目录
1.为什么这里采用时间戳,而不直接像首日全量使用create_time?
备注只分析难理解的部分,其它基础语法可以看下面的第二部分建表语句解析介绍
22-学习笔记尚硅谷数仓搭建-ODS层日志表建表语句解析、数据装载及脚本装载数据-CSDN博客
一、理解业务
1.加购:往购物车加新商品和增加已有商品的数据,属于交易的范畴
2.数据装载:
首日全量:因为首日没有行为变化的数据,所以折中的认为首日全都是加购的
增量:每日增加的数据
3.字段分析:
要根据加购这个行为分析需要的字段,也就是说加购这个行为需要哪些维度衡量才能更准确的统计分析
二、完整的建表语句及数据装载
1.建表语句
sql
DROP TABLE IF EXISTS dwd_trade_cart_add_inc;
CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`sku_id` STRING COMMENT 'SKU_ID',
`date_id` STRING COMMENT '日期ID',
`create_time` STRING COMMENT '加购时间',
`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域加购事务事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');2.首日数据装载
sql
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
select
data.id,
data.user_id,
data.sku_id,
date_format(data.create_time,'yyyy-MM-dd') date_id,
data.create_time,
data.sku_num,
date_format(data.create_time, 'yyyy-MM-dd')
from ods_cart_info_inc
where dt = '2022-06-08'
and type = 'bootstrap-insert';3.每日数据装载(以6月9号为例)
sql
insert overwrite table dwd_trade_cart_add_inc partition (dt = '2022-06-09')
select data.id,
data.user_id,
data.sku_id,
date_format(from_utc_timestamp(ts * 1000, 'GMT+8'), 'yyyy-MM-dd') date_id,
date_format(from_utc_timestamp(ts * 1000, 'GMT+8'), 'yyyy-MM-dd HH:mm:ss') create_time,
if(type = 'insert', data.sku_num, cast(data.sku_num as int) - cast(old['sku_num'] as int)) sku_num
from ods_cart_info_inc
where dt = '2022-06-09'
and (type = 'insert'
or (type = 'update' and old['sku_num'] is not null and cast(data.sku_num as int) > cast(old['sku_num'] as int)));三、建表语句分析
sql
`date_id` STRING COMMENT '日期ID',
`create_time` STRING COMMENT '加购时间',需要注意的是这两个字段
这里为什么会有两个时间?
因为第一个表示的是年月日,而第二个代表的是加入购物的时间但单位是年月日时分秒,两个表示同一个时间但单位不一样,为了后续通过时间维度分析节假日的加购数据,才人为创建了日期ID这个字段
四、首日数据装载分析
1.date_format函数:
sql
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
-- 动态分区
select
data.id,
data.user_id,
data.sku_id,
date_format(data.create_time,'yyyy-MM-dd') date_id,
-- 格式化将日期修改为年月日格式
data.create_time,
data.sku_num,
date_format(data.create_time, 'yyyy-MM-dd')先看这里需要先介绍一个函数:
date_format函数:
date_format 是一个日期格式化函数,用于将日期/时间戳转换为指定格式的字符串。
函数语法
sql
date_format(date/timestamp, format)参数说明
-
date/timestamp:要格式化的日期或时间戳
-
format:格式化模式(字符串)
常用格式化模式
| 符号 | 含义 | 示例 |
|---|---|---|
yyyy |
4位年份 | 2023 |
MM |
月份(01-12) | 10 |
dd |
日期(01-31) | 05 |
HH |
24小时制小时 | 14 |
hh |
12小时制小时 | 02 |
mm |
分钟 | 30 |
ss |
秒钟 | 45 |
a |
AM/PM | PM |
使用示例
sql
-- 将当前时间格式化为标准格式
SELECT date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss');
-- 结果:2023-10-01 14:30:45
-- 只获取年月日
SELECT date_format('2023-10-01 14:30:45', 'yyyy-MM-dd');
-- 结果:2023-10-01
-- 格式化为中文日期格式
SELECT date_format('2023-10-01', 'yyyy年MM月dd日');
-- 结果:2023年10月01日
-- 美国日期格式
SELECT date_format('2023-10-01', 'MM/dd/yyyy');
-- 结果:10/01/2023
-- 获取季度
SELECT date_format('2023-08-15', 'yyyy-Q');
-- 结果:2023-3(表示第3季度)
-- 获取星期
SELECT date_format('2023-10-01', 'yyyy-MM-dd EEEE');
-- 结果:2023-10-01 Sunday注意事项
-
输入类型:第一个参数必须是日期或时间戳类型,如果是字符串需要先转换:
sql-- 错误示例 SELECT date_format('2023-10-01', 'yyyy/MM/dd'); -- 可能报错 -- 正确做法 SELECT date_format(cast('2023-10-01' as date), 'yyyy/MM/dd'); SELECT date_format(to_date('2023-10-01'), 'yyyy/MM/dd'); -
格式区分大小写 :
MM和mm代表不同含义 -
时区问题 :
date_format不会进行时区转换
2.字段最后的一个时间字段
sql
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
-- 动态分区
select
data.id,
data.user_id,
data.sku_id,
date_format(data.create_time,'yyyy-MM-dd') date_id,
-- 格式化将日期修改为年月日格式
data.create_time,
data.sku_num,
date_format(data.create_time, 'yyyy-MM-dd')如上,已经有所有的字段了,为什么还要加一个时间字段?
这个字段是用于指定动态分区,根据创建时间划分不同的时间,因为首日装载不仅有数据仓库上线当天的数据还有以前没有数据仓库时的历史数据,因为只有当业务足够大数据量太多才会用到数据仓库,在这之前都是直接存储在业务数据库,所有会有大量历史数据。如果不进行分区的话,会导致数据仓库上线当天的数据量过多,影响后面的分析,进而影响业务判断
五、每日数据装载分析
sql
date_format(from_utc_timestamp(ts * 1000, 'GMT+8'), 'yyyy-MM-dd') date_id,
date_format(from_utc_timestamp(ts * 1000, 'GMT+8'), 'yyyy-MM-dd HH:mm:ss') 如上的数据装载语句
1.为什么这里采用时间戳,而不直接像首日全量使用create_time?
因为我们人为规定首日全量的数据全是加购,所以可以用创建时间create_time,而这里不仅有insert增加还有update更新,insert还好直接可以使用create_time,因为create_time创建时间和operate_time修改时间是同一个值,而update不行,因为create_time是创建该商品购物车的时间,不是加购时间,而加购时间是另一个字段operate_time修改时间,就是因为有两个类型的不同要做判断很麻烦,所以我们直接使用Maxwell采集数据的时间戳,这个时间就是数据变更的时间。
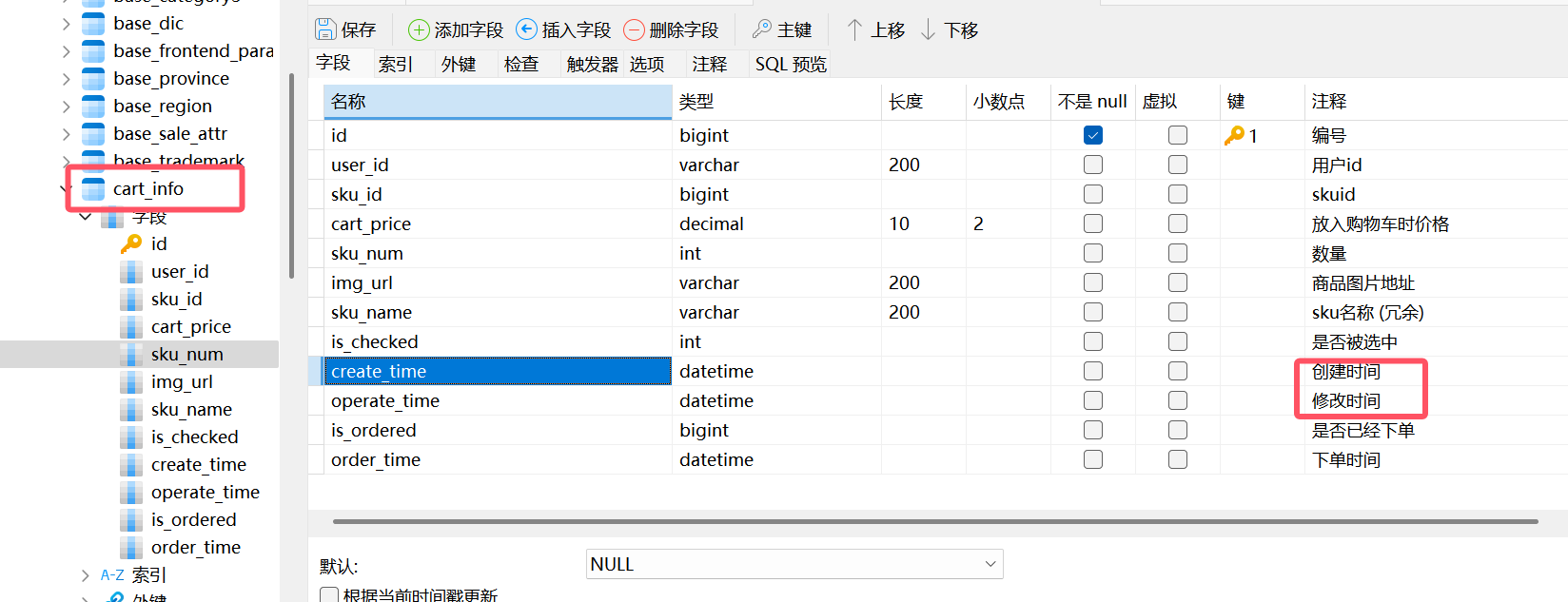
2.那为什么首日全量不使用时间戳?
因为首日全量是通过dataX采集的数据,底层是使用select * from ,得到的是tsv格式的数据,相当于将业务数据库原封不动换个格式采集过来,而每日数据是通过Maxwell采集的数据,底层是使用业务数据库的binlog文件得到的是json数据,里面封装了数据变更的时间戳。
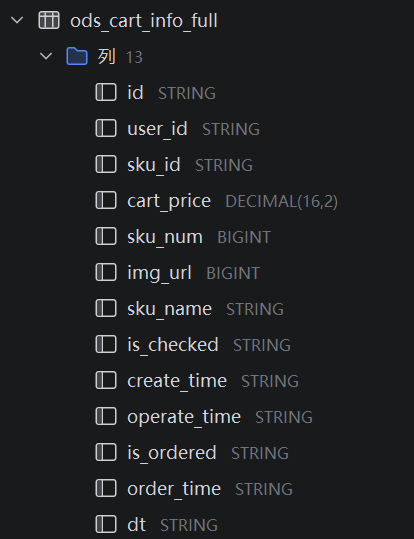
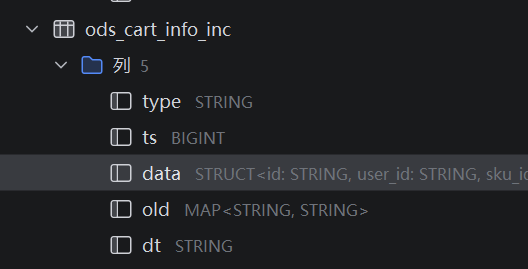
3.from_utc_timestamp函数
from_utc_timestamp函数:用于转换数据为时间类型数据,ts原本的数据类型是bigint,且表示的是秒,所以要乘以1000转换为毫秒,因为from_utc_timestamp传的参数是以毫秒为单位,后面的传的字符串参数表示时区,GMT+8是中国标准时间
sql
where dt = '2022-06-09'
and (type = 'insert'
or (type = 'update' and old['sku_num'] is not null and cast(data.sku_num as int) > cast(old['sku_num'] as int)));对如上的数据装载语句分析:
1.加购有两种:一是insert原来没有商品,新增到购物车的,二是update更新商品,但更新商品有两种,一是减少数量二是增加数量,我们应该判断是否为增加数据。
2.那怎么才知道是增加还是减少呢?
我们通过Maxwell采集增量数据时,会有一个old字段,里面会记录更新前的数据,我们通过比较现在的数据和更新前的数据,就可以判断是增加还是减少。
3.但比较两个值前,需要进行类型转换和判断:更新前的数据可能为空,但更新后一定不为空,所以要判断更新前是否为空,并且old中的sku_num是字符串类型,data中的sku_num是bigint类型,不能相互比较,所以使用cast函数进行类型转换。