模型架构
模型主要包含三个部分:MoonViT-3D、MLP投影器、Kimi-K2。没错,刚发现Kimi-K2其实是单模态的,这里面使用的是Kimi-K2的模型架构而非其训练参数。
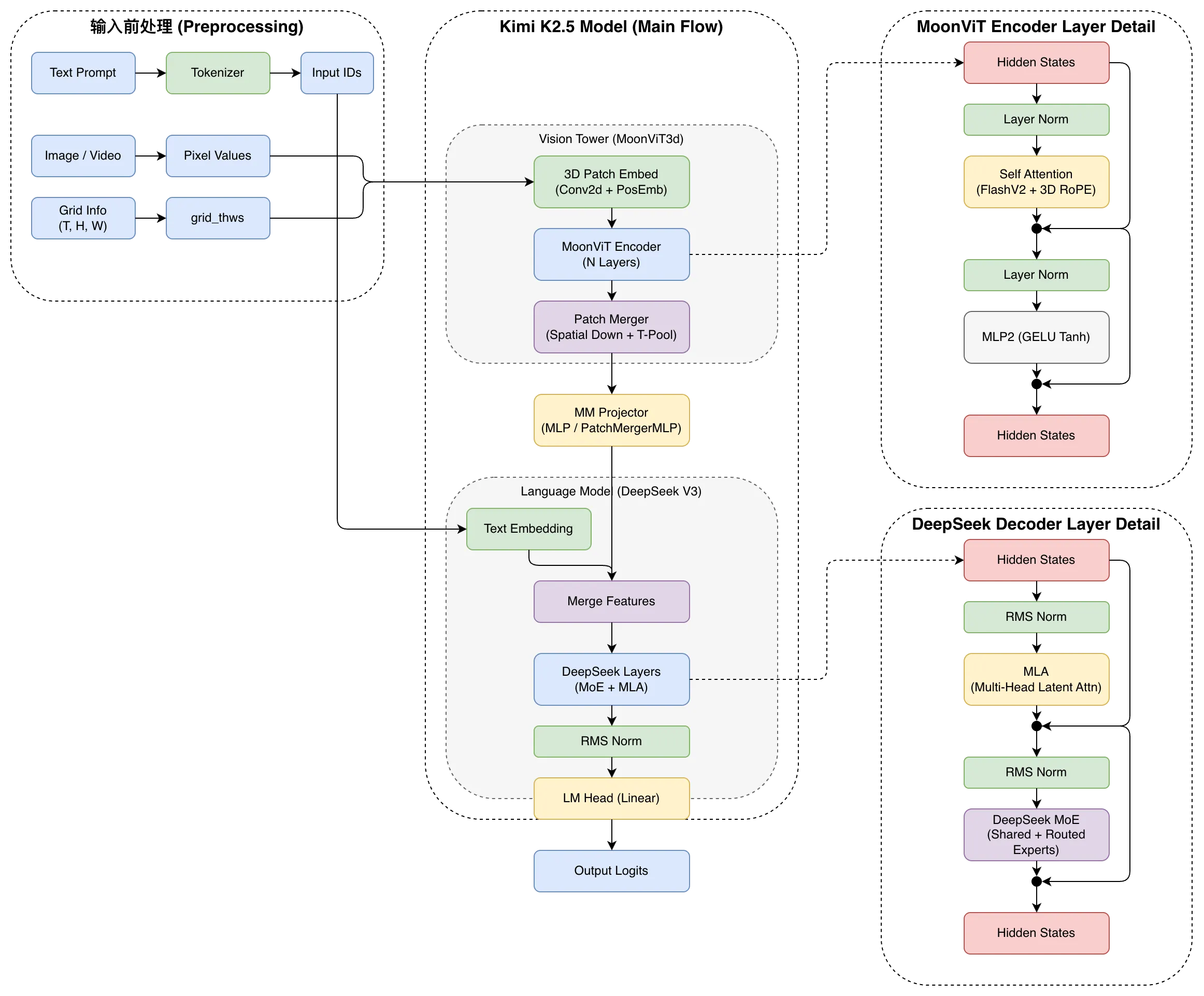
Kimi-K2
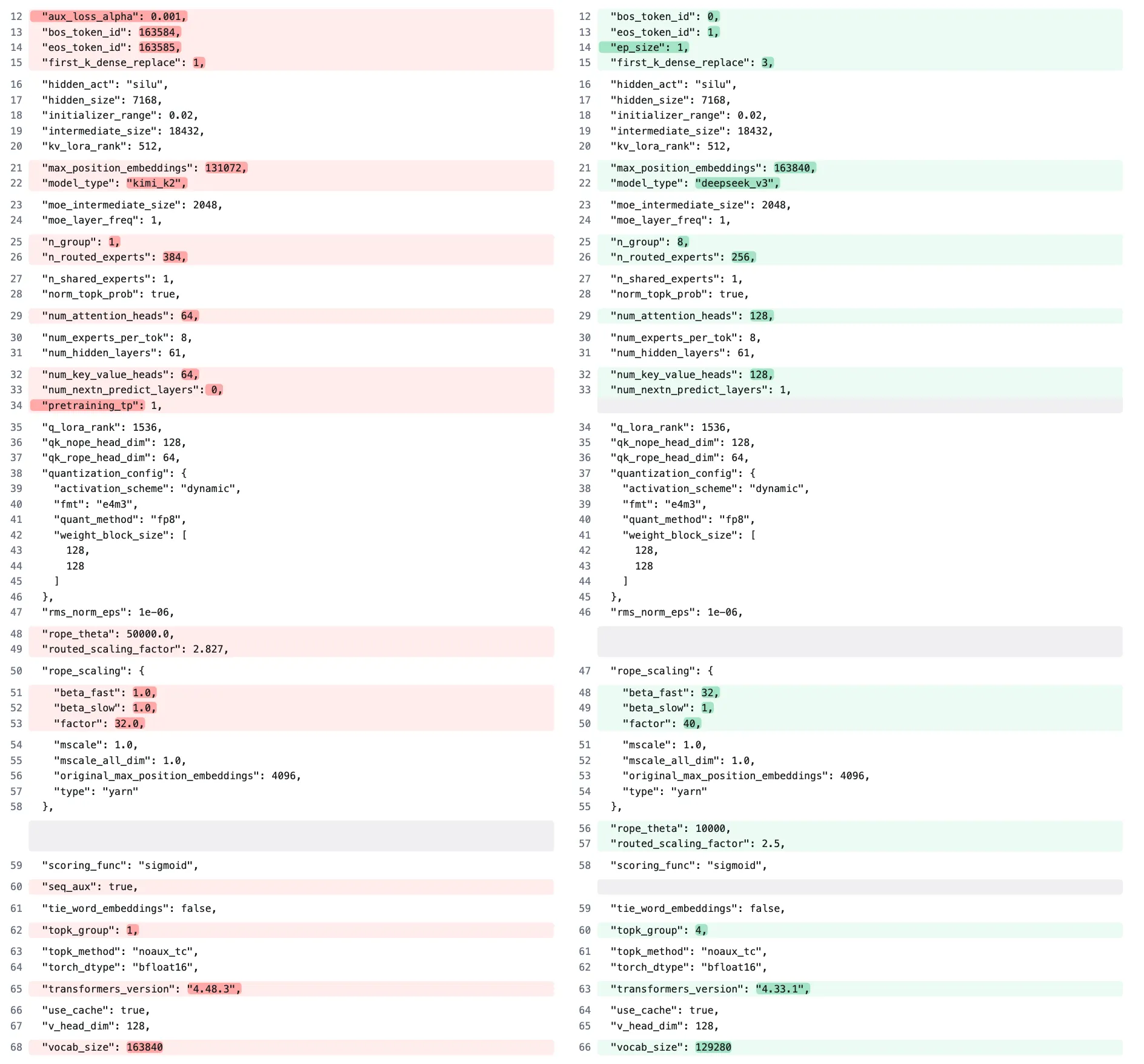
又仔细看了一下Kimi-K2的huggingface仓库,发现其模型架构继承自DeepSeek-V3,只是在模型配置层面有所改动:
左侧为Kimi-K2,右侧为DeepSeek-V3的配置参数。
MoonViT-3D
在Kimi-VL中,使用了MoonViT,其允许原生分辨率处理,无需复杂的切割拼接操作。更详细的介绍可见GitHub仓库:"datawhalechina/self-llm/models/Kimi-VL/02-Kimi-VL-技术报告解读.md"
在Kimi-K2.5中,为了最大程度地使图像理解能力迁移到视频理解上,使用了MoonViT的升级版------MoonViT-3D。使用了统一的架构、完全共享的参数以及一致的嵌入空间,将时间-空间维度一同处理。
- Pack Stage:在
MoonViT3dEncoder中,最多4个连续帧被视为一个时空体积,在这个阶段,4个时间帧被当作一个整体进行特征提取,但并没有减少时间维度的大小。 - Packed Attention:经过上述操作后,每个时空Pack由4帧视频变成了一段 flattened tokens。在这个阶段使用了
cu_seqlens进行mask,保证每次注意力的计算只在每个Pack的范围内,Pack之间不做交互,且注意力的是双向的(相当于transformer-encoder) - Pool Stage:在
tpool_patch_merger函数中,通过.mean(dim=0)操作沿时间维度进行平均池化,将4个时间帧压缩为1个时间步。
最后,一段视频就被编码成一段 token 的 embedding 了,在后面的阶段根据图片插入文字的位置插入到 text tokens 里就完成了多模态融合的功能。