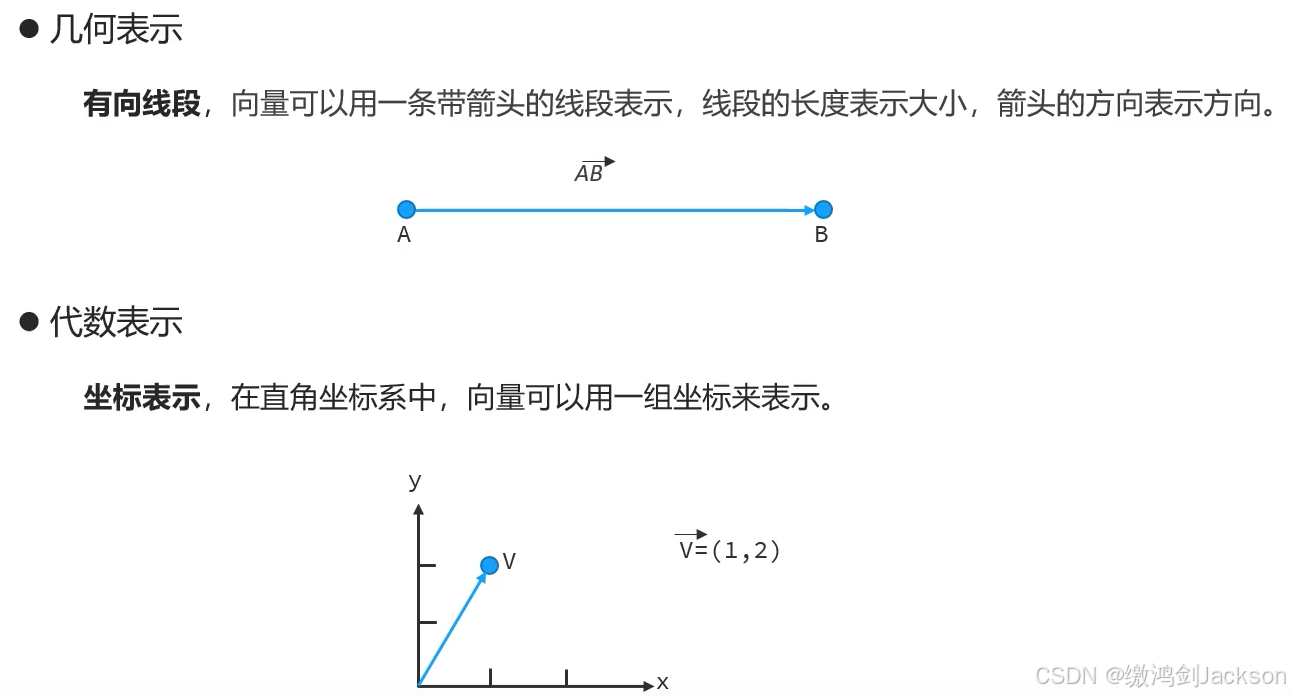
3.什么是向量?(高中知识,看看就行)
在数学中,表示大小和方向的量。
4.余弦相似度(要求不高,记住结论即可)
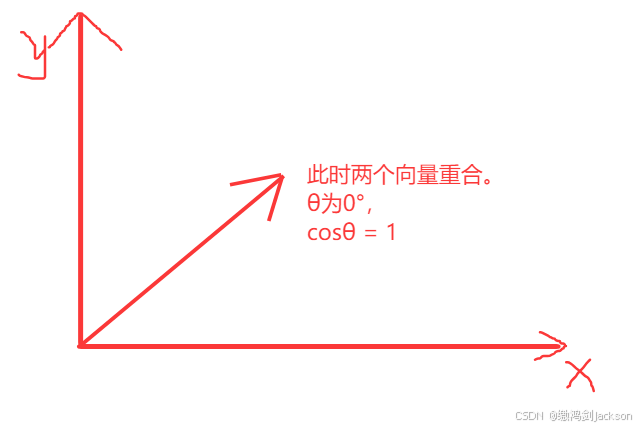
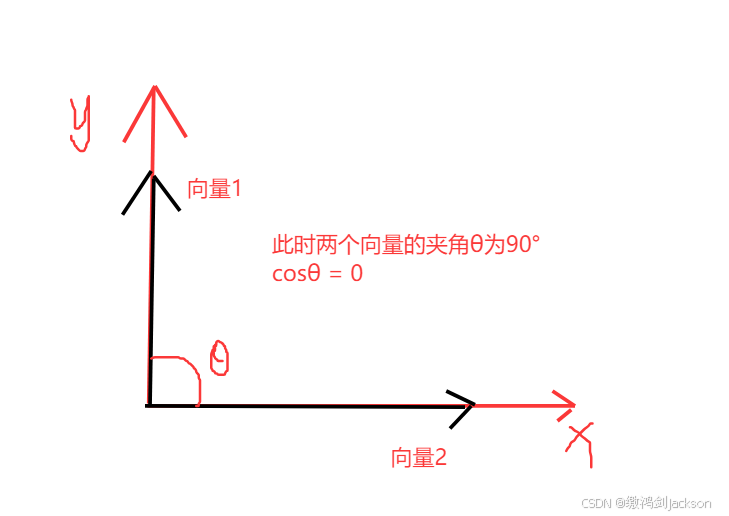
如下图,θ是两个向量的夹角,那cosθ就是所谓的余弦相似度。

下面取两个极限情况:
①当两个向量重合,夹角为0,余弦相似度最大,为1
②当两个向量垂直,夹角为90°,余弦相似度最小,为0
结论:余弦相似度越大,说明向量方向越接近
5.由二维向量,拓展到N维向量(道理相同,一点都不难)
由于我们RAG知识库,存的知识片段,抽象成一个向量时,肯定不是二维的,而是几百~几千个维度的,但是无论多少个维度,道理都是相同的。如下:

四.如何使用向量数据库,存储数据?
1.流程图
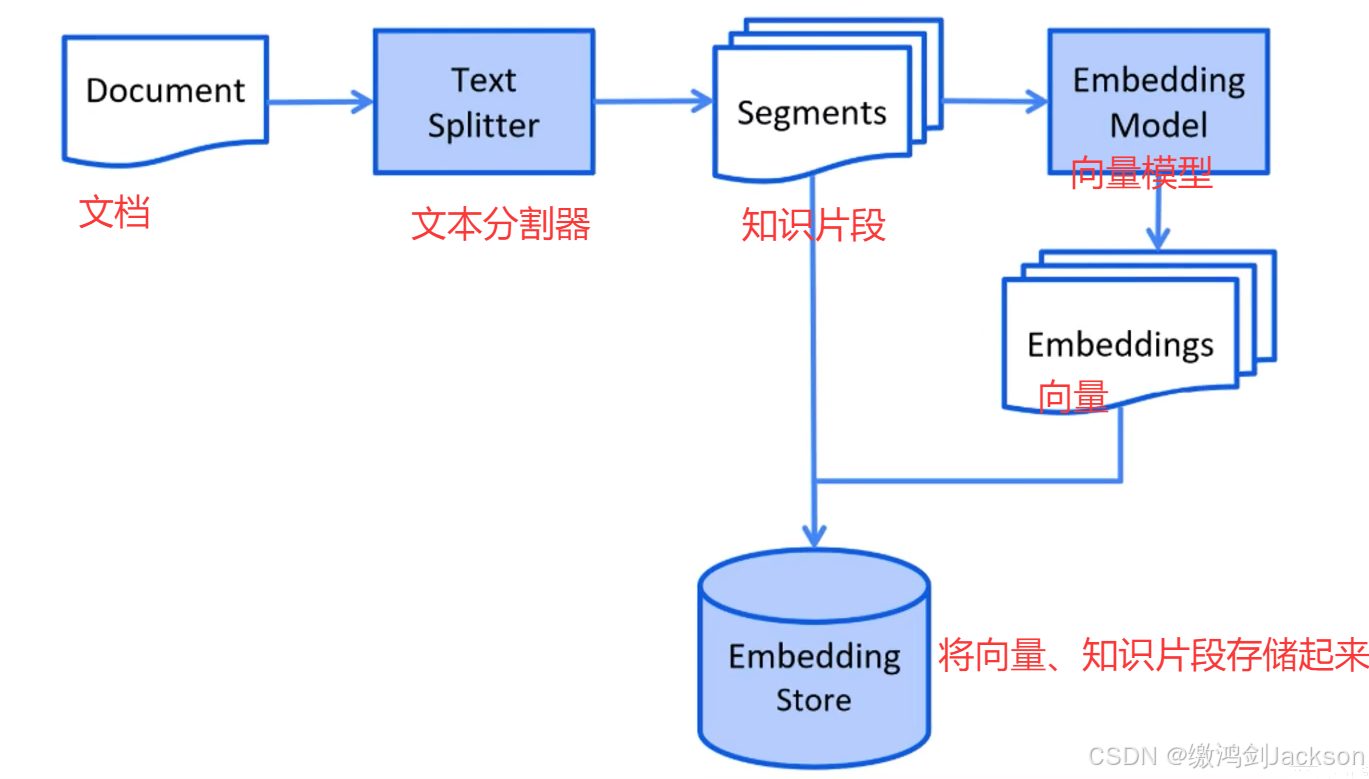
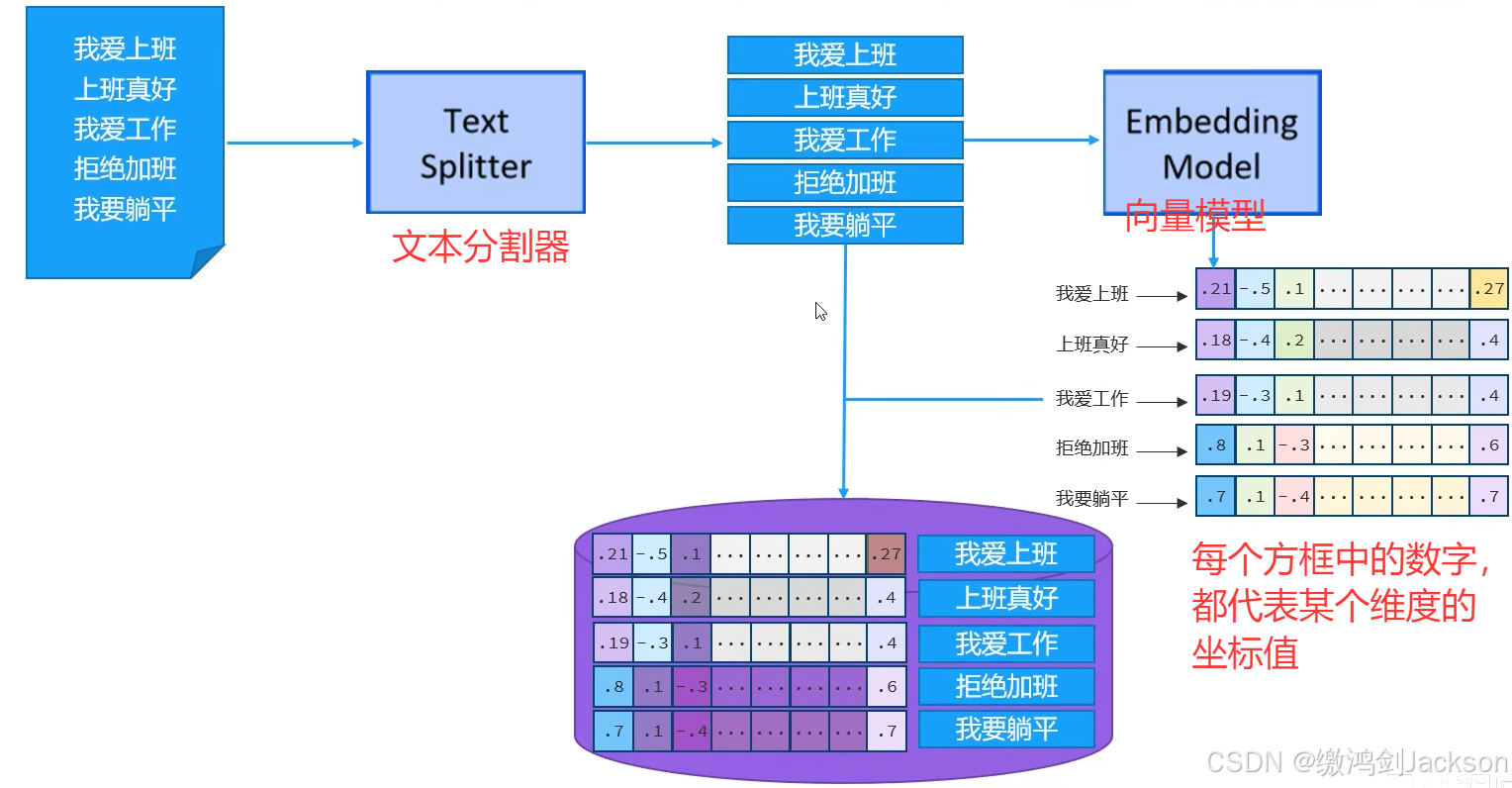
①将公司内部的未公开的知识,存储到文档(Document)中
②借助文本分割器(Text Splitter),将文档分割成一个个小的文本片段(知识片段)
③借助于向量模型(专门用于将文本进行向量化的大模型),将文本片段(知识片段)转换成向量
④将每一个向量及其对应的文本片段(知识片段),存到向量数据库即可。
2.举例
五.如何从向量数据库中,检索出和用户问题相关的文本片段?
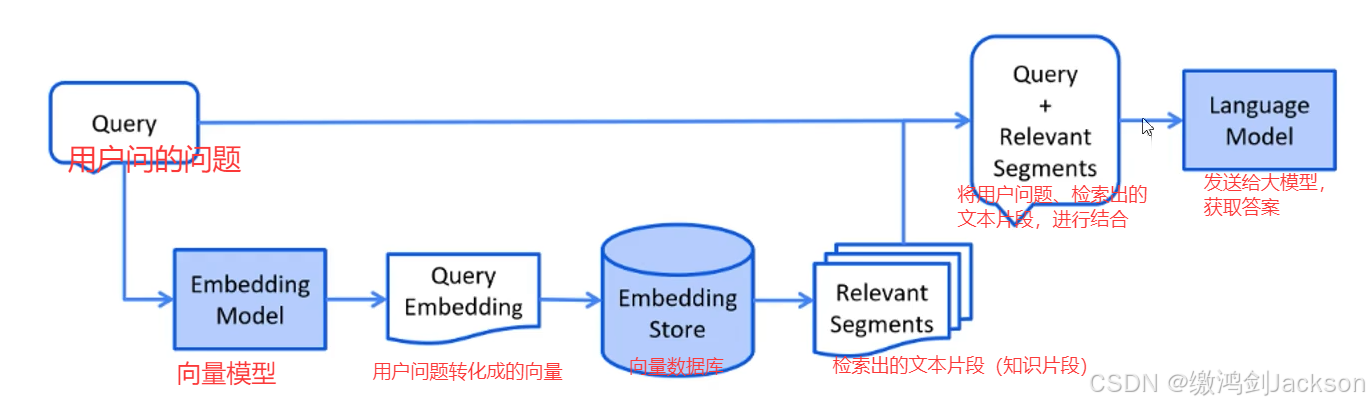
1.流程图
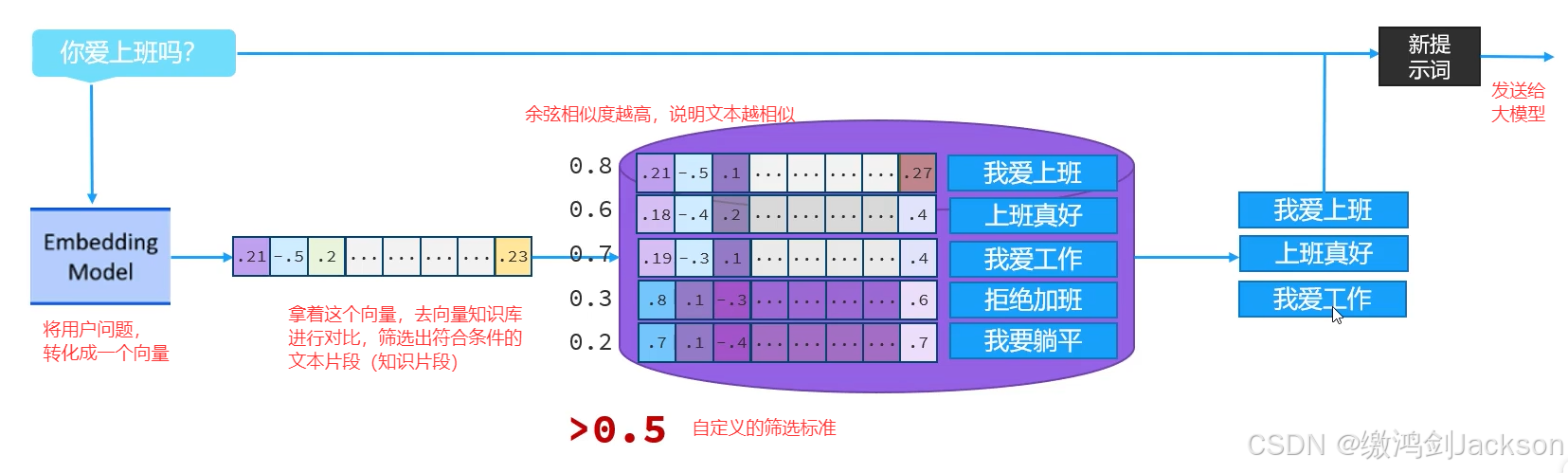
①将用户问的问题,使用向量模型,转化成向量
②拿着这个向量,和向量数据库中存储的向量进行比对,计算它们之间的余弦相似度
③把满足要求(比如余弦相似度必须大于0.6)的向量拿出来,得到对应的文本片段(知识片段)
④将用户的问题、检索出的文本片段(知识片段)结合,一块发给大模型,获取答案
2.举例
总结

以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~