0、回顾
在上一篇博客中,已经复习梳理了关于以顺序存储的线性表(顺序表 ),对顺序表的优点和缺点也有了比较全面的认识。顺序表要求占用连续的内存空间,静态顺序表需一次性定长申请,动态顺序表虽可扩容但扩容仍会产生内存开销,整体空间利用效率非常有限;并且对顺序表表头或表中增删元素时,需要移动大量的数据,操作效率较低。但顺序表的缓存利用率高,支持元素的随机访问,因此,顺序表比较适合用在元素需要高效存储和频繁随机访问的场景。
在本篇博客中,接着上一篇顺序表的内容,对另一种按链式存储的线性表(链表 )展开详细的复习梳理,内容将主要聚焦于链表的基本知识概念和程序代码设计。
数据结构复习 | 顺序表-CSDN博客![]() https://blog.csdn.net/weixin_49337111/article/details/157357799?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_49337111/article/details/157357799?spm=1001.2014.3001.5502
1、什么是单向链表
链表就是由一个或多个含有指针成员的结构体,通过其指针成员的地址指向,形成了一种逻辑上的链式数据结构,并且把每个结构体变量称为该链表的结点(node)。链表的物理存储结构上是非连续、非顺序的,链表的数据元素的逻辑顺序,通过指针连接实现。
链表中,主要分为无头结点的单向链表 、有头结点的 单向链表 ,双向链表、循环链表。这些不同链表的操作都是差不多的,只是指针数目的异同。以最简单的单向链表为例,其基本示意图如下所示:

在上图中所有的链表节点中,都保存着一个指针,指向其逻辑上相邻的下一个节点(末尾节点指向空)。另外也可以注意到,整条链表中用了一个的头指针 head 来指向,由 head 开始可以找到链表中的任意一个节点。这个head 也通常被称为头指针。
2、单向链表特点总结
链式存储中,所有节点的存储位置是随机的,他们之间的逻辑关系用指针来确定,跟物理存储位置无关,因此链表的增删数据操作都非常迅速,不需要移动任何数据。另外,又由于存储的位置与逻辑关系无关,因此也无法直接访问某一个指定的节点,只能从头到尾按遍历的方式一个个找到想要的节点。简单讲,链式存储的优缺点跟顺序存储几乎是相对的。
优点:(1)插入、删除时只需要调整几个指针,无需移动任何数据;(2)当数据节点数量较多时,无需一整片较大的连续内存空间,可以灵活利用离散的内存;(3)当数据节点数量变化剧烈时,内存的释放和分配灵活,速度快。
缺点:(1)在节点中,需要多余的指针来记录节点之间的关联。(2)所有数据都是随机存储的,不支持立即访问任意一个随机数据。
假设链表的长度为n,单向链表的时间复杂度和空间复杂度如下:
增节点: 链表是通过记录头部地址来进行寻找后面数值的,所以需要遍历链表操作,如果在头部增,只需要查找一次,其时间复杂度是O(1),在尾部增需要查找n次,时间复杂度是O(n)。
删节点、查节点、改节点: 如果想要找到对应的元素进行操作(删查改),对于链表,没办法使用二分查找,只能进行遍历查找,找到该节点后再操作(删查改),其平均查找次数是n/2,时间复杂度是 O(n)。(其中,如果是删除表头元素,那么对应的时间复杂度为O(1))
链表的空间复杂度为O(n)。
3、单向链表基础功能代码
对链表进行操作时,一般包括:节点设计、初始化空链表、增删节点、链表遍历、销毁链表。
(1)、节点设计
在链表的节点中应该包含有两个东西分别是数据以及一个指针(指向下一个节点),因此该指针称为后继指针;
节点的设计就分成两个部分: 数据域、指针域
cpp
typedef int ElemType_t;
typedef struct node{
ElemType_t data; //数据域
struct node *next; //指针域
}Node_t;(2)、初始化空链表
链表分两种:带有头结点的链表(推荐)和不带头结点的链表。
初始化创建一个新链表的思路步骤:
①、定义一个头指针
②、让头指针指向头结点(不存放有效数据)
③、让头节点的后继指针指向空NULL 即可
④、返回头指针的值(头节点的入口地址)
cpp
//创建一条只有数据的首结点链表
Node_t* create_list(ElemType_t inputData)
{
//1、申请链表首结点的内存空间
struct node*head = malloc(sizeof(struct node));
if(head == NULL)
{
perror("malloc head error");
return NULL;
}
//2、初始化
head->data = inputData;
head->next = NULL;
//3、返回链表的首结点地址
return head;
}(3)、插入节点
在链表中插入数据时,有头插法和尾插法。
头插法是一种将新节点插入到链表前端的方法。这种方法的特点是新插入的节点总是成为新的头节点,因此插入操作后链表中节点的顺序与插入顺序相反。
尾插法是将新节点插入到链表末端的方法。这种方法的特点是新插入的节点总是成为新的尾节点,因此插入操作后链表中节点的顺序与插入顺序相同。
cpp
//新建一个节点、使用尾插法将其插入到链表中
int insert_nodeToList_tail(Node_t* head,ElemType_t insertData)
{
if(head == NULL){
printf("insert_nodeToList_tail error ,head is NULL\n");
return -1;
}
//1、申请新结点的内存空间
Node_t*newNode = malloc(sizeof(Node_t));
if(newNode == NULL)
{
perror("malloc newNode error");
return -1;
}
//2、并且初始化
newNode->data = insertData;
newNode->next = NULL;
Node_t*p = head;
Node_t*pre = NULL;//存储p的上一个结点的地址
//3、遍历链表,找到最后一个结点
while(p)//p!=NULL
{
pre = p;
p = p->next;
}
//此时 pre才是最后一个结点
//4、最后一个结点的next成员存储 新结点的地址
pre->next = newNode;
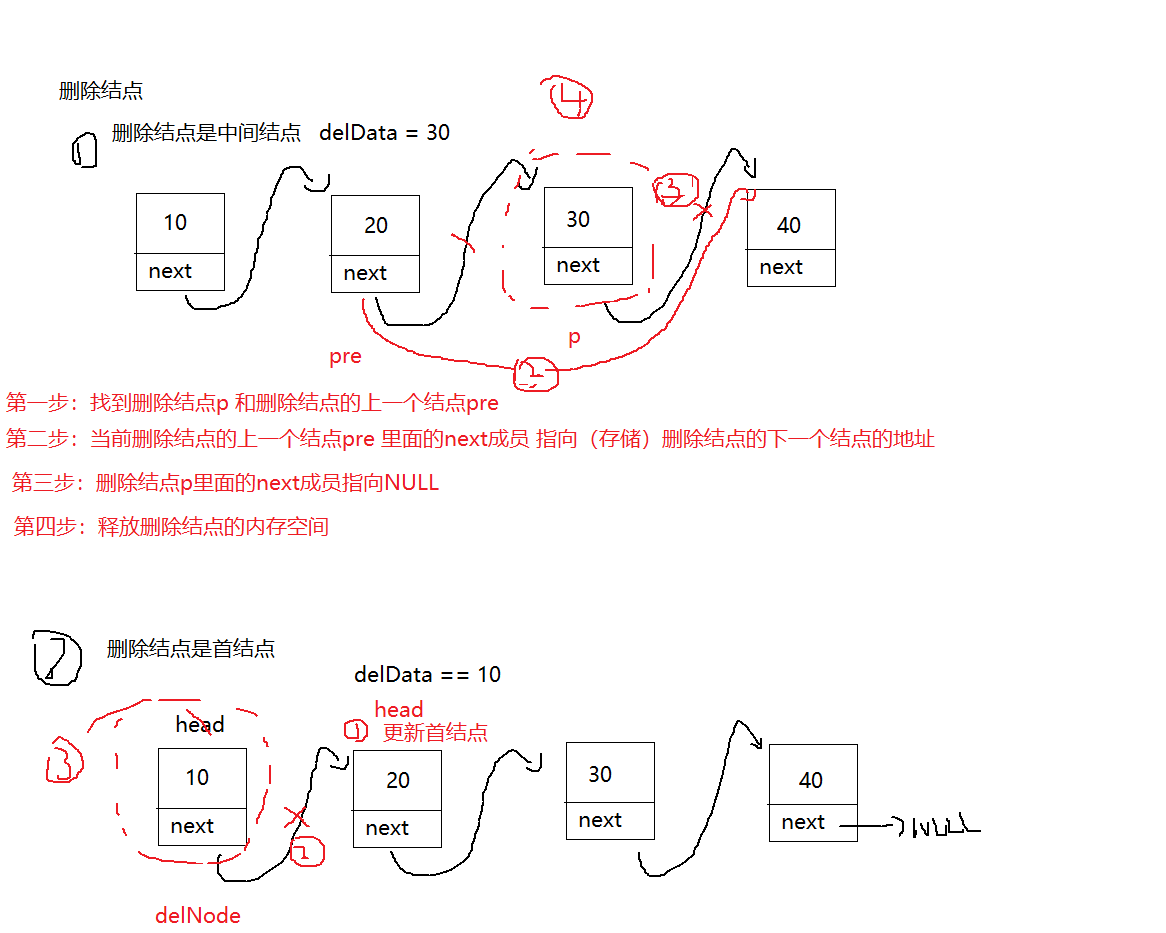
}(4)、删除节点
cpp
//从链表中删除值为delData的结点
Node_t* delete_nodeToList(Node_t* head, ElemType_t delData)
{
//1、先判断当前链表是否为空
if(head == NULL){
printf("head is NULL,delete_nodeToList error\n");
return false;
}
//如果你当前删除的结点是首结点
if(head->data == delData){
Node_t* delNode = head;
//第一步:更新首结点
head = head->next;
//第二步:删除结点断链接
delNode->next = NULL;
//第三步:释放删除结点的内存空间
free(delNode);
//第三步:返回 新的首结点的地址
return head;
}
//2、遍历链表,先找到你要删除的那个结点
Node_t* p = head;
Node_t* pre = NULL; //记录删除结点的上一个结点的地址
bool isFindFlag = false;
while(p)
{
if(p->data == delData)
{
isFindFlag = true;
break;
}
pre = p;
p = p->next;
}
//printf("删除结点 p->data:%d\n",p->data);
//printf("删除结点的上一个结点 pre->data:%d\n",pre->data);
//如果没有找到删除结点直接返回false
if(isFindFlag == false)
return false;
//说明已经找到了
//第二步:当前删除结点的上一个结点pre里面的next成员指向(存储)删除结点的下一个结点的地址
pre->next = p->next;
//第三步:删除结点p 断链接
p->next = NULL;
//第四步:释放删除结点的内存空间
free(p);
return head;
}(5)、查找节点
cpp
//查找某个指定的数据 是否在链表中
bool find_nodeToList(Node_t* head,ElemType_t findData)
{
if(head == NULL){
printf("head is NULL,find_nodeToList error\n");
return false;
}
bool isFindFlag = false;
//遍历链表,挨个元素与 findData 进行比较
Node_t *p = head;
while(p)
{
if(p->data == findData)
{
isFindFlag = true;
break;
}
p = p->next;
}
return isFindFlag;
}(6)、修改链表
cpp
//修改链表中指定的旧数据为新数据
bool modify_nodeToList(Node_t* head, ElemType_t oldData, ElemType_t newData)
{
// 1. 链表为空,直接返回修改失败
if (head == NULL)
{
printf("head is NULL, modify_nodeToList error\n");
return false;
}
// 2. 遍历链表,找到存储oldData的节点
Node_t* p = head;
while (p != NULL)
{
if (p->data == oldData)
{
// 3. 找到目标节点,更新数据域为新数据
p->data = newData;
return true; // 修改成功,直接返回
}
p = p->next;
}
// 4. 遍历完链表未找到目标数据,返回修改失败
printf("未找到值为 %d 的节点,修改失败\n", oldData);
return false;
}(7)、链表遍历
cpp
//遍历打印链表中所有的元素
void print_all_list_element(Node_t* head)
{
if(head == NULL){
printf("head is NULL,print_allToList error\n");
return;
}
Node_t*p = head;
while(p)//p!=NULL
{
printf("%d\t",p->data);
p = p->next;
}
printf("\n");
}(8)、销毁链表
销毁链表的核心逻辑是先存下一个节点,再释放当前节点,避免丢失链表后续节点。
使用二级指针传入头指针地址,才能在函数内部修改外部头指针并置为NULL,防止野指针。
销毁函数需在链表使用完毕后调用,避免内存泄漏,同时修复了原删除函数的返回值类型不匹配问题。
cpp
//销毁整个链表,释放所有节点的内存
void destroy_list(Node_t** head)
{
// 1. 链表本身为空或头指针地址为空,直接返回
if (head == NULL || *head == NULL)
{
printf("链表为空,无需销毁\n");
return;
}
// 2. 定义两个指针:cur保存当前要释放的节点,next保存下一个节点的地址
Node_t* cur = *head;
Node_t* next = NULL;
// 3. 遍历链表,逐个释放节点
while (cur != NULL)
{
next = cur->next;
free(cur);
cur = next;
}
// 4. 最后将头指针置为NULL,避免野指针
*head = NULL;
printf("链表销毁成功\n");
}4、单向链表接口测试用例
cpp
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
//1、链表结点的设计
typedef int ElemType_t;
typedef struct node{
ElemType_t data;//数据域
struct node *next;//指针域
}Node_t;
//2、创建一条只有数据首结点的链表
Node_t* create_list(ElemType_t inputData)
{
//1、申请链表首结点的内存空间
struct node*head = malloc(sizeof(struct node));
if(head == NULL)
{
perror("malloc head error");
return NULL;
}
//2、初始化
head->data = inputData;
head->next = NULL;
//3、返回链表的首结点地址
return head;
}
//3、新建一个节点 插入到链表中
int insert_nodeToList_tail(Node_t* head,ElemType_t insertData)
{
if(head == NULL){
printf("insert_nodeToList_tail error ,head is NULL\n");
return -1;
}
//1、申请新结点的内存空间
Node_t*newNode = malloc(sizeof(Node_t));
if(newNode == NULL)
{
perror("malloc newNode error");
return -1;
}
//2、并且初始化
newNode->data = insertData;
newNode->next = NULL;
//只有一个结点的时候 head->next = newNode;
if(head->next == NULL){
head->next = newNode;
}else{//有多个结点的时候
Node_t*p = head;
while(1)
{
p = p->next;
if(p->next == NULL)
break;
}
//此时p就是最后一个结点
p->next = newNode;
}
#if 0
Node_t*p = head;
Node_t*pre = NULL;//存储p的上一个结点的地址
//3、遍历链表,找到最后一个结点
while(p)//p!=NULL
{
pre = p;
p = p->next;
}
//此时 pre才是最后一个结点
//4、最后一个结点的next成员存储 新结点的地址
pre->next = newNode;
#endif
}
//4、打印链表中所有的元素
void print_allToList(Node_t* head)
{
if(head == NULL){
printf("head is NULL,print_allToList error\n");
return;
}
#if 0
//第一种方法
Node_t*p = head;
while(1)
{
printf("%d\t",p->data);
p = p->next;
if(p == NULL)
break;
}
#endif
//第二种方法
Node_t*p = head;
while(p)//p!=NULL
{
printf("%d\t",p->data);
p = p->next;
}
printf("\n");
}
//5、查找某个指定的数据 是否在链表中
bool find_nodeToList(Node_t* head,ElemType_t findData)
{
if(head == NULL){
printf("head is NULL,find_nodeToList error\n");
return false;
}
bool isFindFlag = false;
//遍历链表,挨个元素与 findData 进行比较
Node_t *p = head;
while(p)
{
if(p->data == findData)
{
isFindFlag = true;
break;
}
p = p->next;
}
return isFindFlag;
}
//6、修改
bool modify_nodeToList(Node_t* head, ElemType_t oldData, ElemType_t newData)
{
// 1. 链表为空,直接返回修改失败
if (head == NULL)
{
printf("head is NULL, modify_nodeToList error\n");
return false;
}
// 2. 遍历链表,找到存储oldData的节点
Node_t* p = head;
while (p != NULL)
{
if (p->data == oldData)
{
// 3. 找到目标节点,更新数据域为新数据
p->data = newData;
return true; // 修改成功,直接返回
}
p = p->next;
}
// 4. 遍历完链表未找到目标数据,返回修改失败
printf("未找到值为 %d 的节点,修改失败\n", oldData);
return false;
}
//7、从链表中 删除值为delData的结点
Node_t* delete_nodeToList(Node_t* head,ElemType_t delData)
{
//1、先判断当前链表是否为空
if(head == NULL){
printf("head is NULL,delete_nodeToList error\n");
return false;
}
//如果你当前删除的结点是首结点
if(head->data == delData){
Node_t* delNode = head;
//第一步:更新首结点
head = head->next;
//第二步:删除结点断链接
delNode->next = NULL;
//第三步:释放删除结点的内存空间
free(delNode);
//第三步:返回 新的首结点的地址
return head;
}
//2、遍历链表,先找到你要删除的那个结点
Node_t* p = head;
Node_t* pre = NULL; //记录删除结点的上一个结点的地址
bool isFindFlag = false;
while(p)
{
if(p->data == delData)
{
isFindFlag = true;
break;
}
pre = p;
p = p->next;
}
//printf("删除结点 p->data:%d\n",p->data);
//printf("删除结点的上一个结点 pre->data:%d\n",pre->data);
//如果没有找到删除结点直接返回false
if(isFindFlag == false)
return false;
//说明已经找到了
//第二步:当前删除结点的上一个结点pre里面的next成员指向(存储)删除结点的下一个结点的地址
pre->next = p->next;
//第三步:删除结点p 断链接
p->next = NULL;
//第四步:释放删除结点的内存空间
free(p);
return head;
}
//8、销毁整个链表,释放所有节点的内存
void destroy_list(Node_t** head)
{
// 1. 链表本身为空或头指针地址为空,直接返回
if (head == NULL || *head == NULL)
{
printf("链表为空,无需销毁\n");
return;
}
// 2. 定义两个指针:cur保存当前要释放的节点,next保存下一个节点的地址
Node_t* cur = *head;
Node_t* next = NULL;
// 3. 遍历链表,逐个释放节点
while (cur != NULL)
{
next = cur->next;
free(cur);
cur = next;
}
// 4. 最后将头指针置为NULL,避免野指针
*head = NULL;
printf("链表销毁成功\n");
}
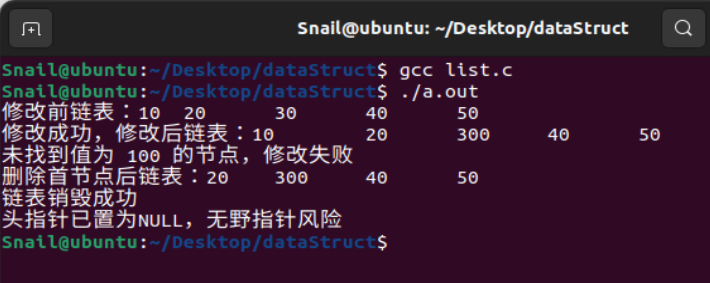
int main(int argc, char **argv)
{
Node_t* head = create_list(10);
if(head == NULL)
{
printf(" create_list error\n");
return -1;
}
insert_nodeToList_tail(head,20);
insert_nodeToList_tail(head,30);
insert_nodeToList_tail(head,40);
insert_nodeToList_tail(head,50);
printf("修改前链表:");
print_allToList(head);
// 调用修改函数,将30修改为300
if (modify_nodeToList(head, 30, 300))
{
printf("修改成功,修改后链表:");
print_allToList(head);
}
else
{
printf("修改失败\n");
}
// 测试修改一个不存在的数据
modify_nodeToList(head, 100, 200);
head = delete_nodeToList(head,10);
printf("删除首节点后链表:");
print_allToList(head);
// 调用销毁链表函数,传入头指针的地址
destroy_list(&head);
// 销毁后验证头指针是否为NULL
if (head == NULL)
{
printf("头指针已置为NULL,无野指针风险\n");
}
return 0;
}