安全问题,往往不是在"上线那一刻"出现的
如果你做过几次大模型微调项目,很可能有一种错觉。
项目初期,一切看起来都很安全。
数据在内网,模型在内网,访问有权限控制,
甚至你可能会想:
"我们又不是直接对外提供服务,哪来的安全风险?"
但很多隐私和安全问题,并不是在模型"上线"那一刻才出现的。
它们更像是被慢慢埋进模型参数里的定时炸弹。
等你意识到问题的时候,往往已经很难回头了。
而微调,正是最容易在不经意间放大这些风险的一步。
一个必须先讲清楚的事实:微调 ≠ 只是"更听话"
很多人第一次接触微调时,会把它理解成一件相对"温和"的事情。
你并没有重新训练模型,
只是用一些数据,让它更符合你的业务需求,
更像你想要的风格。
从这个角度看,微调好像只是"调教",而不是"重塑"。
但从安全和隐私的角度看,微调的本质是:
你在显式地告诉模型:哪些信息值得被强化记住。
而模型一旦记住了某些东西,你就几乎失去了"撤回"的能力。
预训练 vs 微调中"记忆方式"的对比图
内容建议:
- 预训练:分布式、模糊、不可定位
- 微调:集中、明确、可触发
微调放大风险的第一个原因:它会让"偶然信息"变成"稳定行为"
在预训练阶段,模型看到的数据是海量、混杂、去个体化的。
哪怕某些信息本身是敏感的,它们也会被淹没在整体分布中。
但微调完全不同。
微调数据往往有三个特点:
- 数量小
- 风格集中
- 场景明确
这意味着什么?
意味着只要你的数据里偶然出现了一些敏感信息 ,
模型就很容易把它们当成"高价值信号"。
比如:
- 某些真实用户的完整对话
- 内部系统的真实返回字段
- 人工客服在特殊情况下给出的"例外回答"
这些在人工看来是"个例",
但在模型看来,很可能是:
"这是一个应该被认真学习的模式。"
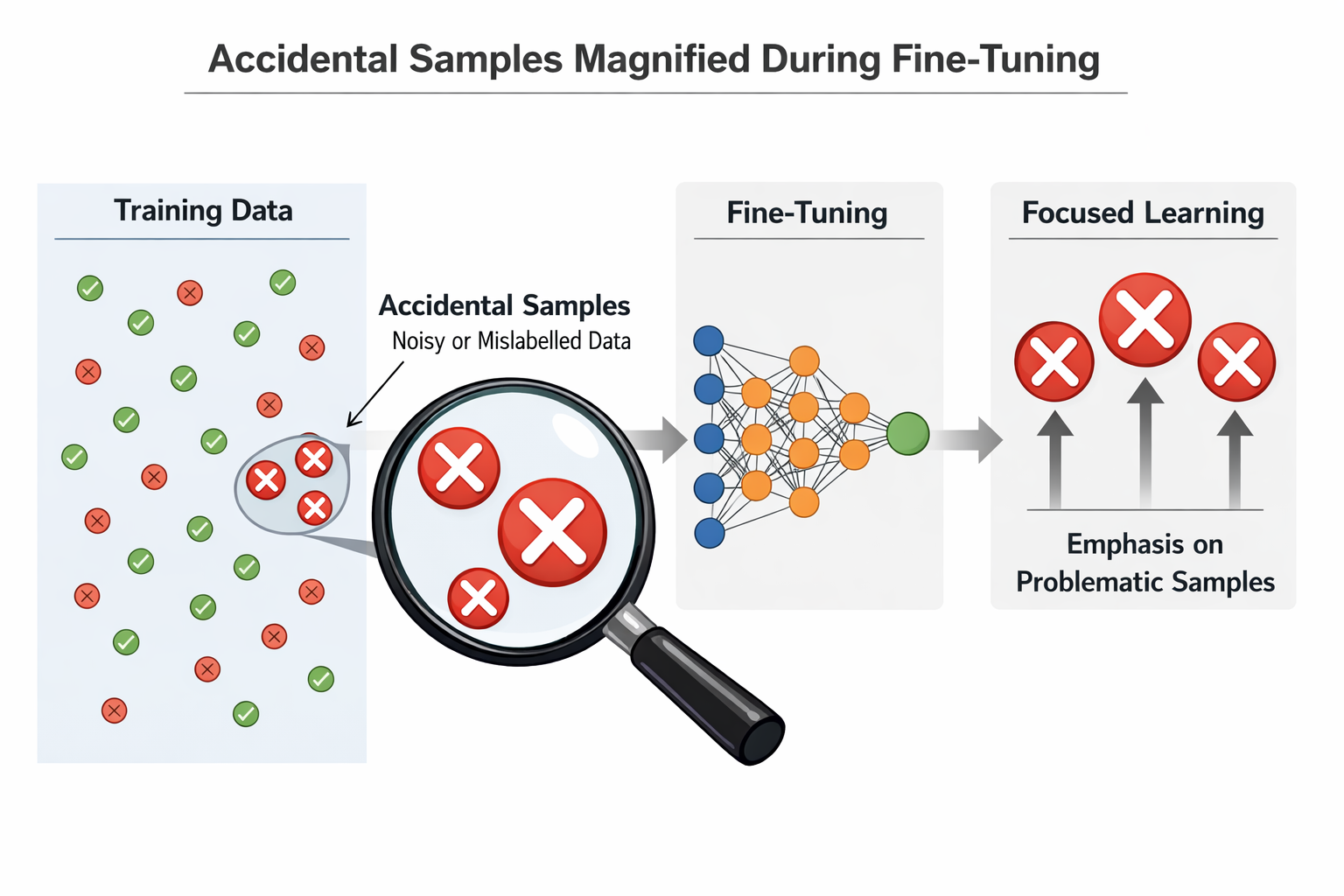
偶然样本在微调中被放大的示意图
第二个放大器:过拟合,本身就是一种隐私风险
很多人谈隐私泄露时,第一反应是"模型会不会背答案"。
但在微调场景里,背答案只是最极端的一种表现。
更常见、也更隐蔽的风险,是:
模型开始在相似问题上泄露相似信息。
这是过拟合在安全层面的直接后果。
举个例子:
你用了一批真实客服对话做微调,其中包含一些用户身份特征。
模型未必会原样复述某个用户的信息,
但它可能会学会一种"默认假设":
- 在某类问题下,自动补全一些不该出现的背景信息
- 在回答中暴露内部流程或状态
这类问题,非常难通过简单测试发现。
一个非常容易被忽略的事实:模型不会区分"能用"和"该用"
这是很多工程师在安全问题上最大的误判。
人类在使用数据时,会有天然的判断:
"这条信息我虽然知道,但不该说。"
模型没有这种意识。
对模型来说,只存在两件事:
- 这条信息是否有助于降低训练损失
- 在当前输入下,它是否"看起来合适"
如果你通过微调数据暗示模型:
"在某些问题下,说这些内容是对的",
那模型就会毫不犹豫地照做。
微调 vs RAG:为什么微调的安全边界更难控制
在很多项目中,安全问题并不是"有没有",而是"谁更可控"。
从安全角度看,微调和 RAG 有一个本质区别:
- RAG:信息在模型外部,可随时撤回
- 微调:信息进入模型参数,几乎不可删除
这意味着:
- RAG 出问题,你可以改文档、改权限、改索引
- 微调出问题,你往往只能:重新训练一个模型
而且,你很难精确知道:
到底是哪一条数据,导致了哪个行为变化。
为什么"只在内部用"并不等于"没有风险"
这是一个非常常见、也非常危险的心理安慰。
很多团队会觉得:
"我们这个模型又不对外,只给内部员工用。"
但内部使用,往往意味着:
- 输入更随意
- 权限更宽松
- 问题更接近真实业务
反而更容易触发模型的"记忆边界"。
而且,一旦模型输出了不该输出的内容,
内部扩散的速度,往往比外部更快。
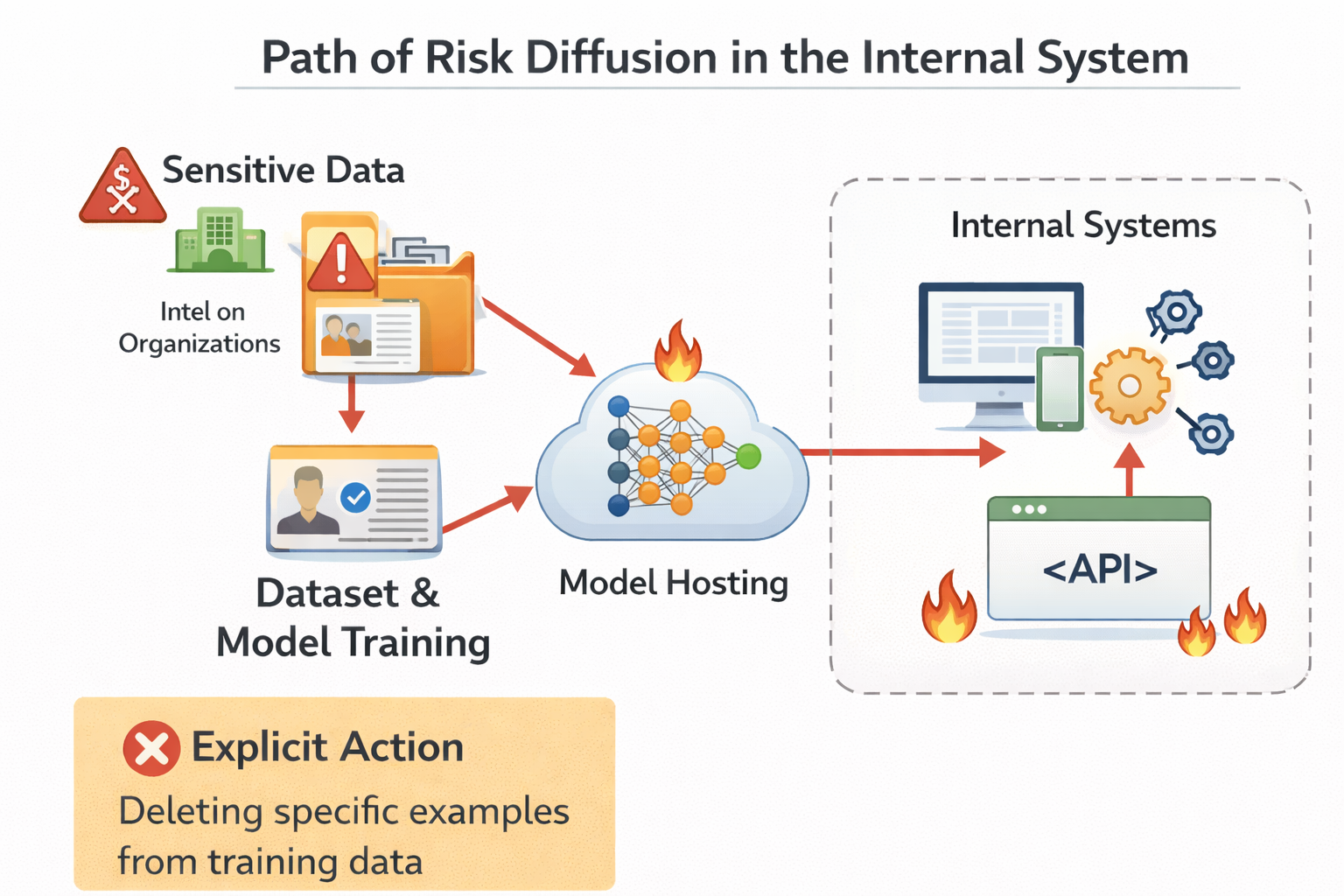
内部系统中风险扩散路径示意图
数据匿名化,并不能完全解决微调的隐私问题
很多人会试图通过"脱敏"来降低风险。
比如:
- 去掉用户名
- 替换 ID
- 模糊时间
这些做法当然是必要的,但远远不够。
因为模型并不只学习"字段值",
它还在学习结构、关系和默认推断方式。
你可能已经把名字去掉了,
但模型仍然学会了:
"在这种场景下,可以默认用户具有某种特征"。
这类风险,是结构性的,而不是字段级的。
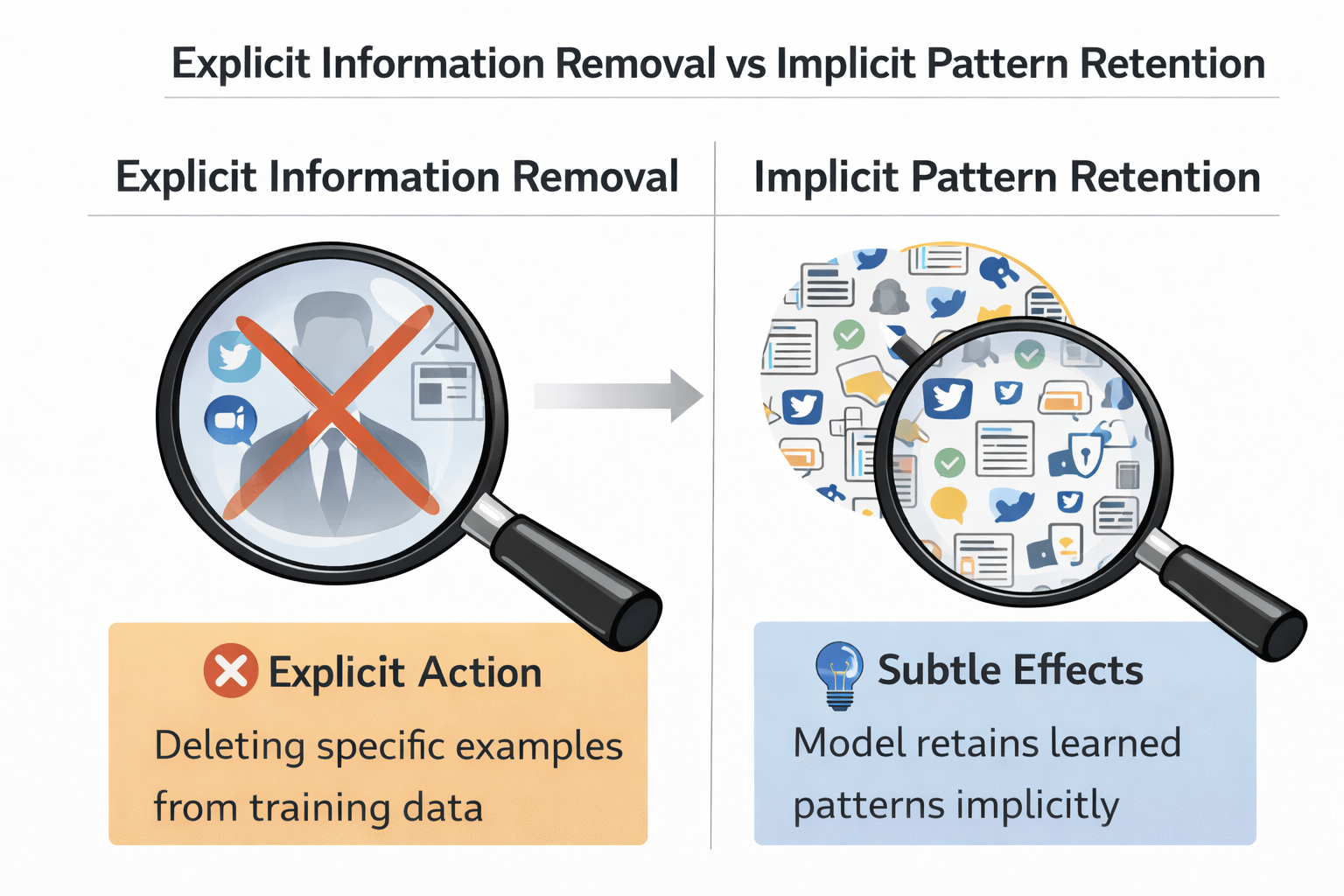
显式信息去除 vs 隐式模式保留示意图
一个现实问题:你很难"证明模型是安全的"
在微调项目中,安全评估往往面临一个非常尴尬的处境。
你可以证明模型"在这些测试用例下没问题",
但你几乎无法证明:
"模型在所有情况下都不会泄露不该泄露的东西。"
而微调,恰恰增加了这种不确定性。
因为你改变了模型原本的行为分布,
却很难穷举所有可能被触发的路径。
为什么安全问题,往往在"效果很好之后"才暴露
这是一个非常讽刺、但真实存在的现象。
很多安全问题,恰恰是在你对微调效果最满意的时候出现的。
原因很简单:
- 模型越"贴合业务",
- 它掌握的内部信息和默认假设就越多,
- 可被误用或误触发的空间也就越大。
你可能会发现:
模型确实更聪明了,但也更"危险"了。
一个更健康的认知:微调不是免费能力,而是风险交换
如果要用一句话总结微调与安全的关系,那就是:
微调从来不是"白送的能力",
而是用可控性,换取定制化。
当你接受微调带来的收益时,你也必须接受一个事实:
风险边界,变得更加模糊了。
工程上,哪些数据最不该进入微调
结合实际项目经验,我会非常明确地说:
下面这些数据,哪怕"看起来很有用",也极不适合直接用于微调:
- 原始用户对话(未充分清洗)
- 带强身份特征的样本
- 内部系统的完整返回结果
- 明显依赖人工判断的"特例处理"
这些数据,更适合通过 RAG、规则或人工流程来处理。
高风险数据类型清单图
一个现实建议:在决定微调之前,先问三个安全问题
在真正开始微调之前,我非常建议你停下来,问自己三个问题:
第一:
如果模型在不合适的场景下输出了这些内容,我能接受吗?
第二:
我是否清楚哪些信息一旦进入模型,就无法撤回?
第三:
这个需求,是否真的必须通过微调来解决?
如果这三个问题你都回答不上来,那继续微调,很可能只是把问题推迟。
在安全敏感场景下,更适合的节奏是什么
在安全或隐私要求较高的场景中,一个更健康的实践路径往往是:
- 先用规则和 RAG 验证需求
- 再用小规模、严格筛选的数据做试探性微调
- 明确评估"行为变化",而不是只看效果提升
在这种需要反复验证、谨慎试探的阶段,使用 LLaMA-Factory online 先进行小规模微调、快速对比模型行为变化,会比一开始就大规模训练更容易控制风险。
总结:微调不是"危险",但它会放大你原本就存在的风险
写到最后,其实结论已经很清楚了。
微调本身不是安全问题的源头,
但它会:
- 放大数据里的隐患
- 固化原本的偶然决策
- 提高错误行为的触发概率
真正成熟的团队,不是"不做微调",
而是清楚地知道:自己正在用什么,交换什么,又承担什么。
如果你开始用"风险"而不是"效果"来理解微调,很多之前模糊的问题,反而会变得清晰。