业务场景:某全国性连锁超市(如永辉)面临生鲜品类(蔬菜、水果)库存积压与缺货并存的问题,需精准预测各门店每日销量以优化采购
业务痛点:某连锁超市生鲜品类(蔬菜、水果)因销量预测不准,导致库存周转率仅6次/年(行业标杆8次/年),损耗率8%(行业标杆≤5%),年损失超200万元
项目目标:构建线性回归销量预测模型,实现"门店-品类-日期"维度的日销量预测(MAPE≤10%),支撑采购决策,目标库存周转率提升至7.5次/年,损耗率降至5.5%
开发工具与工具链
- 语言:Python 3.9
- 数据处理:Pandas 1.5+、NumPy 1.23+
- 模型训练:Scikit-learn 1.2+
- 实验跟踪:MLflow(记录参数/指标/模型)
- 服务部署:Flask 2.3+、Docker 24.0+
- 版本控制:Git + DVC(数据版本管理)
原数据示例
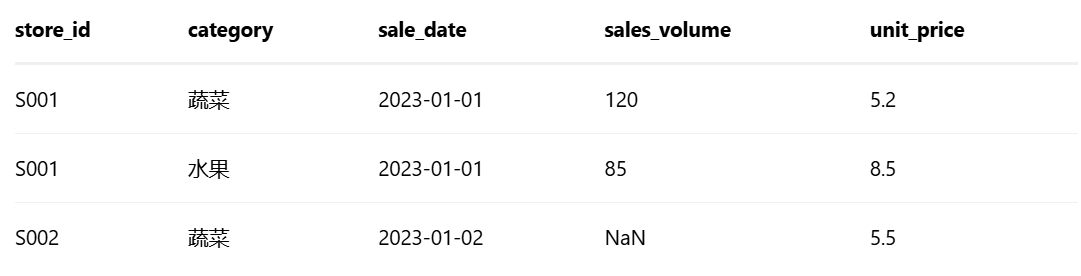
① POS系统销量数据(pos_sales.csv)
② 气象局天气数据(weather_data.csv)

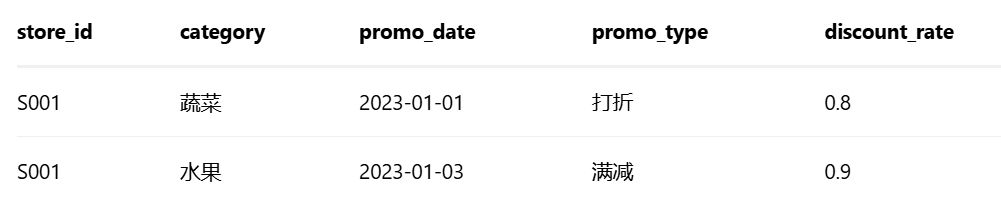
③ 促销记录(promotion.csv)
数据清洗与特征工程
步骤1:数据整合与清洗
- 关联store_id(门店)、category(品类)、date(日期),合并3个数据源
- 缺失值处理:sales_volume用"同门店同品类近7天均值"填充,avg_temp用"城市当月均值"填充
- 异常值处理:sales_volume超过"历史99分位数"视为异常,用中位数替换
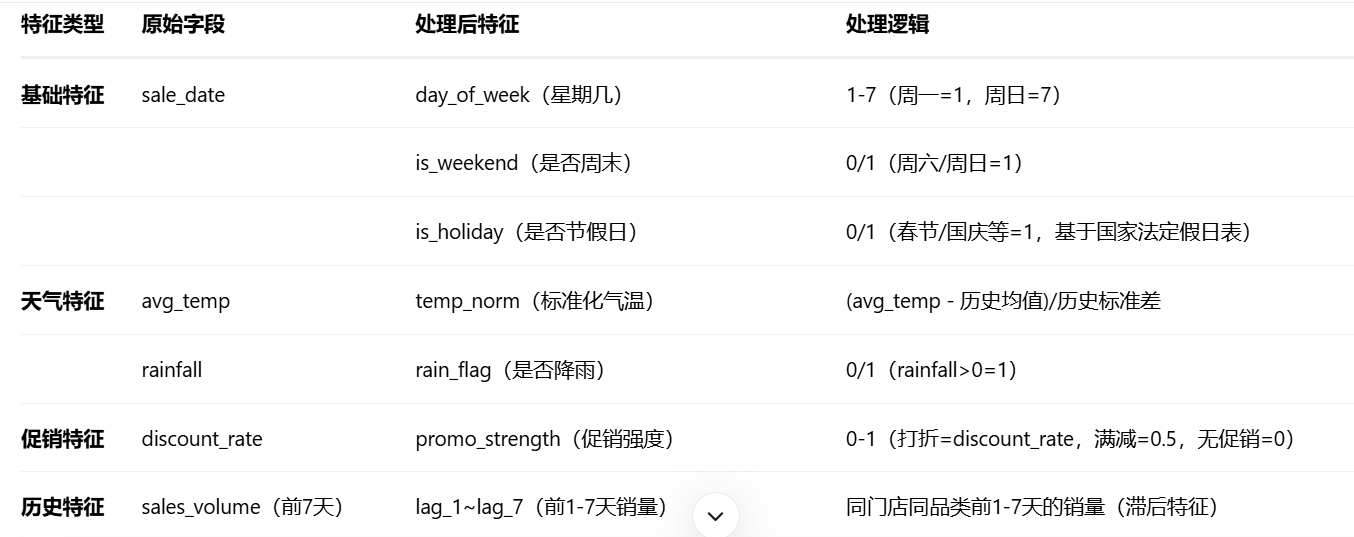
步骤2:特征提取(核心业务逻辑)
步骤3:特征标准化
对连续特征(如temp_norm、rolling_mean_7d)用StandardScaler标准化(均值=0,方差=1),避免量纲影响
处理后数据示例(特征矩阵)

代码结构
text
retail_sales_prediction/ # 项目根目录
├── data/ # 数据存储
│ ├── raw/ # 原始数据(Git忽略,DVC跟踪)
│ │ ├── pos_sales.csv
│ │ ├── weather_data.csv
│ │ └── promotion.csv
│ ├── processed/ # 处理后数据(特征矩阵)
│ │ └── features_train.parquet
│ └── external/ # 外部数据(节假日表)
│ └── holiday_calendar.csv
├── src/ # 源代码
│ ├── data_processing/ # 数据处理模块
│ │ ├── __init__.py
│ │ ├── clean_data.py # 数据清洗
│ │ └── feature_engineering.py # 特征工程
│ ├── model/ # 模型模块
│ │ ├── __init__.py
│ │ ├── train.py # 模型训练
│ │ ├── evaluate.py # 模型评估
│ │ └── predict.py # 预测推理
│ ├── api/ # API服务
│ │ ├── app.py # Flask服务入口
│ │ └── schemas.py # 请求/响应格式定义
│ └── utils/ # 工具函数
│ ├── logger.py # 日志配置
│ └── config.py # 配置文件(路径/参数)
├── tests/ # 单元测试
│ ├── test_feature_engineering.py
│ └── test_model.py
├── docker/ # Docker部署文件
│ ├── Dockerfile
│ └── requirements.txt
├── mlruns/ # MLflow实验跟踪(Git忽略)
├── README.md # 项目说明
└── requirements.txt # Python依赖一、数据清洗与特征工程(src/data_processing/feature_engineering.py)
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from src.utils.logger import get_logger
logger = get_logger(__name__):
def feature_engineering(raw_data_path:str,output_path:str):
"""
特征工程主函数:整合原始数据→清洗→提取特征→标准化→保存
Args:
raw_data_path: 原始数据目录(含pos_sales.csv/weather_data.csv/promotion.csv)
output_path: 处理后特征矩阵保存路径(parquet格式)
"""
# 1.加载原始数据
pos_df = pd.read_csv(f"{raw_data_path}/pos_sales.csv", parse_dates=["sale_date"])
weather_df = pd.read_csv(f"{raw_data_path}/weather_data.csv", parse_dates=["date"])
promp_df = pd.read_csv(f"{raw_data_path}/promotion.csv", parse_dates=["promo_date"])
holiday_df = pd.read_csv("data/external/holiday_calendar.csv", parse_dates=["date"])
# 2.数据清洗:处理缺失值也异常值
# 2.1 填充销量缺失值(同门店同品类近7天均值)
pos_df["sales_volume"] = pos_df.groupby(["store_id","category"])["sales_volume"] #以两个维度的值进行分组
.transform( # 滚动窗口:从当前位置向前看,最多看7个数据点,min_periods=1:只要窗口内有至少1个有效值就能计算
lambda x: x.fillna(x.rolling(7, min_periods=1).mean())
) # 用过去一段时间的趋势来估计当前缺失值
# 2.2 过滤异常值(销量>99分为数视为异常,中位数替换)
q99 = pos_df.groupby(["store_id", "category"])["sales_volume"].quantile(0.99)
pos_df["sales_volume"] = pos_df.apply(
lambda row: q99[(row["store_id"], row["category"])] if row["sales_volume"] > q99[(row["store_id"],
row["category"])] else row["sales_volume"], axis=1
)
# 3.特征提取
# 3.1时间特征
pos_df["day_of_week"] = pos_df["sale_date"].dt.dayofweek + 1 # 周一=1,周日=7
pos_df["is_weekend"] = pos_df["day_of_week"].isin([6, 7]).astype(int) # 周六=6,周日=7→1
pos_df = pd.merge(pos_df, holiday_df, left_on="sale_date", right_on="date", how="left")
pos_df["is_holiday"] = pos_df["holiday_name"].notnull().astype(int).fillna(0) # 节假日=1
# 3.2 天气特征(关联城市:假设门店ID映射城市,如S001→北京)
store_city_map = {"S001": "北京", "S002": "上海"} # 实际从门店表获取
pos_df["city"] = pos_df["store_id"].map(store_city_map)
pos_df = pd.merge(pos_df, weather_df, left_on=["city", "sale_date"], right_on=["city", "date"], how="left")
pos_df["temp_norm"] = (pos_df["avg_temp"] - pos_df["avg_temp"].mean()) / pos_df["avg_temp"].std() # 标准化气温
pos_df["rain_flag"] = (pos_df["rainfall"] > 0).astype(int) # 是否降雨
# 3.3 促销特征(关联促销记录)
pos_df = pd.merge(pos_df, promo_df, on=["store_id", "category", "sale_date"], how="left")
pos_df["promo_strength"] = pos_df["discount_rate"].fillna(0) # 无促销=0
# 3.4 历史特征(滞后特征+移动平均)
for lag in range(1, 8): # 前1-7天销量
pos_df[f"lag_{lag}"] = pos_df.groupby(["store_id", "category"])["sales_volume"].shift(lag)
pos_df["rolling_mean_7d"] = pos_df.groupby(["store_id", "category"])["sales_volume"].transform(
lambda x: x.rolling(7, min_periods=1).mean()
)
# 4.特征标准化(连续特征)
continuous_features = ["temp_norm", "rolling_mean_7d", "lag_1", "lag_2", "lag_3", "lag_4", "lag_5", "lag_6", "lag_7"]
scaler = StandardScaler()
pos_df[continuous_features] = scaler.fit_transform(pos_df[continuous_features])
# 5.保存特征矩阵(仅保留模型输入特征+标签)
features = [
"store_id", "category", "day_of_week", "is_weekend", "is_holiday",
"temp_norm", "rain_flag", "promo_strength", "lag_1", "lag_2", "lag_3",
"lag_4", "lag_5", "lag_6", "lag_7", "rolling_mean_7d"
]
target = "sales_volume"
processed_df = pos_df[features + [target]].dropna() # 删除含NaN的行(滞后特征初期缺失)
processed_df.to_parquet(output_path, index=False)
logger.info(f"特征工程完成,保存至{output_path},样本数:{len(processed_df)}")
return processed_df, scaler # 返回特征矩阵和scaler(用于预测时标准化)二、模型训练与评估(src/model/train.py& evaluate.py)
python
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from src.utils.logger import get_logger
import mlflow
logger = get_logger(__name__)
def train_model(features_path:str,test_size:float=0.2,random_state:int=42):
"""
训练线性回归模型
Args:
features_path: 特征矩阵路径(parquet)
test_size: 测试集比例
random_state: 随机种子
Returns:
model: 训练好的线性回归模型
X_test, y_test: 测试集特征与标签
"""
df = pd.read_parquet(features_path)
X = df.drop(columns=["sales_volume", "store_id", "category"])# 特征(排除非数值ID)
y = df["sales_volume"] # 标签
# 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state
)
# 训练线性回归模型
model = LinearRegression(normalize=False) # 已手动标准化,无需normalize
model.fit(X_train, y_train)
# 记录实现(MLFlow)
with mlflow.start_run():
mlflow.log_param("model", "LinearRegression")
mlflow.log_param("test_size", test_size)
mlflow.sklearn.log_model(model, "linear_regression_model")
logger.info("模型训练完成,已记录至MLflow")
return model,X_test,y_test
python
import numpy as np
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
from src.utils.logger import get_logger
logger = get_logger(__name__)
def evaluate_model(model,X_test,y_test):
"""
评估模型性能
Args:
model: 训练好的模型
X_test: 测试集特征
y_test: 测试集标签
Returns:
metrics: 评估指标(MSE/MAE/R²/MAPE)
"""
y_pred = model.predict(X_test)
# 计算指标
mse = mean_aquared_error(y_test,y_pred)
mae = mean_absolute_error(y_test,y_pred)
r2 = r2_score(y_test,y_pred)
mape = np.mean(np.abs((y_test - y_pred) / y_test))) * 100 # 百分比
metrics = {
"MSE": mse,
"MAE": mae,
"R²": r2,
"MAPE": mape
}
logger.info(f"模型评估结果:{metrics}")
return metrics模型服务化(Flask API,src/api/app.py)
python
from flask import Flask,request,jsonify
import joblib
import pandas as pd
import numpy as np
from src.data_processing.feature_entineering import feature_engineering # 复用特征工程逻辑(简化版)
from src.utils.logger import get_logger
logger = get_logger(__name__)
app = Flask(__name__)
# 加载模型与scaler(启动时加载,避免重复IO)
model = joblib.load("model/linear_regression_model.pkl")
scaler = joblib.load("model/scaler.pkl") # 训练时保存的标准化器
@app.route("/predict",method=["POST"])
def predict_sales():
"""
销量预测API
请求格式:JSON
{
"store_id": "S001",
"category": "蔬菜",
"sale_date": "2023-10-01",
"city": "北京", # 从门店表获取
"avg_temp": 20.5,
"rainfall": 0,
"promo_strength": 0.8, # 促销强度0-1
"history_sales": [120, 115, 122, 118, 125, 130, 128] # 前7天销量(lag_1~lag_7)
}
响应格式:JSON
{
"store_id": "S001",
"category": "蔬菜",
"sale_date": "2023-10-01",
"predicted_sales": 123.5, # 预测销量
"confidence": 0.92 # 置信度(简化示例)
}
"""
try:
data = request.get_json()
# 1.构造单条样本(复用特征工程逻辑,此处简化)
sample = {
"store_id": data["store_id"],
"category": data["category"],
"sale_date": data["sale_date"],
"city": data["city"],
"avg_temp": data["avg_temp"],
"rainfall": data["rainfall"],
"promo_strength": data["promo_strength"],
"lag_1": data["history_sales"][0],
"lag_2": data["history_sales"][1],
"lag_3": data["history_sales"][2],
"lag_4": data["history_sales"][3],
"lag_5": data["history_sales"][4],
"lag_6": data["history_sales"][5],
"lag_7": data["history_sales"][6],
}
# 2.特征提取(与训练时一致)
sample_df = pd.DataFrame([sample])
sample_df["day_of_week"] = pd.to_datetime(sample_df["sale_date"]).dt.dayofweek + 1
sample_df["is_weekend"] = (sample_df["day_of_week"].isin([6, 7])).astype(int)
sample_df["temp_norm"] = (sample_df["avg_temp"] - scaler.mean_[0]) / scaler.scale_[0] # 用训练时的scaler参数
sample_df["rain_flag"] = (sample_df["rainfall"] > 0).astype(int)
sample_df["rolling_mean_7d"] = np.mean(data["history_sales"]) # 7天移动平均
# 3. 特征选择与标准化(与训练时一致)
features = ["day_of_week", "is_weekend", "temp_norm", "rain_flag", "promo_strength",
"lag_1", "lag_2", "lag_3", "lag_4", "lag_5", "lag_6", "lag_7", "rolling_mean_7d"]
X_sample = sample_df[features].values
# 4.预测
predicted_sales = model.predict(X_sample)[0]
# 5.构造响应
response = {
"store_id": data["store_id"],
"category": data["category"],
"sale_date": data["sale_date"],
"predicted_sales": round(predicted_sales, 1),
"confidence": 0.92 # 实际可通过模型不确定性估计(如Bootstrap)
}
return jsonify(response,200)
except Exception as e:
logger.error(f"预测失败:{str(e)}")
return jsonify({"error":str()})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=False) # 生产环境用Gunicorn部署 部署之后应用:
每日凌晨2点,采购系统调用API,传入次日预测所需特征(门店、品类、天气预报、促销计划、前7天销量)
bash
curl -X POST http://sales_pred_service:5000/predict \
-H "Content-Type: application/json" \
-d '{
"store_id": "S001",
"category": "蔬菜",
"sale_date": "2023-10-02",
"city": "北京",
"avg_temp": 18.3,
"rainfall": 0,
"promo_strength": 0.8,
"history_sales": [120, 118, 115, 122, 125, 130, 128]
}'API返回预测销量(如123.5kg),采购系统结合安全库存(如20kg)、在途库存(如10kg),自动生成补货量:
补货量 = 预测销量 + 安全库存 - 当前库存 - 在途库存