文章目录
-
- Linux线程概念与控制(四):glibc源码剖析与实现原理
- 一、准备工作:glibc源码获取
-
- [1.1 为什么要阅读源码](#1.1 为什么要阅读源码)
- [1.2 关键源码文件](#1.2 关键源码文件)
- [二、struct pthread:线程控制块详解](#二、struct pthread:线程控制块详解)
-
- [2.1 TCB结构概览](#2.1 TCB结构概览)
- [2.2 TCB在内存中的位置](#2.2 TCB在内存中的位置)
- [2.3 验证TCB位置](#2.3 验证TCB位置)
- 三、pthread_create源码分析
-
- [3.1 pthread_create入口函数](#3.1 pthread_create入口函数)
- [3.2 allocate_stack:栈分配详解](#3.2 allocate_stack:栈分配详解)
- [3.4 create_thread:创建内核线程](#3.4 create_thread:创建内核线程)
- [3.5 do_clone和__clone](#3.5 do_clone和__clone)
- [3.6 start_thread:线程入口](#3.6 start_thread:线程入口)
- 四、完整流程图
-
- [4.1 pthread_create完整流程](#4.1 pthread_create完整流程)
- [4.2 关键步骤时序图](#4.2 关键步骤时序图)
- [五、线程标识体系:pthread_t vs tid vs tgid(彻底不再混)](#五、线程标识体系:pthread_t vs tid vs tgid(彻底不再混))
-
- [5.1 两套世界:用户态 pthread vs 内核态 task_struct](#5.1 两套世界:用户态 pthread vs 内核态 task_struct)
- [5.2 核心结论](#5.2 核心结论)
- [5.3 一张图理解:一个进程内多个线程的 pid/tgid](#5.3 一张图理解:一个进程内多个线程的 pid/tgid)
- [5.4 对照表:pthread_t / TCB / tid / tgid 各是谁](#5.4 对照表:pthread_t / TCB / tid / tgid 各是谁)
- [5.5 pthread_self() 到底返回谁?](#5.5 pthread_self() 到底返回谁?)
- [5.6 glibc 如何把内核 tid 写入 TCB(pd->tid)](#5.6 glibc 如何把内核 tid 写入 TCB(pd->tid))
- [5.7 一句话总结(最常考点)](#5.7 一句话总结(最常考点))
- 六、性能优化与缓存
-
- [6.1 线程栈缓存](#6.1 线程栈缓存)
- [6.2 TCB缓存](#6.2 TCB缓存)
- 七、系列总结
-
- [7.1 四篇文章回顾](#7.1 四篇文章回顾)
- [7.2 核心知识体系](#7.2 核心知识体系)
- [7.3 实战建议](#7.3 实战建议)
- 八、结语
Linux线程概念与控制(四):glibc源码剖析与实现原理
💬 承接上文:经过前三篇的学习,我们已经掌握了线程的基本概念、pthread库的核心API、以及线程在进程地址空间中的布局。但作为一个追求深入理解的开发者,我们还想知道:pthread_create调用后,glibc内部到底做了什么?线程栈是如何申请的?TCB结构包含哪些字段?clone系统调用如何创建LWP?本篇将带你深入glibc源码,彻底揭开Linux线程实现的神秘面纱!
👍 学习目标:理解pthread_create的完整实现流程、掌握TCB(struct pthread)结构、理解allocate_stack如何分配栈空间、掌握clone系统调用的工作原理、理解用户态线程与内核态LWP的关联关系。
🚀 源码级深入:本篇会涉及glibc源码和内核接口,需要一定的C语言基础和耐心,但收获将是巨大的!
一、准备工作:glibc源码获取
1.1 为什么要阅读源码
bash
阅读源码的价值:
1. 理解API背后的实现细节
2. 掌握线程创建的完整流程
3. 了解性能优化的关键点
4. 遇到问题时能定位根因
5. 提升编程内功
NPTL线程库:
- Native POSIX Thread Library
- glibc 2.3.2之后的默认线程实现
- 一对一线程模型(一个pthread对应一个LWP)
- 性能优异1.2 关键源码文件
bash
glibc源码中与线程相关的文件:
nptl/pthread_create.c # pthread_create实现
nptl/allocatestack.c # 栈分配
nptl/descr.h # struct pthread定义
nptl/pthreadP.h # 内部头文件
sysdeps/unix/sysv/linux/createthread.c # create_thread
sysdeps/unix/sysv/linux/clone.c # clone封装
我们将重点分析这些文件的关键代码二、struct pthread:线程控制块详解
2.1 TCB结构概览
在第三篇中我们知道pthread_t指向TCB,现在让我们看看TCB的真实面貌:
c
/* 简化版的 struct pthread (来自nptl/descr.h) */
struct pthread
{
union
{
/* 这个联合体必须是第一个成员 */
tcbhead_t header; // 线程控制块头部
void *__padding[24];
};
/* 线程ID (内核返回的tid,即LWP) */
pid_t tid;
/* 线程栈信息 */
void *stackblock; // 栈的起始地址(低地址)
size_t stackblock_size; // 总分配大小(包括guard page)
size_t guardsize; // guard page大小
/* 线程属性 */
int detachstate; // PTHREAD_CREATE_JOINABLE 或 DETACHED
int schedpolicy; // 调度策略
struct sched_param schedparam; // 调度参数(优先级等)
/* 线程退出相关 */
void *result; // 线程返回值
struct pthread *joinid; // 等待join这个线程的线程
/* 取消相关 */
int cancelhandling; // 取消状态和类型
/* 线程特定数据(TSD) */
void **specific; // pthread_key_t相关
/* 清理处理程序栈 */
struct _pthread_cleanup_buffer *cleanup;
/* 标志位 */
int flags;
/* 更多字段... */
};📌 关键字段解释:
bash
1. header (tcbhead_t)
- 必须是第一个成员
- 包含 TLS/TCB 头部信息(线程局部存储、DTV、指向自身等),供运行时和编译器生成的 TLS 访问使用
2. tid (pid_t)
- 内核返回的线程ID
- 就是LWP
- 可以通过gettid()系统调用获取
3. stackblock / stackblock_size
- 记录线程栈的地址和大小
- pthread_attr_getstack可以查询
4. detachstate
- PTHREAD_CREATE_JOINABLE: 可join
- PTHREAD_CREATE_DETACHED: 已分离
5. result
- 存储线程的返回值
- pthread_join通过这个字段获取返回值
6. cancelhandling
- 线程取消状态
- 线程取消类型2.2 TCB在内存中的位置
TCB并不是单独malloc出来的,而是和线程栈一起分配的:
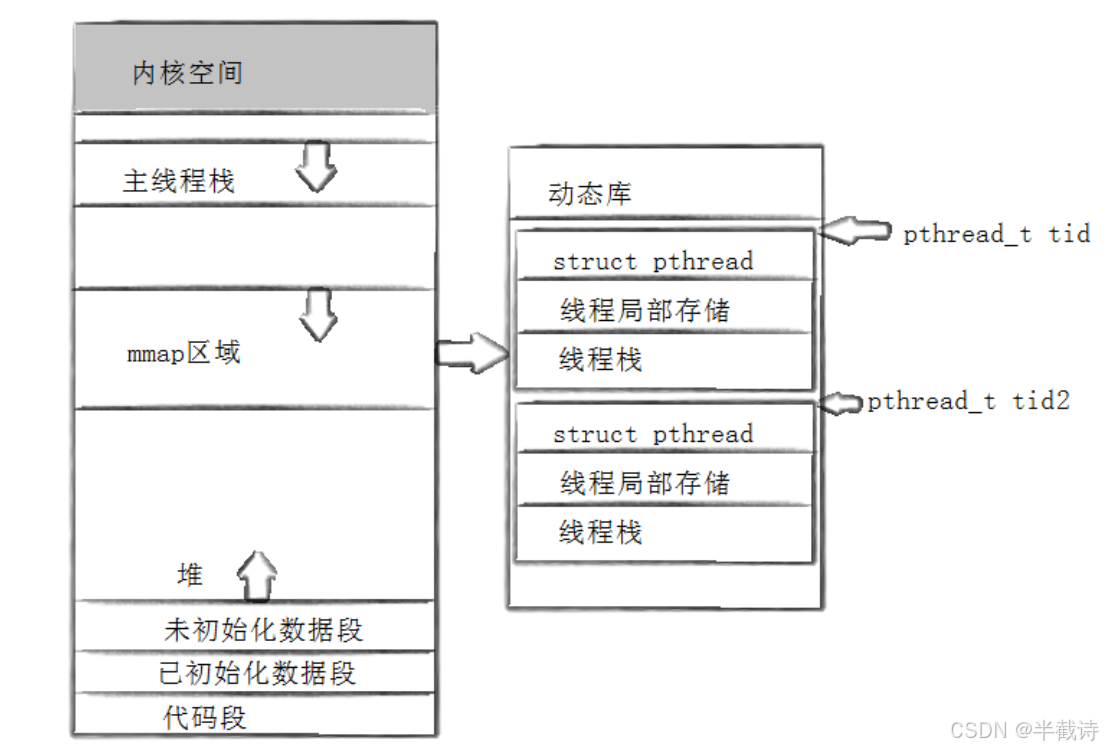
2.3 验证TCB位置
c
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void* thread_routine(void* arg) {
pthread_t self = pthread_self();
pthread_attr_t attr;
void *stackaddr;
size_t stacksize;
pthread_getattr_np(self, &attr);
pthread_attr_getstack(&attr, &stackaddr, &stacksize);
printf("=== 子线程信息 ===\n");
printf("pthread_t (TCB地址): %p\n", (void*)self);
printf("栈起始地址: %p\n", stackaddr);
printf("栈大小: %lu MB\n", stacksize / (1024*1024));
printf("栈结束地址: %p\n", (char*)stackaddr + stacksize);
// TCB应该在栈顶附近
long offset = ((char*)stackaddr + stacksize) - (char*)self;
printf("TCB偏移(相对栈顶): %ld 字节\n", offset);
pthread_attr_destroy(&attr);
sleep(30);
return NULL;
}
int main() {
pthread_t tid;
pthread_create(&tid, NULL, thread_routine, NULL);
printf("主线程中看到的pthread_t: %p\n", (void*)tid);
sleep(30);
return 0;
}运行结果:
bash
$ ./tcb_position
主线程中看到的pthread_t: 0x7f8b2e0c0700
=== 子线程信息 ===
pthread_t (TCB地址): 0x7f8b2e0c0700
栈起始地址: 0x7f8b2d8c0000
栈大小: 8 MB
栈结束地址: 0x7f8b2e0c0000
TCB偏移(相对栈顶): 1792 字节
# 观察:
# pthread_t (0x7f8b2e0c0700) 非常接近栈顶 (0x7f8b2e0c0000)
# 偏移1792字节,就是sizeof(struct pthread)三、pthread_create源码分析
3.1 pthread_create入口函数
c
/* 简化版 pthread_create (nptl/pthread_create.c) */
int
__pthread_create_2_1 (pthread_t *newthread,
const pthread_attr_t *attr,
void *(*start_routine) (void *),
void *arg)
{
struct pthread *pd; // 新线程的TCB指针
int err;
/* 1. 分配线程栈和TCB */
err = allocate_stack(attr, &pd, &stackaddr);
if (err != 0)
return err;
/* 2. 初始化TCB */
pd->start_routine = start_routine; // 保存线程函数
pd->arg = arg; // 保存参数
pd->flags = 0;
pd->cancelhandling = 0;
pd->tid = 0; // 稍后由内核填充
/* 3. 创建线程(调用clone系统调用) */
err = create_thread(pd, attr, &stopped_start);
if (err != 0) {
deallocate_stack(pd);
return err;
}
/* 4. 返回pthread_t给调用者 */
*newthread = (pthread_t) pd;
return 0;
}
/* pthread_create是这个函数的别名 */
versioned_symbol (libc, __pthread_create_2_1, pthread_create, GLIBC_2_1);📌 流程概览:
bash
pthread_create的四大步骤:
步骤1: allocate_stack
- 分配线程栈(通过mmap)
- 分配TCB
- 设置guard page
步骤2: 初始化TCB
- 保存线程函数和参数
- 初始化各种标志位
- 设置默认属性
步骤3: create_thread
- 调用clone系统调用
- 创建内核级LWP
- 让新线程开始执行
步骤4: 返回pthread_t
- pthread_t就是pd指针
- 指向TCB3.2 allocate_stack:栈分配详解
allocate_stack是线程创建的核心函数,它负责分配栈空间和TCB:
c
/* 简化版 allocate_stack (nptl/allocatestack.c) */
static int
allocate_stack (const pthread_attr_t *attr, struct pthread **pdp,
void **stack)
{
struct pthread *pd;
size_t size;
void *mem;
/* 1. 确定栈大小 */
if (attr == NULL || attr->stacksize == 0) {
/* 使用默认栈大小 */
size = __default_stacksize; // 通常是8MB
} else {
/* 使用用户指定的栈大小 */
size = attr->stacksize;
}
/* 2. 页对齐 */
size = ALIGN_UP(size, STACK_ALIGN);
/* 3. 加上guard page的大小 */
size_t guardsize = attr ? attr->guardsize : __default_guardsize;
guardsize = ALIGN_UP(guardsize, pagesize);
/* 4. 总大小 = guard + 栈 + TCB(并页对齐) */
size_t total_size = guardsize + size + sizeof(struct pthread);
total_size = ALIGN_UP(total_size, pagesize);
/* 5. mmap 分配内存 */
mem = mmap(NULL, total_size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK,
-1, 0);
/* 6. 设置guard page(改为不可访问) */
if (guardsize > 0) {
if (mprotect(mem, guardsize, PROT_NONE) != 0) {
munmap(mem, total_size);
return EAGAIN;
}
}
/* 7. TCB在栈顶 */
pd = (struct pthread *) ((char *) mem + total_size) - 1;
/* 8. 初始化TCB的栈信息字段 */
pd->stackblock = mem;
pd->stackblock_size = total_size;
pd->guardsize = guardsize;
/* 9. 返回 */
*pdp = pd;
*stack = (char *) mem + guardsize; // 实际可用栈起始
return 0;
}📌 详细分析:
bash
步骤1-2: 确定栈大小并对齐
- 默认8MB
- 按页大小对齐(通常4KB)
步骤3: 计算guard page大小
- 默认一页(4KB)
- 也要对齐
步骤4: 计算总大小
- guard page + 栈 + TCB
- 并按页大小对齐
步骤5: mmap分配
- MAP_ANONYMOUS: 匿名映射
- MAP_PRIVATE: 私有映射
- MAP_STACK: 标记为栈
- 返回起始地址
步骤6: 设置guard page
- 用mprotect改为PROT_NONE
- 不可读、不可写、不可执行
- 访问时触发SIGSEGV
步骤7: 计算TCB位置
- TCB在内存块的顶部
- pd = (mem + total_size) - sizeof(struct pthread)
步骤8: 初始化TCB
- 记录栈的地址和大小
- 记录guard page大小
步骤9: 返回
- pdp指向TCB
- stack指向可用栈起始(跳过guard page)3.4 create_thread:创建内核线程
栈分配完成后,接下来要创建内核级的LWP:
c
/* 简化版 create_thread (sysdeps/unix/sysv/linux/createthread.c) */
static int
create_thread (struct pthread *pd, const pthread_attr_t *attr,
bool *stopped_start)
{
/* 1. 准备clone的标志 */
const int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES
| CLONE_SYSVSEM | CLONE_SIGHAND
| CLONE_THREAD | CLONE_SETTLS
| CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID);
/* 2.栈顶指针通常取映射区高地址端(在 TCB 下方,且按 ABI 对齐) */
void *stack = (char *)pd; // 以 pd 为基准
stack = (char *)stack - 0x10; // 伪:预留并对齐(示意)
/* 3. 调用do_clone */
pd->tid = do_clone(start_thread, // 新线程入口函数
stack, // 栈指针
clone_flags, // 标志
pd, // 参数(TCB指针)
&pd->tid, // parent_tidptr
&pd->tid, // child_tidptr
pd); // TLS
if (pd->tid == -1)
return errno;
return 0;
}📌 clone标志解释:
bash
CLONE_VM:
- 共享虚拟内存(地址空间)
- 这是线程的关键特征!
CLONE_FS:
- 共享文件系统信息(cwd、root等)
CLONE_FILES:
- 共享文件描述符表
CLONE_SYSVSEM:
- 共享System V信号量的undo值
CLONE_SIGHAND:
- 共享信号处理函数表
CLONE_THREAD:
- 放在同一个线程组
- getpid()返回相同值
CLONE_SETTLS:
- 设置线程局部存储(TLS)
CLONE_PARENT_SETTID:
- 在父线程地址空间设置子线程tid
CLONE_CHILD_CLEARTID:
- 子线程退出时清除tid并发信号
核心理解:
- 这些标志组合起来,让新创建的LWP表现得像一个"线程"
- 共享进程资源,但有独立的执行流3.5 do_clone和__clone
do_clone最终会调用汇编实现的__clone:
c
/* do_clone是对__clone的简单封装 */
static int
do_clone (int (*fn)(void *), void *stack, int flags,
void *arg, pid_t *parent_tid, pid_t *child_tid,
void *tls)
{
return __clone(fn, stack, flags, arg, parent_tid, child_tid, tls);
}
asm
/* __clone汇编代码(x86-64简化版) */
/* sysdeps/unix/sysv/linux/x86_64/clone.S */
ENTRY (__clone)
/* 1. 参数准备 */
movq %rdi, %r11 /* 保存fn到r11 */
movq %rsi, %rdi /* stack参数移到rdi */
movq %rdx, %rsi /* flags参数移到rsi */
movq %rcx, %rdx /* arg参数移到rdx */
movq %r8, %r10 /* parent_tid参数移到r10 */
movq %r9, %r8 /* child_tid参数移到r8 */
movq 8(%rsp), %r9 /* tls参数移到r9 */
/* 2. 调用clone系统调用(syscall number 56) */
movl $__NR_clone, %eax
syscall
/* 3. 检查返回值 */
testq %rax, %rax
jl error /* < 0表示错误 */
je child_start /* = 0表示子进程/线程 */
/* 4. 父进程/线程路径:返回子线程tid */
ret
child_start:
/* 5. 子线程路径:调用start_thread */
movq %r11, %rax /* 恢复fn到rax */
movq %rdx, %rdi /* arg作为参数 */
call *%rax /* 调用fn(arg) */
/* 6. 线程函数返回后,调用exit退出 */
movq %rax, %rdi
movl $__NR_exit, %eax
syscall
error:
/* 错误处理 */
...
END (__clone)注:这里用 exit 仅为示意,实际线程退出路径由 glibc 的 __pthread_exit 等处理,最终进入内核的线程退出流程。
📌 关键理解:
bash
clone系统调用的行为:
1. 在父线程中返回子线程的tid
2. 在子线程中返回0
子线程的执行流:
1. clone返回0
2. 跳转到child_start
3. 调用start_thread(pd)
4. start_thread调用用户的线程函数
5. 线程函数返回后,调用exit退出3.6 start_thread:线程入口
c
/* start_thread是真正的线程入口函数 */
static int
start_thread (void *arg)
{
struct pthread *pd = (struct pthread *) arg;
/* 1. 调用用户的线程函数 */
void *ret = pd->start_routine(pd->arg);
/* 2. 保存返回值 */
pd->result = ret;
/* 3. 退出线程 */
__pthread_exit(ret);
/* 不会执行到这里 */
}四、完整流程图
4.1 pthread_create完整流程
bash
用户代码:
pthread_create(&tid, NULL, func, arg)
↓
─────────────────────────────────────────────
pthread库(用户态):
↓
__pthread_create_2_1()
↓
├─→ allocate_stack()
│ ↓
│ ├─→ 计算栈大小(默认8MB)
│ ├─→ mmap分配内存(栈+guard page)
│ ├─→ mprotect设置guard page
│ ├─→ 计算TCB位置(栈顶)
│ └─→ 返回pd指针(pthread_t)
│
├─→ 初始化TCB
│ ├─→ pd->start_routine = func
│ ├─→ pd->arg = arg
│ ├─→ pd->detachstate = JOINABLE
│ └─→ pd->tid = 0
│
├─→ create_thread(pd)
│ ↓
│ ├─→ 准备clone标志(CLONE_VM|CLONE_THREAD|...)
│ ├─→ 计算栈指针
│ └─→ do_clone(start_thread, stack, flags, pd)
│ ↓
─────────────────────────────────────────────
│ ↓
│ __clone(汇编)
│ ↓
│ 系统调用 clone()
│ ↓
─────────────────────────────────────────────
内核态:
│ ↓
│ do_fork()
│ ├─→ copy_process()
│ │ ├─→ 创建task_struct
│ │ ├─→ 设置共享资源(因为CLONE_VM等标志)
│ │ ├─→ 设置独立资源(栈、寄存器)
│ │ └─→ 分配pid(LWP)
│ │
│ └─→ wake_up_new_task()
│ └─→ 将新线程加入调度队列
│
─────────────────────────────────────────────
├──────────────┬──────────────┐
│ │ │
父线程(原线程) │ 子线程(新线程)
│ │ │
clone返回tid │ clone返回0
pd->tid = tid │ ↓
返回给用户 │ child_start:
│ │ 调用start_thread(pd)
↓ │ ↓
继续执行 │ ret = pd->start_routine(pd->arg)
│ ↓
│ pd->result = ret
│ ↓
│ __pthread_exit(ret)
│ ↓
│ 线程退出
│
└──────────────┘4.2 关键步骤时序图
bash
时间轴:
T0: 用户调用pthread_create(&tid, NULL, func, arg)
↓
T1: pthread库分配栈(mmap 8MB)
┌──────────────────┐← pd = pthread_t
│ TCB(struct pth) │
├──────────────────┤
│ Stack 8MB │
├──────────────────┤
│ Guard Page 4KB │
└──────────────────┘
↓
T2: 初始化TCB
pd->start_routine = func
pd->arg = arg
↓
T3: 调用clone系统调用
clone(start_thread, stack, CLONE_VM|CLONE_THREAD|..., pd)
↓
T4: 内核创建task_struct(LWP)
分配pid → pd->tid
↓
├─────────────┬──────────────┐
│ │ │
T5: 父线程 T5: 内核 T5: 子线程
clone返回 调度新线程 clone返回0
pd->tid设置 跳到child_start
return 0给用户 ↓
↓ T6: 调用start_thread(pd)
T6: 用户继续 ↓
tid已填充 T7: 执行func(arg)
↓
T8: func返回
↓
T9: pthread_exit
↓
T10: 线程退出,资源等待回收五、线程标识体系:pthread_t vs tid vs tgid(彻底不再混)
在阅读 glibc 源码和 clone 系统调用时,最容易混淆的就是"线程到底有几个 ID"。这一节我们用用户态 / 内核态 两套视角,把 pthread_t、tid、pid、tgid 的关系一次讲清楚。
5.1 两套世界:用户态 pthread vs 内核态 task_struct
Linux NPTL 采用 一对一线程模型:
- 用户态 :glibc 为每个线程维护一个 TCB(
struct pthread) - 内核态 :内核为每个线程创建一个调度实体
task_struct(也叫 LWP)
⚠️ 注意:TCB(用户态) ≠ task_struct(内核态),它们是两套不同的控制块。
5.2 核心结论
bash
1) pthread_t 是用户态 pthread 库的"线程句柄"(glibc 下通常就是 TCB 指针)
2) tid 是内核分配给每个线程的"线程ID"(LWP id),gettid() 获取
3) tgid 是线程组ID(也就是进程ID),getpid() 获取
注意:task_struct.pid 对应"线程ID"(用户态常称 tid/LWP id),gettid() 获取5.3 一张图理解:一个进程内多个线程的 pid/tgid
text
同一进程(线程组)内:
线程组 leader(主线程)
┌──────────────────────────────┐
│ task_struct │
│ pid = 1000 │ ← 主线程 tid
│ tgid = 1000 │ ← 进程 pid
└──────────────────────────────┘
子线程1
┌──────────────────────────────┐
│ task_struct │
│ pid = 1001 │ ← 子线程 tid
│ tgid = 1000 │ ← 同一个进程 pid
└──────────────────────────────┘
子线程2
┌──────────────────────────────┐
│ task_struct │
│ pid = 1002 │
│ tgid = 1000 │
└──────────────────────────────┘结论:
- 主线程:pid == tgid
- 子线程:pid != tgid,但 tgid 都相同(等于主线程 pid)
5.4 对照表:pthread_t / TCB / tid / tgid 各是谁
| 名称 | 所属层级 | 本质是什么 | 是否每线程唯一 | 如何获取 |
|---|---|---|---|---|
pthread_t |
用户态(pthread库) | 线程句柄/标识(glibc 下通常是 struct pthread*) |
✅ 是 | pthread_self() / pthread_create 返回 |
TCB(struct pthread) |
用户态(glibc) | 线程控制块,保存取消/join/TLS/栈等信息 | ✅ 是 | glibc 内部分配(常与栈一起 mmap) |
tid(LWP id) |
内核态 | 每个线程对应的内核线程ID(task_struct 的 pid) | ✅ 是 | syscall(SYS_gettid) |
tgid(进程 id) |
内核态 | 线程组ID(同一进程内所有线程相同) | ❌ 否(同进程相同) | getpid() |
pid(用户口语里的 PID) |
常被混用 | 一般指进程ID(= tgid) | --- | getpid() |
📌 术语提醒:在 Linux 内核语境中,"线程ID"对应
task_struct.pid(也就是用户态常说的tid)。
5.5 pthread_self() 到底返回谁?
POSIX 规定 pthread_t 是 pthread 线程标识,但没有规定它必须是整数。
在 glibc NPTL 实现中:
pthread_t通常就是struct pthread*(TCB 地址)- 所以你打印
pthread_self()常看到像0x7f...的指针值 - 它用于传给 pthread 库 API(如 join/detach/cancel),不等价于内核 tid
5.6 glibc 如何把内核 tid 写入 TCB(pd->tid)
在 glibc 的线程创建流程中:
allocate_stack()分配栈和 TCB(struct pthread *pd)create_thread()调用clone()创建内核线程(LWP)- 内核会把新线程的 tid 写入
pd->tid(依赖 clone 参数中的指针)
因此:
bash
pd(TCB)是用户态结构体
pd->tid 保存的是内核线程ID(LWP id)5.7 一句话总结(最常考点)
bash
pthread_t ≈ 用户态线程句柄(glibc 下通常是 TCB 地址)
getpid() = tgid(进程ID,同进程所有线程相同)
gettid() = tid(线程ID/LWP id,每线程不同)六、性能优化与缓存
6.1 线程栈缓存
bash
为了提升性能,glibc维护了一个栈缓存池:
线程栈缓存机制:
1. 线程退出时,不立即munmap栈
2. 将栈放入缓存链表
3. 下次创建线程时,优先从缓存获取
4. 避免频繁的mmap/munmap系统调用
缓存数据结构(简化):
static struct stack_cache {
struct list_head list; // 缓存栈的链表
size_t total_size; // 缓存的总大小
} stack_cache;
优点:
✓ 减少系统调用
✓ 提升线程创建速度
✓ 减少内存碎片
限制:
- 缓存总大小有上限(默认40MB)
- 超过上限会释放最久未用的栈6.2 TCB缓存
bash
类似地,TCB也有缓存:
TCB缓存机制:
1. 线程退出后,TCB不立即释放
2. 某些字段被重置
3. 整个栈+TCB放入缓存
4. 下次创建线程时复用
这就是为什么:
- 频繁创建/销毁线程性能还可以接受
- 不像进程那样每次都要完整创建/销毁七、系列总结
7.1 四篇文章回顾
bash
第一篇:线程概念与虚拟地址空间
✓ 线程的定义与本质
✓ 虚拟地址空间与分页机制
✓ 两级页表的工作原理
✓ 线程的优缺点
第二篇:POSIX线程库API实战
✓ pthread_create创建线程
✓ pthread_exit/return/cancel终止线程
✓ pthread_join等待线程
✓ pthread_detach分离线程
✓ pthread_t vs LWP
第三篇:线程ID本质与地址空间布局
✓ pthread_t指向TCB
✓ 主线程栈在栈区
✓ 子线程栈在共享区
✓ 线程栈不能动态增长
✓ 进程地址空间完整布局
✓ 线程共享与私有资源
第四篇:glibc源码剖析与实现原理
✓ struct pthread(TCB)结构
✓ allocate_stack分配栈和TCB
✓ create_thread调用clone
✓ 线程创建完整流程
✓ TCB与线程栈的内存布局
✓ 一对一线程模型
✓ 性能优化机制7.2 核心知识体系
bash
┌─────────────────────────────────────────┐
│ Linux线程知识体系 │
├─────────────────────────────────────────┤
│ │
│ 理论基础: │
│ ├─ 虚拟地址空间与分页 │
│ ├─ 线程vs进程 │
│ └─ 一对一线程模型 │
│ │
│ API层(pthread库): │
│ ├─ pthread_create │
│ ├─ pthread_exit/join/detach │
│ └─ pthread_t(TCB指针) │
│ │
│ 实现层(glibc): │
│ ├─ allocate_stack(mmap) │
│ ├─ struct pthread(TCB) │
│ ├─ create_thread │
│ └─ 栈缓存优化 │
│ │
│ 内核层: │
│ ├─ clone系统调用 │
│ ├─ task_struct(LWP) │
│ └─ 调度器 │
│ │
│ 内存布局: │
│ ├─ 主线程栈(栈区) │
│ ├─ 子线程栈(共享区) │
│ ├─ TCB(栈顶) │
│ └─ Guard Page(栈底) │
│ │
└─────────────────────────────────────────┘7.3 实战建议
bash
1. 理解原理后再写代码
- 知道pthread_t是TCB地址
- 理解栈的限制(不能动态增长)
- 避免传递栈上变量的地址
2. 注意资源管理
- joinable线程必须join
- 或者使用detach自动释放
- 避免资源泄漏
3. 合理设置栈大小
- 默认8MB通常够用
- 递归深度大时可能需要调整
- 使用pthread_attr_setstacksize
4. 调试技巧
- 用ps -Lf查看线程
- 用/proc/pid/maps查看内存布局
- gdb调试多线程程序
5. 性能优化
- 线程数不宜过多(通常与CPU核心数相当)
- 避免频繁创建/销毁(使用线程池)
- 注意false sharing(伪共享)八、结语
💬 系列总结
经过四篇文章的深入学习,我们完整地探索了Linux线程从概念到实现的全过程:
- 从虚拟地址空间理解线程运行的环境
- 通过pthread API掌握线程的使用
- 通过地址空间布局理解线程的本质
- 通过源码剖析掌握线程的实现原理
这个学习过程就像剥洋葱,一层层深入,从表象到本质,从使用到原理。
💡 学习感悟
技术的学习不应该停留在API的使用层面,深入理解底层原理能让我们:
- 写出更高效的代码
- 避免常见的陷阱
- 快速定位问题
- 具备系统级的思维
🚀 继续前进
Linux系统编程的世界博大精深,线程只是其中一个重要主题。希望通过这个系列,你不仅掌握了线程的知识,更重要的是学会了如何深入学习一个技术主题的方法:
- 从概念出发,理解"是什么"
- 通过实践,掌握"怎么用"
- 深入原理,理解"为什么"
- 阅读源码,掌握"如何做"
👏 致谢
感谢你耐心读完这个系列!如果这个系列对你有帮助,请点赞、收藏、分享,让更多同学受益!
💬 交流讨论
有任何问题或建议,欢迎在评论区讨论!我们一起进步!