这是一篇关于 PGVector 中两种主流近似最近邻(ANN)索引------IVFFlat 和 HNSW 的深度解析。
引言:为什么需要 ANN 索引?
在处理高维向量数据时(例如文本 embedding、图像特征向量),传统的精确 K最近邻搜索(KNN,即暴力扫描所有数据计算距离)随着数据量的增加,速度会变得极慢。
ANN(Approximate Nearest Neighbor,近似最近邻) 索引的核心思想是:牺牲微小的精度(Recall,召回率),换取极大的搜索速度提升。
PGVector 提供了两种最主流的 ANN 索引实现:基于聚类的 IVFFlat 和基于图的 HNSW。
1. IVFFlat (Inverted File Flat) 索引
IVFFlat 是一种基于倒排文件和聚类的索引结构。它的核心思想是"分而治之"。
1.1 原理 (Principle)
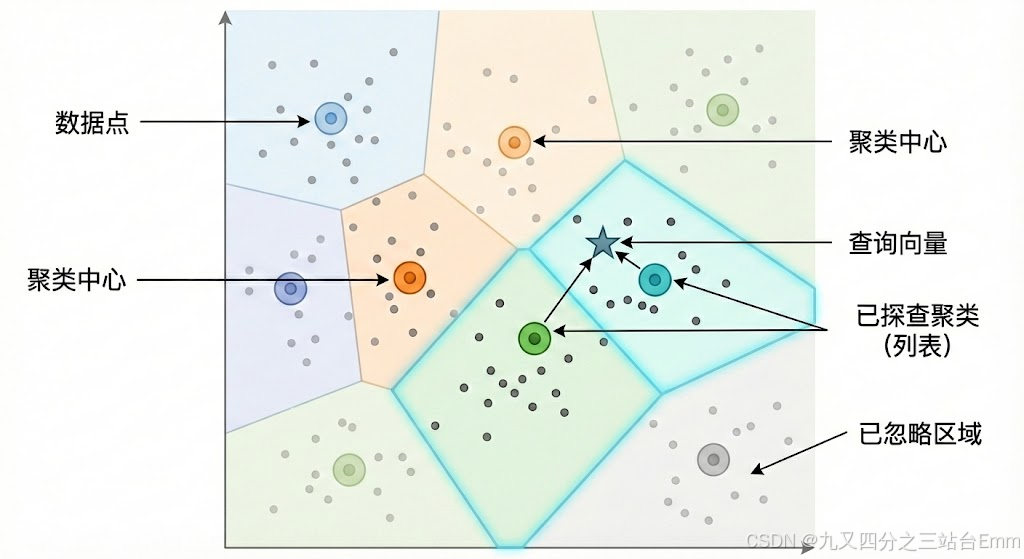
核心概念:空间划分(聚类)
- 聚类 (Clustering): IVFFlat 使用 K-Means 聚类算法将整个向量空间划分成若干个区域(称为 "Lists" 或 "Clusters")。每个区域都有一个中心点(Centroid)。
- 归档 (Inverted File): 数据库中的每个向量都会根据其与哪个中心点最近,而被分配到对应的区域列表中。
- 搜索 (Searching): 当一个新的查询向量到来时,它不需要和所有数据比对。
- 第一步:先计算查询向量与所有聚类中心点的距离,找到最近的几个中心点(粗筛)。
- 第二步:只在这些被选中的区域列表内部,对包含的向量进行精确的距离计算(细筛)。
比喻: 想象你要在一个巨大的图书馆里找一本关于"量子物理"的书。
- 暴力搜索: 从第一排书架的第一本书开始,一本本拿起来看是不是。
- IVFFlat: 你先看图书馆的区域指示牌(聚类中心),走到"科学区 -> 物理类"的书架前(找到最近的 Cluster),然后只扫描这个书架上的书。
1.2 IVFFlat 原理示意图
1.3 建索引 (Index Building)
创建 IVFFlat 索引时,最重要的参数是 lists。
lists(聚类数量): 决定了将空间划分成多少个区域。- 前置条件: 为了计算出高质量的聚类中心,在创建索引前,表中必须已经包含足够多的数据。 如果是空表建索引,效果会非常差。
SQL 示例:
sql
-- 假设你的向量列名为 embedding,使用余弦距离 (vector_cosine_ops)
-- 将数据划分为 100 个聚类区域
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);lists 参数建议:
一个经验法则将 lists 设置为数据行数的平方根附近。
- 对于小于 100万行的数据:
lists≈ rows / 1000 - 对于大于 100万行的数据:
lists≈ sqrt(rows) - (注:这只是起点,具体需根据数据分布测试)
1.4 查询调参 (Query Tuning)
IVFFlat 最大的优势在于查询时的灵活性。你可以在查询的 Session 级别调整参数,在速度和精度之间做权衡,而无需重建索引。
ivfflat.probes(探查数量): 决定了查询时要搜索多少个最近的聚类区域。
调参权衡:
probes = 1:速度最快,但精度(召回率)最低。只搜索最近的那一个聚类。probes = lists:变成了暴力搜索,精度最高(100%),但速度最慢。- 通常设置:
probes的值远小于lists。例如lists=1000时,probes可能设置为 10 到 50。增加probes会线性增加查询时间,同时提高召回率。
SQL 示例 (在查询前设置):
sql
-- 设置当前会话只搜索最近的 10 个聚类区域
SET ivfflat.probes = 10;
SELECT * FROM items ORDER BY embedding <=> '[...查询向量...]' LIMIT 5;2. HNSW (Hierarchical Navigable Small World) 索引
HNSW 是目前业界最先进、综合性能最好的 ANN 算法之一。它基于多层图结构。
2.1 原理 (Principle)
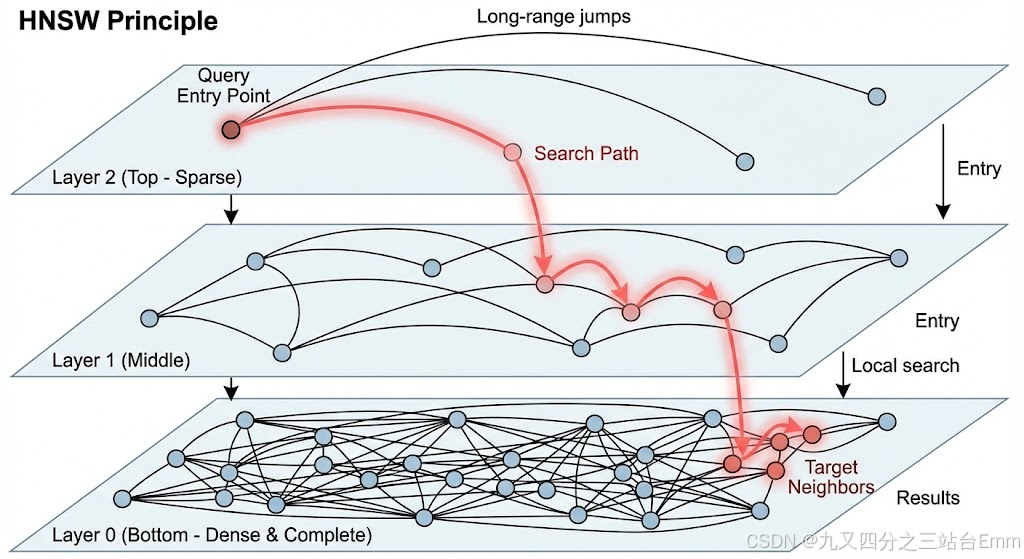
核心概念:分层图 + 小世界网络
- 小世界网络 (Small World): 这是一个图论概念,意味着图中的任意两个节点,可以通过很少几步跳跃连接起来(类似"六度人脉理论")。HNSW 构建的图确保了节点间的高效连通性。
- 分层结构 (Hierarchical): HNSW 将图分为多个层级(Layers)。
- 顶层 (Top Layers): 节点稀疏,连接线很长,用于快速跨越广阔的向量空间,进行"长距离跳跃"。
- 底层 (Bottom Layers): 节点密集,包含所有数据点,连接线较短,用于精细的局部搜索。
搜索过程 (Greedy Search):
查询从最顶层的一个入口节点开始。在每一层,它贪婪地移动到当前节点邻居中离目标最近的那个节点。当在当前层找不到更近的邻居时,就下沉到下一层继续这个过程。最终在最底层(Layer 0)找到近似最近邻。
比喻: 想象一次跨国自驾旅行寻找一个具体地址。
- 顶层(高速公路网): 你先上高速,快速跨越几个省份(长距离跳跃),到达目标城市附近。
- 中层(城市主干道): 下了高速,走城市快速路接近目标区域。
- 底层(社区街道): 最后在社区的小路上慢慢找,直到找到具体的门牌号。
2.2 HNSW 原理示意图
2.3 建索引 (Index Building)
HNSW 的构建过程比 IVFFlat 更复杂,也更消耗内存。它有两个关键参数来控制图的质量和构建速度。
-
m(最大连接数): 每个节点在每一层最多能有多少个邻居(连接)。 -
m越大:图的连通性越好,召回率越高,但内存占用增加,构建时间变长。通常在 16 到 64 之间。 -
ef_construction(构建时候选队列大小): 在插入新节点构建图时,用于寻找最近邻的动态候选列表的大小。 -
ef_construction越大:构建的图质量越高(导航性更好),查询速度和召回率会提升,但索引构建时间会显著增加。
SQL 示例:
sql
-- 使用 HNSW 索引,设置最大连接数为 16,构建队列大小为 64
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64);参数建议:
m: 默认值通常是一个好的起点(如 16)。如果你对召回率要求极高且内存充足,可以尝试增加到 32 或 64。ef_construction: 建议设置为m的 2 倍或更高(例如m=16时设为 64 或 128)。这个值越高,建索引越慢,但后续查询效果越好。
2.4 查询调参 (Query Tuning)
与 IVFFlat 类似,HNSW 也允许在查询时调整参数以平衡速度和精度。
hnsw.ef_search(查询时候选队列大小): 在搜索过程中,维护的动态候选节点列表的大小。
调参权衡:
ef_search越大:搜索时探索的节点越多,找到真实最近邻的概率(召回率)越高,但查询速度越慢。- 重要约束:
ef_search的值必须大于等于你查询语句中LIMIT k的k值。否则,PGVector 会自动将其调整为k。
SQL 示例 (在查询前设置):
sql
-- 假设我们要查询最近的 10 个邻居 (LIMIT 10)
-- 我们将搜索队列设置为 40,以获得比默认值更好的召回率
SET hnsw.ef_search = 40;
SELECT * FROM items ORDER BY embedding <=> '[...查询向量...]' LIMIT 10;总结对比
| 特性 | IVFFlat (倒排文件) | HNSW (分层图) |
|---|---|---|
| 核心原理 | 空间划分 (聚类) | 图导航 (小世界网络) |
| 构建速度 | 快 (基于 K-Means) | 慢 (需逐个插入节点构图) |
| 内存占用 | 较低 | 较高 (存储图的边) |
| 查询速度 | 中等偏快 (取决于 probes) | 极快 (通常是最快的选择) |
| 精度 (Recall) | 好 (可通过 probes 调整) | 极好 |
| 数据要求 | 建索引前需要有数据以计算聚类中心 | 可在空表上创建,随数据插入动态更新 |
| 适用场景 | 数据集非常大,内存受限,或需要频繁批量重建索引的场景。 | 对查询延迟和精度要求极高,且内存充足的生产环境首选。 |