文章目录
-
- TCP可靠性与性能优化详解:从确认应答到拥塞控制
- 一、确认应答(ACK)机制
-
- [1.1 什么是确认应答](#1.1 什么是确认应答)
- [1.2 序列号和确认号的作用](#1.2 序列号和确认号的作用)
- [1.3 确认应答的图示](#1.3 确认应答的图示)
- [1.4 确认应答的问题](#1.4 确认应答的问题)
- 二、超时重传机制
-
- [2.1 为什么需要超时重传](#2.1 为什么需要超时重传)
- [2.2 超时重传的原理](#2.2 超时重传的原理)
- [2.3 超时重传的图示](#2.3 超时重传的图示)
- [2.4 超时时间如何确定](#2.4 超时时间如何确定)
- [2.5 动态计算超时时间](#2.5 动态计算超时时间)
- [2.6 重传次数限制](#2.6 重传次数限制)
- 三、滑动窗口机制
-
- [3.1 滑动窗口的核心思想](#3.1 滑动窗口的核心思想)
- [3.2 滑动窗口的工作原理](#3.2 滑动窗口的工作原理)
- [3.3 滑动窗口的详细图示](#3.3 滑动窗口的详细图示)
- [3.4 滑动窗口的优势](#3.4 滑动窗口的优势)
- [3.5 发送缓冲区的作用](#3.5 发送缓冲区的作用)
- 四、丢包的处理:重传机制详解
-
- [4.1 情况1:数据包到达,ACK丢失](#4.1 情况1:数据包到达,ACK丢失)
- [4.2 情况2:数据包丢失](#4.2 情况2:数据包丢失)
- [4.3 快速重传的图示](#4.3 快速重传的图示)
- [4.4 快速重传的优势](#4.4 快速重传的优势)
- [4.5 接收缓冲区的作用](#4.5 接收缓冲区的作用)
- 五、流量控制
-
- [5.1 流量控制的问题](#5.1 流量控制的问题)
- [5.2 流量控制的原理](#5.2 流量控制的原理)
- [5.3 流量控制的例子](#5.3 流量控制的例子)
- [5.4 流量控制的图示](#5.4 流量控制的图示)
- [5.5 窗口探测](#5.5 窗口探测)
- [5.6 窗口扩大因子](#5.6 窗口扩大因子)
- 六、拥塞控制
-
- [6.1 拥塞控制的问题](#6.1 拥塞控制的问题)
- [6.2 拥塞控制的目标](#6.2 拥塞控制的目标)
- [6.3 拥塞窗口(cwnd)](#6.3 拥塞窗口(cwnd))
- [6.4 慢启动(Slow Start)](#6.4 慢启动(Slow Start))
- [6.5 慢启动阈值(ssthresh)](#6.5 慢启动阈值(ssthresh))
- [6.6 拥塞避免(Congestion Avoidance)](#6.6 拥塞避免(Congestion Avoidance))
- [6.7 拥塞发生后的处理](#6.7 拥塞发生后的处理)
- [6.8 拥塞控制的完整过程](#6.8 拥塞控制的完整过程)
- [6.9 拥塞控制的类比](#6.9 拥塞控制的类比)
- 七、延迟应答与捎带应答
-
- [7.1 延迟应答(Delayed ACK)](#7.1 延迟应答(Delayed ACK))
- [7.2 捎带应答(Piggybacking)](#7.2 捎带应答(Piggybacking))
- 八、面向字节流与粘包问题
-
- [8.1 面向字节流的含义](#8.1 面向字节流的含义)
- [8.2 TCP缓冲区机制](#8.2 TCP缓冲区机制)
- [8.3 读写不匹配](#8.3 读写不匹配)
- [8.4 粘包问题](#8.4 粘包问题)
- [8.5 解决粘包问题](#8.5 解决粘包问题)
- [8.6 UDP有粘包问题吗](#8.6 UDP有粘包问题吗)
- 九、TCP异常情况处理
-
- [9.1 进程终止](#9.1 进程终止)
- [9.2 机器重启](#9.2 机器重启)
- [9.3 机器掉电或网线断开](#9.3 机器掉电或网线断开)
- [9.4 保活定时器(Keep-Alive)](#9.4 保活定时器(Keep-Alive))
- 十、TCP小结
-
- [10.1 TCP为什么可靠](#10.1 TCP为什么可靠)
- [10.2 TCP如何提高性能](#10.2 TCP如何提高性能)
- [10.3 TCP的设计哲学](#10.3 TCP的设计哲学)
- [10.4 容易混淆的点](#10.4 容易混淆的点)
TCP可靠性与性能优化详解:从确认应答到拥塞控制
💬 开篇:上一篇我们学习了TCP的连接管理------三次握手和四次挥手。连接建立之后,TCP如何保证数据可靠地传输呢?这就涉及到TCP的核心机制:确认应答、超时重传、滑动窗口、流量控制、拥塞控制。同时,TCP还通过延迟应答、捎带应答、快速重传等机制来提高性能。这一篇会详细讲解这些机制的原理、实现方式、优化策略。理解了这些,你就理解了TCP为什么既可靠又高效。
👍 点赞、收藏与分享:这篇会把TCP的可靠性机制和性能优化讲透,包括滑动窗口、拥塞控制、粘包问题等核心内容。如果对你有帮助,请点赞收藏!
🚀 循序渐进:从确认应答讲起,到超时重传,到滑动窗口,到流量控制,到拥塞控制,到粘包问题,一步步掌握TCP的可靠性保证和性能优化。
一、确认应答(ACK)机制
1.1 什么是确认应答
确认应答(ACK):接收方告诉发送方"我已经收到了你的数据"。
类比:
bash
唐僧讲经:
唐僧说一句,悟空答一句"师父,我听懂了"
唐僧继续说下一句TCP的确认应答:
bash
发送方发送数据
接收方收到数据后,发送ACK
发送方收到ACK后,继续发送下一批数据1.2 序列号和确认号的作用
序列号(Sequence Number):
- 标识发送的数据的第一个字节的序号
- 用于排序和去重
确认号(Acknowledgment Number):
- 表示"下一个我要接收的序列号"
- 告诉发送方"我已经收到了序列号xxx之前的所有数据"
例子:
bash
发送方发送:序列号1000,数据100字节(字节序号1000-1099)
接收方收到后,发送ACK:确认号1100
含义:"我已收到1000-1099,下一个要接收的是1100"1.3 确认应答的图示
bash
发送方 接收方
| |
| 发送:seq=1000, data=100字节 |
|----------------------------->|
| | 收到1000-1099
| |
| 收到ACK | 发送:ack=1100
|<-----------------------------|
| |
| 发送:seq=1100, data=100字节 |
|----------------------------->|
| | 收到1100-1199
| |
| 收到ACK | 发送:ack=1200
|<-----------------------------|
| |1.4 确认应答的问题
问题:一发一收的方式性能太低。
分析:
bash
发送数据 → 等待ACK → 收到ACK → 发送下一批数据
如果网络延迟高(比如100ms),每次都要等待100ms
吞吐量 = 数据量 / (数据传输时间 + 等待ACK时间)例子:
bash
数据量:1000字节
数据传输时间:1ms
等待ACK时间:100ms
吞吐量 = 1000 / (1 + 100) = 9.9字节/ms ≈ 10KB/s
太慢了!解决方法:滑动窗口(后面详细讲)。
二、超时重传机制
2.1 为什么需要超时重传
问题:数据或ACK可能在网络中丢失。
场景1:数据丢失
bash
发送方发送数据
数据在网络中丢失了
接收方收不到数据,不会发送ACK
发送方一直等待ACK场景2:ACK丢失
bash
发送方发送数据
接收方收到数据,发送ACK
ACK在网络中丢失了
发送方收不到ACK,以为数据丢失了解决方法:超时重传。
2.2 超时重传的原理
核心思想:如果一段时间内没收到ACK,就重发数据。
流程:
bash
1. 发送数据
2. 启动定时器
3. 等待ACK
* 如果在超时时间内收到ACK:停止定时器,发送下一批数据
* 如果超时:重发数据,重新启动定时器2.3 超时重传的图示
场景1:数据丢失,超时重传
bash
发送方 接收方
| |
| 发送:seq=1000 |
|------------X 数据丢失 |
| |
| 等待ACK... |
| 超时! |
| |
| 重传:seq=1000 |
|----------------------------->|
| | 收到1000
| |
| 收到ACK | 发送:ack=1100
|<-----------------------------|
| |场景2:ACK丢失,接收方去重
bash
发送方 接收方
| |
| 发送:seq=1000 |
|----------------------------->|
| | 收到1000
| |
| 等待ACK... | 发送:ack=1100
| X<-----| ACK丢失
| 超时! |
| |
| 重传:seq=1000 |
|----------------------------->|
| | 收到重复的1000(去重)
| |
| 收到ACK | 发送:ack=1100
|<-----------------------------|
| |2.4 超时时间如何确定
问题:超时时间设多长合适?
太长的问题:
bash
超时时间=10秒
数据丢失了,要等10秒才能重传
吞吐量严重下降太短的问题:
bash
超时时间=10ms
网络延迟=100ms
每次都会超时重传,导致大量重复数据
浪费带宽理想的超时时间:
bash
超时时间 = RTT(往返时间) + 一些余量2.5 动态计算超时时间
RTT(Round-Trip Time):数据发送到接收并收到ACK的时间。
TCP的超时时间计算:
bash
RTO (Retransmission Timeout) = SRTT + 4 × RTTVAR
SRTT (Smoothed RTT):平滑的RTT
RTTVAR (RTT Variance):RTT的方差动态调整:
bash
每次收到ACK时,测量RTT
更新SRTT和RTTVAR
重新计算RTOLinux的实现:
bash
超时时间以500ms为单位
如果重传一次后仍未收到ACK,等待2×500ms后再重传
如果再重传仍未收到ACK,等待4×500ms后再重传
依次类推:500ms → 1000ms → 2000ms → 4000ms → ...
指数退避(Exponential Backoff)2.6 重传次数限制
问题:一直重传下去吗?
答案:不是,有次数限制。
Linux的限制:
bash
累计重传次数达到一定限制后,认为网络或对端异常
强制关闭连接查看重传次数限制:
bash
cat /proc/sys/net/ipv4/tcp_retries2
# 通常是15次三、滑动窗口机制
3.1 滑动窗口的核心思想
问题回顾:一发一收的性能太低。
解决方法:一次发送多个数据段,不用等待ACK。
滑动窗口:
bash
允许发送方在收到ACK之前,连续发送多个数据段
窗口大小:无需等待ACK就能发送的最大数据量类比:
bash
一发一收 = 单车道(一次只能过一辆车)
滑动窗口 = 多车道(可以同时过多辆车)3.2 滑动窗口的工作原理
窗口大小:假设窗口大小为4000字节(4个段,每个段1000字节)。
发送过程:
bash
1. 一次性发送4个段:seq=1000, 2000, 3000, 4000
2. 收到第一个ACK(ack=2000)
3. 窗口向右滑动,可以发送seq=5000
4. 收到第二个ACK(ack=3000)
5. 窗口继续滑动,可以发送seq=6000
...图示:
bash
发送缓冲区:
┌────┬────┬────┬────┬────┬────┬────┬────┐
│1000│2000│3000│4000│5000│6000│7000│8000│
└────┴────┴────┴────┴────┴────┴────┴────┘
└─────────────┘
已发送未确认(窗口)
收到ack=2000后,窗口滑动:
┌────┬────┬────┬────┬────┬────┬────┬────┐
│1000│2000│3000│4000│5000│6000│7000│8000│
└────┴────┴────┴────┴────┴────┴────┴────┘
└─────────────┘
已发送未确认(窗口)3.3 滑动窗口的详细图示
bash
发送方 接收方
| |
| 发送:seq=1000 |
|----------------------------->|
| 发送:seq=2000(不等ACK) |
|----------------------------->|
| 发送:seq=3000 |
|----------------------------->|
| 发送:seq=4000 |
|----------------------------->|
| | 收到1000
| | 发送:ack=2000
| 收到ack=2000 |<----|
| 窗口滑动,发送seq=5000 |
|----------------------------->|
| | 收到2000
| | 发送:ack=3000
| 收到ack=3000 |<----|
| 窗口滑动,发送seq=6000 |
|----------------------------->|
| |3.4 滑动窗口的优势
性能提升:
bash
无滑动窗口:
每次发送1000字节,等待100ms
吞吐量 = 1000 / 100ms = 10KB/s
有滑动窗口(窗口大小4000字节):
一次发送4000字节,等待100ms
吞吐量 = 4000 / 100ms = 40KB/s
性能提升4倍!核心公式:
bash
吞吐量 ≈ 窗口大小 / RTT结论:
bash
窗口越大,网络吞吐量越高3.5 发送缓冲区的作用
问题:如果ACK丢失了,如何重传?
答案:使用发送缓冲区。
发送缓冲区的作用:
bash
1. 保存已发送但未收到ACK的数据
2. 如果超时,可以从缓冲区重传
3. 收到ACK后,删除对应的数据发送缓冲区的状态:
bash
┌──────────────┬──────────────┬──────────────┐
│ 已确认 │ 已发送未确认 │ 未发送 │
│ (可删除) │ (等待ACK) │ (待发送) │
└──────────────┴──────────────┴──────────────┘
└──────────────┘
滑动窗口四、丢包的处理:重传机制详解
4.1 情况1:数据包到达,ACK丢失
场景:
bash
发送:seq=1000, 2000, 3000, 4000
接收方收到所有数据
ACK:ack=2000丢失
ACK:ack=3000到达
ACK:ack=4000到达
ACK:ack=5000到达处理:
bash
收到ack=3000,说明1000和2000都已收到
收到ack=5000,说明1000-4000都已收到
部分ACK丢失不要紧,后续ACK可以确认图示:
bash
发送方 接收方
| |
| seq=1000 |
|----------------------------->| 收到
| seq=2000 | ack=2000
|----------------------------->|<----X 丢失
| seq=3000 | 收到
|----------------------------->| ack=3000
| |<----|
| 收到ack=3000 |
| (说明1000和2000都已收到) |
| |4.2 情况2:数据包丢失
场景:
bash
发送:seq=1000, 2000, 3000, 4000
seq=2000丢失
接收方收到:1000, 3000, 4000接收方的行为:
bash
收到1000:发送ack=2000(期望下一个是2000)
收到3000:发送ack=2000(还是期望2000)
收到4000:发送ack=2000(仍然期望2000)发送方的行为:
bash
连续收到3个ack=2000
判断:seq=2000肯定丢失了
立即重传seq=2000(不等超时)这就是"快速重传"(Fast Retransmit)。
4.3 快速重传的图示
bash
发送方 接收方
| |
| seq=1000 |
|----------------------------->| 收到1000
| | ack=2000
| seq=2000 |<----|
|-------X 丢失 |
| seq=3000 |
|----------------------------->| 收到3000(乱序)
| | ack=2000(重复ACK)
| seq=4000 |<----|
|----------------------------->| 收到4000(乱序)
| | ack=2000(重复ACK)
| seq=5000 |<----|
|----------------------------->| 收到5000(乱序)
| | ack=2000(重复ACK)
| 收到3个ack=2000 |<----|
| 快速重传seq=2000 |
|----------------------------->| 收到2000ack=6000 |<----|
| (说明2000-5000都已收到) |
| |4.4 快速重传的优势
对比超时重传:
bash
超时重传:等待RTO(可能是几秒)
快速重传:连续3个重复ACK立即重传(几十毫秒)性能提升:
bash
减少等待时间
提高吞吐量4.5 接收缓冲区的作用
问题:接收方收到乱序的数据怎么办?
答案:使用接收缓冲区。
接收缓冲区的作用:
bash
1. 保存已接收但乱序的数据
2. 等待缺失的数据到达
3. 按顺序交付给应用层例子:
bash
接收顺序:1000, 3000, 4000, 2000
缓冲区:先存3000和4000,等待2000
收到2000后,按顺序交付:1000, 2000, 3000, 4000五、流量控制
5.1 流量控制的问题
问题:接收方的处理速度有限。
场景:
bash
发送方:每秒发送100MB数据
接收方:每秒只能处理10MB数据
接收缓冲区:只有1MB
结果:接收缓冲区很快被打满,后续数据被丢弃后果:
bash
大量丢包
大量重传
性能严重下降5.2 流量控制的原理
核心思想:接收方告诉发送方"我的缓冲区还有多少空间"。
实现方式:
bash
接收方在ACK中告诉发送方:窗口大小(剩余缓冲区大小)
发送方根据窗口大小调整发送速度TCP首部的窗口字段:
bash
16位窗口大小字段
最大值:65535字节5.3 流量控制的例子
场景:
bash
接收缓冲区大小:10000字节
已接收但尚未被应用层处理的数据:6000字节
剩余可用缓冲区:4000字节
接收方发送ACK:
ACK标志 = 1
确认号 = ...
窗口大小 = 4000
(告诉发送方:我还能再接收4000字节)发送方的行为:
bash
收到窗口大小=4000
最多再发送4000字节
等待接收方处理数据,窗口变大5.4 流量控制的图示
bash
发送方 接收方
| |
| 发送4000字节 |
|----------------------------->| 接收缓冲区:4000/10000
| | ack, window=6000
|<-----------------------------|
| |
| 发送6000字节 |
|----------------------------->| 接收缓冲区:10000/10000(满了)
| | ack, window=0
|<-----------------------------|
| |
| 收到window=0,停止发送 |
| | 应用层读取数据...
| | 接收缓冲区:5000/10000
| | ack, window=5000
|<-----------------------------|
| |
| 收到window=5000,继续发送 |
| |5.5 窗口探测
问题:如果接收方缓冲区满了(window=0),发送方停止发送。但接收方的窗口更新ACK丢失了怎么办?
场景:
bash
接收方:window=0
发送方:停止发送
接收方处理了数据:window=5000,发送ACK
ACK丢失
发送方:不知道窗口变大了,一直等待
死锁!解决方法:窗口探测(Window Probe)。
窗口探测:
bash
发送方在收到window=0后,定期发送1字节的探测数据
接收方收到探测数据,回复当前的窗口大小
发送方获得最新的窗口大小5.6 窗口扩大因子
问题:窗口大小字段只有16位
bash
高带宽:1Gbps = 125MB/s
高延迟:RTT=100ms
理想窗口大小 = 125MB/s × 0.1s = 12.5MB
远超65535字节!解决方法:窗口扩大因子(Window Scale)。
窗口扩大因子:
bash
在TCP选项中协商一个扩大因子(0-14)
实际窗口大小 = 窗口字段值 << 扩大因子
例如:窗口字段=65535,扩大因子=7
实际窗口 = 65535 << 7 = 8388480字节 ≈ 8MB六、拥塞控制
6.1 拥塞控制的问题
问题 :网络拥堵时,盲目发很拥堵(路由器缓冲区快满了)
发送方继续高速发送数据
路由器缓冲区满了,丢弃数据包
发送方重传,继续发送大量数据
网络更加拥堵
恶性循环!
后果:
bash
网络拥塞崩溃(Congestion Collapse)
所有连接的吞吐量都下降6.2 拥塞控制的目标
目标:
bash
1. 尽可能快地发送数据(提高吞吐量)
2. 避免造成网络拥堵(维持稳定性)平衡:
bash
发送太慢:浪费带宽
发送太快:造成拥堵6.3 拥塞窗口(cwnd)
拥塞窗口(Congestion Window, cwnd):
bash
发送方估算的网络能承受的数据量
根据网络状况动态调整实际发送窗口:
bash
实际窗口 = min(拥塞窗口, 接收方窗口)
拥塞窗口:避免网络拥堵
接收方窗口:避免接收方过载
取两者的最小值6.4 慢启动(Slow Start)
核心思想:从小窗口开始,逐渐增大。
初始值:
bash
拥塞窗口 cwnd = 1个MSS(Maximum Segment Size,最大报文段大小)
通常MSS = 1460字节增长规则:
bash
每收到一个ACK,cwnd += 1个MSS例子:
bash
初始:cwnd = 1
发送1个段,收到1个ACK:cwnd = 2
发送2个段,收到2个ACK:cwnd = 4
发送4个段,收到4个ACK:cwnd = 8
发送8个段,收到8个ACK:cwnd = 16
...增长速度:
bash
指数增长:1 → 2 → 4 → 8 → 16 → 32 → 64 → ...6.5 慢启动阈值(ssthresh)
问题:一直指数增长会导致网络拥堵。
解决方法:引入慢启动阈值(Slow Start Threshold, ssthresh)。
规则:
bash
cwnd < ssthresh:慢启动,指数增长
cwnd >= ssthresh:拥塞避免,线性增长初始值:
bash
ssthresh = 接收方窗口大小(或一个很大的值)6.6 拥塞避免(Congestion Avoidance)
核心思想:到达阈值后,缓慢增长。
增长规则:
bash
每收到一个完整窗口的ACK,cwnd += 1个MSS例子:
bash
cwnd = 8(8个段)
发送8个段,收到8个ACK:cwnd = 9
发送9个段,收到9个ACK:cwnd = 10
...增长速度:
bash
线性增长:每个RTT增加1个MSS6.7 拥塞发生后的处理
情况1:超时重传(严重拥塞)
判断:
bash
超时未收到ACK
说明网络严重拥堵(可能大量丢包)处理:
bash
1. ssthresh = cwnd / 2(阈值减半)
2. cwnd = 1(重新慢启动)
3. 重传数据情况2:快速重传(轻微拥塞)
判断:
bash
收到3个重复ACK
说明网络轻微拥堵(部分丢包)处理(快速恢复):
bash
1. ssthresh = cwnd / 2(阈值减半)
2. cwnd = ssthresh(不是1,而是阈值)
3. 重传数据
4. 进入拥塞避免阶段(线性增长)6.8 拥塞控制的完整过程
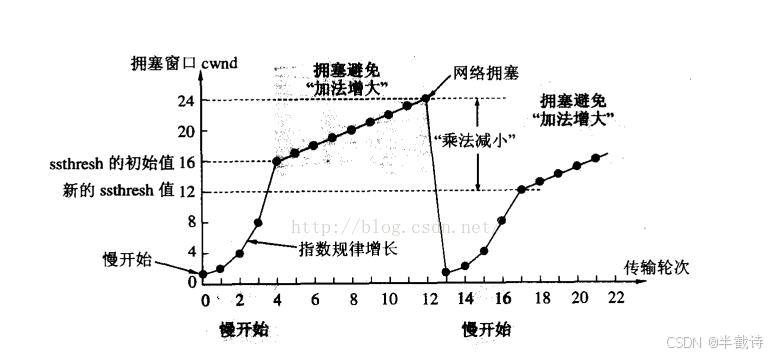
由上面知识我们可以知道,图中所显示的网络拥塞一定是发生了超时重传,cwnd=1
6.9 拥塞控制的类比
类比:热恋的感觉
bash
初期(慢启动):
感情快速升温,每天见面次数翻倍
1次 → 2次 → 4次 → 8次 → ...
稳定期(拥塞避免):
到达一定程度后,缓慢增加
每周增加1次见面
吵架(拥塞发生):
小吵架(快速重传):见面次数减半,但不回到初期
大吵架(超时重传):回到初期,重新开始七、延迟应答与捎带应答
7.1 延迟应答(Delayed ACK)
问题:立即应答可能窗口太小。
场景:
bash
接收缓冲区:1MB
收到500KB数据
立即回复ACK:window=500KB
但实际上:
应用层很快处理了这500KB数据(10ms)
如果延迟200ms再回复ACK:window=1MB延迟应答的好处:
bash
窗口更大 → 吞吐量更高延迟应答的规则:
bash
1. 数量限制:每收到N个包,就应答一次(通常N=2)
2. 时间限制:超过最大延迟时间,立即应答(通常200ms)例子:
bash
收到第1个包:不立即应答
收到第2个包:应答(确认1和2)
收到第3个包:不立即应答
收到第4个包:应答(确认3和4)7.2 捎带应答(Piggybacking)
场景:很多应用层协议是"一发一收"的。
例子:
bash
客户端发送:"How are you?"
服务器收到后:
1. 需要发送ACK(确认收到)
2. 需要发送响应:"Fine, thank you!"捎带应答:
bash
把ACK和响应数据合并发送
一个TCP段同时包含:
- ACK标志=1,确认号=...
- 数据="Fine, thank you!"图示:
bash
客户端 服务器
|
|----------------------------->|
| | 收到
| |
| 收到捎带应答 | 发送:ACK + "Fine, thank you!"
|<-----------------------------|
| |
省略了一个单独的ACK报文优势:
bash
减少报文数量
提高效率八、面向字节流与粘包问题
8.1 面向字节流的含义
TCP是面向字节流的:
bash
应用层看到的是连续的字节流
没有明确的消息边界对比UDP:
bash
UDP是面向数据报的
应用层看到的是一个个独立的数据报
有明确的消息边界8.2 TCP缓冲区机制
发送缓冲区:
bash
应用层调用send(),数据先放入发送缓冲区
TCP根据情况决定何时发送:
- 缓冲区满了:立即发送
- 收到PSH标志:立即发送
- 达到一定时机:发送接收缓冲区:
bash
TCP收到数据,放入接收缓冲区
应用层调用recv(),从缓冲区读取数据全双工:
bash
一个TCP连接同时有发送缓冲区和接收缓冲区
既可以读,也可以写8.3 读写不匹配
TCP的读写可以不匹配:
例子1:多次写,一次读
cpp
// 发送端
send("hello"); // 5字节
send("world"); // 5字节
send("!"); // 1字节
// 接收端
recv(buf, 100); // 一次读取11字节:"helloworld!"例子2:一次写,多次读
cpp
// 发送端
send("hello world!", 12); // 12字节
// 接收端
recv(buf, 5); // 读取5字节:"hello"
recv(buf, 7); // 读取7字节:" world!"结论:
bash
TCP的读写次数和数量可以不匹配
站在应用层的角度,看到的是连续的字节流8.4 粘包问题
粘包问题:
bash
应用层无法区分两个数据包的边界例子:
bash
发送端发送两个数据包:
包1:"hello"
包2:"world"
接收端可能收到:
情况1:"hello" 和 "world"(正常)
情况2:"helloworld"(粘包)
情况3:"hel" 和 "loworld"(拆包)
情况4:"he" "llo" "wo" "rld"(拆包)为什么会粘包:
bash
1. TCP的发送缓冲区可能合并数据
2. TCP的接收缓冲区可能合并数据
3. 网络层可能分片或合并数据8.5 解决粘包问题
核心:明确两个包之间的边界。
方法1:定长包
cpp
// 每个包固定100字节
struct Packet {
char data[100];
};
// 发送
Packet pkt;
strcpy(pkt.data, "hello");
send(&pkt, sizeof(pkt)); // 固定100字节
// 接收
Packet pkt;
recv(&pkt, sizeof(pkt)); // 固定接收100字节优点 :简单
缺点:浪费空间(数据不够100字节也要占用100字节)
方法2:包头长度字段
cpp
// 包头包含长度字段
struct PacketHeader {
uint32_t length; // 数据长度
};
struct Packet {
PacketHeader header;
char data[]; // 可变长度
};
// 发送
std::string msg = "hello world";
PacketHeader header;
header.length = msg.size();
send(&header, sizeof(header));
send(msg.c_str(), msg.size());
// 接收
PacketHeader header;
recv(&header, sizeof(header)); // 先接收包头
char* buf = new char[header.length];
recv(buf, header.length); // 根据长度接收数据优点 :不浪费空间
缺点:需要两次recv(先接收包头,再接收数据)
方法3:分隔符
cpp
// 使用特殊分隔符(如\n或\r\n)
// HTTP协议使用\r\n
// 发送
send("hello\n");
send("world\n");
// 接收
while (true) {
char c;
std::string line;
while (recv(&c, 1) > 0) {
if (c == '\n') {
break; // 遇到分隔符,一个包结束
}
line += c;
}
// line是一个完整的包
}优点 :简单直观
缺点:
- 数据中不能包含分隔符(需要转义)
- 效率较低(逐字节读取)
方法4:应用层协议
cpp
// 例如HTTP协议
// 包头用\r\n\r\n分隔
// 包头中包含Content-Length字段
// 例子:
GET / HTTP/1.1\r\n
Host: www.example.com\r\n
Content-Length: 11\r\n
\r\n
hello world
// 接收流程:
1. 读取包头(直到\r\n\r\n)
2. 解析Content-Length字段
3. 根据Content-Length读取数据8.6 UDP有粘包问题吗
答案:UDP没有粘包问题。
原因:
bash
UDP是面向数据报的
每个数据报都是独立的
有明确的边界例子:
cpp
// 发送端
sendto("hello", 5); // 数据报1
sendto("world", 5); // 数据报2
// 接收端
recvfrom(buf, 100); // 要么收到完整的"hello",要么收不到
recvfrom(buf, 100); // 要么收到完整的"world",要么收不到
不会收到"helloworld"或"hel"结论:
bash
UDP:
- 要么收到完整的数据报
- 要么收不到(丢失)
- 不会出现"半个"或"粘在一起"的情况九、TCP异常情况处理
9.1 进程终止
场景:进程意外终止(如Ctrl+C、crash)。
处理:
bash
1. 进程终止
2. 操作系统自动关闭所有文件描述符(包括socket)
3. 发送FIN(正常关闭流程)结论:
bash
和正常关闭没有什么区别
四次挥手正常进行9.2 机器重启
场景:机器重启(reboot)。
处理:
bash
1. 操作系统关闭所有进程
2. 发送FIN或RST(取决于操作系统)
3. 对端收到FIN或RST,关闭连接结论:
bash
和进程终止类似
连接会被正常关闭9.3 机器掉电或网线断开
场景:机器突然掉电,或网线被拔掉。
问题:无法发送FIN。
对端的处理:
情况1:对端有数据要发送
bash
1. 对端发送数据
2. 等待ACK,超时
3. 重传数据,再次超时
4. 多次重传失败后,判断连接已断开
5. 返回错误给应用层情况2:对端没有数据要发送
1. 对端一直等bash待
2. 连接看起来仍然存在
3. 但实际上对方已经不在了解决方法:保活定时器(Keep-Alive)
9.4 保活定时器(Keep-Alive)
保活定时器:定期检测对方是否还在。
工作原理:
bash
1. 如果一段时间内没有数据传输
2. 定期发送保活探测包(1字节数据)
3. 如果收到ACK,说明对方还在
4. 如果多次探测都没有响应,判断连接已断开Linux的保活参数:
bash
# 保活时间(多久没数据后开始探测)
cat /proc/sys/net/ipv4/tcp_keepalive_time
# 默认7200秒(2小时)
# 保活间隔(探测包的间隔)
cat /proc/sys/net/ipv4/tcp_keepalive_intvl
# 默认75秒
# 保活探测次数(多少次探测失败后判断断开)
cat /proc/sys/net/ipv4/tcp_keepalive_probes
# 默认9次总时间:
bash
2小时 + 75秒 × 9 = 2小时11分15秒
才能判断连接已断开启用保活:
cpp
int opt = 1;
setsockopt(sockfd, SOL_SOCKET, SO_KEEPALIVE, &opt, sizeof(opt));应用层的心跳:
bash
TCP的保活时间太长(2小时)
很多应用层协议自己实现心跳机制
例如:HTTP长连接、QQ、游戏
通常间隔:30秒到5分钟十、TCP小结
10.1 TCP为什么可靠
可靠性机制:
- 校验和:检测数据是否损坏
- 序列号:排序和去重
- 确认应答:确认收到数据
- 超时重传:数据丢失后重传
- 连接管理:三次握手和四次挥手
- 流量控制:避免接收方过载
- 拥塞控制:避免网络拥堵
10.2 TCP如何提高性能
性能优化:
- 滑动窗口:一次发送多个段,不等ACK
- 快速重传:连续3个重复ACK立即重传
- 延迟应答:等待缓冲区有更多空间再应答
- 捎带应答:把ACK和数据合并发送
- 拥塞控制:根据网络状况动态调整发送速度
10.3 TCP的设计哲学
核心矛盾:
bash
可靠性 vs 性能TCP的选择:
bash
在保证可靠性的前提下,尽可能提高性能具体体现:
bash
确认应答:保证可靠性
滑动窗口:提高性能
超时重传:保证可靠性
快速重传:提高性能
流量控制:保证可靠性
拥塞控制:提高性能并维持网络稳定10.4 容易混淆的点
-
序列号vs确认号:
- 序列号:我发送的数据的第一个字节的序号
- 确认号:下一个我要接收的序列号
-
流量控制vs拥塞控制:
- 流量控制:避免接收方过载(接收方窗口)
- 拥塞控制:避免网络拥堵(拥塞窗口)
-
慢启动vs拥塞避免:
- 慢启动:指数增长(1→2→4→8→16...)
- 拥塞避免:线性增长(每个RTT增加1个MSS)
-
超时重传vs快速重传:
- 超时重传:等待RTO超时后重传
- 快速重传:收到3个重复ACK立即重传
-
粘包问题:
- TCP有粘包问题(面向字节流)
- UDP没有粘包问题(面向数据报)
💬 总结:TCP通过一系列复杂的机制,在保证可靠性的同时,尽可能提高性能。确认应答和超时重传保证了可靠性,滑动窗口和快速重传提高了性能,流量控制避免接收方过载,拥塞控制避免网络拥堵。这些机制相互配合,使TCP成为互联网上最重要的传输层协议。理解了这些机制,你就理解了TCP为什么既可靠又高效。下一篇我们会总结TCP和UDP的对比,以及用UDP实现可靠传输的方法。
👍 点赞、收藏与分享:如果这篇帮你理解了TCP的可靠性机制和性能优化,请点赞收藏!网络编程,从理解TCP的核心机制开始!