RunPod Serverless + vLLM:大语言模型部署与配置指南(实战版)
-
- 0)你最终会得到什么
- [1)部署流程:从 0 到 Endpoint(最短路径)](#1)部署流程:从 0 到 Endpoint(最短路径))
-
- [1.1 支持的模型怎么选?](#1.1 支持的模型怎么选?)
- [1.2 控制台操作要点(别踩坑)](#1.2 控制台操作要点(别踩坑))
- 2)硬件选择与显存管理:稳定跑起来的关键
-
- [2.1 vLLM 为啥更容易"显存吃紧"?](#2.1 vLLM 为啥更容易“显存吃紧”?)
- [2.2 先给你一个"能落地"的 VRAM 估算口径](#2.2 先给你一个“能落地”的 VRAM 估算口径)
- [3)环境变量配置:把 vLLM 参数"搬到 RunPod 控制台"](#3)环境变量配置:把 vLLM 参数“搬到 RunPod 控制台”)
-
- [3.1 核心变量(建议你先记这几个)](#3.1 核心变量(建议你先记这几个))
- [3.2 显存与上下文:两颗"定时炸弹"](#3.2 显存与上下文:两颗“定时炸弹”)
- [4)接口调用:RunPod 原生 vs OpenAI 兼容](#4)接口调用:RunPod 原生 vs OpenAI 兼容)
-
- [4.1 RunPod 原生请求(队列式)](#4.1 RunPod 原生请求(队列式))
- [4.2 OpenAI 兼容接口(迁移神器)](#4.2 OpenAI 兼容接口(迁移神器))
- [5)故障排除:80% 的问题都在这三类](#5)故障排除:80% 的问题都在这三类)
-
- [5.1 初始化失败 / 冷启动卡死](#5.1 初始化失败 / 冷启动卡死)
- [5.2 响应慢 / 吞吐上不去](#5.2 响应慢 / 吞吐上不去)
- [5.3 OOM(显存溢出)](#5.3 OOM(显存溢出))
- [6)最佳实践清单(建议直接照抄到项目 README)](#6)最佳实践清单(建议直接照抄到项目 README))
- 结语
目标:用 RunPod Serverless 的 vLLM Worker ,把 Hugging Face 上的主流开源模型快速"无服务器化",并通过环境变量 做显存/吞吐/兼容性调优,最终对外提供 RunPod 原生 API 与 OpenAI 兼容 API 两套调用方式。(docs.runpod.io)
0)你最终会得到什么
-
一个 Serverless Endpoint:按请求自动扩缩容、冷启动自动拉模型
-
两种调用方式:
- RunPod 标准
/run、/runsync(队列式)(docs.runpod.io) - OpenAI 兼容
/openai/v1/*(便于旧系统无缝迁移)(docs.runpod.io)
- RunPod 标准
-
一套"只改变量不重打镜像"的调参方法(环境变量映射 vLLM 配置)(runpod-b18f5ded.mintlify.app)
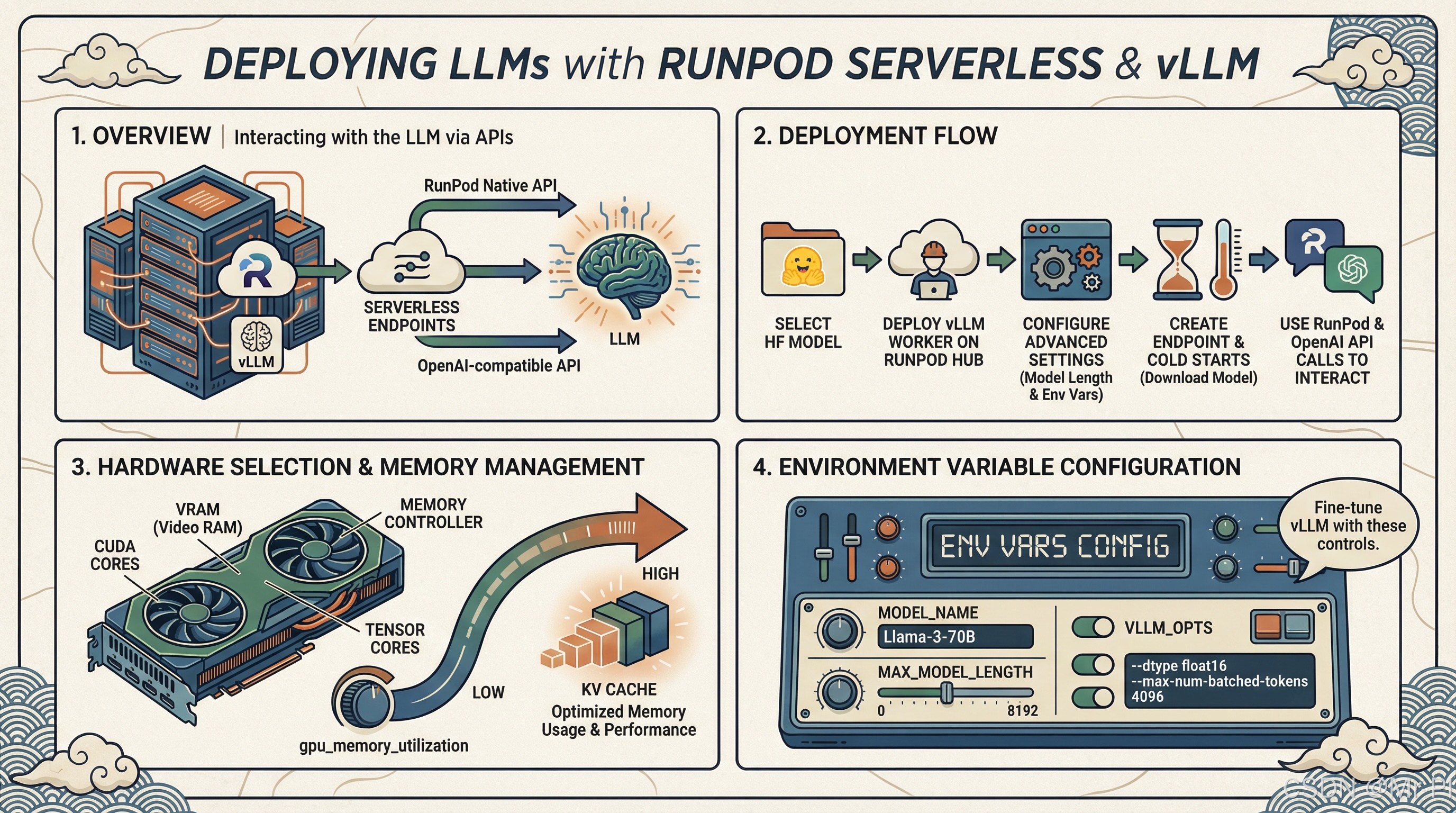
下面这张图就是整体链路:
选择 HF 模型
RunPod Hub 部署 vLLM Worker
Advanced 配置: Max Model Length / Env Vars
Endpoint 创建 & 首次冷启动下载模型
RunPod /runsync or /run 调用
OpenAI Compatible /openai/v1 调用
调优: gpu_memory_utilization / max_model_len / kv cache 等
1)部署流程:从 0 到 Endpoint(最短路径)
RunPod 官方的标准流程其实非常直给:在 Hub 找到 vLLM 仓库 → Deploy → 填模型 ID → Advanced 里设置 Max Model Length → Create Endpoint。(docs.runpod.io)
1.1 支持的模型怎么选?
vLLM 能跑的模型非常广(常见如 Llama / Mistral / Qwen / DeepSeek 等)。经验上建议你先按"用途"选:
- 聊天/指令模型 :优先用
*-Instruct - 成本敏感:优先 7B/8B 档(更容易在 16--24GB VRAM 上跑稳)
- 强推理/长链路:优先更大模型,但要把 KV Cache 和上下文一起算清楚(后面讲)
1.2 控制台操作要点(别踩坑)
- Model 字段 :填 Hugging Face 模型 ID(例如
openchat/openchat-3.5-0106)(docs.runpod.io) - Max Model Length :常见先设
8192,但这不是"越大越好",它直接影响 KV Cache 占用,显存不够就会 OOM(第 2 节详谈)。(docs.runpod.io)
2)硬件选择与显存管理:稳定跑起来的关键
2.1 vLLM 为啥更容易"显存吃紧"?
因为 vLLM 会根据 gpu_memory_utilization 预分配 GPU Cache(KV Cache) ,你把这个值开得越高,吞吐潜力越大,但越接近显存边界就越容易初始化失败/波动。(vLLM)
2.2 先给你一个"能落地"的 VRAM 估算口径
权重占用(粗估):
- FP16 / BF16:约 2 字节/参数
- INT8:约 1 字节/参数
- INT4(AWQ/GPTQ):约 0.5 字节/参数
然后还要为 KV Cache 留空间;vLLM 的官方调优建议是通过 gpu_memory_utilization 来控制预分配比例。(vLLM)
实战建议:
- 第一次跑模型 :
GPU_MEMORY_UTILIZATION=0.85~0.90起步- 初始化失败/冷启动爆显存:先降到
0.85- 显存富余且追吞吐:再试
0.92~0.95(别一上来 0.99)(vLLM)
3)环境变量配置:把 vLLM 参数"搬到 RunPod 控制台"
RunPod 的 vLLM Worker 支持用 环境变量 配置行为与性能,不用你改镜像。(runpod-b18f5ded.mintlify.app)
3.1 核心变量(建议你先记这几个)
MODEL_NAME:HF 模型 ID / 路径DTYPE:auto/float16/bfloat16等HF_TOKEN:拉取受限模型必需(比如某些 Llama/Gemma)QUANTIZATION:awq/gptq/bitsandbytes等(看你的模型权重格式)(runpod-b18f5ded.mintlify.app)
3.2 显存与上下文:两颗"定时炸弹"
GPU_MEMORY_UTILIZATION:控制预分配缓存比例,是吞吐与稳定性的平衡点。(vLLM)MAX_MODEL_LEN:上下文越长,KV Cache 越大;OOM 时优先把它降下来。(vLLM)
如果你需要更"硬核"的控制:vLLM 也支持用
--kv-cache-memory-bytes类参数精细限制 KV Cache(一旦手动指定,会覆盖gpu_memory_utilization的自动推断逻辑)。(vLLM)
4)接口调用:RunPod 原生 vs OpenAI 兼容
4.1 RunPod 原生请求(队列式)
vLLM Worker 属于 RunPod Serverless 的队列端点,调用方式就是标准的 /run(异步)和 /runsync(同步)。(docs.runpod.io)
你要理解的差异只有一个:输入结构 更偏 LLM(prompt/messages/sampling 参数)。(docs.runpod.io)
4.2 OpenAI 兼容接口(迁移神器)
RunPod 提供 OpenAI API 兼容层,方便你把现有 OpenAI SDK/生态工具"基本不改代码"迁过来。(docs.runpod.io)
关键点:如果你希望流式输出和 OpenAI 客户端更一致,RunPod 文档提供了 OpenAI 兼容使用指引(你原文提到的 RAW 输出一致性诉求也属于这一块配置范畴)。(docs.runpod.io)
5)故障排除:80% 的问题都在这三类
5.1 初始化失败 / 冷启动卡死
优先排查顺序(从高概率到低概率):
- 模型参数量 vs GPU VRAM 不匹配(权重 + KV Cache 一起超了)
MAX_MODEL_LEN设太大(先降到 4096/8192 观察)(vLLM)GPU_MEMORY_UTILIZATION太激进(降到 0.85)(vLLM)
5.2 响应慢 / 吞吐上不去
- 提升
GPU_MEMORY_UTILIZATION给 KV Cache 更多空间(前提:显存允许)(vLLM) - 适当限制并发/批处理相关参数(vLLM 官方建议通过降低并发相关配置减少 KV Cache 压力)(vLLM)
5.3 OOM(显存溢出)
- 先降
MAX_MODEL_LEN(最有效)(vLLM) - 再降
GPU_MEMORY_UTILIZATION(让预分配别把边界吃满)(vLLM) - 仍不行:考虑量化权重(INT8/INT4)或换更大 VRAM 的 GPU
6)最佳实践清单(建议直接照抄到项目 README)
- 重试 + 指数退避:Serverless 冷启动/网络波动都可能出现,客户端必须有韧性。
- 优先上 Streaming :长输出体验差异巨大。(docs.runpod.io)
- 超时要跟模型规模挂钩:别用一套 timeout 跑所有模型。
- 多 GPU 兜底:Serverless 选多种 GPU 类型,降低"某机房缺卡导致任务失败"的概率(工程上非常值)。
结语
RunPod Serverless + vLLM 的组合,最大的价值在于:部署足够快、接口足够兼容、参数足够可控 。只要你把 显存(KV Cache)与上下文长度 这条线算清楚,再用 GPU_MEMORY_UTILIZATION + MAX_MODEL_LEN 做稳定性"拨盘",基本就能把推理端点跑到可交付状态。(docs.runpod.io)