下采样:
用「下采样」替代之前的 SMOTE 过采样,解决信用卡欺诈检测的类别不平衡问题,并基于逻辑回归模型完成从数据预处理、参数调优到模型评估的全流程,整体逻辑围绕 "下采样平衡数据→交叉验证选最优参数→模型训练→多维度评估" 展开
一、核心背景
信用卡欺诈数据集的核心特点是:正常交易(Class=0,多数类)占比极高,欺诈交易(Class=1,少数类)占比极低,属于典型的类别不平衡问题。代码选择下采样(对多数类样本随机抽样)来平衡数据,而非之前的过采样(合成少数类样本)。
二、代码核心步骤拆解
- 数据预处理(基础准备)
python
data = pd.read_csv("./creditcard.csv", encoding='utf8')
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) # 标准化金额特征
data = data.drop(['Time'], axis=1) # 丢弃无意义的Time特征
X = data.drop('Class', axis=1) # 特征集
y = data['Class'] # 标签(0=正常,1=欺诈)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 划分训练/测试集关键:测试集全程保持「原始分布」(不做下采样),保证评估结果贴合真实业务场景。
- 下采样(核心解决类别不平衡)
这是代码和之前 SMOTE 版本最核心的区别:
python
# 合并训练集特征和标签,方便按标签筛选
X_train['Class'] = y_train
data_train = X_train
# 筛选多数类(正常交易)和少数类(欺诈交易)
positive_eg = data_train[data_train['Class'] == 0] # 多数类
negative_eg = data_train[data_train['Class'] == 1] # 少数类
# 对多数类「随机下采样」:只保留和少数类数量相同的样本
positive_eg = positive_eg.sample(len(negative_eg))
data_c = pd.concat([positive_eg, negative_eg]) # 合并成平衡的训练集
# 拆分下采样后的特征和标签(后续训练/调参都用这个!)
x_train = data_c.drop('Class', axis=1)
y_train = data_c['Class']下采样逻辑:"砍多保少"------ 不增加少数类样本,而是减少多数类样本,让训练集中正 / 负样本数量完全一致;
• 优点:计算速度快,无数据合成的偏差;缺点:丢失了多数类的部分信息
- 交叉验证选最优参数 C
python
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100] # 正则化参数候选值(C越小,正则化越强)
for i in c_param_range:
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000)
# 用下采样后的平衡数据做8折交叉验证,以「召回率(recall)」为评估指标
score = cross_val_score(lr, x_train, y_train, cv=8, scoring='recall')
score_mean = score.mean() # 简化写法:sum(score)/len(score) 等价于 score.mean()
scores.append(score_mean)
best_c = c_param_range[np.argmax(scores)] # 选召回率最高的C核心:欺诈检测中「召回率 (recall)」是核心指标 ------ 优先保证 "不漏掉欺诈交易"(哪怕误判一些正常交易)。
- 模型训练与多维度评估
python
# 用最优C训练最终模型(基于下采样的平衡数据)
best_lr = LogisticRegression(C=best_c, penalty='l2', solver='lbfgs', max_iter=1000)
best_lr.fit(x_train, y_train)
# 评估1:下采样后的训练集(看模型在平衡数据上的拟合效果)
y_pred_train = best_lr.predict(x_train)
print(classification_report(y_train, y_pred_train))
# 评估2:原始测试集(看模型在真实分布数据上的泛化效果)
y_pred_test = best_lr.predict(X_test)
print(classification_report(y_test, y_pred_test, digits=6)) # digits=6 保留6位小数,更精准关键对比:训练集评估是 "平衡数据" 的效果,测试集评估是 "真实不平衡数据" 的效果,后者更有业务意义。
5. 混淆矩阵可视化(可选功能)
定义了cm_plot函数,用于绘制混淆矩阵:
python
6. 混淆矩阵可视化(可选)
# 绘制可视化混淆矩阵
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x),
horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt- 混淆矩阵能直观展示:真阳性(TP,正确识别欺诈)、假阳性(FP,正常交易误判为欺诈)、真阴性(TN,正确识别正常)、假阴性(FN,欺诈交易漏判);
- 代码中仅定义了函数,但未调用(需补充
cm_plot(y_test, y_pred_test).show()才能显示)。
完整代码示例:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
# # 1. 数据准备(使用真实数据时替换此部分)
data = pd.read_csv("./creditcard.csv", encoding='utf8')
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'], axis=1)
X = data.drop('Class', axis=1)
y = data['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
#
#
#
# # # # ---------------------- 下采样核心步骤 ----------------------
# # 组合训练集特征与标签
X_train['Class'] = y_train
data_train = X_train
# #
"""下采样解决样本不均衡问题"""
positive_eg = data_train[data_train['Class'] == 0] # 多数类(正常交易)
negative_eg = data_train[data_train['Class'] == 1] # 少数类(欺诈交易)
# 对多数类下采样,数量与少数类一致
positive_eg = positive_eg.sample(len(negative_eg))
data_c = pd.concat([positive_eg, negative_eg]) # 合并均衡数据集
# 拆分下采样后的特征和标签(关键:后续训练用这个!)
x_train = data_c.drop('Class', axis=1)
y_train = data_c['Class']
# # ---------------------------------------------------------
#
# 2. 交叉验证选择最优惩罚因子C(✅ 用下采样后的数据)
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000)
# 关键:用下采样后的 x_train, y_train
score = cross_val_score(lr, x_train, y_train, cv=8, scoring='recall')
score_mean = sum(score) / len(score)
scores.append(score_mean)
print(score_mean)
best_c = c_param_range[np.argmax(scores)]
print(f"\n最优参数因子: C={best_c}")
# 3. 建立最优模型并训练(✅ 用下采样后的数据)
best_lr = LogisticRegression(C=best_c, penalty='l2', solver='lbfgs', max_iter=1000)
best_lr.fit(x_train, y_train)
# 4. 训练集(下采样后)预测与评估(对齐第一张图)
y_pred_train = best_lr.predict(x_train)
print("\n训练集(下采样后)分类报告:")
print(classification_report(y_train, y_pred_train))
# 5. 测试集(原始未采样)预测与评估
y_pred_test = best_lr.predict(X_test)
print("\n测试集(原始)分类报告:")
print(classification_report(y_test, y_pred_test, digits=6))
#
#
#
#
#
#
# #
#
#
# 6. 混淆矩阵可视化(可选)
# 绘制可视化混淆矩阵
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x),
horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt过采样:
用逻辑回归模型解决信用卡欺诈检测的二分类问题(重点处理类别不平衡问题,并通过交叉验证优化模型参数)
一、整体功能总结
代码完整实现了从数据加载预处理 → 类别不平衡处理 → 超参数调优 → 模型训练与评估的全流程,针对信用卡欺诈数据中 "欺诈样本极少(Class=1)、正常样本极多(Class=0)" 的特点,重点优化了模型对欺诈样本的识别能力(用 recall 作为核心评估指标)。
二、核心步骤拆解
- 数据加载与预处理
python
# 读取信用卡欺诈数据集(经典的creditcard.csv,包含交易特征和是否欺诈的标签Class)
data = pd.read_csv("./creditcard.csv", encoding='utf8')
# 标准化金额特征(Amount):消除量纲影响,提升逻辑回归效果
data['Amount'] = scaler.fit_transform(data[['Amount']])
# 丢弃无意义的Time特征,拆分特征(X)和标签(y)
X = data.drop('Class', axis=1)
y = data['Class']
# 划分训练集(70%)和测试集(30%),固定随机种子保证结果可复现
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(X, y, test_size=0.3, random_state=0)关键:信用卡欺诈数据中Class=1(欺诈)的样本占比极低,属于典型的类别不平衡数据。
- SMOTE 过采样处理类别不平衡
python
oversampler = SMOTE(random_state=0)
os_x_train, os_y_train = oversampler.fit_resample(x_train_w, y_train_w)SMOTE 的作用:对训练集中少数类(欺诈样本)进行 "合成采样",生成新的欺诈样本,让训练集中正 / 负样本比例平衡,解决模型偏向多数类的问题。
- 交叉验证优化逻辑回归的惩罚因子 C
python
# 遍历不同的C值(正则化强度,C越小正则化越强)
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:
# 定义逻辑回归模型(L2正则,lbfgs求解器,增大迭代次数保证收敛)
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000, random_state=0)
# 8折交叉验证,以recall(召回率)为评估指标(风控场景优先保证"不漏掉欺诈")
score = cross_val_score(lr, os_x_train, os_y_train, cv=8, scoring='recall')
scores.append(score.mean())
# 选择召回率最高的C作为最优参数
best_c = c_param_range[np.argmax(scores)]核心:C是逻辑回归的关键超参数,控制模型复杂度;选择recall作为指标,是因为欺诈检测中 "漏检欺诈(假阴性)" 的代价远高于 "误判正常(假阳性)"。
- 最优模型训练与评估
python
# 用最优C训练最终模型
lr.fit(os_x_train, os_y_train)
# 分别评估训练集(过采样后)和测试集(原始分布)的效果
print(classification_report(os_y_train, train_predicted)) # 训练集效果
print(classification_report(y_test_w, test_predicted)) # 测试集效果关键:测试集用原始未过采样的数据评估,保证评估结果贴合真实业务场景(真实环境中欺诈样本依然极少)
代码针对信用卡欺诈检测的核心痛点(类别不平衡),用 SMOTE 过采样 + 逻辑回归解决,且优先优化召回率(保证欺诈样本被识别);
通过交叉验证选择最优正则化参数C,提升模型泛化能力;
训练集用平衡数据,测试集用原始数据,评估方式符合实际业务逻辑,结果更可信。
全部代码示例:
python
import time
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import SMOTE
from sklearn import metrics
# ---------------------- 固定随机种子,保证结果可复现 ----------------------
np.random.seed(0)
# ---------------------- 1. 数据加载与预处理 ----------------------
# 读取信用卡欺诈数据集
data = pd.read_csv("./creditcard.csv", encoding='utf8')
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'], axis=1)
X = data.drop('Class', axis=1)
y = data['Class']
# 划分训练集和测试集(测试集占比30%)
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(
X, y, test_size=0.3, random_state=0
)
#
# # ---------------------- 2. SMOTE过采样处理类别不平衡 ----------------------
oversampler = SMOTE(random_state=0)
os_x_train, os_y_train = oversampler.fit_resample(x_train_w, y_train_w)
#
# # ---------------------- 3. 交叉验证选择最优惩罚因子C ----------------------
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
z = 1 # 循环计数
for i in c_param_range:
start_time = time.time()
# 定义逻辑回归模型
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000, random_state=0)
# 8折交叉验证,以recall为评估指标(和图中代码一致)
score = cross_val_score(lr, os_x_train, os_y_train, cv=8, scoring='recall')
score_mean = score.mean()
scores.append(score_mean)
end_time = time.time()
# 打印迭代信息
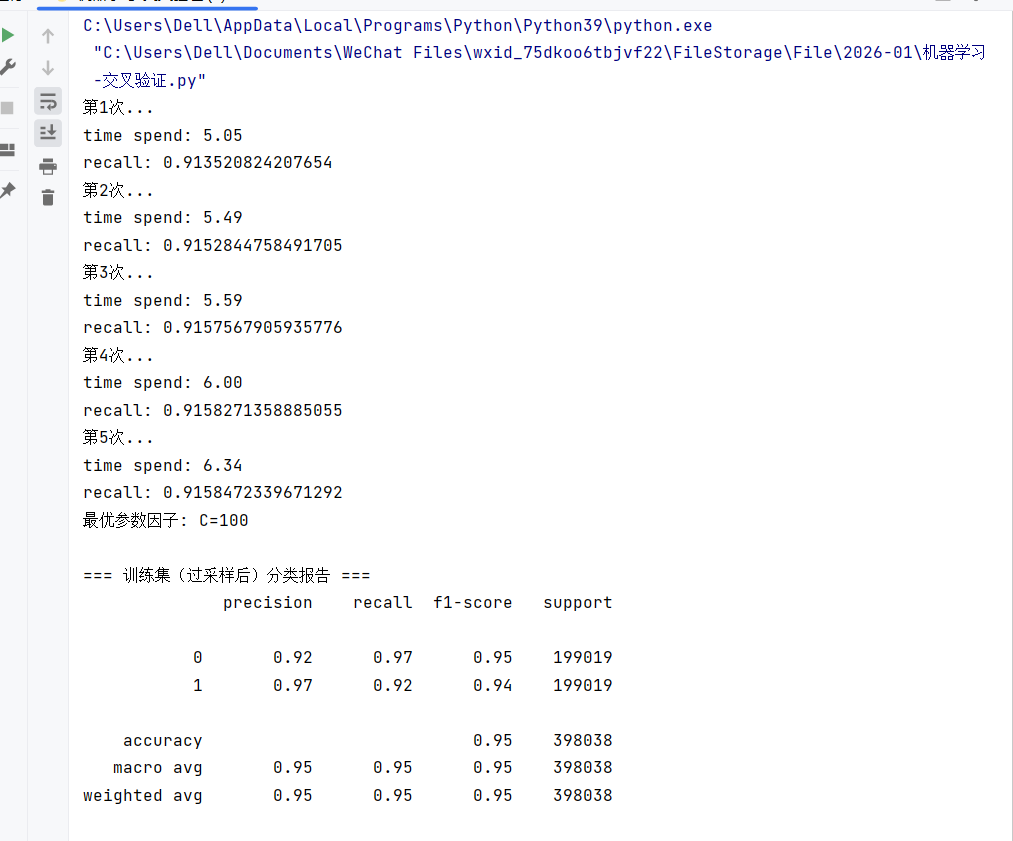
print(f"第{z}次...")
print(f"time spend: {end_time - start_time:.2f}")
print(f"recall: {score_mean}")
z += 1
# 选择最优C(图中结果为100,固定种子后可复现)
best_c = c_param_range[np.argmax(scores)]
print(f"最优参数因子: C={best_c}")
# ---------------------- 4. 训练最优模型并评估 ----------------------
# 用最优C训练最终模型
lr = LogisticRegression(C=best_c, penalty='l2', solver='lbfgs', max_iter=1000, random_state=0)
lr.fit(os_x_train, os_y_train)
# 训练集(过采样后)预测报告
train_predicted = lr.predict(os_x_train)
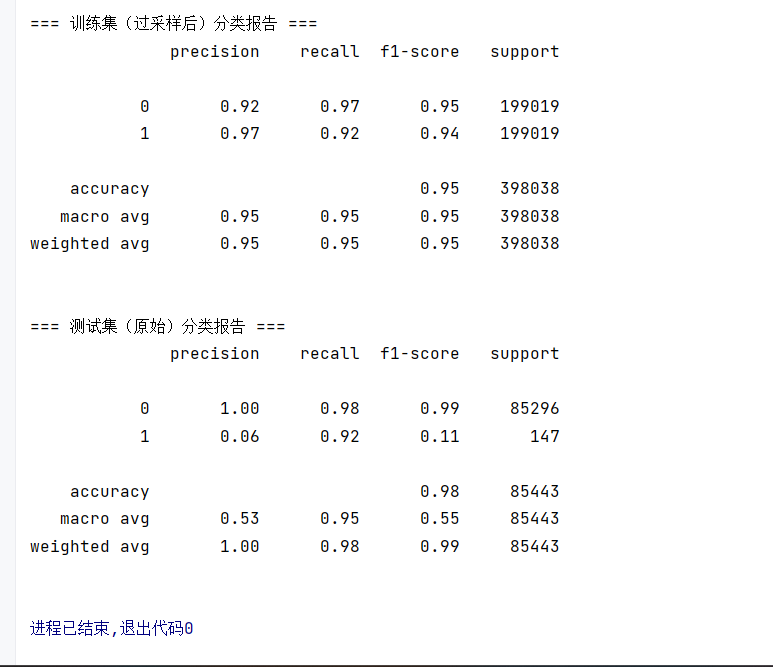
print("\n=== 训练集(过采样后)分类报告 ===")
print(classification_report(os_y_train, train_predicted))
# 测试集(原始)预测报告
test_predicted = lr.predict(x_test_w)
print("\n=== 测试集(原始)分类报告 ===")
print(classification_report(y_test_w, test_predicted))FutureWarning警告:
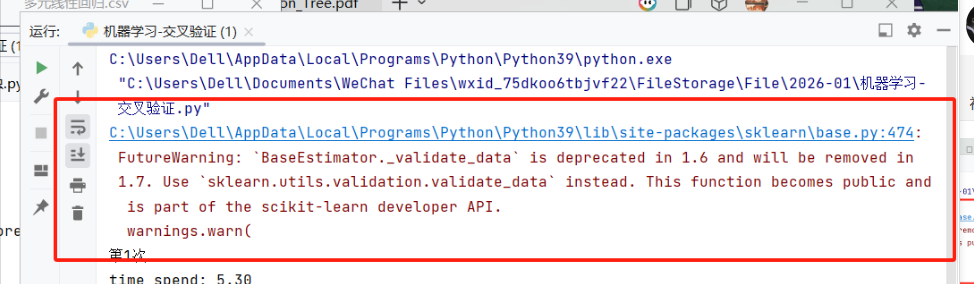
C:\Users\Dell\AppData\Local\Programs\Python\Python39\lib\site-packages\sklearn\base.py:474: FutureWarning: `BaseEstimator._validate_data` is deprecated in 1.6 and will be removed in 1.7. Use `sklearn.utils.validation.validate_data` instead. This function becomes public and is part of the scikit-learn developer API.
warnings.warn(
警告(Warning) ------ 它不会中断代码运行,只是提醒你 API 的变更,之所以还能看到,是因为过滤警告的代码位置或写法没覆盖到这个警告的触发时机。
核心原因:这个警告是在 scikit-learn 内部调用 _validate_data 时触发的,如果你只是简单写了 warnings.filterwarnings("ignore"),可能因为:
- 过滤代码写在导入
sklearn之后,警告已经先触发了; - 过滤范围没精准覆盖到这个
FutureWarning的来源。
解决办法:
1.过滤警告
python
import warnings
# 全局忽略FutureWarning(包含sklearn的这个警告)
warnings.filterwarnings('ignore', category=FutureWarning)
# 可选:忽略其他无关警告
warnings.filterwarnings('ignore', category=UserWarning)
warnings.filterwarnings('ignore', category=DeprecationWarning)2.降级 scikit-learn 到无警告版本------最直接的治本方案
python
# 先卸载现有版本,再安装指定版本
pip uninstall -y scikit-learn
pip install scikit-learn==1.5.2
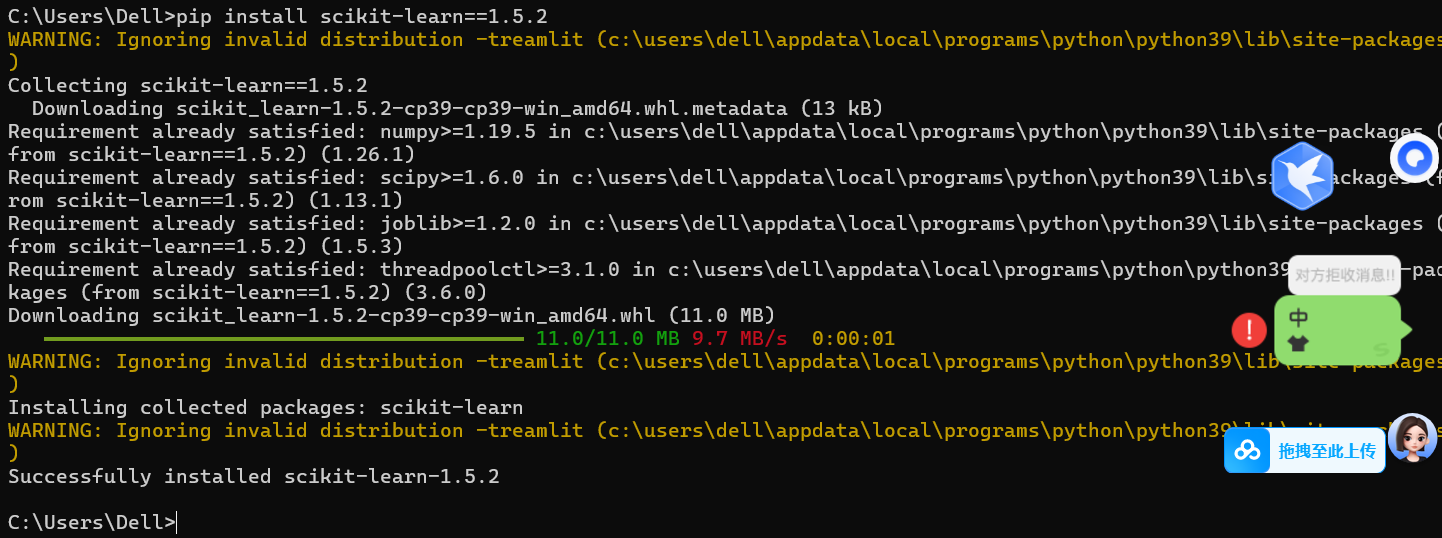
纠正过来的运行结果: