精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、选题背景
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
本系统是一套面向大众点评平台的美食数据深度分析与可视化解决方案,整体采用Python技术栈进行开发实现。系统在数据采集层面运用Scrapy框架完成对大众点评网站美食店铺信息的自动化抓取,涵盖店铺名称、主营菜系、人均消费、评分详情、推荐菜品、营业时间等多维度字段,为后续分析奠定数据基础。数据处理环节借助Spark分布式计算引擎实现海量数据的清洗、转换与聚合运算,有效提升大规模数据集的处理效率。在数据分析维度上,系统构建了区域特征分析、消费者偏好挖掘、质量评价体系构建、商业价值洞察四大分析模块,通过K-means聚类、决策树算法、相关性分析等数据挖掘手段,实现对餐饮市场格局的深度透视。可视化展示层面采用Pyecharts库生成动态交互式图表,包括地理热力图、雷达图、漏斗图、词云图等多种图表形态,直观呈现餐厅分布密度、菜系受欢迎度、价格带划分、评分维度关联等分析结果。整个系统从数据获取到价值呈现形成完整闭环,既展现了大数据技术栈的整合应用能力,也为餐饮行业从业者和消费者提供了数据驱动的决策参考。
二、选题背景
这几年餐饮行业数字化转型的势头挺明显的,线上点评平台已经成了大家找餐厅、做决策的主要渠道。大众点评作为老牌的生活服务平台,上面积累了海量的用户评论和店铺信息,这些数据里头其实藏着不少有价值的消费规律和市场趋势。不过呢,目前大多数研究要么只停留在简单的数据统计层面,要么就是用传统的单机工具处理,面对动辄几万条的数据量就显得有点吃力了。再加上很多现有的分析系统功能比较单一,往往只能看看评分分布或者地理位置,缺乏从多个维度去深挖数据背后逻辑的系统性方案。所以怎么把这些分散的餐饮数据高效地整合起来,用大数据的技术手段去做深度挖掘和可视化呈现,就成了一个值得琢磨的课题,这也正好契合了当前数据分析在实际场景里落地的需求。
做这个系统的实际意义可以从几个层面来看吧。对普通消费者来说,通过分析各个区域的餐厅密度、消费水平和评分表现,能给日常聚餐或者旅游觅食提供点参考,省得盲目踩雷。对想开店的创业者而言,系统里关于菜系受欢迎度、竞争强度分析和价格带划分的结果,多少能辅助判断一下市场定位和选址方向,虽然不敢说有多权威,但至少是个数据层面的依据。从技术学习的角度来说,这个项目把Python爬虫、Spark大数据处理、数据挖掘算法和可视化技术串在一起做,对掌握完整的数据工程流程还是有帮助的。另外,系统里用的K-means聚类和决策树这些算法,在实际业务里也挺常见的,通过这个项目练练手,以后找工作面试的时候也能聊几句真实的项目经验。总的来说,就是个本科毕业设计的水平,主要还是在学习技术怎么用起来,顺便看看数据能讲出什么故事来。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
系统页面模块展示:
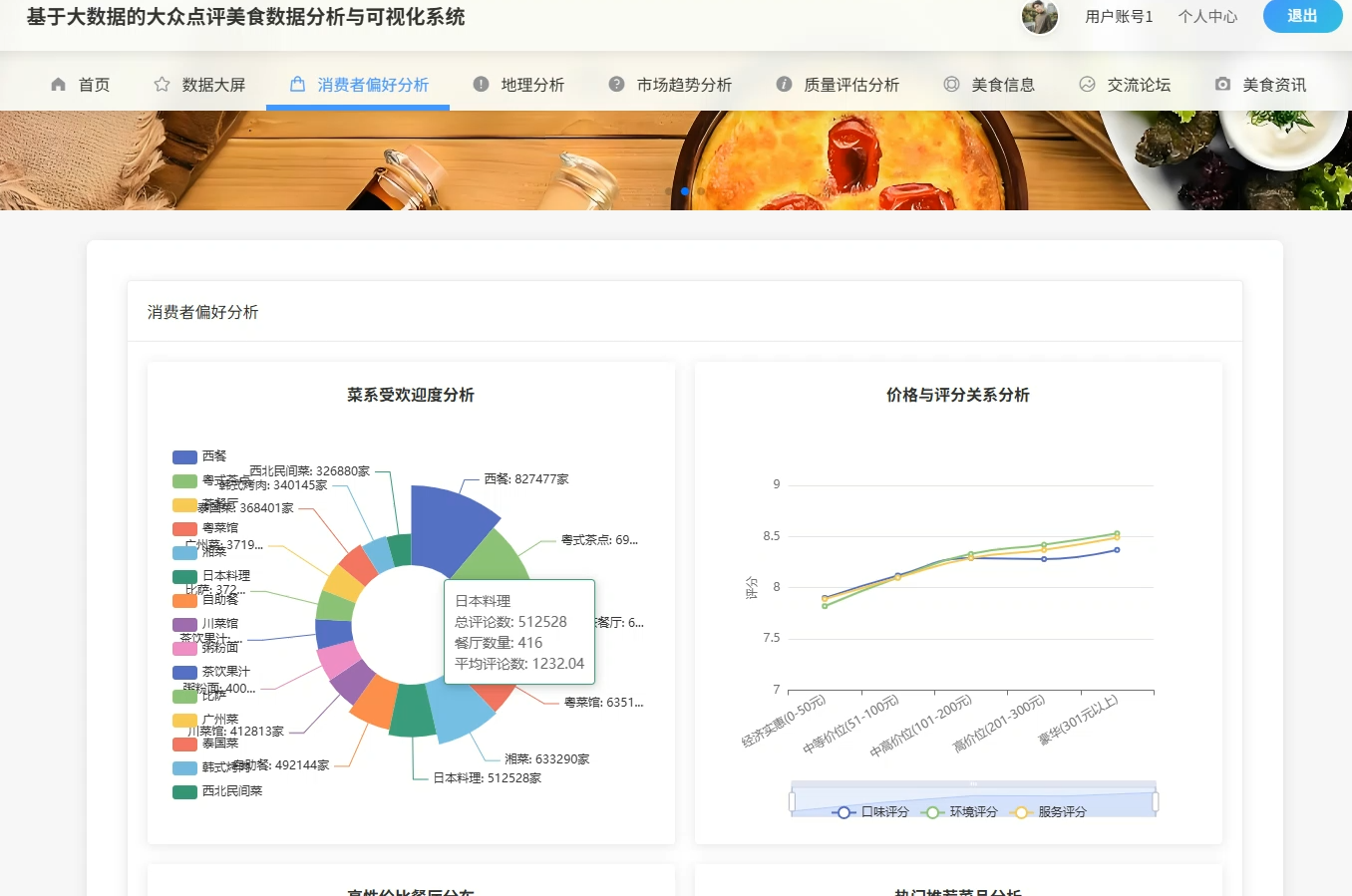
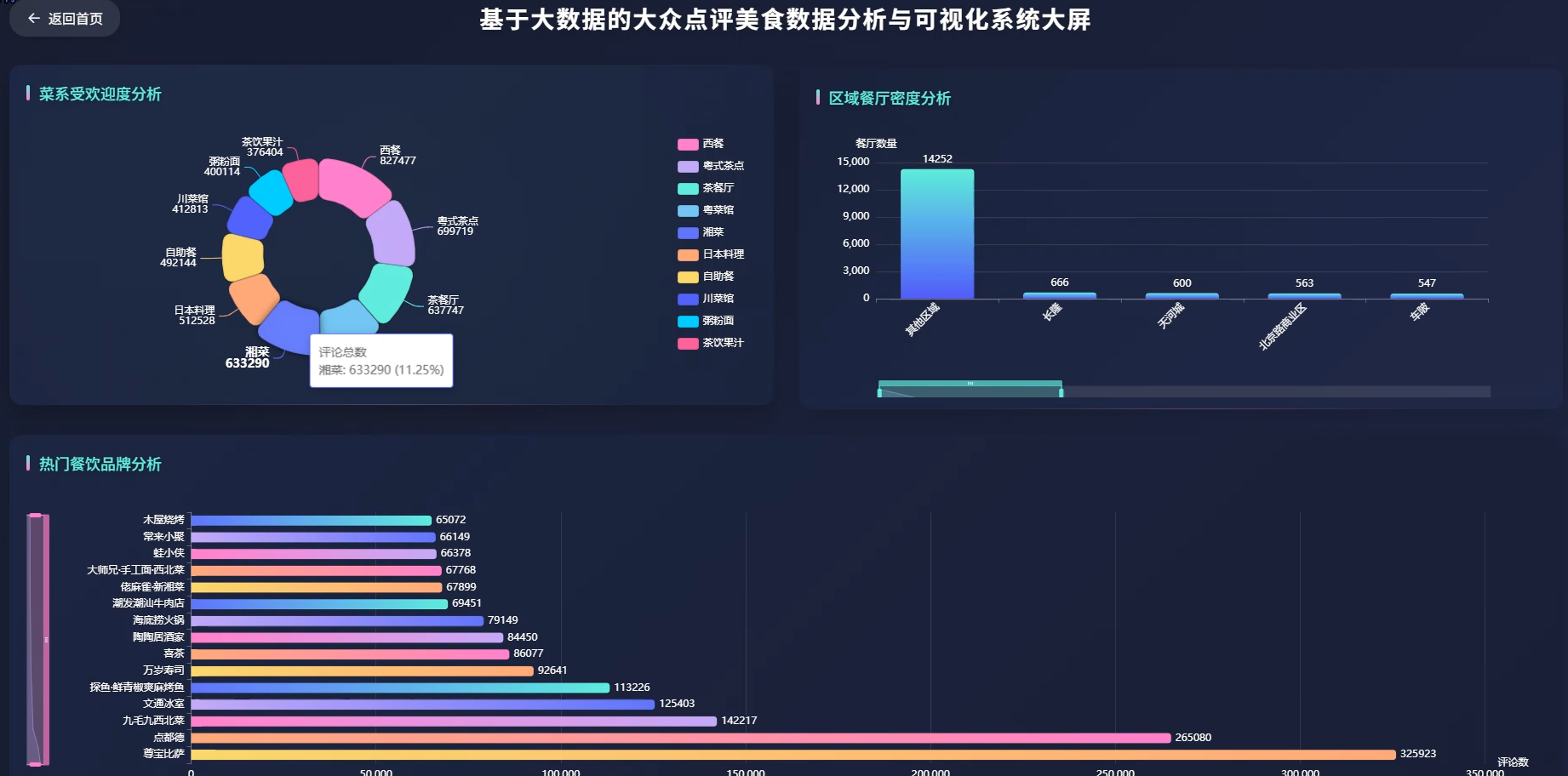
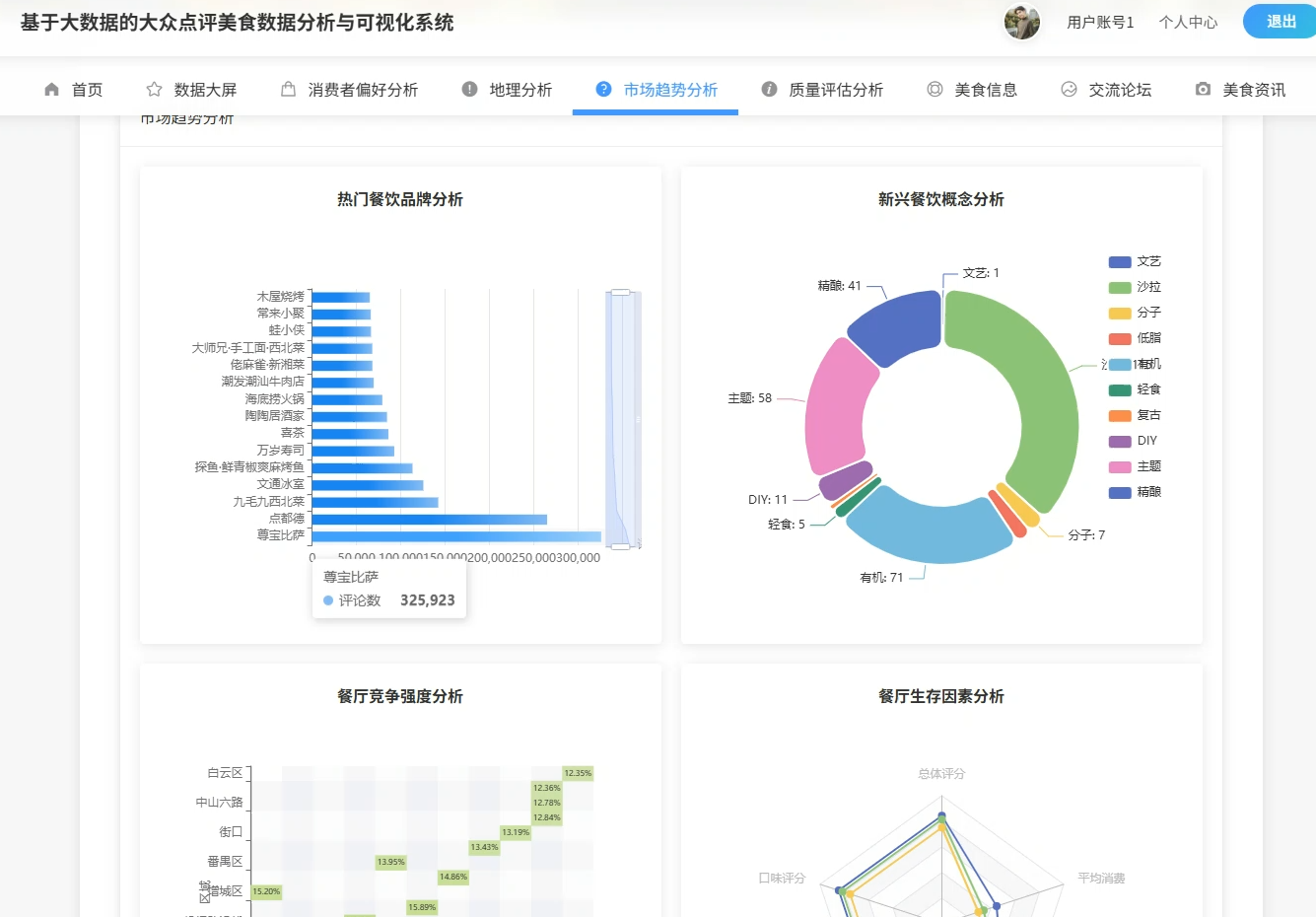
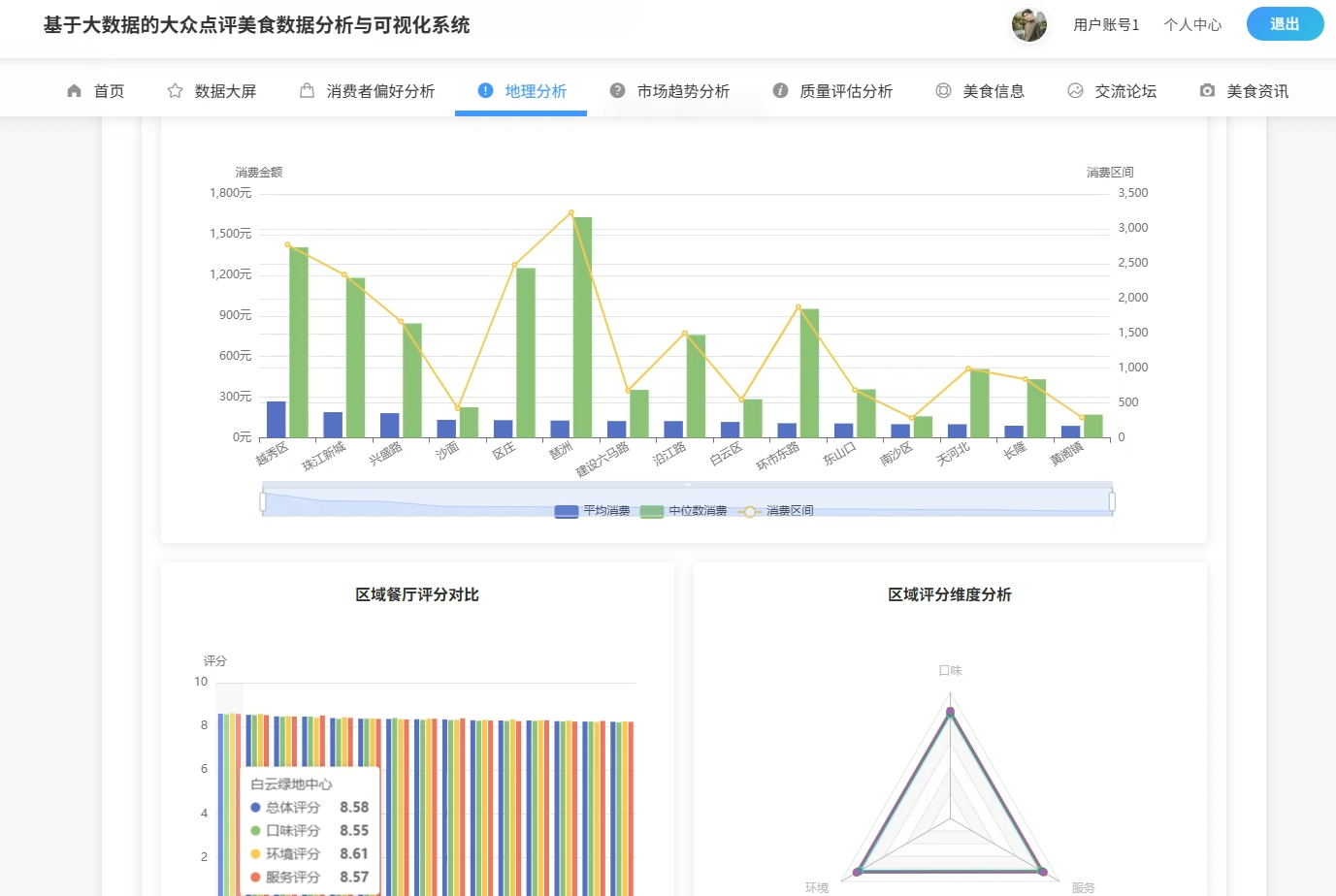
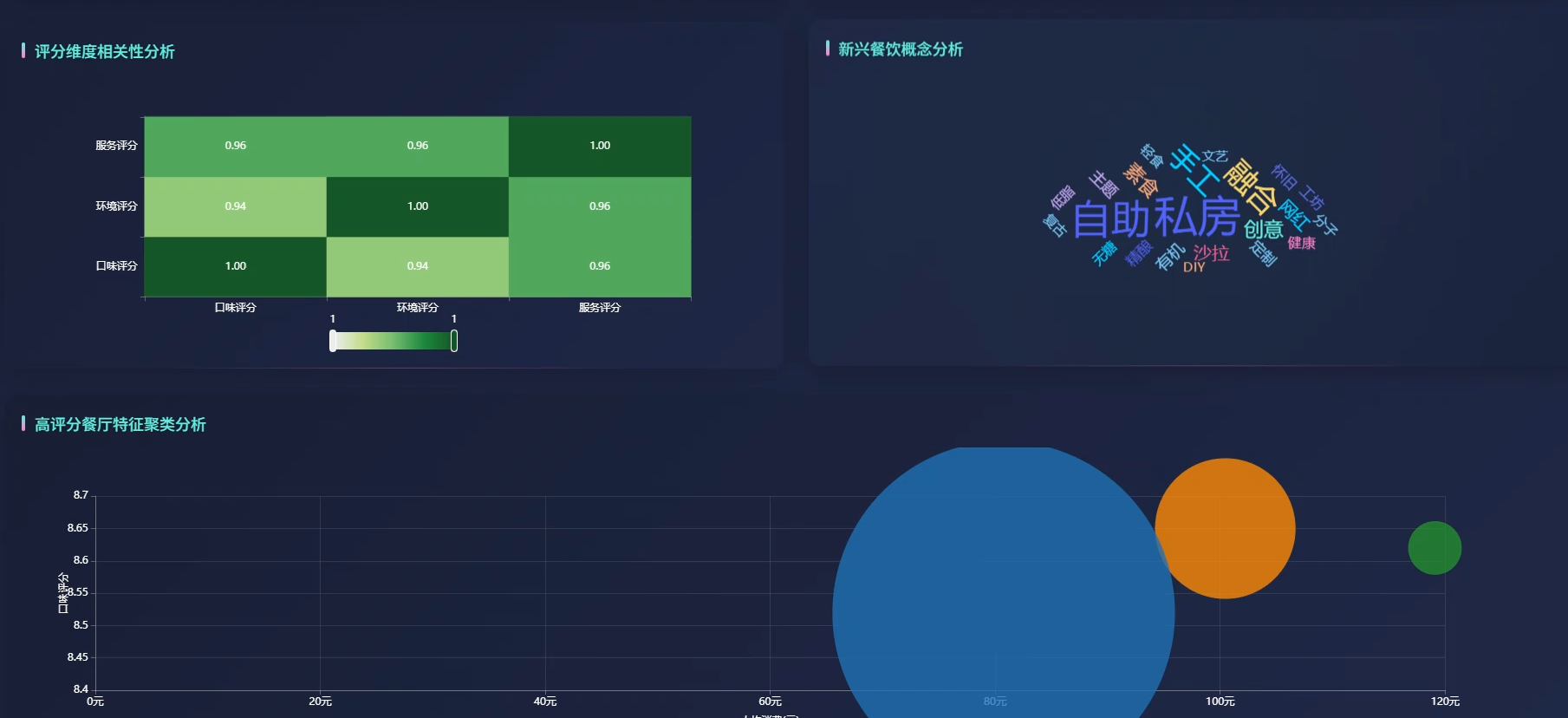
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, stddev, desc, split, explode, regexp_replace, trim, when, isnan
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.clustering import KMeans
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import ClusteringEvaluator
import jieba
import re
from collections import Counter
# 初始化SparkSession
spark = SparkSession.builder \
.appName("DianpingFoodAnalysis") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.master("local[*]") \
.getOrCreate()
# 核心功能1:区域餐厅密度与消费水平分析
def analyze_regional_features(df):
regional_stats = df.groupBy("region") \
.agg(
count("*").alias("restaurant_count"),
avg("per_capita_consumption").alias("avg_consumption"),
stddev("per_capita_consumption").alias("consumption_std"),
avg("overall_rating").alias("avg_rating"),
avg("taste_rating").alias("avg_taste"),
avg("environment_rating").alias("avg_env"),
avg("service_rating").alias("avg_service")
) \
.withColumn("density_level",
when(col("restaurant_count") > 500, "高密度")
.when(col("restaurant_count") > 200, "中密度")
.otherwise("低密度")) \
.withColumn("consumption_level",
when(col("avg_consumption") > 150, "高端消费")
.when(col("avg_consumption") > 80, "中端消费")
.otherwise("大众消费")) \
.orderBy(desc("restaurant_count"))
density_analysis = regional_stats.select("region", "restaurant_count", "density_level",
"avg_consumption", "consumption_level", "avg_rating").collect()
result_list = []
for row in density_analysis:
result_list.append({
"region": row.region,
"count": row.restaurant_count,
"density": row.density_level,
"avg_cost": round(float(row.avg_consumption), 2),
"cost_level": row.consumption_level,
"avg_score": round(float(row.avg_rating), 2)
})
return result_list
# 核心功能2:高性价比餐厅识别与聚类分析
def analyze_cost_performance(df):
processed_df = df.filter(col("per_capita_consumption").isNotNull()) \
.filter(col("overall_rating").isNotNull()) \
.withColumn("review_count_num", col("review_count").cast("int")) \
.filter(col("review_count_num") > 50) \
.withColumn("cost_performance_ratio",
col("overall_rating") / (col("per_capita_consumption") / 50 + 1)) \
.withColumn("popularity_score",
col("overall_rating") * 0.4 + col("taste_rating") * 0.3 +
(col("review_count_num") / 1000) * 0.3)
assembler = VectorAssembler(
inputCols=["per_capita_consumption", "overall_rating", "review_count_num", "cost_performance_ratio"],
outputCol="features"
)
feature_df = assembler.transform(processed_df)
scaler = StandardScaler(inputCol="features", outputCol="scaled_features", withStd=True, withMean=True)
scaled_df = scaler.fit(feature_df).transform(feature_df)
kmeans = KMeans(k=4, seed=42, featuresCol="scaled_features", predictionCol="cluster")
model = kmeans.fit(scaled_df)
clustered_df = model.transform(scaled_df)
high_value_cluster = clustered_df.groupBy("cluster") \
.agg(avg("cost_performance_ratio").alias("avg_cp")) \
.orderBy(desc("avg_cp")).first()["cluster"]
high_value_restaurants = clustered_df.filter(col("cluster") == high_value_cluster) \
.select("shop_name", "region", "main_cuisine", "per_capita_consumption",
"overall_rating", "cost_performance_ratio") \
.orderBy(desc("cost_performance_ratio")) \
.limit(20).collect()
result = []
for r in high_value_restaurants:
result.append({
"name": r.shop_name,
"region": r.region,
"cuisine": r.main_cuisine,
"cost": float(r.per_capita_consumption),
"rating": float(r.overall_rating),
"cp_ratio": round(float(r.cost_performance_ratio), 3)
})
evaluator = ClusteringEvaluator(predictionCol="cluster", featuresCol="scaled_features")
silhouette_score = evaluator.evaluate(clustered_df)
return {"restaurants": result, "silhouette": silhouette_score, "cluster_centers": model.clusterCenters()}
# 核心功能3:推荐菜品的文本挖掘与热门趋势分析
def analyze_popular_dishes(df):
all_dishes_rdd = df.filter(col("recommended_dishes").isNotNull()) \
.select("recommended_dishes", "overall_rating", "review_count") \
.rdd.map(lambda row: (row.recommended_dishes, row.overall_rating, row.review_count))
def extract_dishes(text_rating_count):
text, rating, review_cnt = text_rating_count
if not text or text.strip() == "":
return []
text = str(text).replace("推荐菜:", "").replace("等", "")
dish_list = [d.strip() for d in text.split("、") if len(d.strip()) > 1 and len(d.strip()) < 15]
results = []
for dish in dish_list:
words = list(jieba.cut(dish))
filtered_words = [w for w in words if len(w) > 1 and not w.isdigit()]
clean_dish = "".join(filtered_words)
if len(clean_dish) >= 2:
weight = float(rating) * 0.6 + (float(review_cnt) / 1000) * 0.4 if review_cnt else float(rating) * 0.6
results.append((clean_dish, (1, weight, float(rating))))
return results
dish_pairs = all_dishes_rdd.flatMap(extract_dishes)
dish_aggregated = dish_pairs.reduceByKey(lambda a, b: (a[0]+b[0], a[1]+b[1], a[2]+b[2]))
dish_stats = dish_aggregated.map(lambda x: (x[0], x[1][0], x[1][1]/x[1][0], x[1][2]/x[1][0])) \
.filter(lambda x: x[1] >= 5) \
.sortBy(lambda x: x[2], ascending=False)
top_dishes = dish_stats.take(30)
dish_combinations = all_dishes_rdd.flatMap(lambda x: [(tuple(sorted([a.strip(), b.strip()])), 1)
for a in x[0].split("、") for b in x[0].split("、")
if a.strip() != b.strip() and len(a.strip()) > 1 and len(b.strip()) > 1][:5]) \
.reduceByKey(lambda a, b: a+b) \
.filter(lambda x: x[1] >= 3) \
.sortBy(lambda x: x[1], ascending=False) \
.take(15)
final_dish_list = []
for dish, count, weighted_score, avg_rating in top_dishes:
final_dish_list.append({
"dish_name": dish,
"mention_count": count,
"weighted_score": round(weighted_score, 2),
"avg_rating": round(avg_rating, 2)
})
combo_list = [{"pair": list(combo), "co_occurrence": count} for combo, count in dish_combinations]
return {"hot_dishes": final_dish_list, "common_combinations": combo_list}六、项目文档展示

七、项目总结
这套基于Python和大数据技术的美食数据分析系统,从实际应用场景出发,围绕大众点评平台的餐饮数据构建了一套完整的分析流程。系统在设计上兼顾了技术完整性和功能实用性,通过Scrapy爬虫解决数据来源问题,借助Spark引擎提升大规模数据的处理效率,再运用聚类、分类等算法挖掘数据价值,最后用可视化手段呈现分析结果。整个技术选型和实现路径都比较贴近当前数据工程领域的实际做法,对本科阶段的技术学习和项目经验积累来说应该是有一定帮助的。
从功能覆盖来看,系统不仅实现了基础的数据统计和展示,还尝试从区域特征、消费偏好、质量评价、商业洞察等多个角度去做深度分析,虽然分析的深度和准确度肯定比不上商业级的数据分析产品,但作为毕业设计来说,至少能把大数据技术栈里的几个核心组件串起来用一遍,展示一下从数据获取到价值输出的完整能力。同时,项目过程中也暴露了一些不足,比如爬虫的稳定性还有提升空间,算法的调参也比较粗放,这些都是在后续学习和工作中可以继续深化的地方。总的来说,这个项目算是一个比较扎实的本科毕业设计,既完成了基本的任务要求,也为以后从事数据分析相关的工作打了一点基础。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖