经过之前的简单特征工程处理后,我们就可以编写一个模型来测试效果
数据分割
python
# 数据分割
from sklearn.model_selection import train_test_split
# 分割为训练集和验证集 (80% 训练, 20% 验证)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
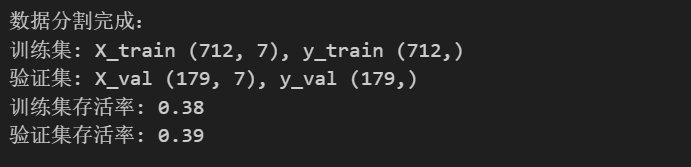
print("数据分割完成:")
print(f"训练集: X_train {X_train.shape}, y_train {y_train.shape}")
print(f"验证集: X_val {X_val.shape}, y_val {y_val.shape}")
print(f"训练集存活率: {y_train.mean():.2f}")
print(f"验证集存活率: {y_val.mean():.2f}")将数据分割为两部分,一部分用来训练,一部分用来验证训练结果,运行输出如下
(一般来说,我们习惯用X表示特征矩阵,即 X 中不含目标变量。X 是通过 df.drop('Survived', axis=1) 从原始数据中移除 'Survived' 列得到的特征矩阵,而 y 是单独提取的标签向量('Survived' 列)。这样确保模型只使用特征进行训练和预测。)
模型训练
首先,我们用最简单的逻辑回归模型来测试效果
逻辑回归模型
python
# 训练逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 创建模型
model = LogisticRegression(random_state=42, max_iter=1000)
# 训练模型
model.fit(X_train, y_train)
# 在验证集上预测
y_pred = model.predict(X_val)
# 评估模型
accuracy = accuracy_score(y_val, y_pred)
print(f"验证集准确率: {accuracy:.4f}")
print("\n分类报告:")
print(classification_report(y_val, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_val, y_pred))解释一下LogisticRegression中的比较重要的参数,这些参数的设置会影响模型的效果
-
penalty (str, 默认 'l2'):正则化类型。
- 'l1':L1 正则化(Lasso),促进稀疏性。
- 'l2':L2 正则化(Ridge),防止过拟合。
- 'elasticnet':弹性网(L1+L2)。
- 'none':无正则化。
-
C (float, 默认 1.0):正则化强度(1/C)。C 越大,正则化越弱;C 越小,正则化越强。
-
random_state (int, 默认 None):随机种子,确保结果可复现。
-
max_iter (int, 默认 100):最大迭代次数。增加可避免收敛警告。
输出如下
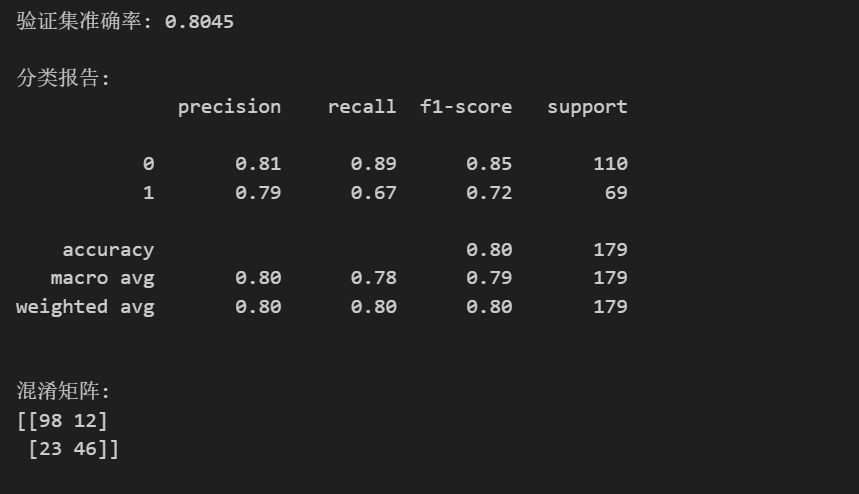
可以看到,验证集上预测的准确率为80.45%,这个数值显然还有提升空间,因此我们可以分类报告和混淆矩阵来查看当前效果,以决定下一步应该做什么
分类报告提供精确率、召回率、F1 分数等指标,评估每个类别的预测性能:
-
Class 0 (未存活):
- Precision (精确率) 0.81:预测为未存活的样本中,81% 实际未存活。
- Recall (召回率) 0.89:实际未存活的样本中,89% 被正确预测。
- F1 0.85:精确率和召回率的平衡。
-
Class 1 (存活):
- Precision 0.79:预测为存活的样本中,79% 实际存活。
- Recall 0.67:实际存活的样本中,67% 被正确预测(较低,说明漏判多)。
- F1 0.72:平衡值较低。
-
Macro avg:简单平均(0.80, 0.78, 0.79)。
-
Weighted avg:按样本数加权平均(0.80, 0.80, 0.80)。
整体准确率 80.45%,模型对未存活类表现更好,但存活类召回率需提升。
混淆矩阵是一个 2x2 表格,显示模型预测结果与实际结果的对比(行=实际标签,列=预测标签)。在本例中,标签为 0(未存活)和 1(存活):
- \[98, 12, 23, 46] 解读:
- 98 (TN):实际未存活,预测未存活(正确预测)。
- 12 (FP):实际未存活,预测存活(误判)。
- 23 (FN):实际存活,预测未存活(漏判)。
- 46 (TP):实际存活,预测存活(正确预测)。
这同样表明模型对未存活预测准确,但对存活有较多漏判(23例)。
接下来,一般有几种处理手段,可以更换几个模型来测试 ;也可以对用过的模型进行调优 ;在测试完几个模型后,可以考虑用几个表现好的模型来做模型集成 ;如果所有模型的结果都不让人满意,那么就有可能是我们在数据探索和特征工程中做的不够到位。
随机森林、决策树、SVM、KNN
python
# 尝试其他模型并比较准确率
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
models = {
'Random Forest': RandomForestClassifier(random_state=42),
'SVM': SVC(random_state=42),
'Decision Tree': DecisionTreeClassifier(random_state=42),
'KNN': KNeighborsClassifier()
}
results = {}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
acc = accuracy_score(y_val, y_pred)
results[name] = acc
print(f"{name}: {acc:.4f}")输出如下
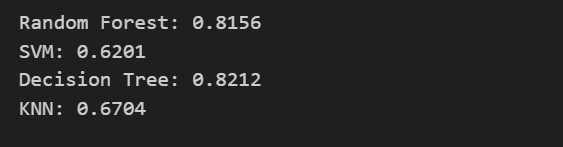
可以发现,决策树表现最好,准确率82.12%,比逻辑回归高1.67%。
泰坦尼克数据集实际上是一个有很多噪声的数据集,尽管我们已经进行了处理,但仍有一些问题,比如部分乘客的存活与否和特征无关(如随机被救),模型无法通过特征捕捉。因此是很难做到高准确率的。
接下来,我们会尝试使用其它方法来尽可能提高准确率。