ACID底层实现:MySQL事务机制的深度解析
事务的本质与重要性
在关系型数据库系统中,事务(Transaction)是保证数据一致性和可靠性的核心机制。ACID原则(原子性、一致性、隔离性、持久性)构成了数据库事务的理论基础,而MySQL作为最流行的开源关系型数据库,其InnoDB存储引擎通过精巧的设计实现了这些原则。
本文将深入探讨MySQL如何实现ACID特性,重点关注各个组件的底层实现机制,包括Undo Log、Redo Log、MVCC和锁系统。通过8000字的深度分析,我们将揭示MySQL事务处理的内在逻辑和设计哲学。
原子性的实现机制
原子性的核心概念
原子性(Atomicity)要求事务中的所有操作要么全部完成,要么全部不执行,不存在中间状态。这一特性是事务最基本的保证,确保了数据库从一种一致状态转换到另一种一致状态。
Undo Log的架构设计
Undo Log的基本结构
Undo Log(撤销日志)是InnoDB实现原子性的核心机制。它记录了事务执行前的数据状态,以便在事务失败或显式回滚时能够恢复到之前的状态。
sql
-- Undo Log相关的系统表空间
-- 每个Undo Log segment包含1024个slot,每个slot对应一个事务
-- Undo Log采用段页式管理,存储在特殊的Undo表空间中Undo Log的物理存储结构:
- Undo Segment:每个回滚段包含1024个Undo Slot
- Undo Page:每个Undo Segment由多个16KB的页组成
- Undo Record:每个修改操作生成一条Undo Record
Undo Log的格式与类型
Undo Log记录主要分为两种类型:
-
INSERT Undo Log:记录插入操作的逆操作
- 只对当前事务可见
- 事务提交后可以立即删除
-
UPDATE Undo Log:记录更新/删除操作的逆操作
- 需要支持MVCC,可能被其他事务引用
- 事务提交后不能立即删除,需要等待所有相关读视图释放
每条Undo Record包含以下关键信息:
c
struct undo_record {
trx_id_t trx_id; // 事务ID
undo_no_t undo_no; // Undo记录编号
table_id_t table_id; // 表ID
type_cmpl_t type_cmpl; // 记录类型
uint32_t info_bits; // 信息位
// 旧数据记录
// 索引信息
// 指向旧版本的指针
};Undo Log的工作流程
事务开始阶段
当一个事务开始时,InnoDB会为该事务分配一个唯一的Transaction ID,并从Undo Segment中分配一个Undo Slot:
c
// 伪代码:事务开始过程
trx_assign_id(trx) {
// 从全局事务ID生成器获取新ID
trx->id = trx_sys_get_new_trx_id();
// 分配Undo Log空间
trx->undo_no = 0;
trx->undo_rseg_space = allocate_undo_slot();
// 初始化Undo Log头部
write_undo_log_header(trx);
}数据修改阶段
当事务执行DML操作时,InnoDB会创建相应的Undo Record:
c
// 伪代码:数据修改时的Undo记录创建
row_update_for_mysql(row, trx) {
// 1. 创建旧数据的Undo记录
undo_rec = trx_undo_report_row_operation(
trx,
TABLE_ID,
INDEX_ID,
old_data
);
// 2. 修改数据页中的记录
// 在每个数据记录的行头中添加必要的信息:
// - DB_TRX_ID: 6字节,最近修改的事务ID
// - DB_ROLL_PTR: 7字节,指向Undo Log的指针
// - DB_ROW_ID: 6字节,行ID(如果有主键则不需要)
// 3. 更新聚簇索引记录
btr_cur_optimistic_update(cur, new_data);
// 4. 更新二级索引(如果需要)
if (has_secondary_index) {
update_secondary_indexes();
}
}事务提交与回滚
事务提交时:
c
trx_commit(trx) {
// 1. 准备提交阶段
trx_prepare_commit(trx);
// 2. 写入提交标记到Undo Log
write_commit_mark_to_undo(trx);
// 3. 刷新日志
log_write_up_to(trx->commit_lsn);
// 4. 清理阶段
// - 如果Undo Log只对当前事务可见,可以立即清理
// - 如果Undo Log被其他事务的读视图引用,加入清理队列
trx_cleanup_at_commit(trx);
}事务回滚时:
c
trx_rollback(trx) {
// 1. 获取事务的所有Undo记录
undo_recs = trx->undo_records;
// 2. 按逆序处理Undo记录(LIFO顺序)
for (undo in reverse(undo_recs)) {
switch (undo->type) {
case INSERT:
// 执行删除操作
row_delete_for_undo(undo);
break;
case DELETE:
// 执行插入操作
row_insert_for_undo(undo);
break;
case UPDATE:
// 执行反向更新
row_update_for_undo(undo);
break;
}
// 3. 释放Undo记录空间
free_undo_record(undo);
}
// 4. 释放事务锁
lock_release_trx_locks(trx);
}Undo Log的管理与清理
Purge机制
由于Update Undo Log需要支持MVCC,不能立即删除,InnoDB引入了Purge线程来负责清理不再需要的Undo Log:
sql
-- InnoDB Purge相关参数
SHOW VARIABLES LIKE 'innodb_purge%';
-- innodb_purge_threads: Purge线程数量
-- innodb_purge_batch_size: 每次Purge操作处理的数量
-- innodb_max_purge_lag: 最大Purge延迟Purge线程的工作流程:
c
// 伪代码:Purge线程主循环
purge_thread_main() {
while (true) {
// 1. 获取可以清理的Undo Log范围
purge_sys->purge_trx_no = trx_sys->oldest_view_low_limit_no();
// 2. 从Undo Log历史链表中收集需要清理的记录
collect_undo_records_to_purge();
// 3. 批量清理Undo记录及其对应的数据记录
batch_purge();
// 4. 释放清理后的Undo Page
free_purged_undo_pages();
// 5. 休眠等待下一次清理
os_thread_sleep(purge_interval);
}
}Undo Tablespace管理
从MySQL 8.0开始,Undo Log存储在独立的Undo表空间中:
sql
-- 查看Undo表空间配置
SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLESPACES
WHERE SPACE_TYPE = 'Undo';
-- Undo表空间参数
SHOW VARIABLES LIKE 'innodb_undo%';
-- innodb_undo_tablespaces: Undo表空间数量(MySQL 8.0默认为2)
-- innodb_undo_directory: Undo表空间存储目录
-- innodb_undo_log_truncate: 是否开启Undo Log截断
-- innodb_max_undo_log_size: 单个Undo表空间的最大大小崩溃恢复中的原子性保证
在数据库崩溃恢复过程中,Undo Log与Redo Log协同工作保证原子性:
c
// 伪代码:崩溃恢复过程
crash_recovery() {
// 阶段1:Redo阶段,重做所有已提交和未提交的事务
redo_phase();
// 阶段2:Undo阶段,回滚所有未提交的事务
undo_phase() {
// 扫描Undo Log段
for (undo_seg in undo_segments) {
// 查找需要回滚的事务
if (undo_seg->transaction_state == ACTIVE) {
// 执行回滚操作
trx_rollback_active(undo_seg->trx_id);
}
}
}
}持久性的实现机制
持久性的基本要求
持久性(Durability)要求一旦事务提交,其对数据库的修改就是永久性的,即使发生系统故障也不会丢失。这是通过Redo Log(重做日志)机制实现的。
Redo Log的架构设计
Redo Log的物理结构
Redo Log是物理日志,记录的是数据页的物理变化。它采用循环写入的方式,由多个固定大小的文件组成:
sql
-- 查看Redo Log配置
SHOW VARIABLES LIKE 'innodb_log%';
-- innodb_log_file_size: 每个Redo Log文件的大小
-- innodb_log_files_in_group: Redo Log文件数量(通常为2)
-- innodb_log_group_home_dir: Redo Log文件目录Redo Log的物理布局:
ib_logfile0 (默认48MB) ib_logfile1 (默认48MB)
|-------------------| |-------------------|
| Log Block 512B | | Log Block 512B |
| Log Block 512B | | Log Block 512B |
| ... | | ... |
|-------------------| |-------------------|Log Buffer与Log File
InnoDB使用多层缓冲机制提高Redo Log写入性能:
- Log Buffer:内存缓冲区,默认16MB
- Log File:磁盘文件,循环写入
c
// 伪代码:Redo Log的内存结构
struct log_sys {
// Log Buffer相关
byte* buf; // Log Buffer起始地址
ulint buf_size; // Log Buffer大小
lsn_t buf_free; // 下一个写入位置
// Checkpoint相关
lsn_t last_checkpoint_lsn; // 最近Checkpoint的LSN
lsn_t next_checkpoint_lsn; // 下一个Checkpoint的LSN
// 文件相关
os_file_t log_file; // 当前写入的文件
lsn_t file_start_lsn; // 文件起始LSN
lsn_t file_end_lsn; // 文件结束LSN
};LSN(Log Sequence Number)机制
LSN是Redo Log的核心概念,它是一个单调递增的64位整数,表示Redo Log中的字节偏移量:
c
// LSN的组成
// 高32位:Log File编号
// 低32位:文件内的偏移量
// 伪代码:LSN相关操作
lsn_t generate_new_lsn() {
// 原子增加全局LSN计数器
return atomic_add(&log_sys->lsn, len);
}
// 将LSN转换为文件位置
void lsn_to_file_pos(lsn_t lsn, uint32_t* file_no, uint32_t* offset) {
*file_no = lsn >> 32;
*offset = lsn & 0xFFFFFFFF;
}Redo Log的写入流程
Mini-Transaction(MTR)
Mini-Transaction是InnoDB中最小的原子写操作单元,保证对多个页的修改是原子的:
c
// 伪代码:Mini-Transaction执行流程
mtr_t mtr;
mtr_start(&mtr);
// 1. 记录Redo Log
mlog_write_initial_log_record(page, type, &mtr);
// 2. 修改数据页
page_cur_insert_rec(page_cursor, rec, offsets, &mtr);
// 3. 提交MTR
mtr_commit(&mtr) {
// 将MTR中的Redo Log写入Log Buffer
mtr_write_log_t log = mtr->log;
// 分配LSN
start_lsn = log_sys->lsn;
end_lsn = start_lsn + log.size;
// 复制日志到Log Buffer
memcpy(log_sys->buf + start_lsn_offset, log.data, log.size);
// 更新数据页的LSN
for (page in mtr->modified_pages) {
page->newest_modification = end_lsn;
}
// 释放MTR锁
mtr_release_locks(&mtr);
}Log Buffer的刷盘策略
InnoDB提供了多种Redo Log刷盘策略,通过innodb_flush_log_at_trx_commit参数控制:
sql
-- 三种刷盘策略
-- 1: 每次事务提交都刷盘(最安全,性能最低)
-- 0: 每秒刷盘一次(性能最高,可能丢失1秒数据)
-- 2: 每次提交只写到操作系统缓存,依赖操作系统刷盘不同策略的实现:
c
// 伪代码:事务提交时的日志刷盘
trx_flush_log_if_needed(trx) {
switch (innodb_flush_log_at_trx_commit) {
case 1:
// 强制刷盘
log_write_up_to(trx->commit_lsn, true);
break;
case 0:
// 交给后台线程每秒刷盘
// 设置标志,后台线程会处理
log_sys->flush_time = current_time;
break;
case 2:
// 只写到操作系统缓存
log_write_up_to(trx->commit_lsn, false);
break;
}
}Checkpoint机制
Checkpoint机制是Redo Log管理的关键,它标记了哪些修改已经持久化到数据文件,从而可以安全地重用Redo Log空间。
Fuzzy Checkpoint
InnoDB使用模糊检查点(Fuzzy Checkpoint),只确保到某个LSN之前的所有修改都已刷盘:
c
// 伪代码:Checkpoint执行过程
log_checkpoint() {
// 1. 计算可以推进的Checkpoint LSN
checkpoint_lsn = calc_checkpoint_lsn();
// 2. 确保所有小于checkpoint_lsn的脏页都已刷盘
buf_flush_sync_for_checkpoint(checkpoint_lsn);
// 3. 写入Checkpoint记录
write_checkpoint_record(checkpoint_lsn);
// 4. 更新系统信息
log_sys->last_checkpoint_lsn = checkpoint_lsn;
}自适应刷新(Adaptive Flushing)
InnoDB根据系统负载自动调整脏页刷新速率:
c
// 伪代码:自适应刷新算法
adaptive_flush() {
// 计算脏页比例
dirty_pct = buf_pool->modified_len / buf_pool->curr_size;
// 计算Redo Log生成速率
redo_rate = log_sys->lsn - last_lsn;
// 根据多个因素计算目标刷新率
target_rate = calculate_flush_rate(dirty_pct, redo_rate,
checkpoint_age, io_capacity);
// 执行刷新
buf_flush_batch(target_rate);
}崩溃恢复过程
当数据库异常关闭后重启时,InnoDB通过Redo Log进行崩溃恢复:
c
// 伪代码:完整的崩溃恢复流程
crash_recovery() {
// 阶段1:初始化恢复系统
recv_sys_init();
// 阶段2:扫描Redo Log文件,解析日志记录
recv_scan_log_recs(start_lsn, end_lsn) {
while (current_lsn < end_lsn) {
// 读取日志记录
log_rec = parse_log_record(current_lsn);
// 验证日志记录的完整性
if (!validate_log_rec(log_rec)) {
break; // 遇到损坏的日志记录
}
// 添加到恢复哈希表
recv_add_to_hash_table(log_rec);
current_lsn += log_rec->len;
}
}
// 阶段3:应用Redo日志(前滚)
recv_apply_hashed_log_recs() {
for (page_rec in hash_table) {
// 读取数据页
page = buf_page_get(page_id);
// 如果页面LSN小于日志LSN,需要重做
if (page->lsn < log_rec->end_lsn) {
apply_log_rec_to_page(page, log_rec);
}
}
}
// 阶段4:回滚未完成的事务(使用Undo Log)
trx_rollback_or_clean_all_without_sess();
// 阶段5:清理恢复环境
recv_recovery_from_checkpoint_finish();
}隔离性的实现机制
隔离级别与并发问题
SQL标准定义了四个隔离级别,解决不同的并发问题:
- READ UNCOMMITTED:可能发生脏读、不可重复读、幻读
- READ COMMITTED:解决脏读,可能发生不可重复读、幻读
- REPEATABLE READ:解决脏读、不可重复读,可能发生幻读
- SERIALIZABLE:解决所有并发问题
MVCC(多版本并发控制)
MVCC是InnoDB实现非锁定读(快照读)的核心机制,它通过维护数据的多个版本来实现读写不阻塞。
行格式与隐藏字段
InnoDB的每行数据都包含三个隐藏字段:
- DB_TRX_ID(6字节):最近修改该行的事务ID
- DB_ROLL_PTR(7字节):指向Undo Log中旧版本数据的指针
- DB_ROW_ID(6字节):行ID(如果没有主键)
c
// 伪代码:行记录结构
struct row_rec {
// 隐藏字段
trx_id_t trx_id; // DB_TRX_ID
roll_ptr_t roll_ptr; // DB_ROLL_PTR
row_id_t row_id; // DB_ROW_ID
// 列数据
col1_t col1;
col2_t col2;
// ...
// 行头信息
info_bits_t info_bits; // 删除标志等
};Read View(读视图)
Read View定义了事务能看到的数据版本范围:
c
// 伪代码:Read View结构
struct read_view_t {
// 创建Read View时活跃事务列表
ids_t* ids; // 活跃事务ID数组
ulint n_ids; // 活跃事务数量
// 关键快照点
trx_id_t up_limit_id; // 低水位线
trx_id_t low_limit_id; // 高水位线
trx_id_t creator_trx_id; // 创建者事务ID
// 其他状态信息
bool closed; // 是否关闭
};Read View的创建时机:
- READ COMMITTED:每次查询都创建新的Read View
- REPEATABLE READ:事务第一次查询时创建Read View,后续查询复用
可见性判断算法
判断一行数据对当前事务是否可见的算法:
c
// 伪代码:可见性判断
bool changes_visible(trx_id_t trx_id, read_view_t* view) {
// 1. 如果trx_id小于低水位线,且不在活跃事务列表中,可见
if (trx_id < view->up_limit_id) {
return true;
}
// 2. 如果trx_id大于等于高水位线,不可见
if (trx_id >= view->low_limit_id) {
return false;
}
// 3. 在高低水位线之间,检查是否在活跃事务列表中
return !binary_search(view->ids, trx_id, view->n_ids);
}锁机制
虽然MVCC提供了非锁定读,但写操作和部分读操作仍然需要锁来保证一致性。
锁的类型
InnoDB实现了多粒度锁系统:
-
行级锁:
- 共享锁(S锁)
- 排他锁(X锁)
-
表级锁:
- 意向共享锁(IS锁)
- 意向排他锁(IX锁)
-
间隙锁(Gap Lock):
- 锁定一个范围,但不包括记录本身
-
临键锁(Next-Key Lock):
- 记录锁 + 间隙锁的组合
锁的内存结构
c
// 伪代码:锁结构
struct lock_t {
// 锁的基本信息
lock_type_t type; // 锁类型
lock_mode_t mode; // 锁模式
// 锁定的资源
lock_rec_t rec_lock; // 记录锁信息
lock_table_t table_lock; // 表锁信息
// 事务信息
trx_t* trx; // 持有锁的事务
// 链表连接
lock_t* next; // 同一个事务的下一个锁
lock_t* prev; // 同一个事务的上一个锁
// 哈希链连接
lock_t* hash_next; // 哈希链下一个
lock_t* hash_prev; // 哈希链上一个
};锁的兼容性矩阵
| IS | IX | S | X
-----|-----|-----|-----|-----
IS | 兼容 | 兼容 | 兼容 | 不兼容
IX | 兼容 | 兼容 | 不兼容 | 不兼容
S | 兼容 | 不兼容 | 兼容 | 不兼容
X | 不兼容 | 不兼容 | 不兼容 | 不兼容不同隔离级别的实现
READ COMMITTED的实现
在READ COMMITTED级别下:
- 读操作使用快照读,每次查询创建新的Read View
- 写操作使用记录锁,不包含间隙锁
c
// 伪代码:READ COMMITTED下的SELECT操作
row_search_for_mysql_rc() {
// 每次查询都创建新的Read View
view = read_view_open_now(trx);
// 查找满足条件的记录
while ((rec = btree_search(...))) {
// 检查记录可见性(使用新创建的Read View)
if (row_sel_check_trx_id(rec, view)) {
return rec;
}
}
// 查询结束关闭Read View
read_view_close(view);
}REPEATABLE READ的实现
在REPEATABLE READ级别下:
- 读操作使用快照读,事务第一次查询时创建Read View并复用
- 写操作使用临键锁,防止幻读
c
// 伪代码:REPEATABLE READ下的加锁逻辑
row_search_for_mysql_rr() {
// 如果是事务的第一次查询,创建Read View
if (trx->read_view == NULL) {
trx->read_view = read_view_open_now(trx);
}
// 查找记录并加锁
rec = btree_search_and_lock(...);
// 检查可见性(使用事务级别的Read View)
if (!row_sel_check_trx_id(rec, trx->read_view)) {
// 如果不可见,需要沿着Undo链查找可见版本
while (rec != NULL && !visible) {
roll_ptr = rec->roll_ptr;
rec = find_undo_version(roll_ptr);
visible = row_sel_check_trx_id(rec, trx->read_view);
}
}
return rec;
}临键锁与幻读防止
临键锁是InnoDB防止幻读的关键机制:
c
// 伪代码:临键锁的加锁过程
lock_rec_lock_rr(space_id, page_no, heap_no, mode) {
// 1. 加记录锁
lock_rec_add_to_queue(space_id, page_no, heap_no, mode);
// 2. 加间隙锁
next_heap_no = page_rec_get_next(heap_no);
if (next_heap_no != PAGE_HEAP_NO_SUPREMUM) {
lock_rec_add_to_queue(space_id, page_no,
next_heap_no, LOCK_GAP);
} else {
// 如果是上确界记录,需要锁住下一个页的第一个记录
next_page_no = btr_page_get_next(page);
lock_rec_add_to_queue(space_id, next_page_no,
0, LOCK_GAP);
}
}死锁检测与处理
InnoDB使用等待图(Wait-for Graph)算法检测死锁:
c
// 伪代码:死锁检测算法
deadlock_check(trx) {
// 构建等待图
graph = build_wait_for_graph();
// 深度优先搜索检测环
if (dfs_find_cycle(graph, trx)) {
// 发现死锁,选择牺牲者
victim = choose_victim(cycle_transactions);
// 回滚牺牲者事务
trx_rollback_to_savepoint(victim, NULL);
return true;
}
return false;
}死锁处理策略:
- 超时机制 :
innodb_lock_wait_timeout(默认50秒) - 主动检测 :
innodb_deadlock_detect(默认开启) - 牺牲者选择:选择回滚代价最小的事务
一致性的实现机制
一致性的多层含义
一致性(Consistency)在数据库中有多层含义:
- 事务一致性:数据库从一种一致状态转换到另一种一致状态
- 数据一致性:数据满足所有预定义的约束
- 最终一致性:分布式系统中的概念
Undo Log在一致性中的作用
虽然原子性主要通过Undo Log实现,但Undo Log在一致性保证中也扮演着关键角色:
约束验证与回滚
在执行数据修改时,如果违反约束,需要利用Undo Log进行回滚:
c
// 伪代码:外键约束检查与回滚
check_foreign_key_constraint() {
// 检查外键约束
if (foreign_key_violation) {
// 记录错误日志
log_foreign_key_error();
// 使用Undo Log回滚当前操作
trx_rollback_last_sql_stmt(trx);
// 抛出错误
return DB_FOREIGN_KEY_ERROR;
}
return DB_SUCCESS;
}一致性读的实现
一致性读依赖于Undo Log构建数据的多版本:
c
// 伪代码:通过Undo链查找可见版本
row_vers_build_for_consistent_read(rec, trx, index, offsets,
read_view, heap, old_vers) {
// 沿着Undo链遍历
while (roll_ptr != NULL) {
// 从Undo Log中获取旧版本
old_rec = trx_undo_prev_version_build(rec, roll_ptr, index,
offsets, heap);
// 检查可见性
if (read_view_sees_trx_id(read_view, old_rec->trx_id)) {
*old_vers = old_rec;
return;
}
// 继续向前查找
roll_ptr = old_rec->roll_ptr;
}
*old_vers = NULL;
}Redo Log与一致性
Redo Log通过Write-Ahead Logging(WAL)协议保证数据一致性:
WAL协议
WAL协议的核心原则:日志先行
- 所有数据修改必须先写入Redo Log
- 只有Redo Log落盘后,事务才能提交
- 数据页可以延迟刷盘
c
// 伪代码:WAL协议的实现
mtr_commit_with_wal(mtr) {
// 1. 将Redo Log写入Log Buffer
log_write_to_buffer(mtr->log);
// 2. 根据策略决定是否刷盘
if (need_flush) {
log_flush_to_disk();
}
// 3. 数据页修改仍然在内存中
// 可以异步刷盘
}Doublewrite Buffer
为了防止页断裂(Page Torn)问题,InnoDB使用Doublewrite Buffer:
sql
-- Doublewrite Buffer配置
SHOW VARIABLES LIKE 'innodb_doublewrite%';
-- innodb_doublewrite: 是否启用Doublewrite
-- innodb_doublewrite_dir: Doublewrite文件目录
-- innodb_doublewrite_files: Doublewrite文件数量Doublewrite的工作流程:
c
// 伪代码:Doublewrite刷盘过程
buf_flush_write_block_low(page) {
// 1. 先将页写入Doublewrite Buffer
write_to_doublewrite_buffer(page);
// 2. 将Doublewrite Buffer刷盘
flush_doublewrite_buffer();
// 3. 再将页写入实际数据文件位置
write_to_data_file(page);
// 4. 同步数据文件
fsync_data_file();
}约束保证机制
主键与唯一约束
InnoDB使用B+树索引保证主键和唯一约束:
c
// 伪代码:唯一约束检查
row_ins_check_unique_constraint(index, entry, thr) {
// 在索引中查找相同键值的记录
cursor = btr_cur_search_to_nth_level(index, entry, PAGE_CUR_LE);
if (cursor->low_match == cursor->up_match) {
// 找到重复键,违反唯一约束
if (!ignore_duplicate) {
return DB_DUPLICATE_KEY;
}
}
return DB_SUCCESS;
}外键约束
外键约束通过引用完整性检查实现:
c
// 伪代码:外键约束检查
row_ins_check_foreign_constraint(foreign, table, entry, thr) {
// 检查父表中是否存在对应的记录
parent_index = foreign->referenced_index;
parent_entry = build_parent_entry(entry, foreign);
cursor = btr_cur_search_to_nth_level(parent_index, parent_entry,
PAGE_CUR_GE);
if (!cursor->low_match) {
// 父记录不存在,违反外键约束
return DB_NO_REFERENCED_ROW;
}
return DB_SUCCESS;
}CHECK约束
从MySQL 8.0.16开始,InnoDB支持原生的CHECK约束:
sql
CREATE TABLE t1 (
id INT PRIMARY KEY,
age INT,
CONSTRAINT age_check CHECK (age >= 0 AND age <= 150)
);
-- CHECK约束在数据修改时验证
INSERT INTO t1 VALUES (1, 200); -- 违反CHECK约束,操作失败崩溃恢复中的一致性保证
在崩溃恢复过程中,InnoDB需要保证数据库恢复到一致性状态:
c
// 伪代码:崩溃恢复的一致性保证
crash_recovery_ensure_consistency() {
// 阶段1:前滚(Redo)
// 重做所有已提交和未提交的事务修改
apply_all_redo_logs();
// 阶段2:回滚(Undo)
// 回滚所有未提交的事务
rollback_uncommitted_transactions();
// 阶段3:修复损坏的页
// 使用Doublewrite Buffer恢复损坏的页
recover_corrupted_pages_from_doublewrite();
// 阶段4:验证约束
// 检查外键、唯一约束等
verify_all_constraints();
// 阶段5:重建索引(如果需要)
if (need_index_rebuild) {
rebuild_corrupted_indexes();
}
}ACID特性的协同工作
事务执行的整体流程
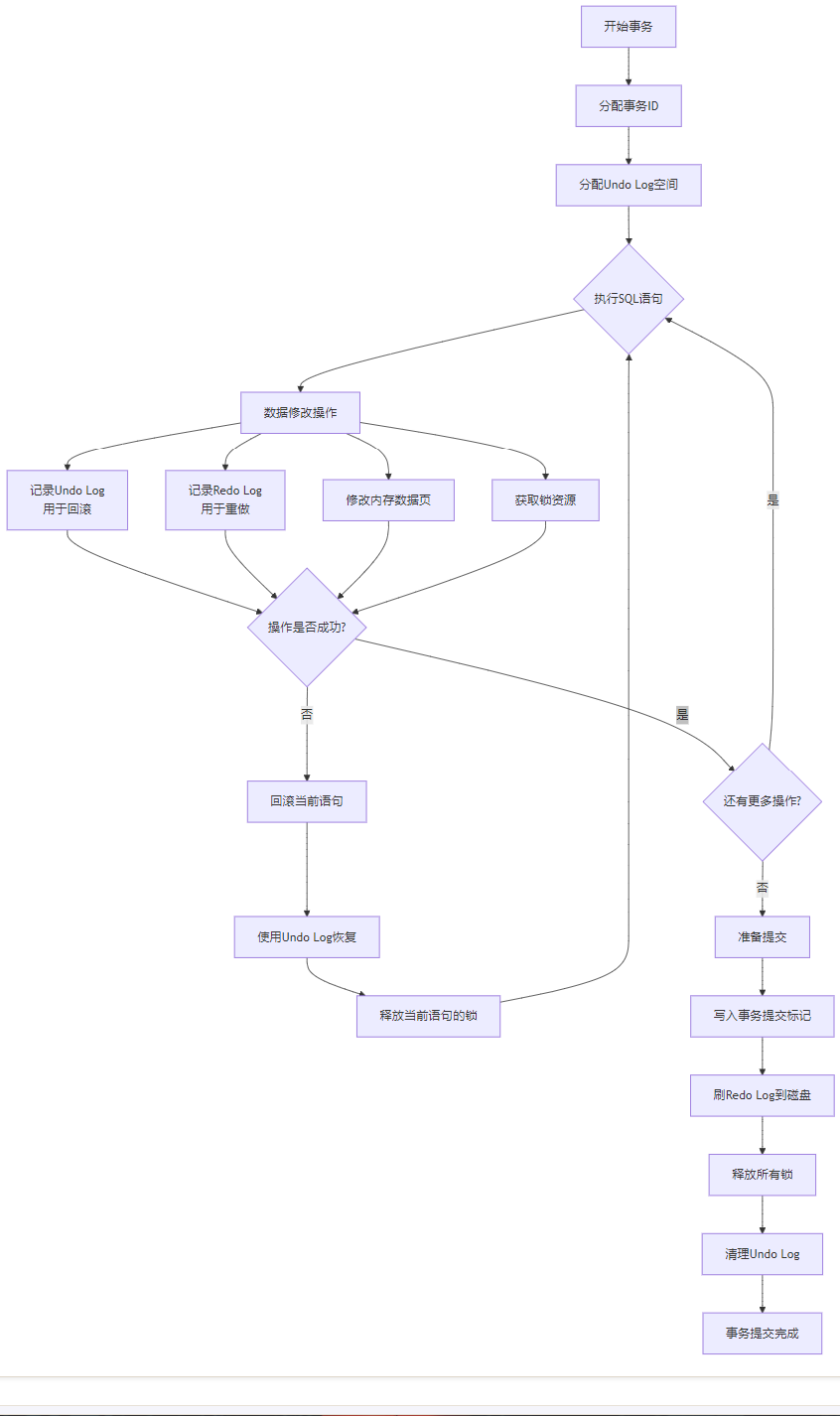
一个完整的事务执行过程展示了ACID各特性如何协同工作:
c
// 伪代码:完整的事务执行流程
execute_transaction(sql_statements) {
// 阶段1:事务开始
trx_start(trx);
// 阶段2:语句执行
for (stmt in sql_statements) {
// 2.1 解析和优化
plan = optimize_sql(stmt);
// 2.2 执行前准备
acquire_needed_locks(plan); // 隔离性:锁
// 2.3 执行数据修改
for (op in plan->operations) {
// 原子性:记录Undo Log
undo_rec = record_undo_for_operation(op);
// 持久性:记录Redo Log
redo_rec = record_redo_for_operation(op);
// 执行实际修改
execute_operation(op);
// 一致性:约束检查
if (!check_constraints(op)) {
// 违反约束,回滚当前语句
rollback_current_statement(undo_rec);
goto error_handling;
}
}
}
// 阶段3:事务提交
trx_commit(trx) {
// 3.1 准备提交(两阶段提交的第一阶段)
prepare_commit();
// 3.2 写入提交标记到Redo Log
write_commit_record();
// 3.3 刷Redo Log到磁盘(持久性)
flush_redo_log();
// 3.4 释放锁(隔离性)
release_locks();
// 3.5 清理Undo Log(原子性)
schedule_undo_for_purge();
}
return SUCCESS;
error_handling:
// 阶段4:事务回滚
trx_rollback(trx) {
// 使用Undo Log回滚所有修改(原子性)
rollback_using_undo_log();
// 释放锁(隔离性)
release_locks();
// 清理资源
cleanup_resources();
}
return ERROR;
}内存与磁盘的协同
InnoDB通过多层缓冲实现高性能的ACID保证:
内存结构:
┌─────────────────────────────────────────┐
│ Buffer Pool │
│ ┌──────────────────────────────────┐ │
│ │ Data Pages │ │
│ │ ┌────────────┐ ┌────────────┐ │ │
│ │ │ Dirty │ │ Clean │ │ │
│ │ │ Pages │ │ Pages │ │ │
│ │ └────────────┘ └────────────┘ │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Change Buffer │ │
│ │ (for secondary indexes) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Log Buffer │ │
│ │ (for Redo Log) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Undo Logs │ │
│ │ (in Undo Tablespace) │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────┘
磁盘结构:
┌─────────────────────────────────────────┐
│ Disk Storage │
│ ┌──────────────────────────────────┐ │
│ │ Data Files │ │
│ │ (ibdata1, ibd files) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Redo Log Files │ │
│ │ (ib_logfile0,1) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Undo Tablespaces │ │
│ │ (undo_001, undo_002) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Doublewrite Buffer │ │
│ │ (ib_16384_0.dblwr) │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────┘性能优化与ACID的平衡
在实际应用中,需要在ACID保证和性能之间取得平衡:
参数调优
sql
-- 影响ACID特性的关键参数
-- 1. 持久性相关
SET GLOBAL innodb_flush_log_at_trx_commit = 2; -- 平衡性能与持久性
SET GLOBAL sync_binlog = 0; -- 关闭二进制日志同步
-- 2. 隔离性相关
SET SESSION transaction_isolation = 'READ-COMMITTED'; -- 提高并发性
-- 3. 原子性相关
SET GLOBAL innodb_undo_log_truncate = ON; -- 自动清理Undo Log
SET GLOBAL innodb_max_undo_log_size = 1073741824; -- 设置Undo Log大小
-- 4. 一致性相关
SET GLOBAL foreign_key_checks = 0; -- 关闭外键检查(谨慎使用)监控与诊断
sql
-- 监控事务状态
SELECT * FROM information_schema.INNODB_TRX;
SELECT * FROM information_schema.INNODB_LOCKS;
SELECT * FROM information_schema.INNODB_LOCK_WAITS;
-- 监控Undo Log
SELECT * FROM information_schema.INNODB_METRICS
WHERE NAME LIKE '%undo%';
-- 监控Redo Log
SHOW ENGINE INNODB STATUS\G
-- 查看LOG部分最佳实践
-
合理选择隔离级别:
- 大多数应用使用READ COMMITTED或REPEATABLE READ
- 需要最高一致性时使用SERIALIZABLE
-
控制事务大小:
- 避免大事务,减少锁竞争和Undo Log占用
- 及时提交事务,释放锁资源
-
优化索引设计:
- 减少锁的粒度
- 提高查询性能
-
合理配置日志:
- 根据数据重要性调整
innodb_flush_log_at_trx_commit - 适当增加Redo Log大小,减少Checkpoint频率
- 根据数据重要性调整
高级特性与未来发展趋势
MySQL 8.0的ACID增强
原子DDL
MySQL 8.0引入了原子DDL,确保DDL操作要么完全成功,要么完全回滚:
sql
-- 原子DDL示例
CREATE TABLE t1 (id INT PRIMARY KEY);
CREATE TABLE t2 (id INT PRIMARY KEY);
-- 如果第二个语句失败,第一个也会回滚
-- 在MySQL 8.0之前,t1会被创建,t2不会实现原理:
c
// 伪代码:原子DDL实现
atomic_ddl_execute(ddl_statements) {
// 1. 准备阶段:记录DDL的Redo和Undo日志
ddl_log = prepare_ddl_log(ddl_statements);
// 2. 执行阶段
try {
for (stmt in ddl_statements) {
execute_ddl_statement(stmt);
}
// 3. 提交:标记DDL完成
commit_ddl_log(ddl_log);
} catch (error) {
// 4. 回滚:使用DDL日志回滚
rollback_using_ddl_log(ddl_log);
throw error;
}
}增强的在线DDL
MySQL 8.0改进了在线DDL机制,支持更多操作的在线执行:
sql
-- 在线添加索引(不阻塞DML)
ALTER TABLE t1 ADD INDEX idx_name (name), ALGORITHM=INPLACE, LOCK=NONE;
-- 在线修改列类型(某些情况)
ALTER TABLE t1 MODIFY COLUMN name VARCHAR(100), ALGORITHM=INPLACE;InnoDB集群与分布式事务
Group Replication中的ACID
MySQL Group Replication使用分布式一致性协议保证多节点间的ACID:
c
// 伪代码:Group Replication事务提交
group_replication_commit(trx) {
// 1. 本地准备
trx_prepare(trx);
// 2. 发送到组(使用Paxos协议)
certification_info = build_certification_info(trx);
send_to_group(certification_info);
// 3. 等待全局事务序
global_seq = wait_for_global_sequence();
trx->seq_no = global_seq;
// 4. 冲突检测
if (check_conflict(global_seq, certification_info)) {
// 冲突,需要回滚
trx_rollback(trx);
return CONFLICT_ERROR;
}
// 5. 提交(在所有节点上)
commit_on_all_nodes(trx);
return SUCCESS;
}XA分布式事务
InnoDB支持XA(eXtended Architecture)分布式事务:
sql
-- XA事务示例
XA START 'xid1'; -- 开始XA事务
INSERT INTO t1 VALUES (1);
XA END 'xid1';
XA PREPARE 'xid1'; -- 准备阶段
XA COMMIT 'xid1'; -- 提交阶段XA事务的两阶段提交:
- 准备阶段:所有参与者准备提交,记录Undo和Redo日志
- 提交阶段:协调者发送提交命令,所有参与者提交事务
总结
MySQL的ACID实现是一个复杂而精巧的系统工程,各个组件协同工作,在保证数据一致性和可靠性的同时,追求高性能和高并发:
- 原子性:主要通过Undo Log实现,记录了事务修改前的状态,支持回滚操作
- 持久性:主要通过Redo Log实现,采用WAL协议确保提交的数据不会丢失
- 隔离性:通过MVCC和锁机制实现,平衡了并发性能和数据一致性
- 一致性:是ACID的最终目标,通过原子性、隔离性和持久性共同保证
这些机制不是孤立的,而是紧密耦合的:
- Undo Log不仅支持原子性,也支持MVCC和一致性读
- Redo Log不仅保证持久性,也与Undo Log协同保证崩溃恢复
- 锁机制不仅保证隔离性,也与日志系统协同保证数据完整性
随着技术的发展,MySQL的ACID实现也在不断演进:
- MySQL 8.0引入了原子DDL、增强的在线DDL等功能
- 云原生环境对ACID实现提出了新的挑战和机遇
- 新硬件(如NVM)可能引发存储引擎的变革
理解MySQL的ACID底层实现,不仅有助于设计高性能、高可用的数据库应用,也能在面对复杂的数据一致性问题时,做出合理的技术决策。