目录
- [一. 检查OS版本及操作系统配置](#一. 检查OS版本及操作系统配置)
- [二. 驱动和固件下载与安装](#二. 驱动和固件下载与安装)
- 三.下载mindie镜像并打包
-
- [1.下载Docker Desktop](#1.下载Docker Desktop)
- 2.下载mindie镜像
- 3.镜像打包
- 四.下载权重文件
- 五.下载openai_web
- 六.加载镜像
- 七.创建并启动容器
- 八.修改配置文件
- 九.启动大模型
- 十.启动open_webui
一. 检查OS版本及操作系统配置
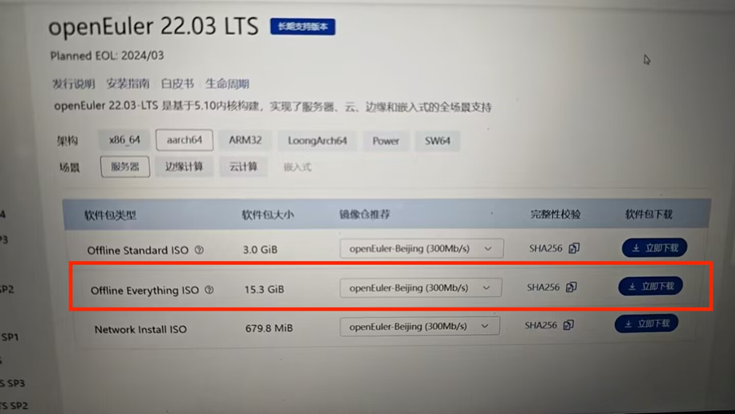
博主这里服务器的显卡为华为的Atlas 300l Duo,安装的操作系统为openEuler 22.03 LTS。具体如下图。

二. 驱动和固件下载与安装
查看显卡实际参数,下载对应的固件和驱动。
① firmware:初始化、控制硬件本身。存在于显卡的BIOS芯片中。电脑开机时,它初始化GPU核心、显存,设置基础显示模式(让你在进入Windows前能看到BIOS画面)。
② driver:翻译OS指令,管理硬件资源,提供OS标准接口。
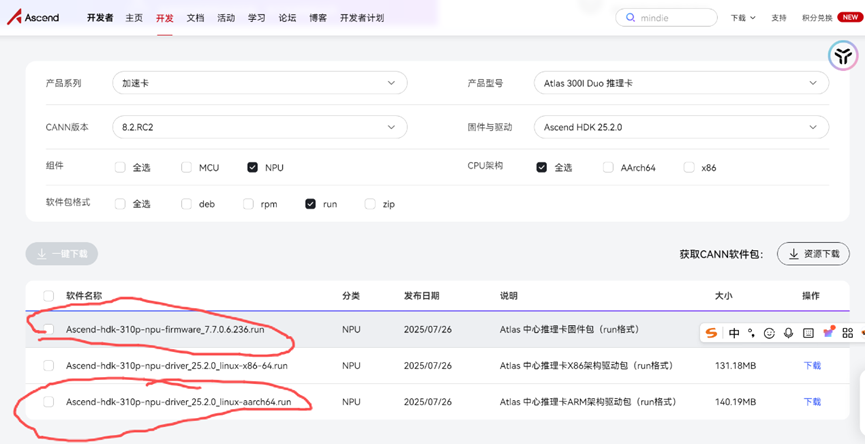
驱动安装参考:https://blog.csdn.net/mizhiakk/article/details/147305068
NPU Chip有几行,就是有几个npu卡,下图中就有2块npu。
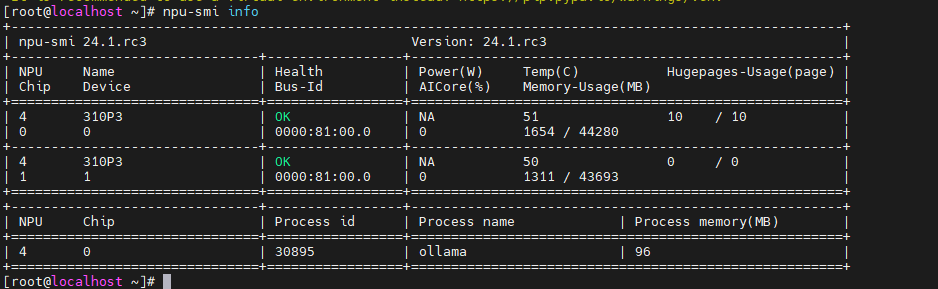
具体参数含义,参考下面链接:
https://www.hiascend.com/document/detail/zh/Atlas 200I A2/2550/re/npu/topic_0000002481546300.html
三.下载mindie镜像并打包
1.下载Docker Desktop
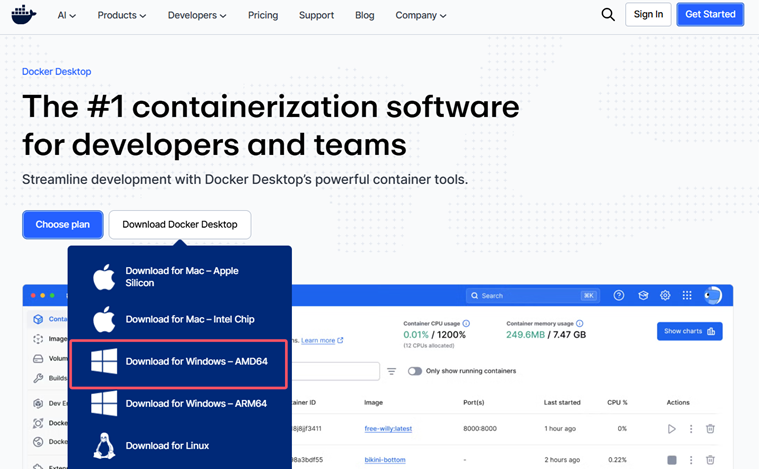
博主是使用windows下载Docker的,所以要安装Docker Desktop。
I.下载最新版本
下载地址:https://www.docker.com/products/docker-desktop/
II.下载历史版本
下载地址:https://docs.docker.com/desktop/release-notes/
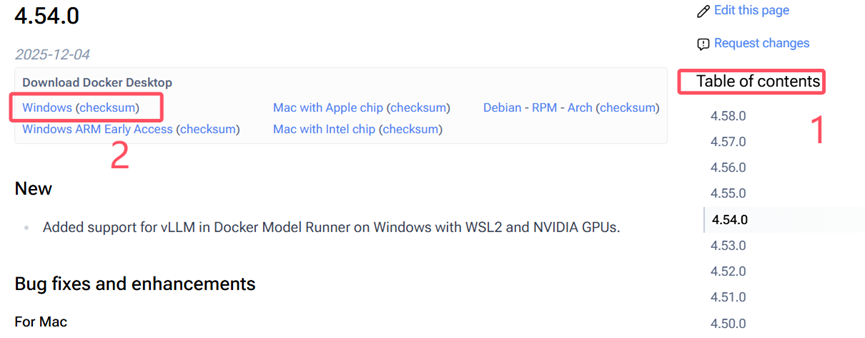
Docker最好下载版本稍低的,否则拉取的mindie镜像可能有问题。博主下载的4.39.0
先在右侧边栏选择合适的版本,再下载对应架构的Docker Desktop
2.下载mindie镜像
下载地址:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
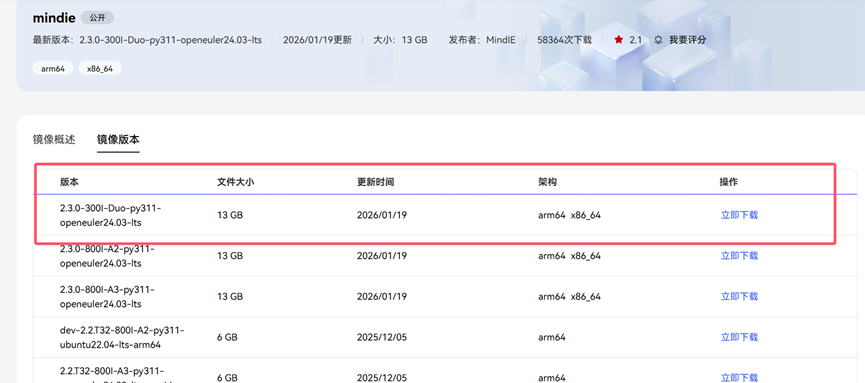
根据服务器指令集的类型,选择合适的架构镜像来下载。
因为博主要部署的服务器是arm架构的,所以我这里选择arm架构来下载。

3.镜像打包
I.先进入指定目录,然后打包
进入想要存放tar包的目录,执行以下命令:
bash
docker save -o mindie1.tar 02efebd6ce64
II.命令中指定目录,然后打包
bash
docker save -o "D:\docker_image\image\mindie1.tar" 02efebd6ce64这里mindie1是镜像的tar包名字,可以自定义。02efebd6ce64是想要打包的镜像,可以通过docker images来查看。

执行完之后,当前目录下会生成对应的tar包。

之后将mindie1.tar拷贝到服务器中相应目录。(eg:/opt/mindie_image)
四.下载权重文件
根据显卡及操作系统相关参数,这里提供三种权重文件的下载地址。
- 量化版本32B:https://www.modelscope.cn/models/rubick321/qwen3-32b-w8a8-mindie-300I/files
- 32B:https://www.modelscope.cn/models/Qwen/Qwen3-32B/files
- 14B:https://www.modelscope.cn/models/Qwen/Qwen3-14B/files
以量化版32B为例:

这里建议使用modelscope指定目录来下载,因为modelscope默认下载到C盘目录下。
1.安装modelscope
建议下载Anaconda来管理包,使用conda,直接用base环境执行 pip install modelscope 可能会报包错误。
bash
conda create -n virtual1 python=3.11
conda activate virtual1
pip install modelscope这里的python版本,要和上面下载mindie镜像中命令的版本一致。
2.下载权重文件
之后按照红框中的命令下载权重文件。
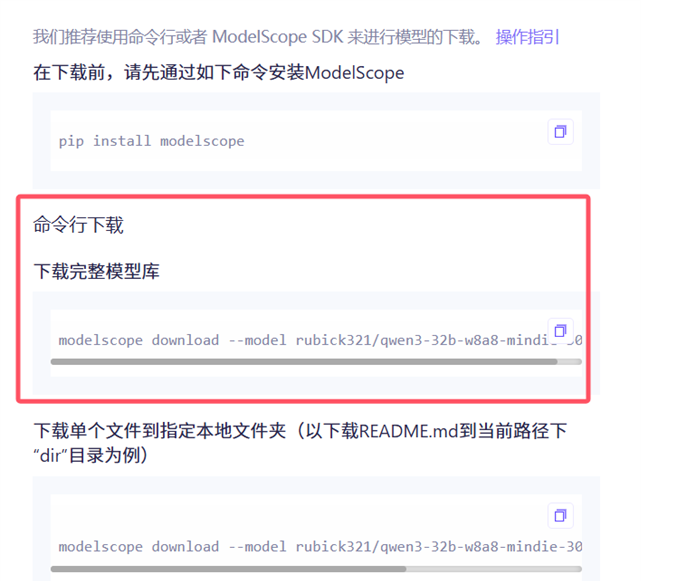
这里建议使用modelscope指定目录来下载,因为modelscope默认下载到C盘目录下。
bash
modelscope download --model rubick321/qwen3-32b-w8a8-mindie-300I --cache_dir "D:\docker_image"五.下载openai_web
1.下载地址
下载地址:https://docs.openwebui.com/getting-started/quick-start/
因为博主是用windows下载的镜像,然后再导入的,所以这里选择Diocker、WSL
按照下面的步骤拉取镜像。
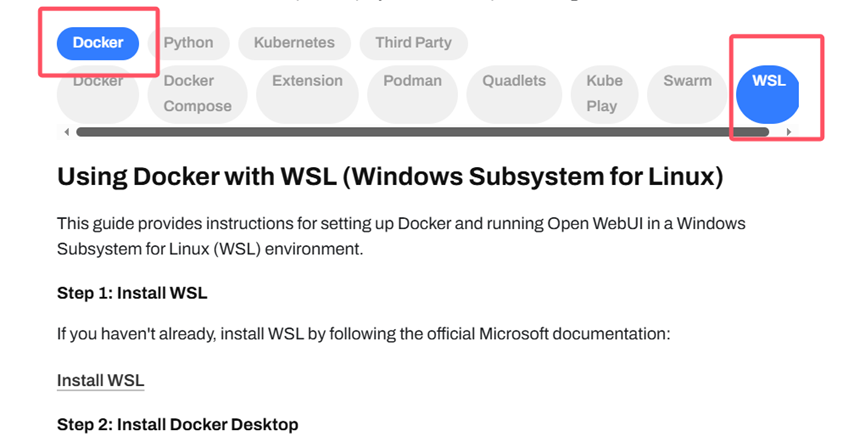
将拉取好的镜像打包成open_webui.tar。

六.加载镜像
将mindie1.tar和open_webui.tar包拷贝至带安装服务器上。
bash
// 加载大模型镜像
docker load -i mindie1.tar
//加载openai镜像
docker load -i open_webui.tar加载完毕后,可以使用docker images 命令来检查是否加载成功。
七.创建并启动容器
1.启动大模型的容器
bash
#!/usr/bin/sh
docker run -it -d --shm-size 200g --net=host --name qwen3-32b-1 --privileged --device=/dev/davinci_manager --device=/dev/hisi_hdc --device=/dev/devmm_svm --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /usr/local/sbin:/usr/local/sbin -v /opt/tools/qwen3-32b-w8a8-mindie-300I/rubick321/:/opt/tools/qwen3-32b-w8a8-mindie-300I/rubick321 02efebd6ce64 /bin/bash将以上内容复制进model_start.txt,然后通过sh model_start.txt来创建并启动qwen3-32b-1容器。
这里注意,尽量不要使用换行符,如果使用,可能会报格式错误。
02efebd6ce64是大模型对应的image id,根据实际情况修改。
2.启动open_webui的容器
bash
#!/usr/bin/sh
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open_webui fa72924fe8da将以上内容复制进open_webui_start.txt,然后通过sh model_start.txt来创建并启动open_webui容器。
这里注意,尽量不要使用换行符,如果使用,可能会报格式错误。
fa72924fe8da是open_webui对应的image id,根据实际情况修改。
八.修改配置文件
1.查看正在运行的容器
bash
docker ps -a2.进入容器内部
bash
docker exec -it 9889d616d775 /bin/bash 9889d616d775 是容器的id
3.修改conf.json文件
bash
cd /usr/local/Ascend/mindie/latest/mindie-service/conf
vim conf.json博主修改的内容为红框中的参数。
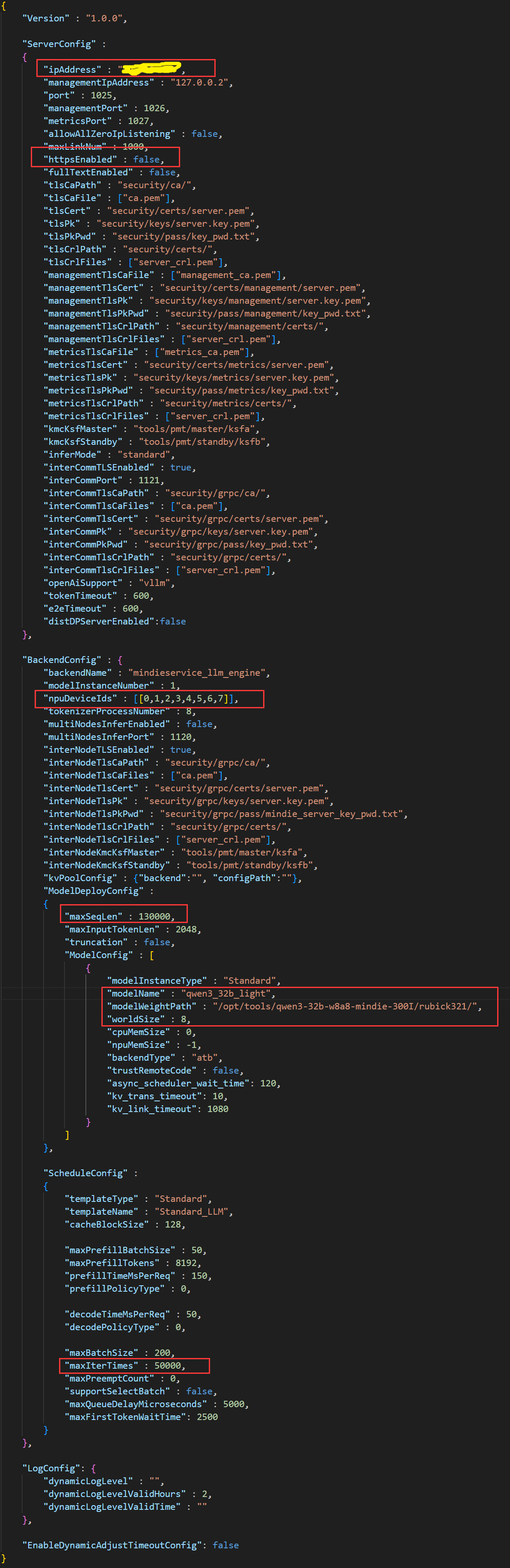
- ipAddress:部署大模型的ip地址。
- httpsEnabled:关闭HTTPS通信。
- npuDeviceIds:\[0,1,2,3...] NPU编号,一般是从0号开始,按顺序使用。
- worldSize:使用NPU卡的数量。
- maxSeqLen:输入和输出的最大总长度,需大于等于maxInputTokenLen和maxIterTimes的和。
- maxInputTokenLen:输入部分的最大token数量,必须小于maxSeqLen,如果输入被截断,可能需要增加这个参数的值。
- maxIterTimes:最大迭代次数,即输出的最大token数,必须小于maxSeqLen。
- modelName:模型名称,自定义。调用模型时即使用此名称。
- modelWeightPath:容器内模型映射路径,与docker run设置保持一致。
- maxPrefillBatchSize:预填充阶段一个batch中的请求个数上限,范围在1,maxBatchSize之间,建议设置为maxBatchSize的一半。
- maxPrefillTokens:预填充阶段一个batch中包含的Input token总数的上限,设置为与maxInput-TokenLen相同。
- maxBatchSize:解码阶段的最大batch size,影响并发能力,取值范围1,5000。
九.启动大模型
bash
cd /usr/local/Ascend/mindie/latest/mindie-service/bin
./mindieservice_daemon验证大模型是否能正常使用,这里推荐使用postman进行测试。
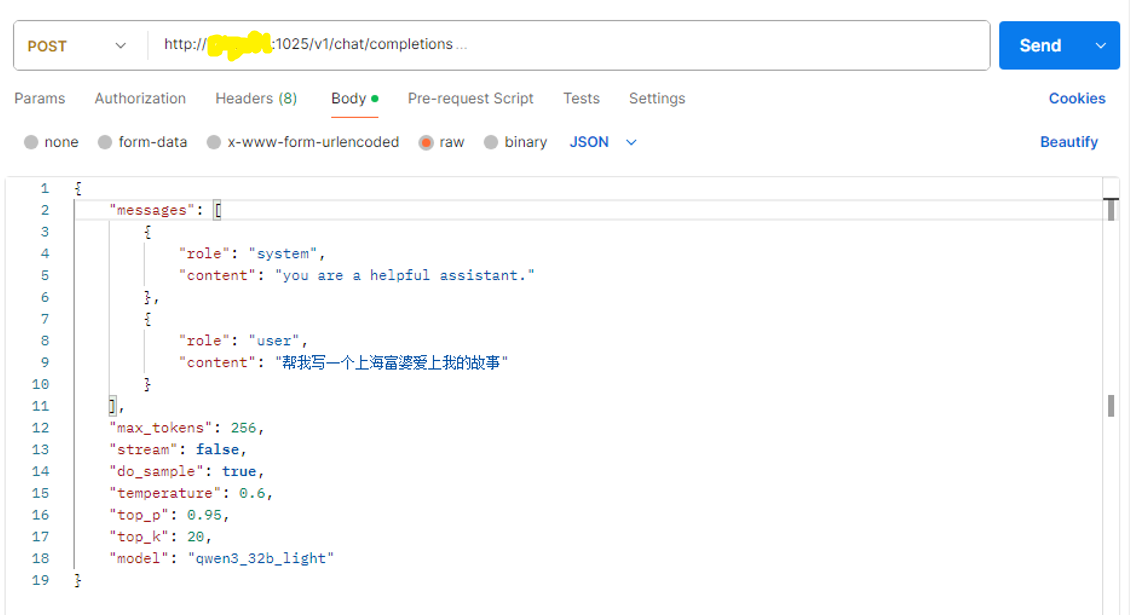
完整请求体如下:
powershell
{
"messages": [
{
"role": "system",
"content": "you are a helpful assistant."
},
{
"role": "user",
"content": "帮我写一篇日记"
}
],
"max_tokens": 256,
"stream": false,
"do_sample": true,
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"model": "qwen3_32b_light"观察输出内容,相信你能看出来是否成功。
十.启动open_webui
1.验证open_webui是否安装成功
打开http://<ip地址>:3000,如果能打开,即安装成功。
(eg:http://192.168.1.155:3000)
2.添加大模型接口
点击头像->管理员面板->设置->外部连接。OpenAI接口中默认接口全部禁用,并添加大模型暴露的接口地址。
(eg:http://192.168.1.155:1025/v1)
3.禁用相关接口
将Ollama接口连接,全部禁用。
4.选择模型
主页面->选择模型->选择已部署的模型(这里的名字是八.3中modelName,eg:qwen3_32b_light)
参考:
https://blog.csdn.net/mizhiakk/article/details/147305068
https://blog.csdn.net/qq_32793161/article/details/151833692?sharetype=blog&shareId=151833692&sharerefer=APP&sharesource=qq_39671159&sharefrom=qq