InterviewGuide 是一个集成了简历分析、模拟面试和知识库管理的智能面试辅助平台。系统利用大语言模型(LLM)和向量数据库技术,为求职者和 HR 提供智能化的简历评估和面试练习服务。
项目地址:
Github:https://github.com/Snailclimb/interview-guide
Gitee:https://gitee.com/SnailClimb/interview-guide
这是一个基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 的 AI 智能面试辅助平台。系统提供三大核心功能:
智能简历分析:上传简历后,AI 自动进行多维度评分并给出改进建议
模拟面试系统:基于简历内容生成个性化面试题,支持实时问答和答案评估
RAG 知识库问答:上传技术文档构建私有知识库,支持向量检索增强的智能问答
1、添加 API 限流保护:基于 Redis+Lua 封装分布式限流组件,支持按用户、IP 或全局维度的精准流量控制,有效防御恶意刷接口行为,保障高价值 AI API 的配额安全。
2、前端性能优化:
RAG 聊天界面引入虚拟列表。
引入懒加载和代码分割,解决了首屏加载缓慢和 Bundle 体积过大的问题。
3、功能优化:
向量功能和 Tika 简历解析优化。
增加面试问题去重功能,避免重复提问。
4、Docker 快速部署:通过 Docker Compose 一键搭建包含数据库扩展、缓存、对象存储在内的全套运行环境。
5、后端方向:提供"架构与分布式能力侧重"、"AI 应用与响应式编程侧重"、"工程化与基础设施侧重"三个版本,无论你面试的是后端、大模型应用还是架构岗位,都能找到最合适的切入点。
6、测试/测开方向:专门设计了"单元测试与 TDD"以及"功能/异常场景覆盖"两个版本,突出测试工程师在 AI 质量保障中的核心竞争力。
后端方向版本一(架构与分布式能力侧重)
技术栈列表:
- Java 21
- Spring Boot 4.0
- Spring AI 2.0
- PostgreSQL(含 pgvector 向量扩展)
- Redis
- Apache Tika(用于文档解析)
- iText 8(用于 PDF 处理)
- Docker(容器化部署)
- Gradle 8.14(构建工具)
这是一个基于大语言模型的简历分析与模拟面试系统,主要功能包括:
- 简历评估与建议
- 个性化面经练习
- 简历/文档上传与智能问答
- PDF 报告导出
测试/测开方向版本二(功能测试与异常场景覆盖)
测试技术栈与工具:
- JUnit 5:单元测试框架
- Mockito:模拟框架(用于创建和管理测试替身,如 Mock、Stub)
- Spring Boot Test:Spring Boot 应用集成测试支持
- Redis:(用于集成测试或模拟缓存层)
- StepVerifier:(通常指 Project Reactor 的测试工具,用于测试响应式流,验证 SSE 流式输出)
- AssertJ:流式断言库,提供更丰富的断言语法
- inOrder 验证:(通常指 Mockito 的验证模式,确保方法按特定顺序调用)
测试覆盖核心功能:
- 向量检索服务测试
- SSE 流式输出验证
- 全局异常处理与系统稳定性测试
- 各种异常场景下的系统行为验证
根据您提供的多个章节标题,这看起来是一个基于大语言模型的简历分析与模拟面试系统 的完整项目开发课程大纲。以下是这些内容的梳理和归类:
📦 项目概述
一个基于大语言模型的智能简历分析与模拟面试平台,支持简历评估、RAG知识库问答、模拟面试和PDF报告导出等功能。
🗺️ 课程大纲结构
第一阶段:环境搭建
-
本地搭建 PostgreSQL + PGvector 向量数据库
- 向量数据库环境配置
- 支持简历和面经的向量化存储与检索
-
Spring Boot + RustFS 构建高性能 S3 兼容的对象存储服务
- 构建简历文件存储服务
- 支持多格式文档上传与管理
-
大模型 API 申请和 Ollama 部署本地模型
- 云端大模型API接入
- 本地模型部署(Ollama)
- 模型服务配置
-
环境搭建终章与项目启动
- 整体环境验证
- 项目初始化启动
第二阶段:核心功能开发
-
简历上传、多格式内容提取与解析
- 支持PDF/DOCX等格式
- 使用Apache Tika等工具进行内容提取
-
Spring AI 与大模型集成
- Spring AI框架接入
- 大模型对话接口实现
-
Spring AI + pgvector 实现 RAG 知识库问答
- 检索增强生成(RAG)实现
- 向量化检索与上下文增强
-
手把手教你写出生产级结构化 Prompt
- Prompt工程实践
- 结构化提示词设计
-
AI 模拟面试功能
- 智能面试对话
- 面试场景模拟
-
基于 iText 8 实现 PDF 报告导出
- 评估报告生成
- PDF格式化输出
-
基于 SSE(Server-Sent Events)的打字机效果输出
- 流式响应实现
- 实时打字机效果
-
Docker Compose 一键部署
- 容器化部署配置
- 多服务编排
第三阶段:进阶优化
-
统一异常处理与业务错误码设计
- 全局异常处理
- 标准化错误响应
-
MapStruct 实体映射最佳实践
- 对象映射优化
- 性能提升
-
基于 Redis Stream 的异步任务处理实现
- 异步任务队列
- 后台处理任务
-
Spring Boot 4.0 升级指南
- 版本迁移
- 新特性应用
🛠️ 涉及核心技术栈
- 后端框架:Spring Boot 4.0, Spring AI 2.0
- 数据库:PostgreSQL + pgvector, Redis
- AI/ML:大模型API, Ollama, RAG
- 文件处理:Apache Tika, iText 8
- 存储服务:RustFS (S3兼容对象存储)
- 部署:Docker, Docker Compose
- 构建工具:Gradle
- 开发语言:Java 21
🎯 项目特色功能
- 智能简历分析 - 多格式解析与内容提取
- RAG知识库 - 向量检索增强问答
- AI模拟面试 - 个性化面试练习
- 实时交互 - SSE流式输出打字机效果
- 专业报告 - PDF格式评估报告
- 高性能存储 - 自建S3兼容对象存储
- 生产级部署 - Docker容器化一键部署
这是一个非常完整的全栈AI应用开发项目,覆盖了从环境搭建、核心功能开发到生产优化的全流程。
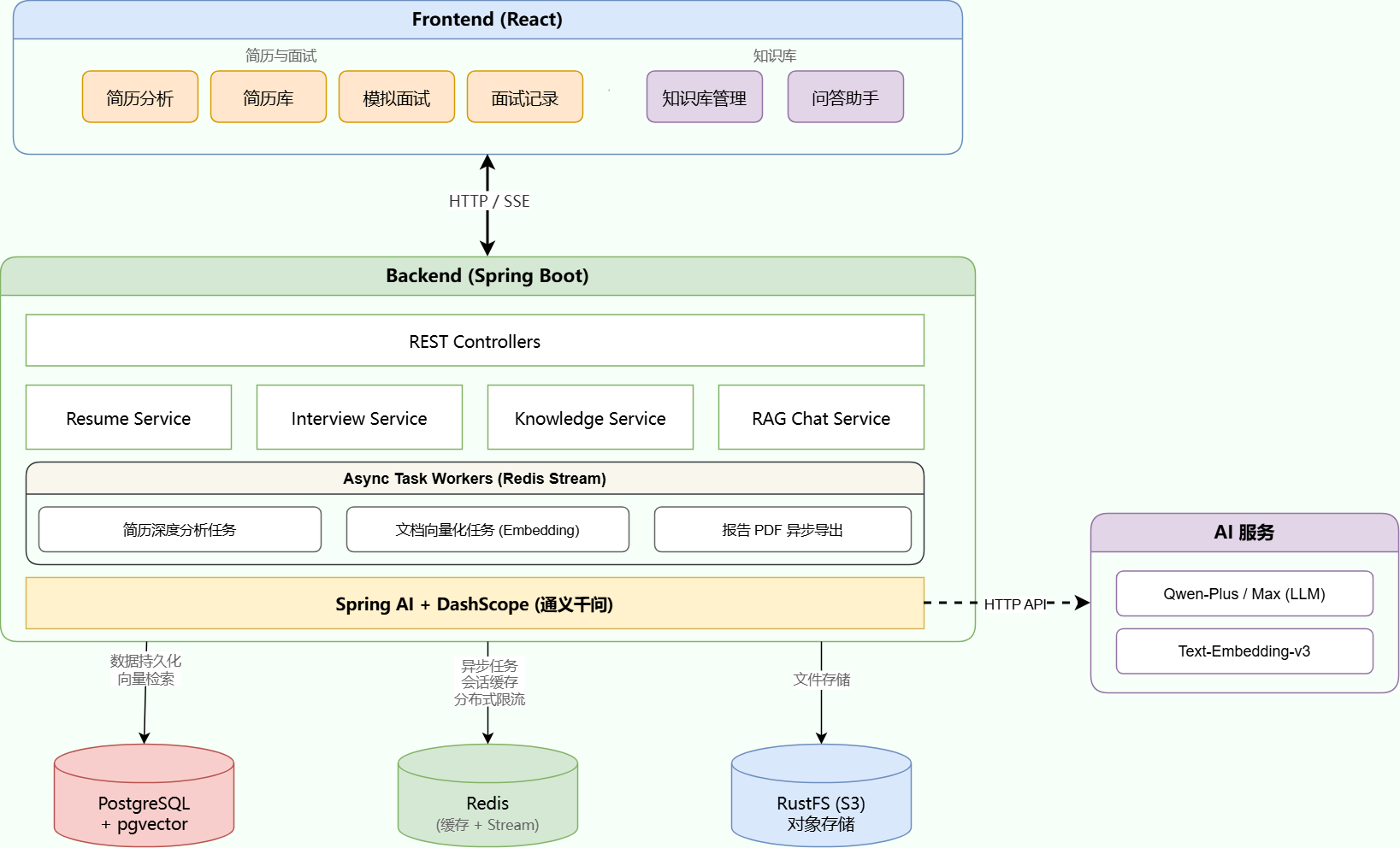
这是一个完整且专业的大模型简历分析与面试系统后端架构。
🏗️ 后端系统架构(五层设计)
1. REST Controllers(API入口层)
- 职责:统一的HTTP API入口,接收并验证请求
- 技术:Spring MVC RESTful API
- 功能:请求路由、参数校验、响应格式化
2. 业务服务层(核心业务逻辑)
| 服务模块 | 核心职责 |
|---|---|
| Interview Service | 面试会话管理、AI问题生成、答案评估 |
| Knowledge Service | 知识库文档上传、文本分块、向量化处理 |
| RAG Chat Service | 检索增强生成、流式问答(打字机效果) |
| Resume Service | 简历上传、多格式解析、AI智能分析 |
3. 异步处理层(高性能关键)
- 技术:Redis Stream 消息队列
- 架构:生产者-消费者模式
- 异步任务类型 :
- 简历深度分析
- 知识库文档向量化
- 面试报告生成
- PDF报告导出
4. AI 集成层(智能核心)
- 框架:Spring AI 2.0
- 模型对接:DashScope(通义千问)API + 本地Ollama
- 统一接口 :标准化LLM调用,支持:
- 对话生成(模拟面试)
- 文本向量化(embedding)
- 内容分析评估
5. 数据存储层(多类型存储)
| 存储类型 | 技术方案 | 存储内容 |
|---|---|---|
| 关系+向量数据库 | PostgreSQL + pgvector | 用户数据、元数据、向量数据 |
| 缓存+队列 | Redis | 会话状态、任务队列 |
| 文件存储 | RustFS/MinIO (S3兼容) | 原始文件(PDF、DOCX等) |
🔄 核心流程详解
📄 异步处理流程(简历分析/向量化)
1. 上传请求 → 保存文件到S3 → 发送Redis Stream消息 → 立即返回任务ID
2. 后台Consumer监听Stream → 消费消息
3. 执行分析/向量化任务(调用AI服务)
4. 更新数据库任务状态
5. 前端轮询获取任务状态状态流转 :PENDING → PROCESSING → COMPLETED / FAILED
💬 知识库问答流程(RAG)
1. 用户提问 → 问题向量化(Embedding)
2. pgvector相似度搜索 → 检索相关文档片段
3. 构建上下文增强的Prompt
4. LLM生成智能回答
5. SSE流式返回(打字机效果)🛠️ 完整技术栈概览
后端开发
- 语言: Java 21
- 框架: Spring Boot 4.0 + Spring AI 2.0
- 构建: Gradle 8.14
- 对象映射: MapStruct
数据存储
- 主库: PostgreSQL + pgvector(向量检索)
- 缓存/队列: Redis + Redis Stream
- 文件存储: RustFS/MinIO(S3兼容)
AI/ML能力
- AI框架: Spring AI
- 大模型: 通义千问(DashScope)+ Ollama本地模型
- RAG: 检索增强生成
文件处理
- 文档解析: Apache Tika
- PDF生成: iText 8
- 流式输出: SSE(Server-Sent Events)
部署运维
- 容器化: Docker + Docker Compose
- 测试: JUnit 5, Mockito, Spring Boot Test
- 监控: 统一异常处理、业务错误码
🎯 架构优势
- 解耦清晰:五层架构,职责分离
- 性能优化:异步处理耗时任务,SSE流式响应
- 扩展性强:支持多模型、多存储、多格式
- 生产就绪:完整的异常处理、监控、部署方案
- AI友好:深度集成Spring AI,统一LLM接口
这是一个典型的现代化AI应用后端架构,结合了传统微服务设计模式与AI专项能力,适合作为生产级项目模板。
🏗️ 智能简历分析与模拟面试系统 - 技术架构文档
📋 技术栈总览
🖥️ 后端技术栈
| 技术 | 版本 | 说明 |
|---|---|---|
| Spring Boot | 4.0 | 应用框架 |
| Java | 21 | 开发语言 |
| Spring AI | 2.0 | AI集成框架 |
| PostgreSQL + pgvector | 14+ | 关系数据库 + 向量存储 |
| Redis | 6+ | 缓存 + 消息队列(Stream) |
| Apache Tika | 2.9.2 | 多格式文档解析 |
| iText 8 | 8.0.5 | PDF报告导出 |
| MapStruct | 1.6.3 | 高性能对象映射 |
| Gradle | 8.14 | 构建工具 |
🎨 前端技术栈
| 技术 | 版本 | 说明 |
|---|---|---|
| React | 18.3 | UI框架 |
| TypeScript | 5.6 | 开发语言 |
| Vite | 5.4 | 构建工具 |
| Tailwind CSS | 4.1 | 原子化CSS框架 |
| React Router | 7.11 | 路由管理 |
| Framer Motion | 12.23 | 动画库 |
| Recharts | 3.6 | 图表库 |
| Lucide React | 0.468 | 图标库 |
🔍 关键技术选型详解
1. 为什么选择 Spring AI?
核心优势:
- 统一抽象:一套代码支持多种LLM提供商(OpenAI、阿里云DashScope、Ollama等)
- 生态集成:与Spring Boot无缝集成,支持自动配置、依赖注入
- 向量存储支持:原生支持pgvector、Milvus等向量数据库
- 结构化输出 :通过
BeanOutputConverter将LLM输出直接映射为Java对象
java
// Spring AI 结构化输出示例
var converter = new BeanOutputConverter<>(ResumeAnalysisDTO.class);
String result = chatClient.prompt()
.system(systemPrompt)
.user(userPrompt + converter.getFormat())
.call()
.content();
return converter.convert(result); // 直接得到Java对象2. 为什么选择 PostgreSQL + pgvector?
方案对比分析:
| 方案 | 优点 | 缺点 |
|---|---|---|
| PostgreSQL + pgvector | 一套数据库搞定,运维简单 | 向量检索性能不如专业向量库 |
| PostgreSQL + Milvus | 向量检索性能更好 | 多一个组件,运维复杂度增加 |
| PostgreSQL + Pinecone | 云托管,无需运维 | 成本高,数据在第三方 |
选择理由:
- 架构简单:不引入额外组件,降低运维复杂度
- 性能够用:HNSW索引支持毫秒级检索,万级文档场景足够
- 事务一致性:向量数据和业务数据在同一数据库
- SQL查询:可结合WHERE条件进行过滤检索
sql
-- pgvector 相似度搜索示例
SELECT content, 1 - (embedding <=> $1) as similarity
FROM vector_store
WHERE metadata->>'category' = 'Java'
ORDER BY embedding <=> $1
LIMIT 5;3. 为什么引入 Redis?
主要使用场景:
- 会话缓存:替代ConcurrentHashMap实现分布式会话管理
- 异步任务队列:基于Redis Stream处理耗时AI任务(简历分析、向量化)
消息队列方案对比:
| 维度 | Redis Stream | RabbitMQ | Kafka | 内存队列 |
|---|---|---|---|---|
| 吞吐量 | 高(十万级QPS) | 中(万级QPS) | 极高(百万级) | 极高(千万级) |
| 延迟 | 极低(亚毫秒) | 低(毫秒) | 中(毫秒级) | 极低(纳秒) |
| 持久化 | 支持(RDB/AOF) | 支持 | 强支持 | 无 |
| 运维复杂度 | 低 | 中 | 高 | 极低 |
| 适用场景 | 轻量级流处理 | 复杂路由 | 大数据流 | 进程内解耦 |
选择Redis Stream的理由:
- 复用现有组件:无需引入新中间件
- 功能满足需求:支持消费者组、消息确认、持久化
- 运维简单:对中小型项目完全够用
4. 构建工具为什么选择 Gradle?
- SpringBoot官方现在使用Gradle
- 相比Maven更新颖,配置更简洁
- 个人偏好,构建脚本更灵活
5. 为什么使用 MapStruct?
对象映射方案对比:
| 方案 | 性能 | 类型安全 | 使用复杂度 |
|---|---|---|---|
| MapStruct | 零反射,最快 | 编译时检查 | 定义接口即可 |
| BeanUtils | 反射,慢 | 运行时报错 | 一行代码 |
| ModelMapper | 反射,较慢 | 运行时报错 | 配置复杂 |
| 手写转换 | 最快 | 编译时检查 | 重复代码多 |
6. 为什么使用 Apache Tika?
- 格式支持全:支持上百种文档格式(PDF、DOCX、TXT等)
- 自动识别:根据文件内容自动检测格式
- 统一API:屏蔽不同格式差异,统一提取纯文本
java
// Tika解析示例
Tika tika = new Tika();
String content = tika.parseToString(inputStream); // 自动识别并提取文本7. 为什么使用 SSE 而不是 WebSocket?
技术方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| SSE | 简单,基于HTTP,单向推送 | 仅支持服务端→客户端 |
| WebSocket | 双向通信,功能强大 | 协议复杂,需维护连接状态 |
选择SSE的理由:
- 场景匹配:LLM流式输出是单向的(服务端→客户端)
- 实现简单:基于HTTP,天然支持重连、跨域
- Spring支持好 :
Flux<ServerSentEvent<String>>一行代码搞定
8. 前端技术选型理由
| 技术 | 选择理由 |
|---|---|
| React | 生态最成熟,组件化开发,社区资源丰富 |
| TypeScript | 类型安全,IDE智能提示,减少运行时错误 |
| Vite | 开发服务器启动快(秒级),HMR热更新体验好 |
| Tailwind CSS | 原子化CSS,快速开发,无需写CSS文件 |
🎯 架构设计亮点
1. PostgreSQL的"瑞士军刀"优势
PostgreSQL在AI时代的核心优势是其强大的可扩展性:
- AI向量检索:pgvector扩展
- 全文搜索:内置支持或pg_bm25扩展
- 时序数据:TimescaleDB扩展
- 地理信息:PostGIS扩展
这种"一站式"解决能力让项目不需要依赖大量外部中间件,极大地简化了技术栈和运维成本。
2. 异步处理架构
- 耗时任务异步化:简历分析、向量化等10-60秒的任务异步处理
- 状态管理 :
PENDING → PROCESSING → COMPLETED/FAILED - 用户体验:立即返回任务ID,前端轮询获取结果
3. RAG流程优化
问题 → 向量化 → pgvector相似度搜索 → 上下文增强 → LLM生成 → SSE流式返回📊 技术选型总结
| 技术类别 | 选择方案 | 核心理由 |
|---|---|---|
| AI框架 | Spring AI | 官方支持,生态集成,统一抽象 |
| 数据库 | PostgreSQL + pgvector | 一体化方案,运维简单,事务一致 |
| 消息队列 | Redis Stream | 轻量级,复用组件,满足需求 |
| 对象映射 | MapStruct | 零反射,高性能,类型安全 |
| 文档解析 | Apache Tika | 格式支持全,自动识别 |
| 流式输出 | SSE | 场景匹配,实现简单 |
| 前端框架 | React + TS + Vite | 生态成熟,开发体验好 |
这个技术选型体现了务实与创新结合的理念:既选择了成熟稳定的基础框架(Spring Boot、React),又在AI集成(Spring AI)、向量存储(pgvector)等方面采用了前沿技术,整体架构既保证了开发效率,又具备良好的扩展性和维护性。
🚀 AI应用开发全栈架构方案
一、核心技术栈
后端技术矩阵:
- Java 21 + Spring Boot 4.0(虚拟线程赋能)
- Spring AI 2.0 - 统一的AI模型抽象层
- PostgreSQL 16 + pgvector - 一体化数据存储
- Redis 7 - 分布式限流与异步任务队列
- Apache Tika 2.9 - 多格式文档解析
前端技术生态:
- React 18 + TypeScript 5.0
- Tailwind CSS 4 - 原子化CSS框架
- Framer Motion - 交互动效引擎
- Recharts - 数据可视化库
- SSE - 服务器推送流式响应
二、架构设计亮点
1. 模块化单体架构
src/
├── domain/ # 核心业务领域
├── application/ # 应用服务层
├── infrastructure/ # 基础设施层
│ ├── ai/ # AI能力集成
│ ├── storage/ # 存储抽象
│ └── queue/ # 消息队列
├── interfaces/ # 对外接口层
└── common/ # 共享组件2. RAG全链路优化
java
// RAG处理管道
@Component
public class RAGPipeline {
@Autowired private DocumentParser parser;
@Autowired private TextSplitter splitter;
@Autowired private EmbeddingService embedding;
@Autowired private VectorStore vectorStore;
public CompletableFuture<RAGResponse> process(Document doc) {
return CompletableFuture.supplyAsync(() -> {
// 1. 文档解析与清洗
String content = parser.parse(doc)
.map(this::cleanText)
.filter(this::deduplicateByHash);
// 2. 智能分块(语义保持)
List<TextChunk> chunks = splitter.splitBySemantic(content);
// 3. 向量化与存储
List<Embedding> vectors = embedding.encode(chunks);
vectorStore.batchUpsert(vectors);
return buildResponse(chunks);
}, virtualThreadExecutor);
}
}3. 高性能对象映射
java
@Mapper(componentModel = "spring")
public interface ResumeMapper {
@Mapping(target = "skills", expression = "java(extractSkills(entity.getContent()))")
@Mapping(target = "score", ignore = true)
ResumeDTO toDTO(ResumeEntity entity);
// 编译期生成高效映射代码
default List<String> extractSkills(String content) {
return AIAnalyzer.extractSkills(content);
}
}三、核心特性实现
1. Spring AI 2.0深度集成
yaml
# application-ai.yml
spring:
ai:
openai:
base-url: ${AI_PROVIDER_URL}
api-key: ${API_KEY}
chat:
options:
model: gpt-4-turbo
temperature: 0.7
max-tokens: 2000
# 多模型支持配置
providers:
qwen:
api-key: ${QWEN_KEY}
chat:
model: qwen-max2. 智能提示词工程
java
@Bean
public PromptTemplate resumeAnalyzerPrompt() {
return new PromptTemplate("""
你是一个专业的简历分析师。
系统规则:
1. 以JSON格式返回分析结果
2. 包含技能匹配度评分(0-100)
3. 识别关键成就
用户简历:
{resume}
岗位要求:
{jobDescription}
请分析并返回:
""");
}
// 自动类型转换
@Bean
public BeanOutputConverter<AnalysisResult> analysisResultConverter() {
return new BeanOutputConverter<>(AnalysisResult.class);
}3. 分布式限流体系
lua
-- redis/rate_limit.lua
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local window = tonumber(ARGV[2])
local current = redis.call('GET', key)
if current and tonumber(current) >= limit then
return 0
else
redis.call('INCR', key)
redis.call('EXPIRE', key, window)
return 1
end四、部署架构
yaml
# docker-compose.yml
version: '3.8'
services:
app:
build: .
environment:
- JAVA_TOOL_OPTIONS=-XX:+UseZGC -Xmx2g
deploy:
resources:
limits:
cpus: '2'
memory: 4G
ports:
- "8080:8080"
postgres:
image: pgvector/pgvector:pg16
environment:
POSTGRES_DB: ai_app
POSTGRES_PASSWORD: ${DB_PASSWORD}
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
- pgdata:/var/lib/postgresql/data
redis:
image: redis:7-alpine
command: redis-server --appendonly yes
volumes:
- redis-data:/data五、性能优化策略
1. 向量检索优化
sql
-- 创建HNSW索引
CREATE INDEX ON document_embeddings
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 近似最近邻查询
SELECT * FROM document_embeddings
ORDER BY embedding <=> $1
LIMIT 10;2. 虚拟线程配置
java
@Configuration
public class VirtualThreadConfig {
@Bean
public AsyncTaskExecutor virtualThreadExecutor() {
return new TaskExecutorAdapter(
Executors.newVirtualThreadPerTaskExecutor()
);
}
@Bean
public TomcatProtocolHandlerCustomizer<?> protocolHandlerCustomizer() {
return protocolHandler -> {
protocolHandler.setExecutor(
Executors.newVirtualThreadPerTaskExecutor()
);
};
}
}六、监控与可观测性
java
@Aspect
@Component
@Slf4j
public class AIAPIMonitor {
@Around("@annotation(AICall)")
public Object monitorAICall(ProceedingJoinPoint joinPoint) {
long start = System.currentTimeMillis();
String model = getModelName(joinPoint);
try {
Object result = joinPoint.proceed();
long duration = System.currentTimeMillis() - start;
Metrics.recordLatency(model, duration);
Metrics.recordTokenUsage(model, extractTokenCount(result));
return result;
} catch (Exception e) {
Metrics.recordError(model, e.getClass().getSimpleName());
throw e;
}
}
}七、开发工具链
gradle
// versionCatalog.gradle
dependencyResolutionManagement {
versionCatalogs {
libs {
// Spring
library('spring-boot', 'org.springframework.boot:spring-boot-starter:4.0.0')
library('spring-ai', 'org.springframework.ai:spring-ai-core:2.0.0')
// 数据库
library('postgresql', 'org.postgresql:postgresql:42.7.0')
library('pgvector', 'com.pgvector:pgvector:0.1.4')
// 工具
library('mapstruct', 'org.mapstruct:mapstruct:1.6.0.Beta1')
library('apache-tika', 'org.apache.tika:tika-core:2.9.1')
}
}
}八、前端关键技术
tsx
// 流式响应组件
const StreamResponse: React.FC = () => {
const [content, setContent] = useState('');
useEffect(() => {
const eventSource = new EventSource('/api/ai/stream');
eventSource.onmessage = (event) => {
const data = JSON.parse(event.data);
setContent(prev => prev + data.chunk);
if (data.done) {
eventSource.close();
}
};
return () => eventSource.close();
}, []);
return (
<div className="markdown-body animate-fade-in">
<ReactMarkdown>{content}</ReactMarkdown>
</div>
);
};
// 数据可视化
const SkillRadarChart: React.FC<{ data: SkillAnalysis }> = ({ data }) => {
return (
<ResponsiveContainer width="100%" height={400}>
<RadarChart data={data.points}>
<PolarGrid />
<PolarAngleAxis dataKey="skill" />
<PolarRadiusAxis />
<Radar
name="匹配度"
dataKey="score"
stroke="#8884d8"
fill="#8884d8"
fillOpacity={0.6}
/>
</RadarChart>
</ResponsiveContainer>
);
};九、项目特色价值
- 技术前瞻性:Java 21虚拟线程 + Spring Boot 4.0模块化设计
- 工程完备性:从AI集成到部署监控的全链路覆盖
- 性能卓越:编译期代码生成 + 向量检索优化
- 生产就绪:分布式限流、异步处理、错误恢复
- 全栈能力:后端深度 + 现代前端交互体验
这个架构设计既保证了技术先进性,又兼顾了生产环境的稳定性要求,是传统后端工程师向AI应用开发转型的理想实践路径。