
文章目录
一、并查集
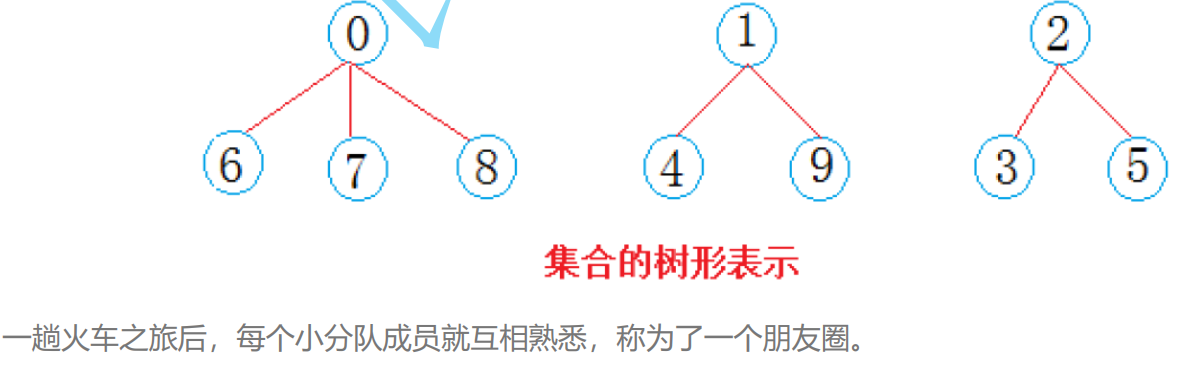
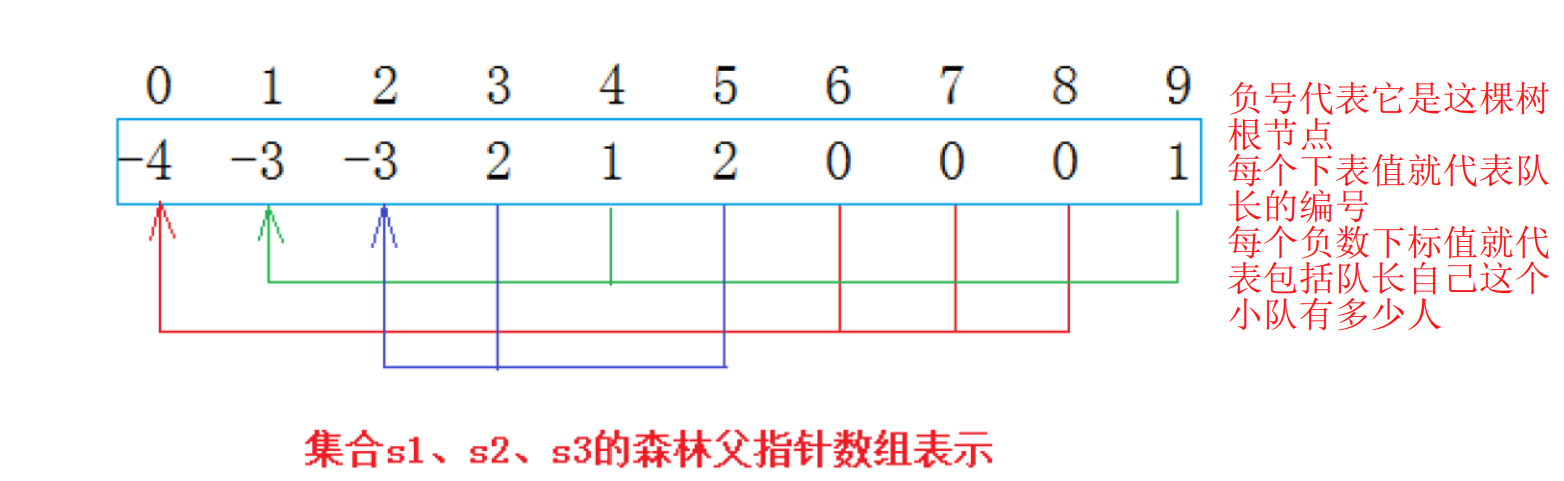
java
package unionFindSet;
import java.util.Arrays;
import java.util.Map;
/**
* @author pluchon
* @create 2026-02-11-10:24
* 作者代码水平一般,难免难看,请见谅
*/
//模拟实现并查集
public class UnionFindSet {
//底层默认是数组
private int [] array;
//统计有效集合个数
private int setCount;
public UnionFindSet(int size) {
this.array = new int[size];
//全部初始化为-1
Arrays.fill(array,-1);
//每个人都是独立的集合
this.setCount = size;
}
//查找指定下标根节点
public int findRoot(int index){
if(index < 0 || index >= array.length){
throw new ArrayIndexOutOfBoundsException("下标异常");
}
//路径压缩,顺便把沿途的下标里的值直接指向老大
if(array[index] < 0){
return index;
}
//递归写法
return array[index] = findRoot(array[index]);
}
//合并两个集合,但是前提是两个下标必须属于不同集合
public void toUnion(int index1,int index2){
int root1 = findRoot(index1);
int root2 = findRoot(index2);
//判断
if(root1 == root2){
return;
}
//让小集合合并到大集合
if(Math.abs(array[root1]) < Math.abs(array[root2])){
//交换值
int tmp = root1;
root1 = root2;
root2 = tmp;
}
//正常合并
array[root1] += array[root2];
//被合并的下标指向要改变
array[root2] = root1;
//有效集合个数减一
this.setCount--;
}
//判断是否属于同一个集合
public boolean isSameSet(int index1,int index2){
return findRoot(index1) == findRoot(index2);
}
//打印并查集
public void printSet(){
System.out.println(Arrays.toString(array));
}
//获取集合数量
public int getSetCount(){
return this.setCount;
}
//--------测试部分---------
public static void main(String[] args) {
System.out.println("====== 并查集:朋友圈关系压测 ======");
// 假设有 10 个人,编号 0-9
UnionFindSet ufs = new UnionFindSet(10);
// 场景 1:建立好友关系
System.out.println("建立关系:(0,1), (1,2), (3,4), (5,6), (0,7)");
ufs.toUnion(0, 1);
ufs.toUnion(1, 2);
ufs.toUnion(3, 4);
ufs.toUnion(5, 6);
ufs.toUnion(0, 7);
// 场景 2:连通性检查
System.out.println("\n--- 连通性检查 ---");
System.out.println("0 和 2 是好朋友吗? " + ufs.isSameSet(0, 2)); // 应为 true
System.out.println("0 和 4 是好朋友吗? " + ufs.isSameSet(0, 4)); // 应为 false
System.out.println("7 和 2 是好朋友吗? " + ufs.isSameSet(7, 2)); // 应为 true(间接好友)
// 场景 3:统计朋友圈数量
System.out.println("\n--- 朋友圈统计 ---");
System.out.println("当前总朋友圈个数: " + ufs.getSetCount()); // 10 - 5 = 5 个
// 场景 4:打印底层数组,观察根节点的值
// 根节点的值应该是负数,绝对值代表该圈子的人数
System.out.print("底层数组状态: ");
ufs.printSet();
// 场景 5:极端合并测试
System.out.println("\n--- 全员大团圆测试 ---");
for (int i = 0; i < 9; i++) {
ufs.toUnion(i, i + 1);
}
System.out.println("全员合并后朋友圈个数: " + ufs.getSetCount()); // 应为 1
System.out.println("全员合并后根节点人数 (绝对值): " + Math.abs(ufs.array[ufs.findRoot(0)]));
}
}二、LRU缓存
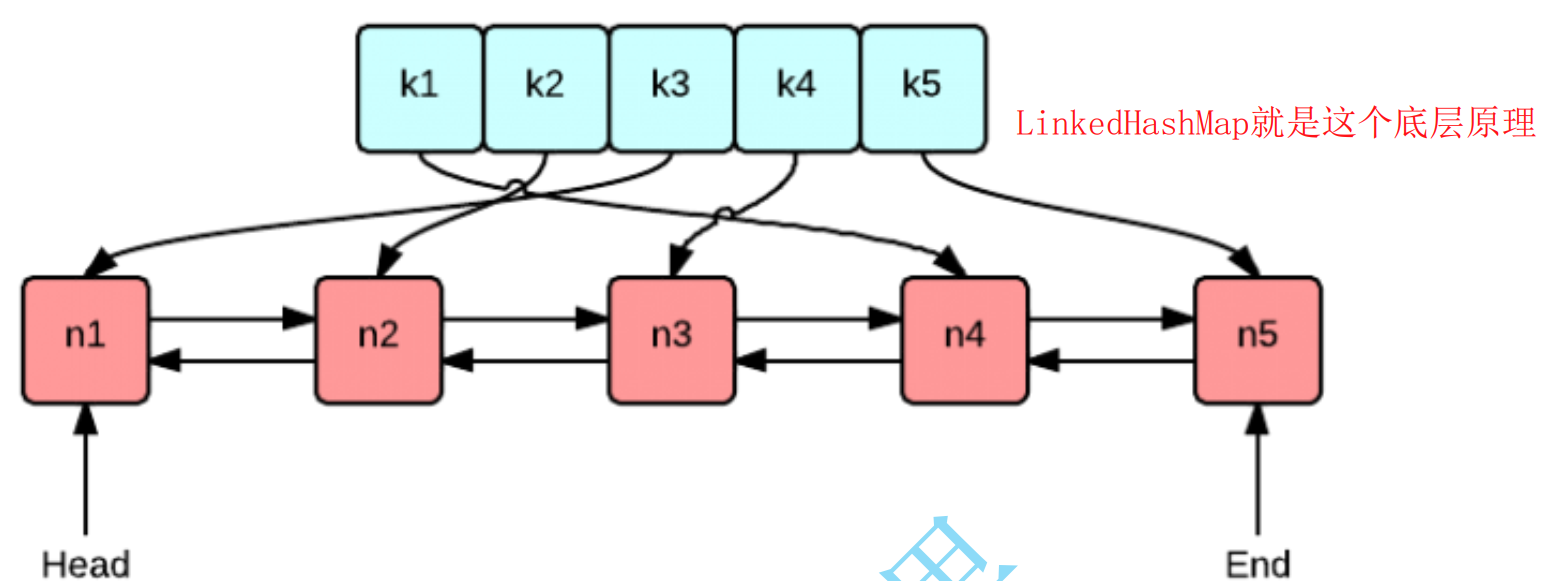
1. 借助JDK自带类实现
java
package LRUCache;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @author pluchon
* @create 2026-02-11-13:54
* 作者代码水平一般,难免难看,请见谅
*/
//模拟实现LRU缓存,接住JDK双向链表哈希表类
public class MyLRUCacheSimple<K, V> extends LinkedHashMap<K, V> {
//默认初始容量
private final int capacity;
public MyLRUCacheSimple(int capacity) {
//调用父类,并且是基于访问顺序accessOrder = true来存储
//初始容量设为capacity,加载因子0.75,开启访问顺序维护
super(capacity, 0.75f, true);
this.capacity = capacity;
}
//此时的get方法一定会,返回最近访问的数据
//如果找不到,根据业务需求返回null或指定的默认值
public V getVal(K key) {
return super.get(key);
}
//放置内容
public void putVal(K key, V value) {
super.put(key, value);
}
//必须重写这个方法,默认是false
//此时才会判断如果超过容量就自动删除头节点(也就是最久未访问的节点)
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
//--------简单测试用例--------
public static void main(String[] args) {
System.out.println("====== LRU 缓存测试 (泛型版) ======");
// 1. 创建一个容量为 3 的缓存
MyLRUCacheSimple<String, Integer> lru = new MyLRUCacheSimple<>(3);
// 2. 存入三个数据:A, B, C
lru.putVal("A", 1);
lru.putVal("B", 2);
lru.putVal("C", 3);
System.out.println("存入 A, B, C 后的缓存: " + lru);
// 3. 访问一次 A,让 A 变成"最近最常访问"的数据
lru.getVal("A");
System.out.println("访问 A 后 (A 移到末尾): " + lru);
// 4. 存入新数据 D,此时容量超出,最久未访问的 B 应该被删除
lru.putVal("D", 4);
System.out.println("存入 D 后 (B 应该被淘汰): " + lru);
// 验证 B 是否真的没了
if (lru.getVal("B") == null) {
System.out.println("验证成功: B 已经被自动淘汰");
}
// 5. 存入 E,再次触发淘汰,此时最久未访问的 C 应该被删除
lru.putVal("E", 5);
System.out.println("存入 E 后 (C 应该被淘汰): " + lru);
System.out.println("\n最终有效个数: " + lru.size());
}
}2. 手动实现 HashMap&双向链表
java
package LRUCache;
import java.util.HashMap;
import java.util.Map;
/**
* @author pluchon
* @create 2026-02-11-20:23
* 作者代码水平一般,难免难看,请见谅
*/
//模拟实现LRU缓存,自己实现
public class MyLRUCacheNormal<K,V> {
//双向链表的每一个节点
class DeLinkedNode{
K key;
V val;
DeLinkedNode preV;
DeLinkedNode next;
//提供无参构造方法,方便创建
public DeLinkedNode() {
}
//提供带参构造方法,方便创建新的节点
public DeLinkedNode(K key, V val) {
this.key = key;
this.val = val;
}
}
//LRU核心逻辑
private Map<K,DeLinkedNode> cache;
//头节点和尾巴节点,本质上不存数据,是傀儡节点
private DeLinkedNode head;
private DeLinkedNode tail;
//有效节点个数
private int usedNode;
//总共容量
private int capacity;
public MyLRUCacheNormal(int capacity) {
//初始化
this.usedNode = 0;
cache = new HashMap<>();
head = new DeLinkedNode();
tail = new DeLinkedNode();
this.capacity = capacity;
//修改指针
head.next = tail;
tail.preV = head;
}
//放入元素
public void put(K key, V value){
//看看这个元素是否已经先被放入
DeLinkedNode node = cache.get(key);
//如果被放入
if(node != null){
//定位位置,更新value值,并移动至尾部,作为最新的节点
node.val = value;
removeToTail(node);
}else{
//如果没有放入,新创建节点,放入表。插入尾部,检查是否超过容量,移除头节点
DeLinkedNode newNode = new DeLinkedNode(key,value);
cache.put(key,newNode);
moveToTail(newNode);
usedNode++;
if(usedNode > capacity){
//移除头部节点
DeLinkedNode removeHeadNode = removeToHead();
cache.remove(removeHeadNode.key);
usedNode--;
}
}
}
//获取元素
public V get(K key){
DeLinkedNode node = cache.get(key);
//如果不存在,返回-1
if(node == null){
return null;
}
//这个元素存在,且被我我们访问,因此移动至尾部
removeToTail(node);
return node.val;
}
//添加至尾巴
private void moveToTail(DeLinkedNode node){
tail.preV.next = node;
node.next = tail;
node.preV = tail.preV;
tail.preV = node;
}
//删除头部
private DeLinkedNode removeToHead(){
DeLinkedNode headNode = head.next;
removeNode(headNode);
return headNode;
}
//移动节点到尾部
private void removeToTail(DeLinkedNode node){
//删除当前节点
removeNode(node);
//移动到尾部
moveToTail(node);
}
//删除当前节点
private void removeNode(DeLinkedNode node){
node.preV.next = node.next;
node.next.preV = node.preV;
}
//--------测试--------
public static void main(String[] args) {
System.out.println("====== 手写版 LRU 缓存测试 ======");
MyLRUCacheNormal<String, Integer> lru = new MyLRUCacheNormal<>(3);
lru.put("张三", 100);
lru.put("李四", 200);
lru.put("王五", 300);
System.out.println("初始存入:张三, 李四, 王五");
// 访问张三,张三变为"最新"
lru.get("张三");
System.out.println("访问 '张三',使其置顶");
// 存入赵六,此时容量满,最久未访问的"李四"应该被剔除
lru.put("赵六", 400);
System.out.println("存入 '赵六',触发淘汰");
System.out.println("检查李四是否存在: " + lru.get("李四")); // 应为 null
System.out.println("检查张三是否存在: " + lru.get("张三")); // 应为 100
System.out.println("检查赵六是否存在: " + lru.get("赵六")); // 应为 400
lru.put("孙七", 500);
System.out.println("存入 '孙七',王五应该被淘汰");
System.out.println("检查王五是否存在: " + lru.get("王五")); // 应为 null
}
}感谢你的阅读