一、研究动机
论文标题: Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
论文地址: https://arxiv.org/abs/2602.03689
作者背景: 伊利诺大学香槟分校、香港科技大学、圣路易斯华盛顿大学、德克萨斯农工大学
代码仓库: https://github.com/GasolSun36/BAR-RAG
1.1 问题背景:从通用模型到专门训练
检索增强生成(RAG)系统在知识密集型任务上取得了显著成功,常见的 RAG 实现方式是直接调通用大模型 API(如 GPT-4、Claude 等)作为生成器,配合检索器构建系统。这种方式部署简单、无需训练,在许多企业级应用中已经取得了不错的效果。
不过,随着业务场景复杂度的提升,开发者往往会遇到一些零散但持续的小问题:多跳推理偶尔出错、对检索噪声有时敏感、输出格式不够稳定、引用规范难以保证......这些问题单独来看影响不大,但累积起来会让 prompt 变得越来越臃肿------各种业务限制、格式要求、边界情况处理不断叠加,心智负担日益加重,最终影响主体内容的生成效果。
在这种情况下,对生成器做专门训练或微调成为一种让效果更进一步的选择:将这些零散的要求内化到模型参数中,而非堆砌在 prompt 里,从而获得更稳定、更鲁棒的表现。
1.2 训练生成器时的隐藏陷阱
然而,一旦进入"训练生成器"的范式,一个新的问题就浮现出来:
RAG 系统有一个常见的困境:检索出来的证据看起来很"相关",但模型还是答错了。更令人困惑的是,即使答案确实存在于检索返回的 Top-K 文档中(高召回率),最终的问答准确率也往往跟不上。
论文指出了一个被忽视的关键原因:检索器和重排器只优化"相关性",却不管这些证据对生成器来说是否"合适"。
当检索结果被用作生成器的训练数据时,"只追求相关性"会导致证据落入两个极端:
极端一:太简单------答案直接"塞脸上"
检索器最喜欢那些与问题高度匹配、直接包含答案的段落------因为它们的相关性分数最高。但如果生成器总是在这类"送分题"上训练,它就会学会走捷径:看到类似线索就直接猜答案,根本不做真正的推理。
就像学生只靠背答案应付考试,一旦题目稍有变化就束手无策。
极端二:太难------关键信息缺失
另一种情况是,检索到的文档虽然看起来相关,但缺少推理链条上的关键环节。无论生成器怎么努力,都做不出来。这种样本对训练来说也是无效的------它提供不了有意义的学习信号。
这就造成了严重的训练-测试分布失配:
- 训练时:检索器提供高相关性证据,答案往往直接可见,生成器在"简单模式"下学习
- 部署时:真实场景下的检索结果充满噪声、不完整或模糊,生成器却要在"困难模式"下工作
生成器在"送分题"上练出来的能力,到了真实场景就不够用了。
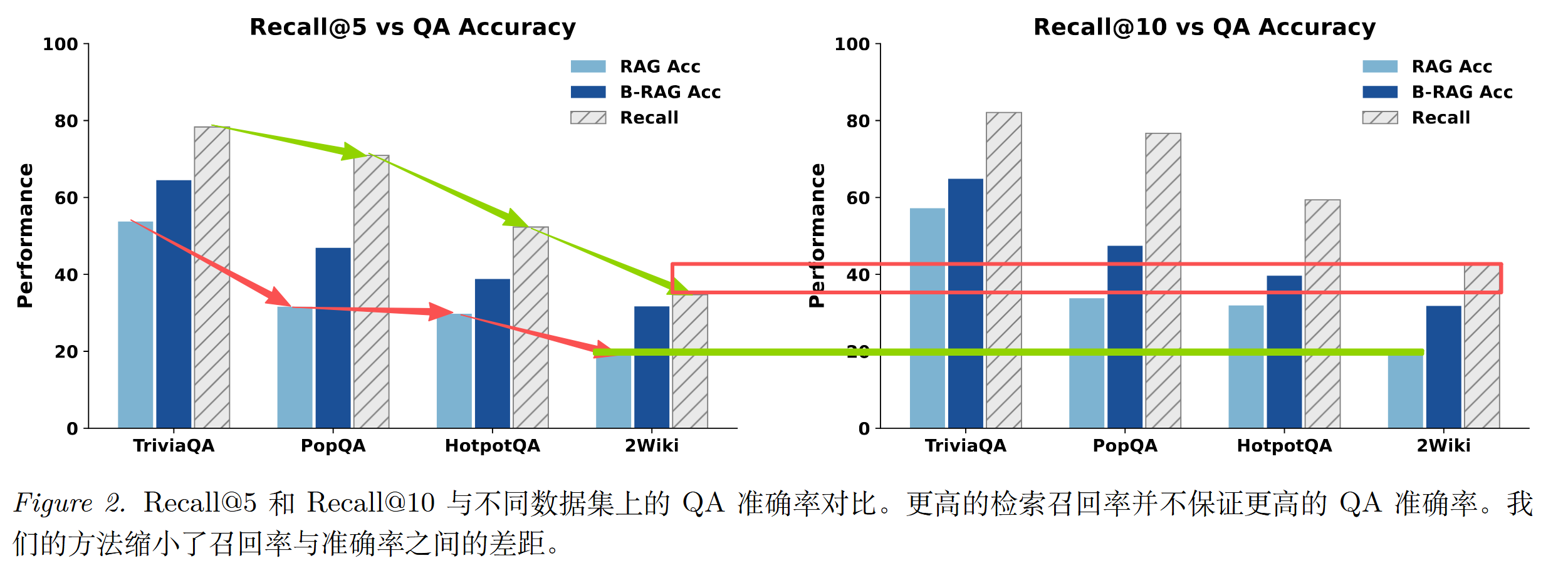
从上图可以看出:即使答案所在的文档出现在 Top-K 检索结果中(高 Recall),标准 RAG 流程也往往无法将高召回率转化为相应的答案准确率提升。这个差距正是"相关性 ≠ 合适性"的直接体现。
1.4 核心洞察:最好的训练信号来自"边界样本"
就像健身时的训练强度:太轻松练不出肌肉,太重了会受伤,只有在"刚好吃力"的区间才能最有效地进步。
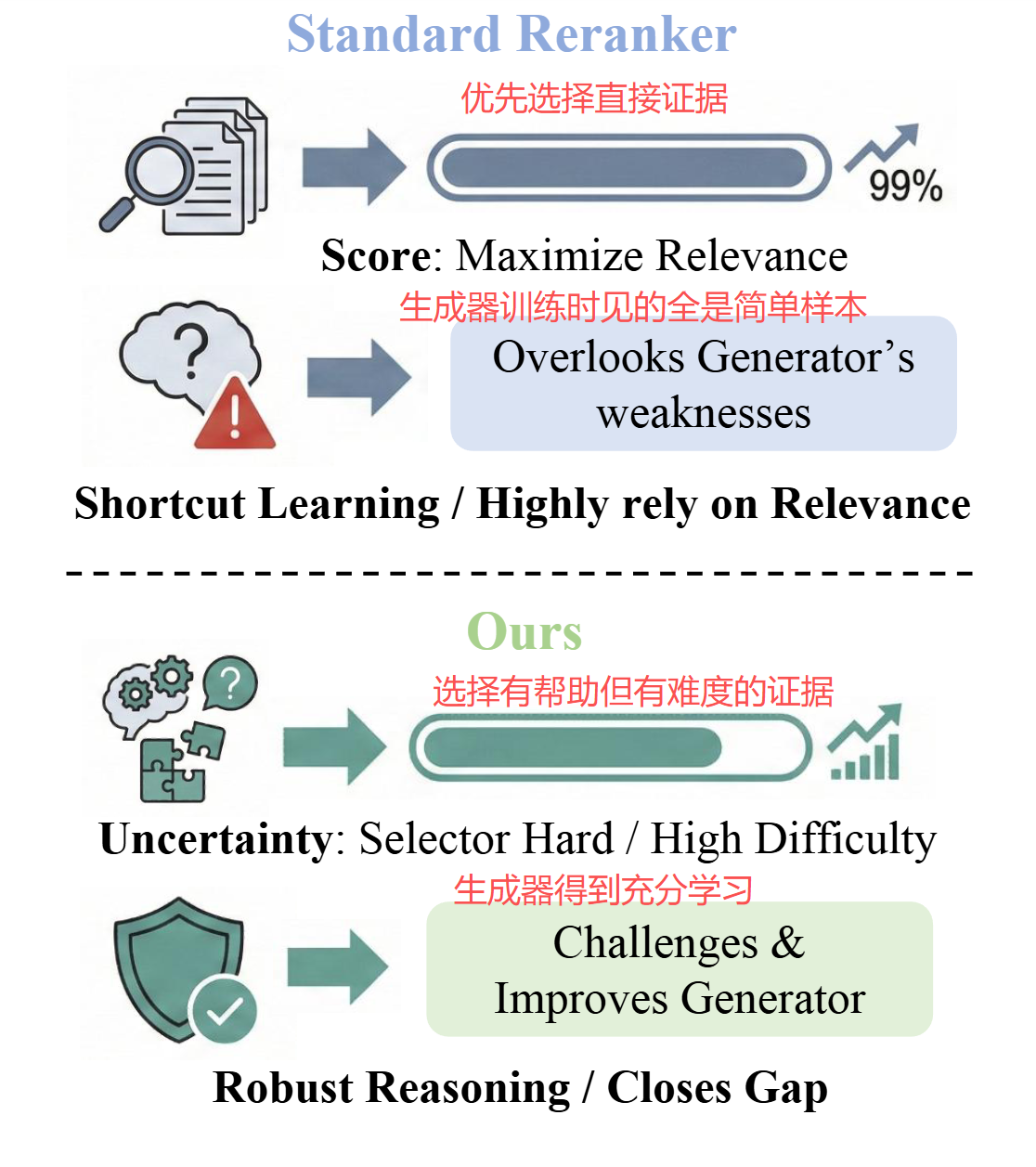
论文把这个区间叫做 Goldilocks Zone(恰到好处区) ,并引出了一个关键的范式转变:不应该把重排器视为被动的相关性打分器,而应该视为主动的证据集选择器------它的职责是挑选最能帮助生成器进步的文档组合,而非单纯最相关的文档。
二、方法原理与实现
2.1 核心思路:把重排器变成"教练"
传统的重排器像一个"相关性打分员":给每个文档打个分,按分数排序返回。它只关心"这个文档和问题有多相关"。
BAR-RAG 提出了一个范式转变:把重排器变成一个"证据组合挑选器",或者说一个"教练"。这个教练的职责不是找最相关的文档,而是找最能帮助生成器进步的文档组合------那些落在"恰到好处区"的证据集。
2.2 两阶段训练框架
BAR-RAG 的训练分为两个阶段,可以多次迭代:
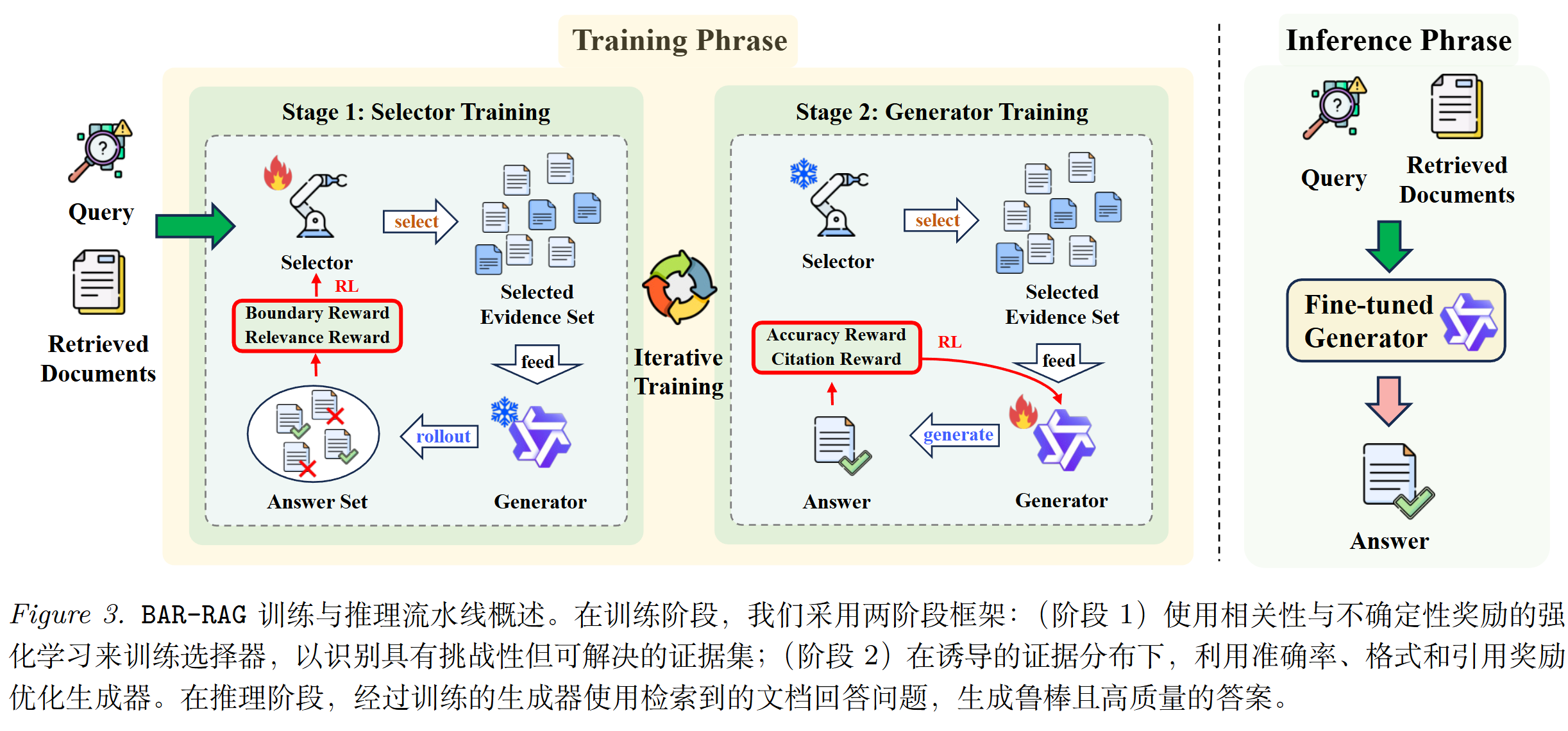
阶段一:训练选择器(Selector)
选择器的任务是:从检索返回的候选文档池中,挑选出一组"恰到好处"的证据。
怎么判断一组证据是否"恰到好处"?论文采用了一个直观的方法:
- 让生成器在这组证据上多次尝试回答问题
- 统计正确率
- 如果正确率接近 50%(可配置),说明这组证据既不太简单也不太难------恰好在生成器的能力边界上
选择器的训练目标就是学会挑选这样的证据组合,同时兼顾相关性和文档数量要求。
阶段二:训练生成器(Generator)
阶段二冻结选择器,用它产出的"恰到好处"证据来训练生成器。
这样,生成器在训练时就会频繁遇到"需要整合多个线索、需要真正推理"的证据组合,而不是那些答案直接可见的"送分题"。久而久之,生成器的推理能力和抗噪声能力都会增强。
迭代训练
两个阶段可以交替进行多轮:
- 第一轮:用当前生成器训练选择器 → 用选择器产出的证据训练生成器
- 第二轮:用更强的生成器重新训练选择器(因为能力边界变了)→ 再训练生成器
- ......
随着迭代,选择器会不断调整,始终瞄准生成器的"当前能力边界",形成良性循环。
2.3 训练细节
训练前的过滤
在训练选择器之前,论文做了一个轻量级的过滤:
- 如果一个问题无论给什么证据都几乎必对(太简单),剔除
- 如果一个问题无论给什么证据都几乎必错(不可解),也剔除
因为这两类问题无法提供有意义的学习信号------选择什么证据结果都一样。
选择器的奖励设计
选择器的训练采用强化学习,奖励由四部分组成:
| 奖励组件 | 作用 |
|---|---|
| 边界奖励 | 核心奖励。鼓励选出的证据让生成器正确率接近目标值(如 50%),太高或太低都扣分 |
| 相关性奖励 | 选中的文档平均检索分越高越好,确保不会为了追求难度而选无关文档 |
| 格式奖励 | 输出必须是合法的文档索引集合,格式错误直接零分 |
| 数量惩罚 | 鼓励选择接近目标数量的文档,偏离就扣分 |
生成器的奖励设计
生成器的训练同样采用强化学习,奖励由三部分组成:
| 奖励组件 | 作用 |
|---|---|
| 准确性奖励 | 答案的正确性,包括完全匹配和部分匹配 |
| 引用奖励 | 鼓励在推理过程中引用适量的文档,引用太少或太多都不给高分 |
| 格式奖励 | 输出必须符合规定格式,否则零分 |
2.4 推理阶段:不增加任何成本
这是 BAR-RAG 一个非常工程友好的设计:选择器只在训练时使用,推理时直接丢掉。
上线后的系统还是标准的 RAG 流程:检索器返回 Top-K 文档,生成器基于这些文档生成答案。唯一的区别是,生成器经过了"恰到好处"证据的训练,变得更强壮、更抗噪了。
这意味着:
- 不增加推理延迟
- 不增加推理成本
- 不改变线上架构
三、实验结果
3.1 实验设置
数据集:7 个知识密集型问答任务
- 单跳:Natural Questions (NQ)、TriviaQA、PopQA
- 多跳:HotpotQA、2WikiMultiHopQA、MuSiQue、Bamboogle
模型:
- Qwen-2.5-3B-Instruct
- Qwen-2.5-7B-Instruct
- LLaMA-3.1-8B-Instruct
评估指标:精确匹配(Exact Match, EM)
公平性:所有方法使用相同的检索器(E5-base-v2)、相同的重排器(Qwen-3-Embedding-8B)、相同的 Top-5 文档输入。
3.2 主要结果
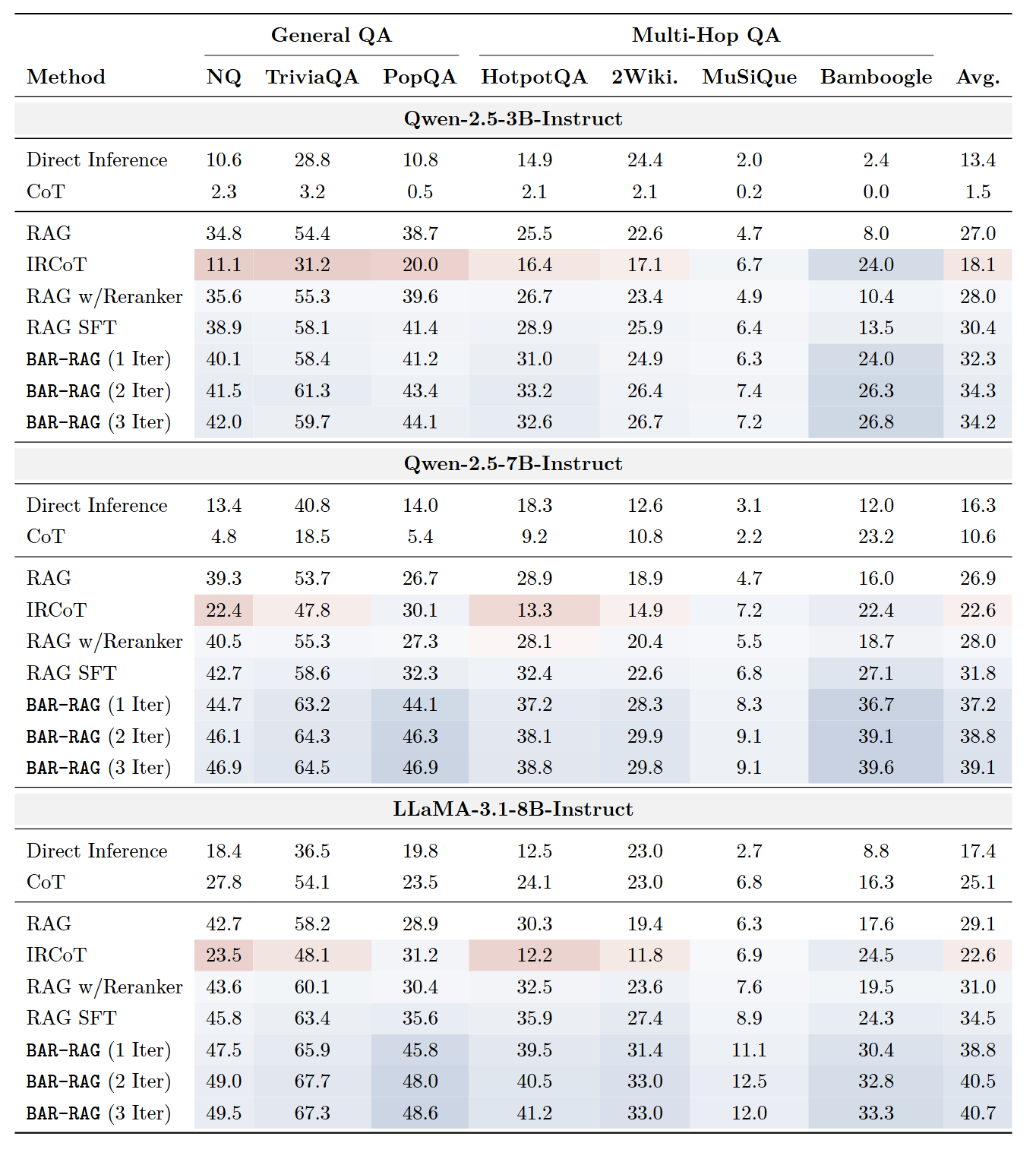
以 Qwen-2.5-7B-Instruct 为例:
-
大幅超越基线:BAR-RAG 相比标准 RAG 平均提升 12.2 个点,相比最强基线 RAG SFT 平均提升 7.3 个点
-
多跳任务提升更明显:在需要整合多个文档信息的任务上(如 Bamboogle +23.6),优势尤为突出
-
跨模型一致有效:在 LLaMA-3.1-8B 和 Qwen-2.5-3B 上也观察到类似的提升
3.3 证据数量变化时的鲁棒性
论文测试了当给生成器的证据数量变化时(从 1 篇到 30 篇),各方法的表现:
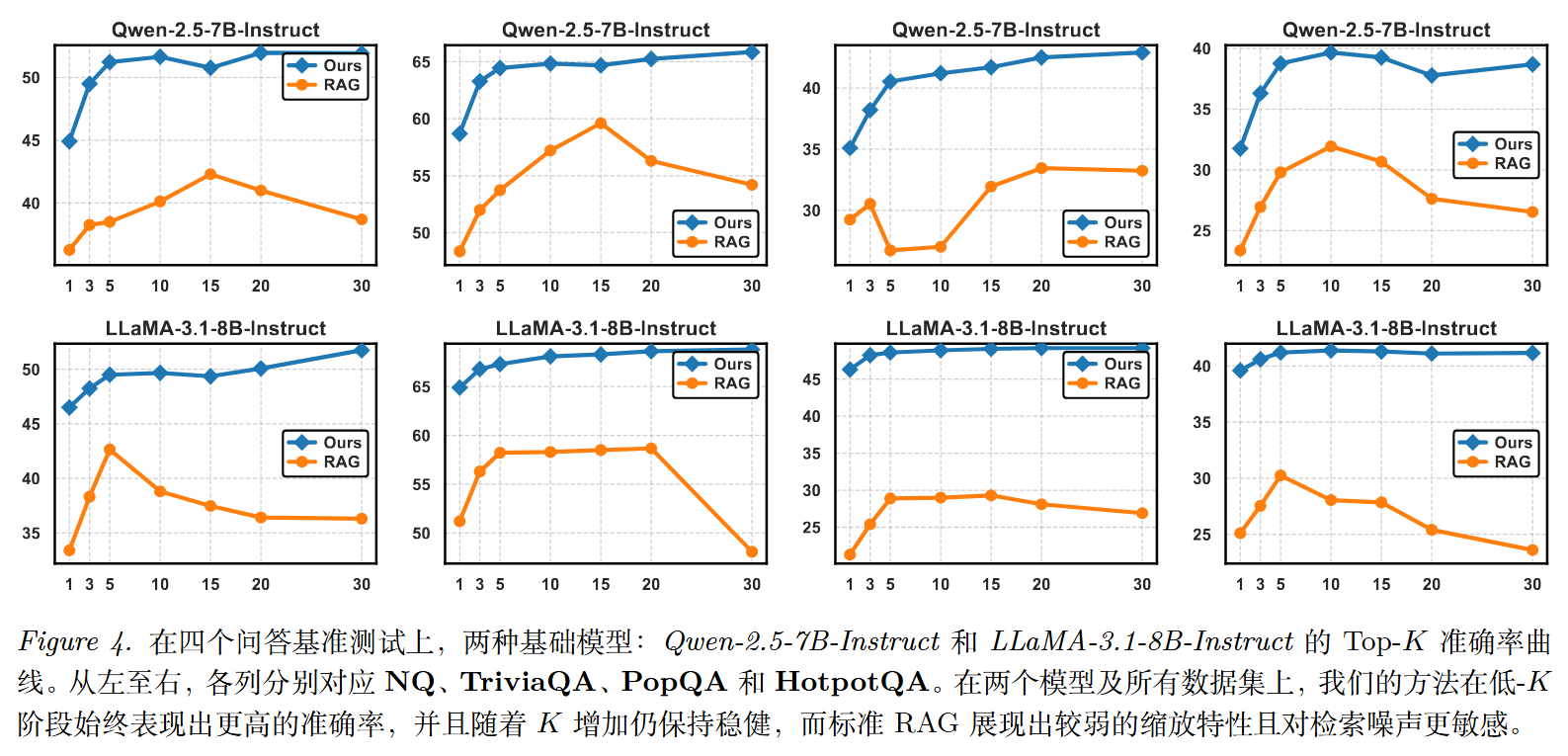
结果显示:
- 证据少时优势最大:当只给 1-3 篇文档时,BAR-RAG 的优势最明显------这正是最考验推理能力的情况
- 证据多时也更稳定:当文档数量增加(噪声也随之增加)时,BAR-RAG 的性能下降比其他方法更平缓
这说明经过"恰到好处"训练的生成器,真的学会了更强的推理和抗噪能力。
3.4 证据难度分布的变化
论文可视化了不同方法产生的证据难度分布:
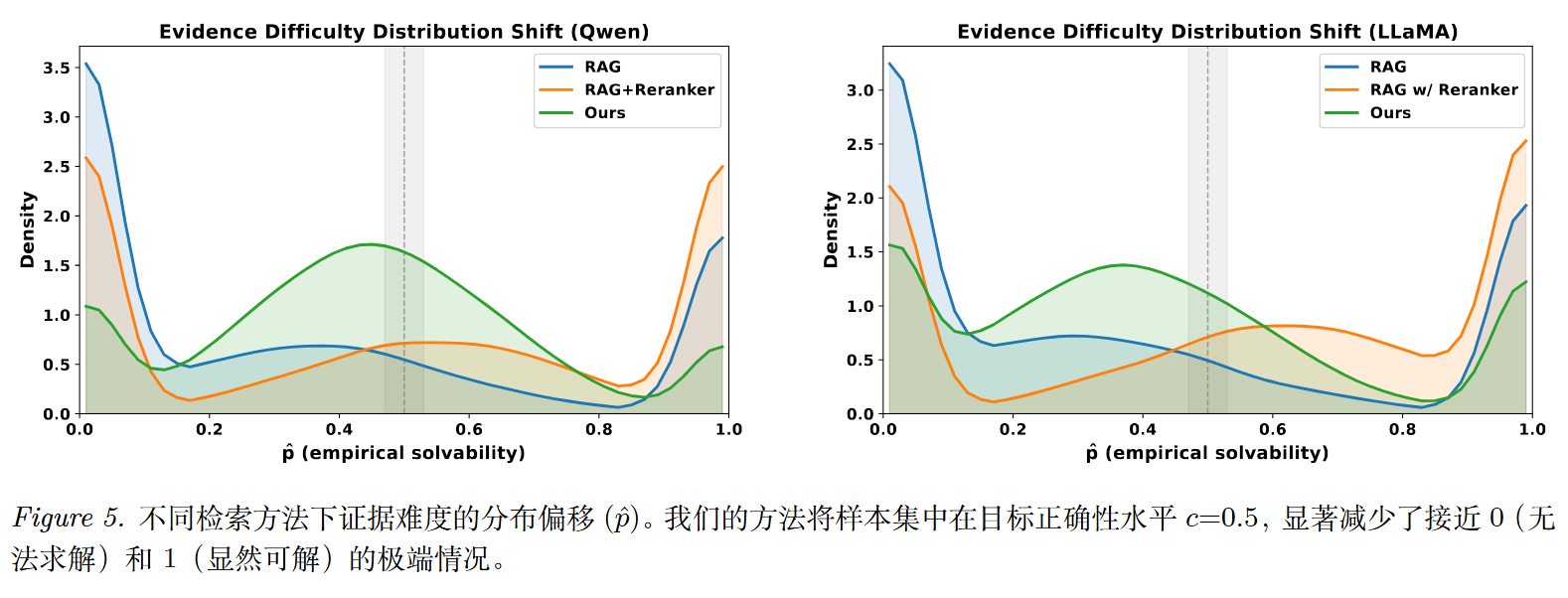
- 朴素 RAG / RAG + Reranker:呈现双峰分布,大量样本要么接近 0(不可解)要么接近 1(答案直给)
- BAR-RAG:将概率质量集中到 0.5 附近,显著减少了两个极端
这正好验证了论文的核心目标:让训练样本落在生成器的"能力边界"上。
3.5 消融实验
| 配置 | NQ | PopQA | HotpotQA | 平均 |
|---|---|---|---|---|
| 完整方法 | 46.9 | 46.9 | 38.8 | 44.2 |
| 去掉训练前过滤 | 42.6 | 32.1 | 32.3 | 35.6 |
| 去掉阶段1(选择器训练) | 42.1 | 42.5 | 41.9 | 42.2 |
| 去掉阶段2(生成器训练) | 39.7 | 34.1 | 36.7 | 36.8 |
| 去掉边界奖励 | 43.4 | 43.6 | 33.5 | 40.2 |
关键结论:
- 过滤很重要:去掉过滤后性能大幅下降,说明"太简单/不可解"的样本确实会干扰训练
- 两个阶段都不可或缺:去掉任何一个阶段都会导致明显退化
- 边界奖励是核心:去掉边界奖励后性能下降最明显,说明"瞄准能力边界"是最关键的设计
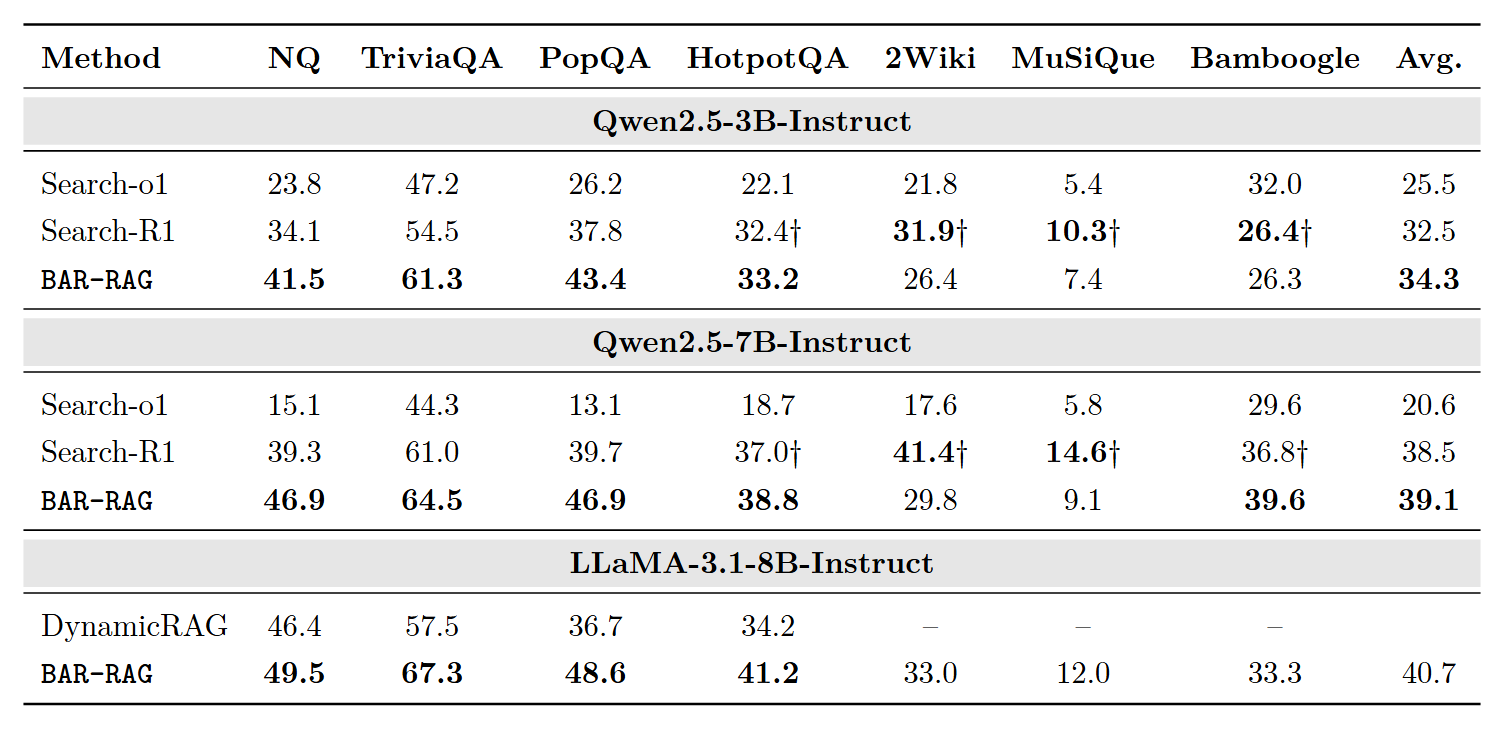
3.6 与 Search Agent 效果对比
Search Agent 通过扩展检索预算(检索-反思-补充检索)来提高整体回答效果,作者对比了 BAR-RAG 与 O1、R1 等深度研究模型,发现经过良好训练的生成器与这些使用了更多检索与推理算力的模型相比,仍具一战之力
四、后续研究方向
4.1 自适应的目标难度
当前论文使用固定的目标正确率(如 50%)。但不同类型的问题可能需要不同的目标:
- 简单问题可能 60-70% 更合适
- 复杂多跳问题可能 30-40% 更合适
未来可以让目标难度根据问题类型或生成器当前能力自适应调整。
4.2 降低 Rollout 成本
当前判断一组证据"是否恰到好处"需要让生成器多次尝试回答,统计正确率。这个过程比较耗时。
未来可以训练一个轻量级的"可解度预测器",直接预测一组证据对生成器的难度,而不需要实际生成答案。
4.3 推广到更多任务
"恰到好处"的思想不仅适用于问答:
- 多轮对话:上下文信息太全 vs 太少
- 工具调用:工具描述太详细 vs 太模糊
- 长文写作:参考材料太直接 vs 太零散
这些场景都存在类似的"太简单/太难"问题,BAR-RAG 的思路可能同样适用。
4.4 与 Agent RAG 融合
Search-o1、Search-R1 等方法通过多轮搜索来"找得更全",而 BAR-RAG 通过边界训练来"练得更稳"。
一个自然的想法是:让多轮搜索负责扩展候选池,让 BAR-RAG 的思想负责塑形训练分布,两者结合可能效果更好。