一、问题:历史经验难以复用
每次故障发生,你是否有这样的感觉:
"这个问题好像之前遇到过..." "上次是怎么解决的来着?" "要是能自动找到类似的历史案例就好了"
我们积累了大量故障处置记录,但每次还是靠人工回忆、翻找文档。历史经验就像散落的珍珠,缺少一根线把它们串起来。
本文介绍一种简单有效的方案:用 LLM 理解故障特征,用 Jaccard 计算相似度,实现故障案例的智能匹配。
二、核心思路
2.1 两个角色,各司其职
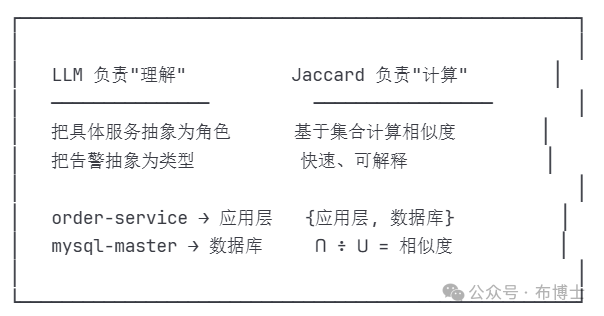
为什么需要 LLM? 因为直接用服务名匹配,几乎不可能找到相似案例------你的系统有上百个服务,两次故障涉及完全相同服务的概率太低了。
为什么需要 Jaccard? 因为它简单、快速、可解释。"这两个故障有 80% 的特征重叠",谁都能理解。
2.2 Jaccard 相似度
一句话解释:两个集合的交集除以并集。
集合 A = {苹果, 香蕉, 橙子}
集合 B = {苹果, 香蕉, 葡萄}
交集 = {苹果, 香蕉} = 2 个
并集 = {苹果, 香蕉, 橙子, 葡萄} = 4 个
Jaccard 相似度 = 2 ÷ 4 = 0.5三、关键一步:LLM 特征抽象
3.1 为什么要抽象?
看这个例子:
故障 A:order-service + payment-service + mysql-master 出问题
故障 B:user-service + product-service + mysql-slave 出问题
直接用服务名计算 Jaccard = 0(没有交集)
但实际上,这两个故障本质相同:都是"数据库问题影响了应用层"抽象后:
故障 A 角色:{应用层, 数据库}
故障 B 角色:{应用层, 数据库}
Jaccard = 1.0(完全匹配!)3.2 用 LLM 做角色推断
我们定义 7 种服务角色:
| 角色 | 典型代表 |
|---|---|
| Gateway | nginx、kong、api-gateway |
| Application | 各类业务服务 |
| Database | MySQL、MongoDB、PostgreSQL |
| Cache | Redis、Memcached |
| MessageQueue | Kafka、RabbitMQ |
| Middleware | ES、ZK、Nacos |
| Infra | 监控、日志等运维组件 |
LLM 推断的 Prompt 示例:
请根据以下信息判断服务的角色类型。服务信息:- 服务名称:{service_name}- 最近告警:{recent_alerts}- 服务描述:{service_description}可选角色:1. Gateway - 流量入口(网关、负载均衡)2. Application - 业务应用服务3. Database - 数据库(MySQL、MongoDB等)4. Cache - 缓存(Redis、Memcached等)5. MessageQueue - 消息队列(Kafka、RabbitMQ等)6. Middleware - 中间件(ES、ZK、Nacos等)7. Storage - 存储服务8. Infra - 基础设施组件请输出:{ "role": "角色名称", "confidence": 0.0-1.0 之间的置信度, "reason": "判断依据"}─────────────────────────────────────────────────────────────────────────示例输出:输入: 服务名称:order-mysql-master 服务描述:MySQL 数据库集群(主) 最近告警:slow_query_time > 1s, connection_count > 80%
输出:{ "role": "Database", "confidence": 0.95, "reason": "服务名包含mysql,端口3306是MySQL默认端口,告警为数据库典型告警,拓扑位置为叶子节点且被多服务调用"}3.3 告警类型分类
同样用 LLM 将告警抽象为 5 种类型:
| 类型 | 说明 | 典型告警 |
|---|---|---|
| Resource | 资源类 | CPU高、内存满、连接池耗尽 |
| Latency | 延时类 | 超时、慢查询、响应慢 |
| Error | 错误类 | 5xx、异常、失败率 |
| Availability | 可用性 | 宕机、不可达 |
| Capacity | 容量类 | 队列积压、流量超限 |
四、匹配流程
4.1 完整流程
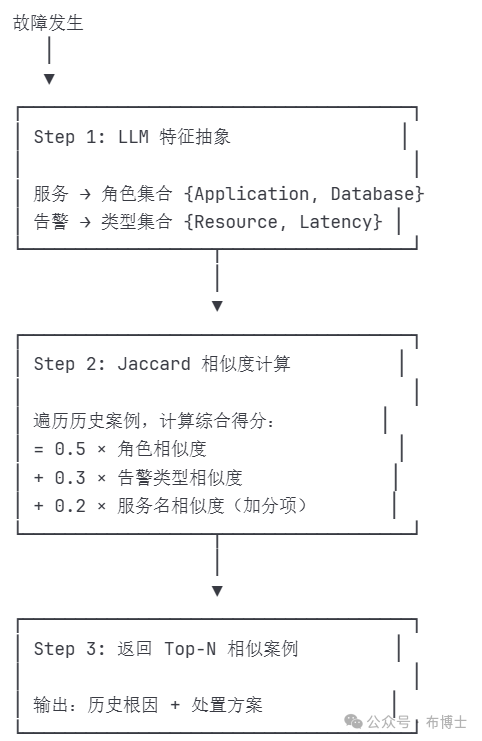
4.2 计算示例
当前故障:
-
角色集合:{Application, Database}
-
类型集合:{Resource, Latency, Error}
历史案例 A:
-
角色集合:{Application, Database}
-
类型集合:{Resource, Latency}
计算:
角色相似度 = 2/2 = 1.0
类型相似度 = 2/3 = 0.67
服务名相似度 = 0(不同服务)
综合得分 = 0.5×1.0 + 0.3×0.67 + 0.2×0 = 0.70相似度 0.70,推荐为参考案例。
五、工程实践要点
5.1 LLM 调用优化
| 策略 | 说明 |
|---|---|
| 存储 | 服务角色推断结果存DB,避免重复调用 |
| 批量 | 新服务批量推断,减少 API 调用 |
5.2 阈值建议
| 相似度 | 建议 |
|---|---|
| ≥ 0.8 | 高度相似,直接参考处置方案 |
| 0.6-0.8 | 中度相似,作为诊断参考 |
| < 0.6 | 相似度低,仅供了解 |
六、总结
一句话概括:用 LLM 把"具体"变成"抽象",用 Jaccard 把"抽象"变成"相似度"。

核心价值:
-
历史经验不再依赖人工回忆
-
秒级定位相似案例
-
新人也能借助历史经验处理故障
这个方案的妙处在于:LLM 和 Jaccard 各取所长------LLM 有理解能力但计算慢,Jaccard 计算快但不懂语义,两者结合刚刚好。
