MPA: Multimodal Prototype Augmentation for Few-Shot Learning
Authors: Liwen Wu, Wei Wang, Lei Zhao, Zhan Gao, Qika Lin, Shaowen Yao, Zuozhu Liu, Bin Pu
Deep-Dive Summary:
MPA: 用于小样本学习的多模态原型增强 (Multimodal Prototype Augmentation for Few-Shot Learning)
摘要 (Abstract)
小样本学习 (Few-Shot Learning, FSL) 旨在通过极少量的标注样本识别新类别。然而,现有方法大多仅关注视觉模态,且直接从原始支撑集图像计算原型,缺乏全面且丰富的多模态信息。为此,本文提出了一种新型的多模态原型增强框架 MPA ,其核心组件包括:基于大语言模型的多变体语义增强 (LMSE)、层次化多视图增强 (HMA) 以及自适应不确定类吸收器 (AUCA)。LMSE 利用大模型生成多样的类别描述以丰富语义线索;HMA 通过自然变换和几何视图增强特征多样性;AUCA 则通过插值和高斯采样引入不确定类,有效吸收不确定样本。实验表明,MPA 在四个单域和六个跨域基准测试中均表现优异,在 5-way 1-shot 设置下,其性能分别领先次优方法 12.29 % 12.29\% 12.29% 和 24.56 % 24.56\% 24.56%。
1. 引言 (Introduction)
由于小样本场景下标注数据有限,传统的基于原型的度量方法往往仅依赖单模态、单视图特征,导致泛化能力不足。
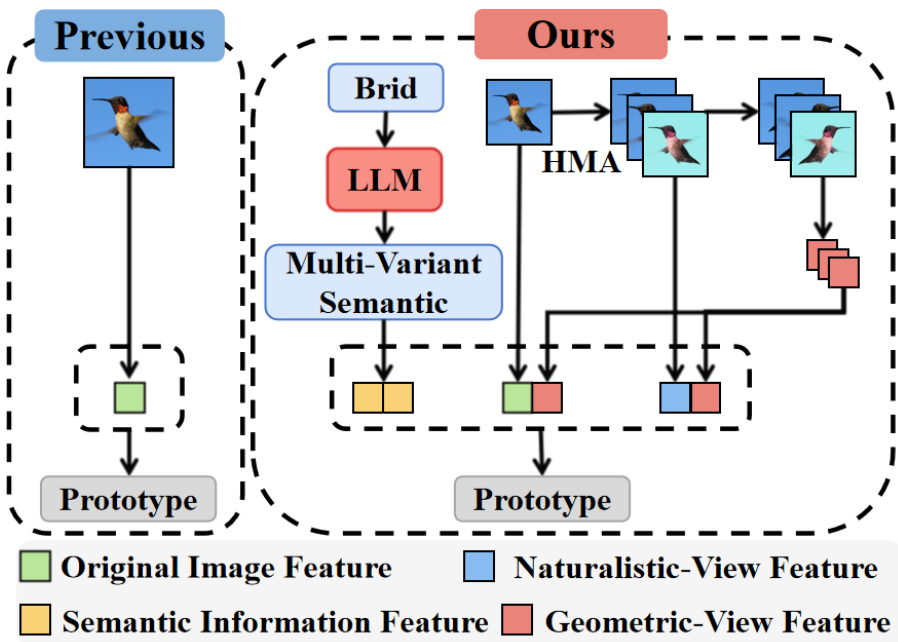
图 1:与现有仅关注原始图像特征的方法不同,MPA 整合了多模态特征原型(即基于 LLM 的多变体语义特征和层次化多视图特征),显著提升了模型在多样化任务中的泛化性能和鲁棒性。
如图 1 所示,单模态方法难以区分视觉上高度相似的类别(如不同种类的鸟)。通过引入语义描述(如"体型小、喙部尖锐且弯曲")可以提供关键的补充信息。此外,通过多视图变换(视角、光照、距离变化)可以捕捉样本更全面的表示。
2. 研究方法 (Methodology)
2.1 概述 (Overview)
MPA 框架通过整合语义增强、视图增强和不确定类处理来强化原型表示。
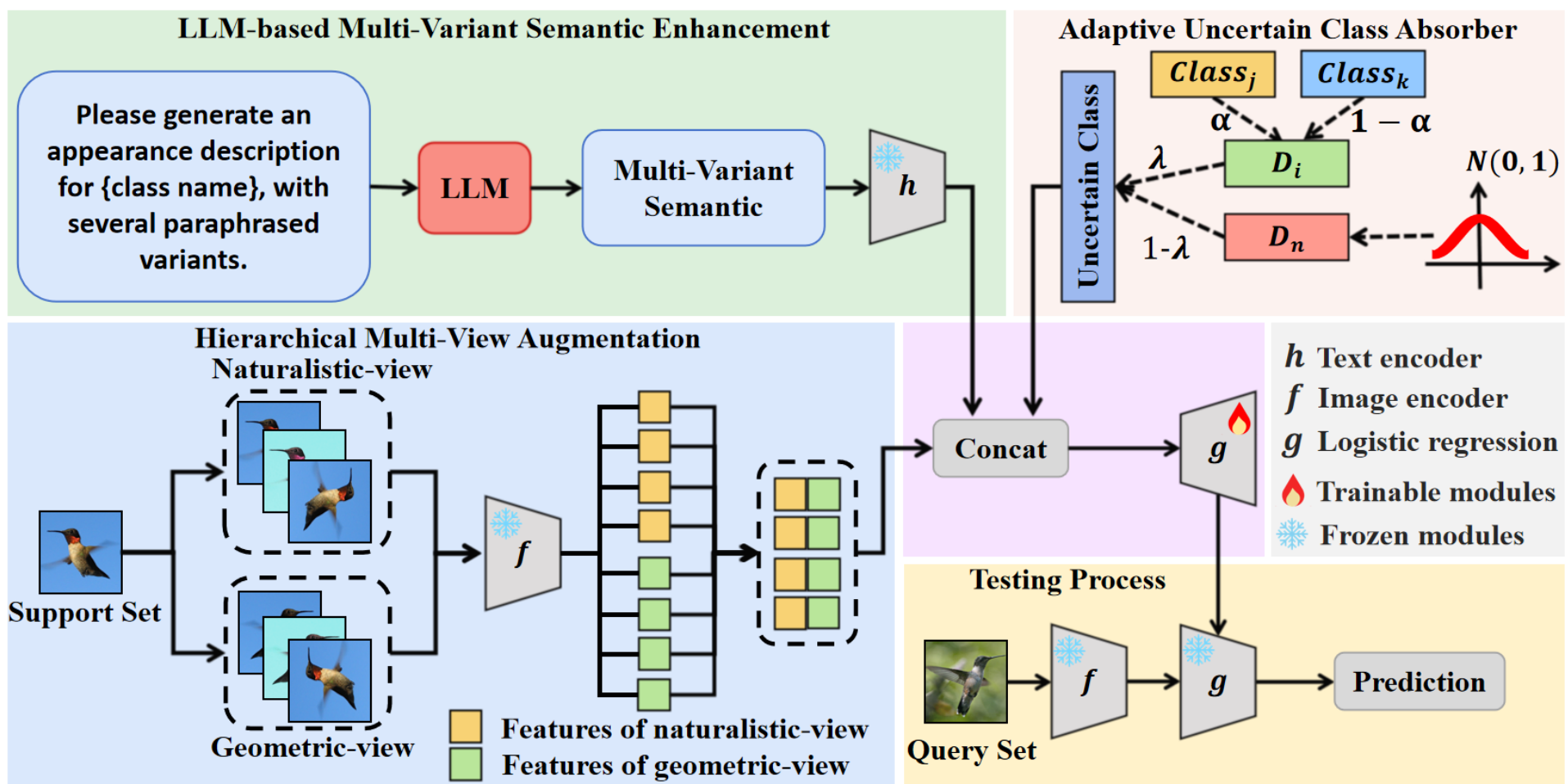
图 2:MPA 概述。框架包含三个组件:基于 LLM 的多变体语义增强 (LMSE)、层次化多视图增强 (HMA) 和自适应不确定类吸收器 (AUCA)。
2.2 基于 LLM 的多变体语义增强 (LMSE)
LMSE 利用大语言模型(如 GPT-4.0)为每个类别生成多样的外观描述。首先,使用 CLIP 图像编码器提取图像特征:
F i = f ( { I n } n = 1 N ) = { f ( I 1 ) , f ( I 2 ) , ... , f ( I N ) } , ( 1 ) F_{\mathrm{i}} = f\left(\{I_{n}\}{n = 1}^{N}\right) = \left\{f(I{1}),f(I_{2}),\ldots ,f(I_{N})\right\} , \quad (1) Fi=f({In}n=1N)={f(I1),f(I2),...,f(IN)},(1)
接着,利用 LLM 生成描述并使用 CLIP 文本编码器投影到共享语义空间:
F t = h ( G L L M ( c ) ) , ( 2 ) F_{\mathrm{t}} = h\left(\mathcal{G}_{\mathrm{LLM}}(c)\right), \quad (2) Ft=h(GLLM(c)),(2)
其中 G L L M ( c ) \mathcal{G}_{\mathrm{LLM}}(c) GLLM(c) 生成包含原始名称和四个改写变体的集合,从而引入潜在的知识和上下文多样性。
2.3 层次化多视图增强 (HMA)
HMA 通过中心裁剪、旋转(如 45 ∘ , 90 ∘ 45^{\circ}, 90^{\circ} 45∘,90∘ 等)和颜色抖动模拟自然变化,生成自然视图 I α I_{\alpha} Iα:
I α = { τ n ( I ) ∣ τ n ∈ T } , ( 3 ) I_{\alpha} = \{\tau_{n}(I) | \tau_{n}\in \mathcal{T}\} , \quad (3) Iα={τn(I)∣τn∈T},(3)
并由图像编码器提取其特征:
F α = f ( { I a ( m ) } m = 1 M ) = { f ( I a ( 1 ) ) , f ( I a ( 2 ) ) , ... , f ( I a ( M ) ) } , ( 4 ) F_{\alpha} = f(\{I_{a}^{(m)}\}{m = 1}^{M}) = \{f(I{a}^{(1)}),f(I_{a}^{(2)}),\dots ,f(I_{a}^{(M)})\} , \quad (4) Fα=f({Ia(m)}m=1M)={f(Ia(1)),f(Ia(2)),...,f(Ia(M))},(4)
同时利用水平翻转生成几何补充视图,以增强特征分布的丰富度。
2.4 自适应不确定类吸收器 (AUCA)
AUCA 通过插值和高斯分布采样构建"不确定类"以缓解类别干扰。插值数据公式为:
D i = α 1 − α ⋅ F j F k , ( 5 ) \mathbf{D}_i = \\alpha \\quad 1 - \\alpha \cdot \left\\mathbf{F}_j \\quad \\mathbf{F}_k\\right, \quad (5) Di=α1−α⋅FjFk,(5)
高斯采样数据为:
D n ∼ N ( 0 , 1 ) , ( 6 ) \mathbf{D}_{\mathrm{n}}\sim \mathcal{N}(0,1), \quad (6) Dn∼N(0,1),(6)
通过计算类原型间的余弦相似度 S j , k S_{j,k} Sj,k (式 7) 构造对称矩阵 S \mathbf{S} S (式 8),归一化后得到 S j , k ′ S_{j,k}^{\prime} Sj,k′ (式 9)。最终计算动态因子 λ \lambda λ:
λ = 1 − 2 ( C 2 ) ∑ j = 1 C − 1 ∑ k = j + 1 C S j , k ′ , ( 10 ) \lambda = 1 - \frac{2}{\binom{C}{2}}\sum_{j = 1}^{C - 1}\sum_{k = j + 1}^{C}S_{j,k}^{\prime}, \quad (10) λ=1−(2C)2j=1∑C−1k=j+1∑CSj,k′,(10)
不确定类数据 D u \mathbf{D}_{\mathrm{u}} Du 的期望表示为:
E D u = ( 1 − λ ) ⋅ D n + λ ⋅ D i , D u ∼ { D n , P ( D u = D n ) = 1 − λ D i , P ( D u = D i ) = λ , ( 11 ) \begin{array}{rl} & {\mathbb{E}\\mathbf{D}_{\\mathrm{u}} = (1 - \lambda)\cdot \mathbf{D}{\mathrm{n}} + \lambda \cdot \mathbf{D}{\mathrm{i}},}\\ & {\qquad \mathbf{D}{\mathrm{u}}\sim \left\{ \begin{array}{ll}\mathbf{D}{\mathrm{n}}, & P(\mathbf{D}{\mathrm{u}} = \mathbf{D}{\mathrm{n}}) = 1 - \lambda \\ \mathbf{D}{\mathrm{i}}, & P(\mathbf{D}{\mathrm{u}} = \mathbf{D}_{\mathrm{i}}) = \lambda \end{array} \right.,} \end{array} \quad (11) EDu=(1−λ)⋅Dn+λ⋅Di,Du∼{Dn,Di,P(Du=Dn)=1−λP(Du=Di)=λ,(11)
λ \lambda λ 反映了批次内类原型的差异,在跨域场景下通常较小,在单域场景下较大。最后使用逻辑回归分类器进行分类。
3. 实验 (Experiments)
3.1 数据集与设置
实验涵盖了 10 个数据集,包括 4 个单域(如 miniImageNet)和 6 个跨域数据集(如 CUB, EuroSAT, CropDisease)。使用 CLIP ViT-L/14 作为特征提取器,在 NVIDIA RTX 4090 上运行。
3.2 与 SOTA 方法对比
单域 FSL 结果:
如表 1 所示,在 5-way 1-shot 设置下,MPA 的平均准确率领先次优方法 12.29 % 12.29\% 12.29%。在 miniImageNet 和 FC100 等数据集上均取得了显著提升。
表 1:单域 5-way 1-shot 性能对比。
| Method | miniImageNet | tieredImageNet | CIFAR-FS | FC100 | Average |
|---|---|---|---|---|---|
| SPM (AAAI-24) | 93.70 | 88.79 | 82.40 | 68.35 | 83.31 |
| MPA (Ours) | 98.87 | 98.57 | 97.47 | 87.47 | 95.60 |
跨域 FSL 结果:
如表 2 和表 4 所示,MPA 在 5-way 1-shot 设置下平均提升了 24.56 % 24.56\% 24.56%。即使在 Cars 等具有挑战性的细粒度数据集上,MPA 依然表现强劲。
表 2:跨域 5-way 1-shot 分类对比。
| Method | CUB | Cars | Places | Planta | EuroSAT | CropDisease | Average |
|---|---|---|---|---|---|---|---|
| SPM (AAAI-24) | 84.39 | 41.71 | 72.35 | 53.85 | 74.97 | 84.43 | 68.62 |
| MPA (Ours) | 98.95 | 98.51 | 93.55 | 91.73 | 87.05 | 95.28 | 94.18 |
表 5:细粒度数据集 (CUB/Cars) 的对比。
|------------|--------|--------|--------|--------|
| Method | CUB || Cars ||
| Method | 1-shot | 5-shot | 1-shot | 5-shot |
| SPM | 84.39 | 95.95 | 41.71 | 62.89 |
| MPA (Ours) | 98.95 | 99.32 | 98.51 | 99.63 |
4. 结论 (Conclusion)
MPA 框架通过整合 LLM 语义增强、多视图变换和自适应不确定类吸收,极大地丰富了小样本任务中的原型表示。实验证明,该方法在各种复杂场景(包括单域、跨域和细粒度识别)中均具有极强的泛化能力和稳健性,为小样本学习提供了新的多模态解决方案。
消融实验 (Ablation Study)
MPA 组件的影响。如表 6 所示,为了全面评估我们 MPA 框架中各组件的贡献,我们在三个数据集上进行了消融实验。在不引入 HMA 和 AUCA 的情况下,单独使用 LMSE 就能显著提高 EuroSAT 和 CIFAR-FS 的性能。引入 HMA 后,Places 和 CIFAR-FS 的性能进一步提升,表明多视图增强有助于模型泛化。最后,当三个模块协同工作时,在所有数据集上均达到了最佳性能,展示了各模块的有效性和互补性。
表 6:5-way 1-shot 设置下三个组件在三个数据集上的消融实验。
| LMSE | HMA | AUCA | EuroSAT | Places | CIFAR-FS |
| × | × | × | 76.41 | 87.24 | 93.69 |
| ✓ | × | × | 83.03 | 93.43 | 95.36 |
| × | ✓ | × | 79.44 | 84.71 | 94.17 |
| ✓ | ✓ | × | 85.69 | 92.64 | 96.32 |
| ✓ | ✓ | ✓ | 87.05 | 93.55 | 97.47 |
骨干网络(Backbone)的影响。为了评估 MPA 在具有挑战性的 5-way 1-shot 设置下的泛化能力,我们在多种 CLIP 骨干网络变体上进行了实验,包括 ViT-L/14、ViT-B/32、ViT-B/16 和 ResNet101。如表 7 所示,MPA 在所有骨干网络和数据集上均始终优于基准线(Baseline),展示了在少样本场景下强大的鲁棒性和适应性。
扩展评估与分析 。为了进一步验证我们方法的通用性和鲁棒性,我们提供了几项扩展实验和分析。具体而言,表 8 考察了不同大语言模型(LLMs)对语义增强的影响,其中 GPT-4.0 获得了最高的准确率。附录 A 2 † A2^{\dagger} A2† 评估了 AUCA 在含有不确定样本的极端条件下的有效性。附录 A 3 † A3^{\dagger} A3† 展示了动态因子 λ \lambda λ 的统计分析,以证明 AUCA 在不同领域的适应性。附录 A 4 † A4^{\dagger} A4† 提供了 MPA 特征在五个目标域数据集上的 UMAP 可视化,结果显示与基准线相比,MPA 能清晰地分离类别边界。附录 A 5 † A5^{\dagger} A5† 提供了额外的特征可视化和分析。
这些发现一致支持了我们的方法在学习可迁移表示和应对多样化数据分布方面的有效性。
表 7:在 5-way 1-shot 设置下,不同 CLIP 骨干网络在三个数据集上的性能比较。
|---------------|-----------|---------|--------|-------|
| Method | Backbone | EuroSAT | Places | FC100 |
| Baseline Ours | ViT-L/14 | 76.41 | 87.24 | 77.18 |
| Baseline Ours | ViT-L/14 | 87.05 | 93.55 | 87.47 |
| Baseline Ours | ViT-B/32 | 65.47 | 82.32 | 60.20 |
| Baseline Ours | ViT-B/32 | 74.15 | 91.08 | 75.95 |
| Baseline Ours | ViT-B/16 | 71.19 | 83.92 | 67.95 |
| Baseline Ours | ViT-B/16 | 78.92 | 92.00 | 79.73 |
| Baseline Ours | ResNet101 | 57.88 | 78.71 | 46.40 |
| Baseline Ours | ResNet101 | 65.99 | 83.99 | 51.61 |
表 8:在两个数据集的 5-way 1-shot 任务上,使用不同 LLM 的 LMSE 性能比较。
| LLM | tieredImageNet | CIFAR-FS |
| GPT-3.5 | 97.88 | 97.20 |
| GPT-4.0 | 98.57 | 97.47 |
| DeepSeek-V3 | 97.79 | 97.01 |
| DeepSeek-R1 | 97.79 | 97.25 |
| ChatGLM-3 | 97.99 | 97.19 |
| Claude-4 | 98.17 | 97.39 |
| Gemini-2.5 | 98.17 | 96.53 |
| InternVL3 | 98.16 | 97.15 |
| Qwen2.5 | 98.15 | 97.36 |
| ERNIE X1 | 98.03 | 97.32 |
结论 (Conclusion)
在本文中,我们提出了一种名为 MPA 的新型多模态少样本学习框架,该框架包含基于大模型的变体语义增强(LMSE)、层次化多视图增强(HMA)和自适应不确定类别吸收器(AUCA),旨在提高泛化性和稳定性。LMSE 旨在生成高质量的语义特征,减少对图像数据的依赖;HMA 通过结合自然增强和几何视图来丰富支撑集表示;AUCA 通过插值和正态分布采样动态生成自适应不确定类别,以处理不确定样本并减少类别重叠。在四个单域数据集和六个跨域数据集上的实验表明,该方法达到了最先进的性能,证明了在各种少样本学习(FSL)场景中的强大泛化能力和有效性。
致谢 (Acknowledgments)
本研究由云南省基础研究计划项目(Nos. 202301AU070194 和 202501AT070233)、云南省专项项目(No. 202403AP140021)、云南大学专业学位研究生实践创新项目(No. ZC-24248950)、云南省专家工作站(No. 202305AF150078)以及中国国家自然科学基金(Nos. 62162067 和 62562061)资助。
附录 (Appendix)
A1. 训练程序
在少样本图像识别设置中,我们首先使用 CLIP 图像编码器从每张图像及其自然视图、几何视图中提取特征,捕捉自然变化和空间变换。同时,通过 CLIP 文本编码器获取类名的多变体语义信息。为了处理离群值并增强表示,动态生成不确定类别以吸收不确定样本。随后在丰富的支撑集特征上训练逻辑回归分类器,最后使用该分类器预测查询图像的标签。MPA 框架的详细描述和算法见算法 1。
算法 1:MPA 训练分类器的流程。
输入:目标域数据集 D t D_{t} Dt,CLIP 图像编码器 f θ f_{\theta} fθ,CLIP 文本编码器 h θ h_{\theta} hθ。
输出:训练好的逻辑回归参数 θ l o g i c \theta_{\mathrm{logic}} θlogic。
1: while training do
2: 从 D t D_{t} Dt 中随机采样一个少样本任务 T T T。
3: 通过公式 (3) 和 (4) 描述的层次化多视图增强来丰富支撑集表示。
4: 通过使用支撑集类名提示 LLM 来提取多变体语义表示,如公式 (2) 所示。
5: 将导出的语义嵌入通过 h θ h_{\theta} hθ 投影到视觉空间;通过向量复制调整维度并将其合并到支撑集中。
6: 利用公式 (5) 和 (11) 描述的生成机制合成不确定类别样本,并将其集成到支撑集中。
7: 使用逻辑回归分类器在丰富的支撑集上执行监督优化。
8: 相应地更新逻辑回归参数 θ l o g i c \theta_{\mathrm{logic}} θlogic。
9: end while
10: return θ l o g i c \theta_{\mathrm{logic}} θlogic。
A2. 极端条件下的 AUCA
为了评估 AUCA 的鲁棒性,我们在 5-way 5-shot 设置下引入了人工不确定性。如表 9 所示,AUCA 持续提升了性能,在 CUB 数据集上获得了 2.97 % 2.97\% 2.97% 的增益,在目标域上平均提升了 2.39 % 2.39\% 2.39%。
| AUCA | CUB | Cars | CIFAR-FS | FC100 |
| × | 82.75 | 84.96 | 73.89 | 60.29 |
| ✓ | 85.72 | 87.44 | 75.96 | 62.31 |
表 9:在 5-way 5-shot 设置下,包括人工添加不确定样本的目标域数据集的平均分类准确率。
| 数据集 | 识别任务 | 均值 | 方差 |
| CUB | 细粒度鸟类 | 0.3150 | 0.0011 |
| Cars | 细粒度汽车 | 0.3646 | 0.0014 |
| Places | 场景 | 0.4727 | 0.0018 |
| Planta | 植物 | 0.3236 | 0.0012 |
| EuroSAT | 卫星图像 | 0.2244 | 0.0013 |
| CropDisease | 农业病害 | 0.2208 | 0.0014 |
| miniImageNet | 通用少样本 | 0.3947 | 0.0015 |
| tieredImageNet | 通用少样本 | 0.4257 | 0.0013 |
| CIFAR-FS | 通用少样本 | 0.3002 | 0.0009 |
| FC100 | 通用少样本 | 0.2779 | 0.0011 |
表 10:来自不同领域的各个数据集上动态因子 λ \lambda λ 的均值和方差。
... (此处省略原文中冗长的空表格行) ...
|---|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|
| TieredImageNet |||
| | | |
| | | |
| | Original Abstract: Recently, few-shot learning (FSL) has become a popular task that aims to recognize new classes from only a few labeled examples and has been widely applied in fields such as natural science, remote sensing, and medical images. However, most existing methods focus only on the visual modality and compute prototypes directly from raw support images, which lack comprehensive and rich multimodal information. To address these limitations, we propose a novel Multimodal Prototype Augmentation FSL framework called MPA, including LLM-based Multi-Variant Semantic Enhancement (LMSE), Hierarchical Multi-View Augmentation (HMA), and an Adaptive Uncertain Class Absorber (AUCA). LMSE leverages large language models to generate diverse paraphrased category descriptions, enriching the support set with additional semantic cues. HMA exploits both natural and multi-view augmentations to enhance feature diversity (e.g., changes in viewing distance, camera angles, and lighting conditions). AUCA models uncertainty by introducing uncertain classes via interpolation and Gaussian sampling, effectively absorbing uncertain samples. Extensive experiments on four single-domain and six cross-domain FSL benchmarks demonstrate that MPA achieves superior performance compared to existing state-of-the-art methods across most settings. Notably, MPA surpasses the second-best method by 12.29% and 24.56% in the single-domain and cross-domain setting, respectively, in the 5-way 1-shot setting. PDF Link: 2602.10143v1 #### 部分平台可能图片显示异常,请以我的博客内容为准  |
|