这篇文章到底在解决什么问题
现代 AI 系统的性能很大程度取决于 Kernel 的质量。Kernel 把高层算法语义翻译成硬件层的并行执行指令,但要做到接近硬件峰值性能,需要对 GPU 架构、内存层级、并行编程模型有深度理解。问题在于:
- 高性能 Kernel 编写 门槛高、成本大、不可规模化 。
- 不同硬件平台之间 性能不可移植 。
- 传统代码生成只关心正确性,而 Kernel 生成必须同时考虑 性能、资源占用和硬件适配 。
这篇 survey 的核心目标,是系统梳理 LLM 和 LLM Agent 在 Kernel 生成上的最新进展,并把 数据集、评测基准、方法范式和未来挑战 整理成一个可复用的研究地图。
背景:LLM + Kernel 为什么是必然组合
LLM 的基础是 Transformer,通过自回归概率建模学习隐性知识:
P ( x ) = ∏ t = 1 T P ( x t ∣ x 1 , ... , x t − 1 ; θ ) P(x) = \prod_{t=1}^{T} P(x_t \mid x_{1}, \dots, x_{t-1}; \theta) P(x)=t=1∏TP(xt∣x1,...,xt−1;θ)
这让 LLM 能"压缩"专家知识,适合吸收硬件规范、优化策略等难以形式化的经验。
与此同时,Kernel 编程本质上是 性能导向的程序合成 ,它关注的不只是"能跑",而是"跑得快、跑得稳、跑得适配"。这使得 Kernel 生成更像 编译器优化问题 ,而非普通的软件工程代码生成。
论文全局脉络(从问题到方法再到挑战)
作者给出了一个很清晰的逻辑结构:
- 解释 Kernel 工程为何难以规模化。
- 说明 LLM 和 Agent 如何替代传统手工优化。
- 梳理 LLM 后训练方法(SFT / RL)。
- 总结 Agentic 系统的四大结构维度。
- 系统整理数据集与评测基准。
- 给出未来挑战与研究方向。
下面按这个顺序展开。
LLM for Kernel Generation:后训练方法的两大范式
1. Supervised Fine-Tuning(SFT)
SFT 的核心就是构建"高层意图---低层 Kernel 实现"的对齐数据。文章提到两个关键趋势:
- 高质量样本筛选 :ConCuR 强调用精简推理链、优良性能、多任务多样性筛选样本,最终训练出 KernelCoder。
- 编译器对齐数据 :KernelLLM 利用 Triton 编译器自动生成 PyTorch-Triton 对齐样本,并通过结构化 prompt 来提升 Kernel 生成的一致性。
一句话总结:SFT 靠数据设计,不是靠模型"变聪明"。
2. Reinforcement Learning(RL)
RL 的优点是能把 运行时反馈 转化成改进信号,适合优化性能。
代表方法包括:
- Kevin :多轮优化 + 跨轮奖励归因。
- QiMeng-Kernel :宏观策略由 RL 训练,微观代码由 LLM 生成。
- AutoTriton / TritonRL :结合结构指标和运行时性能,避免奖励稀疏。
- CUDA-L1/L2 :引入 LLM-as-a-judge,让奖励变得更密集、更可控。
RL 的本质不是"让模型变聪明",而是让它 探索到更优的性能策略 。
LLM Agent for Kernel Generation:闭环优化的四个维度
1. 学习机制:从单步生成到长程探索
LLM Agent 将 Kernel 优化变成 多轮迭代 + 反馈驱动的探索问题 。典型技术:
- 迭代式优化(Caesar、PEAK、TritonX)
- 强化式搜索(MaxCode)
- 进化算法(FM Agent、EvoEngineer)
核心价值在于:摆脱一次性生成,把 Kernel 优化当成"搜索过程"。
2. 外部记忆:知识库与结构化记忆
为了避免幻觉和知识缺失,Agent 往往配套外部记忆系统:
- AI CUDA Engineer :向量库检索高质量 Kernel 示例。
- KernelEvolve :硬件专用知识库。
- ReGraphT :将优化路径显式建成"推理图谱"。
换句话说:LLM 不再是孤立思考,而是有"硬盘"的专家。
3. 硬件 Profiling Integration:数据驱动的性能优化
Agent 会接入硬件规格与 profiling 结果,例如:
- QiMeng 系列 :根据硬件手册和 meta-prompt 生成优化 Kernel。
- CUDA-LLM / TritonForge :把编译与运行时反馈变成优化指导。
- PRAGMA / KERNELBAND :把低层指标转换成可读建议。
这是 Agent 能做到"贴着硬件跑"的关键。
4. Multi-Agent Orchestration:专业分工
Kernel 优化涉及算法规划、代码生成、调试、评测等多技能,因此出现多 Agent 结构:
- STARK / AKG :Plan-Code-Debug 拆分流程。
- CudaForge / KForge :Coder + Judge 互相博弈。
- KernelFalcon :多层任务分解,适用于大规模架构。
一句话:Kernel 开发变成"多智能体协作工程"。
数据集与知识库:这是决定上限的部分
作者把数据分成两大类: 训练数据 和 知识库 。
训练数据(Training Corpora)
- 结构化数据集 :KernelBook、HPC-Instruct、KernelBench samples。
- 代码仓库 :CUTLASS、FlashAttention、xFormers、Liger-Kernel 等。
- 框架内核 :PyTorch ATen、vLLM、TensorRT-LLM、DeepSpeed。
- DSL 资源 :Triton、TileLang、cuTile。
知识库(Knowledge Bases)
- 官方文档:CUDA Guide、PTX ISA、Tuning Guides
- 社区资源:GPU-MODE、Triton Index、Awesome-CUDA
- 教学资源:Triton-Puzzles、LeetCUDA
- Profiling 工具:Nsight Compute、Triton-Viz
关键结论:Kernel 优化不是缺模型,而是缺 硬件语义数据 和 优化路径轨迹 。
Benchmark:评测体系正在发生三大变化
文章整理了 ParEval、KernelBench、TritonBench、MultiKernelBench 等最新基准。
1. 指标更加综合
除了正确性,还引入了效率、速度、相似度等多维指标。
核心指标定义:
- pass@k : k k k 次生成中至少有一次正确
pass@ k ≜ E 1 − ( n − c k ) / ( n k ) \text{pass@}k \triangleq \mathbb{E}\left1-\\binom{n-c}{k} /\\binom{n}{k}\\right pass@k≜E1−(kn−c)/(kn)
- speedup@k :与 baseline 的速度提升
speedup@ k ≜ E ∑ j = 1 n ( ( j − 1 k − 1 ) T b a s e ) / ( ( n k ) T j ) \text{speedup@}k \triangleq \mathbb{E}\left\\sum_{j=1}\^n \\left(\\binom{j-1}{k-1}T\^{\\mathrm{base}}\\right)/\\left(\\binom{n}{k}T_j\\right)\\right speedup@k≜Ej=1∑n((k−1j−1)Tbase)/((kn)Tj)
2. 硬件从单一 GPU 走向多平台
评测开始纳入 AMD、HUAWEI、Google TPU 等平台。
3. 内容从算法示例走向生产负载
FlashInfer-Bench、BackendBench 等开始对真实系统中出现的 workload 做评测。
图表:领域增长趋势
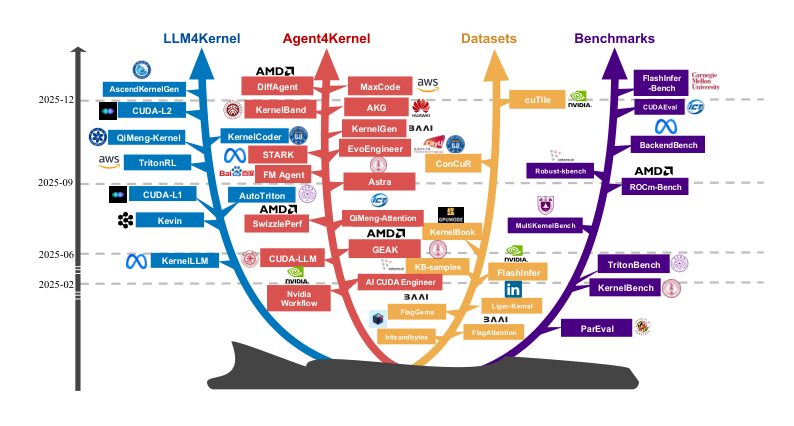
图解:该图按年份和研究方向整理 LLM 驱动 Kernel 生成的发展轨迹,可以直观看到从 SFT、RL 到 Agentic 系统的研究爆发趋势,以及数据与评测体系逐步完善的过程。
挑战与机会:真正的难点在哪里
1. 数据稀缺与合成扩展
高性能 Kernel 数据存在 长尾问题 ,真实优化过程少,只有"最终版"而缺少"演化轨迹"。解决方向包括:
- 大规模合成数据
- 收集优化过程中的中间状态
- 构建可用于 RL 的交互式环境
2. Agent 的推理能力与工程可靠性
当前 Agent 仍以手工流程为主,问题包括:
- 长任务容易迷失
- 优化策略难以收敛
- 缺少形式化验证
未来方向是 自规划 + 结构化知识库 + 工程级规范 。
3. 训练与编译的基础设施瓶颈
推理速度远快于编译和运行反馈,形成瓶颈。需要:
- Gym-like 分布式环境
- 异步大规模反馈执行
- 标准化的硬件反馈接口
4. 评测缺乏跨平台泛化能力
当前评测仍高度集中在 NVIDIA,缺乏对多硬件、多语言、多任务的通用验证。
5. 人机协作仍是长期方向
Agent 并不能取代人类,而是需要 混合协作模式 :
- LLM 提供候选方案
- 人类提供约束与验证
- 通过可解释性实现工程级信任
总结:这篇 survey 的真正贡献
这篇文章的价值不在提出新方法,而在于 提供了一个系统化视角 。它告诉我们:
- Kernel 生成正在从"模型能力"走向"系统工程"。
- 数据、评测和工具链 才是决定上限的关键因素。
- 未来 LLM + Agent 能否成功,不仅取决于模型,还取决于 反馈机制、基础设施和跨硬件泛化能力 。
换句话说,这不是一个"单点突破"的问题,而是一个需要 模型 + 数据 + 硬件生态协同进化 的长期工程。
本文参考自 Towards Automated Kernel Generation in the Era of LLMs