
最近,法国AI公司LightOn在文档理解领域投下了一枚重磅炸弹------他们推出的LightOnOCR-2-1B模型仅凭10亿参数,就在权威OCR评测基准OlmOCR-Bench上击败了参数量大它9倍的竞争对手,登顶SOTA宝座。

更令人振奋的是,这个突破性的模型已经全面开源,相关的模型、代码和数据集均已上线Hugging Face,为开发者社区带来了一个强大而高效的生产力工具。
相关资源:
论文地址:https://arxiv.org/abs/2601.14251
项目主页:https://huggingface.co/blog/lightonai/lightonocr-2
代码仓库: https://huggingface.co/collections/lightonai/lightonocr-2
一、传统OCR的"积木塔"困境
在深入探讨LightOnOCR-2之前,我们有必要了解传统OCR技术面临的根本挑战。长期以来,文档处理流程就像搭建一个脆弱的"积木塔":
-
**版面分析模块:**判断标题、段落、表格的位置
-
**文本检测模块:**定位每个文字的具体坐标
-
**文字识别模块:**将图像转换为字符
-
**后处理模块:**恢复正确的阅读顺序和结构
这种多阶段流程存在明显缺陷:
-
**系统脆弱:**任何一个环节出错都会导致整个流程崩溃
-
**维护成本高:**需要同时维护和更新多个独立模块
-
**适应能力差:**面对新文档格式时,往往需要重新调整多个模块
二、端到端OCR:从"积木塔"到"全能专家"
LightOnOCR-2代表了一种全新的技术范式------端到端文档理解。这种模型像一个"全能专家",直接从原始文档图像输入,一步到位生成结构清晰、顺序正确的文本输出。
这种方法的优势显而易见:
-
**简化工程架构:**无需复杂的多模块流水线
-
**统一优化目标:**整个模型朝着最终任务目标优化
-
**更强适应性:**通过训练数据学习各种文档格式的通用表示
三、技术揭秘:1B参数如何胜过9B模型?
架构创新:强强联合的设计理念
LightOnOCR-2采用编码器-解码器架构,但每个组件都经过精心选择:
-
**视觉编码器:**基于Mistral-Small-3.1的预训练权重,采用原生支持高分辨率的ViT架构,能精准捕捉文档中的微小排版细节
-
**语言解码器:**初始化为Qwen3模型,具备强大的文本生成和结构化能力
-
**多模态投影器:**简单的双层MLP,高效连接视觉和语言模块
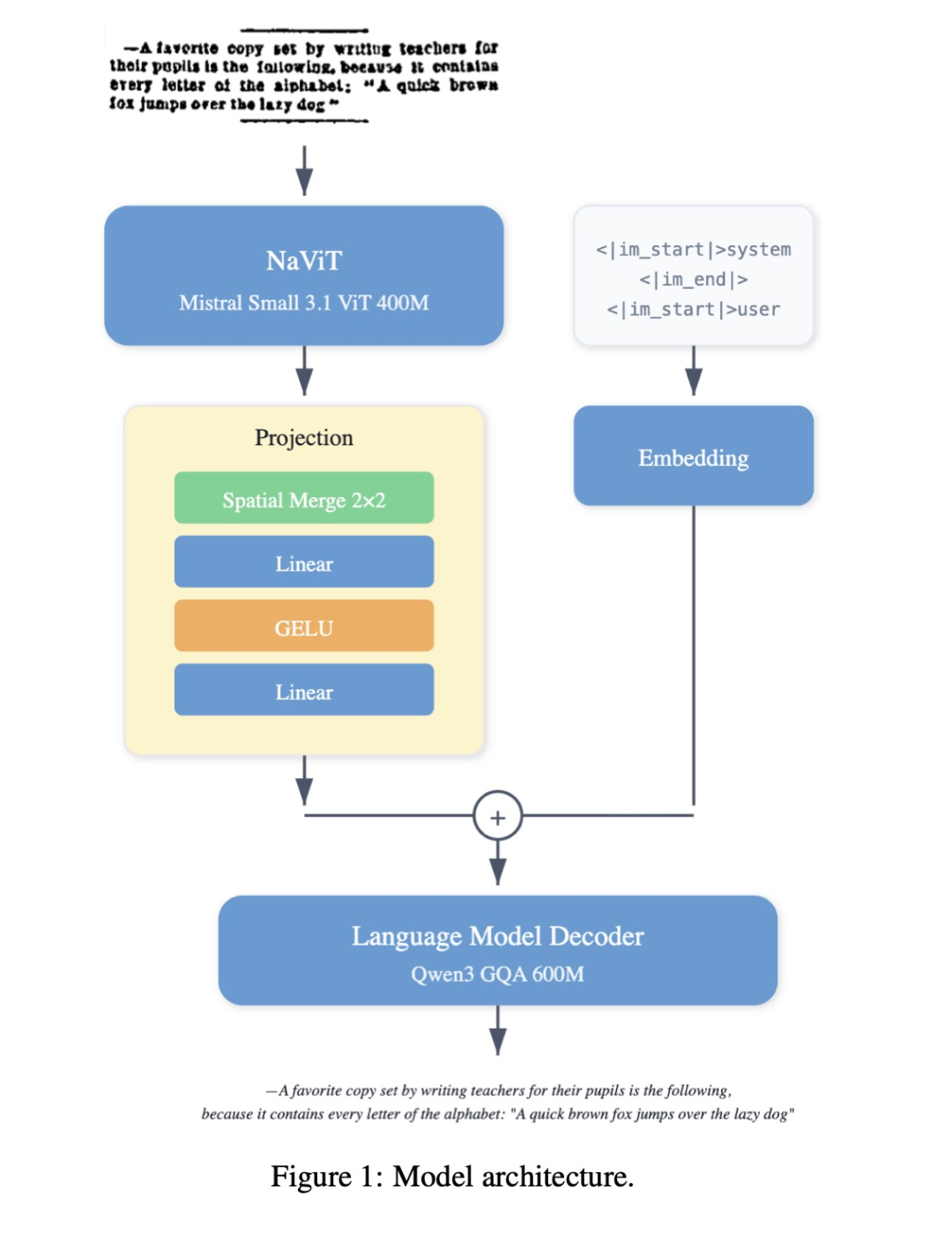
这种设计让模型从一开始就具备了顶级的视觉理解和语言生成能力。
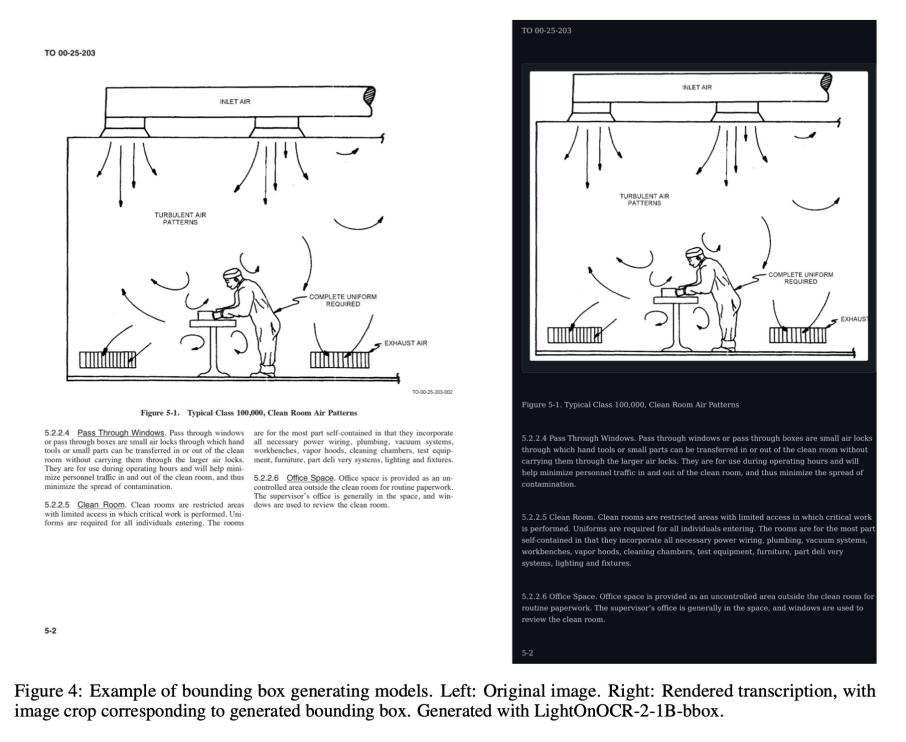
超越文字:图像边界框检测
LightOnOCR-2不仅能识别文字,还能精确定位文档中的图像区域。在生成的文本中,模型会使用类似Markdown的语法标记图像位置,并提供精确的边界框坐标。
这项功能的实现依赖于两个关键技术:
-
**坐标监督预训练:**在训练数据中引入精确的位置标注
-
**基于IoU奖励的强化学习:**通过强化学习微调,让模型的定位精度达到"指哪打哪"的水平
模型融合的艺术:任务算术合并
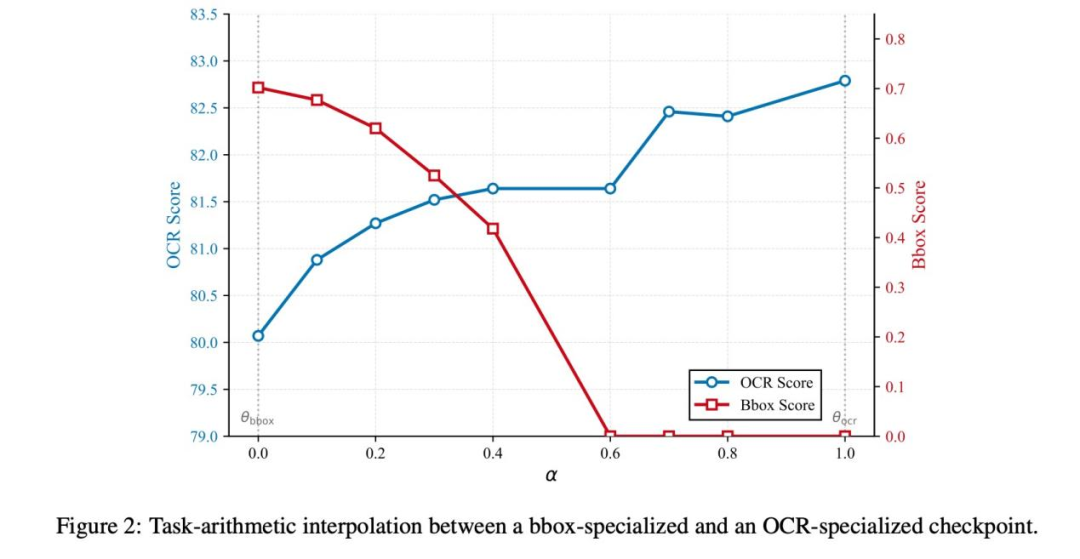
同时优化OCR和图像定位两个任务可能相互冲突。LightOn团队采用任务算术合并技术解决了这一难题:
-
分别训练专注于OCR和Bbox检测的两个"专家模型"
-
通过线性插值公式将两个模型的权重融合
-
调整混合比例α,在OCR精度和定位精度之间找到最佳平衡点
这种方法不需要额外训练,成本极低,却能创造出"双优"的融合模型。
四、性能表现:效率与精度的双重突破
基准测试:新的SOTA诞生
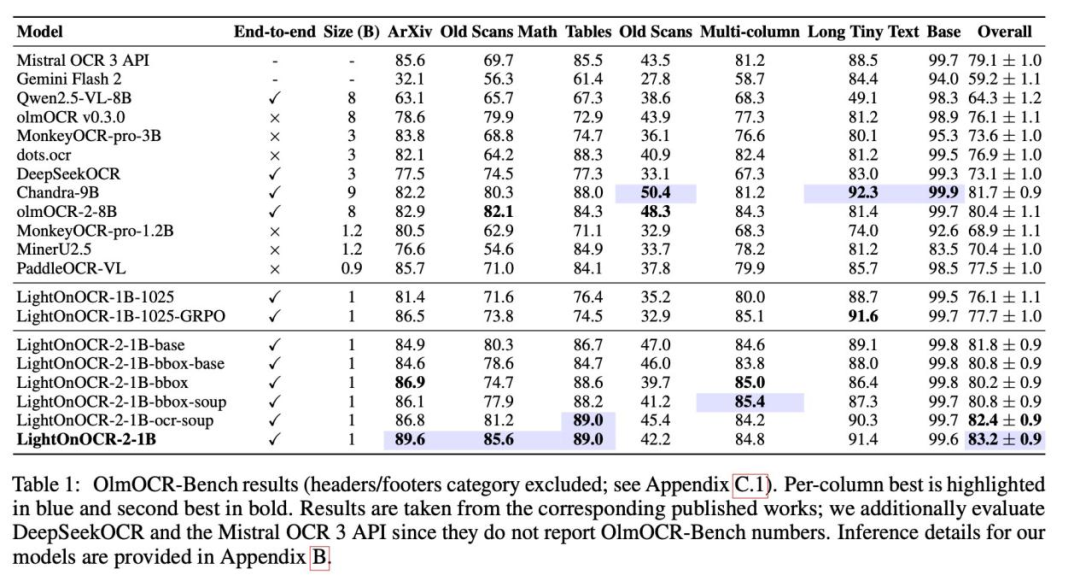
在OlmOCR-Bench基准测试中,LightOnOCR-2-1B取得了83.2分的优异成绩,超越了此前最强的9B参数模型Chandra(81.7分),成为新的榜单冠军。
推理效率:小体积大能量
-
在单张NVIDIA H100 GPU上,LightOnOCR-2的推理速度达到5.71页/秒:
-
比8B参数的olmOCR-2快1.7倍
-
比9B参数的Chandra快3.3倍以上
这种效率优势在实际部署中意味着显著的成本节约和响应速度提升。

鲁棒性表现
论文展示的测试案例令人印象深刻:
-
**复杂科学文献:**准确识别数学公式和特殊符号

-
**多栏复杂布局:**正确处理报纸、杂志等多栏文档
-
**老旧扫描件:**对模糊、倾斜、褪色的历史文档依然稳健

-
**表格处理:**保持表格结构完整,数据对齐准确

五、局限性及未来展望
目前,LightOnOCR-2对中日韩等非拉丁语系文字的支持仍有提升空间,手写体识别能力也需进一步加强。但这些限制并不妨碍其设计思想的先进性:
-
**高效架构设计:**证明了小参数模型通过精心设计也能超越大模型
-
**多任务统一:**为端到端文档理解提供了可复现的技术路径
-
**开源精神:**推动整个领域的技术进步和知识共享
结语
LightOnOCR-2的出现标志着OCR技术正朝着更智能、更统一、更高效的方向发展。它不仅是技术上的突破,更是对传统文档处理范式的重新思考。
对于开发者而言,这个开源模型提供了一个强大的起点;对于企业用户,它展示了端到端文档处理的可行性;对于研究社区,它开辟了多模态文档理解的新方向。
在数字化进程加速的今天,高效准确的文档处理能力已成为基础生产力工具。LightOnOCR-2以1B参数挑战9B巨无霸的成功经验,或许能为整个AI行业带来启示:有时候,精巧的设计比庞大的规模更重要。
