MUSE: 层次记忆和自我反思提升的 Agent
论文标题: Learning on the Job: An Experience-Driven, Self-Evolving Agent for Long-Horizon Tasks
作者: Cheng Yang 1 , 2 † ^{1,2†} 1,2†, Xuemeng Yang 2 † ^{2†} 2†, Licheng Wen 2 , 4 † ^{2,4†} 2,4†, Daocheng Fu 3 , 2 ^{3,2} 3,2, Jianbiao Mei 5 , 2 ^{5,2} 5,2, Rong Wu 5 , 2 ^{5,2} 5,2, Pinlong Cai 2 ^2 2, Yufan Shen 2 ^2 2, Nianchen Deng 2 ^2 2, Botian Shi 2 ⊠ ^{2\boxtimes} 2⊠, Yu Qiao 2 ^2 2, Haifeng Li 1 ⊠ ^{1\boxtimes} 1⊠
(1 Central South University, 2 Shanghai AI Laboratory, 3 Fudan University, 4 Shanghai Innovation Institute, 5 Zhejiang University)
代码: https://github.com/KnowledgeXLab/MUSE
5. 总结
核心结论 :
MUSE (Memory-Utilizing and Self-Evolving) 框架通过引入层级化记忆和自我反思机制,解决了 LLM 智能体在长时序任务中无法从经验中学习的问题。在 TheAgentCompany (TAC) 基准测试中,MUSE 仅使用轻量级的 Gemini-2.5 Flash 模型,便取得了 51.78% 的成功率,以 20% 的相对优势超越了此前由 Claude-3.5 Sonnet 驱动的 SOTA (OpenHands)。
前瞻展望 :
这项工作标志着智能体范式从"静态推理 (In-Context Inference)"向"动态进化 (Test-Time Evolution)"的转变。它证明了在不微调模型参数的情况下,通过结构化的情境记忆 (Episodic Memory) 和 程序性记忆 (Procedural Memory) 积累,智能体能够展现出类似人类的"在岗学习"能力,这将极大地降低构建垂直领域高性能 Agent 的成本。
1. 思想
当前,构建能够执行长时序、跨应用操作的通用智能体面临着本质性的困难。
-
大问题 (The Grand Challenge):
- 静态性 (Test-Time Static): 现有的智能体框架(如 AutoGPT, OpenHands)在部署后是"失忆"的。每次任务都是从零开始,之前的成功经验或失败教训无法沉淀。
- 长时序的脆弱性 (Long-Horizon Fragility): 真实世界的生产力任务(如 TAC Benchmark)往往涉及跨应用(Browser, Terminal, IDE)的数百步操作。随着步数增加,错误累积会导致成功率指数级下降。
- 泛化与特化的矛盾: 通用大模型缺乏特定环境下的"肌肉记忆"(例如:某个特定版本的 GitLab API 的怪癖,或某个内部系统的特殊登录流程)。
-
小问题 (Specific Technical Hurdles):
- 如何将非结构化的交互轨迹 (Trajectory) 转化为可复用的知识?
- 如何避免随着记忆积累导致的上下文窗口爆炸 (Context Overflow)?
- 如何在不引入人工标注的情况下,让智能体自我判断经验的有效性?
-
核心思想 (Core Idea) : MUSE
- 闭环学习 (Closed-Loop Learning): 建立 "Plan-Execute-Reflect-Memorize" (规划-执行-反思-记忆) 的循环。智能体不仅输出动作,还输出对自身行为的评价。
- 层级化记忆 (Hierarchical Memory) : 模仿人类认知,将记忆解耦为三类:
- 战略记忆 (Strategic Memory): 宏观的解决问题范式(类似"直觉")。
- 程序性记忆 (Procedural Memory): 标准操作程序 (SOPs),针对具体子任务的步骤(类似"技能")。
- 工具记忆 (Tool Memory): 对特定工具使用的微调说明(类似"肌肉记忆")。
- 完全解耦的架构: 将"执行者 (PE Agent)"与"观察者 (Reflect Agent)"分离,观察者负责从执行者的轨迹中提取确定的知识,确保存入记忆的信息具有高置信度。
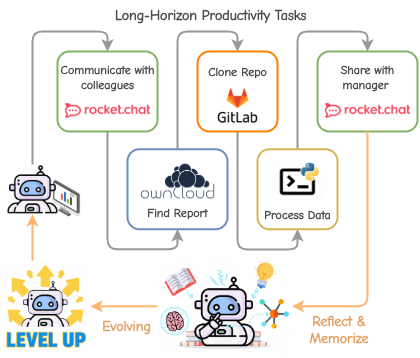
Figure 1: MUSE 的核心理念展示。智能体在长时序生产力任务中,通过不断的"尝试-反思-记忆",将原始轨迹转化为结构化经验,实现自我进化。
2. 方法
MUSE 的架构设计严密地围绕着 记忆的生命周期 (生成、存储、检索、更新)展开。系统主要由三个组件构成:记忆模块 (Memory Module) 、规划执行智能体 (PE Agent) 和 反思智能体 (Reflect Agent)。
2.1 记忆模块的数学抽象
我们将记忆模块 M \mathcal{M} M 定义为三个子集的并集:
M = { M s t r a t , M p r o c , M t o o l } \mathcal{M} = \{ \mathcal{M}{strat}, \mathcal{M}{proc}, \mathcal{M}_{tool} \} M={Mstrat,Mproc,Mtool}
- 战略记忆 (Strategic Memory) ( M s t r a t \mathcal{M}_{strat} Mstrat) :
战略记忆不是 具体的代码或操作步骤(那是 Procedural Memory 的职责)。它是元认知 (Meta-Cognition) 级别的原则,用于解决 "Dilemma"(两难困境或高层决策)。
作用 : 在任务初始化时加载,指导全局规划。- 数据结构 : Key-Value 对。
M s t r a t = { < Dilemma j , Strategy j > } \mathcal{M}_{strat} = \{ < \text{Dilemma}_j, \text{Strategy}_j > \} Mstrat={<Dilemmaj,Strategyj>} - 具体内容示例 (源自论文附录 Table 6):
- Dilemma: "Systemic Root Cause" (面对重复出现的错误,是修补表面还是查根源?)
- Strategy: "Diagnose and address underlying systemic causes... ensure long-term stability beyond symptom treatment." (强制 Agent 进行深度诊断而不是简单重试)。
- Dilemma: "Robust Context State" (如何处理状态不确定性?)
- Strategy: "Explicitly manage and continuously verify data... verify integrity of dependencies." (强制显式验证)。
- 作用位置 :
M s t r a t \mathcal{M}_{strat} Mstrat 在 Agent 初始化 (Initialization) 阶段直接被加载到 System Prompt 中。
它充当了 Agent 的"行为准则"或"性格设定",指导 Agent 在面对模糊情况时,倾向于采取更鲁棒、更具反思性的策略,而不是贪婪策略。
- 数据结构 : Key-Value 对。
- 程序性记忆 ( M p r o c \mathcal{M}_{proc} Mproc) :
这是核心的技能库,存储成功的子任务执行路径(SOPs)。为了优化上下文长度,采用双层检索机制 。
对于每个 SOP 条目 p p p,定义为二元组 p = ( i n d e x p , c o n t e n t p ) p = (index_p, content_p) p=(indexp,contentp)。- i n d e x p index_p indexp: 轻量级的索引描述(如子任务目标、涉及应用)。
- c o n t e n t p content_p contentp: 详细的操作步骤、注意事项、关键参数。
- 检索策略 : 在规划阶段,仅加载索引集合 I M p r o c = { i n d e x p ∣ p ∈ M p r o c } I_{\mathcal{M}{proc}} = \{index_p | p \in \mathcal{M}{proc}\} IMproc={indexp∣p∈Mproc} 进入 Context。当 PE Agent 决定执行特定子任务时,通过工具 a m e m a_{mem} amem 动态检索具体的 c o n t e n t p content_p contentp。
- 工具记忆 ( M t o o l \mathcal{M}_{tool} Mtool) :
针对单个工具 t t t 的使用优化。
定义为 M t o o l = { D s t a t i c , I d y n a m i c } \mathcal{M}{tool} = \{ D{static}, I_{dynamic} \} Mtool={Dstatic,Idynamic}。- D s t a t i c D_{static} Dstatic: 工具的静态功能描述(类似 Docstring)。
- I d y n a m i c I_{dynamic} Idynamic: 动态指令,包含基于过往经验生成的 "Tips"(例如:"这个API在这类输入下容易报错,建议先检查X")。
- 机制 : 当观察到环境状态 o t o_t ot 并决定使用工具时,系统自动注入 I d y n a m i c I_{dynamic} Idynamic 指导动作 a t + 1 a_{t+1} at+1。
2.2 规划-执行智能体 (PE Agent)
PE Agent 负责与环境交互。其工作流是一个嵌套的循环:
-
任务分解 : 给定总任务 τ \tau τ,生成子任务队列 Q = s t 1 , s t 2 , ... , s t M Q = st_1, st_2, \\dots, st_M Q=st1,st2,...,stM。
s t i = ( d e s c i , g o a l i ) st_i = (desc_i, goal_i) sti=(desci,goali)其中 d e s c i desc_i desci 是描述, g o a l i goal_i goali 是 Reflect Agent 用于验证的成功条件。
**如何分解子任务 **
- 输入 : 用户给定的原始任务描述 τ \tau τ (例如:"为新员工 Alice 创建 GitLab 账号并分配到 Frontend 组")。
- 过程 : PE Agent 将 τ \tau τ 映射为一个有序队列 Q i n i t Q_{init} Qinit。
Q i n i t = s t 1 , s t 2 , ... , s t M Q_{init} = st_1, st_2, \\dots, st_M Qinit=st1,st2,...,stM - 子任务结构 ( s t i st_i sti) : 每个子任务是一个元组,包含两个关键字段:
description: 自然语言描述,用于指导行动(例如 "Log in to GitLab as admin")。goal: 验收标准,这是专门留给 Reflect Agent 使用的 Ground Truth(例如 "Verify login success by checking the URL is /dashboard")。
- 特点: 初始分解通常基于 LLM 的通用知识,往往是粗粒度的,可能遗漏具体的环境依赖(例如不知道需要先获取 Admin 密码)。
-
ReAct 循环 : 对于每个子任务 s t i st_i sti,执行标准的 Thought-Action-Observation 循环:
a t ∼ π t e s t ( a t ∣ h t , M ) a_t \sim \pi_{test}(a_t | h_t, \mathcal{M}) at∼πtest(at∣ht,M)其中历史 h t = ( o 1 : t , a 1 : t − 1 ) h_t = (o_{1:t}, a_{1:t-1}) ht=(o1:t,a1:t−1)。
注意 : PE Agent 被限制了最大步数 N = 20 N=20 N=20 以防止死循环。 -
动态重规划 : 每个子任务完成后,PE Agent 根据当前环境状态更新后续队列 Q Q Q。这是一个闭环控制过程,发生在每个子任务尝试之后。
- 触发条件 : 当前子任务 s t i st_i sti 执行完毕(无论 Reflect Agent 判定为 Success 还是 Failure)。
- 输入 :
- 当前的剩余队列 Q r e m a i n = s t i + 1 , ... , s t M Q_{remain} = st_{i+1}, \\dots, st_M Qremain=sti+1,...,stM。
- 刚刚的执行轨迹 h k : t h_{k:t} hk:t (Trajectory)。
- Reflect Agent 的反馈结果 f f f (Success/Failure) 和 诊断报告 R R R (如果是失败,含失败原因)。
- 当前环境最新的 Observation o t o_t ot。
- 操作逻辑 :
PE Agent 执行函数 U p d a t e ( Q r e m a i n , h , f , R ) → Q n e w Update(Q_{remain}, h, f, R) \rightarrow Q_{new} Update(Qremain,h,f,R)→Qnew。- Case 1: 成功 (Success) : 简单移除 s t i st_i sti,检查 Q r e m a i n Q_{remain} Qremain 是否需要根据新获取的信息(如获取到的 IP 地址)微调后续参数。
- Case 2: 失败 (Failure) :
- 插入前置依赖 : 如果失败原因是"未登录",则在头部插入
login任务。 - 路径修正: 如果失败原因是"按钮不存在",则替换当前任务为替代方案(如"改用 CLI 创建用户")。
- 插入前置依赖 : 如果失败原因是"未登录",则在头部插入
- 本质 : 这是一个在线搜索算法。初始 Plan 只是一个 heuristic path,实际路径是在交互中动态生成的 Directed Acyclic Graph (DAG) 的遍历。
2.3 反思智能体 (Reflect Agent)
这是 MUSE 能够"自我进化"的关键。它作为一个独立的监督者,不直接参与任务推进,而是负责后验评估 (Posterior Evaluation)。
-
子任务评估 :
当子任务 s t i st_i sti 结束时,Reflect Agent 接收轨迹 h k : t h_{k:t} hk:t 和目标 g o a l i goal_i goali。
它执行两类验证:
- 轨迹回溯 (Trajectory Referencing): 检查逻辑一致性。
- 主动验证 (Active Verification) : 使用工具(如
ls,grep, 网页浏览)去环境中确认结果(例如:确认文件是否真的生成了)。
输出结果 f ∈ { s u c c e s s , f a i l u r e } f \in \{success, failure\} f∈{success,failure}。
- If Success : 将 h k : t h_{k:t} hk:t 提炼为 SOP p n e w p_{new} pnew,并加入 M p r o c \mathcal{M}_{proc} Mproc。
- If Failure : 生成故障分析 R f a i l R_{fail} Rfail,指导 PE Agent 重试或重规划。
-
全局记忆更新 (Post-Task Distill) :
当整个任务 τ \tau τ 结束时,Reflect Agent 回顾完整轨迹,提取跨任务的通用模式,更新 M s t r a t \mathcal{M}{strat} Mstrat 和 M t o o l \mathcal{M}{tool} Mtool。这是一个"去重"和"泛化"的过程,防止记忆库无限膨胀。
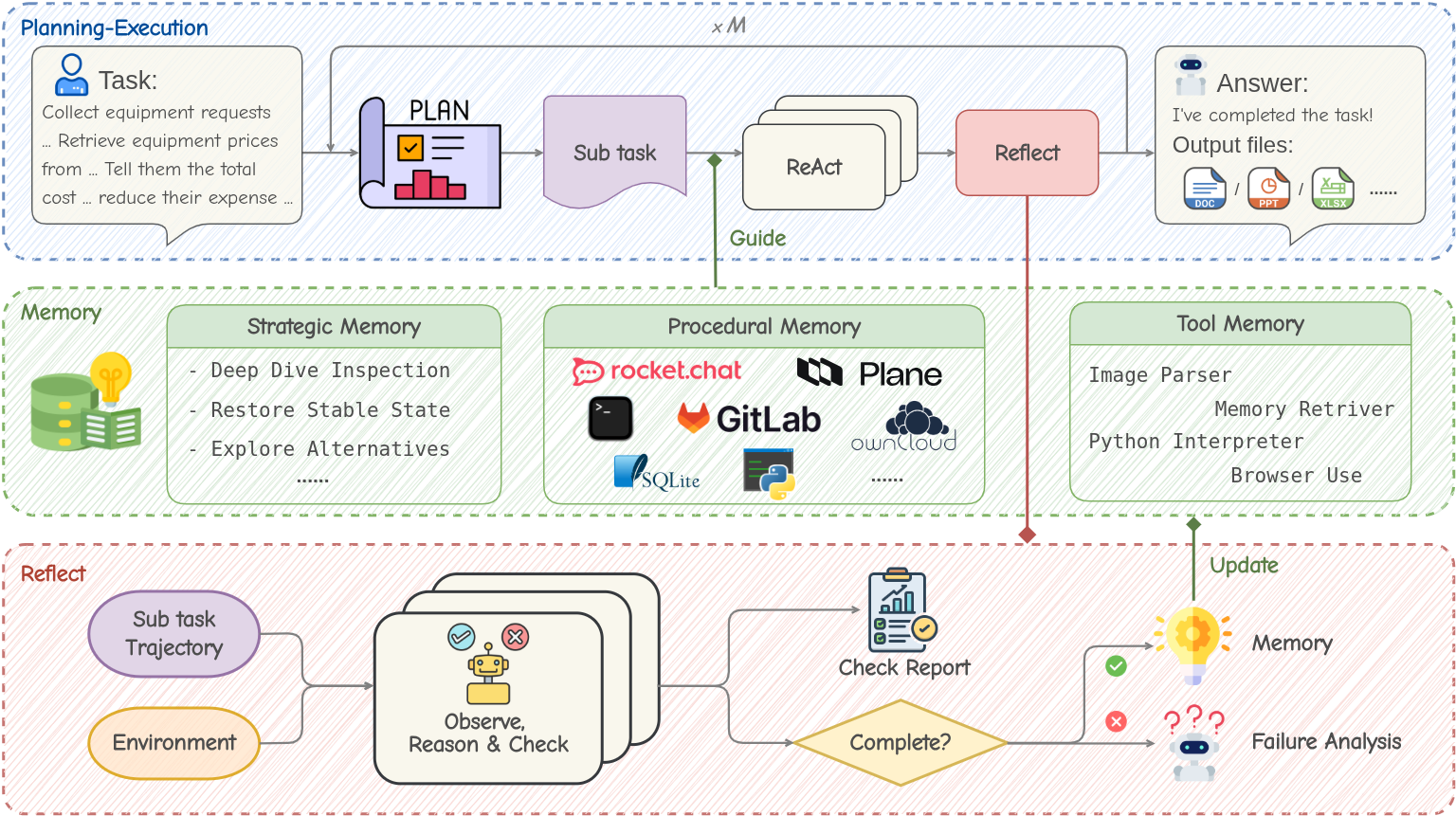
Figure 2: MUSE 的工作流架构。PE Agent 在环境中执行,Reflect Agent 监控并提炼经验存入 Memory Module。Memory Module 包含战略、程序、工具三个层级。
3. 优势
MUSE 相比于现有的 Agent 框架(如 OpenHands, Voyager, ExpeL)具有显著的差异化优势:
- 无需参数微调 (Gradient-Free): 所有的"学习"都发生在上下文记忆中。这使得 MUSE 可以直接应用于闭源模型(GPT-4, Gemini)或无法承担微调成本的场景。
- 跨任务泛化 (Zero-Shot Generalization) : 实验表明,在简单任务集上积累的 SOP 和工具使用技巧,可以直接迁移到未见过的困难任务中。这是因为 M p r o c \mathcal{M}_{proc} Mproc 存储的是"如何操作软件"的通用知识,而非特定任务的过拟合解。
- 抗噪性 (Robustness) : 通过 Reflect Agent 的主动验证机制,大幅减少了 LLM 常见的"虚假成功"幻觉。只有经过验证的轨迹才会转化为记忆,保证了知识库的高质量。
- 极简工具集: MUSE 仅使用最基础的工具(Browser, Shell, Python, Vision),依靠组合基础工具解决复杂问题,而非依赖预定义的特化 API。
4. 实验
4.1 实验设置
- 基准测试 : TheAgentCompany (TAC)。这是一个高保真的长时序生产力基准,包含 175 个任务,模拟真实操作系统环境(包含 GitLab, RocketChat, OwnCloud 等)。平均任务步数 > 40,涉及跨应用交互。
- 模型 :
- MUSE: Gemini-2.5 Flash (轻量级模型)。
- Baseline: OpenHands (配置 Gemini-2.5 Pro, Claude-3.5 Sonnet 等 SOTA 模型)。
- 评价指标 :
- S c k p t S_{ckpt} Sckpt: Checkpoint 完成率。
- S p a r t i a l S_{partial} Spartial: 部分完成分数(主要指标)。
- P C R PCR PCR: 完美完成率。
4.2 持续学习能力 (Continuous Learning)
为了验证"Learning on the Job",作者构建了一个包含 18 个任务的子集 T c l \mathcal{T}_{cl} Tcl。智能体在这个子集上连续运行 3 轮 (Iterations)。
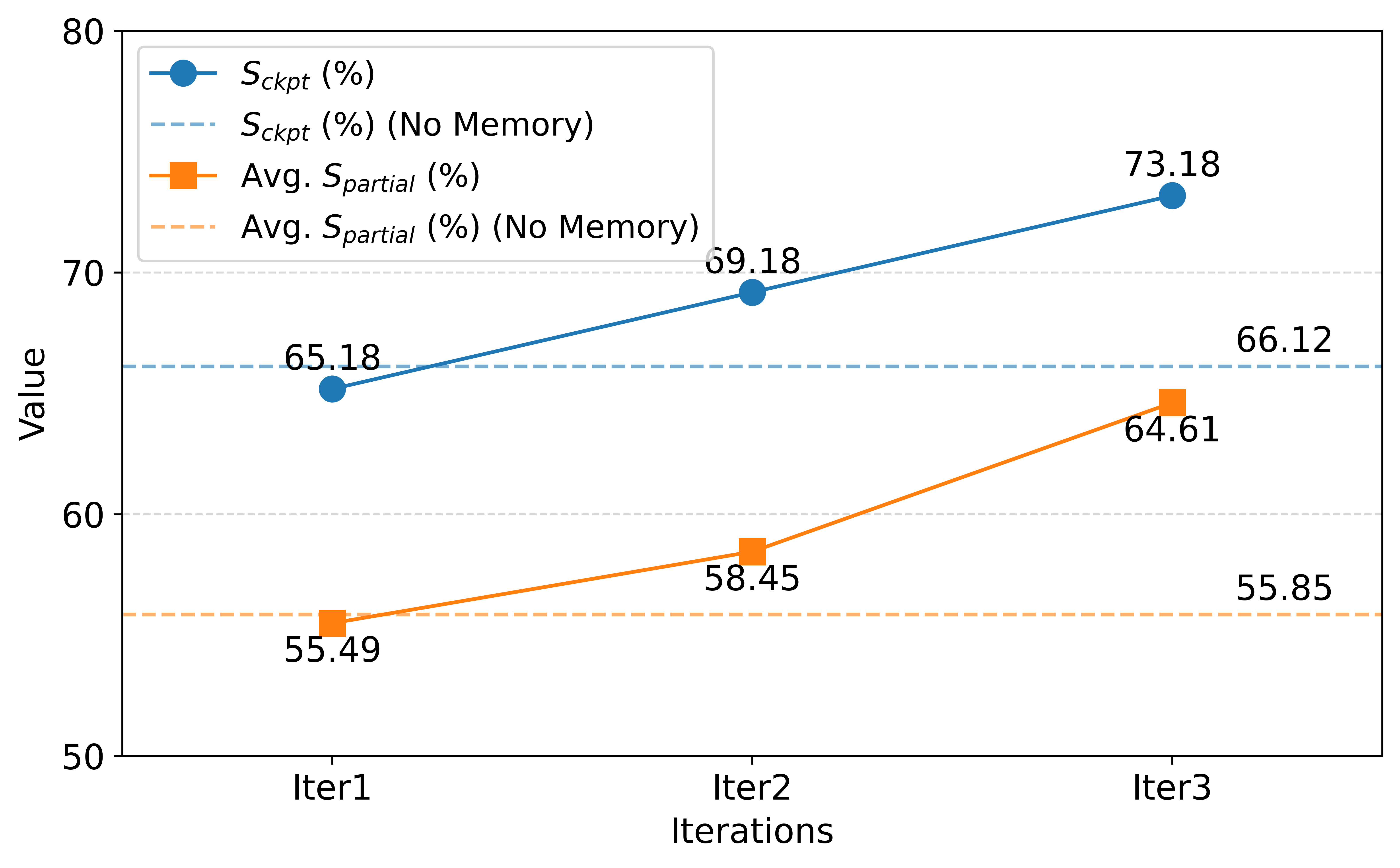
Figure 3: MUSE 在 T c l \mathcal{T}_{cl} Tcl 上连续 3 轮迭代的性能趋势。蓝色实线表示 Checkpoint 完成率,橙色实线表示平均得分。可以看出随着经验积累,性能单调上升。
- 结果 : 第 3 轮相比 Baseline (无记忆) 提升了 >10%。这证明了智能体成功地利用了前一轮的经验来修正错误或加速执行。
4.3 泛化能力与 SOTA 对比
作者将在 T c l \mathcal{T}{cl} Tcl 上积累的记忆冻结,直接用于测试全集(175个任务)和困难子集 T h a r d \mathcal{T}{hard} Thard。
Table 2: TAC 全集 (175 tasks) 性能对比
| Framework | Model | Avg. S p a r t i a l S_{partial} Spartial (%) | PCR (%) |
|---|---|---|---|
| OWL-RolePlay | GPT-4o + o3-mini | 11.04 | 4.00 |
| OpenHands | Gemini-1.5 Pro | 8.02 | 3.43 |
| OpenHands | Gemini-2.5 Pro | 39.28 | 30.29 |
| OpenHands-Versa | Claude-3.5 Sonnet | 43.19 | 33.14 |
| MUSE (Ours) | Gemini-2.5 Flash | 51.78 | 41.14 |
- 核心发现 :
- 超越 SOTA: MUSE 仅用 Flash 模型就击败了由 Claude-3.5 Sonnet 驱动的 OpenHands-Versa(51.78% vs 43.19%)。
- 泛化性 : 在 T h a r d \mathcal{T}_{hard} Thard(大多数模型得分为 0 的困难任务)上,MUSE 达到了 33.41% 的分数,而 Baseline 仅有个位数。这说明记忆模块中的 SOPs 具有极强的跨任务复用性。
4.4 消融实验
- 移除 Memory: 性能大幅下降,证明了经验积累的重要性。
- 移除 Reflect Agent: 即使保留 Memory 架构但移除反思机制,性能也会下降。这表明如果没有 Reflect Agent 过滤低质量轨迹,错误的经验会污染记忆库(Garbage In, Garbage Out)。
4.5 案例分析 (Case Study)
论文展示了一个有趣的案例:任务要求在 GitLab 上指派 Issue 给某个用户,但该用户账号不存在。
- 常规 Agent: 会反复尝试搜索用户,最终失败。
- MUSE :
- Reflect Agent 发现任务失败(用户未找到)。
- PE Agent 根据反馈进行重规划。
- 自主演化 : 智能体决定先创建一个同名的新账号,然后再指派 Issue。
这一过程完全由智能体自主发现,并未在预定义规则中,体现了极强的环境适应能力。
附录
工具集
| Tool | Function |
|---|---|
| run_cmd | Execute a full shell command string and return its result, suitable for file and sys- tem operations. |
| run_python_code | Execute Python code in an isolated environment for data processing and analysis. |
| access_guide | Retrieve structured procedural memory for accurate interaction. |
| gpt4o_describe_image | Use GPT-4o to recognize and interpret the content of images. |
| browser_go_to_url | Navigate the browser to a specified URL, supporting page refresh and reset. |
| browser_input | Input text into a specified field in the current browser page. |
| browser_send_keys | Send keyboard shortcuts or keystrokes (e.g., Enter) to the current browser tab. |
| browser_update | Wait and refresh to retrieve the latest accessibility tree and interactive elements. |
| browser_click | Click a specified interactive element in the current browser page by index. |
| browser_extract_content_by_vision | Extract specified content from a browser screenshot using GPT-4o. |
| browser_close_tab | Close a specified browser tab by index. |
| browser_go_back | Navigate back in the browser history of the current tab. |
| browser_list_tabs | List all currently open browser tabs. |
| browser_switch_tab | Switch to a specified browser tab by index. |
Prompt
见代码仓库: MUSE/prompt at main · KnowledgeXLab/MUSE
技术细节
-
自然语言 vs. 向量检索的抉择 (The Natural Language Prior) :
MUSE 的记忆设计有一个极其关键的特性:它完全放弃了 主流的基于 Embedding 的向量检索(Vector RAG),转而使用结构化的自然语言索引。
- 细节 : M p r o c \mathcal{M}{proc} Mproc 的检索是两阶段的。首先将所有 SOP 的
index(纯文本描述)放入 Context,让 LLM 依靠语义理解去"决定"是否需要查阅某个 SOP,然后通过工具 a m e m a{mem} amem 主动拉取content。 - 深层含义 : 这避免了 Vector Search 在面对细粒度差异(如 "Click generic button" vs "Click submit button")时常见的检索精度丢失问题。这也意味着记忆库的可扩展性受限于 LLM 的 Context Window 能容纳多少个 SOP 的
index,而非无限扩展。
- 细节 : M p r o c \mathcal{M}{proc} Mproc 的检索是两阶段的。首先将所有 SOP 的
-
工具记忆的"注入"方式 (Injection of M t o o l \mathcal{M}_{tool} Mtool) :
M t o o l \mathcal{M}{tool} Mtool 中的 I d y n a m i c I{dynamic} Idynamic (动态指令) 是如何生效的?- 细节 : 它是Contextual Injection 。当 PE Agent 决定调用某个工具(如
browser_click)时,系统会拦截这个意图,查找该工具的 I d y n a m i c I_{dynamic} Idynamic(例如:"注意:在此页面点击后需要等待 2秒再刷新"),并将其作为 Observation 的一部分或 System Prompt 的临时补充,强制 Agent 在生成具体参数时参考这些 Tips。这是一次微观的"Retrieved-Augmented Generation"。
- 细节 : 它是Contextual Injection 。当 PE Agent 决定调用某个工具(如
-
记忆即代码 (Memory as Code) :
MUSE 实际上是在运行时 (Runtime) 编写一本"操作手册"。
- M p r o c \mathcal{M}_{proc} Mproc 本质上是伪代码形式的宏(Macro)。
- 这暗示了未来 Agent 的发展方向可能不是让 LLM 变得更聪明(参数更多),而是让 LLM 变成更好的"文档编写者"和"文档阅读者"。
-
与微调 (Fine-tuning) 的正交性 :
论文声称"无需微调"。但在工业界落地时,最佳实践应该是:用 MUSE 框架在沙箱中跑出大量高质量轨迹 → \rightarrow → 清洗数据 → \rightarrow → 微调一个小模型 (SFT) → \rightarrow → 部署。
MUSE 不应仅被视为推理框架,更应被视为一个高质量合成数据生成器 (Synthetic Data Generator)。
-
TAC Benchmark 的特殊性 :
TAC 是一个环境封闭但任务多样 的测试集。环境(OS, Apps)是固定的。这有利于 SOP 的积累。如果环境 UI 频繁剧烈变化(如真实的 Web 浏览), M p r o c \mathcal{M}_{proc} Mproc 中的许多基于视觉或 DOM 结构的 SOP 可能会迅速失效(Stale Memory)。MUSE 对环境动态变化的鲁棒性(Memory Decay/Update)仍有待验证。
三个记忆库分别如何更新?
程序性记忆 ( M p r o c \mathcal{M}_{proc} Mproc): 实时增量与全局重构
这是更新频率最高、最核心的记忆库,对应"SOP (Standard Operating Procedure)"。
-
更新时机 (Trigger):
- 即时更新 (Online) : 每一个子任务 (Sub-task) s t i st_i sti 成功完成后。
- 延迟重构 (Offline) : 整个父任务 (Parent Task) τ \tau τ 完成后。
-
输入数据 :
Reflect Agent 验证为 f = success f=\text{success} f=success 的子任务执行轨迹 h k : t = ( o k : t , a k : t − 1 ) h_{k:t} = (o_{k:t}, a_{k:t-1}) hk:t=(ok:t,ak:t−1)。
-
更新逻辑:
- 抽象化 (Abstraction): Reflect Agent 将原始轨迹中的具体参数(如"点击坐标(10,20)"或"输入字符串'2023-Q4'")泛化为通用描述(如"点击提交按钮"或"输入目标季度")。
- 索引构建 (Indexing) : 为新的 SOP 生成轻量级索引 i n d e x p = ( Application , Goal ) index_p = (\text{Application}, \text{Goal}) indexp=(Application,Goal)。
- 全局整合 (Consolidation) : 在父任务结束后,系统会对 M p r o c \mathcal{M}_{proc} Mproc 进行一次"垃圾回收"式的扫描。
- 去重: 如果新生成的 SOP 与库中已有的高度相似,则进行合并。
- 泛化: 如果多个 SOP 解决了类似问题但略有不同,尝试合并为一个更通用的分支逻辑 SOP。
M p r o c ( t + 1 ) ← Refine ( M p r o c ( t ) ∪ Abstract ( h k : t ) ) \mathcal{M}{proc}^{(t+1)} \leftarrow \text{Refine}(\mathcal{M}{proc}^{(t)} \cup \text{Abstract}(h_{k:t})) Mproc(t+1)←Refine(Mproc(t)∪Abstract(hk:t))
战略记忆 ( M s t r a t \mathcal{M}_{strat} Mstrat): 困难驱动的提取
这是高层级的"智慧",主要来源于对失败 和困境的反思。
-
更新时机 (Trigger) :
仅在整个父任务 (Parent Task) τ \tau τ 结束后更新。
-
输入数据 :
完整的任务轨迹,特别关注那些触发了重试 (Retry) 或 重规划 (Replan) 的片段。
-
更新逻辑 :
Reflect Agent 扫描轨迹,寻找"困境-解决"模式 (Problem-Solution Patterns)。
- 识别困境: 找到 Agent 卡住、循环报错或产生幻觉的时刻。
- 提取策略: 识别最终是如何打破僵局的(例如:"不要依赖模糊搜索,直接构造 URL")。
- 格式化 : 生成键值对 < Dilemma , Strategy > < \text{Dilemma}, \text{Strategy} > <Dilemma,Strategy>。
- 上下文控制 : 为了防止 System Prompt 爆炸, M s t r a t \mathcal{M}_{strat} Mstrat 会强制执行数量限制。新生成的策略会与旧策略进行语义对比,仅保留高频出现或极具代表性的策略,淘汰琐碎的规则。
工具记忆 ( M t o o l \mathcal{M}_{tool} Mtool): 动态指令微调
这是对工具静态文档(Docstring)的动态补充,类似"补丁"。
-
更新时机 (Trigger) :
仅在整个父任务 (Parent Task) τ \tau τ 结束后更新。
-
输入数据 :
特定工具调用的 a t a_t at (Action) 和随后的 o t o_t ot (Observation),特别是报错信息 (Traceback) 或非预期输出。
-
更新逻辑 :
系统仅更新工具记忆中的 I d y n a m i c I_{dynamic} Idynamic (Dynamic Instruction) 部分,保持 D s t a t i c D_{static} Dstatic 不变。
- 错误归因: 分析工具调用失败的原因(例如:参数类型错误、缺少前置步骤、需要特定的 Wait 时间)。
- 生成 Tips : 将修正后的正确用法转化为自然语言提示(例如:
access_guide工具提示 "Always pass app name as dict key... otherwise TypeError")。 - 注入机制: 下次 PE Agent 准备调用该工具时,这些 Tips 会被注入到 Prompt 中作为 Constraints。
I d y n a m i c ( n e w ) ← ExtractTips ( { ( a t , o t ) ∣ a t uses Tool k } ) I_{dynamic}^{(new)} \leftarrow \text{ExtractTips}(\{ (a_t, o_t) | a_t \text{ uses Tool}_k \}) Idynamic(new)←ExtractTips({(at,ot)∣at uses Toolk})
总结
| 记忆类型 | 更新频率 | 核心驱动力 | 存储内容 (抽象度) | 解决什么问题 |
|---|---|---|---|---|
| Procedural | 高 (Sub-task 级) | Success Trajectories (成功的经验) | 具体步骤 SOP (中) | 怎么做具体的子任务 (How to do X) |
| Strategic | 低 (Task 级) | Failures & Retries (失败的教训) | 抽象原则 (高) | 如何规划、如何避免死胡同 (High-level Planning) |
| Tool | 低 (Task 级) | Execution Errors (报错与异常) | 使用技巧/Tips (低) | 如何正确调用 API (Syntax/Pre-conditions) |