⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,"虽小必牢"(虽然你犯的事很小,但你肯定会坐牢)。
下一代检测:基于自编码器(Autoencoder)的异常流量检测
你好,我是陈涉川,欢迎来到我的专栏。现在我们正式步入模块三:盾之固------AI 加固的防御体系。
这是整个专栏的转折点:从"理解"和"进攻"转向"建设"和"防御"。第 19 篇作为模块三的开篇,必须具备奠基性的意义。它不仅要讲清楚技术,更要重塑读者对"防御"的认知------从"匹配已知"进化为"感知未知"。
引言:当"永恒之蓝"遇见 AI
在网络安全的世界里,攻防的不对称性从未如此显著。长久以来,防御者像是一个守着厚厚一本《罪犯花名册》(特征库)的门卫,每经过一个人,都要核对照片。如果是花名册上的人,抓起来;如果不是,放行。
这种模式在 2010 年之前或许还能勉强维持。但今天,随着 Metasploit 等自动化工具的普及,尤其是生成式 AI 介入攻击链后,恶意流量的变种速度呈指数级爆炸。黑客只需修改几个比特的 Padding,或者调整一下 C2 通信的抖动频率,就能轻易绕过传统的 Snort 或 Suricata 规则。
我们正面临着防御者的终极噩梦:如何抵御从未见过的攻击?
本文将带你进入"模块三:盾之固------AI 加固的防御体系"。我们将抛弃传统的"黑名单"思维,利用深度学习中的自编码器(Autoencoder),为网络构建一个类似于生物体的"免疫系统"------不再通过特征识别罪犯,而是通过感知异常来定义威胁。
1. 破局:从"黑名单"到"免疫系统"
在网络安全的世界里,长久以来存在着一种不对称的博弈。防御者像是一个守着厚厚一本《罪犯花名册》(特征库)的门卫,每经过一个人,他都要核对照片。如果是花名册上的人,抓起来;如果不是,放行。
这种**基于误用检测(Misuse Detection)**的模式,在 2010 年之前或许还能勉强维持。但随着 Metasploit 等工具的普及,尤其是生成式 AI 介入攻击链后,恶意流量的变种速度已经呈指数级爆炸。黑客只需修改几个比特的 Padding,或者调整一下 C2 通信的抖动频率,就能轻易绕过传统的 Snort 或 Suricata 规则。
防御者面临着三个无法回避的噩梦:
- 零日攻击(Zero-day Attacks): 这种攻击从未在历史上出现过,自然没有特征码。门卫的《花名册》里没有他的照片。
- 多态与变形(Polymorphism & Metamorphism): 恶意软件每次传播都改变自身的哈希值和代码结构,但行为逻辑不变。
- 海量告警疲劳(Alert Fatigue): 传统的阈值设定往往在"漏报"和"误报"之间左右互搏,安全分析师每天淹没在数万条低信度的告警中。
我们需要一次范式转移(Paradigm Shift)。
我们需要从**"识别罪犯"转向"定义良民"**。
这就像人体的免疫系统。免疫细胞并不需要认识世界上所有的细菌和病毒(那是抗生素的事),它们只需要深刻地理解"什么是人体自身的健康细胞"。凡是与"健康细胞"特征不符的,无论它长什么样,无论它叫什么名字,都被视为异类进行攻击。
在 AI 安全领域,实现这一理念的核心算法,就是自编码器(Autoencoder, AE)。它是**异常检测(Anomaly Detection)**皇冠上的明珠。
2. 自编码器的哲学:压缩即理解
要理解自编码器在安全中的威力,我们首先要抛弃"分类"的概念。在第 19 篇之前,我们讨论的大多是监督学习(Supervised Learning):给 AI 一堆数据,告诉它这是 DDoS,那是 SQL 注入。
但在异常检测中,我们假设:攻击数据是稀缺的、未知的,而正常流量是海量的、易得的。
自编码器是一种**无监督学习(Unsupervised Learning)**神经网络。它的核心逻辑非常反直觉:它的训练目标不是预测未来,而是完美地复制自己。
2.1 结构解构:沙漏型网络
自编码器的结构就像一个沙漏,两头大,中间小。它由三个核心部分组成:
- 编码器(Encoder): 这是一个神经网络函数 f(x),它接收高维的输入数据 x(例如一个包含 80 个特征的网络流向量),将其通过层层压缩,映射到一个低维的潜在空间(Latent Space)。
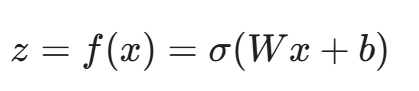
在这里,z 就是数据的"压缩表示"或"瓶颈特征"。
- 瓶颈层(Bottleneck / Latent Vector): 这是沙漏最细的地方。由于维度被强制降低,神经网络被迫丢弃噪音和不重要的细节,只保留数据最核心、最本质的规律。这就像你读了一本 50 万字的小说,让你用 100 字概括剧情,你只能保留主线,丢弃无关的风景描写。
- 解码器(Decoder): 这是编码器的逆过程 g(z),它试图利用那个被压缩的 z,还原出原始数据 x。
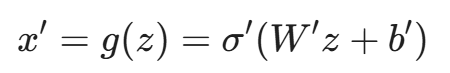
这里的 x' 是重构后的数据。
2.2 检测原理:重构误差(Reconstruction Error)
这就是魔法发生的地方。
我们在训练阶段,只给自编码器看"正常的网络流量"(Web 访问、数据库查询、心跳包等)。我们强迫它学习如何压缩这些正常流量,并将其还原。
经过成千上万次的迭代,自编码器成为了"正常流量的大师"。它极其擅长捕捉 HTTP GET 请求的规律、DNS 解析的频率分布。
此时,如果一段异常流量(例如 SQL 注入或 C2 信标)进入网络,会发生什么?
- 异常流量进入编码器。
- 因为自编码器从未见过这种模式,它试图用描述"正常流量"的规律去压缩这段"异常流量"。
- 关键点: 这种强制压缩会导致大量核心信息丢失,因为异常流量的分布规律与正常流量完全不同。
- 解码器试图利用糟糕的压缩信息还原数据。
- 结果是:还原出来的 x' 与原始输入 x 差异巨大!
我们定义重构误差(Loss):
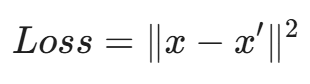
- 如果 Loss 很小 → AI 觉得很眼熟 → 正常流量。
- 如果 Loss 很大 → AI 觉得一脸懵逼,还原不出来 → 异常流量(攻击)。
这种机制不需要我们告诉 AI 什么是攻击。只要它不像正常流量,它就是可疑的。这就是**基于异常的检测(Anomaly-based Detection)**的最高境界。
3. 数学深潜:流形假设与损失函数
为了让专业人士信服,我们需要下潜到数学层面来解释为什么 AE 优于 PCA(主成分分析)等传统降维方法。
3.1 流形假设(Manifold Hypothesis)
网络流量数据在高维空间中并不是均匀分布的。
假设我们用一个向量表示一个网络流,包含 源端口, 目的端口, 包大小, 持续时间, TCP 标志位... 等 100 个特征。这是一个 100 维的欧几里得空间。在这个巨大的空间里,合法的网络流量并不是到处都是,而是聚集在某些特定的低维区域。
例如,HTTPS 流量(端口 443)通常有特定的包大小分布;DNS 流量(端口 53)通常是短促的 UDP 包。
流形假设认为:高维数据实际上位于(或接近)嵌入在高维空间中的低维流形上。
自编码器的工作,本质上就是学习这个正常流量的流形曲面。
- 正常流量位于流形上(或非常接近流形),投影到低维再投影回来,距离变化很小。
- 异常流量远离这个流形,强行将其投影到流形上会产生巨大的"投影误差"。
3.2 深度学习 vs. 线性降维
如果编码器和解码器都是线性的(即没有激活函数,只有矩阵乘法),那么自编码器等价于 PCA(主成分分析)。PCA 只能学习线性的超平面。
但在网络安全中,流量特征是非线性的。
- 例如:当 TCP 窗口大小(Window Size)急剧减小时,通常意味着拥塞,但如果此时包大小(Packet Size)依然很大且频率极高,这可能就不符合线性相关性,而是一种复杂的应用层 DDoS 攻击。
基于神经网络的深度自编码器(Deep Autoencoder),通过引入非线性激活函数(ReLU, Tanh, Sigmoid),可以学习弯曲的、复杂的流形结构,从而捕捉极度隐蔽的异常模式。
3.3 目标函数(Objective Function)
对于一个包含 N 个样本的正常流量数据集 X = \{x^{(1)}, x^{(2)}, ..., x^{(N)}\},我们的训练目标是最小化所有样本的重构误差之和。
最常用的损失函数是 均方误差(Mean Squared Error, MSE):
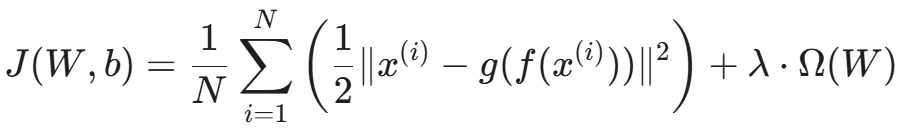
其中:
- 第一项是重构保真度(Reconstruction Fidelity)。
- 第二项 λ × Ω(W) 是正则化项(如 L2 正则化),用于防止过拟合,确保模型学习到的是通用特征而非死记硬背。
4. 特征工程:将比特流转化为张量
这是大多数教程忽略,但在工程落地中决定生死的环节。如果你直接把原始的 PCAP 包字节喂给自编码器,模型大概率收敛不了。网络安全的数据预处理与图像处理(CV)或自然语言处理(NLP)有着本质区别。
我们需要构建从**原始流量(Raw Traffic)到特征向量(Feature Vector)**的流水线。
4.1 流量切分:流(Flow)与会话(Session)
我们很少对单个数据包(Packet)进行异常检测,因为单个包的信息熵太低。攻击通常体现在一系列包的时序行为中。
最通用的做法是基于 五元组(5-tuple) 聚合流量:
(源 IP, 目的 IP, 源端口, 目的端口, 协议)
我们需要使用工具(如 CICFlowMeter 或 Argus)将 PCAP 文件转换为流特征数据(CSV 格式)。
4.2 关键特征提取
基于 CIC-IDS-2017 或 CSE-CIC-IDS2018 等现代数据集的研究,以下几类特征对自编码器最敏感:
- 统计特征(Statistical Features):
- Flow Duration:流持续时间。
- Total Fwd Packets / Total Bwd Packets:前向/后向发包总数。
- Total Length of Fwd Packets:总字节数(检测大文件传输或数据渗漏)。
- 时序特征(Inter-arrival Time, IAT):
- Flow IAT Mean / Std / Max / Min:包到达时间间隔的统计值。
- 安全含义: 机器生成的攻击流量(如 DoS)通常具有非常规律的 IAT(方差极小),而人类行为或正常网络波动会导致 IAT 方差较大。
- 标志位特征(Flag Counts):
- SYN, ACK, FIN, RST 的计数。
- 安全含义: SYN Flood 攻击会有大量的 SYN 而没有 ACK;扫描行为通常伴随着大量的 RST。
- 头部特征(Header Features):
- Fwd Header Length。
- Window Size:TCP 窗口大小(慢速攻击检测的关键)。
4.3 数据的数值化与归一化(核心难点)
神经网络只吃 0, 1 或 -1, 1 之间的浮点数。网络数据中的"坑"非常多。
4.3.1 类别特征处理(Categorical Data)
对于协议类型(TCP/UDP/ICMP),我们不能用 1, 2, 3 来表示,因为 UDP(2) 并不比 TCP(1) "大"。
解决方案:
- 针对协议类型(TCP/UDP): 由于类别极少,直接使用独热编码(One-Hot Encoding)。
- 针对端口号(Port): 这是一个大坑。端口取值范围是 0-65535,如果使用 One-Hot 会导致特征维度爆炸(从 80 维瞬间膨胀到 6万多维)。强烈推荐使用 Embedding 层 (将端口映射为 dense vector)或频次编码(越常用的端口数值越大),这能有效避免维度灾难。
4.3.2 极差处理与对数变换
网络流特征的数值跨度极大。
- Flow Duration 可能是几微秒,也可能是几小时(10^9 数量级)。
- Packet Count 可能是 1 个,也可能是 100 万个。
如果直接使用 Min-Max 归一化:
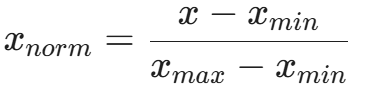
一旦数据集中出现一个超大的异常值(Outlier),所有的正常值都会被压缩到接近 0 的位置,导致特征失效。
最佳实践: 结合 对数变换(Log Transformation) 和 Z-Score 标准化。
首先对长尾分布的特征取对数,缩小量级:
x' = log(x + 1)
(加 1 是为了防止 \log(0))
然后进行 Z-Score 标准化,使其符合标准正态分布:
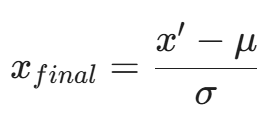
这样,神经网络就能在一个健康的梯度范围内通过反向传播(Backpropagation)学习权重。
5. 模型架构设计的艺术
在构建用于异常检测的自编码器时,"层数越多越好" 是一个误区。我们需要精心设计网络的拓扑结构。
5.1 输入层与输出层的维度
假设经过特征工程后,我们每个 Flow 变成了 80 维的向量。
- 输入层节点数:80
- 输出层节点数:80
铁律:输出层的激活函数必须与数据预处理方式匹配。
- 如果数据归一化到 0, 1:输出层用 Sigmoid。
- 如果数据归一化到 -1, 1:输出层用 Tanh。
- ⚠️ 关键注意 :如果数据使用 Z-Score 标准化 (分布在 {R},包含大于 1 或小于 -1 的值),输出层必须使用 Linear(不加激活函数)。否则,模型将无法重构超出 Tanh 范围的数值,导致训练失败。
5.2 隐藏层的压缩比(Compression Ratio)
瓶颈层的大小决定了模型的"记忆力"。
- 如果瓶颈层太宽(例如 70 维),模型可能会学会"恒等映射"(Identity Mapping),即直接复制输入到输出,什么特征都没学到。这被称为"过拟合"。
- 如果瓶颈层太窄(例如 2 维),模型会丢失过多信息,连正常流量都无法重构。
经验法则: 漏斗形状通常按 2 的幂次递减。
例如:80 → 64 → 32 → 16 (Latent) → 32 → 64 → 80。
5.3 激活函数的选择
在隐藏层,ReLU (Rectified Linear Unit) 依然是王者。它计算快,且能缓解梯度消失问题。
但在安全领域,Leaky ReLU 或 ELU (Exponential Linear Unit) 有时表现更好。
- 原因: 某些网络特征值为负(如果是 Z-Score 处理后)或极其接近零,ReLU 的"死区"特性可能导致某些神经元永久死亡,无法捕捉微小的流量波动。
5.4 正则化与 Dropout
为了防止自编码器"死记硬背"训练数据中的噪音,我们必须引入正则化:
- L1/L2 正则化: 惩罚过大的权重。
- Dropout: 在训练过程中随机"关闭"一部分神经元。这在检测中有一个变种应用------去噪自编码器(Denoising Autoencoder, DAE)。
在 DAE 中,我们在输入数据 x 中人为加入高斯噪音变成 \tilde{x},但要求网络重构原始的纯净数据 x。

这强迫模型学习数据中鲁棒的结构特征,而不是噪音。对于网络流量这种本身就充满抖动的数据,DAE 的效果通常优于标准 AE。
6. 训练策略:半监督的独舞
这是自编码器与 SVM 或随机森林最根本的区别。
6.1 数据集划分的特殊性
在传统的机器学习中,我们随机划分 训练集/验证集/测试集。但在异常检测中,我们必须污染控制。
- 训练集(Training Set): 必须只包含正常流量(Benign Traffic) 。
- 是的,你需要剔除所有的攻击流量。这听起来很难,但在实际的企业环境中,你可以选择一段"业务平稳期"(如没有任何告警的一周)的流量作为基线。
- 如果训练集中混入了攻击流量,自编码器会把攻击流量也当作"正常"学会,导致漏报。这被称为数据中毒(Data Poisoning)。
- 验证集(Validation Set): 包含正常流量和少量的异常流量。用于调整超参数(如阈值)。
- 测试集(Test Set): 包含正常流量和各种类型的异常流量(已知的和未知的)。用于评估最终效果。
6.2 阈值的确定(Thresholding)
训练完成后,模型可以吐出每个样本的重构误差(MSE)。但多少误差才算异常?
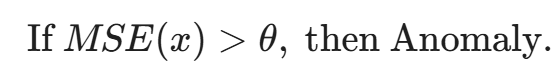
如何确定 θ?
- 统计法: 计算验证集(只含正常流量)中所有样本的 MSE,计算其均值 μ 和标准差 σ。
设定 θ = μ + 3σ。根据切比雪夫不等式或正态分布假设,这能覆盖 99.7% 的正常流量。
- 分位数法: 这是工程中最推荐的方法。 因为重构误差的分布往往不是标准的正态分布,而是长尾分布。使用标准差(3σ)容易受极大离群点影响,而分位数(如 99%)能更稳健地切分出'极其罕见'的异常。取验证集 MSE 的第 95% 或 99% 分位数作为阈值。
- 精确率-召回率权衡(Precision-Recall Trade-off): 绘制 ROC 曲线,根据业务对"误报"的容忍度选择最佳阈值。如果是在 SOC 中做辅助检测,阈值可以低一点(高召回);如果是直接联动防火墙阻断,阈值必须高(高精确)。
7. 深入剖析:为什么 AE 能检测出复杂的攻击?
让我们通过一个具象的例子来结束第一部分的理论构建。
场景:检测慢速 HTTP DoS 攻击(如 Slowloris)。
- 正常流量特征: 完整的 HTTP 请求头,发送速度快,连接建立后迅速传输数据并断开。
- 自编码器学到了:Window Size 大,IAT 小,Flow Duration 短。这些特征在潜在空间中紧密聚集。
- Slowloris 攻击特征: 攻击者建立连接后,以极慢的速度发送 HTTP 头(例如每 15 秒发送一个字节),目的是耗尽服务器的并发连接池。
- 特征表现:Flow Duration 极大,IAT Mean 极大,Packet Count 适中,Payload 极小。
当 Slowloris 流量进入自编码器:
- 编码器试图压缩这个向量。它以前见过的长连接通常是"大文件下载"(伴随大量 Payload),见过的短 Payload 通常是"快速请求"。
- 这个"长连接 + 小 Payload + 高 IAT"的组合在潜在空间中找不到对应的坐标。
- 编码器只能强行将其映射到最近的"正常"坐标(可能是某种心跳包)。
- 解码器根据这个错误的坐标重构,结果还原出了一个"正常的心跳包"。
- 比对: 输入是 Slowloris,输出是心跳包。两者的特征向量(尤其是 IAT 和 Duration 维度)差异巨大。
- 结果: MSE 爆表 → 触发告警。
哪怕我们从未告诉 AI 什么是 Slowloris,它也能基于"由于不像正常流量,所以可疑"的逻辑将其揪出来。
8. 代码实战:构建你的第一个流量"免疫系统"
理论已备,代码先行。在本节中,我们将使用 Python 和 PyTorch 框架,构建一个完整的自编码器异常检测模型。
为了贴近实战,假设我们已经完成了第一部分所述的数据预处理,拥有了一个形状为 (N, 80) 的标准化 Tensor,其中 80 是特征维度(基于 CIC-IDS2017 数据集)。
8.1 模型定义:PyTorch 风格的沙漏
即使是简单的全连接网络,在工程实现上也有许多细节值得考究。比如,为什么我们要用 BatchNorm?因为网络流量数据的分布即使经过预处理,依然可能存在协变量偏移(Covariate Shift),BN 层能加速收敛并防止梯度消失。
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
class NIDSAutoencoder(nn.Module):
def __init__(self, input_dim=80):
super(NIDSAutoencoder, self).__init__()
# 编码器 (Encoder): 80 -> 64 -> 32 -> 16
self.encoder = nn.Sequential(
nn.Linear(input_dim, 64),
nn.BatchNorm1d(64), # 批归一化,稳定训练
nn.Tanh(), # Tanh 能够处理负值输入(标准化后的数据)
nn.Linear(64, 32),
nn.BatchNorm1d(32),
nn.Tanh(),
nn.Linear(32, 16), # 瓶颈层 (Latent Space)
nn.Tanh() # 这里的激活函数决定了潜在空间的分布范围
)
# 解码器 (Decoder): 16 -> 32 -> 64 -> 80
self.decoder = nn.Sequential(
nn.Linear(16, 32),
nn.BatchNorm1d(32),
nn.Tanh(),
nn.Linear(32, 64),
nn.BatchNorm1d(64),
nn.Tanh(),
nn.Linear(64, input_dim),
# ⚠️ 关键点:这里不加激活函数(即 Linear 激活)
# 原因:输入数据做了 Z-Score 标准化,数值范围理论上是负无穷到正无穷。
# 如果使用 Tanh,输出会被截断在 [-1, 1] 之间,导致无法重构 >1 或 <-1 的异常值(Outliers)。
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded8.2 训练循环与损失函数
这里的关键在于:我们只使用正常流量进行训练。
python
# 超参数设置
BATCH_SIZE = 256
LEARNING_RATE = 1e-3
EPOCHS = 50
# 假设 train_data 是只包含正常流量的 Tensor
# 真实场景中,train_loader 需要从 DataLoader 加载
# train_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NIDSAutoencoder(input_dim=80).to(device)
# 损失函数:均方误差 (MSE)
criterion = nn.MSELoss()
# 优化器:AdamW (Adam with Weight Decay)
# 相比 Adam,AdamW 在正则化方面表现更好,能防止模型过拟合特定的流量模式
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-5)
print(f"开始在 {device} 上训练模型...")
for epoch in range(EPOCHS):
model.train()
total_loss = 0
for batch_data in train_loader:
# 自编码器的输入和标签都是 x
inputs = batch_data[0].to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, inputs) # 计算重构误差
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
# 打印日志(实际工程中应记录到 TensorBoard)
if (epoch + 1) % 5 == 0:
print(f'Epoch [{epoch+1}/{EPOCHS}], Loss: {avg_loss:.6f}')
print("训练完成,模型已学会'正常流量'的模样。")8.3 检测阶段:计算阈值与判定
模型训练好后,如何抓坏人?我们需要确定阈值 θ。这一步通常在验证集(Validation Set)上进行。
python
def get_reconstruction_errors(model, data_loader):
model.eval()
errors = []
with torch.no_grad():
for batch_data in data_loader:
inputs = batch_data[0].to(device)
outputs = model(inputs)
# 计算每个样本的 MSE Loss (不求平均,保留每个样本的独立误差)
# inputs shape: (B, 80), outputs shape: (B, 80)
# loss shape: (B, )
loss = torch.mean((inputs - outputs) ** 2, dim=1)
errors.extend(loss.cpu().numpy())
return np.array(errors)
# 1. 在验证集(纯净或极少污染)上计算误差分布
val_errors = get_reconstruction_errors(model, val_loader)
# 2. 设定阈值:均值 + 3倍标准差 (3-sigma法则)
threshold = np.mean(val_errors) + 3 * np.std(val_errors)
print(f"异常检测阈值设定为: {threshold:.6f}")
# 3. 在测试集(包含攻击)上进行检测
test_errors = get_reconstruction_errors(model, test_loader)
predictions = (test_errors > threshold).astype(int) # 1为异常,0为正常
# 接下来可以使用 sklearn.metrics 计算 Precision, Recall, F1-Score9. 进阶架构:当时间成为第四维度
上述的普通自编码器(Vanilla AE)处理的是"快照"数据,即它把一个网络流压缩成了一行统计数据。但在高级攻击中,**时序(Time Series)**是关键。
例如,一个 低频慢速暴力破解(Low-and-Slow Brute Force),每次尝试密码间隔 10 分钟。如果只看单次连接,完全正常;但如果把时间轴拉长,就会发现规律性的异常。
这时,我们需要 LSTM-Autoencoder。
9.1 LSTM-Autoencoder:记忆的压缩
长短期记忆网络(LSTM)擅长处理序列数据。我们将 AE 中的全连接层(Dense Layer)替换为 LSTM 层。
- 输入形式: 不再是 (Batch, 80),而是 (Batch, Sequence_Length, Features)。例如 (256, 10, 80) 表示每次输入过去 10 个数据包的特征序列。
- 编码器: 一个 LSTM 层,读取 10 个时间步的数据,最后输出一个隐状态向量(Hidden State),这就是压缩后的潜在表示。
- 解码器: 另一个 LSTM 层,根据这个隐状态,试图按顺序"重播"出那 10 个时间步的数据。
为什么它更强?
因为它不仅学习了"数据包大小"的分布,还学习了"数据包 A 后面跟着数据包 B"的转移概率。
如果黑客在正常的 HTTP 请求序列中插入了一个恶意的 Shellcode 片段,这种时序上的突变会导致 LSTM 解码器产生巨大的重构误差。
9.2 变分自编码器(VAE):从确定性到概率论
普通 AE 容易发生过拟合,即它只是"记住"了训练数据,而不是"理解"了分布。变分自编码器(Variational Autoencoder, VAE) 引入了贝叶斯推断。
VAE 的编码器不再输出一个固定的向量 z,而是输出两个向量:均值 μ 和方差 σ^2。它告诉我们:
"这个流量样本大概位于潜在空间的这个区域(μ),以及它可能的波动范围(σ)。"
然后,我们从这个正态分布 N(μ, σ^2) 中随机采样一个 z 传给解码器。
安全含义:
VAE 在潜在空间中强制生成了连续的、平滑的流形。这使得它对噪声具有极强的鲁棒性。在网络环境中,抖动(Jitter)和丢包是常态,VAE 能更好地分辨"网络波动引起的异常"和"黑客攻击引起的异常",从而大幅降低误报率(False Positive Rate),这是 SOC 分析师最看重的指标。
10. 工程落地:从实验室到 SOC 的惊险一跃
很多 AI 模型在 Jupyter Notebook 里表现完美(F1-Score 0.99),一旦部署到生产环境就崩溃。在网络安全领域,这个问题尤为严重。本节我们将探讨工程化的核心挑战。
10.1 概念漂移(Concept Drift):模型的衰老
网络流量不是静态的。
- 双十一大促期间,电商公司的流量模式会剧变(并发激增,但不是 DDoS)。
- 公司上线了一个新的微服务,引入了新的 gRPC 协议流量。
- 员工开始广泛使用 ChatGPT,导致出站流量中 HTTPS 的长连接比例增加。
如果你用上个月的数据训练模型来检测今天的流量,误报率会飙升。这就是概念漂移。
解决方案:在线学习与周期性重训(Retraining Pipeline)
我们需要构建一个 MLOps 闭环:
- 影子模式(Shadow Mode): 新模型上线不直接拦截,只产生日志。
- 人工反馈回路(Human-in-the-loop): SOC 分析师对告警进行标记("这是误报,这是真的攻击")。
- 增量学习(Incremental Learning): 将分析师确认为"正常"的误报样本加入训练集。
- 自动触发重训: 当模型在监控集上的分布差异(如 KL 散度)超过阈值时,触发夜间自动重训。
10.2 实时性挑战:处理 10Gbps 流量
深度学习模型的推理速度通常比基于规则的系统(如 Snort)慢。在骨干网出口,流量高达 10Gbps 甚至 100Gbps,每个包的处理时间必须在微秒级。
架构优化:分层过滤漏斗
不要让 AI 检查每一个包。
- L1 静态过滤(eBPF/XDP): 在网卡层面丢弃明显的黑名单 IP 和畸形包。
- L2 传统 IDS(Snort/Zeek): 处理已知的特征匹配。
- L3 AI 检测(自编码器): 只有通过了 L1 和 L2 的"看似正常"流量,才会被复制一份(Port Mirroring)发送给 AI 推理集群。
技术栈推荐:
- 流量采集: Kafka(缓冲洪峰)。
- 流式计算: Apache Flink(实时聚合 5-tuple 特征)。
- 推理引擎: NVIDIA Triton Inference Server 或 TensorRT(将 PyTorch 模型转化为量化的 INT8 格式,推理速度提升 10 倍)。
策略优化:抓大放小与首包检测
即使有 GPU 加速,对骨干网 10Gbps 的全流量进行深度神经网络推理也是极不经济的。在工程实践中,我们通常采用**"首包检测(First-N Packets)"**策略。 研究表明,大多数恶意流量的特征(如握手异常、协议头畸形)集中在流的前 10-20 个数据包中。因此,我们只需将每个新连接的前 N 个包送入自编码器进行检测。一旦 AI 判定该流为"正常",后续的数据包可直接由底层网络设备(如交换机 ASIC 或 eBPF)快速放行,不再占用 GPU 推理资源。
10.3 可解释性(Explainable AI, XAI):打破黑盒
当 AI 报警说:"IP 10.0.0.5 是恶意的",安全分析师会问:"为什么?"
如果 AI 只能回答:"因为重构误差是 0.8",分析师会想砸电脑。
我们需要引入 SHAP (SHapley Additive exPlanations) 值或 IG (Integrated Gradients) 算法。
通过计算输入特征对重构误差的贡献度,我们可以给出这样的解释:
"告警原因:Destination Port (445) 和 Flow Duration 的组合异常。在正常流量中,445 端口通常用于局域网 SMB 共享,流量大且持续时间长;但该样本通过 445 端口发送了极短的小包(疑似永恒之蓝漏洞扫描)。"
有了可解释性,AI 就不再是冷冰冰的机器,而是分析师的智能副驾驶。
11. 对抗性攻击:当黑客试图欺骗 AI
在专栏的第四模块我们将详细讨论 AI 安全,但在这里必须通过"对抗攻击"来审视自编码器的弱点。
如果黑客知道你在使用自编码器防御,他会怎么做?
他会试图实施 对抗样本攻击(Adversarial Example Attack)。
11.1 梯度攻击
黑客的目标是:构造一个恶意攻击流量 x_{mal},在保留攻击效能的同时,让自编码器的重构误差 Loss(x_{mal}) 尽可能小(即看起来像正常流量)。
这在数学上是一个优化问题:
\min_{\delta} \| g(f(x_{mal} + \delta)) - (x_{mal} + \delta) \|^2
其中 \delta 是添加的微小扰动(Perturbation)。
在网络流量中,黑客可以修改一些对功能无关紧要的字段(Unconstrained Features):
- 在 HTTP Header 中添加一些无意义的填充字段(Padding)。
- 微调发包的时间间隔(加一点随机延迟)。
- 修改 TTL 值。
通过这些微调,黑客可以让攻击流量的特征向量在潜空间中向"正常簇"移动,从而骗过解码器。
11.2 毒化攻击(Poisoning Attack)
如果黑客长期潜伏在你的网络中,并且你在做"周期性重训"。黑客可以每天发送少量的、逐渐变化的恶意流量。
今天的模型把这些流量当作异常;但如果没有及时发现,下周重训时,这些流量就可能被混入训练集。
久而久之,黑客像"温水煮青蛙"一样,通过训练集投毒,教会了你的自编码器:"这种攻击行为也是正常的。"
防御之道:
- 对抗训练(Adversarial Training): 在训练阶段主动生成对抗样本喂给模型,增强鲁棒性。
- 鲁棒统计学: 在计算阈值时,使用中位数而非均值,使用 MAD(绝对中位差)而非标准差,以减少离群点的影响。
总结:构建数字世界的潜意识
至此,我们完成了从"特征匹配"到"异常感知"的范式跨越。
如果说传统的防火墙和 IDS 是网络防御系统的"显意识"------它们逻辑严密,照章办事(基于规则);那么基于自编码器的 AI 模型,就是我们赋予网络的"潜意识"。
它不需要知道攻击的具体名字,不需要看懂 Payload 里的 Shellcode。它只是凭借着对"正常"的深刻记忆,在海量数据流过的瞬间,敏锐地感觉到:"这个流量的'味道'不对。"
这种直觉,是防御 0-day 漏洞和隐蔽隧道的最后一道防线。
然而,潜意识只能告诉我们"有危险",却无法告诉我们"危险是什么"。自编码器给出的高重构误差,可能是一次从未见过的 APT 攻击,也可能只是公司新上线的某个业务系统。 这就引出了下一个巨大的挑战:如何把 AI 模糊的"直觉",转化为安全运营人员(SecOps)可以执行的"确据"?
这就需要一个强大的大脑,来统筹规则的严谨与 AI 的直觉。
下期预告 当单点的检测模型部署完毕,海量的告警将如潮水般涌入 SOC(安全运营中心)。如何避免分析师淹没在"告警疲劳"中?如何将离散的异常点,自动串联成一条完整的攻击链路? 下一篇,我们将进入这一模块的核心腹地:《20. 智能 SOC 的大脑:基于图神经网络的告警关联与自动研判》。我们将探讨 AI 如何不再仅仅是报警器,而变身为福尔摩斯。
陈涉川
2026年02月04日