2026.2.2
本文提出一种肌肉骨骼感知(MUSA)深度学习框架,通过将头颈部CT图像配准分解为姿态校正和残余精细形变,并利用骨骼结构和软组织间不均匀形变约束,有效提升了复杂头颈部区域图像配准的准确性和解剖学合理性,兼容多种网络架构,适用于主体内和主体间配准任务。
Title 题目
01
Usculo-Skeleton-Aware (MUSA) deep learning for anatomically guided head-and-neck CT deformable registration
肌肉骨骼感知(MUSA)深度学习用于解剖引导的头颈部CT可变形图像配准
文献速递介绍
02
可变形图像配准(DIR)在医学图像分析中至关重要,但基于深度学习的DIR(DL-DIR)在头颈部CT图像配准中面临挑战。头颈部区域形变幅度大、自由度高,且是肌肉骨骼运动与软组织形变复杂叠加的结果,超出传统均匀平滑正则化的描述能力。传统配准常采用分层或多分辨率策略,而DL-DIR中有些方法采用显式多分辨率,有些则依赖神经网络固有的层次结构。现有深度学习方法在头颈部CT配准中缺乏针对其独特解剖特性的专门设计。本文提出了一种肌肉骨骼感知(MUSA)框架,将头颈部形变分解为姿态校正和残余精细形变,通过两个网络顺序处理:Pos-Net(姿态校正网络)使用MUSA损失函数在高弯曲能量正则化下鼓励骨骼结构局部近似仿射运动,Ref-Net(精细化网络)处理残余精细形变。MUSA框架结合显式多分辨率策略和骨骼与软组织间不均匀形变约束,旨在实现更解剖学合理的形变估计和更高的配准准确性。
Aastract摘要
02
深度学习可变形图像配准(DL-DIR)在多个解剖部位的准确性已超越耗时的非深度学习方法。然而,DL-DIR在组织异质且形变较大的区域,如头颈部CT图像中,仍然面临挑战,许多现有最先进的方法难以捕捉大范围、解剖学上合理的形变。这表明头颈部复杂的形变可能超越了单一网络结构或均匀平滑正则化的能力。为解决头颈部区域多尺度肌肉骨骼运动和软组织形变相结合的挑战,我们提出了肌肉骨骼感知(MUSA)框架,通过显式多分辨率策略和骨骼结构与软组织之间不均匀形变约束,解剖学地引导DL-DIR。该方法将复杂形变分解为整体姿态变化和残余精细形变,可适应主体间和主体内配准。结果表明,MUSA框架能持续提升配准准确性,更重要的是,显著提高了各种网络架构下形变的合理性。
Method 方法
03
本文提出的MUSA框架旨在解决头颈部CT配准的复杂性。首先,MUSA损失函数扩展了标准的MSE加弯曲能量(BE)损失,通过对骨骼区域施加更大的BE正则化(参数α控制),鼓励骨骼内部的局部仿射运动,实现空间变异正则化。当α=1时,MUSA损失退化为标准损失。MUSA框架采用两阶段分解方法,如图1所示,将头颈部复杂形变分解为肌肉骨骼运动导致的整体姿态变化和残余软组织形变。第一阶段,Pos-Net(姿态校正网络)接收低分辨率图像作为输入,并使用MUSA损失进行训练,以校正姿态。第二阶段,Ref-Net(精细化网络)接收全分辨率图像和第一阶段形变后的图像作为输入,并使用标准损失函数处理残余精细形变。最终形变是两阶段形变的组合。MUSA损失依赖于骨骼结构的分割,通过深度学习方法(如三阶段粗到细定位分割网络和形状约束分割网络)获得,仅在Pos-Net训练期间使用。该框架兼容多种主流网络架构,包括基于U-Net的(VoxelMorph、Res-U-Net)、具有大有效感受野的(TransMorph、LK-U-Net)以及显式多分辨率模型(LapIRN、Dual-PR-Net)。实验使用了来自TCIA的380张图像构建主体间数据集,以及7名患者的院内主体内数据集。评估指标包括目标配准误差(TRE)、Dice分数、95百分位Hausdorff距离(HD95)和平均对称表面距离(ASD),并分析了形变正则性和合理性(雅可比行列式、形变幅度分布)。超参数λ和α经过独立调优,最终选择α=1000。此外,还进行了与Dice损失的对比实验,以突出MUSA损失的独特贡献。
Discussion讨论
04
本文讨论了可变形配准评估的固有挑战,包括未知真实形变和地标标注的局限性。尽管如此,MUSA框架在TRE上的显著统计学改进,特别是在主体内数据集上更大的效应量,证实了其有效性。MUSA通过分而治之的策略,将复杂头颈部形变分解为整体姿态变化和残余精细形变,有效地近似肌肉骨骼运动和软组织形变。Pos-Net中的空间变异正则化使得骨骼形变得以合理保留,为Ref-Net提供了更好的初始对齐,避免了局部最小值,从而生成更合理的形变。MUSA框架的性能提升部分归因于其扩大了网络的有效感受野,迫使网络学习骨骼内部的远程依赖关系。MUSA框架也提供了更高的透明度和可解释性,允许对配准过程中出现的问题进行阶段性识别和纠正。与Dice损失相比,MUSA损失通过正则化形变而非直接强制轮廓匹配,提升了形变合理性,而非仅是分割匹配。实验结果强调了显式多分辨率策略在深度学习DIR中处理大形变的重要性,特别是在头颈部这种复杂区域,其作用可能超越单纯的网络架构改进。MUSA方法对主体间和主体内配准均适用,虽然针对纯粹主体内配准任务可能需要更严格的刚性约束。研究的局限性包括简化的解剖学先验(仅骨骼和软组织)、骨骼分割精度对性能的影响、金属伪影和口腔张合引起的拓扑结构变化等未解决的问题。
Conclusion结论
05
本研究提出了一种肌肉骨骼感知(MUSA)框架,用于基于深度学习的可变形图像配准,旨在解决头颈部CT配准的挑战性任务。所提出的Pos-Net + Ref-Net框架将复杂的头颈部形变分解为整体姿态变化和残余精细形变,并依次进行处理。该框架在各种网络架构中均表现出有效性,持续提高了配准的准确性和形变合理性。我们的实验强调了在头颈部CT配准中,显式多分辨率建模和解剖学引导对于确保解剖学合理形变的重要性。
Results结果
06
姿态校正结果显示,与两阶段多分辨率基线的第一阶段相比,MUSA框架的Pos-Net能更有效地调整运动图像姿态以匹配固定图像,同时确保骨骼结构未发生不切实际的形变(图4)。定量结果方面,MUSA框架在所有测试架构上均持续显著降低了目标配准误差(TRE),特别是在低容量模型上效果更明显。主体间数据集的TRE改进具有统计学意义(p<0.0001/3)。HD95指标在主体间数据集上也有统计学上的显著改善,表明MUSA能减少轮廓对齐中的离群误差。然而,Dice分数和ASD的提升幅度较小,不具有普遍统计学意义。定性结果(图7)进一步证实,单阶段方法在下颌、下巴和鼻子等区域存在明显配准误差,而MUSA方法在所有网络架构上均生成了视觉上更一致、更合理的形变图像,尤其在捕捉头部旋转等姿态变化方面表现更优。形变合理性分析(图9)表明,MUSA损失并未导致折叠增加或SDlog|JÏ•|显著变化,且雅可比行列式图显示MUSA方法减轻了骨骼结构中不切实际的扩张和收缩,使其值更接近于1。有效感受野(ERF)分析(图10和图11)揭示,MUSA损失能扩大网络的ERF,尤其在骨骼区域,有助于网络考虑更多的解剖学上下文。与Dice损失的对比实验表明,Dice损失虽能提高骨骼Dice分数,但对TRE和形变合理性无显著改善,而MUSA损失则侧重于提升形变合理性和降低TRE。
Figure 图
07
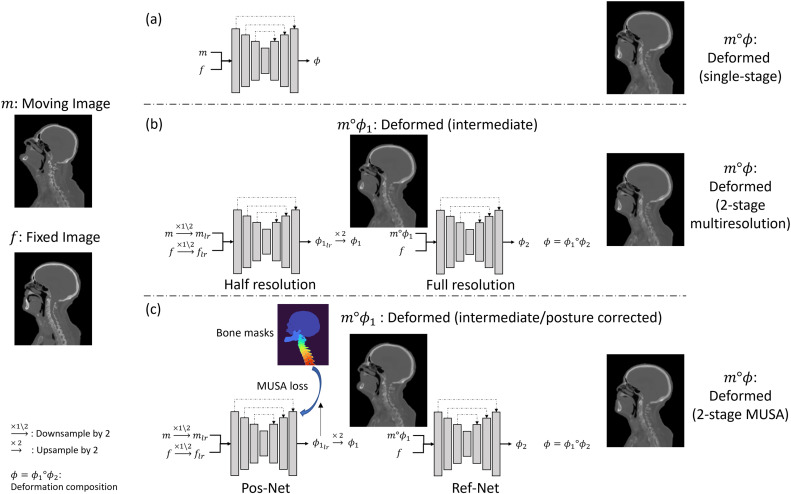
图1. 提出的MUSA配准框架(c)和基线(a, b)。MUSA框架(c)采用两阶段方法,利用两级图像金字塔进行显式多分辨率设置。在第一阶段,Pos-Net以低分辨率图像对(mlr和flr)作为输入,并使用骨骼分割计算的MUSA损失进行训练。第一阶段形变(Ï•1)将运动图像(m)形变为姿态校正后的形变图像(m∘ϕ1)作为中间状态。在第二阶段,Ref-Net以全分辨率图像对(m∘ϕ1和f)作为输入,并预测残余形变(Ï•2),采用标准均匀平滑正则化。最终形变是两阶段的组合(Ï•=Ï•1∘ϕ2),最终形变图像是(m∘ϕ)。两阶段多分辨率基线(b)与两阶段MUSA框架类似,只是两个阶段都使用均匀平滑正则化。单阶段基线(a)直接在全分辨率图像对上预测形变,采用均匀平滑正则化。图中神经网络可以采用大多数为基于深度学习的DIR设计的架构。
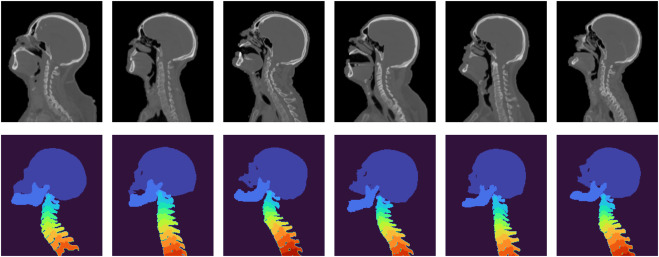
图2. 用于MUSA损失计算的头颈部CT图像及其相应骨骼分割的示例。第一行显示了冠状面CT图像的中心切片。第二行显示了使用最大强度投影(MIP)渲染的骨骼分割。
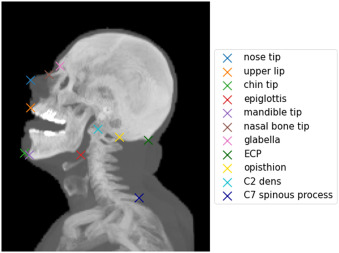
图3. 用于目标配准误差(TRE)评估的11个标注地标的示例。地标叠加在通过最大强度投影(MIP)渲染的CT图像上。
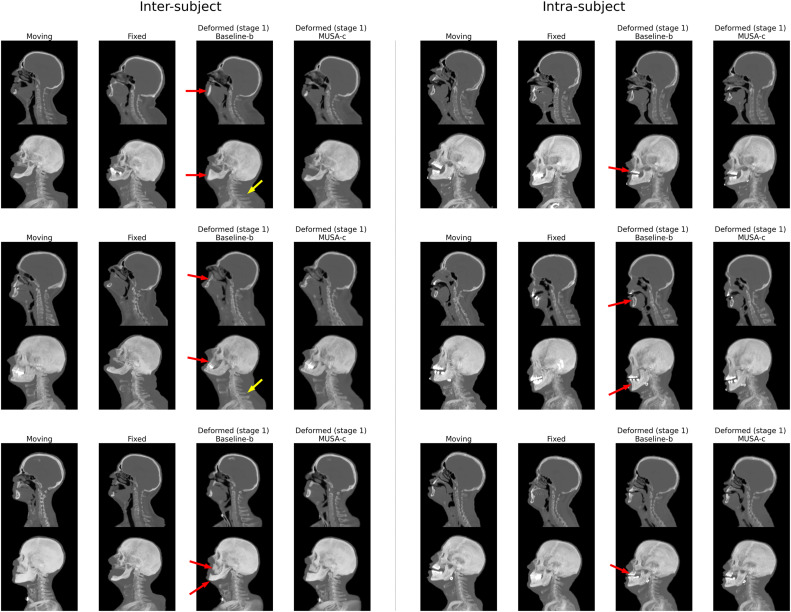
图4. 使用提出的MUSA损失从Pos-Net获得的姿态校正结果。左右面板分别展示了主体间和主体内配准的三个示例案例结果。对于每个案例,显示了运动图像、固定图像、两阶段多分辨率基线(b)的第一阶段形变图像和MUSA方法(c)的第一阶段形变图像。同时呈现了冠状面的中心切片和最大强度投影(MIP)渲染。
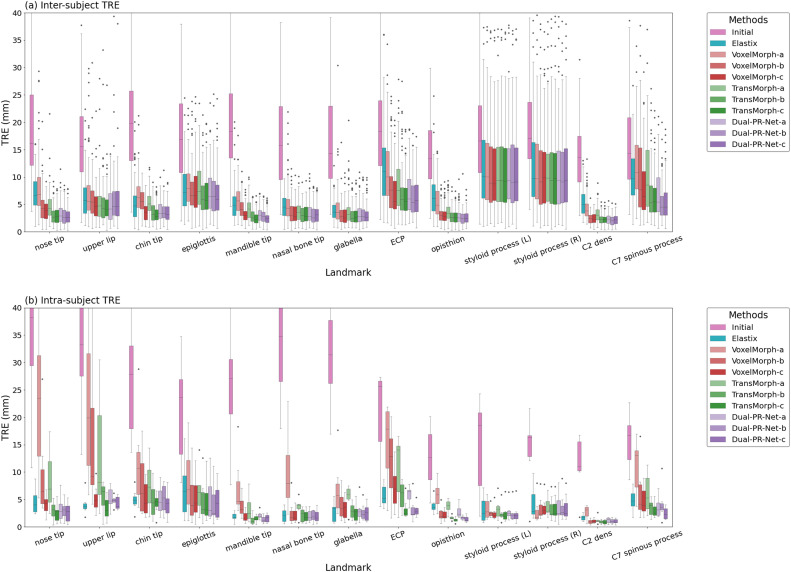
图5. 主体间(5a)和主体内(5b)配准中不同地标的目标配准误差(TRE)箱线图。由于空间限制,展示了VoxelMorph、TransMorph和Dual-PR-Net三种代表性网络架构。图例中的字母后缀a/b/c表示三种比较配置:(a)单阶段配准,(b)两阶段多分辨率配准,和(c)两阶段MUSA配准。由于在主体间配准中,左右茎突对所有方法都表现出过高的TRE,因为这些结构过于精细,无法被配准算法捕获。因此,它们被排除在平均TRE计算之外,以避免偏差。
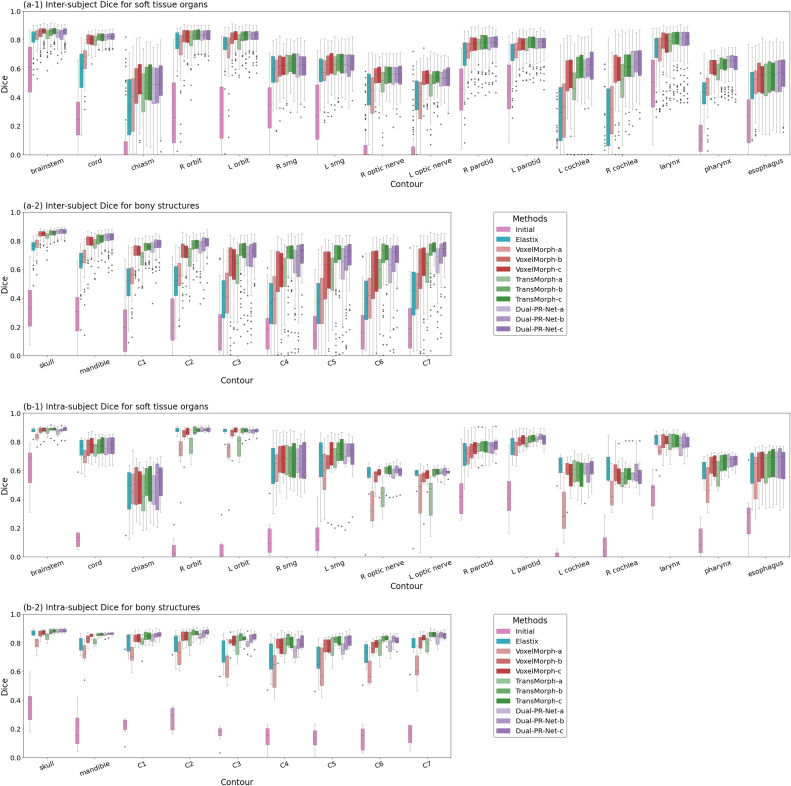
图6. 不同解剖结构的Dice分数箱线图。(6a-1/6a-2)显示主体间结果,(6b-1/6b-2)显示主体内结果。软组织器官(6a-1/6b-1)和骨骼结构(6a-2/6b-2)分别显示在不同的图中。由于空间限制,展示了VoxelMorph、TransMorph和Dual-PR-Net三种代表性网络架构。图例中的字母后缀a/b/c表示三种比较配置:(a)单阶段配准,(b)两阶段多分辨率配准,和(c)两阶段MUSA配准。
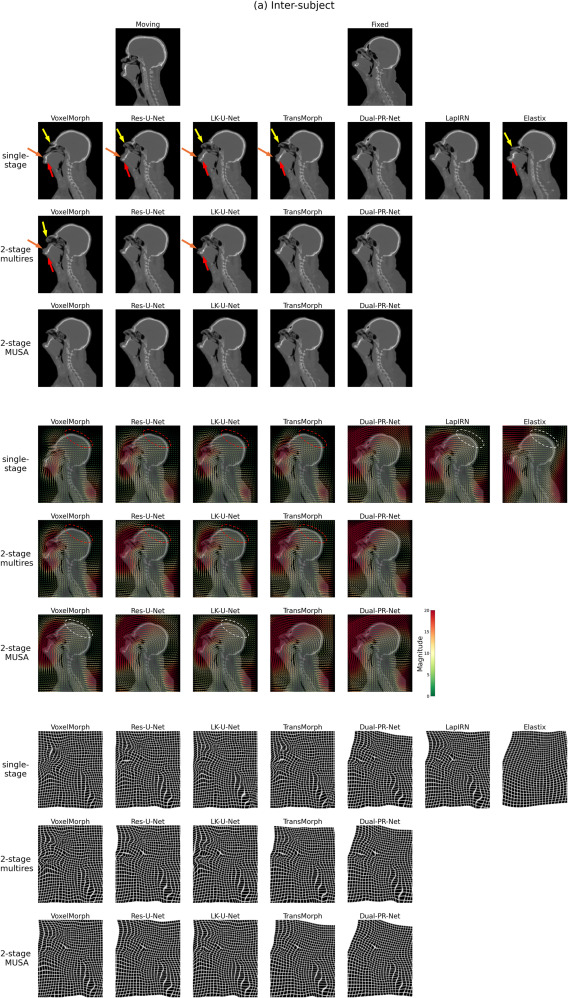
图7a. 主体间配准的定性结果。两阶段MUSA配准结果与单阶段基线和两阶段多分辨率基线进行比较。显示了冠状面的中心切片,因为在头顶到脚底(SI)和前后(AP)方向上存在大部分形变。顶部显示运动图像和固定图像,随后是形变图像、形变矢量场图和形变网格图。形变图像中的箭头突出显示配准错误。矢量场图中的虚线椭圆突出显示头部旋转(俯仰)差异明显的感兴趣区域。具体来说,红色椭圆表示未能恢复旋转运动,而白色椭圆表示运动幅度被低估。最后三个模型(即Dual-PR-Net、LapIRN和Elastix)具有显式多分辨率建模。

图7b. 主体内配准的定性结果。两阶段MUSA配准结果与单阶段基线和两阶段多分辨率基线进行比较。显示了冠状面的中心切片,因为在头顶到脚底(SI)和前后(AP)方向上存在大部分形变。顶部显示运动图像和固定图像,随后是形变图像、形变矢量场图和形变网格图。形变图像中的箭头突出显示配准错误。矢量场图中的虚线椭圆突出显示头部旋转(俯仰)差异明显的感兴趣区域。具体来说,红色椭圆表示未能恢复旋转运动,而白色椭圆表示运动幅度被低估。最后三个模型(即Dual-PR-Net、LapIRN和Elastix)具有显式多分辨率建模。
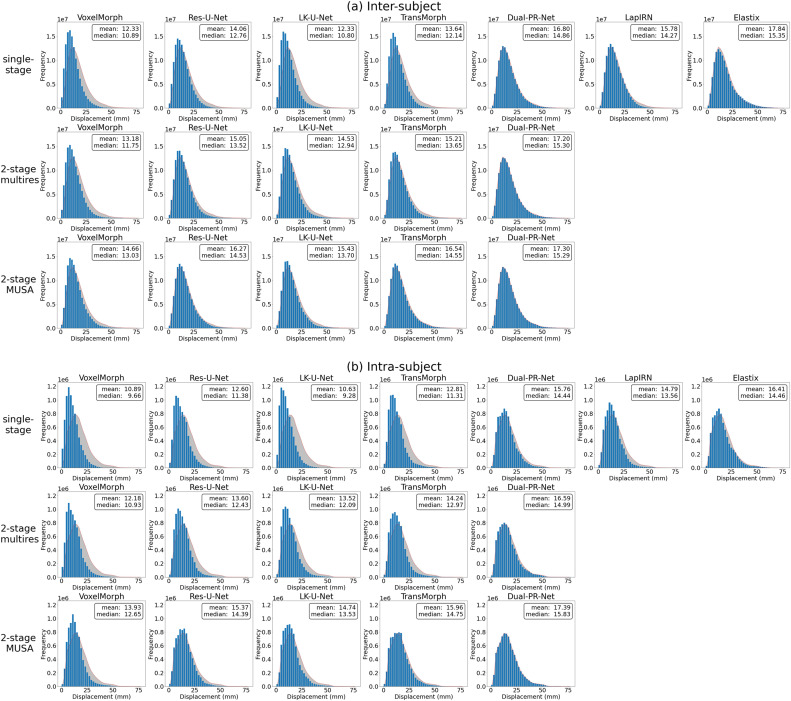
图8. (8a)主体间和(8b)主体内配准的形变幅度直方图。这些直方图是从测试集中的所有形变矢量场生成的,仅考虑身体掩膜内的形变。选择使用Dual-PR-Net架构的两阶段MUSA方法作为参考,其直方图轮廓以红色虚线和灰色阴影显示以突出差异。每个子图的右上角显示了整个形变幅度分布的平均值和中位值。三行分别对应于单阶段配准、两阶段多分辨率方法和两阶段MUSA方法。最后三个模型(即Dual-PR-Net、LapIRN和Elastix)具有显式多分辨率建模。
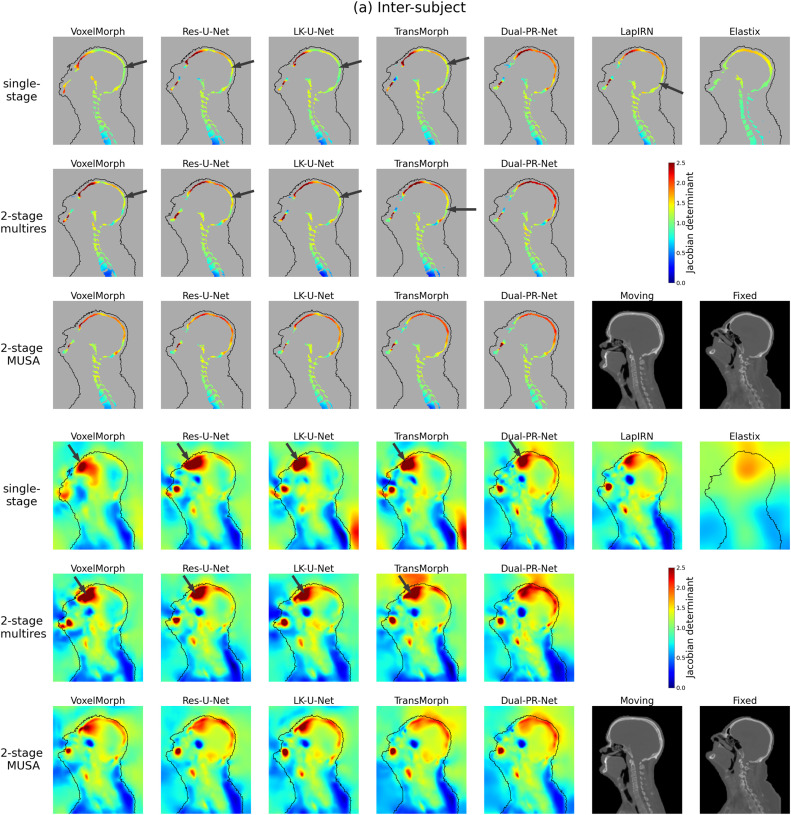
图9a. 形变在主体间配准中的雅可比行列式图。展示了与图7相同的案例。显示了冠状面的中心切片。在顶部面板中,地图用形变图像的骨骼掩膜进行遮罩。在底部面板中,显示了带有形变图像身体轮廓的完整雅可比行列式图。箭头突出显示不合理的体积变化。最后三个模型(即Dual-PR-Net、LapIRN和Elastix)具有显式多分辨率建模。
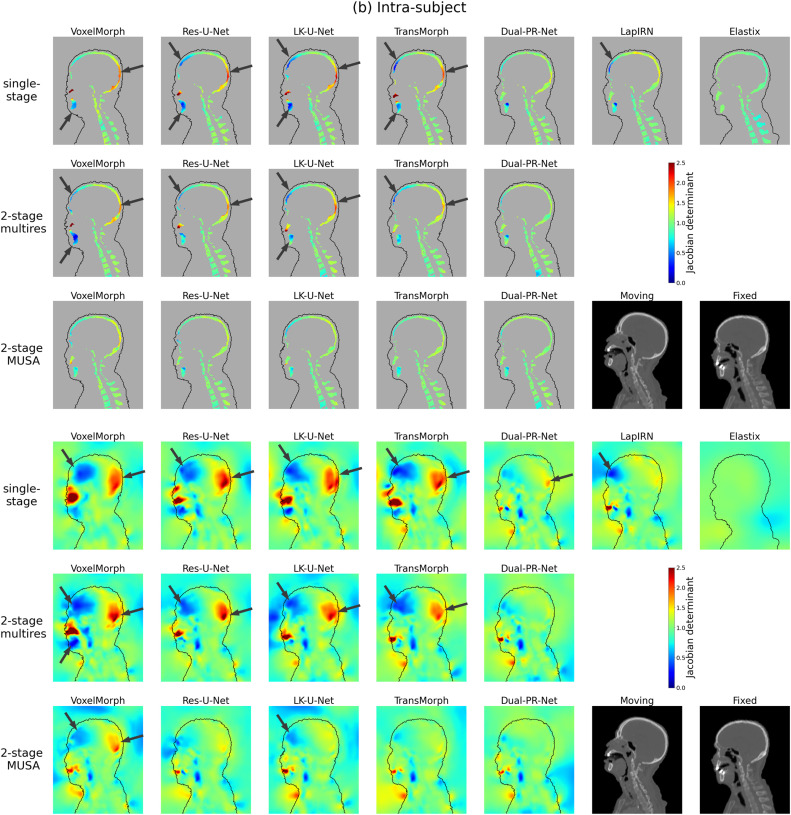
图9b. 形变在主体内配准中的雅可比行列式图。展示了与图7相同的案例。显示了冠状面的中心切片。在顶部面板中,地图用形变图像的骨骼掩膜进行遮罩。在底部面板中,显示了带有形变图像身体轮廓的完整雅可比行列式图。箭头突出显示不合理的体积变化。最后三个模型(即Dual-PR-Net、LapIRN和Elastix)具有显式多分辨率建模。
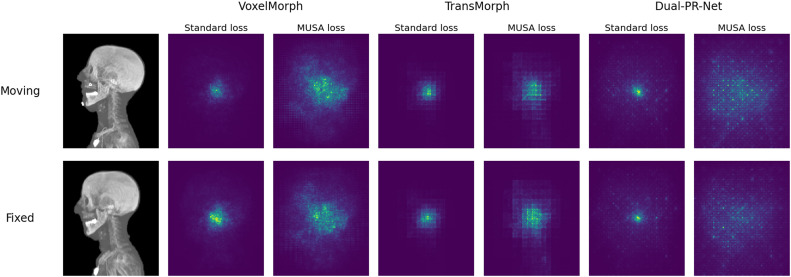
图10. 提出的MUSA损失对有效感受野(ERFs)的影响。以VoxelMorph、TransMorph和Dual-PR-Net为例展示。对于每种架构,ERF是为两阶段多分辨率方法(标准损失)和两阶段MUSA方法(MUSA损失)中使用的第一阶段网络计算的。ERF计算的探测点设置在形变场的中心。两行分别显示了反向传播到运动图像和固定图像的结果。ERF可视化采用沿冠状面的最大强度投影(MIP)渲染。

图11. 以VoxelMorph和TransMorph为例,展示了MUSA损失(公式(5))中不同α值对应的有效感受野(ERFs)。探测点设置在固定图像中头顶部的颅骨掩膜内。显示了对应于运动图像的ERF。固定图像的结果类似。ERF可视化采用沿冠状面的最大强度投影(MIP)渲染。
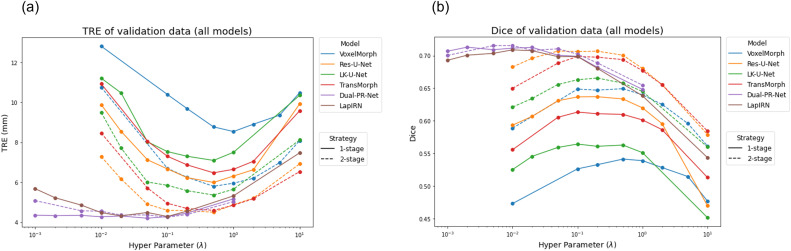
图A1. 实验中使用的所有单阶段(实线)和两阶段(虚线)基线在公式(3)中不同Î>>值下的验证数据(a) TRE和(b) Dice分数。
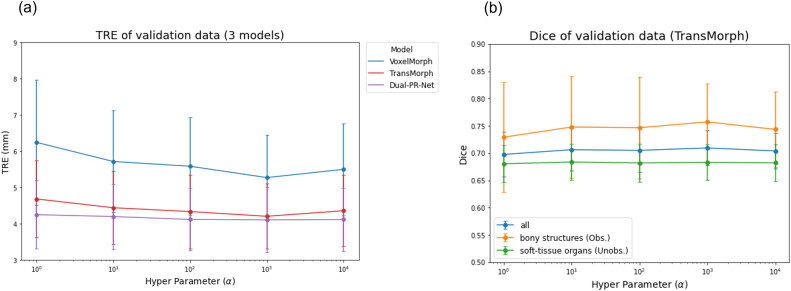
图A2. (a) MUSA损失(公式(5))中不同α值下,VoxelMorph、TransMorph和Dual-PR-Net这三个代表性模型的验证数据TRE。(b) MUSA损失中不同α值下,TransMorph的验证数据Dice分数。三条曲线分别显示了所有结构、已观察骨骼结构和未观察软组织器官的Dice分数。请注意,两图中每条曲线最左侧的点(即α=1)对应于使用标准损失函数(公式(3))训练的两阶段多分辨率基线(即基线(b))。
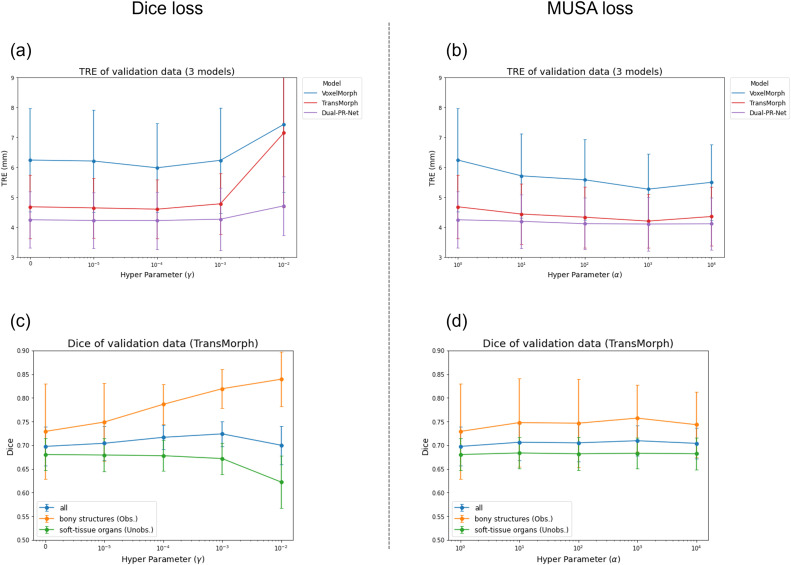
图B1. 给定Dice损失中不同γ值和MUSA损失中不同α值的验证数据的TRE和Dice分数。(a) Dice损失中不同γ值的TRE,(b) MUSA损失中不同α值的TRE,(c) Dice损失中不同γ值的Dice分数,(d) MUSA损失中不同α值的Dice分数。请注意,每条曲线最左侧的点(即Dice损失中γ=0或MUSA损失中α=1)对应于使用标准损失函数(公式(3))训练的两阶段基线。
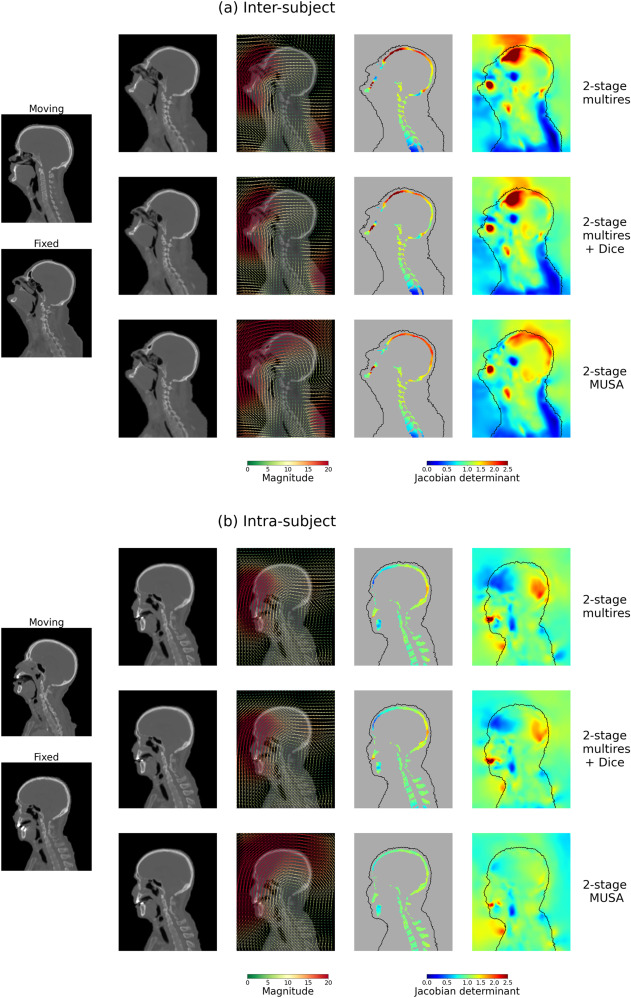
图B2. 为了展示MUSA损失和Dice损失之间的区别,我们比较了两阶段多分辨率基线、两阶段Dice损失基线和提出的两阶段MUSA方法。展示了与图7和图9中相同的案例。定性配准结果(类似于图7)包括形变图像和形变矢量场图。雅可比行列式图(类似于图9)也一并展示。所有实验均使用TransMorph架构。