B+树
mysql的InnoDB引擎采用b+树存储索引; 为什么采取这个数据结构,我觉得可以对比其他的树形结构,来体会它的优点。
1、为什么不选二叉树 / 红黑树?
像二叉树,红黑树(特殊的二叉树)如果数据量很多的话,树会很高;
==》 每多一层就意味着多一次磁盘 I/O 操作,这在数据库场景中是性能瓶颈。
2、为什么不选b树?
b树每个节点可以存储更多的数据,例如5阶B树可最多可以存储4个key:
B 树通过 "多路平衡" 的设计,确实大幅降低了树高,但它有两个明显缺点:
非叶子节点存数据;范围查询效率低
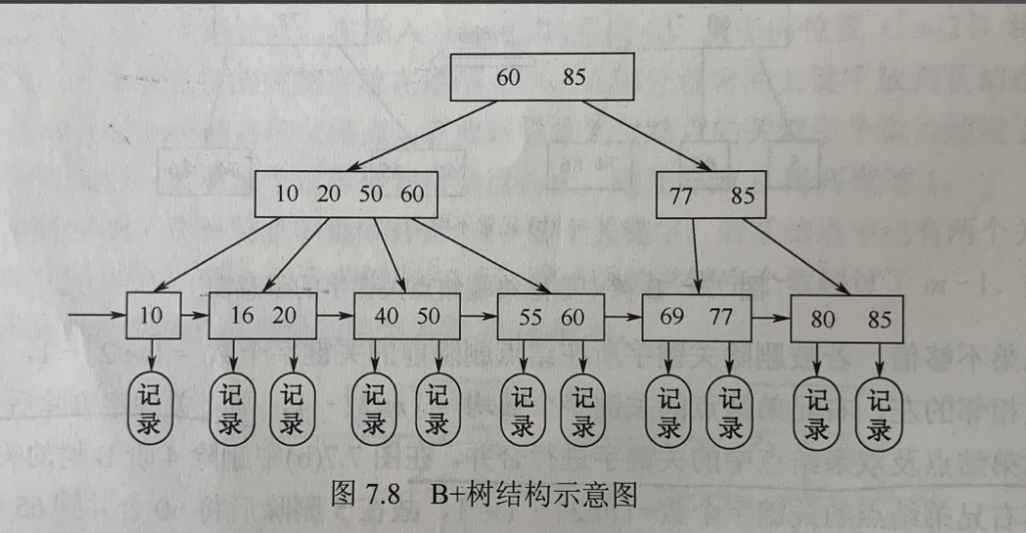
3、b+树
1) 非叶节点只存指针 :
b+树的非叶节点只有存储指针,不存存储数据,它们的作用只是为了导航找到叶子节点的数据; 这样的优点有:磁盘的读取代价比b树更低;
(因为在找树形叶子节点中数据的过程中,中间节点也会被完整加载,正因其非叶节点只存储索引。故而可以容纳更多索引键,从而减低树高,即减少IO次数)
2)叶子节点的双向链表
b+树的叶子节点是一个双向链表,我们可以在叶子节点层面上进行数据的查找扫描; 即b+树便于扫描和区间查询 。
高效场景 :执行 BETWEEN ... AND ... 或 ORDER BY 这类范围查询时,B + 树只需找到区间的起始叶子节点,然后顺着链表向后扫描即可,效率远高于 B 树。
讨论:
1、b+树它优势在于磁盘页可以存储更多的索引键**。 是否因为这样我们可以在一个节点中设计更多的索引键,这样就能压缩树高?**
==> 是的,数据库在设计时,会让一个 B+ 树节点的大小恰好等于一个磁盘页。 即你看的树高只是逻辑样态,我们最终关系的其实查找到目标值所需要的IO数。
物理层面:数据库的最小 IO 单位是「磁盘页」(通常 4KB)。每次 IO 操作,就是读取或写入一个完整的磁盘页。
逻辑层面:B + 树的一个节点,在物理上就对应一个磁盘页。所以,访问一个节点,就等于触发一次磁盘 IO。
性能层面 :我们说的「树高」,本质上就是从根节点到叶子节点需要经过的节点数量,也就是需要触发的IO 次数。