🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 ------ 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- [1. 背景介绍](#1. 背景介绍)
-
- [1 引言](#1 引言)
- [2 多模态食物学习(MMFL)概述](#2 多模态食物学习(MMFL)概述)
- [3 单模态信号的采集与表示](#3 单模态信号的采集与表示)
-
- [3.1 面向食物的视觉模态(Food-Oriented Vision)](#3.1 面向食物的视觉模态(Food-Oriented Vision))
- [3.2 面向食物的听觉模态(Food-Oriented Audition)](#3.2 面向食物的听觉模态(Food-Oriented Audition))
- [3.3 面向食物的嗅觉模态(Food-Oriented Olfaction)](#3.3 面向食物的嗅觉模态(Food-Oriented Olfaction))
- [3.4 面向食物的味觉模态(Food-Oriented Gustation)](#3.4 面向食物的味觉模态(Food-Oriented Gustation))
- [3.5 面向食物的触觉模态(Food-Oriented Tactility)](#3.5 面向食物的触觉模态(Food-Oriented Tactility))
- [3.6 面向食物的文本模态(Food-Oriented Text)](#3.6 面向食物的文本模态(Food-Oriented Text))
- [4 多模态食物学习方法(Methods of MMFL)](#4 多模态食物学习方法(Methods of MMFL))
-
- [4.1 用于多粒度食物分析的 MMFL 方法(MMFL for Multi-Grained Food Analysis)](#4.1 用于多粒度食物分析的 MMFL 方法(MMFL for Multi-Grained Food Analysis))
-
- 视觉+上下文融合的典型任务设计
- 食物识别任务中的模态融合实践
- [食物检测与分割中的 MMFL 应用](#食物检测与分割中的 MMFL 应用)
- [营养估计任务(Nutrition Estimation)](#营养估计任务(Nutrition Estimation))
- [多模态基础模型(Foundational Models)在营养估计中的应用](#多模态基础模型(Foundational Models)在营养估计中的应用)
- [4.2 面向食物检索的 MMFL 方法(MMFL for Food Retrieval)](#4.2 面向食物检索的 MMFL 方法(MMFL for Food Retrieval))
-
- 主流方法路径包括:
- 面临的关键挑战之一:
- 注意力机制的引入:
- 面向预训练大模型的探索:
- [总结对比四类方法(见图 3):](#总结对比四类方法(见图 3):)
- [4.3 面向食物生成的 MMFL 方法(MMFL for Food Generation)](#4.3 面向食物生成的 MMFL 方法(MMFL for Food Generation))
-
- 图像生成任务(以"从食谱生成图像"为例):
- [Diffusion 模型的兴起:](#Diffusion 模型的兴起:)
- 从图像/视频生成食谱:
- 方法分类与对比总结:
- [4.4 面向烹饪视频索引与检索的 MMFL 方法(MMFL for Cooking Video Indexing and Retrieval)](#4.4 面向烹饪视频索引与检索的 MMFL 方法(MMFL for Cooking Video Indexing and Retrieval))
- [4.5 面向饮食推荐的 MMFL 方法(MMFL for Diet Recommendation)](#4.5 面向饮食推荐的 MMFL 方法(MMFL for Diet Recommendation))
-
- [通用推荐模型框架通常包含三个组件 73:](#通用推荐模型框架通常包含三个组件 [73]:)
- 典型研究工作包括:
- 健康导向与疾病特定推荐系统:
- [基础模型(Foundational Models)的新机遇:](#基础模型(Foundational Models)的新机遇:)
- [4.6 面向人-食交互(HFI)的 MMFL 方法(MMFL for HFI)](#4.6 面向人-食交互(HFI)的 MMFL 方法(MMFL for HFI))
- [4.7 总结与讨论(Summary and Discussion)](#4.7 总结与讨论(Summary and Discussion))
-
- 多粒度食物分析方面:
- 跨模态检索与生成方面:
- 视频与推荐任务方面:
- 人-食交互与新兴方向:
- 面向未来的大模型趋势:
- 当前局限与未来发展趋势:
- [MMFL 的跨学科特性与协同潜力:](#MMFL 的跨学科特性与协同潜力:)
- [5 多模态食物数据集(Multimodal Food Dataset)](#5 多模态食物数据集(Multimodal Food Dataset))
- [6 应用(Applications)](#6 应用(Applications))
-
- [6.1 医疗健康(Healthcare)](#6.1 医疗健康(Healthcare))
- [6.2 餐饮服务(Catering)](#6.2 餐饮服务(Catering))
- [6.3 农业与食品工业(Agriculture and Food Industry)](#6.3 农业与食品工业(Agriculture and Food Industry))
- [6.4 食品文化(Culture)](#6.4 食品文化(Culture))
- [6.5 综合讨论(Discussion)](#6.5 综合讨论(Discussion))
- [7 挑战与未来工作(Challenges and Future Work)](#7 挑战与未来工作(Challenges and Future Work))
-
- [7.1 MMFL 基准构建(MMFL Benchmark)](#7.1 MMFL 基准构建(MMFL Benchmark))
- [7.2 多模态食物基础模型(Multimodal Food Foundation Models)](#7.2 多模态食物基础模型(Multimodal Food Foundation Models))
- [7.3 多模态饮食估计(Multimodal Diet Estimation)](#7.3 多模态饮食估计(Multimodal Diet Estimation))
- [7.4 类人多模态感知(Human-Like MMFL)](#7.4 类人多模态感知(Human-Like MMFL))
- [7.5 面向新兴应用的 MMFL(MMFL for Novel Applications)](#7.5 面向新兴应用的 MMFL(MMFL for Novel Applications))
- [8 结论(Conclusion)](#8 结论(Conclusion))
1. 背景介绍
Min W, Hong X, Liu Y, et al. Multimodal Food LearningJ. ACM Transactions on Multimedia Computing, Communications and Applications, 2025.
🚀以上学术论文翻译由ChatGPT辅助。
食品为中心的研究在多媒体社区中受到越来越多的关注,因为它在人类生存、营养与健康、愉悦与享受等方面具有深远的影响。人类对食物的体验通常是多感官的:我们会看到食物的外观,闻到它的气味,品尝其风味,感受其质地,并在咀嚼时听到声音。因此,**多模态食物学习(multimodal food learning)**在食品中心研究中至关重要,其目标是关联来自多个食物模态的信息,以支持从识别、检索、生成、推荐到交互等多种多媒体任务,从而推动在医疗健康、农业等不同领域的应用。
然而,据我们所知,目前尚无关于该主题的综述性研究。为填补这一空白,本文形式化定义了多模态食物学习,并全面综述了其典型任务、技术进展、现有数据集与应用场景,旨在为研究人员和实践者提供系统性的研究蓝图。
在总结当前研究现状的基础上,我们进一步指出了若干开放性研究问题与有前景的研究方向,包括:
- 多模态食物学习基准体系的构建;
- 多模态食物基础模型(foundation model)的构建;
- 多模态膳食估计(multimodality diet estimation)方法的研究。
我们还指出,多媒体领域与食品科学领域之间更紧密的协同合作,不仅有助于应对当前面临的诸多挑战,同时也能开辟更多全新的研究机会,推动多模态食物学习的快速发展。
本文是该领域的首篇综合性综述文章,我们汇总评述了约 170 篇研究工作,相信这将惠及该研究社区内外的学术与产业界。
1 引言
食物是人类生命的基础,对我们的生存、健康、情绪与文化有着深远的影响。由于其在日常生活中的独特作用,与食物相关的分析与应用长期以来一直是多媒体领域的重要研究课题之一 51, 81, 148。
人类对食物的体验是**多感官(multi-sensory)**的。如图 1 所示,我们通过视觉看到食物,通过嗅觉感知其气味,通过味觉体验其风味,通过触觉感受其质地,并在咀嚼或咬合时通过听觉获得声音反馈。此外,我们还会通过语言和文本来描述食物。因此,要实现对食物的全面感知与认知,必须调动人类的所有感官,这被称为 食物智能(food intelligence) 131, 132。
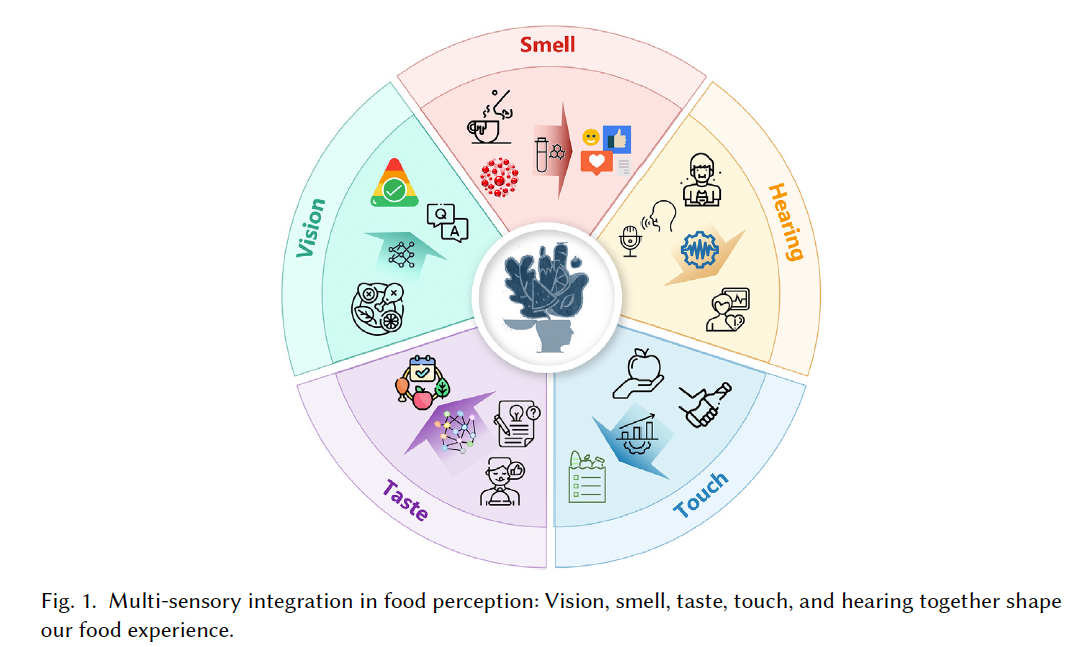
在食物智能中,不同模态扮演着不同的角色:
- 食物的视觉信息对于选择与接受起关键作用;
- 咀嚼过程中的声音有助于判断食物的新鲜程度;
- 嗅觉与味觉则在食物偏好与选择中发挥重要作用 74。
人类的多感官系统会通过大脑中的神经网络整合这些感官信息及其交互,从而实现对食物的感知、理解与欣赏------这正是**多模态食物学习(MultiModal Food Learning, MMFL)**的目标。
MMFL 致力于构建模型,用以关联并整合食物相关的多种模态信息 ,实现对食物的智能理解与建模。其研究可以追溯到 21 世纪初期,早期研究多聚焦于多模态烹饪视频的索引任务。例如,有学者提出将视频片段与菜谱中的烹饪步骤进行关联的方法 35, 81。
随后,为了服务于健康管理,研究者提出了 Multimedia FoodLog 系统 3,将食物图像处理与营养数据库结合,用于记录个体的日常饮食摄入。随着深度学习的快速发展,越来越多研究者开始探索各类 MMFL 方法 74,涵盖任务包括但不限于:
- 食物分类(food classification) 33, 143
- 菜谱检索与生成(recipe retrieval & generation) 71, 137
- 营养成分评估(nutritional assessment) 134
- 膳食推荐(dietary recommendation) 142
- 风味预测(flavor prediction) 8
近年来,随着多模态大语言模型(multimodal Large Language Models, LLMs)生成能力的提升,它们也被引入到食物计算任务中,如膳食评估、食物推荐、面向食物的视觉问答(Visual Question Answering, VQA)等任务 109。
相较于通用多模态学习 ,通常聚焦于主流模态(如视觉与语言) 6,MMFL 需要考虑更多特殊模态,如嗅觉与味觉 ,以完整支持食物的多媒体体验与面向食物的应用,如利用虚拟现实实现沉浸式真实的用餐体验,这也带来了独特的技术挑战。
例如:
- 主流模态(如图像、文本)的信息采集已较为成熟;
- 然而,嗅觉与味觉信息的采集与数字化因其生成机制复杂,仍面临巨大挑战,亟需新的数据处理方式。
因此,如何实现有效的多模态食物数据采集、表示与学习,成为MMFL研究中亟需深入思考的问题。
考虑到其独特性,若想全面综述该研究方向,我们必须回答以下几个关键问题:
- 如何实现多模态食物信号的采集与数字表示?
- 如何实现多模态食物信息之间的交互建模?
- 如何构建模态丰富的食物数据集以推动 MMFL?
- MMFL 的未来发展趋势是什么?
为回答上述问题,本文的组织结构如下:
- 第 2 节:形式化定义 MMFL 并给出其总体框架;
- 第 3 节:介绍单模态信号的采集与表示方法;
- 第 4 与第 5 节:综述典型任务、其技术进展与已有多模态食物数据集;
- 第 6 节:总结多模态食物学习在各类应用场景中的落地实践;
- 第 7 节:探讨当前面临的主要挑战与未来研究展望;
- 第 8 节:给出全文总结与结论。
2 多模态食物学习(MMFL)概述
食物是与人类生存高度相关的显著类别,因此与食物相关的感知与认知过程更加复杂,需要整合多种感官层面的信息 30, 132。例如,视觉信息应与味觉和嗅觉信息联合用于食物识别,因为这些属性共同构成了食物刺激的感知维度。
类似于人类通过多感官信号感知并与食物交互的方式,**多模态食物学习(MMFL)**的目标是构建具有智能理解、推理与学习能力的"面向食物的智能体(food-oriented agents)",通过多模态信息融合来实现"食物智能(food intelligence)"。
在此背景下,"food-oriented agents" 通常指的是能够处理和关联多种食物模态信息的模型或算法系统。
如图 2 所示,**食物模态(food modalities)的范围非常广泛,既包括感官模态(vision、smell、taste、touch、hearing),也包括更抽象的模态,如语言(language)和分子结构(molecular structure)等非感官层面的信息。因此,食物模态数据具有多模态性与多尺度性(multimodal and multiscale)**特征。
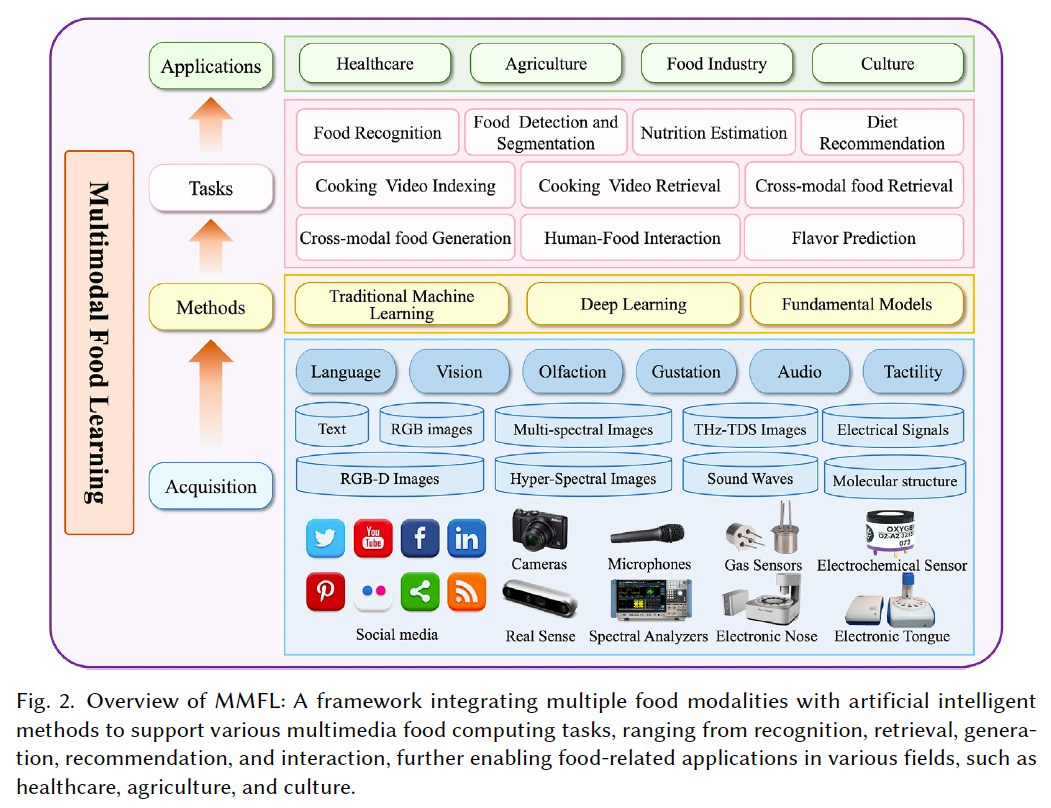
这些多模态食物数据可以来自不同来源:
- 网络空间(cyberspace):如网站、社交媒体等;
- 硬件设备:如摄像头、多光谱/高光谱成像设备、电子鼻、电子舌等。
常见的模态信息包括食物图像、菜谱文本、烹饪视频等,但还有一些更独特的模态信息,如嗅觉与触觉感知等。此外,传感器的类型也高度多样,例如光学成像设备可采集 RGB、RGB-D、近红外光谱、多光谱等多种信号形式。
另一个重要特征是多尺度性:
- 在宏观层面,可获取菜品、食材等结构性数据;
- 在微观层面,还可以建模分子尺度甚至更细粒度的食物成分信息,例如宏量营养素(如蛋白质、脂肪、碳水化合物等)。
在获取上述多模态食物数据的基础上,MMFL 方法通常涉及以下几类技术流程:
- 表征学习(representation)
- 模态转换(translation)
- 多模态融合(fusion)
- 对齐与联合学习(alignment and co-learning)
这些方法涵盖了传统机器学习、深度学习与基础模型(foundation models)等技术路径,进一步支持多媒体食物计算中的多种任务,包括但不限于:
- 食物识别(recognition)
- 信息检索(retrieval)
- 内容生成(generation)
- 个性化推荐(recommendation)
- 人机交互(interaction)
上述任务广泛应用于餐饮、健康、文化等多个领域,构成了食物相关多媒体技术应用的技术基座。
3 单模态信号的采集与表示
本节简要介绍每种食物模态的生成机制、采集方式、数字化表示方法及其典型任务。
3.1 面向食物的视觉模态(Food-Oriented Vision)
视觉在人类分析与识别食物中至关重要,通常是人们选择与消费食物的首要依据。对食物的第一印象通常由其整体外观(如大小、形状与颜色)构成,这些信息与过往经验比对后,可预测其感官质量与安全性。
我们可以通过多种成像技术采集食物的视觉信息,其中最常用于多媒体领域的是由摄像头捕获的图像,如 RGB 和 RGB-D 图像 78, 97, 134。此外,还可以使用光谱分析仪采集不可见光,生成多光谱、高光谱与太赫兹(THz-TDS)图像。最常用于食物视觉的波段是可见光-近红外波段,广泛应用于食物特性检测。
类似于 RGB 图像,光谱图像可以表示为一个三维矩阵,其中一维为光谱通道数。光谱信息包含食物的物理与化学属性,因此在食品科学与农业中广泛用于质量分析与控制 42。不过,在多媒体研究中关于光谱成像的工作仍然较少,尤其是在面向食物的应用中 150。
视觉模态的典型任务包括:
- 食物识别(food recognition)48, 60, 79;
- 食材识别(ingredient recognition)144, 146;
- 食物图像检索(food retrieval)123;
- 食物检测(food detection)1;
- 食物分割(food segmentation)52;
- 视觉营养分析(visual nutrition analysis)134。
与通用视觉任务不同,食物视觉语义具有细粒度、高类内变异与类间相似性高的特点。食物图像通常信息结构不明确,模式复杂且不固定,且包含多种混合分布的食材成分。
在餐厅自助结算场景中,食物检测用于智能识别菜品 1;而精确定位食材需要图像分割 52。部分研究还探索基于 RGB 或高光谱图像的营养成分估计任务 24, 55,如碳水化合物、蛋白质与脂肪的预测。由于 RGB 图像精度有限,多模态信息融合将是必要路径,后续将在 MMFL 部分进一步探讨。
3.2 面向食物的听觉模态(Food-Oriented Audition)
在食物感知中,听觉线索(如咬合时的清脆声)会影响进食体验。与食物相关的声音包括:咀嚼声、切割声、饮料气泡声等,这些声音传达出食物的质地、新鲜度与口感等信息。
听觉线索对食物属性(如脆度与新鲜感)的多感官感知起到重要作用。例如,咬苹果时的脆响或饮料中的气泡声可显著增强感官体验,提高消费者满意度 20。
在单模态应用中,有研究利用音频信息与机器学习方法进行:
- 食物数量识别 46;
- 食物质地属性预测 95。
此外,音频信息通常与其他模态联合使用以提高预测性能 54, 80。
3.3 面向食物的嗅觉模态(Food-Oriented Olfaction)
嗅觉使人能够感知气态中的挥发性化学物质。相比于视觉(光波长)与听觉(声音频率)具有明确物理-感知映射,嗅觉感知机制更为复杂,因此采集设备需包含气体传感器,如广泛使用的电子鼻(e-nose) 49。
加入嗅觉模态可以增强多媒体系统的现实感与沉浸感,例如在烹饪类多媒体中引入嗅觉信号(音频+视频+气味)83。
当前嗅觉信号数字化感知主要有两种建模方式:
- 认知建模视角:建立气味与目标属性之间的关联,用机器学习建模嗅觉感知与食物属性之间的关系 7;
- 化学建模视角:建立气味与分子结构之间的映射关系,将认知信息转化为化学信息 53。
嗅觉信息在食物感知中极为关键,已被广泛用于风味调控 47、新鲜度预测 34 等任务。
3.4 面向食物的味觉模态(Food-Oriented Gustation)
味觉通过味蕾与食物中的可溶性物质接触产生,主要包括五种基本味觉:甜、咸、酸、苦、鲜(umami)。
味觉信息在多媒体领域的数字化研究相对较少,但其与嗅觉同属化学感知模态,具有类似的建模路径。数字味觉信号主要通过**电子舌(e-tongue)**等基于物理、化学或生物化学机制的传感器采集 125。
味觉建模方法包括:
- 认知视角:用电子舌感知整体样品信号,训练模型预测类别或属性 59;
- 化学视角:使用已知成分与标签数据,建立 tastant 分子与感知信息之间的映射关系,常采用 BERT、CNN 等方法 44。
多媒体研究中也有部分工作尝试在增强现实或虚拟现实系统中模拟味觉体验 102, 103。
3.5 面向食物的触觉模态(Food-Oriented Tactility)
触觉感知依赖于直接接触物体并感知其物理属性,相关信息通过触觉传感器获取。用于食物的触觉属性包括:质地、硬度、水分与温度,可用于食物成熟度评估、烹饪状态判别、食材分类等任务 68, 160。
食物触觉信息还被广泛用于机器人抓取与交互 70。与其他物体不同,食物触觉信息具有动态变化特性,如烹饪过程中的硬度与湿度随时间变化,因此传感系统需具备实时响应能力。
在触觉机器人控制系统中,已有研究提升了食物交互控制的精度与稳定性 70。
3.6 面向食物的文本模态(Food-Oriented Text)
文本模态包括:菜谱、食材列表与营养成分表、食品产品信息、用户评论等。这些文本信息为理解食物的各个方面提供了丰富基础。
典型研究包括:
- 菜谱-食材网络构建 88;
- 烹饪知识发现 106;
- 食物日志记录与营养管理 155;
- 多模态知识图谱构建与融合 77。
引入食物知识图谱到文本计算中有助于提升个性化饮食推荐的准确性 16, 39。
近年来,**大语言模型(LLMs)**也被用于处理复杂的食物相关问题,一些研究开发了专用的 food-specific LLMs 96, 109, 156, 163,应用于:
- 食物实体抽取;
- 个性化推荐;
- 营养配餐;
- 智能餐厅管理;
- 烹饪建议等任务。
借助 LLM 与图计算,研究者正推动从智能厨房设备到个性化菜谱推荐等多样化应用的发展。
4 多模态食物学习方法(Methods of MMFL)
MMFL 的发展历程大致可分为三个阶段,与机器学习的发展趋势高度一致:
- 第一阶段:主要采用传统机器学习方法,如概率图模型(probabilistic graph model)与多核学习(multiple kernel learning)9, 40,在此阶段,单模态特征提取与模态间相关性建模是分开的;
- 第二阶段:随着深度神经网络的兴起,传统方法逐步被深度模型替代,实现了特征提取与模态对齐的一体化建模框架。此阶段,深度神经网络成为 MMFL 的主流方法,尤其是大型多模态数据集如 Recipe1M 116 的发布进一步推动了该领域发展;
- 第三阶段:大语言模型(LLMs)的出现,催生了面向食物的多模态 LLM 方法,用于营养估计、饮食推荐、食物视觉问答(VQA)等任务 109。
在每一阶段中,MMFL 方法与通用多模态学习类似,均面临表征(representation)、转换(translation)、对齐(alignment)与融合(fusion)等关键挑战 6。
当前,MMFL 广泛应用于典型多媒体食物计算任务,包括:
- 多粒度食物分析(如识别、检测与分割);
- 跨模态检索与生成;
- 烹饪视频索引与检索;
- 饮食推荐与人-食交互(Human-Food Interaction, HFI)体验建模。
4.1 用于多粒度食物分析的 MMFL 方法(MMFL for Multi-Grained Food Analysis)
多粒度食物分析旨在从粗到细地获取食物语义信息,包括食物种类、食材组成以及营养含量,通过多模态信息的融合实现更高精度的感知与推理。该方向目前主要包括四类任务:
- 食物识别(Recognition)
- 食物检测(Detection)
- 食物分割(Segmentation)
- 营养估计(Nutrition Estimation)
视觉+上下文融合的典型任务设计
食物图像常与音频、文本、地理位置信息等上下文模态相关联。例如:
- 视觉模态:提供颜色、形状、质地、食材构成与光谱特征;
- 音频模态:提供烹饪状态线索,如沸腾(boiling)与慢炖(simmering);
- 文本模态:提供操作步骤、营养信息等描述性知识。
因此,跨模态信息融合是提高预测性能的关键。
食物识别任务中的模态融合实践
Gowda 等人 33 对多种基于 Transformer 的视觉-语言模型在食物分类任务中进行了比较,发现预训练的多模态模型显著优于未预训练架构 143。
Bettadapura 等 9 使用地理位置信息辅助识别,构建餐厅上下文食物图像数据集,并通过多核学习融合手工特征进行识别;
Xu 等 153 提出融合深度视觉特征与位置信息的地理局部化识别模型;
Herranz 等 40 构建概率图模型联合建模菜品图像、餐厅与地理位置信息。
Mirtchouk 等 80 利用多模态传感数据结合随机森林回归进行更准确的食物分类;
Lee 等 54 结合音频与超声波信息进行连续摄食行为识别。
食物检测与分割中的 MMFL 应用
- Joan 等 99 构建融合食物托盘 RGB 图像与菜单文本信息的多模态神经网络用于托盘检测;
- Raju 等 101 基于 k-means 聚类,分割多种温度下外观相似的食物,提升分割鲁棒性;
- Lan 等 52 提出通用分割框架 FoodSAM,可适配多数据集和挑战;
- Wu 等 149 提出"开放词表的食物分割"问题,并设计跨模态嵌入模块提升零标签类别的分割能力。
营养估计任务(Nutrition Estimation)
与宏观语义预测任务(如识别/检测)不同,营养估计任务关注营养成分(如蛋白质、脂肪、碳水化合物)与热量等微观属性的推断。
RGB-D图像常用于估算食物体积与表面积,从而提升估算准确性:
- Myers 等 84 采用 4 步方法:识别 → 三维体素构建 → 体积估计 → 基于数据库推断热量;
- Lu 等 64 利用上下文信息+3D重建算法实现少样本营养评估;
- Thames 等 128 将图像+深度图作为4通道输入到CNN中,直接回归蛋白质、脂肪、碳水等值,在 Nutrition5k 数据集上评估;
- Shao 等 118 提出融合多模态特征+多尺度特征的 RGB-D 网络,提升估计性能。
视觉+文本的融合策略也逐渐被采纳:
- Qiu 等 100 提出融合图像描述与 RGB 深度估计的 Transformer 框架,实现食物类型识别与份量评估;
- 58 联合分析菜品图、描述与健康评分,生成个性化饮食建议。
多模态基础模型(Foundational Models)在营养估计中的应用
随着多模态基础模型的兴起,如 CLIP 与 GPT-4V,营养估计进入新阶段:
- Lo 等 62 利用 GPT-4V 进行营养成分估计,借助视觉上下文(如邻近物体比例)推断食物份量,再转化为营养值;
- GPT-4V 展现出优秀的分量估计能力与语义理解能力,具备从图像中"识别 → 理解 → 转换"为营养成分的能力。
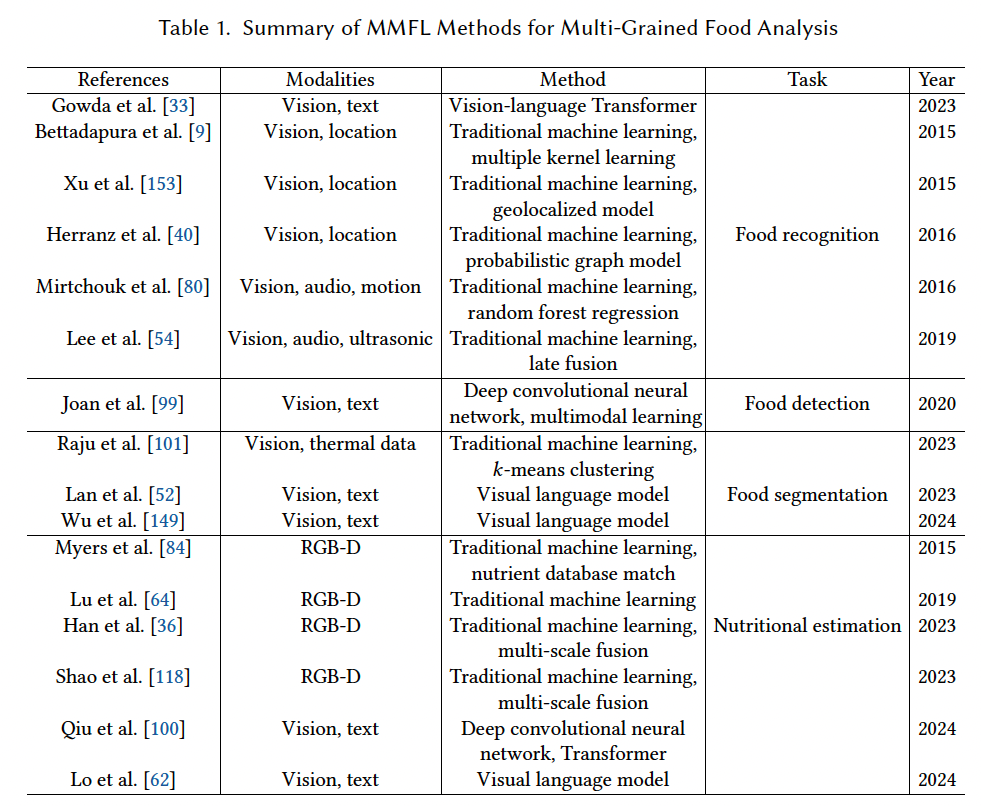
表格 1 总结了基于 MMFL 的多粒度食物分析方法。
4.2 面向食物检索的 MMFL 方法(MMFL for Food Retrieval)
随着互联网和社交媒体上食谱与食物图片数量的激增,MMFL 能够有效地构建食材列表、烹饪步骤与食物图像 之间的跨模态关联,从而支持如烹饪机器人 等新型应用。
跨模态食物检索主要聚焦于食谱文本与食物图像之间的相互检索任务,其关键在于对两种模态的特征表示进行学习,并实现语义对齐。
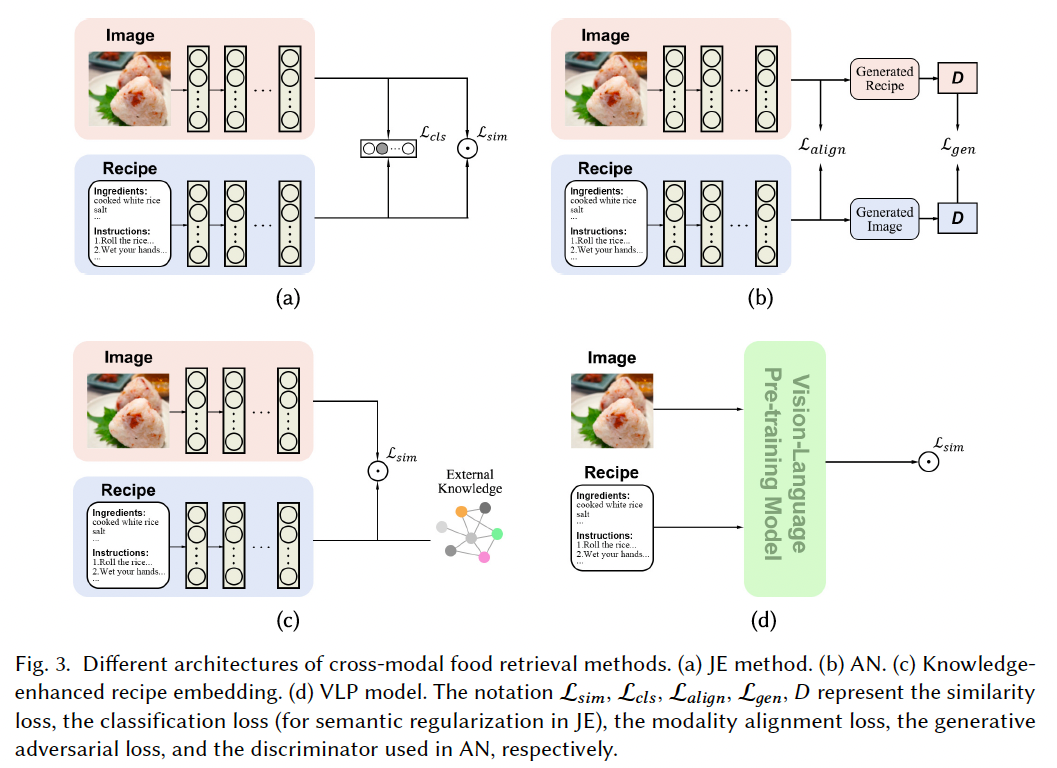
主流方法路径包括:
- Joint Embedding(JE)方法:Salvador 等人 116 首次提出该思路,利用余弦相似度将食谱与图像嵌入到同一语义空间,并引入食物分类的语义正则项进行约束;
- Carvalho 等 11 引入 Triplet Loss,使图像与文本特征在公共嵌入空间中依据语义信息分布;
- Xie 等 151 强化了语义正则化过程,将图像与食谱文本分别提取语义嵌入后,与菜谱步骤与像素级图像特征融合,提升表达能力;
- Adversarial Network(AN)方法:利用对抗机制在对比学习中对图像与食谱之间的高层语义进行细粒度对齐 138, 168。
面临的关键挑战之一:
- 图像与食谱的语义不一致性 :食谱中常包含不可见信息 (如隐藏食材、烹饪过程、顺序等),而这些无法直接从图像中获取。因此,需要将食谱中的描述性信息与知识信息进行解耦建模。
为解决该问题:
- Chen 等 13 引入外部知识库增强模型对食材与烹饪动作的理解;
- Min 等 75 使用受限玻尔兹曼机(RBM)分别学习可见与不可见食材特征,并融合至统一表示;
- Chen 等 12 提取食谱的三元组(食材、烹饪方法、切割方式)进行结构建模;
- Wang 等 139 使用分层 Transformer 编码器提取菜谱的底层-高层结构信息;
- Papadopoulos 等 93 将食谱与图像统一转化为"烹饪程序"形式的中间编码表示。
注意力机制的引入:
- Chen 等 14 提出堆叠注意力网络,将图像与食谱步骤、食材、图像描述等文本特征通过注意力机制分别编码并对齐;
- Fu 等 31 设计级联式 Bi-RNN + Attention 结构,实现从词到句的逐层建模;
- 也有研究 115, 119 使用级联 Transformer 编码器进行标题、食材、步骤三类文本的无监督建模。
面向预训练大模型的探索:
- 大规模视觉语言预训练模型(VLP)在通用多模态任务中表现优异,但直接应用于菜谱检索效果不佳,主要由于 recipe 文本结构复杂,且图文对齐困难;
- Huang 等 43 提出结构感知的 Prompt Learning 策略与自适应食谱编码器(分层 Transformer);
- Shukor 等 120 提出 VLPCook,将图文对转换为图像+结构化文本对以适配 VLP。
总结对比四类方法(见图 3):
| 方法类型 | 优点 | 局限 |
|---|---|---|
| Joint Embedding (JE) | 简单直接、适配性强 | 缺乏细粒度语义对齐 |
| Adversarial Network (AN) | 强化多模态对齐与推理 | 难以训练收敛 |
| 知识增强方法 | 提高对食材细粒度对齐能力 | 无法全局构建图文对应关系 |
| VLP 预训练模型 | 表征与泛化能力强 | 计算开销大、需大量预训练与调优 |
4.3 面向食物生成的 MMFL 方法(MMFL for Food Generation)
食物生成任务在食物设计、广告创作 等领域有广阔应用前景。
与食谱检索不同,跨模态食物生成任务要求在没有候选选项的前提下:
- 从食谱生成图像;
- 或从图像生成食谱。
图像生成任务(以"从食谱生成图像"为例):
早期方法主要基于生成对抗网络(GAN):
- R2GAN 168:学习 recipe-text 与图像的联合嵌入,提升语义一致性;
- CookGAN 167:引入因果建模机制,逐步上采样保持细节;
- ChefGAN 92:结合图像-文本嵌入提升图像细节;
- CI-GAN 136:使用 GAN 反演优化图像语义一致性;
- ML-CookGAN 61:采用多标签生成器 + 多分支判别器,支持复杂食谱信息;
- CookGALIP 152:建模烹饪步骤与食材因果关系,控制语义与细节。
Diffusion 模型的兴起:
- ClusDiff 37:引入聚类机制实现条件扩散生成,细化类别内差异;
- RD-FGM 140:结合 RecipeCLIP 与 Diffusion,提升图文一致性与视觉细节。
从图像/视频生成食谱:
- Inverse Cooking 114:首次实现图像 → 食谱的转换;
- Wang 等 135, 137:引入结构感知机制与图文检索联合训练;
- Zhang 等 157:以"成分生成"作为中间引导任务;
- FIRE 模型 17:结合视觉 Transformer 与 LLM,处理多成分复杂结构食谱生成;
- Wu 等 147:将视频与食材信息融合生成更精确食谱;
- Nishimura 等 87:借鉴密集视频字幕生成,提出基于 Transformer 的多模态递归结构。
方法分类与对比总结:
-
GAN 方法
- JE类 GAN 模型:将图像与食谱信息(如标题、成分、步骤)嵌入到共享空间中,通过联合嵌入保证生成图像与输入食谱的语义一致;
- 因果建模类 GAN 模型:显式建模食谱中的成分因果关系,在生成过程中分阶段参考因果路径,逐步提升图像分辨率与结构一致性。
-
Diffusion 方法
- 与 GAN 不同,扩散模型注重在逐步生成中深度融合食谱信息,在每个去噪阶段引入 recipe 信息,多次交叉注意力引导细节生成,确保在每一步都能参考关键语义信息。

表 2 总结了上述方法的具体对比。
4.4 面向烹饪视频索引与检索的 MMFL 方法(MMFL for Cooking Video Indexing and Retrieval)
烹饪视频的索引与检索对于理解烹饪过程具有重要意义。早期研究主要聚焦于将视频片段与菜谱中的步骤建立对齐关系以实现烹饪视频的语义索引 22, 35, 81。
例如:
- Hamada 等人 35 提出了一种多媒体集成系统,通过对烹饪视频与菜谱文本进行语义分割,并利用菜谱中的顺序约束、文本与视频音频的共现词、视频背景与语义描述的对应关系,实现两者的语义对齐;
- Cao 等人 10 首次提出了基于视频的跨模态菜谱检索任务,即:给定文本菜谱,从视频候选集中检索相应的烹饪视频,或反向操作。他们使用不同的注意力网络分别学习视频与菜谱的表征,并进一步学习二者之间的交互特征以增强其匹配能力;
- Malmaud 等人 69 综合考虑了文本、语音和视觉模态,使用**隐马尔可夫模型(HMM)**将菜谱步骤与视频语音文本对齐,并通过 CNN 食物检测器进一步细化视频内容的对应关系。
这些方法标志着 MMFL 在视频领域的应用从"步骤对齐"向"多模态检索与理解"不断演进。
4.5 面向饮食推荐的 MMFL 方法(MMFL for Diet Recommendation)
个性化饮食推荐的核心目标是推荐满足用户需求的膳食列表,这涉及多维度信息建模,如用户的口味偏好与营养需求。因此,MMFL 在该任务中扮演关键角色。
通用推荐模型框架通常包含三个组件 73:
- 上下文与知识建模(如用户的文化背景、健康状态等);
- 个性化用户建模(如历史偏好、生理指标等);
- 多模态食物分析(如图像、食材、营养成分等)。
由于用户偏好与食物的视觉属性、食材种类密切相关,如何整合多模态信息以提升推荐准确性成为核心挑战。
典型研究工作包括:
- Rostami 等人 110:基于生活事件识别构建个性化推荐用户模型;
- Elsweiler 等人 27:研究用户对食物图像的响应行为,通过优化推荐的菜品类型与图像样例,促进更健康的选择;
- Zhou 等人 166:提出 FREEDOM 模型,利用转换后的多模态特征之间的相似性构建项目交互图;
- Zhang 等人 159:结合自监督学习与聚类方法,提出多模态饮食推荐系统,提升推荐的相关性与准确性。
健康导向与疾病特定推荐系统:
饮食推荐区别于其他推荐任务的一个关键点在于其对人体健康的直接影响。不仅要满足"想吃什么",还要引导"吃得健康" 130。
- Iwendi 等人 45:整合食物特征、生理数据与疾病特征,提出面向患者的饮食推荐系统;
- Raut 等人 105:基于群体营养需求、日常活动水平与食物数据,采用**群体智能算法(colony algorithm)**为不同患者群体定制推荐;
- Elsweiler 等人 25:结合用户体征与营养目标,设计在口味与健康间平衡的膳食计划;
- Ng 等人 86:融合营养指南与用户偏好,构建婴幼儿膳食推荐系统。
基础模型(Foundational Models)的新机遇:
近年来,大模型展现出在不同场景下处理下游任务的强大适应能力。LLMs 正成为饮食推荐系统的前沿核心,具备对多源异构信息的理解能力,可生成个性化、有意义的推荐建议 156, 163。
- Rostami 等人 109:构建基于多模态 LLM 的个性化推荐框架,融合食物日志、上下文感知建模与世界饮食地理信息(World Food Atlas),提升推荐的相关性与定制化水平。
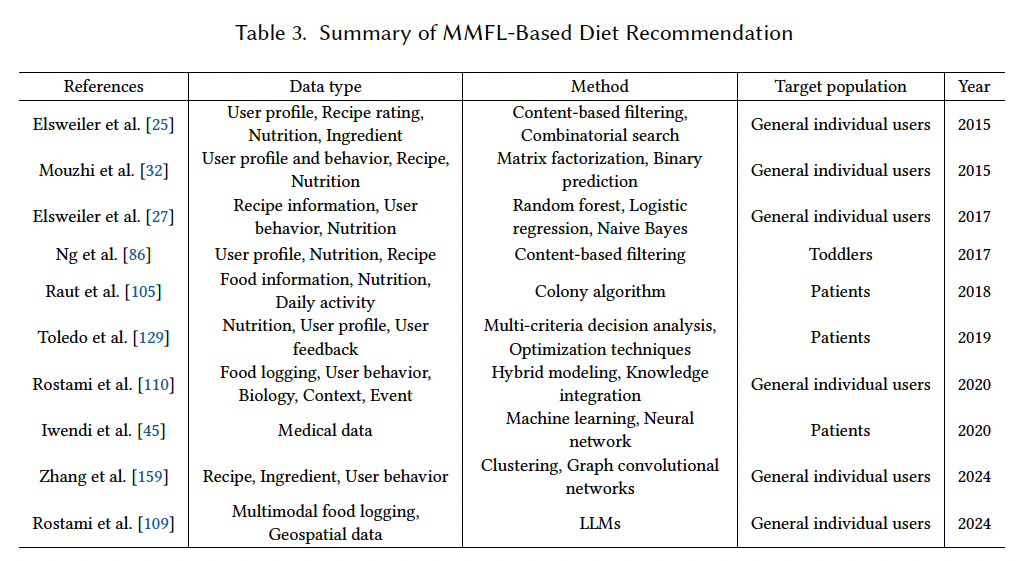
表格 3 总结了上述 MMFL 支持的饮食推荐方法。
4.6 面向人-食交互(HFI)的 MMFL 方法(MMFL for HFI)
为了创造真正沉浸式的虚拟体验,多感官的信息感知尤为重要。因此,迫切需要新的多媒体形式,能够深度调动人类的各种感官,不仅包括视觉、听觉与触觉,还包括味觉与嗅觉等非传统模态,以在非物理环境中营造真实感知的"临场感"。在人机交互系统中,**人-食交互(Human-Food Interaction, HFI)**是沉浸式体验的重要组成部分。
HFI 被定义为"自我与食物之间的连接关系" 21,涵盖我们如何烹饪、进食与处理食物等多个方面。它涉及食物的全感官感知过程,包括外观、气味、味道、质地、咬合声音等维度。
借助 MMFL,可以整合视觉、听觉、触觉与嗅觉等模态,实现更全面、真实的食物交互体验。
- 例如,Ranasinghe 等人 104 提出了一个系统,允许用户通过配置不同的刺激,实现定制化的虚拟风味体验。当用户使用该系统饮用饮品时,视觉、味觉与嗅觉刺激协同作用,生成增强后的风味感知;
- Weidner 等人 145 探讨了嗅觉、视觉与味觉在虚拟现实中如何协同影响多感官集成,从而提升 HFI 的沉浸感与交互质量。
4.7 总结与讨论(Summary and Discussion)
本节对 MMFL 在典型食物导向多媒体任务中的技术发展进行了总结,涵盖识别、检索、生成、推荐与交互等方面。
多粒度食物分析方面:
除视觉模态外,**文本、音频、视频与上下文信息(如营养数据、地理位置等)**能提供互补信息,用于粗到细的食物语义预测:
- 例如,文本信息能增强食物语义表示的完整性 143;
- 位置信息可大幅缩小识别范围 153;
- 对于复杂菜品(如中餐),高粒度语义信息难以仅凭视觉获取,预测隐含食材与具体营养含量常需融合深度图像、高光谱等模态。
跨模态检索与生成方面:
受大规模数据集(如 Recipe1M 116)推动,图像-食谱间的跨模态检索与生成成为研究热点:
- 检索任务核心在于学习共享嵌入空间,常结合**特征解耦 124与注意力机制 139**以缓解语义不一致问题;
- 生成任务中,GAN 与 Diffusion 模型(如 PizzaGAN 94 与 CookGAN 167)被定制以适配食物场景。
视频与推荐任务方面:
- 视频索引与检索方面仍研究较少,目标是建立烹饪片段与步骤的对应关系,提升视频内容的结构化理解;
- 饮食推荐广泛采用 MMFL,结合用户偏好建模与营养约束,实现口味与健康的动态平衡。
人-食交互与新兴方向:
HFI 方面的研究逐渐重视嗅觉与味觉的数字模拟与集成,提升虚拟食物体验的现实感 104。此外,MMFL 还拓展至多个新兴任务,如:
- 烹饪文化分析 72, 76;
- 风味预测 47;
- 机器人抓取与食物操作任务 70。
面向未来的大模型趋势:
- 由于大模型的强泛化能力,从传统机器学习向"面向食物的多模态大模型"过渡是趋势所向,未来有望同时支持多任务协同建模。
当前局限与未来发展趋势:
尽管食物具有天然的多感官属性,当前研究仍聚焦于主流模态,如图像、菜谱文本与视频。
例如,在多粒度食物分析中,视觉主导的识别、检测、分割与营养估计是重点方向。但由于图像存在细粒度分类困难与模式复杂等挑战,视觉模态常常难以胜任复杂任务(如营养估计,尤其是中餐)。
因此,越来越多的研究尝试引入 文本、深度图像与上下文信息 以提升性能 134, 143, 153。然而,针对"全感官融合"的系统性研究仍相对稀缺,尤其是触觉、嗅觉与味觉等模态。其主要原因包括:
- 数据采集成本高;
- 感知信号不易捕获(如气味的挥发性特征);
- 缺乏标准化硬件与数字编码机制。
随着气味-味觉采集设备与数字化技术的发展 ,这些模态将逐步进入主流研究视野。例如,近期发布的多模态葡萄酒数据集就用于跨模态风味预测任务 8,标志着该趋势的开启。
MMFL 的跨学科特性与协同潜力:
MMFL 本质上跨越多个领域,包括:
- 高光谱/多光谱成像:揭示食物的化学成分,支撑精确营养评估;
- 营养科学:与多模态数据融合,实现面向个体健康需求的精准推荐;
- 感官分析:辅助构建真实的多感官交互模型。
这些跨学科融合推动 MMFL 成为研究食物识别、评价与个性化交互的重要技术平台,未来将为复杂问题提供更具创新性与实践价值的解决方案。
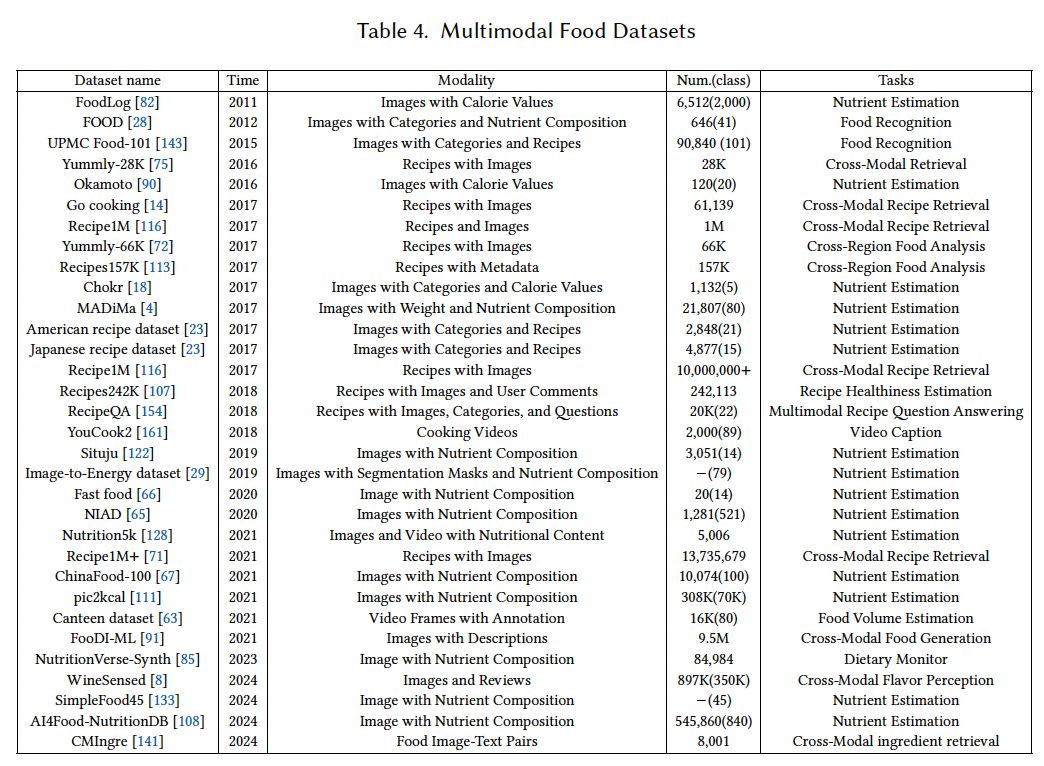
5 多模态食物数据集(Multimodal Food Dataset)
为了支持上述 MMFL 方法的评估,研究者构建了多种类型的多模态食物数据集,本节对其进行简要概述。
如表 4 所示,目前使用最广泛的是食谱类数据集,其中包含菜谱文本与食物图像。
早期数据集:
- 小规模数据集:如 UPMC Food-101 143、Yummly-28K 75、Yummly-66K 72;
- 随后发布的大规模多模态数据集 Recipe1M 116 与 Recipe1M+ 71 推动了图像-食谱跨模态检索与生成任务的发展,成为该领域的重要评估基准。
营养估计数据集:
另一类常用于营养估计任务的数据集包括:
- MADiMa 4;
- Nutrition5k 128:该数据集包含 RGB-D 食物图像、食材组成与营养信息,是当前主流的营养估计评测数据集,已有大量研究基于其进行实验。
然而,Nutrition5k 规模有限,未来有必要构建更大规模的营养估计数据集,覆盖中餐等非西式菜品。
味觉与嗅觉模态数据集稀缺:
目前极少有数据集涵盖食物特有模态 (如气味与味道)。近期,Thoranna 等人 8 构建了葡萄酒多模态数据集,引入风味维度用于探索视觉、语言与风味之间的关系。
预计未来随着嗅觉与味觉模态的引入,MMFL 在多媒体感知体验方面将产生更多有趣研究。
6 应用(Applications)
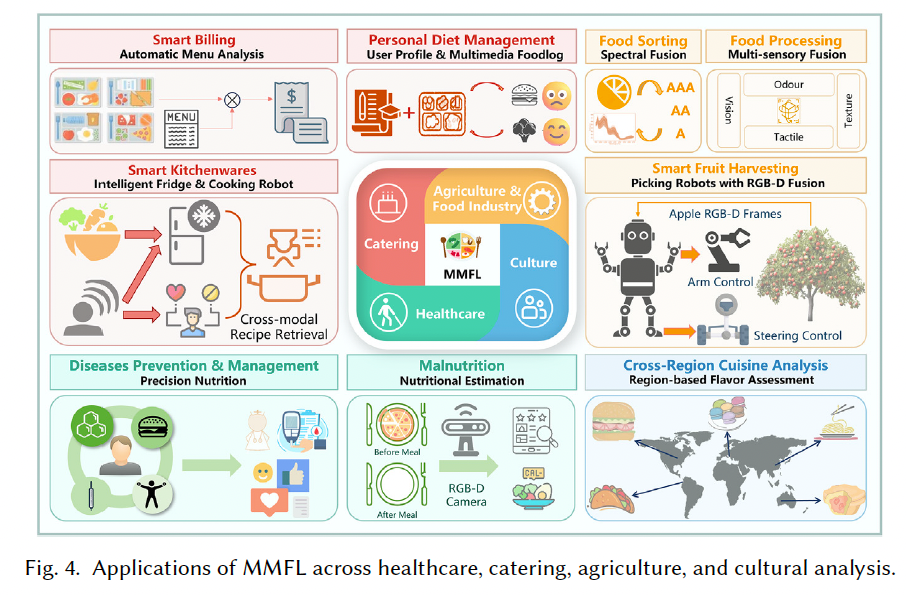
如图 4 所示,MMFL 支持的应用广泛分布于以下四大领域:
6.1 医疗健康(Healthcare)
在健康医疗场景中,对个体营养摄入的自动化与智能化监测 对预防与治疗营养相关疾病至关重要。
MMFL 能融合多种模态信息,提升营养估计的精度,减轻参与者负担、降低医疗成本。
- 例如,Lu 等人 64 提出一种系统,通过处理患者餐前与餐后的 RGB-D 图像对,自动估算住院患者的营养摄入;
- 精准营养(Precision Nutrition)日益受到关注,其核心是融合多模态传感器数据,基于数字营养技术实现实时预测与反馈 117;
- 一项代表性工作 98 融合个人膳食日志、血糖与肠道菌群等多源信息,预测特定饮食对血糖水平的影响。
6.2 餐饮服务(Catering)
餐饮服务覆盖从外卖到定制化用餐服务等不同场景,面临如人员短缺、供应链不稳定等挑战,推动了智能化发展趋势,如:
- 智能厨房:融合智能冰箱、厨具等设备,提升厨房操作效率;
- 智能结算系统:基于食物图像检测实现自助结账 99;
- 个性化饮食推荐:将上传图像与语音交互文本融合,实现定制化菜单推荐;
- 烹饪机器人 :
- 学会"做菜"的第一步是学会看图识菜谱;
- MMFL 可实现图像到菜谱的跨模态检索,为机器人提供烹饪指引 115;
- 菜品追踪与饮食日志记录:通过图像与文本自动生成饮食日志,结合用户信息提供个性化营养建议。
6.3 农业与食品工业(Agriculture and Food Industry)
全球人口预计将在 2050 年达 97 亿,对食物的需求将增长 50% 以上。因此,食品生产与加工亟需向"更高营养、更低能耗、更环保"方向演进 38。
- 在智慧农业 中,MMFL 已广泛应用于:
- 水果采摘机器人 19;
- 果实品质评估与分级 160;
- 产量统计等;
- MMFL 保证了多源数据融合后的识别鲁棒性,如结合图像与深度信息 127;
- 在食品工业中,融合视觉、嗅觉、味觉、触觉等多模态信息,有助于提升食物分拣、切割、包装、安全与质量检测等环节的精度与效率 38。
6.4 食品文化(Culture)
食物不仅是营养载体,更是社会与文化的重要组成 。
多源多模态食物数据被用于跨地域菜系分析 2, 76:
- 例如,Min 等人 76 提出融合文本、图像与用户评论的多模态食谱分析框架;
- 该框架支持对食谱中的食材类型、烹饪方法、地域风格等进行结构化建模;
- 支持实现如:多维食物摘要、基于地域的风味分析、个性化推荐等。
6.5 综合讨论(Discussion)
MMFL 的应用横跨食品科学、医学与文化研究等多个学科:
- 在食品科学中,MMFL 有助于深入理解食物质量、安全性与营养构成,推动精细化加工与生产;
- 在医疗场景中,结合饮食模式、健康记录与感知信息,可实现个性化营养与慢病管理;
- 在文化研究中,多模态分析加深对传统饮食、地域菜系与文化意义的理解。
展望:
未来研究应聚焦于将 MMFL 方法定制应用于具体的跨学科任务场景,以实现更具实用性与可推广性的智能食物系统。
7 挑战与未来工作(Challenges and Future Work)
7.1 MMFL 基准构建(MMFL Benchmark)
现有 MMFL 数据集主要集中于视觉与语言模态,如包含食物图像与菜谱文本的 Recipe1M 数据集 116,支持图文检索与生成任务。也有少量烹饪视频数据集涵盖视觉、文本与音频模态,用于视频索引与食谱生成。
但目前涵盖嗅觉与味觉等食物特有模态的数据集极为稀缺,主要原因包括:
- 采集设备受限;
- 收集成本高昂。
虽然食品科学领域已有不少关于多感官融合的研究,例如利用电子鼻(E-nose)和电子舌(E-tongue)对食物进行质量与安全检测 162,但多媒体与食品科学研究者之间的合作仍较少。
构建全感官食物数据集 将有助于模拟人-食交互(HFI)。例如,视觉会影响人对热量的感知 30。Tan 等人 126 提出了类脑多感官神经网络,集成人工视觉、听觉与模拟嗅觉、味觉神经,可用于多模态气味与味觉识别与成像。
参考 AI 领域深度学习的发展路径,构建大规模全感官食物基准将促进 AI 在食品科学的快速渗透,反向推动食品科技的发展。
因此,亟需加强多媒体与食品科学的交叉合作,构建大规模、多模态、全感官的食物数据集,支持更具创新性与现实意义的研究。
7.2 多模态食物基础模型(Multimodal Food Foundation Models)
多媒体正在深刻重塑食品领域,从食物设计、生产、存储、运输到消费 各环节引入自动化与精准化。
LLMs 的强泛化能力为 MMFL 带来新机遇,未来应建立多模态食物基础模型(Multimodal Food Foundation Models, MFoodFM),以实现个性化食物解决方案与精准营养建议,提升全球健康水平。
目前多数模型来源于通用语言模型,存在以下问题:
- 缺乏对食物细粒度特征的准确建模,在识别、食材替代与营养估计等任务中表现不佳;
- 饮食文化偏向西方,对多样性人群产生不合适或错误的营养建议。
为应对上述问题,应:
- 构建覆盖全球饮食文化的大规模数据集;
- 融合更多感官输入,如嗅觉、味觉与触觉,使模型更贴近人类感知过程,提高结果的可解释性与适应性 121。
例如,食物助手可借助味觉/嗅觉输入生成更易理解的营养建议。
此外,MFoodFM 可作为智能食物代理(food agent),如:
- 烹饪视频 LLM:结合图像、颜色、酸度等多模态输入生成烹饪动作;
- 可通过语言提示(如"辣椒炒肉应带有姜香味")生成烹饪步骤与视频摘要。
当前的关键挑战包括:如何训练具有时序对齐、长上下文理解与实时性要求的烹饪视频大模型,有待未来深入研究。
7.3 多模态饮食估计(Multimodal Diet Estimation)
快速且准确的饮食估计有助于监控健康与营养摄入,是营养科学与健康管理中的核心问题 89。
图像营养估计是一个病态问题(ill-posed problem),因图像中可提取信息有限。现有研究主要融合 RGB 与深度信息,以估算体积。
这类方法多适用于成分简单、食材可分离的西式菜肴。但对于成分混杂、外观复杂的东方菜品效果有限。
因此,未来应引入更多传感模态 ,并深入探索MMFL 驱动的饮食估计方法。
7.4 类人多模态感知(Human-Like MMFL)
人类大脑的眶额皮层会对视觉、嗅觉、味觉等食物刺激产生响应,多模态集成是人类感知食物的关键 5。
然而,现有 MMFL 多集中于视觉-语言模态,对味觉与嗅觉等模态考虑不足。这些模态具有独特的生成机制,在表征上存在异质性差异。
此外,人类对食物的感知也与语义记忆与认知结构相关,这要求 MMFL 融合数据驱动与知识驱动。
因此,发展**类人 MMFL(Human-like MMFL)**不仅有助于理解人类生存机制 30, 112,还可催生新的多媒体任务与应用:
- 推动"食物感知科学"发展;
- 研究人脑对视觉、嗅觉、触觉、味觉等刺激的神经调节机制;
- 构建可进行个体化感知分析的感官仿真模型,提升 AR/VR 下的多媒体体验;
- 揭示消费者的食物选择偏好。
7.5 面向新兴应用的 MMFL(MMFL for Novel Applications)
MMFL 将支持更多新兴应用:
- 例如,将食物视觉、声音与味觉关联,构建新型多媒体体验;
- 实现"智能工业厨师":不只考虑颜色,还能融合气味判断是否翻炒;
- 构建集成所有模态的智能厨师代理,为未来智能制造与食品工业服务。
此外,搭载 MMFL 的机器人可彻底变革食物的生产与准备方式,如:
- 农业机器人;
- 3D 食物打印;
- 烹饪机器人 57。
凭借其跨学科特性,MMFL 有望在多个领域开启更多创新应用。
8 结论(Conclusion)
MMFL 正受到多媒体与交叉学科领域的广泛关注,应用潜力日益凸显。
本文首先对 MMFL 进行了形式化定义 ,并提出了系统的任务分类方式;
随后系统回顾了多粒度食物分析、跨模态检索与生成、烹饪视频检索、饮食推荐、人-食交互(HFI)等方法技术进展;
并总结了当前主流的多模态食物数据集;
进一步探讨了其在医疗、餐饮、农业、食品工业与文化 等领域的落地应用场景;
最后,本文详细讨论了当前 MMFL 面临的核心挑战与未来发展趋势。
虽然视觉-语言模态已得到深入研究,但如嗅觉与味觉等新模态正在兴起,带来更多令人兴奋的多模态应用机会。
随着大模型范式的迅猛发展,多模态食物基础模型 将在促进人类健康方面发挥关键作用。
同时,MMFL 的跨学科特性也将推动其在多媒体与相关领域实现更加丰富和创新的应用落地。
据我们所知,这是首篇关于 MMFL 的系统性综述文章,我们相信本综述将为多媒体及相关领域的研究者提供有力参考,掌握该方向的技术进展与未解问题。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 "Stay Hungry, Stay Foolish" ------ 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
