引言:RAG技术的重要性与核心架构
在当今人工智能快速发展的时代,检索增强生成(Retrieval-Augmented Generation,RAG)技术已成为连接大型语言模型与特定领域知识的关键桥梁。RAG通过从外部知识库中检索相关信息来增强LLM的生成过程,显著提高了回答的准确性和时效性。本文将深入解析RAG知识库的核心API架构,帮助开发者全面理解从原始文档到智能检索的完整流程。
一、RAG知识库核心架构全景图
从第一张架构图可以看出,RAG知识库处理流程遵循清晰的流水线设计:
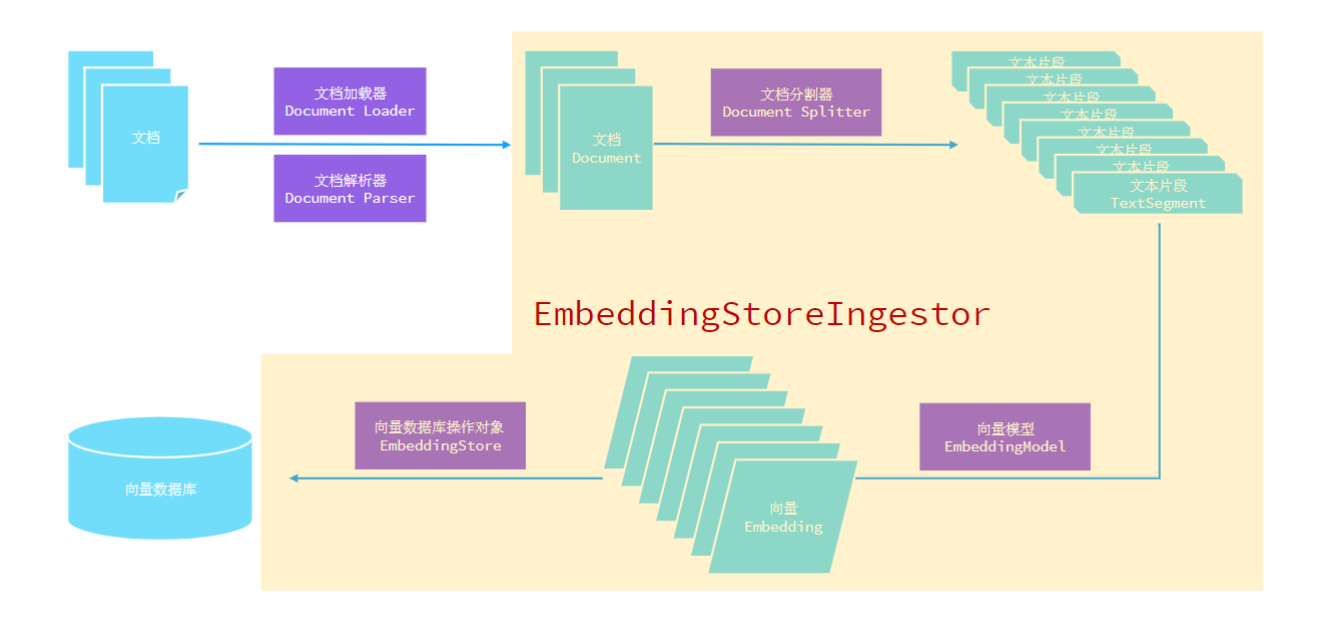
这个流程体现了数据从非结构化到结构化,再到向量化表示的全过程。每个环节都有专门的技术组件负责,形成了一个模块化、可扩展的系统架构。
二、文档加载器(Document Loader):数据入口的多元化支持
文档加载器是RAG系统的"数据入口",负责从各种来源加载文档数据。根据第二张图的介绍,常见的文档加载器包括:
1. FileSystemDocumentLoader
-
功能:根据本地磁盘绝对路径加载文档
-
适用场景:本地文件系统存储的文档
-
优势:加载效率高,访问速度快
2. ClasspathDocumentLoader
-
功能:相对于类路径加载文档
-
适用场景:应用程序内置资源文件
-
优势:与应用程序打包部署一致
3. UrlDocumentLoader
-
功能:根据URL路径加载网络文档
-
适用场景:互联网上的公开文档资源
-
优势:支持动态内容获取
最佳实践:在实际项目中,建议根据数据来源的稳定性、访问速度和安全性要求,选择合适的加载器组合。对于生产环境,通常需要实现混合加载策略。
三、文档解析器(Document Parser):格式转换的专业化处理
文档解析器负责将非纯文本数据转化为机器可读的纯文本格式。第三张图展示了多种解析器的专业化分工:
主流文档解析器对比
| 解析器类型 | 支持格式 | 特点 | 适用场景 |
|---|---|---|---|
| TextDocumentParser | 纯文本文件 | 处理简单,效率高 | 日志文件、配置文件 |
| ApachePdfBoxDocumentParser | PDF文档 | 开源免费,功能全面 | 技术文档、研究报告 |
| ApachePoiDocumentParser | Office文档 | 微软官方格式支持 | 企业文档、报告 |
| ApacheTikaDocumentParser | 几乎所有格式 | 全能型解析器 | 混合格式文档库 |
配置示例
javascript
// 引入PDF解析器依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdf-box</artifactId>
<version>1.0.1-beta6</version>
</dependency>
// 使用示例
ClasspathDocumentLoader.loadDocuments(
"data/document.pdf",
new ApachePdfBoxDocumentParser()
);技术要点:Apache Tika作为默认解析器,采用MIME类型检测和内容提取技术,能够处理超过1400种文件格式,是构建通用文档处理系统的首选。
四、文档分割器(Document Splitter):智能分块的策略选择
文档分割是RAG系统中的关键预处理步骤,直接影响检索质量和上下文相关性。
分割策略详解
-
DocumentByParagraphSplitter
-
按照自然段落分割
-
优点:保持语义完整性
-
适用:结构化文档、技术文档
-
-
DocumentBySentenceSplitter
-
按照句子边界分割
-
优点:符合语言结构
-
适用:新闻报道、文章
-
-
DocumentByRegexSplitter
-
按照正则表达式分割
-
优点:灵活性高
-
适用:特定格式文档
-
-
DocumentSplitters.recursive()(默认)
-
递归分割策略
-
执行顺序:段落→行→句子→词
-
优点:鲁棒性强,适应多种情况
-
配置与调优
java
// 构建分割器示例
DocumentSplitter documentSplitter = DocumentSplitters.recursive(
300, // 每个片段最大字符数
50 // 片段重叠字符数
);参数调优建议:
-
片段大小:通常设置在300-1000字符之间,需平衡上下文完整性和检索精度
-
重叠大小:设置10-20%的重叠可以避免重要信息被切割
-
策略选择:中文文档建议使用按句子或段落分割,英文文档可使用递归分割
五、向量模型(Embedding Model):语义理解的核心引擎
向量模型是将文本转换为数值向量的关键组件,决定了语义理解的准确性。
配置文件
java
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: text-embedding-v3
log-requests: true
log-responses: true
max-segments-per-batch: 10EmbeddingModel接口设计
java
public interface EmbeddingModel {
// 单个文本向量化
default Response<Embedding> embed(String text) {
return this.embed(TextSegment.from(text));
}
// 批量向量化
Response<List<Embedding>> embedAll(List<TextSegment> texts);
// 获取向量维度
default int dimension() {
return ((Embedding)this.embed("test").content()).dimension();
}
}模型选型推荐
-
BGE (BAAI General Embedding) 系列
-
如BgeSmallEnV15QuantizedEmbeddingModel
-
优势:中英文混合表现优秀,支持量化
-
适用:多语言场景
-
-
OpenAI Embeddings
-
优势:API稳定,效果优秀
-
注意:需考虑成本和延迟
-
-
本地化模型
-
如Sentence-BERT、Instructor
-
优势:数据隐私保护,无网络延迟
-
适用:对数据安全要求高的场景
-
配置示例
java
// 配置向量模型
EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel) // 设置向量模型
.maxResults(3) // 最大返回结果数
.minScore(0.6) // 最小相似度分数
.build();六、向量数据库与存储操作(Embedding Store)
向量数据库是RAG系统的长期记忆,负责高效存储和检索向量数据。
EmbeddingStore接口设计
java
public interface EmbeddingStore<Embedded> {
// 添加单个向量
String add(Embedding embedding);
// 添加文本和向量
void add(String text, Embedding embedding);
// 相似性搜索
EmbeddingSearchResult<Embedded> search(EmbeddingSearchRequest request);
}主流向量数据库对比
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Milvus | 专为向量设计,性能优秀 | 大规模向量检索 |
| Chroma | 轻量级,易于部署 | 原型开发和小型项目 |
| Pinecone | 全托管服务,易用性好 | 云原生应用 |
| RedisSearch | 基于Redis,内存存储 | 实时性要求高的场景 |
| pgvector | PostgreSQL扩展,ACID特性 | 需要事务支持的应用 |
Redis向量数据库完整配置示例
1. 准备向量数据库
bash
# 停止并运行Redis向量数据库
docker stop redis-vector
docker rm redis-vector
docker run -d --name redis-vector -p 6379:6379 redislabs/redisearch:latest2. 引入依赖
XML
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-store-embedding-redis</artifactId>
<version>1.0.1-beta6</version>
</dependency>3. 配置文件
spring:
redis:
host: localhost
port: 6379
password:
database: 04. 代码实现
java
// 注入并使用RedisEmbeddingStore
@Autowired
private RedisEmbeddingStore embeddingStore;
// 文档摄入
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(documentSplitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
// 内容检索
EmbeddingStoreContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5)
.minScore(0.7)
.build();结语
RAG知识库的建设是一个系统工程,每个环节都需要精心设计和优化。通过本文对核心API的详细解析,相信读者已经对RAG知识库的构建有了全面的理解。在实际应用中,建议根据具体业务需求,灵活选择和组合这些组件,并持续监控和优化系统性能。
记住:优秀的RAG系统不是单一组件的简单堆砌,而是各个组件协同工作的结果。从文档加载到向量检索,每个环节的优化都能为最终效果带来提升。