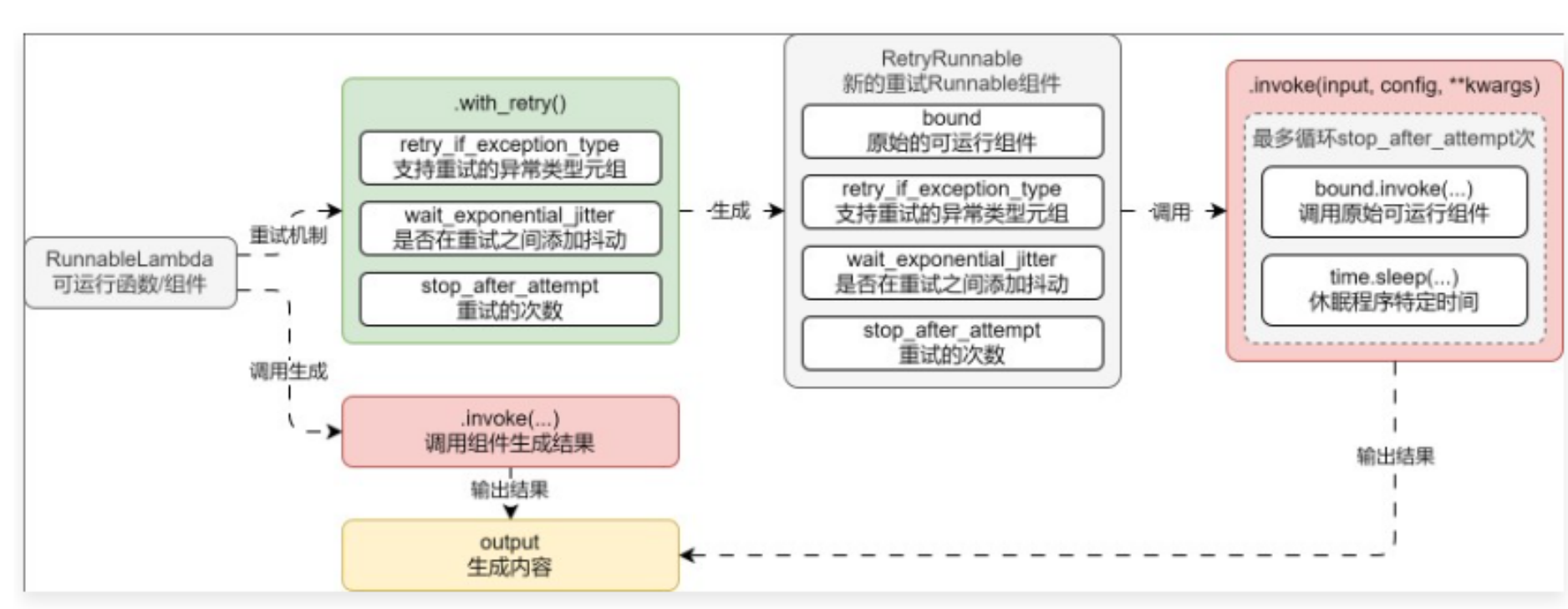
01. Runnable 重试机制
在 LangChain 中,针对 Runnable 抛出的异常提供了重试机制------with_retry(),当 Runnable 组件出现异常时,支持针对特定的异常或所有异常,重试特定的次数,并且配置每次重试时间的时间进行指数增加。
with_retry 函数的参数如下:
- retry_if_exception_type:需要重试的异常,默认为所有异常,类型为元组。
- wait_exponential_jitter:是否在重试之间添加抖动,默认为 True,即每次重试时间指数增加(并随机再增加 1 秒内的时间)。
- stop_after_attempt:重试的次数,默认为 3,即 3 次重试后没有正常结果就暂停。
例如,想要让一个 Runnable 组件最多重试 2 次,只需在 with_retry() 函数中传递 stop_after_attempt参数即可,代码
from langchain_core.runnables import RunnableLambda
counter = -1
def func(x):
global counter
counter += 1
print(f"当前的值为 {counter=}")
return x / counter
chain = RunnableLambda(func).with_retry(stop_after_attempt=2)
resp = chain.invoke(2)
print(resp)
with_retry() 函数的运行原理非常简单,通过构建一个新的 Runnable,在执行调用类的函数时,循环特定次数,直到组件能正常执行结束即暂停,并且在每次循环的过程中,休眠特定的时间,运行流程图如下
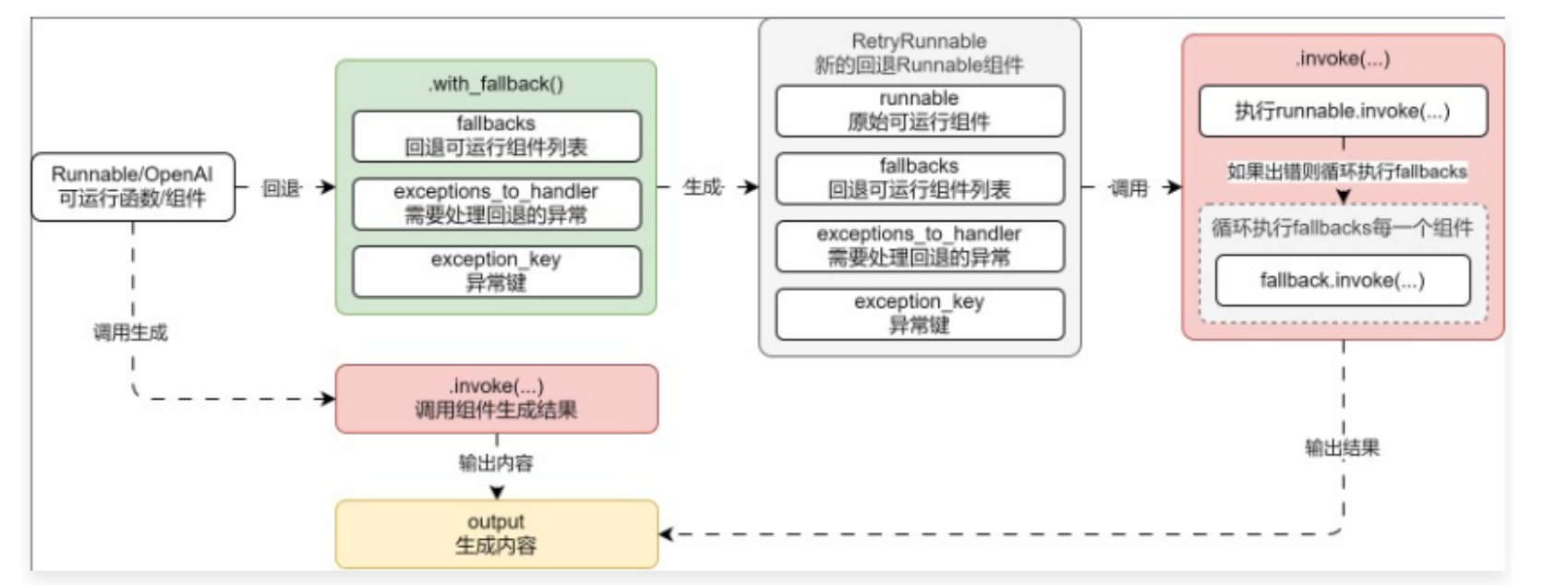
02. Runnable 回退机制
在某些场合中,对于 Runnable 组件的出错,并不想执行重试方案,而是执行特定的备份/回退方案,例如 OpenAI 的 LLM 大模型出现异常时,自动切换到 文心一言 的模型上,在 LangChain 中也提供了对应的回退机制------ with_fallback,
with_fallback 函数的参数:
- fallbacks:原始组件运行失败,进行回退/替换的 Runnable 组件列表,必填参数。
- exceptions_to_handle:需要回退的异常,默认为所有异常,类型为元组。
- exception_key:错误异常键,当指定错误信息后,Runnable 组件产生的错误异常作为输入的一部分传递给回退组件,且以指定的键名存储,默认为 None,表示异常不会传递给回退处理程序。
例如,为 LLM 添加回退备选方案,当 OpenAI 模型调用失败时,自动切换到文心一言执行任务
import dotenv
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
1.构建prompt与LLM,并将model切换为gpt-3.5-turbo-18k引发出错
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-18k").with_fallbacks(QianfanChatEndpoint())
2.构建链应用
chain = prompt | llm | StrOutputParser()
3.调用链并输出结果
content = chain.invoke({"query": "你好,你是?"})
print(content)
运行流程如下