⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,"虽小必牢"(虽然你犯的事很小,但你肯定会坐牢)。
暗网情报:自动化采集与情感分析在威胁狩猎中的应用
你好,我是陈涉川。老生常谈的都市传说,在网络安全的版图中,暗网(Dark Web) 是威胁情报(CTI)皇冠上最晦涩但也最耀眼的宝石。如果说之前的篇章我们是在防御"已经发生"或"正在发生"的攻击,那么这一篇我们将深入"攻击发生之前"的混沌领域。
在这里,威胁不再是日志里的异常流量,而是黑客论坛里的一个叫卖贴,是 Telegram 私密群组里的一段 Python 代码,或者是勒索软件谈判聊天室里的一句威胁。
我们要构建的,是一个能够自动潜入这片深海、听懂黑话、并从中提炼出战术情报的 AI 侦察兵。
"深渊不仅会回望你,深渊还会向你兜售 0-day 漏洞。在没有光的地方,信息就是唯一的货币。"
引言:左移防御的极限
在传统的安全运营中心(SOC)中,分析师们处理的是 IOCs(入侵指标):哈希值、IP 地址、域名。这些都是滞后指标------当你看到它们时,攻击往往已经开始,甚至已经结束。
威胁狩猎(Threat Hunting)的核心在于"主动"。最极致的主动,就是在黑客购买攻击工具的时候就发现他。
暗网(The Dark Web),这个构建在 Tor、I2P 和 Freenet 之上的隐秘网络,是网络犯罪的供应链源头。
- 初始访问经纪人(IABs) 在这里出售企业 VPN 的凭证。
- 恶意软件开发者 在这里发布最新的勒索软件即服务(RaaS)。
- 数据泄露者 在这里通过"拍卖"形式处理窃取的数据库。
然而,监控暗网不仅是技术挑战,更是工程学噩梦。这里没有搜索引擎优化,只有极端的反爬虫机制、复杂的验证码、乃至诱捕研究人员的蜜罐。
本篇将探讨如何构建一个企业级的、基于 AI 的暗网情报采集与分析系统。
第一章 迷雾中的灯塔:暗网采集系统的架构设计
普通的网络爬虫(Crawler)在暗网活不过三分钟。暗网站点的生命周期极短,服务器极其不稳定,且充满了对"机器人"的敌意。我们需要的是一个高可用、高隐蔽、分布式的采集架构。
1.1 分布式匿名网络接入层
你不能直接用公司的 IP 去扫描 Tor 节点,那等于是在裸奔。我们需要构建一个 Tor/I2P 代理池。
此外,必须引入随机抖动(Random Jitter)。在每次请求之间插入遵循泊松分布(Poisson Distribution)的随机延迟,模拟人类不规律的阅读节奏,防止基于时序流量分析的关联封禁。
- 节点轮询(Circuit Rotation):
使用 Stem 库控制 Tor 进程。每完成 N 次请求或通过检测到被封禁(403 Forbidden),强制发送 NEWNYM 信号,切换出口节点(Exit Node)。
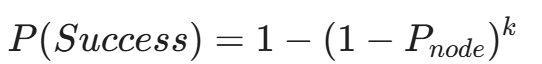
其中 k 是可用出口节点的数量。为了保证高可用性,我们通常维护一个包含 50-100 个 Tor 实例的 Docker 集群,通过 HAProxy 进行负载均衡。
- 隔离环境(Isolation):
所有的采集器(Worker)都运行在无状态的容器中。任何持久化存储(Cookies, LocalStorage)都在内存中进行,任务结束后立即销毁。这不仅是为了反指纹,也是为了防止被反向入侵(黑客通过 Web 漏洞攻击爬虫服务器)。
1.2 动态拓扑发现(Onion Mapping)
暗网没有 DNS 注册中心。发现新站点主要依靠:
- 索引站爬取: 监控 Ahmia, Torch, Hidden Wiki 等入口。
- 递归链接分析: 类似于 PageRank,从已知站点爬取 .onion 链接。
- DHT 嗅探(针对 I2P/Torrent): 监听分布式哈希表中的新节点广播。
我们需要维护一个动态的 Seed List。由于暗网站点经常遭遇 DDoS 或被执法部门查封(Seized),系统必须具备**存活心跳检测(Liveness Check)**机制,将死链剔除,避免浪费算力。
1.3 高吞吐数据管道(The Data Pipeline)
采集器抓取的不是最终数据,而是"原始快照"。我们需要构建基于 Kafka 或 RabbitMQ 的缓冲层。
- 解耦(Decoupling): 爬虫只负责"抓",解析器负责"算"。即使解析服务崩溃,爬虫数据也不会丢失,而是堆积在队列中。
- 重复数据删除(Deduplication): 暗网论坛有大量重复转载。在入库前,利用 Bloom Filter (布隆过滤器) 和 SimHash 算法对文本进行指纹比对,剔除 90% 的冗余内容,节省存储成本。
第二章 突破叹息之墙:高对抗下的反爬与验证码破解
暗网管理员(Admin)是世界上最偏执的一群人。为了防止执法部门和安全公司的扫描,他们部署了比 Cloudflare 更激进的防御系统(如 DDoS-Guard, EndGame)。
2.1 浏览器指纹的伪装(Anti-Fingerprinting)
简单的 Python Requests 在暗网寸步难行。现代暗网论坛大量使用 JavaScript 来验证客户端环境。
如果你的 Canvas 渲染结果、WebGL 参数、AudioContext 指纹与标准 Tor Browser 不一致,服务器直接拒绝连接。
解决方案:基于 Playwright 的指纹注入
我们不禁用 JS,而是欺骗 JS。
通过 Hook 浏览器底层的 API,注入随机化但合法的指纹数据:
- User-Agent: 严格模拟当前 Tor Browser 的版本(例如 Mozilla/5.0 (Windows NT 10.0; rv:109.0) Gecko/20100101 Firefox/115.0)。
- Screen Resolution: 锁定为 Tor 推荐的 1000x1000 或标准窗口大小,禁止最大化。
- Canvas Noise: 在 HTMLCanvasElement.prototype.toDataURL 中注入微小的随机噪点,使得指纹哈希值每次都不同,但肉眼看不出区别。
2.2 验证码军备竞赛(CAPTCHA Wars)
这是爬虫面临的最大拦路虎。暗网的验证码从简单的字符识别,进化到了逻辑题、甚至 ASCII 艺术识别。
- 第一代:传统 OCR(Tesseract)。 对付简单的字母数字组合。
- 第二代:深度学习目标检测(YOLO/CNN)。
针对滑块验证、点击特定物体("请点击图中的红绿灯")。我们需要建立一个庞大的标注数据集(可以通过众包平台获取),训练专门的 CNN 模型。
- 第三代:逻辑与常识(LLM 辅助)。
现在的验证码可能是:"它是圆的,能吃,通常是红色的。请输入这个单词。"
对于这种语义验证码,我们将图像转为 Base64,发送给多模态大模型(如 GPT-4V 或 MiniGPT-4),Prompt 设为:"Solve this riddle based on the image, output only the answer."
- 终极手段:人工打码农场(Human-in-the-loop)。
当 AI 失败率超过阈值时,API 自动将验证码转发给 2Captcha 或 Anti-Captcha 等服务,由真人解决。虽然有成本,但对于高价值目标(如顶级俄语黑客论坛 XSS 或 Exploit.in),这是值得的。
第三章 幽灵特工:虚拟身份管理与社会工程学自动化
仅仅能"看"是不够的。许多高价值情报隐藏在"回复可见"或"需要 10 个积分"的门槛之后。
我们需要构建虚拟身份(Sock Puppets),并让它们在社区中"活"起来。
3.1 账号生命周期管理(ALM)
- 注册自动化: 自动注册机需要解决临时邮箱(Temp Mail)接收验证码、PGP 密钥生成与上传的问题。
- 养号策略(Account Nurturing):
一个注册时间为"今天"且发帖数为 0 的账号是不可信的。
我们要设计一个 Bot 行为脚本:
-
- 潜伏期(Day 1-7): 只浏览,不发言,模拟真实阅读行为(随机滚动页面,停留时间符合正态分布)。
- 活跃期(Day 8-30): 在"灌水区"或"新手区"发布无意义但安全的回复("Thanks for sharing", "Great tool")。这些回复可以由 LLM 生成,确保语种和黑话风格与论坛一致。
- 成熟期(Day 30+): 此时账号已有一定积分,可以访问受限板块。
3.2 信任度量化(Trust Metrics)
在威胁狩猎中,不仅我们要评估黑客,黑客也在评估我们。
某些高级论坛(如 BreachForums)有严格的声望系统(Reputation)。
我们需要监控自己账号的健康度:
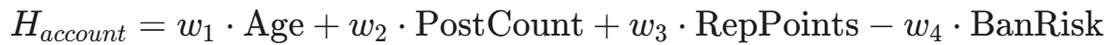 当 H_{account} 低于阈值时,系统应自动停止高频采集,进入"静默恢复"模式。
当 H_{account} 低于阈值时,系统应自动停止高频采集,进入"静默恢复"模式。
3.3 语言变色龙(Linguistic Chameleon)
不同的论坛有不同的方言。
- 俄语区(XSS, Exploit): 充满各种俚语(如 "Слив" 表示泄露,"Бтк" 表示比特币)。
- 英语区(BreachForums): 充满了 "FUD" (Fully Undetectable), "Refud", "Vouch"。
- 中文区(Telegram 群组): "狗推", "三件套", "CVV"。
我们在生成回复时,必须微调 LLM,使其加载特定社区的黑话词典(Slang Dictionary)。如果在俄语黑客论坛用标准的翻译软件生成的俄语发帖,会被立刻识别为"小白"或"警察",导致即刻封号。
第四章 数据炼金术:非结构化数据的清洗与实体提取
当爬虫成功抓取到 HTML 源码后,真正的挑战才刚刚开始。暗网数据是极其脏乱的非结构化文本。
4.1 异构数据解析(Heterogeneous Parsing)
- 论坛(Forum): 需要提取 楼主、发布时间、回复楼层、引用关系。
- 市场(Marketplace): 需要提取 商品名称、价格(通常是 USD 但以 BTC 结算)、卖家信誉、交易量。
- 粘贴板(Pastebin/DeepPaste): 纯文本,通常包含泄露的数据库字段或代码片段。
我们需要为每个主流站点编写解析器(Parser) ,或者使用基于 DOM 树密度分析的通用提取算法。
4.2 命名实体识别(NER)的暗网定制版
通用的 NLP 模型(如 spaCy 的 standard model)在暗网文本上表现极差。因为"Apple"在这里通常指的不是水果,也不是苹果公司,可能是"Apple ID 钓鱼页面"。
我们需要训练一个 Dark-NER 模型,专门识别以下实体:
- 加密货币地址: BTC, ETH, XMR (Monero) 地址。正则表达式是基础,但需要结合上下文判断(是"付款地址"还是"捐赠地址")。
- 通信账号: Telegram ID, Jabber/XMPP, Tox ID, Email。
- 技术资产(IOC): IP, Domain, Hash (MD5/SHA256)。
- 犯罪术语(Crime Terms): "CVV" (信用卡), "Fullz" (全套个人信息), "RDP" (远程桌面), "Shell" (Webshell)。
技术栈:BERT-CRF
我们使用 BERT-base-multilingual-cased 作为底座,在标注好的暗网语料库上进行微调(Fine-tuning)。
L = L_{CRF} +λ L_{Emission}
通过 CRF(条件随机场)层,我们可以利用标签之间的转移概率(例如 B-IP 后面不太可能接 I-EMAIL)来修正 BERT 的输出,提高识别准确率。
4.3 跨语言情报对齐(Cross-Lingual Alignment)
俄语黑客论坛的价值最高,但语言壁垒最厚。直接用 Google 翻译会丢失语境(例如将 "Carding" 翻译成"梳理羊毛"而不是"盗刷信用卡")。 我们需要部署本地化的翻译大模型(如 NLLB-200 或微调过的 LLaMA-3):
- 黑话词典注入: 在 Embedding 层之前,先通过正则表达式将 slang(如 "Dump", "Fullz")替换为标准语义占位符。
- 语义对齐: 将所有非英语内容映射到统一的向量空间,确保"勒索软件"在俄语、英语和中文中能检索到同一批情报。
4.4 身份消歧与关联(Identity Resolution)
黑客通常有多个马甲。在 Forum A 叫 DarkKnight99,在 Forum B 可能叫 Knight_of_Darkness。
我们需要通过以下特征构建虚拟身份图谱(Virtual Identity Graph):
- 共享的联系方式: 相同的 PGP Key、相同的 XMPP 账号或 BTC 钱包地址。
- 语言指纹(Stylometry): 分析其拼写错误习惯、标点符号使用频率、常用的独特的短语。
- 活动时间模式: 如果两个账号总是在 UTC 时间的凌晨 2 点到 6 点活跃,且从未同时在线发言,它们可能属于同一个人。
第五章 隐形战场:隐写术与混淆内容的还原
在高级威胁狩猎中,我们经常遇到黑客试图隐藏信息的情况。
5.1 图像隐写分析
在暗网市场,卖家有时会将真实的联系方式或详细的商品清单(如被盗信用卡列表)隐藏在展示图片中,以逃避平台的关键词审查或自动化扫描。
我们需要集成基于 Python 的 zsteg**(** 针对 PNG/BMP) 或 Stegano库。相比于人工使用的 StegSolve,这些库可以以 CLI 形式运行,自动遍历所有 Bit Plane(位平面),寻找隐藏的 ASCII 标志头(如 PK, ELF, MZ)。:
- LSB 分析: 检查最低有效位是否包含 ASCII 码。
- Exif 元数据提取: 虽然大部分平台会清洗 Exif,但偶尔会有漏网之鱼泄露黑客的 GPS 坐标或设备信息。
5.2 混淆文本还原
为了防止被搜索引擎索引,黑客常用混淆写法:
- tdotme/username
- user (at) protonmail (dot) com
- 127.0.0.1
采集系统必须包含一个去混淆中间件(De-obfuscator Middleware),利用正则替换和模糊匹配,将这些人类可读但机器难读的字符串还原为标准的 URL 和 Email 格式,以便后续的关联分析。
至此,我们已经搭建起了一套庞大的暗网数据摄取引擎(Ingestion Engine)。
- 我们利用 Tor 代理池和反指纹浏览器 突破了暗网的访问限制。
- 我们利用 AI 辅助的验证码破解 解决了自动化登录难题。
- 我们利用 养号脚本 潜伏在核心黑客社区。
- 我们利用 Dark-NER 将杂乱的网页变成了结构化的情报数据库。
现在,我们的 Elasticsearch 数据库中每天都在涌入数万条新的帖子、商品和聊天记录。
但这只是一堆数据(Data),还不是情报(Intelligence)。
如何判断这几万条信息中,哪一条是针对我们企业的真实威胁?
如何区分黑客是在"吹牛"(Scam/Hype)还是真的掌握了 0-day 漏洞?
如何预测勒索软件组织的下一个目标行业?
这需要给系统装上一个"大脑"------情感分析(Sentiment Analysis)与威胁态势感知模型。这正是我们下一篇(下部)要深入探讨的核心内容。
在充满谎言、诈骗和夸大其词的地下网络中,AI 的任务不是寻找真相,而是计算概率。当所有人都说要攻击你时,那只是噪音;当只有一个人在角落里低声讨论你的数据库架构时,那才是信号。
第六章 情感计算:破译黑客社区的"晴雨表"
暗网是一个情绪极其不稳定的地方。愤怒、炫耀、恐慌和贪婪在这里交织。通过量化这些情绪,我们可以预测威胁态势的变化。
6.1 基于方面的情感分析 (ABSA)
通用的情感分析只能告诉你这句话是"积极"还是"消极"。但在暗网情报中,这远远不够。
黑客说:"这个勒索软件加密速度太快了,简直完美!"
- 通用情感: 积极(Positive)。
- 防御者视角: 极度危险(High Threat)。
我们需要使用 ABSA (Aspect-Based Sentiment Analysis),针对特定方面(Target Aspect)进行分析。
模型架构:BERT-SPC (Sentence Pair Classification ,这本质上是一个句子对分类任务,Sentence Pair Classification)
我们将输入构造成 CLS 评论文本 SEP 目标实体 SEP 的形式。
- 输入 1: "LockBit 3.0 的解密工具有 Bug,根本无法恢复文件。" + 实体:"LockBit" -> 情感:负面(信誉崩塌)。
- 输入 2: "LockBit 3.0 的加密速度提升了 50%。" + 实体:"LockBit" -> 情感:正面(技术升级)。
实战应用:RaaS 组织的健康度监控
我们监控某勒索软件组织(如 Play Ransomware)的所有提及帖。
如果关于"支付(Payment)"和"支持(Support)"的负面情感在短时间内飙升,往往预示着该组织内部出现了分赃不均或技术故障,甚至可能即将跑路(Exit Scam)。这对于正在进行勒索谈判的受害者来说是至关重要的战略情报------不要支付赎金,因为他们可能已经无法解密了。
6.2 恐慌指数与漏洞利用预测
当一个新的 CVE(如 Log4j)被披露时,我们监控暗网的情绪曲线:
- 好奇阶段: 关键词 POC, Test, How to 出现。情感中性。
- 狂热阶段: 关键词 Working, Mass Scan, Root 飙升。情感极度高昂。
- 变现阶段: 关键词 Selling, Shop, Access 出现。
我们可以构建一个 Vulnerability Weaponization Score (VWS):
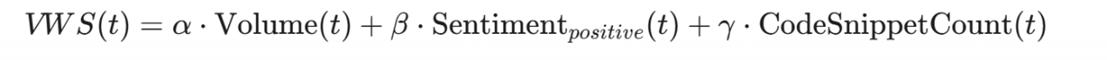
当 VWS 超过阈值时,意味着该漏洞已完成武器化,SOC 必须立刻将修补优先级提至最高,哪怕官方补丁还没出(这时需要应用虚拟补丁)。
第七章 话题建模:在噪声中发现新型威胁
暗网论坛每天产生数万条帖子,90% 都是垃圾广告("出售 CVV"、"洗钱服务")。我们要找出那 10% 真正讨论新技术的帖子。
7.1 BERTopic 的动态话题聚类
传统的 LDA(隐含狄利克雷分布)在处理短文本和黑话时效果不佳。我们采用 BERTopic,一种基于 Transformer 的话题建模技术。
流程:
- Embedding: 使用微调过的 Sentence-BERT 将帖子转化为向量。
- Dimensionality Reduction: 使用 UMAP 将高维向量降维,保留局部结构。
- Clustering: 使用 HDBSCAN 进行基于密度的聚类,自动发现话题,并允许噪声点(垃圾广告)的存在。
- Representation: 使用 c-TF-IDF 提取每个聚类的关键词。
案例:发现"隐形"的供应链攻击
系统自动聚类出了一个新话题,关键词包括:Python library, PyPI, Typo, Stealer。
分析师介入调查,发现这是黑客在讨论如何向 PyPI 官方仓库上传带有后门的恶意包。这比传统的安全新闻报道早了整整一周。
7.2 零样本分类(Zero-Shot Classification)
当老板问:"由于地缘政治紧张,我们需要知道暗网是否在讨论针对我们行业的攻击?"
我们不需要重新训练模型,可以使用 BART-Large-MNLI 进行零样本分类。
- Premise: 抓取到的帖子内容。
- Hypothesis: "This text is about cyber attacks on the Energy Sector."
- Result: 模型输出蕴含概率(Entailment Probability)。
这使得情报系统具有极高的灵活性,可以随时响应突发的业务需求。
第八章 社会网络分析(SNA):绘制黑客组织的权力地图
虽然黑客是匿名的,但他们的交互关系暴露了他们的组织结构。
8.1 构建交互图谱
我们将清洗后的数据转化为图结构 G(V, E):
- 节点 V: 论坛用户 ID。
- 边 E: 回复、引用、交易评价、私信(如果发生了泄露)。
8.2 关键人物识别(HVI Identification)
利用图算法寻找核心节点:
- PageRank / Eigenvector Centrality: 找出**"意见领袖"**。也就是那些发言虽然不多,但每次发言都被大量高权重用户回复的人。这通常是真正的技术大牛或组织头目。
- Betweenness Centrality(介数中心性): 找出**"中间人(Broker)"**。这些人连接着不同的子社区(例如连接着"恶意软件开发组"和"洗钱组"),他们通常是初始访问经纪人(IAB)。
8.3 社区发现(Community Detection)
使用 Louvain 算法 挖掘紧密的小团体。
如果你发现一个紧密的子图,里面的用户频繁交换关于 SWIFT、Banking 的代码片段,且使用一种罕见的加密方言,你可能锁定了一个针对金融系统的高级持续性威胁(APT)小组。
第九章 实战:威胁狩猎自动化工作流 (The Hunter's Loop)
所有的技术最终都要服务于行动。我们将上述组件整合为一个闭环的威胁狩猎系统。
9.1 场景一:凭证泄露的实时阻断
触发条件: 采集器在某俄语论坛的"日志云(Cloud of Logs)"分享区,解析出了包含公司域名 @mycompany.com 的 user:pass 组合。
自动化响应流程(SOAR):
- 验证: AI 检查该邮箱是否为公司在职员工(对接 HR 系统)。
- 风险评分: 检查该密码是否符合公司当前的强密码策略(如果是 123456,可能是历史遗留数据;如果是复杂密码,可能是最新泄露)。
- 行动:
- 调用 Active Directory API,强制重置该用户密码。
- 撤销该用户的所有 Session Token。
- 在 SIEM 中追溯该用户过去 24 小时的 VPN 登录日志,寻找异常 IP。
- 发送 Slack 通知给 SOC 团队:"已自动阻断一起凭证泄露事件,涉及用户 X。"
9.2 场景二:针对性勒索软件预警
触发条件: 情感分析和 NER 模型发现暗网正在讨论"某制造业巨头"的内网拓扑图,且话题热度(Velocity)急剧上升。
响应流程:
- 情报确认: 将帖子截图和翻译件发送给 CTI 分析师。
- 关联分析: 搜索该黑客 ID 的历史发言,发现他曾出售过 Citrix 漏洞利用工具。
- 防御加固:
- 自动扫描边界防火墙,确认 Citrix 相关端口是否开放。
- 在 EDR 上下发针对该黑客常用工具(如 Cobalt Strike 特征)的激进拦截策略。
- 向高管发布"红色预警"。
9.3 误报运营与反馈循环(RLHF in Ops)
自动化系统最大的敌人是误报疲劳(Alert Fatigue)。如果 AI 每天发送 100 条假警报,分析师会直接关闭系统。 我们构建了一套基于 RLHF (人类反馈强化学习) 的微调机制:
- 一键反馈: 在 Slack 警报下方设置 Confirm 和 False Positive 按钮。
- 权重自适应: 如果分析师点击"误报",系统自动提取该样本的特征(如特定的无害关键词组合),作为负例(Negative Sample)加入训练集,并在下一次模型更新中降低类似情报的评分权重。
第十章 伦理与法律边界:在灰色地带跳舞
在建设暗网情报能力时,技术不是唯一的瓶颈,法律合规才是最大的地雷。
10.1 主动交互的红线(Active Engagement)
- 被动采集(Passive): 爬取公开帖子。通常合法(视各国法律而定,属于 OSINT 范畴)。
- 主动交互(Active): 注册账号,甚至私聊黑客套取情报(HUMINT)。
- 风险: 诱导犯罪(Entrapment)。如果你为了套话,建议黑客"为什么不试试攻击 X 公司呢?",你就成为了共犯。
- 原则: 永远不要提供技术帮助,永远不要建议目标,永远不要支付金钱(购买数据可能涉嫌资助恐怖主义或洗钱)。
10.2 隐私数据处理(GDPR/CCPA)
我们在暗网抓取的数据(如泄露的数据库)包含了大量无辜平民的 PII(个人身份信息)。
- 数据最小化: 在入库前进行脱敏。只存储哈希值或部分掩码(j***@gmail.com)。
- 被遗忘权: 如果客户要求删除其泄露数据,系统必须支持这一操作。虽然数据在暗网还在,但在你的情报库里必须消失。
- •非法内容熔断(CSAM Filtering): 这是暗网采集的红线。系统必须集成 PhotoDNA 或基于哈希的黑名单库(如 NCMEC 列表)。在图片落地存储前,先计算哈希值进行比对。一旦命中违禁内容,立即内存丢弃并标记该 URL 为永久黑名单,绝不能写入硬盘。
结语:照亮深渊的火把
暗网情报不是水晶球,它无法预言每一次攻击。但它为防御者提供了一个极其宝贵的时间窗口。
在黑客从"购买访问权限"到"部署勒索软件"之间,通常有 3 到 14 天的潜伏期。
通过构建这套基于 AI 的自动化采集与分析系统,我们争取的正是这黄金 14 天。
我们不再是被动等待 SIEM 报警的"救火队员",我们变成了在防火墙之外巡逻的"守夜人"。
随着大语言模型(LLM)能力的不断进化,未来的暗网情报将更加智能化。也许有一天,我们的 AI Agent 能够伪装成最老练的黑客,潜入勒索软件的核心群组,在攻击发动的前一秒,悄悄修改掉他们的加密密钥。
这将是网络安全防御的最高境界------不战而屈人之兵。
下一篇预告
既然我们已经掌握了攻击手段(自动化渗透、恶意代码生成、DDoS)和情报手段(暗网挖掘),是时候来一场真刀真枪的全景式演练了。
理论是苍白的,实战是血腥的。当 AI 红队(Attacker) 遇上 AI 蓝队(Defender),会发生什么样的化学反应?
在下一篇 《实战案例:解析某次真实的"AI vs. AI"攻防演练》 中,我将带你复盘一场在高度仿真的金融内网环境中进行的、为期 48 小时的无人值守攻防对抗。
我们将看到:
- 红队 AI 如何利用刚刚生成的 0-day 变种绕过蓝队的检测。
- 蓝队 AI 如何在 5 分钟内完成"流量异常 -> 规则生成 -> 自动隔离"的极限操作。
- 以及在 AI 互博的纳秒级战场中,人类直觉(Human Intuition) 如何成为那唯一的"终止开关(Kill Switch)"。
敬请期待这场硅基生物的战争。
陈涉川
2026年02月02日