本文部分内容为GPT问答生成, 肯定有错漏的地方,人老体衰,还请轻拍指正~~
文章目录
- 一、LLMUnity中脚本的继承关系
- [二、LLMUnity中RAG search的种类](#二、LLMUnity中RAG search的种类)
-
-
- [1、 LLM 检索技术对比:SimpleSearch vs. DBSearch vs. DuckDB向量搜索](#1、 LLM 检索技术对比:SimpleSearch vs. DBSearch vs. DuckDB[向量搜索])
- [2、 核心结论](#2、 核心结论)
-
- [三、普通数据库 VS 列数据库 VS 向量数据库](#三、普通数据库 VS 列数据库 VS 向量数据库)
-
-
- [1、数据库技术大比拼:普通行式 vs. 分析型列式 vs. 向量数据库](#1、数据库技术大比拼:普通行式 vs. 分析型列式 vs. 向量数据库)
-
- [四、核心选型结论(检索组件 + 数据库双层维度)](#四、核心选型结论(检索组件 + 数据库双层维度))
-
-
- [1、LLM 检索组件选型:按场景定方案,拒绝过度设计](#1、LLM 检索组件选型:按场景定方案,拒绝过度设计)
- [2、AI 应用底层数据库选型:按核心需求选类型,兼顾场景拓展性](#2、AI 应用底层数据库选型:按核心需求选类型,兼顾场景拓展性)
-
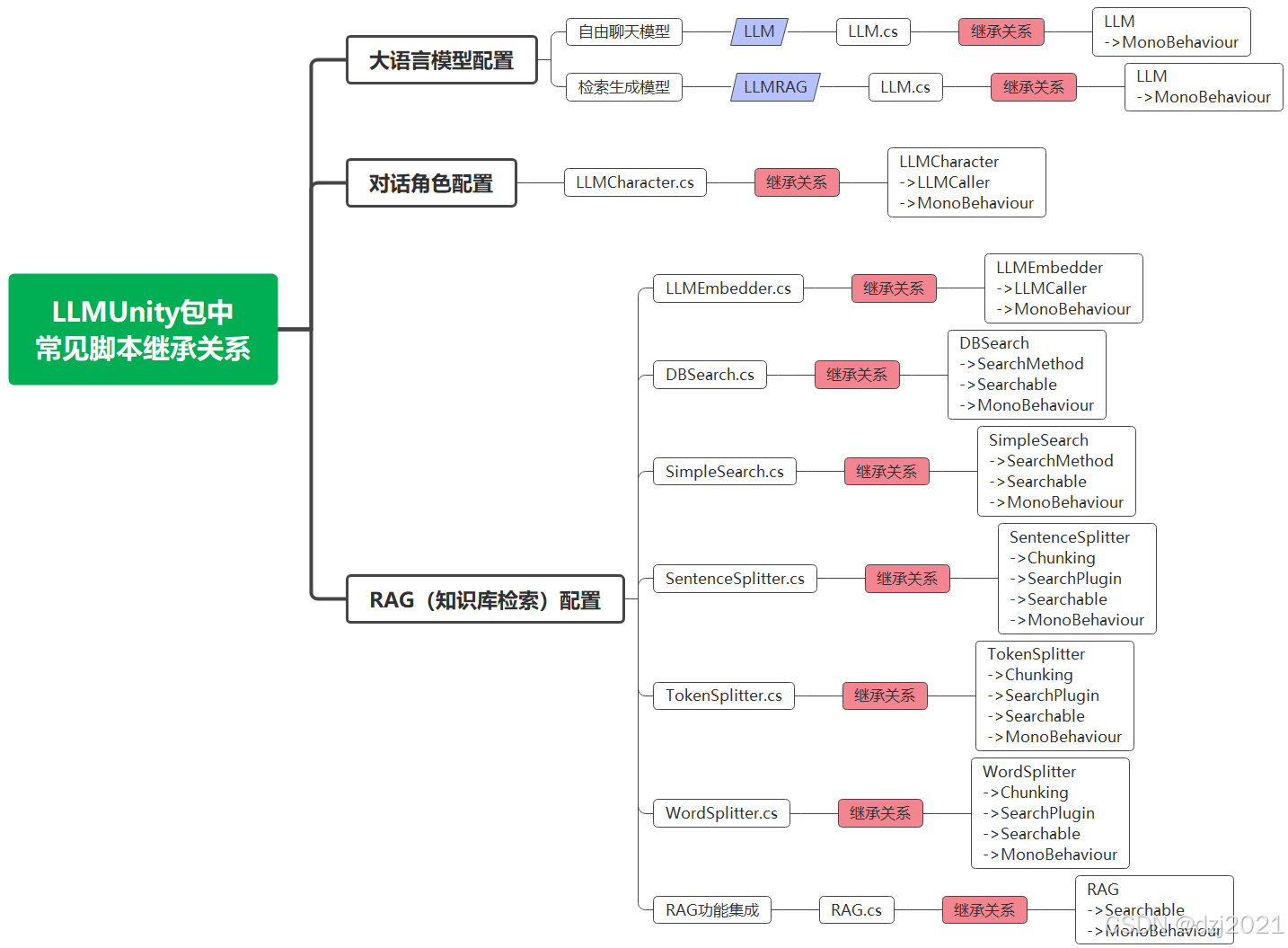
一、LLMUnity中脚本的继承关系
二、LLMUnity中RAG search的种类
1、 LLM 检索技术对比:SimpleSearch vs. DBSearch vs. DuckDB向量搜索
在构建 RAG(检索增强生成)系统或 AI NPC 时,选择合适的检索组件至关重要。下表对比了 LLMUnity 的原生组件与目前流行的 DuckDB 方案。
| 维度 | SimpleSearch.cs (原生) | DBSearch.cs (原生) | DuckDB + VSS (进阶方案) |
|---|---|---|---|
| 算法原理 | 暴力搜索 (线性扫描) | ANN (近似最近邻/HNSW) | 向量化 HNSW (C++ 级优化) |
| 检索性能 | O ( N ) O(N) O(N):随数据量线性变慢 | O ( log N ) O(\log N) O(logN):大规模下极快 | 极快:利用 CPU SIMD 指令集加速 |
| 结果准确度 | 100% 准确 (绝对最优解) | 近似准确 (存在极小误差) | 近似准确 (精度/速度可调) |
| 建议数据量 | < 1,000 条片段 | 1,000 ~ 100,000 条 | 1,000 ~ 1,000,000+ 条 |
| 内存管理 | 向量常驻内存,占用较小 | 索引和向量常驻内存,占用较大 | 灵活,支持磁盘缓存和分页加载 |
| 逻辑过滤 | 不支持:仅语义匹配 | 不支持:仅语义匹配 | 极强:支持标准 SQL (WHERE/AND) |
| 持久化方式 | 二进制/JSON 序列化 | 专用索引文件 (.zip/.bin) | 标准数据库文件 (.db) |
| 适用场景 | 简单 NPC 对话、小型原型演示 | 中大型世界观、长篇百科检索 | 专业 RAG 应用、复杂逻辑游戏系统 |
2、 核心结论
结合实操落地场景,补充3类检索组件的选型优先级和避坑点,少走弯路:
-
SimpleSearch:适合"小而精"的场景。像是一页页翻书,虽然慢但保证不漏掉任何信息。
⚠️ 避坑:不要用于1000条以上数据,否则会严重影响LLM响应速度,降低用户体验。
-
DBSearch:适合"大而快"的场景。通过预建索引实现毫秒级响应,是处理海量文本的工业级标准。
⚠️ 避坑:内存敏感场景慎用(如嵌入式设备),10万条以上建议定期清理无效索引,减少内存占用。
-
DuckDB:适合"复杂而专业"的场景。不仅拥有 DBSearch 的速度,还能通过 SQL 实现混合搜索(例如:只搜特定章节、特定角色的记忆),是目前本地 RAG 系统的最佳实践。
✅ 优势:兼顾速度、灵活性和可扩展性,可无缝对接LLMUnity,适合从原型快速迭代到生产级应用。
三、普通数据库 VS 列数据库 VS 向量数据库
1、数据库技术大比拼:普通行式 vs. 分析型列式 vs. 向量数据库
在构建现代 AI 应用(如 RAG 系统)时,理解这三种数据库的差异是技术选型的关键。
| 维度 | 普通数据库 (行式 / OLTP) | 分析型数据库 (列式 / OLAP) | 向量数据库 (Vector DB) |
|---|---|---|---|
| 核心定位 | 面向事务处理,解决高频单条数据的增删改查 | 面向批量分析,解决大规模结构化数据的计算统计 | 面向语义检索,解决高维向量的快速近邻匹配 |
| 代表产品 | MySQL, PostgreSQL, SQLite | DuckDB, ClickHouse, BigQuery, Snowflake | Pinecone, Milvus, Weaviate, Qdrant |
| 数据存储布局 | 按行存储:一条数据的所有字段物理连续存储,开箱即取整行数据 | 按列存储:同一列的所有数据物理连续存储,查询仅加载目标列 | 索引优先存储:专用格式存储高维向量,同时构建拓扑索引(如 HNSW),弱化行 / 列概念 |
| 硬件资源利用 | 侧重磁盘 IO 优化,适配机械硬盘,对 CPU 利用率低 | 侧重 CPU / 内存优化,充分利用多核 + SIMD,适配固态硬盘 | 侧重 CPU/GPU 优化,支持异构计算,对内存带宽要求高 |
| 擅长核心操作 | 高频 CRUD:单条 / 少量数据的增、删、改、查,支持高并发写 | 批量聚合计算:求和、平均值、分组统计、大批量过滤排序,支持复杂 OLAP 函数 | 语义向量检索:Top-K 近邻匹配、相似度计算,支持向量增删改的增量索引 |
| 检索核心原理 | 关键词匹配 / B-Tree/B+Tree 索引,基于字符匹配 | 向量化执行 (SIMD) / 列级扫描,基于数值计算 | ANN 近似近邻算法 (HNSW/IVF/FAISS),基于向量空间距离 |
| 核心数据形态 | 结构化表格数据(姓名、年龄、订单号、时间戳等),字段维度低 | 大规模结构化 / 半结构化数据(日志、报表、量化数据等),支持多维列计算 | 高维向量数据(512/1024/1536 维,代表文本 / 图片 / 音频的语义特征)+ 少量元数据 |
| 事务支持 | 强 ACID:支持事务原子性、一致性、隔离性、持久性,适合核心业务交易 | 弱 / 无 ACID:部分支持最终一致性,牺牲事务换分析性能 | 弱事务:仅支持基础的向量增删改,无复杂事务,聚焦检索性能 |
| RAG 场景核心能力 | 弱:无原生向量支持,需自定义函数序列化向量,仅能做简单暴力检索,效率极低 | 强 (潜力股):原生支持向量类型 + 相似度函数,列存架构极速计算向量距离,支持向量 + 结构化数据混合查询 | 最强 (原生):专为海量向量设计,专用索引 + 量化优化,检索效率是暴力计算的百倍以上,部分支持基础结构化过滤 |
| RAG 部署成本 | 低:生态成熟,易上手,但需二次开发向量能力,后期维护成本高 | 中低:轻量产品(如 DuckDB)无部署成本,SQL 语法通用,无需额外学习成本 | 中高:需学习专用索引配置、向量调优,分布式产品需搭建集群,维护成本较高 |
| 生活化形象比喻 | 像名片夹:翻开一页就能看到一个人的所有信息,找单个人快,找一群人的某个特征慢 | 像财务报表:只想看 "利润" 这一列时,无需翻阅全文,批量提取某类信息效率极高 | 像宇宙星座图:将每个语义转化为星星,意思相近的星星聚成星座,按空间距离快速找相似星星 |
四、核心选型结论(检索组件 + 数据库双层维度)
1、LLM 检索组件选型:按场景定方案,拒绝过度设计
- (1)快速验证 / 极小数据量(<1000 条):直接用 SimpleSearch,无需考虑性能,追求开发效率与结果精准度,零调优成本;
- (2)LLMUnity 生态内 / 纯语义检索(1000-100000 条):选择 DBSearch,原生集成无依赖,ANN 索引保证大规模数据的检索速度,满足绝大多数游戏 AI/NPC 场景;
- (3)专业 RAG / 混合检索 / 大规模数据(100000 条 +):必选 DuckDB + VSS,兼顾检索速度、灵活的 SQL 过滤、轻量部署,是本地 RAG 系统的最佳实践,同时可无缝对接后续的数据分析需求。
2、AI 应用底层数据库选型:按核心需求选类型,兼顾场景拓展性
- (1)纯业务交易 + 少量数据检索:选普通行式数据库(MySQL/SQLite),优先保证业务数据的事务安全性,向量检索需求可通过轻量扩展实现(如 SQLite 的 vector 扩展),适合小型 AI 应用的 "一站式" 需求;
- (2)结构化分析 + 中小规模 RAG(百万级向量内):选分析型列式数据库(DuckDB/ClickHouse),列运算 + 向量搜索双核心能力,完美适配 "结构化数据统计 + 向量语义检索" 的混合场景,一次部署满足多类需求,性价比最高;
- (3)纯大规模向量检索 / 分布式 RAG(亿级向量 + 高并发):选原生向量数据库(Milvus/Qdrant),专用索引与分布式架构,保证海量向量的毫秒级检索与高并发支持,适合企业级生产环境的纯 AI 检索场景;
- (4)超大型混合场景(分布式业务数据 + 亿级向量 + 复杂分析):采用 "行式数据库 + 列式数据库 + 向量数据库" 协同架构,行式数据库管业务交易,列式数据库管批量分析,向量数据库管语义检索,通过数据同步实现三者联动,打造完整的 AI 数据生态。