精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、选题背景意义
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
本系统专注于基于大数据技术的肺癌数据分析与可视化领域,旨在通过先进的数据处理手段挖掘医疗数据背后的深层价值。系统核心功能涵盖人口统计学特征分析、行为风险因素评估及临床症状关联挖掘等多个维度,通过热力图展示年龄与症状的相关性,利用随机森林算法计算各风险因素的权重,并构建肺癌风险预警指数。系统采用分布式计算框架对海量数据进行高效清洗与转换,通过直观的可视化图表将复杂的分析结果呈现出来,不仅为用户提供清晰的数据视图,还支持多维度的交叉分析与风险模式识别,从而辅助进行科学的健康评估与决策支持。
二、选题背景意义
选题背景
近年来,随着生活环境的变化和生活习惯的改变,肺部健康问题日益受到社会各界的广泛关注,肺癌已经成为威胁人类生命安全的主要疾病之一。面对海量的医疗健康数据,如何利用现代信息技术从中提取有价值的信息,辅助医生和研究人员进行早期的筛查与预防,成为了当前医疗信息化领域的重要研究方向。传统的数据分析方式往往难以处理大规模、多维度且关系复杂的医疗数据,导致很多潜在的致病因素和风险特征无法被及时发现。在这样的现实需求下,开发一套能够高效处理数据并进行深度挖掘的系统显得尤为迫切,这为利用大数据技术解决实际的医疗分析问题提供了广阔的应用场景。
选题意义
做这个课题主要是想尝试用数据技术来解决一些实际的医疗分析问题,虽然只是个毕业设计,但也希望能有一点实际的使用价值。系统通过对年龄、性别、生活习惯以及临床症状这些数据的深度关联分析,能把那些隐藏在数据背后的风险找出来,比如吸烟和饮酒到底对肺癌有多大影响,不同年龄段的人有哪些高发症状。这些分析结果不仅仅是为了展示图表,更是希望能给相关的筛查工作提供一点数据参考,帮助大家更直观地了解肺癌的风险因素。当然,系统肯定还有很多需要完善的地方,但在数据挖掘和可视化呈现方面的探索,对于提升数据分析在实际领域的应用还是有一定积极作用的。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
四、系统展示
项目页面模块展示:
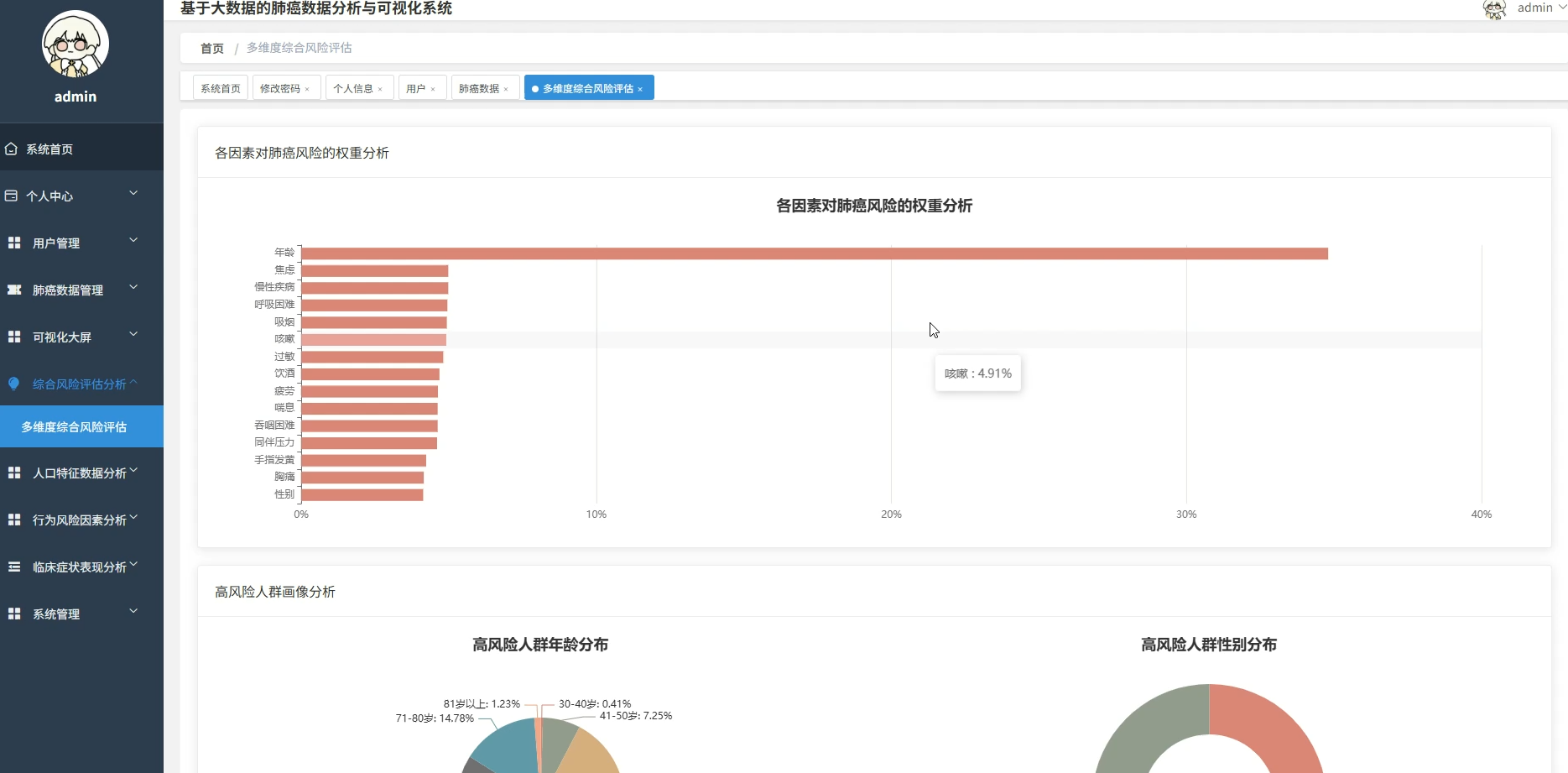
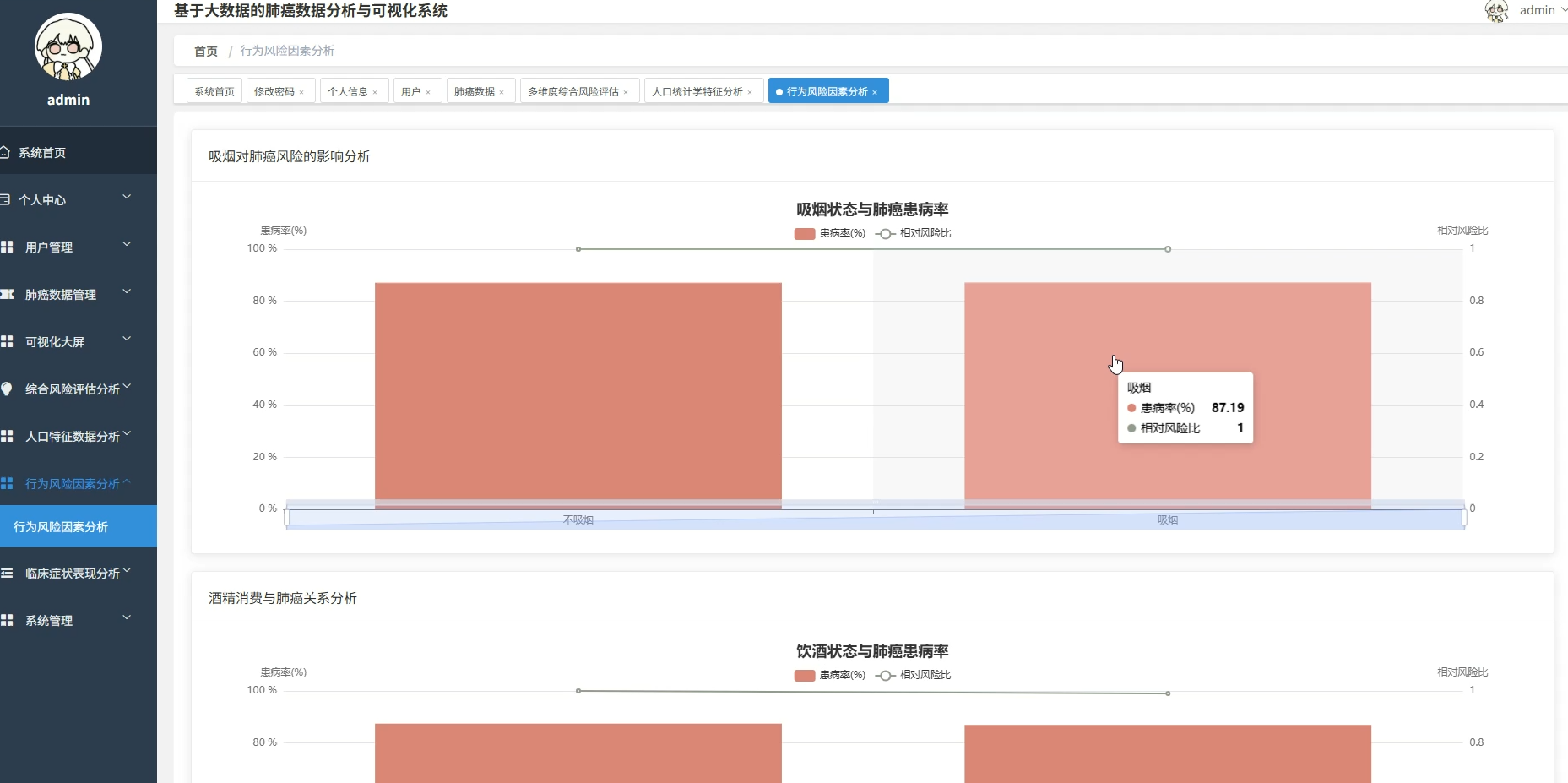
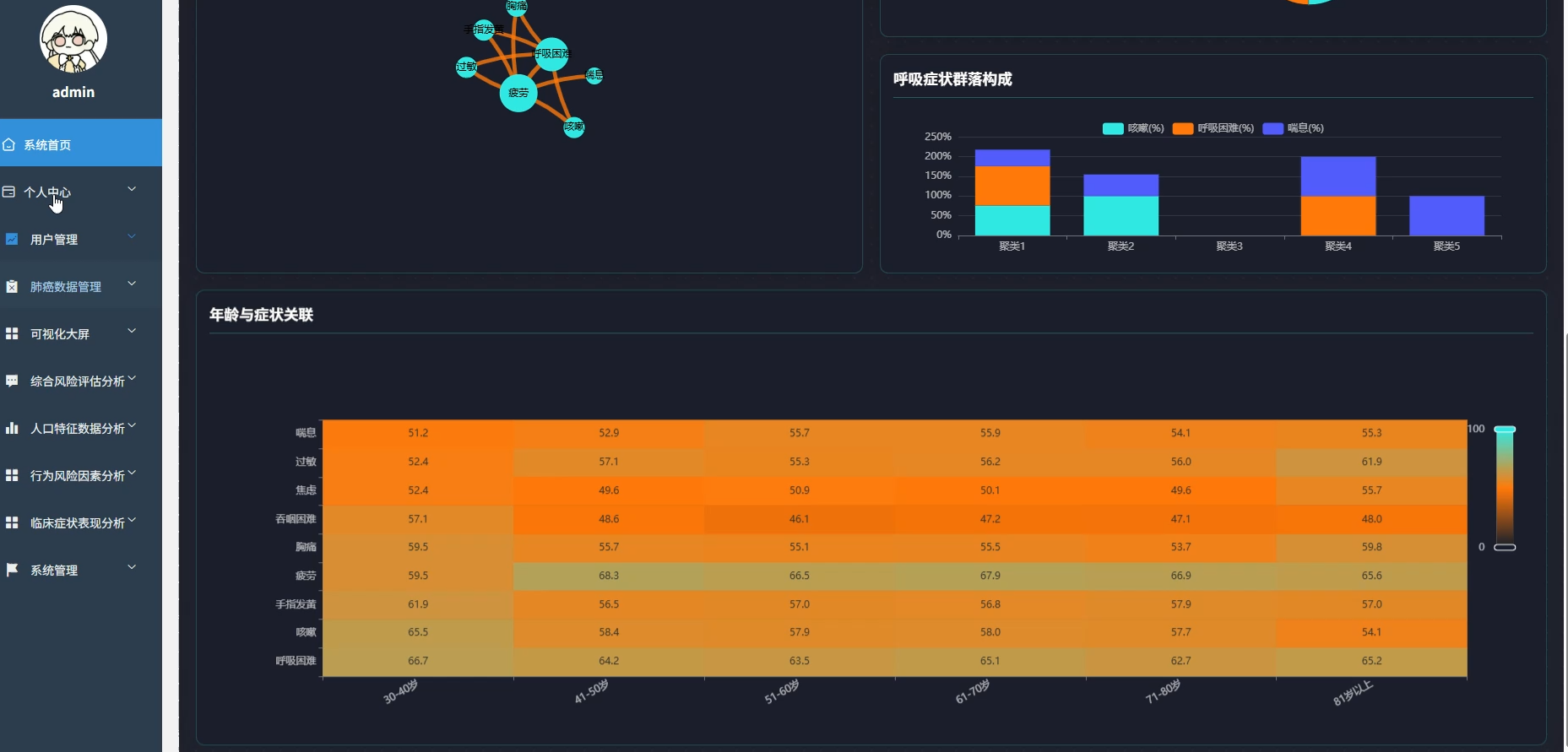
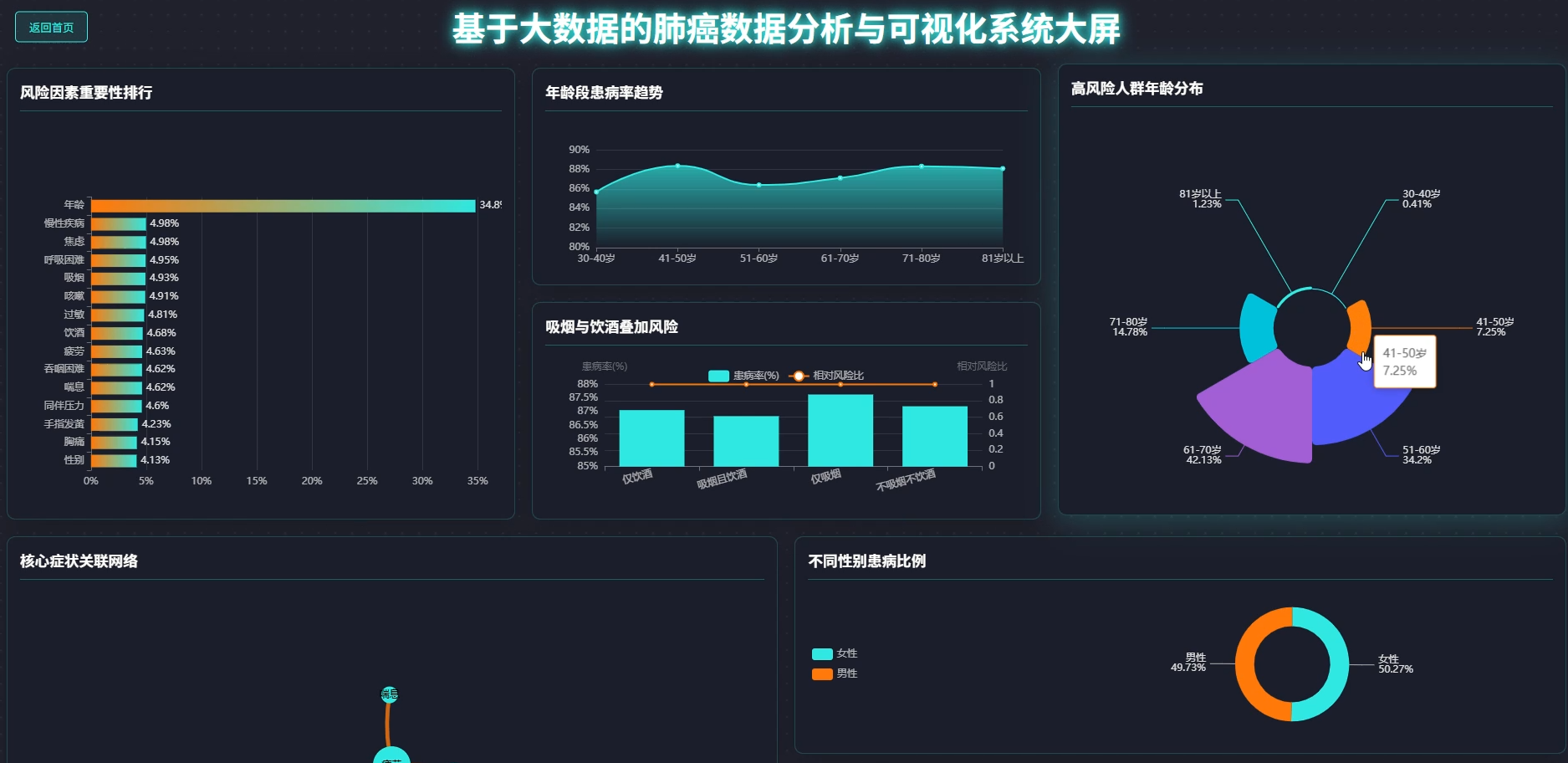
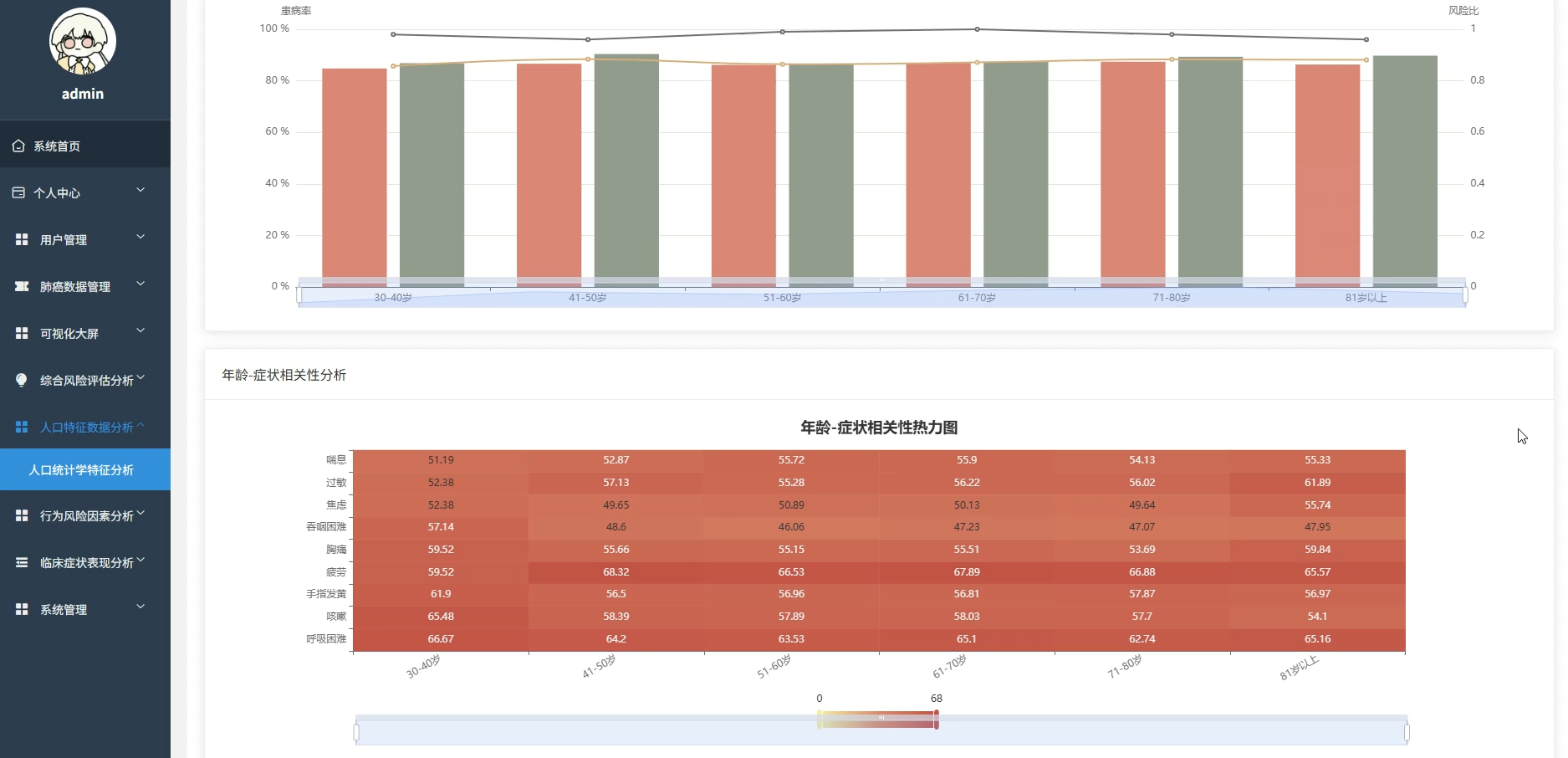
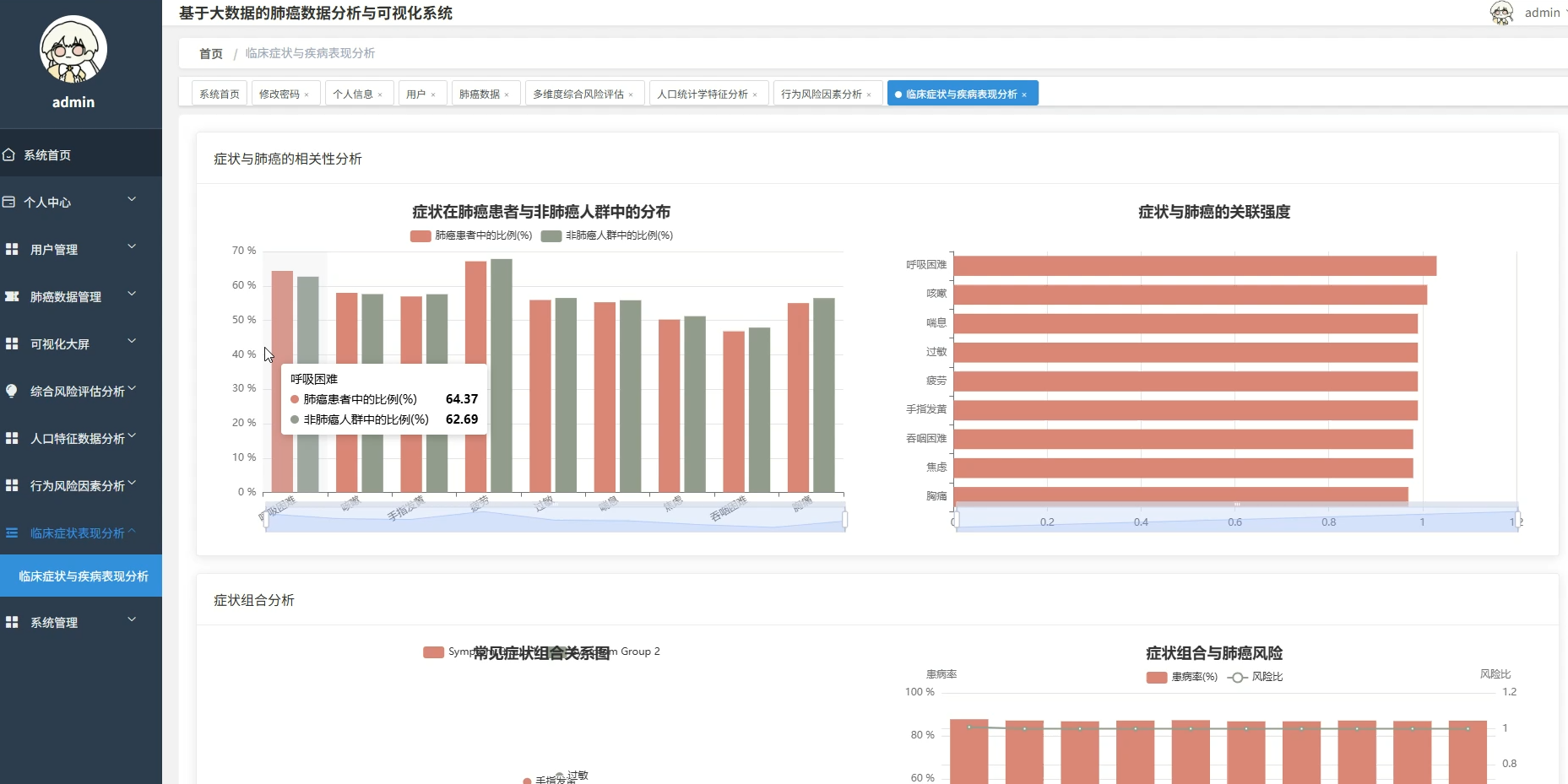
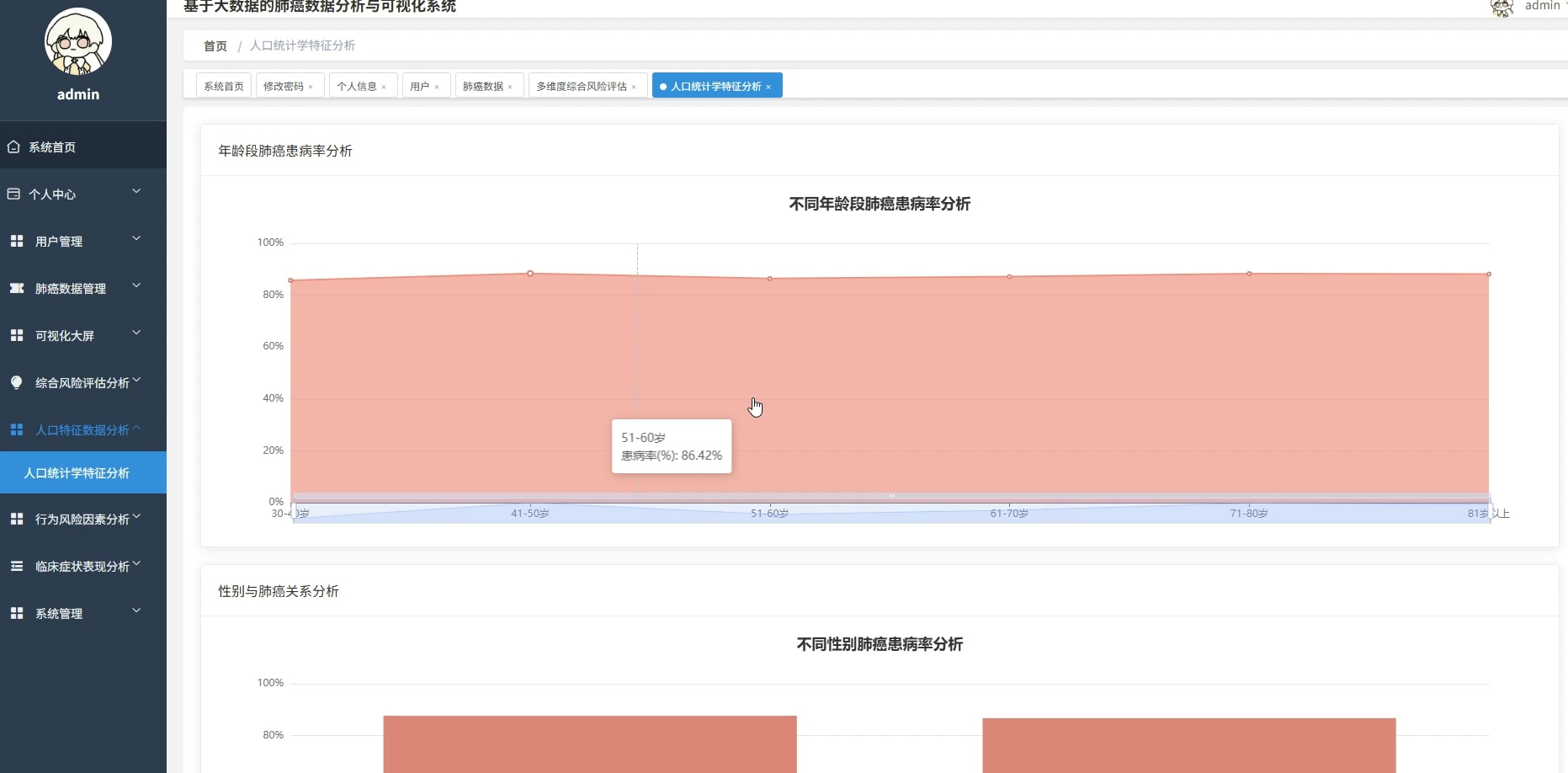
五、代码展示
bash
spark = SparkSession.builder.appName("LungCancerAnalysis").getOrCreate()
df = spark.read.csv("hdfs://data/lung_cancer.csv", header=True, inferSchema=True)
def analyze_age_symptom_heatmap(data_frame):
symptom_cols = ["YELLOW_FINGERS", "ANXIETY", "PEER_PRESSURE", "CHRONIC_DISEASE", "FATIGUE", "ALLERGY", "WHEEZING", "ALCOHOL_CONSUMING", "COUGHING", "SHORTNESS_OF_BREATH", "SWALLOWING_DIFFICULTY", "CHEST_PAIN"]
age_buckets = [(30, 40), (41, 50), (51, 60), (61, 70), (71, 80), (81, 100)]
def get_age_bucket(age):
for start, end in age_buckets:
if start <= age <= end:
return f"{start}-{end}"
return "Other"
bucket_udf = udf(get_age_bucket, StringType())
df_with_buckets = data_frame.withColumn("AgeGroup", bucket_udf(col("AGE")))
result_list = []
for symptom in symptom_cols:
group_data = df_with_buckets.groupBy("AgeGroup").agg(avg(col(symptom)).alias("avg_value")).collect()
for row in group_data:
result_list.append((row["AgeGroup"], symptom, float(row["avg_value"])))
return result_list
def analyze_risk_factors_accumulation(data_frame):
risk_cols = ["SMOKING", "ALCOHOL_CONSUMING", "PEER_PRESSURE"]
def count_risks(smoking, alcohol, peer):
count = 0
if smoking == 1: count += 1
if alcohol == 1: count += 1
if peer == 1: count += 1
return count
count_risks_udf = udf(count_risks, IntegerType())
df_with_counts = data_frame.withColumn("RiskCount", count_risks_udf(col("SMOKING"), col("ALCOHOL_CONSUMING"), col("PEER_PRESSURE")))
accumulation_stats = df_with_counts.groupBy("RiskCount").agg((sum(when(col("LUNG_CANCER") == 1, 1)).alias("cancer_count")), count("*").alias("total_count")).collect()
final_result = {}
for row in accumulation_stats:
risk_level = row["RiskCount"]
cancer_count = row["cancer_count"]
total = row["total_count"]
if total > 0:
final_result[risk_level] = cancer_count / total
return final_result
def random_forest_feature_importance(data_frame):
feature_columns = ["AGE", "SMOKING", "YELLOW_FINGERS", "ANXIETY", "PEER_PRESSURE", "CHRONIC_DISEASE", "FATIGUE", "ALLERGY", "WHEEZING", "ALCOHOL_CONSUMING", "COUGHING", "SHORTNESS_OF_BREATH", "SWALLOWING_DIFFICULTY", "CHEST_PAIN"]
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
df_assembled = assembler.transform(data_frame)
indexer = StringIndexer(inputCol="LUNG_CANCER", outputCol="label")
df_indexed = indexer.fit(df_assembled).transform(df_assembled)
train_data, test_data = df_indexed.randomSplit([0.8, 0.2], seed=42)
rf = RandomForestClassifier(labelCol="label", featuresCol="features", numTrees=100)
model = rf.fit(train_data)
importances = model.featureImportances.toArray()
feature_importance_map = dict(zip(feature_columns, importances))
sorted_features = sorted(feature_importance_map.items(), key=lambda x: x[1], reverse=True)
return sorted_features六、项目文档展示

七、项目总结
本次基于大数据的肺癌数据分析与可视化系统的设计与实现,是一次将大数据技术应用于医疗健康领域的有益尝试。系统从人口统计学、行为风险及临床症状等多个角度出发,利用Spark大数据处理框架,完成了数据清洗、关联分析及预测建模等一系列工作,成功实现了对肺癌风险因素的量化评估与可视化展示。虽然受限于时间和数据规模,系统在实际临床应用中还存在一定的局限性,但在数据挖掘算法的实现和交互式分析的探索上取得了预期的效果。这次毕设经历不仅加深了对大数据技术栈的理解,也锻炼了解决实际问题的能力,为今后的学习与工作积累了宝贵的经验。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖