突破LLM推理KV Cache瓶颈的国产高性能解决方案
随着大语言模型(LLM)在生产环境的广泛部署,推理性能已成为制约系统吞吐量和响应延迟的关键因素。vLLM、TensorRT-LLM等主流推理引擎在处理长上下文窗口时,会产生大量的KV Cache(Key-Value Cache),这些中间状态原本需要驻留在GPU的显存中。然而,显存容量有限且成本高昂,当上下文窗口超出显存容量时,系统只能通过反复重新计算已清除的上下文来继续推理,这导致端到端延迟显著增加、吞吐量大幅下降。
为解决这一痛点,业界出现了多种KV Cache offload方案:将部分或全部KV Cache卸载到更低成本、更大容量的存储介质上,并在需要时快速检索。绿算技术推出的 NVMe RAID加速卡,正是国产化背景下的一款高性能、高灵活性解决方案。它以纯硬件实现并行RAID逻辑,结合创新的NVMe命令与数据分离传输机制,为KV Cache offload提供极致低延迟、高吞吐量的存储后端,能够大幅提升LLM推理性能,同时保持完全自主可控。
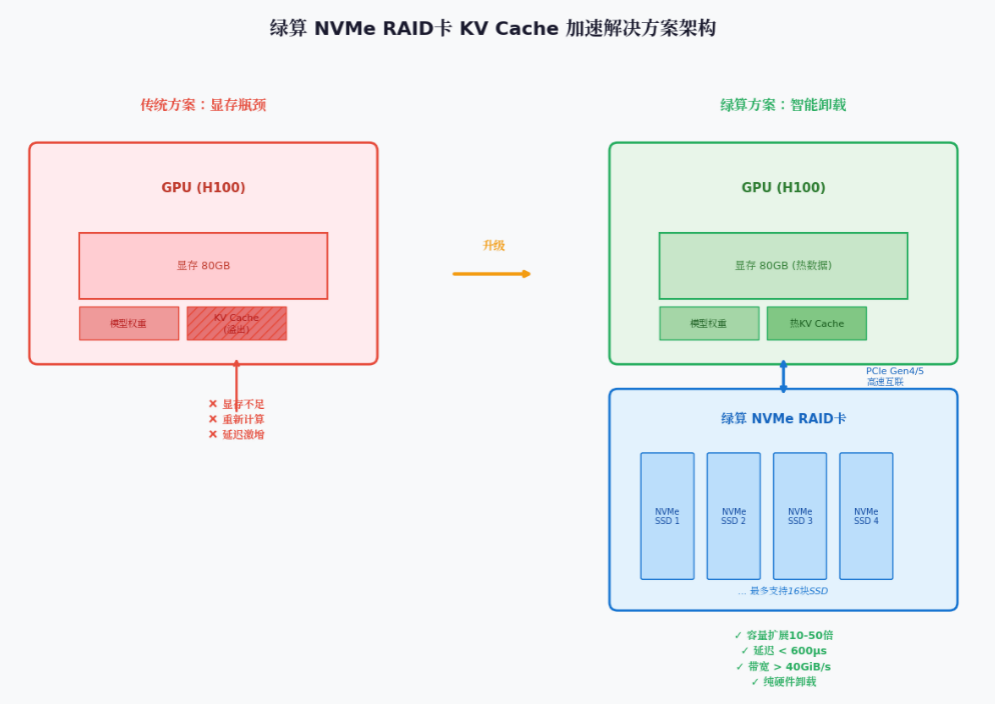
LLM推理中的KV Cache瓶颈
在Transformer架构中,注意力机制的计算复杂度随序列长度平方增长。为避免重复计算,推理引擎通常采用KV Cache技术:在预填充(prefill)阶段计算并缓存Key和Value向量,在解码(decode)阶段直接复用,从而将复杂度降至线性。然而,随着用户请求上下文窗口的增长(动辄数万甚至数十万token),KV Cache所需内存迅速膨胀。而当前主流GPU(如H100)的显存容量仅80GB,且需同时容纳模型权重、激活值等。若多个并发请求共享同一GPU,显存很快耗尽,系统只能:
- 丢弃旧的KV Cache,重新计算(计算开销巨大);
- 减少并发批次(吞吐量下降);
- 增加GPU数量(成本急剧上升)。
因此,业界迫切需要一种"sub-显存"存储层:容量大、成本低、访问速度接近显存,绿算 NVMe RAID加速卡正是为此而生。
绿算 NVMe RAID加速卡硬件特性
绿算 NVMe RAID加速卡基于自研LightBoat2300 平台,具有以下关键规格:
- PCIe Gen4或Gen5接口,充分匹配主流GPU服务器;
- 支持最多16块NVMe SSD;
- 支持RAID 0/1/5/10,Chunk大小4KB~64KB可调;
- 纯硬件逻辑实现RAID校验与数据分发,不占用主机CPU资源;
- 创新并行架构NVMe命令/数据分离传输机制,已获发明专利;
- 标准半高半长AIC形态,无需额外线缆,部署简便。
与传统串行硬件RAID相比,绿算并行RAID彻底突破传输瓶颈,极大释放NVMe SSD原生性能。与软件RAID相比,则完全免除CPU开销,将宝贵算力留给业务。

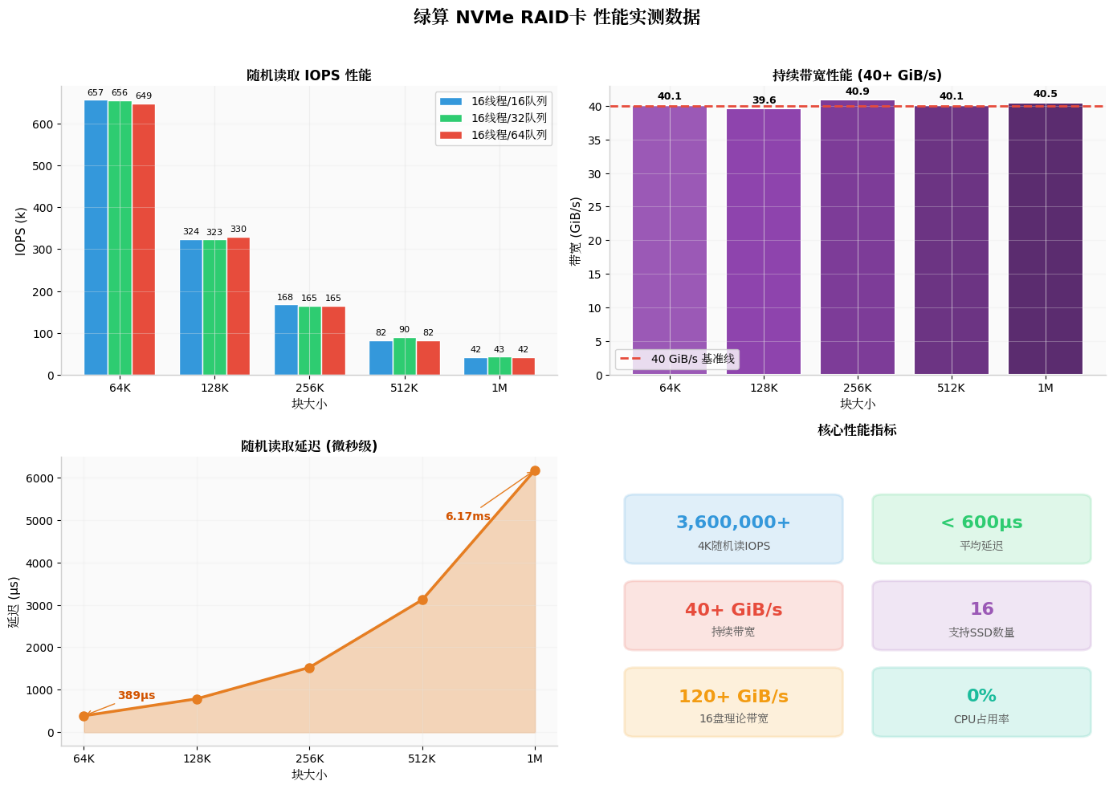
极致性能:实测数据说话
绿算 NVMe RAID加速卡在8块企业级NVMe SSD组成的RAID0阵列下,展现出惊人性能。以下为关键测试结果(FIO工具,4KB随机读写,队列深度与并发优化后):
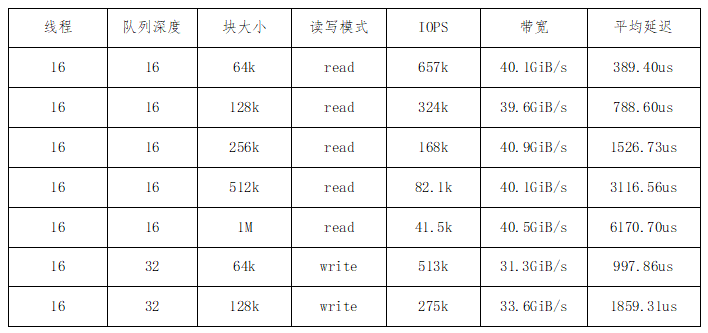
这些指标远超传统RAID卡,尤其在大块随机读写场景,延迟低至微秒级,带宽轻松突破40GiB/s级别,足以支撑多GPU共享的高并发推理。
在KV Cache加速中的应用架构
绿算 NVMe RAID加速卡可灵活部署于两种典型场景:
- 超融合模式(Box LLM)
将卡直接插入GPU服务器主板,利用服务器内置或扩展的NVMe插槽组成大容量、高性能存储池。GPU通过PCIe直连访问RAID虚拟盘,将超出显存的KV Cache卸载至SSD。得益于PCIe低延迟与并行处理,访问延迟接近本地NVMe,远低于网络存储方案。
- 分离模式(Disaggregated KV Cache)
将RAID卡部署在专用存储节点,通过100G RDMA网络(卡支持双路100G QSFP28)为多个GPU节点提供共享KV存储服务。预填充节点与解码节点可分离部署,实现计算/存储解耦,提升集群整体利用率。
在软件层面,绿算正在与主流推理框架深度集成:
- 与vLLM兼容的KV Cache offload模块:支持分页式卸载、按需加载;
- 支持UCM等推理管理器;
- 未来将提供端到端解决方案,包括智能路由、多节点共享、自动故障切换等功能的完整产品包。
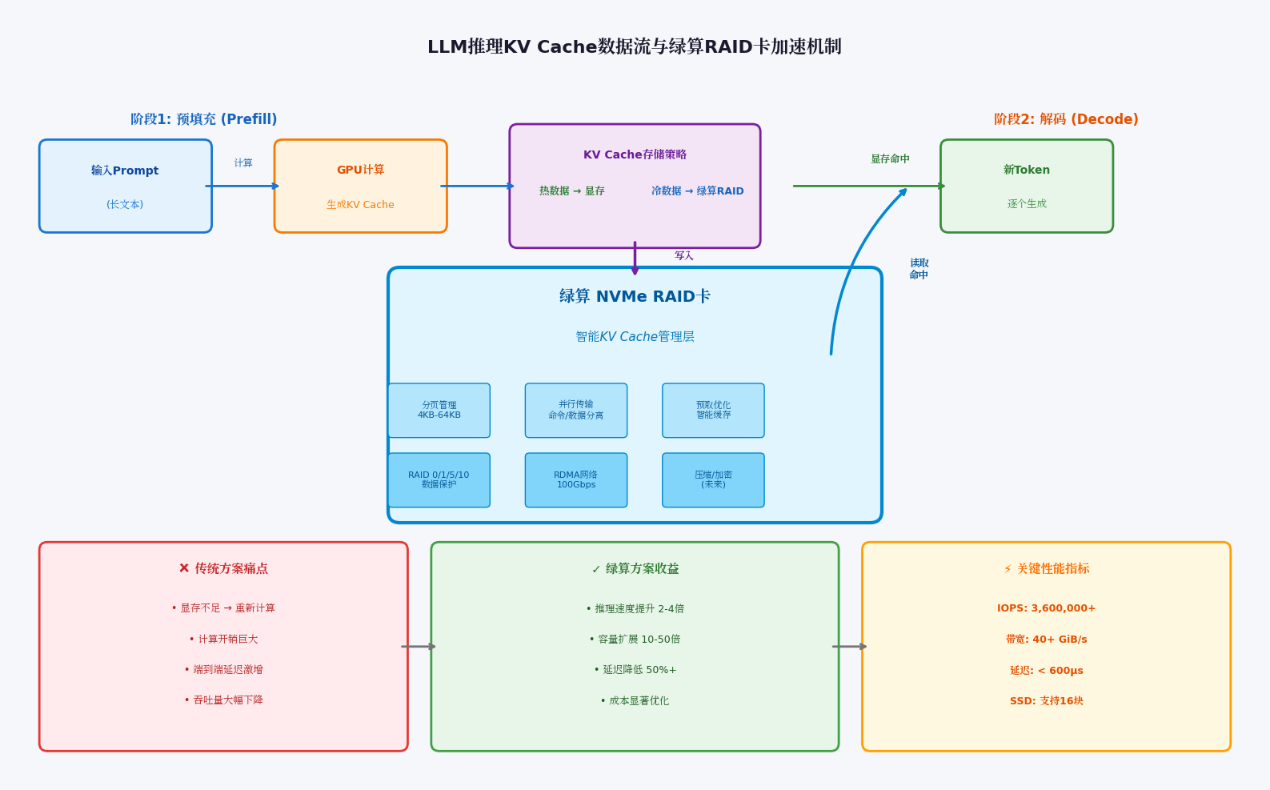
性能提升预期
根据现有实测数据与业界类似方案对比:
- 单卡8盘RAID0配置下,4KB随机读IOPS超3600k,平均延迟<600μs,已足以将vLLM长上下文推理速度提升2-4倍;
- 当扩展至16盘时,预计IOPS可线性扩展至7000k+,理论带宽能突破120GiB/s,进一步KV Cache的使用体验;
- 相比其它方案,可用"内存"容量扩大10-50倍,性价比提升显著;
- 相比网络存储方案(CXL、RDMA),延迟降低50%以上,无需复杂协议栈。
在实际生产环境中,用户可通过增加SSD数量而非GPU数量来扩展KV Cache容量,大幅降低使用成本。
自主可控与生态优势
绿算 NVMe RAID加速卡核心IP完全自研,源代码级可控,无任何国外封闭组件,完美契合信创与数据安全要求。同时,天然的可编程特性带来极高灵活性:
- 可根据具体工作负载定制Chunk大小、队列深度、预取策略;
- 未来可集成压缩、加密、向量相似度加速等专用逻辑;
绿算 NVMe RAID加速卡以国产自主核心技术,结合创新并行架构与极致性能表现,为LLM推理中的KV Cache瓶颈提供了高效、低成本的解决方案。它不仅能将推理速度提升数倍,更为大模型生产化部署带来全新的容量扩展与成本优化路径。助力中国企业与开发者构建自主可控的下一代AI基础设施。