【Video Agent】(Arxiv2601)Agentic Very Long Video Understanding
- [论文简介 🍀](#论文简介 🍀)
- 一、论文阅读
-
- [1.1 引言(Introduction)](#1.1 引言(Introduction))
- [1.2 方法(Method)](#1.2 方法(Method))
-
- [1.2.1 任务设定(Tools Design)](#1.2.1 任务设定(Tools Design))
- [1.2.2 实体图表示(Entity Graph Representations)](#1.2.2 实体图表示(Entity Graph Representations))
- [1.2.3 智能体框架(Agentic Framework EGAgent)](#1.2.3 智能体框架(Agentic Framework EGAgent))
- [1.3 实验(Experiments)](#1.3 实验(Experiments))
-
- [1.3.1 任务与数据集(Tasks & Datasets)](#1.3.1 任务与数据集(Tasks & Datasets))
- [1.3.2 对比实验(Comparison with State-of-the-arts)](#1.3.2 对比实验(Comparison with State-of-the-arts))
- [1.3.3 消融实验(Ablation Study)](#1.3.3 消融实验(Ablation Study))
- 二、论文理解&总结
- 三、代码学习
- 写在最后
写在前面:如果想了解更多关于长视频理解和视频智能体新工作,可以关注笔者的Github仓库:Awesome-Video-Agent。
论文简介 🍀
- 📖 题目:Agentic Very Long Video Understanding
- 📅 来源:Arxiv
- 🏫 单位:1、Reality Labs Research at Meta;2、University of Wisconsin-Madison
- 🌍 主页:https://arxiv.org/pdf/2601.18157
- 💻 代码:https://facebookresearch.github.io/egagent
- ✒️ 摘要:全天候个人AI助手的出现------这类助手由智能眼镜等可全天佩戴设备所支持------对上下文理解提出了新的要求:这种理解不能仅停留于短暂、孤立的事件,而需要覆盖以自我视角视频为载体的连续、纵向经验流。实现这一愿景需要推进长时程视频理解能力,在这一任务中,系统必须解释并回忆跨越数天甚至数周的视觉与音频信息。现有方法,包括大语言模型和检索增强生成,受限于有限的上下文窗口,且缺乏在超长视频流上执行组合式、多跳推理的能力。论文通过EGAgent来应对这些挑战;它是一种以实体场景图为核心的增强型智能体框架,实体场景图用于表示人物、地点、物体及其随时间变化的关系。该系统为规划智能体配备了可在这些图上进行结构化搜索与推理的工具,以及混合视觉与音频搜索能力,从而实现细粒度、跨模态且时间一致的推理。在EgoLifeQA和Video-MME(Long)数据集上的实验表明,论文方法在EgoLifeQA上达到了当前最优性能(57.5%),并在Video-MME(Long)上取得了有竞争力的性能(74.1%),适用于复杂的纵向视频理解任务。
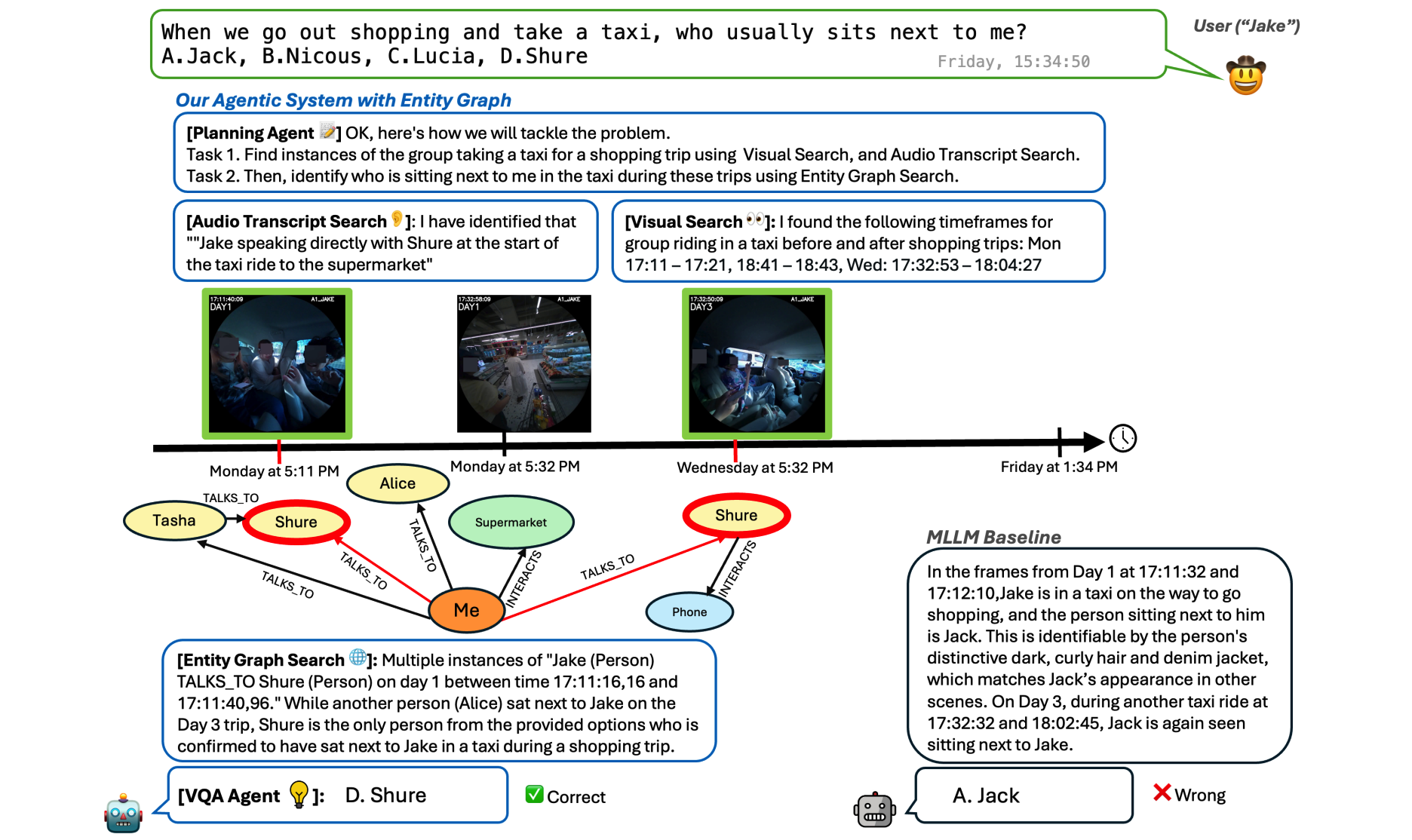
给定一个自然语言查询,论文智能体框架EGAgent将查询分解为子任务,并利用视觉搜索,音频转录搜索和实体场景图搜索来识别跨越多天的相关事件。这个例子突出了框架执行多跳,跨模态推理的能力,首先使用音频和视觉线索执行时间定位,然后使用实体图来推断答案。实体图由用于人、对象或位置的节点以及捕捉关系(例如与之交谈和与之交互)的边组成,每个边都标注有关于关系何时成立的时间间隔。
一、论文阅读
1.1 引言(Introduction)
- 现有方法的不足:
- 现有长视频理解方法受限于LLM上下文窗口,难以支持跨天的组合式、多跳推理。
- 现有长视频理解方法难以在长时间范围内维持实体及其关系的一致推理,也难以进行细粒度时间定位,不同模态之间的信息连接也不够有效。
- 论文的核心思想(贡献):
- 论文提出了实体图表示,将人物、物体、地点作为节点,将talks-to、interacts-with、mentions、uses等关系作为边,并为每条边加入时间区间标注,从而得到可随新文档增量更新、具备时间感知能力的结构化索引。
- 论文提出了EGAgent框架,并通过大量实验证明了方法的有效性,进行了充分的消融研究。
解锁全天候个人AI助手,不仅需要理解孤立事件,还需要理解不断演变的用户体验的连续流。近来,配备AI的可穿戴消费设备不断出现,例如Ray-Ban Meta眼镜、Amazon Echo Frames、Snapchat Spectacles,以及各种原型设备,这为AI智能体持续获取用户随时间所见所做的信息创造了机会。为了让这类助手能够提供有帮助、个性化且具备上下文感知能力的辅助,它们需要具备纵向视频理解能力,也就是在极长时间跨度内(数天乃至数月)回忆并解释用户亲身经历的能力。
论文研究"超长视频理解"这一挑战。在以往文献中,"长"的定义一直在不断演变。像MSR-VTT和DiDeMo这类视频长度最多约为1分钟的经典基准,曾一度被认为是长视频;但近期工作已将这一边界进一步推进到数分钟,乃至长达1小时。近期的EgoLife又将这一边界推进到一周内超过50小时的第一人称视频,论文将这一长度定义为"超长"。与以往侧重大量短小、彼此独立视频的基准不同,EgoLife提供了来自6名个体的连续、纵向的第一人称视频。这种为期一周的时间跨度带来了新的研究方向,例如跨多天跟踪实体及其交互、分析重复行为与习惯,以及处理视频流中长时间不活跃或"空档"时段。智能体式方法通过为智能体配备在大型语料上搜索、检索和推理的工具,已显示出解决其中部分局限性的潜力。然而,现有智能体式方法往往难以在长时间范围内对实体及其关系维持连贯推理,并且难以进行细粒度的时间定位,例如跟踪跨多天重复发生的动作或习惯(例如,"这周我喝了多少次水?")。重要的是,还需要有效连接不同模态中的信息,才能支持更丰富、更准确的推理。
为应对这些挑战,论文提出了EGAgent,这是一种增强的智能体式方法,其核心是从长视频中提取并利用实体场景图,其中节点表示人物、地点和物体,边表示它们之间的关系(例如uses、interacts with、mentions、talks to)。每条边都带有时间区间标注,用于指示该关系成立的时间。在论文提出的EGAgent系统中,论文为一个规划智能体赋予了在该实体图上进行搜索和推理的能力,同时还使用视觉搜索工具(SQL与语义搜索混合)和音频转写搜索工具。如图1所示,系统将该图与音频、视觉搜索结合起来,以定位跨越多天的所有与购物相关的出租车乘坐记录,并推断出谁始终坐在用户旁边。通过利用实体图这类结构化表示,EGAgent保留了复杂关系,并支持在较长时间范围内进行细致的组合式推理,从而克服现有方法的局限。
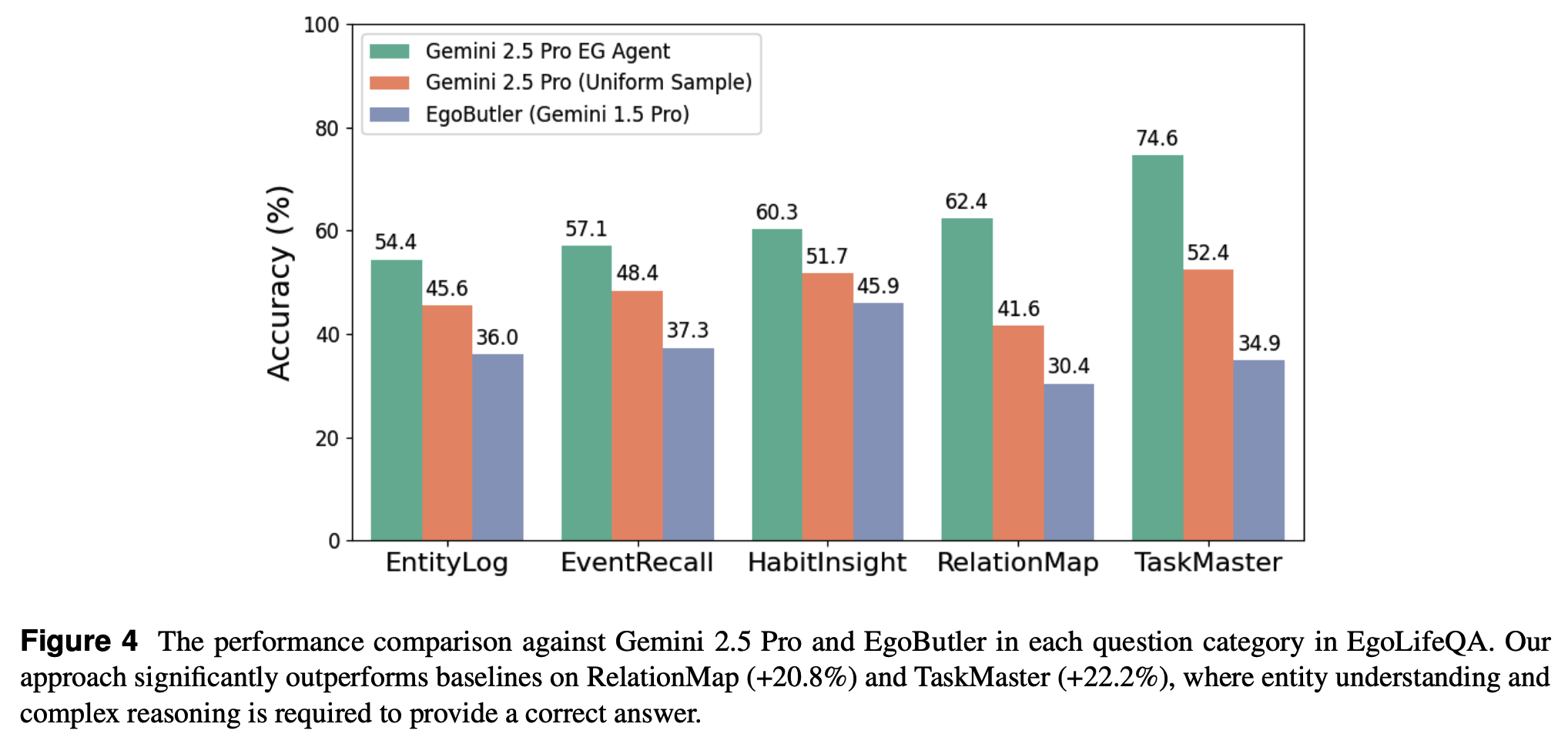
论文在EgoLifeQA基准上评估了EGAgent流程,并展示了当前最优性能。值得注意的是,EGAgent在RelationMap和TaskMaster两个类别上分别超过此前最优结果32%和39.7%,而这两个类别都需要多跳关系推理。EGAgent在Video-MME(Long)基准上也取得了有竞争力的结果。
总结来说,论文的贡献如下。
- 论文提出了一种用于长视频理解的实体图表示,用于实现跨越超长时间范围的结构化、跨模态推理。
- 论文提出了一个智能体框架,该框架联合查询实体图以及视觉和音频搜索工具,在EgoLifeQA上比此前最优结果高出20.6%。
- 论文针对EgoLife上的超长视频理解,对实体图构建和智能体工具使用进行了详细的消融研究。
1.2 方法(Method)
论文首先形式化超长视频理解任务,以及此类长视频的实体图表示提取。最后,论文讨论所提出的智能体框架EGAgent的设计,该框架利用这些实体图表示来进行超长视频理解。

图2 展示了论文EGAgent流程的概览,该流程通过①中的跨模态推理来实现超长视频理解。给定一个超长视频和一个查询,规划智能体会制定回答该查询所需的多步骤子任务计划。规划智能体使用检索工具来探查从长视频中提取出的三种数据源:音频转录文本、视觉帧嵌入以及实体场景图,而实体场景图是EGAgent的核心。②展示了规划智能体如何组合从视觉数据库和实体图中检索到的跨模态信息,以回答一个EgoLife查询。③可视化了实体图查询机制,其中检索工具设计一个SQL查询,以检索供规划智能体进行推理的相关关系。
1.2.1 任务设定(Tools Design)
论文聚焦于超长视频理解任务,具体而言,是针对可能跨越整整一周的视频进行视频问答。令 V = { v t } t = 1 T \mathcal{V}=\{v_t\}{t=1}^{T} V={vt}t=1T 表示以1 FPS(每秒1帧)采样得到的视频。类似地,令 A T = { u i , t s t a r t i , t e n d i } i = 1 N \mathcal{AT}=\{u_i,t{start_{i}},t_{end_{i}}\}{i=1}^{N} AT={ui,tstarti,tendi}i=1N表示转写语音集合,其中每段语音 u i u_i ui都关联有时间戳 ( t s t a r t i , t e n d i ) (t{start_{i}},t_{end_{i}}) (tstarti,tendi)。在测试时,系统接收一个自然语言形式的复杂查询 Q Q Q,并且必须生成一个文本答案 A A A。形式化地,该任务是获得一个映射 H : ( V , A T , Q ) → A H:(\mathcal{V},\mathcal{AT},Q)\rightarrow A H:(V,AT,Q)→A。
对于这类超长视频,若将所有视频帧和转写文本朴素地输入多模态LLM或VLM,由于上下文窗口的限制,这是不可行的。当前主流方法是视频检索增强生成,即Video Retrieval Augmented Generation(RAG),它首先选择性地检索出与用户查询 Q Q Q相关的一小部分视频帧和音频转写文本,然后让VLM基于这一检索结果生成答案 A A A。然而,在超长第一人称视频上,朴素的RAG方法不足以回答这类第一人称查询,因为这类查询往往以实体为中心,并且需要跨越多天进行多跳推理。这些查询包括追踪重复行为,或特定人物、物体与地点之间的交互。对非结构化片段或字幕直接进行基于嵌入的检索,难以在时间上保持连贯的实体身份,从而无法支持诸如"这周我和人物X说话的所有时间"之类的组合性约束。
论文通过两个步骤来解决这一问题。第一,为了支持对随时间变化的实体关系进行查询,论文构建了一个以实体为中心的场景图,它显式编码人物、物体、地点以及时间局部化的关系,并提供一个结构化索引,从而能够将范围收缩到视频中的相关区域。第二,论文提出了一个智能体框架EGAgent,其中包含一个规划智能体,它以迭代方式将 Q Q Q分解为若干子任务,并调用专门的检索工具,其中包括上述构建的实体图。
1.2.2 实体图表示(Entity Graph Representations)
根据论文的观察,基线方法通常难以处理那些需要理解一个人随时间形成的习惯或重复行为的问题(例如,"我早上经常在手机上查看什么?"),以及那些涉及对不同实体之间在较长时间段内的交互与关系进行推理的问题,例如人物、物体或地点(例如,"在我们去看狗之前,谁和我一起去了二楼找Tasha?")。由于这些方法没有显式建模实体关系,也没有跟踪长期行为模式,因此它们在这类问题上的表现,尤其是在长时间范围内,是有限的。
为了解决这一问题,论文构建了一个实体图 G = ( V , E ) G=(V,E) G=(V,E)来捕捉关系和交互,从而使规划智能体能够在推理阶段查询该图。
- 节点( V V V):实体(即个人、物体、地点)
- 边( E E E):关系(即交互、提及、交谈、使用)以及时间信息
每条边都带有时间信息标注,从而能够跟踪相应关系的存在、先后顺序以及持续时间。这种时间结构对于推理那些在长时间范围内展开或重复发生的事件和交互至关重要。
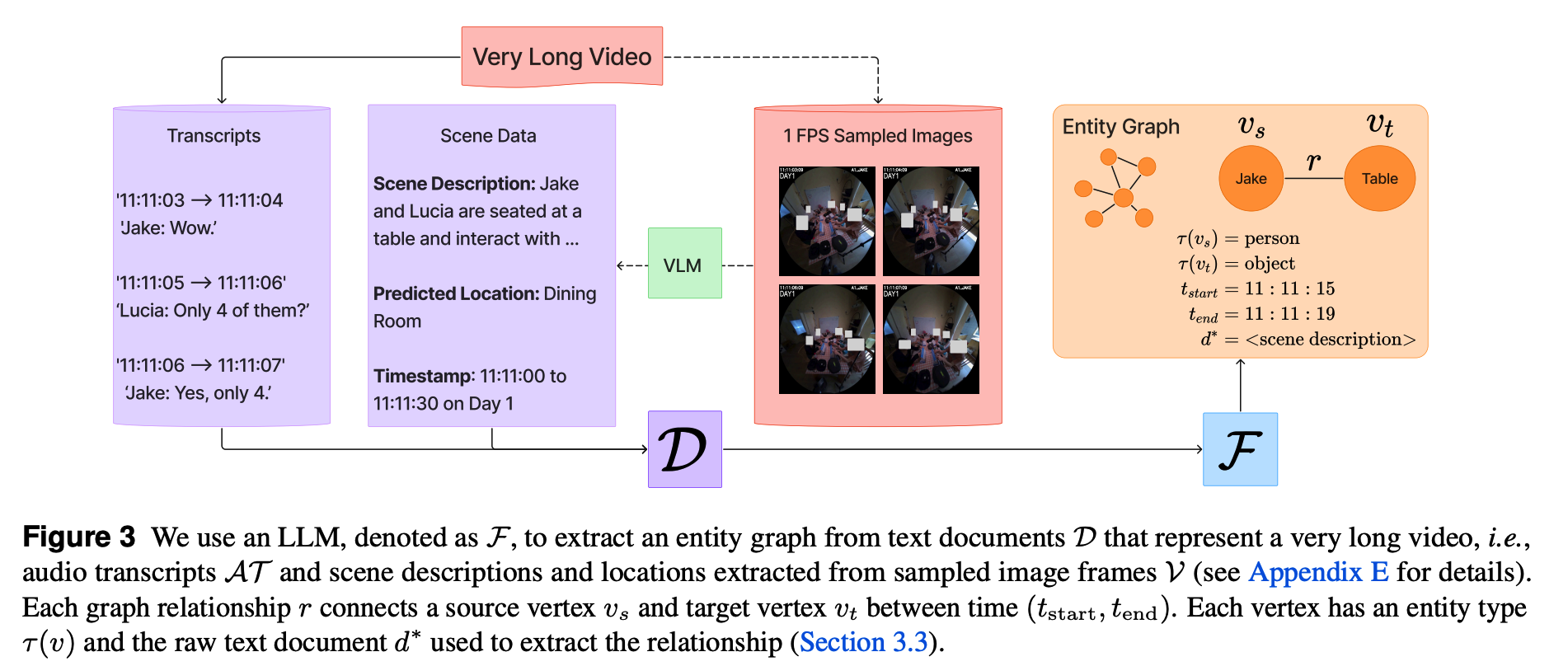
实体图构建(Entity Graph Creation) 。论文从给定的文本文档集合 D \mathcal{D} D中构建实体图 G = ( V , E ) G=(V,E) G=(V,E),该集合包括音频转录文本、场景描述以及预测的场景位置(如图3所示)。论文在附录E中讨论了提取场景数据以生成这些文档 D \mathcal{D} D的细节。对于每个文档 d ∈ D d\in \mathcal{D} d∈D,论文应用一个基于LLM的抽取器 F \mathcal{F} F,联合识别实体及其关系:
( V d , E d ) = F ( d ) ( 1 ) (V_d,E_d)=\mathcal{F}(d) \quad(1) (Vd,Ed)=F(d)(1)
这里, V d V_d Vd是从 d d d 中抽取的实体集合, E d E_d Ed是从 d d d 中抽取的关系集合。总体的实体和关系聚合为:
( V , E ) = ( ⋃ d ∈ D V d , ⋃ d ∈ D E d ) ( 2 ) (V,E)=\left(\bigcup_{d\in \mathcal{D}}V_d,\bigcup_{d\in \mathcal{D}}E_d\right) \quad(2) (V,E)=(d∈D⋃Vd,d∈D⋃Ed)(2)
论文为每个节点 v ∈ V v\in V v∈V分配一个类型 τ ( v ) \tau(v) τ(v),其取值为"person"、"object"、"location"之一。论文最初将每条边 e e e表示为一个元组 ( v s , v t , r ) (v_s,v_t,r) (vs,vt,r),其中 v s v_s vs和 v t v_t vt分别是源节点和目标节点,且 r ∈ R r\in R r∈R是关系类型。关系类型集合为:
R = { talks-to , interacts-with , mentions , uses } ( 3 ) R=\{\text{talks-to},\text{interacts-with},\text{mentions},\text{uses}\} \quad(3) R={talks-to,interacts-with,mentions,uses}(3)
随后,每条边 e e e都用从源文档 d d d中得到的时间信息 ( t s t a r t , t e n d ) (t_{start},t_{end}) (tstart,tend)进行标注。完成时间标注后,每条边表示为:
e = ( v s , v t , r , t s t a r t , t e n d ) ( 4 ) e=(v_s,v_t,r,t_{start},t_{end}) \quad(4) e=(vs,vt,r,tstart,tend)(4)
最终得到的图被存储为如下元组集合:
( v s , τ ( v s ) , v t , τ ( v t ) , r , t s t a r t , t e n d , d ∗ ) ( 5 ) (v_s,\tau(v_s),v_t,\tau(v_t),r,t_{start},t_{end},d^*) \quad(5) (vs,τ(vs),vt,τ(vt),r,tstart,tend,d∗)(5)
其中, d ∗ d^* d∗是抽取该边所依据的支持性文本片段。该图以SQLite3数据库的形式存储在内存中,其中每一行对应一个元组。随着新的文档 d d d不断到来,图构建过程支持增量更新,从而使 G G G能够随时间不断增长并细化。
1.2.3 智能体框架(Agentic Framework EGAgent)
给定上述超长视频及实体图表示,论文提出了一种用于多模态推理的智能体框架EGAgent,其总结见算法1,并在图2中进行了说明。EGAgent由六个主要组件构成:一个规划智能体(Planning Agent)、三个检索工具(Retriever Tools)(视觉搜索、音频转录搜索和实体图搜索)、一个分析工具(Analyzer Tool),以及一个VQA智能体(见图2中的①)。论文在附录B中进一步讨论了智能体设计的更多细节,并给出了定性示例。

每个组件都作用于特定的数据模态或推理步骤。规划智能体将复杂的用户查询 Q Q Q 分解为若干子任务,选择合适的工具,并维护一个用于累积跨模态证据的工作记忆 M M M。检索工具(视觉搜索、音频转录搜索、实体图搜索)访问不同的数据源,为每个子任务查找相关信息;分析工具对检索到的信息进行过滤和提炼;VQA智能体则基于累积的证据生成最终答案 A A A。
规划智能体(Planning Agent) 负责协调整个推理过程。给定用户查询 Q Q Q 以及每个工具的自然语言定义,规划智能体会联合地将 Q Q Q分解为一个由 N N N个子任务组成的序列 { S 1 , S 2 , ... , S N } \{S_1,S_2,\ldots,S_N\} {S1,S2,...,SN},并为每个子任务分配相应的 T o o l i Tool_i Tooli以及合适的查询参数 q i q_i qi(算法1第2至3行)。
每个子任务 S i S_i Si针对所需信息的某个特定方面,例如物体定位、检查说话人区分后的语音,或者确认过去的交互。对于每个 ( S i , T i , q i ) (S_i,T_i,q_i) (Si,Ti,qi),规划智能体会从以下工具中选择一个检索工具 T i T_i Ti:
- (i) 视觉搜索工具( T o o l v i s Tool_{vis} Toolvis)用于检索视觉内容;
- (ii) 音频转录搜索工具( T o o l a u d Tool_{aud} Toolaud)用于检索转写语音;
- (iii) 实体图搜索工具( T o o l e g Tool_{eg} Tooleg)用于查询以实体为中心的场景图。
检索到的内容会被传递给分析工具,相应的分析结果则被更新到工作记忆 M M M中。这样的迭代过程使EGAgent能够在保持每个子任务上下文规模可控的同时,逐步细化其对查询 Q Q Q的理解。最后,VQA智能体利用工作记忆和原始查询给出最终答案。图2中的②给出了一个示例,展示规划智能体如何对借助检索工具获得的跨模态信息进行推理。
视觉搜索工具(Visual Search Tool) 以1 FPS对视频帧进行采样,并使用视觉编码器将每一帧 v t v_t vt嵌入为 ϕ I ( v t ) ∈ R d \phi_I(v_t)\in\mathbb{R}^d ϕI(vt)∈Rd。生成的嵌入以及时间戳、位置等属性被存储在一个支持高效检索的向量数据库中。在推理时,规划智能体提供文本子查询 q i q_i qi(其被嵌入为 ϕ T ( q ) \phi_T(q) ϕT(q))以及可选的属性过滤器 f f f(例如"kitchen""morning")。该工具对向量数据库中过滤后的行计算余弦相似度 cos ( ϕ T ( q ) , ϕ I ( x t ) ) \cos(\phi_T(q),\phi_I(x_t)) cos(ϕT(q),ϕI(xt)),并返回 k k k个最近邻供进一步分析。
音频转录搜索工具(Audio Transcript Search Tool) 在文本转录上运行。论文考虑了两种变体:
- (i) 基于LLM的搜索,即针对相关时间范围将完整转录输入LLM中进行搜索(由于上下文限制,按天并行处理);
- (ii) 基于BM25的词法搜索。前者能够提供显著更高质量的结果,但代价是更高的延迟。
实体图搜索工具(Entity Graph Search Tool) 查询以SQLite数据库中元组形式存储的、以实体为中心的场景图 G G G(公式(5))。在推理过程中,规划智能体会围绕以下字段发出SQL查询 q q q:
- (i) 时间过滤;
- (ii) 关键词文本搜索;
- (iii) 实体源节点和/或目标节点 ( v s , v t ) (v_s,v_t) (vs,vt);
- (iv) 关系类型 r r r。
在实际中,真实世界数据往往是不完整或有噪声的,因此规划智能体采用一种"从严格到宽松"的查询策略:它首先对所有指定字段发出精确匹配查询;如果没有找到结果,则通过扩大时间窗口、允许部分文本匹配,并最终放宽关系类型过滤,逐步放松约束。当精确匹配可用时,这一策略最大化精度;而当无法获得精确匹配时,它又能提高召回率(图2中的③展示了一个查询轨迹示例,附录C则给出了SQL查询的定性示例)。
分析工具(Analyzer Tool) 通过LLM判断针对每个子任务 S i S_i Si所检索上下文的相关性,以执行轻量级推理、证据抽取以及可选的去重。
VQA智能体(VQA Agent) 是一个多模态LLM,它以 Q Q Q和 M M M中的紧凑证据为条件来生成最终答案 A A A(算法1第13行),从而能够对跨度为整周的第一人称视频进行细致且时间一致的推理。
1.3 实验(Experiments)
1.3.1 任务与数据集(Tasks & Datasets)
基准。
- EgoLifeQA:EgoLifeQA由500道长上下文多项选择题组成,这些题目来源于EgoLife数据集。在该数据集中,六名参与者共同生活一周,并使用Project Aria眼镜持续记录他们的日常活动。该基准聚焦于六名参与者之一Jake视角下的50小时视频。这些多项选择题涵盖诸如定位物品、回忆过往事件、追踪习惯以及分析社交互动等实际问题。每道题有四个候选答案,其中只有一个正确选项。每道题都关联一个查询时间(例如第4天上午11:34)以及一个经过人工核实的目标时间,用于指示视频中包含正确回答该题所需信息的具体片段。
- Video-MME(Long):Video-MME包含900个视频和2700道多项选择题。该基准依据视频长度划分为Short、Medium和Long三个子集。论文聚焦于Long子集,该子集由300个视频组成,视频时长范围为30到60分钟。
实现细节。为了为实验准备实体图,论文针对Video-MME数据集中的每个视频分别提取一个图。对于EgoLifeQA,由于更长的输入转录文本更容易导致LLM调用失败,论文改为每小时视频提取一个图。在这两个数据集中,音频都用文本转录来表示。对于Video-MME,转录由诸如Whisper之类的ASR基础模型生成。相比之下,EgoLife提供的是人工说话人区分后的转录,其中同时包含说话人身份及其对应的话语内容。论文在附录E中进一步讨论了更多细节,并提供了代码片段以及所有智能体与工具使用的提示词。
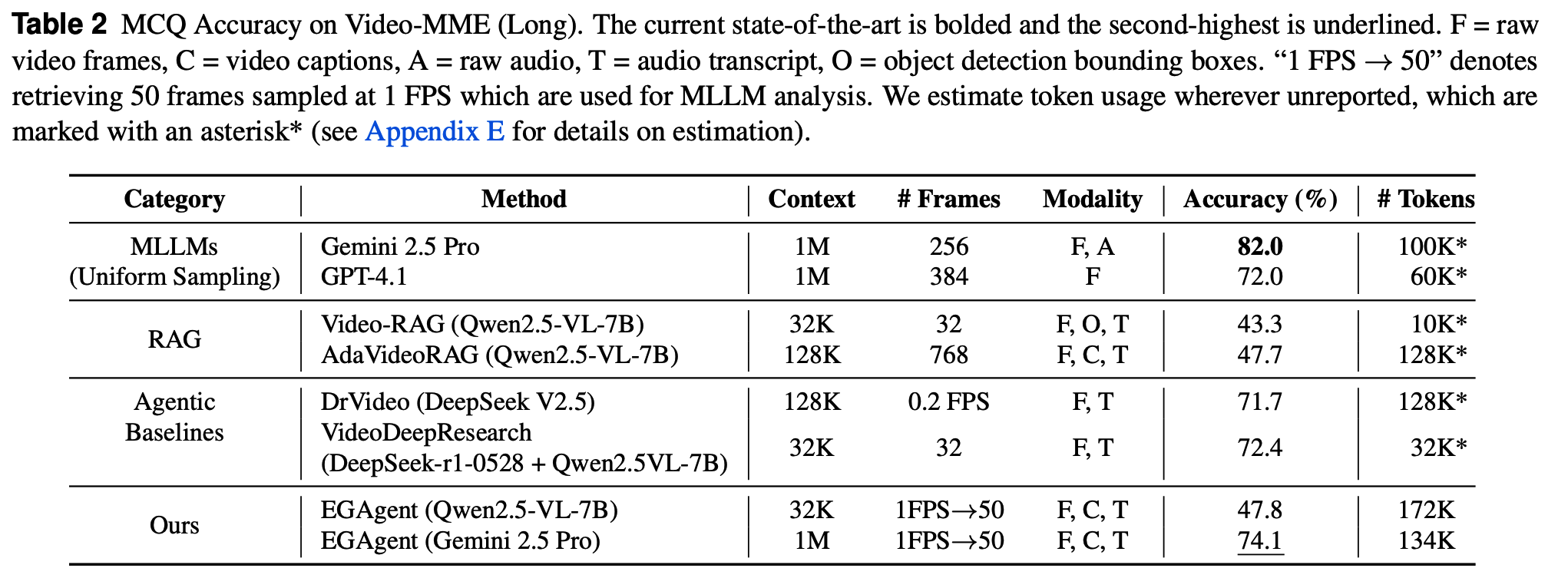
1.3.2 对比实验(Comparison with State-of-the-arts)

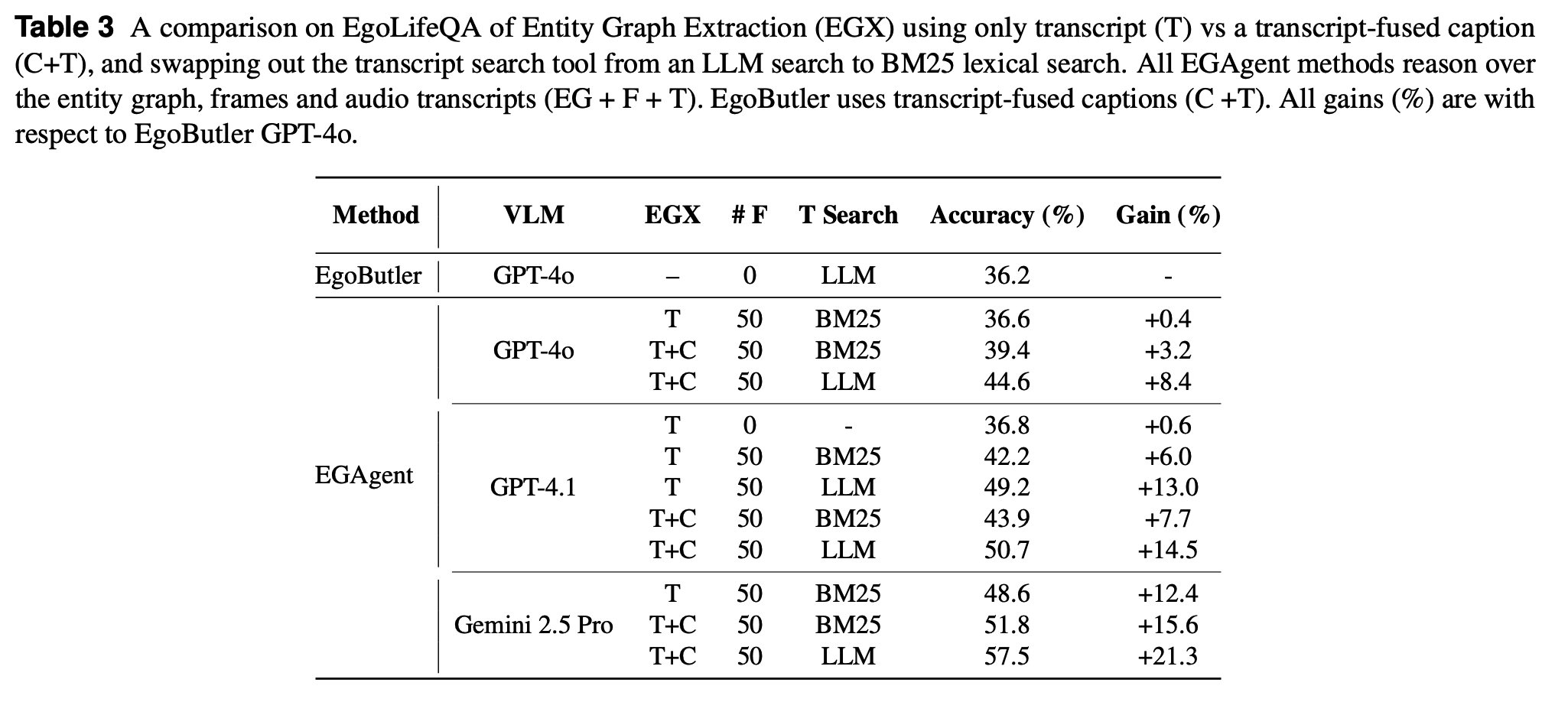
1.3.3 消融实验(Ablation Study)

二、论文理解&总结
暂时省略,用到再分析。
三、代码学习
暂时省略,用到再分析。
写在最后
由于笔者🖊️精力有限且本文更多的目的是通过📒博客记录学习过程并分享更多知识,因此文中部分描述不太具体,如有不太理解💫的地方可在评论区👀留言。非特殊赶deadline⏰或假期⛱️期间,笔者会经常上线回复💬。如有不便之处,请海涵~
如果想了解更多关于长视频理解和视频智能体新工作,可以关注笔者的Github仓库:Awesome-Video-Agent。
另外,创造不易,转载请注明出处💗💗💗~