目录
-
- 论文概览
- 一、研究动机(Motivation)
-
- [1.1 核心问题:小数据集的局限性](#1.1 核心问题:小数据集的局限性)
- [1.2 ImageNet的机遇](#1.2 ImageNet的机遇)
- [1.3 为什么选择CNN?](#1.3 为什么选择CNN?)
- [二、关键创新点(Key Innovations)](#二、关键创新点(Key Innovations))
-
- [2.1 架构创新](#2.1 架构创新)
- [2.2 网络架构细节](#2.2 网络架构细节)
- [2.3 抗过拟合技术](#2.3 抗过拟合技术)
-
- [技术1:数据增强(Data Augmentation)](#技术1:数据增强(Data Augmentation))
- 技术2:Dropout(核心创新)
- 三、训练细节
-
- [3.1 优化配置](#3.1 优化配置)
- [3.2 权重初始化策略](#3.2 权重初始化策略)
- 四、最终结果(Results)
-
- [4.1 ILSVRC-2010 测试集结果](#4.1 ILSVRC-2010 测试集结果)
- [4.2 ILSVRC-2012 竞赛结果(测试集标签未公开)](#4.2 ILSVRC-2012 竞赛结果(测试集标签未公开))
- [4.3 更大规模测试(Fall 2009版本)](#4.3 更大规模测试(Fall 2009版本))
- 五、定性分析
-
- [5.1 学到的特征可视化(Figure 3)](#5.1 学到的特征可视化(Figure 3))
- [5.2 语义相似性(Figure 4)](#5.2 语义相似性(Figure 4))
- 六、历史意义与影响
-
- [6.1 关键结论](#6.1 关键结论)
- [6.2 对领域的深远影响](#6.2 对领域的深远影响)
- [6.3 局限性(作者自评)](#6.3 局限性(作者自评))
- 总结
我来详细分析这篇具有里程碑意义的论文------AlexNet(2012年ImageNet竞赛冠军方案)。
论文概览
这篇论文是深度学习发展史上的转折点,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在多伦多大学完成,发表于NIPS 2012。它在ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了突破性成果,将图像分类错误率大幅降低,重新点燃了对神经网络的研究热情。
一、研究动机(Motivation)
1.1 核心问题:小数据集的局限性
"But objects in realistic settings exhibit considerable variability, so to learn to recognize them it is necessary to use much larger training sets."
作者指出,当时主流的图像数据集(如MNIST、Caltech-101/256、CIFAR-10/100)规模太小(仅数万张图片),无法捕捉真实世界中物体的巨大变化性。虽然MNIST等简单任务接近人类水平,但这不能推广到复杂的真实场景。
1.2 ImageNet的机遇
ImageNet提供了前所未有的规模:
- 1.2百万训练图像
- 1000个类别
- 高分辨率图像
这为解决复杂视觉识别任务提供了数据基础,但也对计算能力和模型设计提出了严峻挑战。
1.3 为什么选择CNN?
作者明确阐述了选择卷积神经网络(CNN)的理论依据:
- 容量可控:通过调整深度和宽度控制模型复杂度
- 先验知识 :利用图像的平稳统计特性 (stationarity of statistics)和像素依赖的局部性(locality of pixel dependencies)
- 参数效率:相比全连接网络,连接数和参数量大幅减少,更易训练
"CNNs have much fewer connections and parameters and so they are easier to train"
二、关键创新点(Key Innovations)
2.1 架构创新
| 创新点 | 具体做法 | 效果 |
|---|---|---|
| ReLU激活函数 | 使用 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) 替代tanh/sigmoid | 训练速度快6倍 |
| 多GPU并行训练 | 将网络分布在两块GTX 580 GPU上 | 支持更大网络规模 |
| 局部响应归一化(LRN, Local Response Normalization) | 模拟生物神经元的侧向抑制机制 | Top-1错误率降低1.4% |
| 重叠池化(Overlapping Pooling) | 步长s=2,池化窗口z=3 | Top-1错误率降低0.4%,减少过拟合 |
ReLU的关键优势:
- 传统饱和激活函数(tanh)在梯度较小时学习缓慢
- ReLU是非饱和的,梯度始终为1(正区间),解决了梯度消失问题
- 这使得训练深层网络成为可能
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
输出范围 − 1 , 1 -1,1 −1,1。
sigmoid ( x ) = 1 1 + e − x \text{sigmoid}(x) = \frac{1}{1 + e^{-x}} sigmoid(x)=1+e−x1
输出范围 0 , 1 0,1 0,1。
2.2 网络架构细节
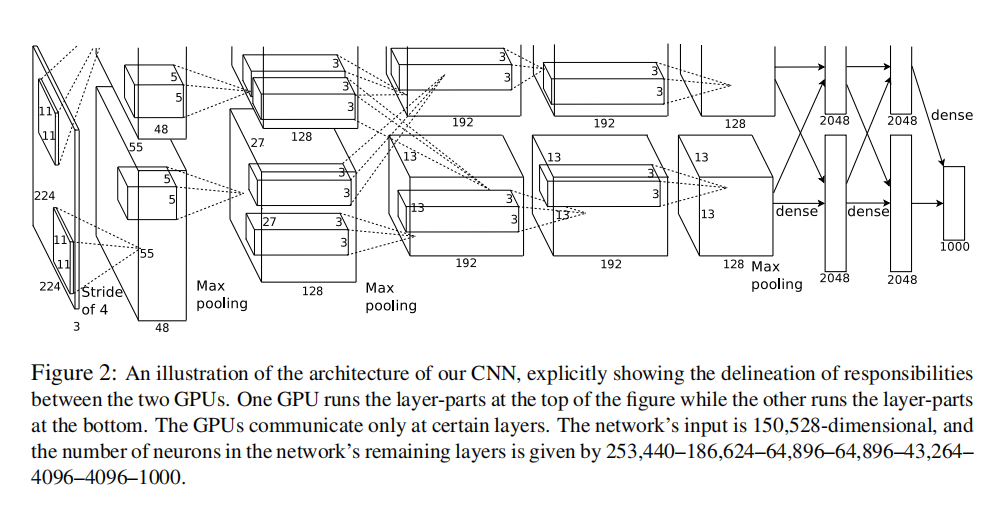
输入: 224×224×3 RGB图像
├── Conv1: 96 kernels, 11×11, stride 4 → ReLU → LRN → MaxPool
├── Conv2: 256 kernels, 5×5 → ReLU → LRN → MaxPool
├── Conv3: 384 kernels, 3×3 → ReLU (跨GPU连接)
├── Conv4: 384 kernels, 3×3 → ReLU (同GPU内连接)
├── Conv5: 256 kernels, 3×3 → ReLU → MaxPool
├── FC6: 4096 → ReLU → Dropout(0.5)
├── FC7: 4096 → ReLU → Dropout(0.5)
└── FC8: 1000-way Softmax关键设计:Conv3使用跨GPU连接,而Conv4-5只在同GPU内连接,形成"列状"结构(Columnar CNN)。
2.3 抗过拟合技术
技术1:数据增强(Data Augmentation)
-
随机裁剪+水平翻转 :从256×256图像随机提取224×224补丁,理论扩充2048倍数据
-
PCA颜色增强:对RGB通道进行主成分分析,添加随机扰动:
p 1 , p 2 , p 3 α 1 λ 1 , α 2 λ 2 , α 3 λ 3 T \\mathbf{p}_1, \\mathbf{p}_2, \\mathbf{p}_3\\alpha_1\\lambda_1, \\alpha_2\\lambda_2, \\alpha_3\\lambda_3^T p1,p2,p3α1λ1,α2λ2,α3λ3T
这捕捉了光照不变性,降低Top-1错误率1%以上
技术2:Dropout(核心创新)
"This technique reduces complex co-adaptations of neurons"
- 在FC6和FC7层以0.5概率随机丢弃神经元
- 关键机制:防止神经元共适应(co-adaptation),强制学习鲁棒特征
- 测试时使用所有神经元,输出乘以0.5进行近似
- 代价:训练迭代次数翻倍,但显著减少过拟合
三、训练细节
3.1 优化配置
- 优化器:带动量的SGD(Stochastic Gradient Descent,随机梯度下降),momentum=0.9
- 批量大小:128
- 权重衰减:0.0005(发现这能减少训练错误,不只是正则化)
- 学习率调度:初始0.01,验证错误率停止改善时除以10,共降低3次
- 训练时间:5-6天(2块GTX 580 3GB GPU)
3.2 权重初始化策略
- 权重:零均值高斯,标准差0.01
- 偏置:Conv2/4/5和全连接层初始化为1(加速ReLU早期学习),其余为0
四、最终结果(Results)
4.1 ILSVRC-2010 测试集结果
| 方法 | Top-1错误率 | Top-5错误率 |
|---|---|---|
| 稀疏编码(Sparsecoding) | 47.1% | 28.2% |
| SIFT + Fisher Vectors | 45.7% | 25.7% |
| AlexNet (CNN) | 37.5% | 17.0% |
突破性进展 :Top-5错误率比前最佳方法降低8.7个百分点(相对提升34%)
4.2 ILSVRC-2012 竞赛结果(测试集标签未公开)
| 模型 | Top-5验证错误率 | Top-5测试错误率 |
|---|---|---|
| 1个CNN | 18.2% | - |
| 5个CNN平均 | 16.4% | 16.4% |
| 1个CNN*(预训练) | 16.6% | - |
| 7个CNNs*集成 | 15.4% | 15.3% 🏆 |
| 第二名(传统方法) | - | 26.2% |
注:带表示在完整ImageNet 2011 Fall(1500万图像,22000类)上预训练
历史性胜利 :领先优势达10.9个百分点(相对提升41.6%),震惊计算机视觉界。
4.3 更大规模测试(Fall 2009版本)
- 10,184类别,890万图像
- Top-1: 67.4% , Top-5: 40.9%(对比之前最佳78.1%/60.9%)
五、定性分析
5.1 学到的特征可视化(Figure 3)
- GPU 1(上层48个核):主要学习颜色无关特征(边缘、方向)
- GPU 2(下层48个核):主要学习颜色特定特征(彩色blob)
- 这种专业化是自发形成的,与随机初始化无关
5.2 语义相似性(Figure 4)
- 网络在最后一层(4096维)学习到了语义相似性
- 检索到的相似图像在像素层面差异很大(不同姿态、背景),但在语义层面相近
六、历史意义与影响
6.1 关键结论
- 深度至关重要:移除任何一个卷积层都会导致性能下降约2%
- 大数据+大模型+GPU:证明了三者结合可以解决复杂视觉任务
- 纯监督学习的胜利:未使用无监督预训练即取得突破
6.2 对领域的深远影响
- 开启深度学习革命:2012年后,CNN成为计算机视觉的主流方法
- GPU训练普及:证明了GPU在深度学习中的核心价值
- ReLU和Dropout成为标准:至今仍广泛使用
- ImageNet挑战赛:此后几年错误率持续下降,2015年ResNet超越人类水平
6.3 局限性(作者自评)
"we still have many orders of magnitude to go in order to match the infero-temporal pathway of the human visual system"
作者清醒地认识到,与人脑视觉通路相比,仍有巨大差距,展望了视频序列和更大网络的未来方向。
总结
这篇论文的成功源于三个关键因素的完美结合:
- 数据规模:ImageNet提供百万级标注数据
- 计算能力:GPU实现高效卷积运算
- 算法创新:ReLU、Dropout、多GPU并行等技术突破
AlexNet不仅是技术上的胜利,更证明了深度神经网络在复杂感知任务上的潜力,直接推动了2010年代AI的爆发式发展。Ilya Sutskever和Geoffrey Hinton此后继续在OpenAI和深度学习领域发挥核心作用,而Alex Krizhevsky的工作奠定了现代计算机视觉的基础。